 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Long-Range Transformers for Dynamic Spatiotemporal Forecasting
Sep 24, 2021
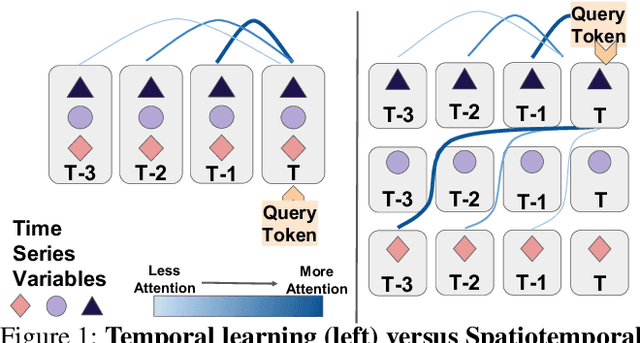
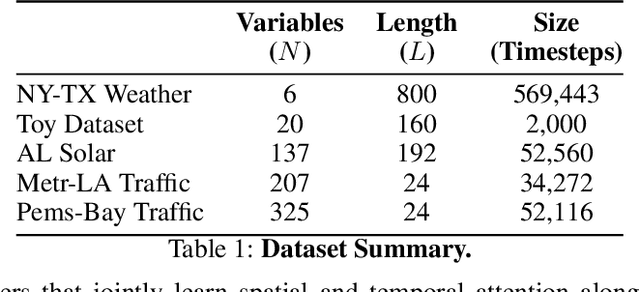
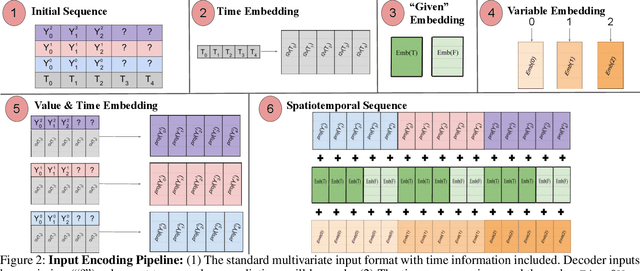
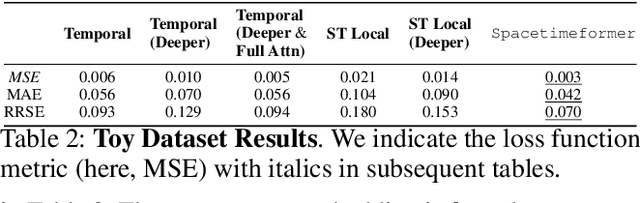
Multivariate Time Series Forecasting (TSF) focuses on the prediction of future values based on historical context. In these problems, dependent variables provide additional information or early warning signs of changes in future behavior. State-of-the-art forecasting models rely on neural attention between timesteps. This allows for temporal learning but fails to consider distinct spatial relationships between variables. This paper addresses the problem by translating multivariate TSF into a novel spatiotemporal sequence formulation where each input token represents the value of a single variable at a given timestep. Long-Range Transformers can then learn interactions between space, time, and value information jointly along this extended sequence. Our method, which we call Spacetimeformer, scales to high dimensional forecasting problems dominated by Graph Neural Networks that rely on predefined variable graphs. We achieve competitive results on benchmarks from traffic forecasting to electricity demand and weather prediction while learning spatial and temporal relationships purely from data.
