 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Safe Adaptive Learning-based Control for Constrained Linear Quadratic Regulators with Regret Guarantees
Oct 31, 2021
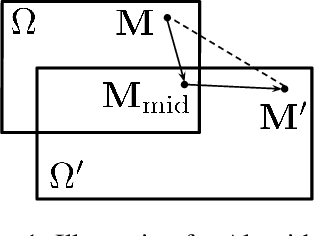
We study the adaptive control of an unknown linear system with a quadratic cost function subject to safety constraints on both the states and actions. The challenges of this problem arise from the tension among safety, exploration, performance, and computation. To address these challenges, we propose a polynomial-time algorithm that guarantees feasibility and constraint satisfaction with high probability under proper conditions. Our algorithm is implemented on a single trajectory and does not require system restarts. Further, we analyze the regret of our learning algorithm compared to the optimal safe linear controller with known model information. The proposed algorithm can achieve a $\tilde O(T^{2/3})$ regret, where $T$ is the number of stages and $\tilde O(\cdot)$ absorbs some logarithmic terms of $T$.
Zeroth-order non-convex learning via hierarchical dual averaging
Sep 13, 2021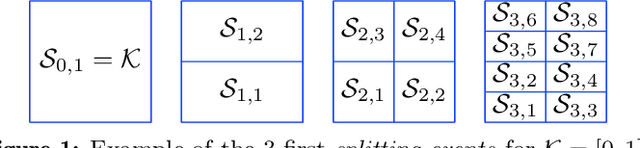
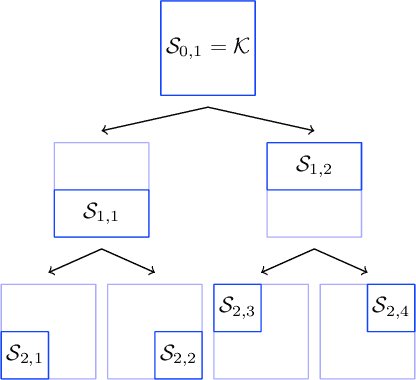
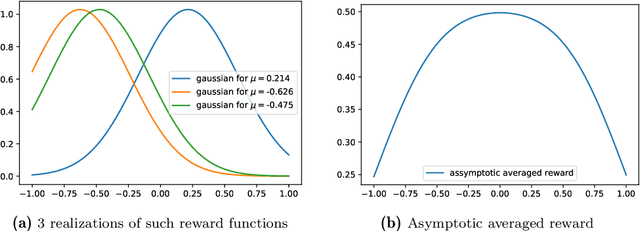
We propose a hierarchical version of dual averaging for zeroth-order online non-convex optimization - i.e., learning processes where, at each stage, the optimizer is facing an unknown non-convex loss function and only receives the incurred loss as feedback. The proposed class of policies relies on the construction of an online model that aggregates loss information as it arrives, and it consists of two principal components: (a) a regularizer adapted to the Fisher information metric (as opposed to the metric norm of the ambient space); and (b) a principled exploration of the problem's state space based on an adapted hierarchical schedule. This construction enables sharper control of the model's bias and variance, and allows us to derive tight bounds for both the learner's static and dynamic regret - i.e., the regret incurred against the best dynamic policy in hindsight over the horizon of play.
