 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TiWS-iForest: Isolation Forest in Weakly Supervised and Tiny ML scenarios
Nov 30, 2021
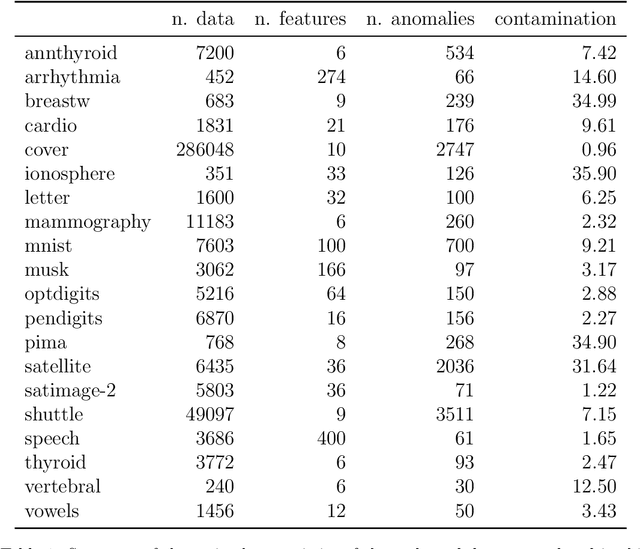
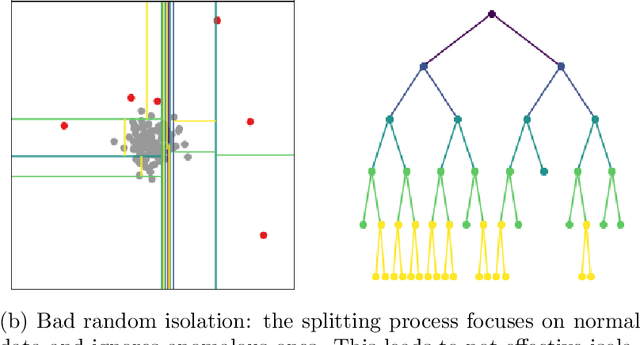
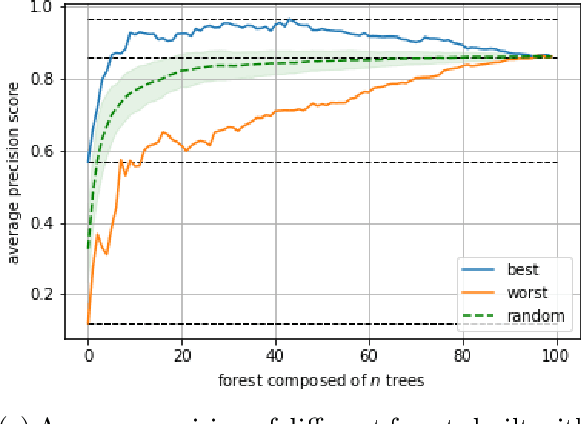
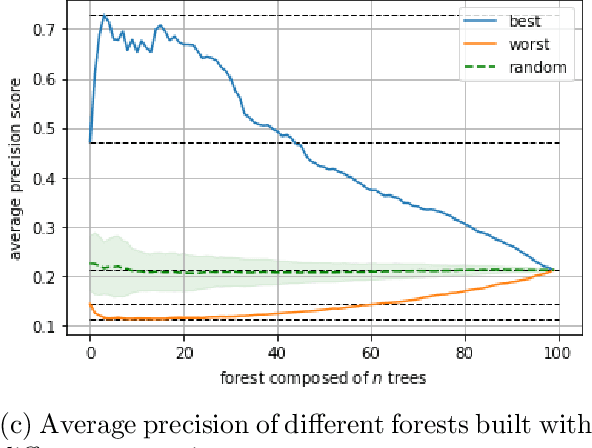
Unsupervised anomaly detection tackles the problem of finding anomalies inside datasets without the labels availability; since data tagging is typically hard or expensive to obtain, such approaches have seen huge applicability in recent years. In this context, Isolation Forest is a popular algorithm able to define an anomaly score by means of an ensemble of peculiar trees called isolation trees. These are built using a random partitioning procedure that is extremely fast and cheap to train. However, we find that the standard algorithm might be improved in terms of memory requirements, latency and performances; this is of particular importance in low resources scenarios and in TinyML implementations on ultra-constrained microprocessors. Moreover, Anomaly Detection approaches currently do not take advantage of weak supervisions: being typically consumed in Decision Support Systems, feedback from the users, even if rare, can be a valuable source of information that is currently unexplored. Beside showing iForest training limitations, we propose here TiWS-iForest, an approach that, by leveraging weak supervision is able to reduce Isolation Forest complexity and to enhance detection performances. We showed the effectiveness of TiWS-iForest on real word datasets and we share the code in a public repository to enhance reproducibility.