Online Refinement of Low-level Feature Based Activation Map for Weakly Supervised Object Localization
Oct 12, 2021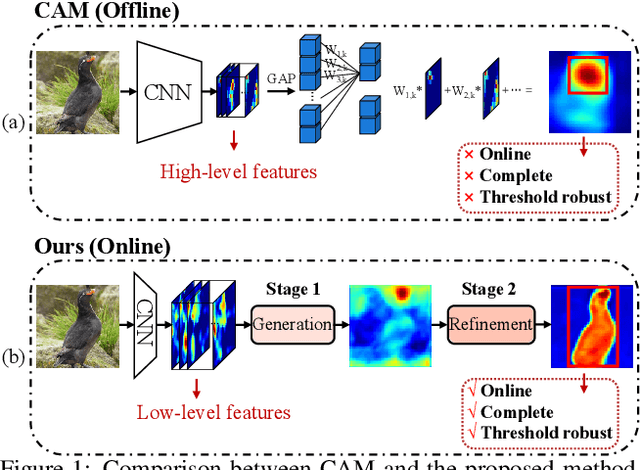
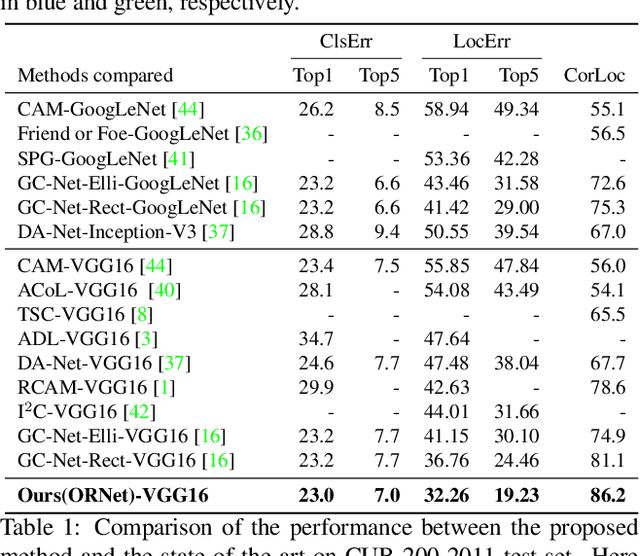

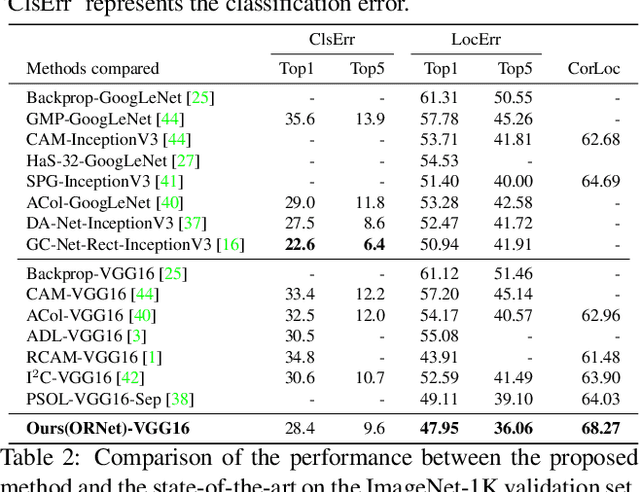
We present a two-stage learning framework for weakly supervised object localization (WSOL). While most previous efforts rely on high-level feature based CAMs (Class Activation Maps), this paper proposes to localize objects using the low-level feature based activation maps. In the first stage, an activation map generator produces activation maps based on the low-level feature maps in the classifier, such that rich contextual object information is included in an online manner. In the second stage, we employ an evaluator to evaluate the activation maps predicted by the activation map generator. Based on this, we further propose a weighted entropy loss, an attentive erasing, and an area loss to drive the activation map generator to substantially reduce the uncertainty of activations between object and background, and explore less discriminative regions. Based on the low-level object information preserved in the first stage, the second stage model gradually generates a well-separated, complete, and compact activation map of object in the image, which can be easily thresholded for accurate localization. Extensive experiments on CUB-200-2011 and ImageNet-1K datasets show that our framework surpasses previous methods by a large margin, which sets a new state-of-the-art for WSOL.