AirObject: A Temporally Evolving Graph Embedding for Object Identification
Nov 30, 2021
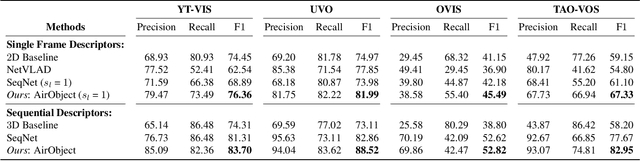
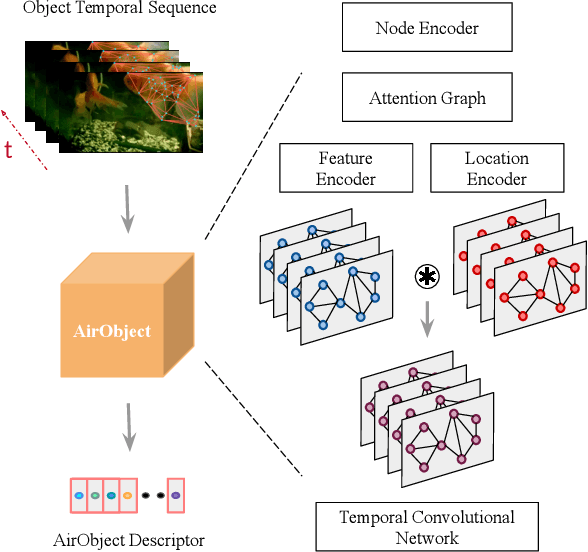
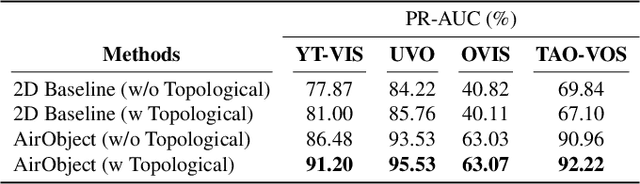
Object encoding and identification are vital for robotic tasks such as autonomous exploration, semantic scene understanding, and re-localization. Previous approaches have attempted to either track objects or generate descriptors for object identification. However, such systems are limited to a "fixed" partial object representation from a single viewpoint. In a robot exploration setup, there is a requirement for a temporally "evolving" global object representation built as the robot observes the object from multiple viewpoints. Furthermore, given the vast distribution of unknown novel objects in the real world, the object identification process must be class-agnostic. In this context, we propose a novel temporal 3D object encoding approach, dubbed AirObject, to obtain global keypoint graph-based embeddings of objects. Specifically, the global 3D object embeddings are generated using a temporal convolutional network across structural information of multiple frames obtained from a graph attention-based encoding method. We demonstrate that AirObject achieves the state-of-the-art performance for video object identification and is robust to severe occlusion, perceptual aliasing, viewpoint shift, deformation, and scale transform, outperforming the state-of-the-art single-frame and sequential descriptors. To the best of our knowledge, AirObject is one of the first temporal object encoding methods.
Do You Think It's Biased? How To Ask For The Perception Of Media Bias
Dec 16, 2021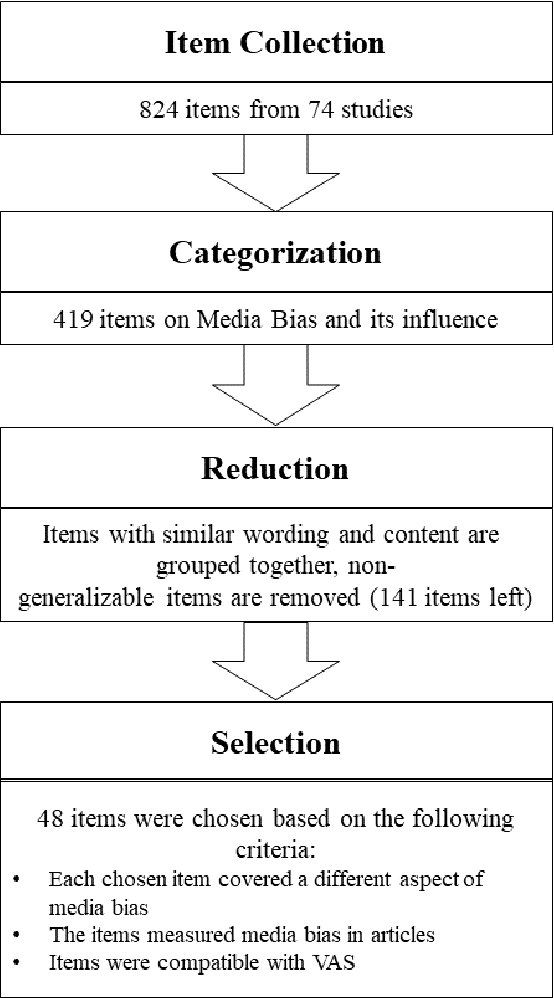
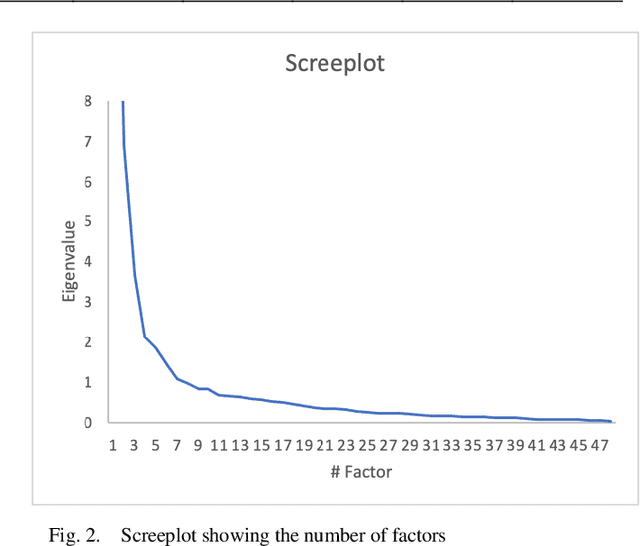

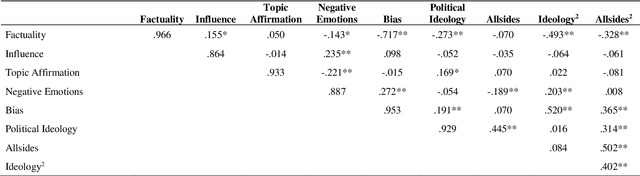
Media coverage possesses a substantial effect on the public perception of events. The way media frames events can significantly alter the beliefs and perceptions of our society. Nevertheless, nearly all media outlets are known to report news in a biased way. While such bias can be introduced by altering the word choice or omitting information, the perception of bias also varies largely depending on a reader's personal background. Therefore, media bias is a very complex construct to identify and analyze. Even though media bias has been the subject of many studies, previous assessment strategies are oversimplified, lack overlap and empirical evaluation. Thus, this study aims to develop a scale that can be used as a reliable standard to evaluate article bias. To name an example: Intending to measure bias in a news article, should we ask, "How biased is the article?" or should we instead ask, "How did the article treat the American president?". We conducted a literature search to find 824 relevant questions about text perception in previous research on the topic. In a multi-iterative process, we summarized and condensed these questions semantically to conclude a complete and representative set of possible question types about bias. The final set consisted of 25 questions with varying answering formats, 17 questions using semantic differentials, and six ratings of feelings. We tested each of the questions on 190 articles with overall 663 participants to identify how well the questions measure an article's perceived bias. Our results show that 21 final items are suitable and reliable for measuring the perception of media bias. We publish the final set of questions on http://bias-question-tree.gipplab.org/.