Lightweight Decoding Strategies for Increasing Specificity
Oct 22, 2021
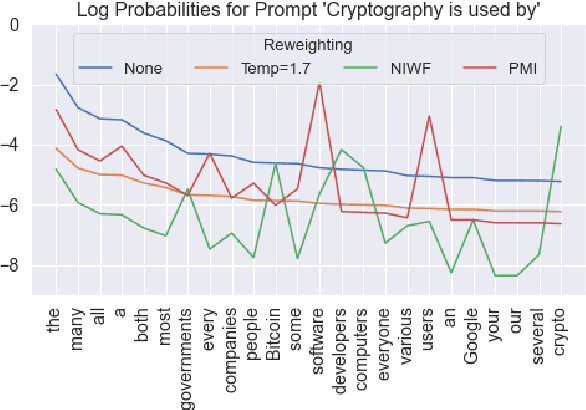

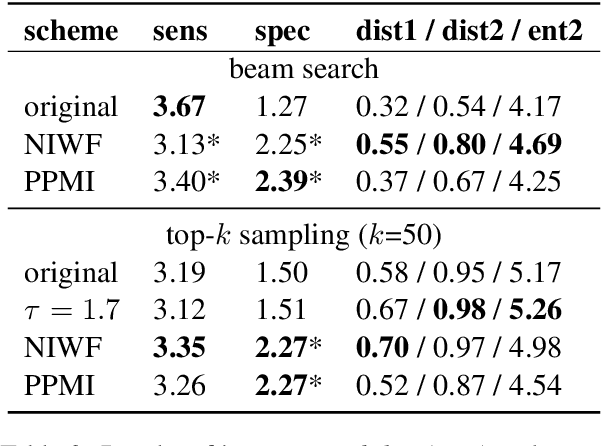
Language models are known to produce vague and generic outputs. We propose two unsupervised decoding strategies based on either word-frequency or point-wise mutual information to increase the specificity of any model that outputs a probability distribution over its vocabulary at generation time. We test the strategies in a prompt completion task; with human evaluations, we find that both strategies increase the specificity of outputs with only modest decreases in sensibility. We also briefly present a summarization use case, where these strategies can produce more specific summaries.
Matching in the Dark: A Dataset for Matching Image Pairs of Low-light Scenes
Sep 08, 2021
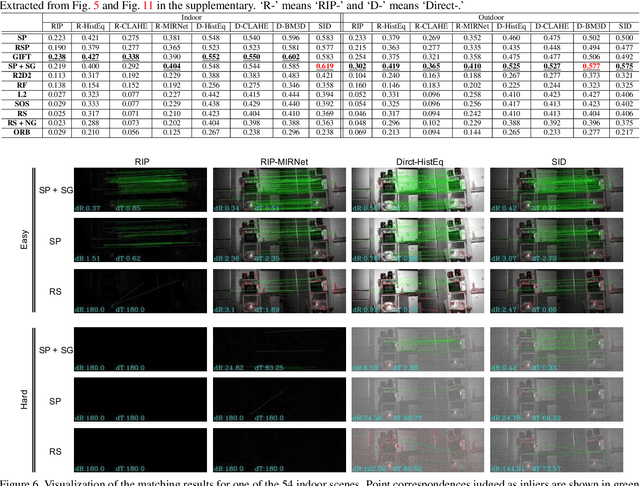
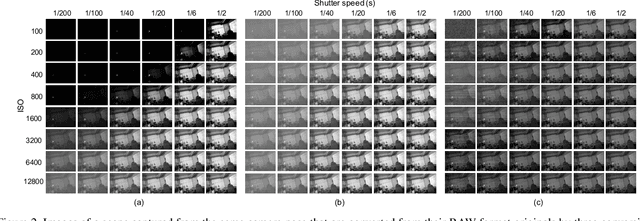
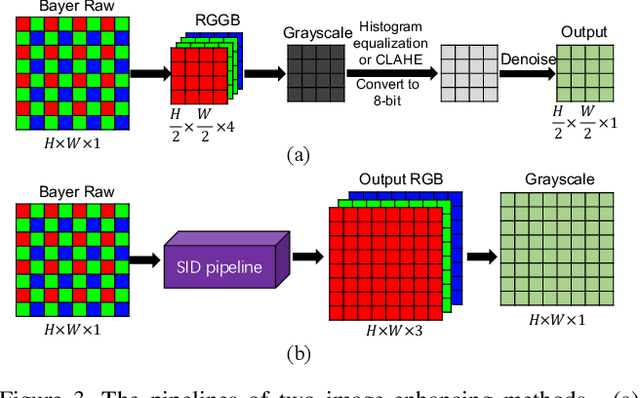
This paper considers matching images of low-light scenes, aiming to widen the frontier of SfM and visual SLAM applications. Recent image sensors can record the brightness of scenes with more than eight-bit precision, available in their RAW-format image. We are interested in making full use of such high-precision information to match extremely low-light scene images that conventional methods cannot handle. For extreme low-light scenes, even if some of their brightness information exists in the RAW format images' low bits, the standard raw image processing on cameras fails to utilize them properly. As was recently shown by Chen et al., CNNs can learn to produce images with a natural appearance from such RAW-format images. To consider if and how well we can utilize such information stored in RAW-format images for image matching, we have created a new dataset named MID (matching in the dark). Using it, we experimentally evaluated combinations of eight image-enhancing methods and eleven image matching methods consisting of classical/neural local descriptors and classical/neural initial point-matching methods. The results show the advantage of using the RAW-format images and the strengths and weaknesses of the above component methods. They also imply there is room for further research.