Utilizing Edge Features in Graph Neural Networks via Variational Information Maximization
Jun 13, 2019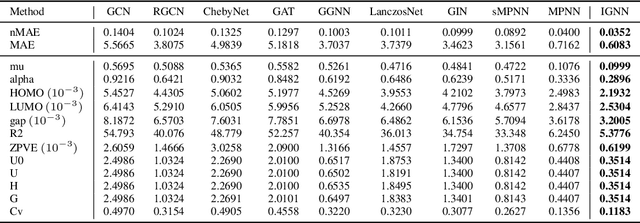
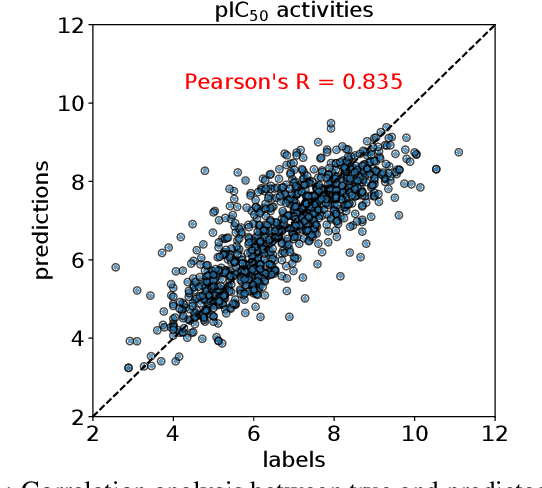

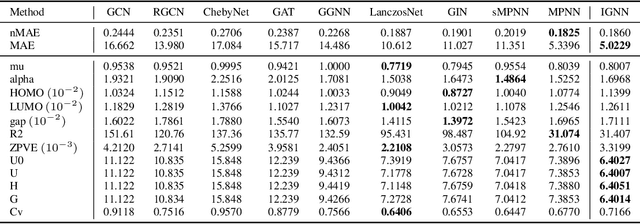
Graph Neural Networks (GNNs) achieve an impressive performance on structured graphs by recursively updating the representation vector of each node based on its neighbors, during which parameterized transformation matrices should be learned for the node feature updating. However, existing propagation schemes are far from being optimal since they do not fully utilize the relational information between nodes. We propose the information maximizing graph neural networks (IGNN), which maximizes the mutual information between edge states and transform parameters. We reformulate the mutual information as a differentiable objective via a variational approach. We compare our model against several recent variants of GNNs and show that our model achieves the state-of-the-art performance on multiple tasks including quantum chemistry regression on QM9 dataset, generalization capability from QM9 to larger molecular graphs, and prediction of molecular bioactivities relevant for drug discovery. The IGNN model is based on an elegant and fundamental idea in information theory as explained in the main text, and it could be easily generalized beyond the contexts of molecular graphs considered in this work. To encourage more future work in this area, all datasets and codes used in this paper will be released for public access.
Lifting 2D Object Locations to 3D by Discounting LiDAR Outliers across Objects and Views
Sep 16, 2021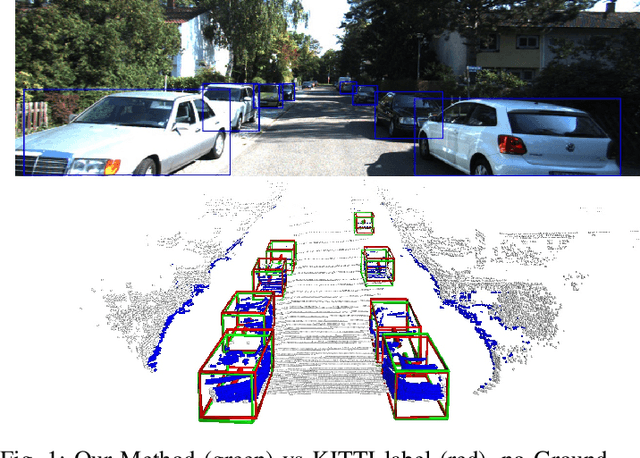
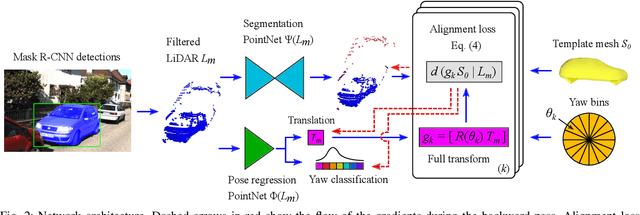


We present a system for automatic converting of 2D mask object predictions and raw LiDAR point clouds into full 3D bounding boxes of objects. Because the LiDAR point clouds are partial, directly fitting bounding boxes to the point clouds is meaningless. Instead, we suggest that obtaining good results requires sharing information between \emph{all} objects in the dataset jointly, over multiple frames. We then make three improvements to the baseline. First, we address ambiguities in predicting the object rotations via direct optimization in this space while still backpropagating rotation prediction through the model. Second, we explicitly model outliers and task the network with learning their typical patterns, thus better discounting them. Third, we enforce temporal consistency when video data is available. With these contributions, our method significantly outperforms previous work despite the fact that those methods use significantly more complex pipelines, 3D models and additional human-annotated external sources of prior information.
Technology Fitness Landscape and the Future of Innovation
Oct 27, 2021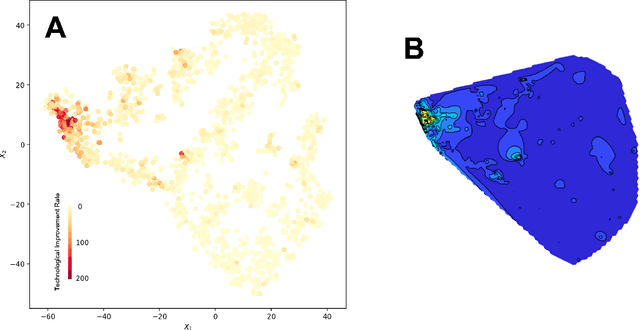
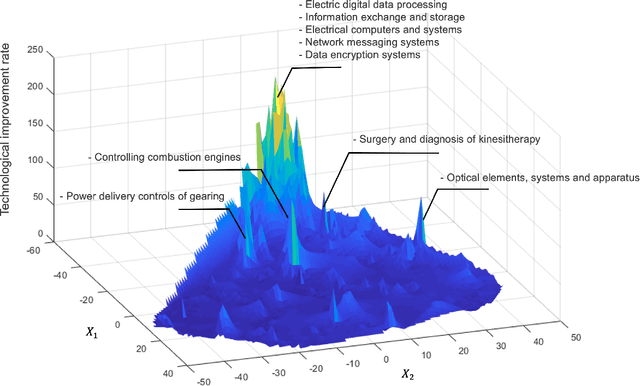
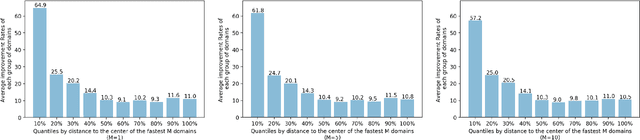
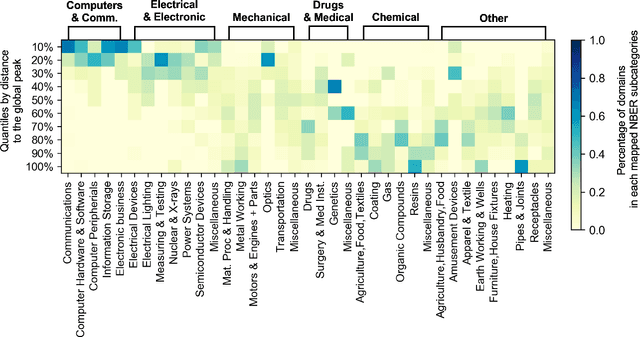
We present a deep learning-based technology fitness landscape premised on a neural embedding space of 1,757 technology domains and their respective improvement rates. The technology embedding space is a high-dimensional vector space trained via applying neural embedding techniques to patent data. The improvement rates of respective technology domains are drawn from a prior study. The technology fitness landscape exhibits a high hill related to information and communication technologies (ICT) and a vast low plain of the remaining domains. The technology fitness landscape presents a bird's eye view of the structure of the total technology space, a new way to interpret technology evolution with a biological analogy, and a biologically-inspired inference to next innovation.