Equivariant vector field network for many-body system modeling
Oct 26, 2021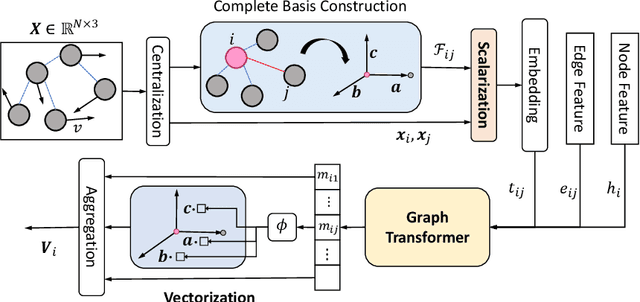
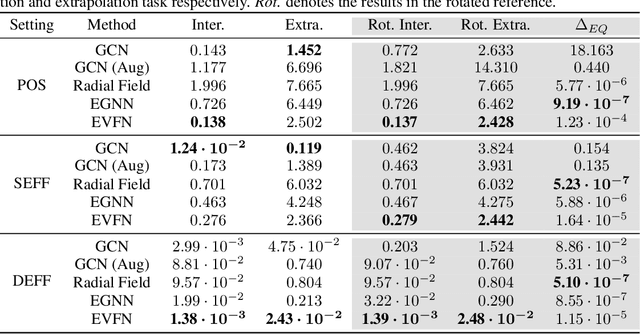
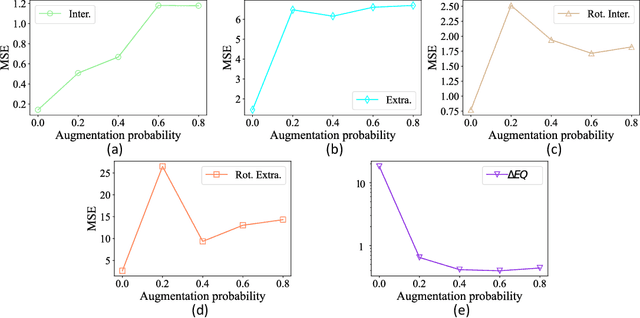
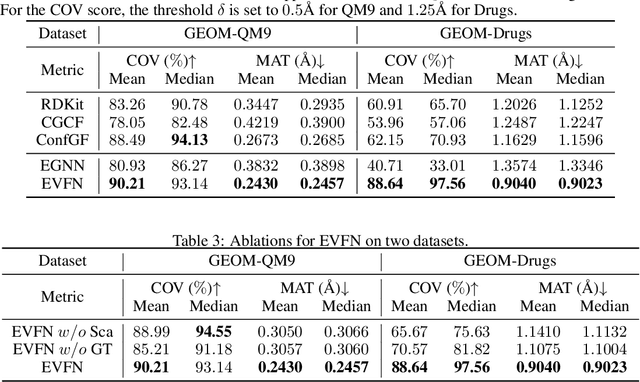
Modeling many-body systems has been a long-standing challenge in science, from classical and quantum physics to computational biology. Equivariance is a critical physical symmetry for many-body dynamic systems, which enables robust and accurate prediction under arbitrary reference transformations. In light of this, great efforts have been put on encoding this symmetry into deep neural networks, which significantly boosts the prediction performance of down-streaming tasks. Some general equivariant models which are computationally efficient have been proposed, however, these models have no guarantee on the approximation power and may have information loss. In this paper, we leverage insights from the scalarization technique in differential geometry to model many-body systems by learning the gradient vector fields, which are SE(3) and permutation equivariant. Specifically, we propose the Equivariant Vector Field Network (EVFN), which is built on a novel tuple of equivariant basis and the associated scalarization and vectorization layers. Since our tuple equivariant basis forms a complete basis, learning the dynamics with our EVFN has no information loss and no tensor operations are involved before the final vectorization, which reduces the complex optimization on tensors to a minimum. We evaluate our method on predicting trajectories of simulated Newton mechanics systems with both full and partially observed data, as well as the equilibrium state of small molecules (molecular conformation) evolving as a statistical mechanics system. Experimental results across multiple tasks demonstrate that our model achieves best or competitive performance on baseline models in various types of datasets.