An Efficient Indexing and Searching Technique for Information Retrieval for Urdu Language
Feb 28, 2021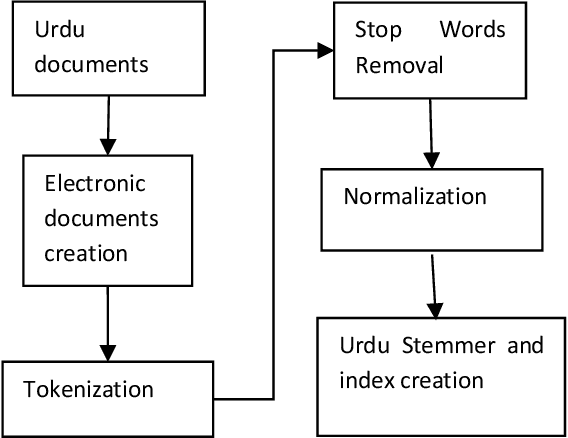
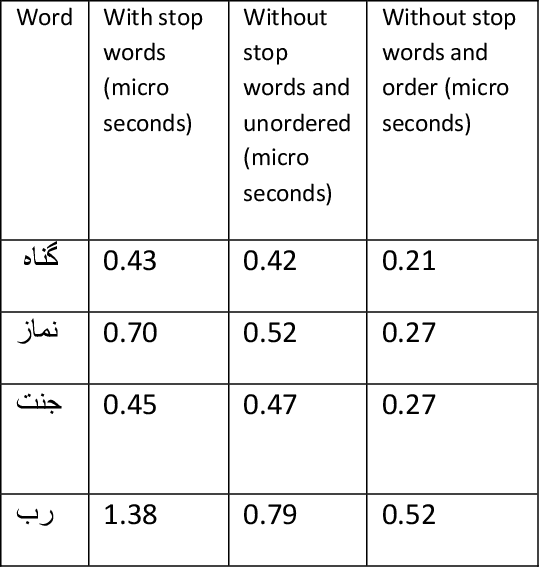
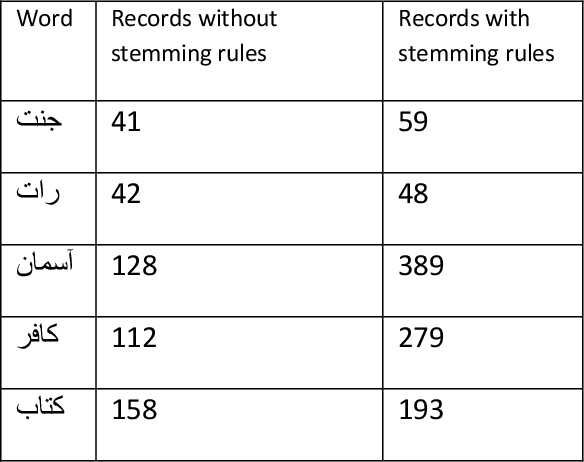
Indexing techniques are used to improve retrieval of data in response to certain search condition. Inverted files are mostly used for creating indexes. This paper proposes indexing technique for Urdu language. Language processing step in Index creation is different for a particular language. We discuss index creation steps specifically for Urdu language. We explore morphological rules for Urdu language and implement these rules to create Urdu stemmer. We implement our proposed technique with different implementations and compare results. We suggest that indexes should be created without stop words and also index file should be an order index file.
Multiway Non-rigid Point Cloud Registration via Learned Functional Map Synchronization
Nov 25, 2021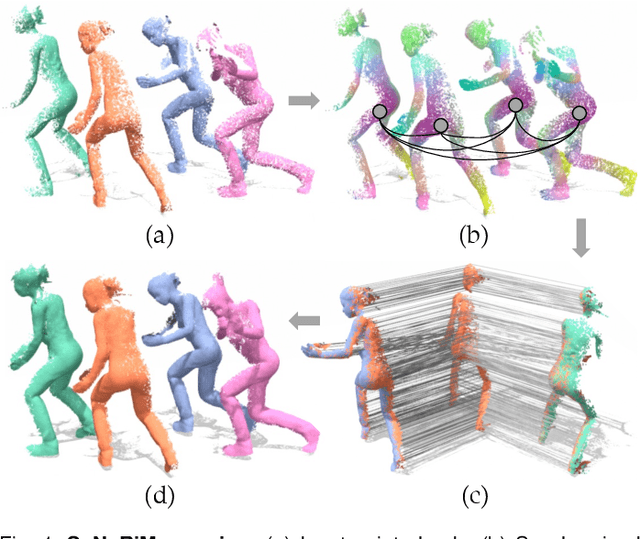
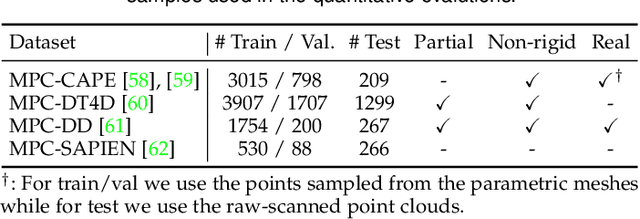
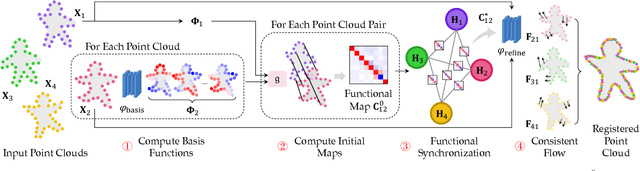
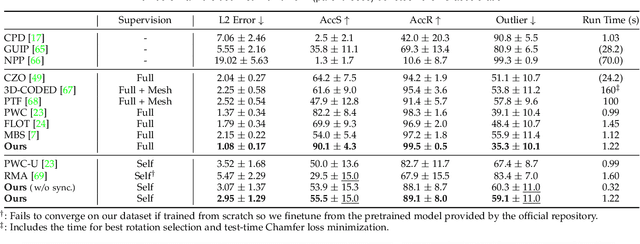
We present SyNoRiM, a novel way to jointly register multiple non-rigid shapes by synchronizing the maps relating learned functions defined on the point clouds. Even though the ability to process non-rigid shapes is critical in various applications ranging from computer animation to 3D digitization, the literature still lacks a robust and flexible framework to match and align a collection of real, noisy scans observed under occlusions. Given a set of such point clouds, our method first computes the pairwise correspondences parameterized via functional maps. We simultaneously learn potentially non-orthogonal basis functions to effectively regularize the deformations, while handling the occlusions in an elegant way. To maximally benefit from the multi-way information provided by the inferred pairwise deformation fields, we synchronize the pairwise functional maps into a cycle-consistent whole thanks to our novel and principled optimization formulation. We demonstrate via extensive experiments that our method achieves a state-of-the-art performance in registration accuracy, while being flexible and efficient as we handle both non-rigid and multi-body cases in a unified framework and avoid the costly optimization over point-wise permutations by the use of basis function maps.
New Performance Measures for Object Tracking under Complex Environments
Nov 13, 2021Various performance measures based on the ground truth and without ground truth exist to evaluate the quality of a developed tracking algorithm. The existing popular measures - average center location error (ACLE) and average tracking accuracy (ATA) based on ground truth, may sometimes create confusion to quantify the quality of a developed algorithm for tracking an object under some complex environments (e.g., scaled or oriented or both scaled and oriented object). In this article, we propose three new auxiliary performance measures based on ground truth information to evaluate the quality of a developed tracking algorithm under such complex environments. Moreover, one performance measure is developed by combining both two existing measures ACLE and ATA and three new proposed measures for better quantifying the developed tracking algorithm under such complex conditions. Some examples and experimental results conclude that the proposed measure is better than existing measures to quantify one developed algorithm for tracking objects under such complex environments.