Disentangled representations: towards interpretation of sex determination from hip bone
Dec 17, 2021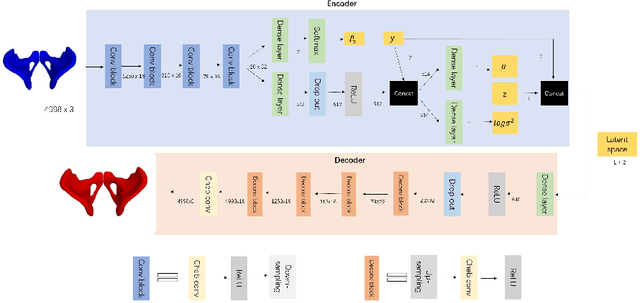


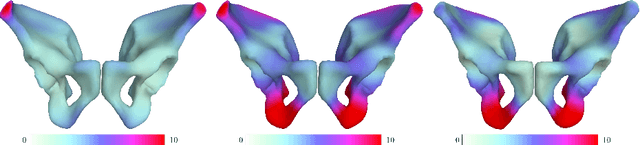
By highlighting the regions of the input image that contribute the most to the decision, saliency maps have become a popular method to make neural networks interpretable. In medical imaging, they are particularly well-suited to explain neural networks in the context of abnormality localization. However, from our experiments, they are less suited to classification problems where the features that allow to distinguish between the different classes are spatially correlated, scattered and definitely non-trivial. In this paper we thus propose a new paradigm for better interpretability. To this end we provide the user with relevant and easily interpretable information so that he can form his own opinion. We use Disentangled Variational Auto-Encoders which latent representation is divided into two components: the non-interpretable part and the disentangled part. The latter accounts for the categorical variables explicitly representing the different classes of interest. In addition to providing the class of a given input sample, such a model offers the possibility to transform the sample from a given class to a sample of another class, by modifying the value of the categorical variables in the latent representation. This paves the way to easier interpretation of class differences. We illustrate the relevance of this approach in the context of automatic sex determination from hip bones in forensic medicine. The features encoded by the model, that distinguish the different classes were found to be consistent with expert knowledge.
Semantic Segmentation of Legal Documents via Rhetorical Roles
Dec 03, 2021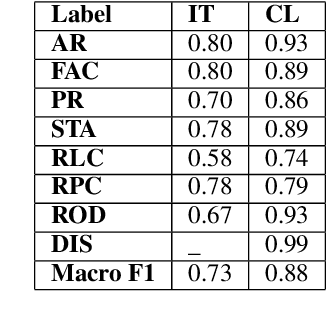
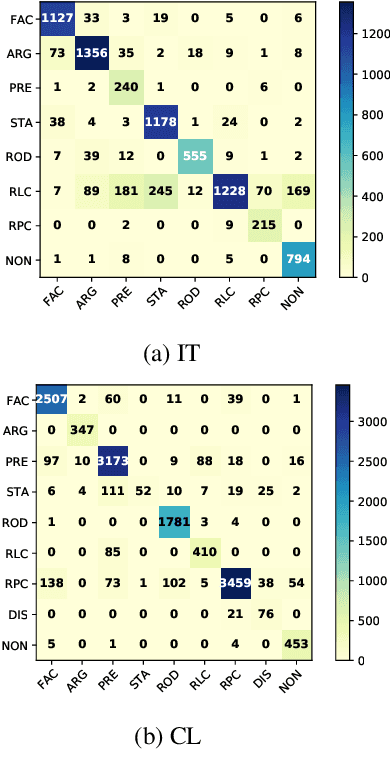
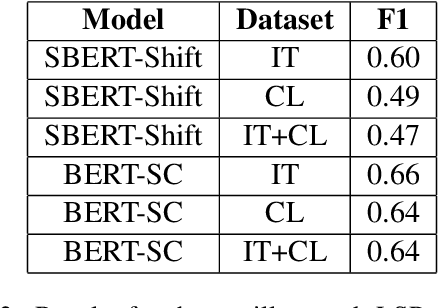
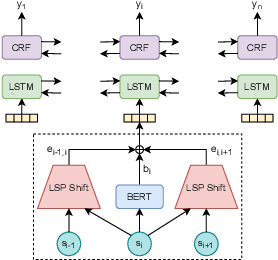
Legal documents are unstructured, use legal jargon, and have considerable length, making it difficult to process automatically via conventional text processing techniques. A legal document processing system would benefit substantially if the documents could be semantically segmented into coherent units of information. This paper proposes a Rhetorical Roles (RR) system for segmenting a legal document into semantically coherent units: facts, arguments, statute, issue, precedent, ruling, and ratio. With the help of legal experts, we propose a set of 13 fine-grained rhetorical role labels and create a new corpus of legal documents annotated with the proposed RR. We develop a system for segmenting a document into rhetorical role units. In particular, we develop a multitask learning-based deep learning model with document rhetorical role label shift as an auxiliary task for segmenting a legal document. We experiment extensively with various deep learning models for predicting rhetorical roles in a document, and the proposed model shows superior performance over the existing models. Further, we apply RR for predicting the judgment of legal cases and show that the use of RR enhances the prediction compared to the transformer-based models.
SimulSLT: End-to-End Simultaneous Sign Language Translation
Dec 08, 2021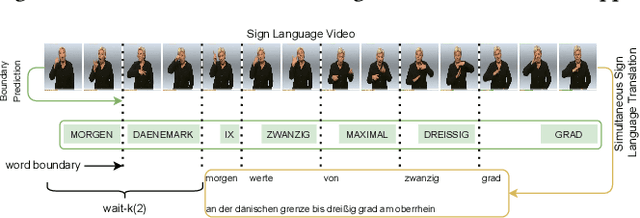
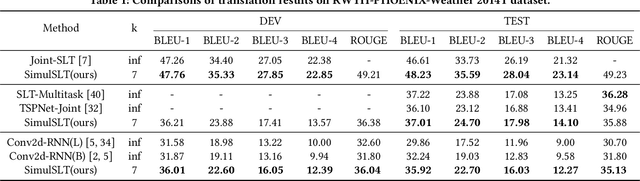
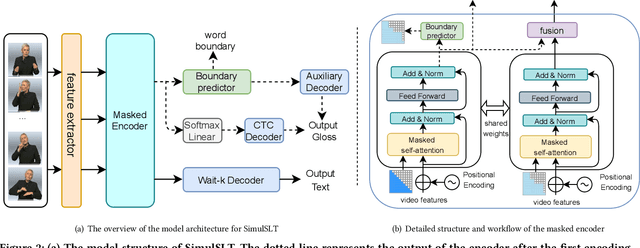
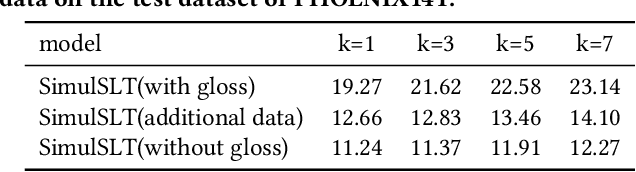
Sign language translation as a kind of technology with profound social significance has attracted growing researchers' interest in recent years. However, the existing sign language translation methods need to read all the videos before starting the translation, which leads to a high inference latency and also limits their application in real-life scenarios. To solve this problem, we propose SimulSLT, the first end-to-end simultaneous sign language translation model, which can translate sign language videos into target text concurrently. SimulSLT is composed of a text decoder, a boundary predictor, and a masked encoder. We 1) use the wait-k strategy for simultaneous translation. 2) design a novel boundary predictor based on the integrate-and-fire module to output the gloss boundary, which is used to model the correspondence between the sign language video and the gloss. 3) propose an innovative re-encode method to help the model obtain more abundant contextual information, which allows the existing video features to interact fully. The experimental results conducted on the RWTH-PHOENIX-Weather 2014T dataset show that SimulSLT achieves BLEU scores that exceed the latest end-to-end non-simultaneous sign language translation model while maintaining low latency, which proves the effectiveness of our method.
IR-Net: Forward and Backward Information Retention for Highly Accurate Binary Neural Networks
Sep 25, 2019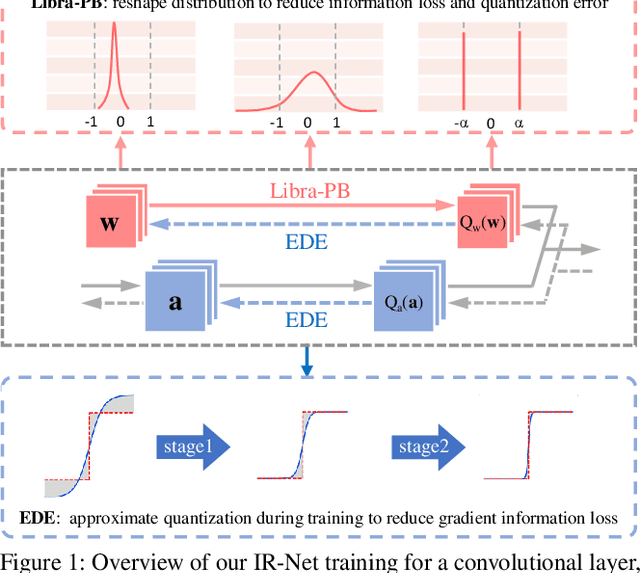

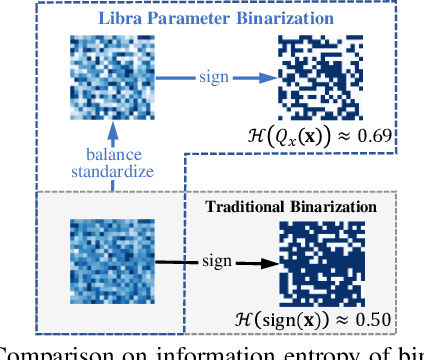
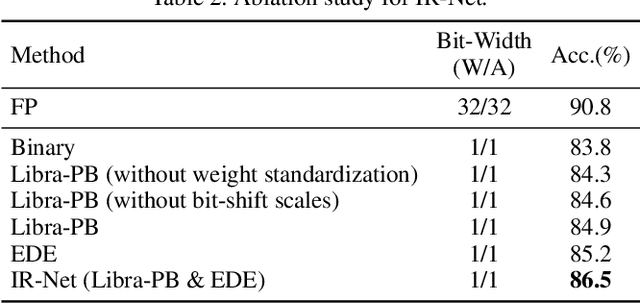
Weight and activation binarization is an effective approach to deep neural network compression and can accelerate the inference by leveraging bitwise operations. Although many binarization methods have improved the accuracy of the model by minimizing the quantization error in forward propagation, there remains a noticeable performance gap between the binarized model and the full-precision one. Our empirical study indicates that the quantization brings information loss in both forward and backward propagation, which is the bottleneck of training highly accurate binary neural networks. To address these issues, we propose an Information Retention Network (IR-Net) to retain the information that consists in the forward activations and backward gradients. IR-Net mainly relies on two technical contributions: (1) Libra Parameter Binarization (Libra-PB): minimize both quantization error and information loss of parameters by balanced and standardized weights in forward propagation; (2) Error Decay Estimator (EDE): minimize the information loss of gradients by gradually approximating the sign function in backward propagation, jointly considering the updating ability and accurate gradients. Comprehensive experiments with various network structures on CIFAR-10 and ImageNet datasets manifest that the proposed IR-Net can consistently outperform state-of-the-art quantization methods.
Robotic Perception of Object Properties using Tactile Sensing
Dec 28, 2021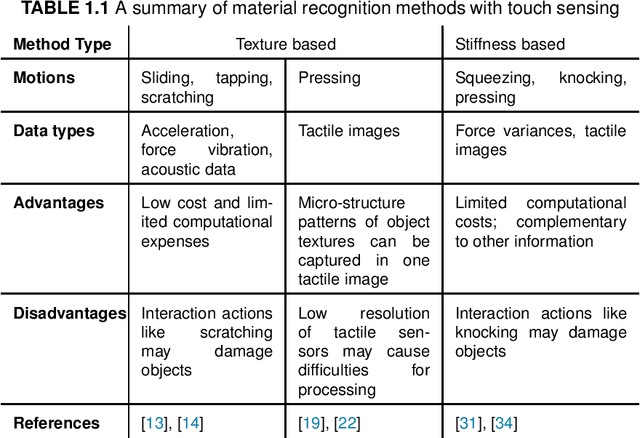
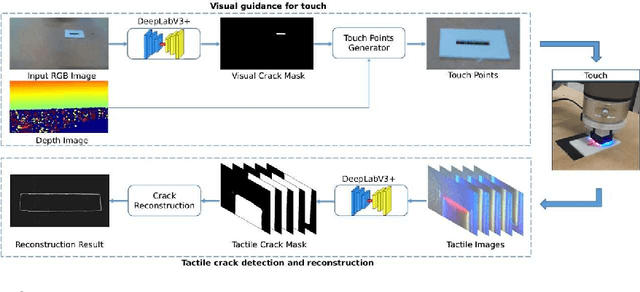
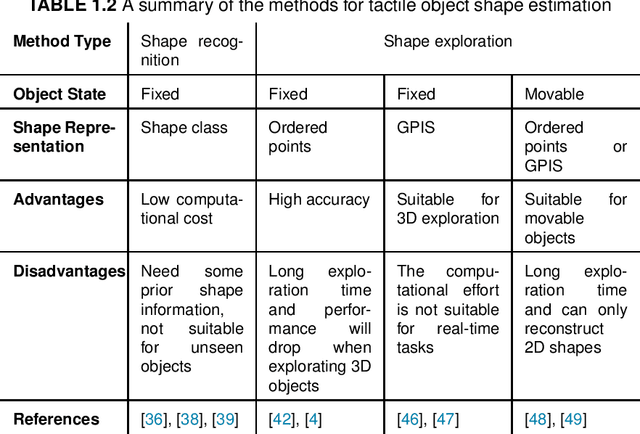
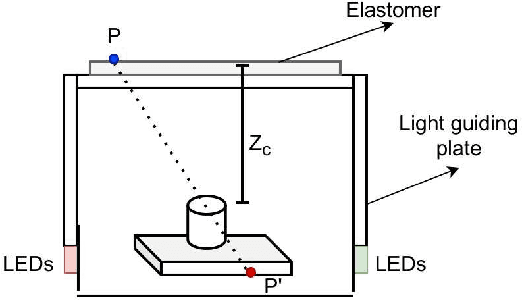
The sense of touch plays a key role in enabling humans to understand and interact with surrounding environments. For robots, tactile sensing is also irreplaceable. While interacting with objects, tactile sensing provides useful information for the robot to understand the object, such as distributed pressure, temperature, vibrations and texture. During robot grasping, vision is often occluded by its end-effectors, whereas tactile sensing can measure areas that are not accessible by vision. In the past decades, a number of tactile sensors have been developed for robots and used for different robotic tasks. In this chapter, we focus on the use of tactile sensing for robotic grasping and investigate the recent trends in tactile perception of object properties. We first discuss works on tactile perception of three important object properties in grasping, i.e., shape, pose and material properties. We then review the recent development in grasping stability prediction with tactile sensing. Among these works, we identify the requirement for coordinating vision and tactile sensing in the robotic grasping. To demonstrate the use of tactile sensing to improve the visual perception, our recent development of vision-guided tactile perception for crack reconstruction is presented. In the proposed framework, the large receptive field of camera vision is first leveraged to achieve a quick search of candidate regions containing cracks, a high-resolution optical tactile sensor is then used to examine these candidate regions and reconstruct a refined crack shape. The experiments show that our proposed method can achieve a significant reduction of mean distance error from 0.82 mm to 0.24 mm for crack reconstruction. Finally, we conclude this chapter with a discussion of open issues and future directions for applying tactile sensing in robotic tasks.