OH-Former: Omni-Relational High-Order Transformer for Person Re-Identification
Sep 23, 2021
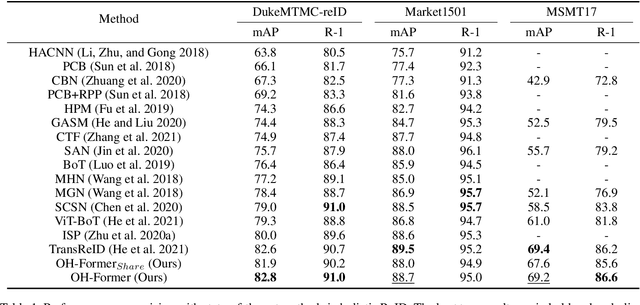
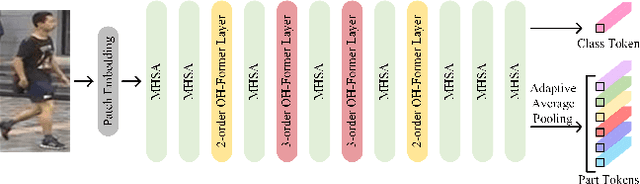
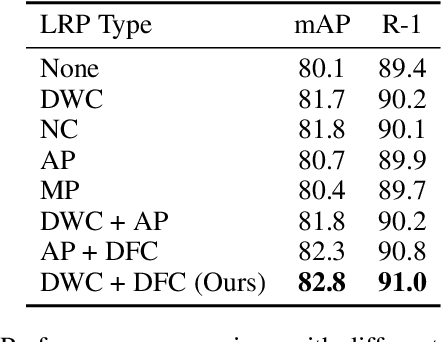
Transformers have shown preferable performance on many vision tasks. However, for the task of person re-identification (ReID), vanilla transformers leave the rich contexts on high-order feature relations under-exploited and deteriorate local feature details, which are insufficient due to the dramatic variations of pedestrians. In this work, we propose an Omni-Relational High-Order Transformer (OH-Former) to model omni-relational features for ReID. First, to strengthen the capacity of visual representation, instead of obtaining the attention matrix based on pairs of queries and isolated keys at each spatial location, we take a step further to model high-order statistics information for the non-local mechanism. We share the attention weights in the corresponding layer of each order with a prior mixing mechanism to reduce the computation cost. Then, a convolution-based local relation perception module is proposed to extract the local relations and 2D position information. The experimental results of our model are superior promising, which show state-of-the-art performance on Market-1501, DukeMTMC, MSMT17 and Occluded-Duke datasets.
Phänomen-Signal-Modell: Formalismus, Graph und Anwendung
Jul 31, 2021If we consider information as the basis of action, it may be of interest to examine the flow and acquisition of information between the actors in traffic. The central question is, which signals an automaton has to receive, decode or send in road traffic in order to act safely and in a conform manner to valid standards. The phenomenon-signal-model is a method to structure the problem, to analyze and to describe this very signal flow. Explaining the basics, structure and application of this method is the aim of this paper. -- Betrachtet man Information als Grundlage des Handelns, so wird es interessant sein, Fluss und Erfassung von Information zwischen den Akteuren des Verkehrsgeschehens zu untersuchen. Die zentrale Frage ist, welche Signale ein Automat im Stra{\ss}enverkehr empfangen, decodieren oder senden muss, um konform zu geltenden Ma{\ss}st\"aben und sicher zu agieren. Das Ph\"anomen-Signal-Modell ist eine Methode, das Problemfeld zu strukturieren, eben diesen Signalfluss zu analysieren und zu beschreiben. Der vorliegende Aufsatz erkl\"art Grundlagen, Aufbau und Anwendung dieser Methode.
Knowledge Distillation for Object Detection via Rank Mimicking and Prediction-guided Feature Imitation
Dec 09, 2021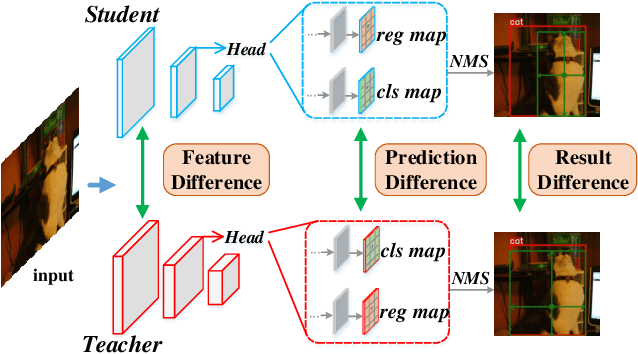
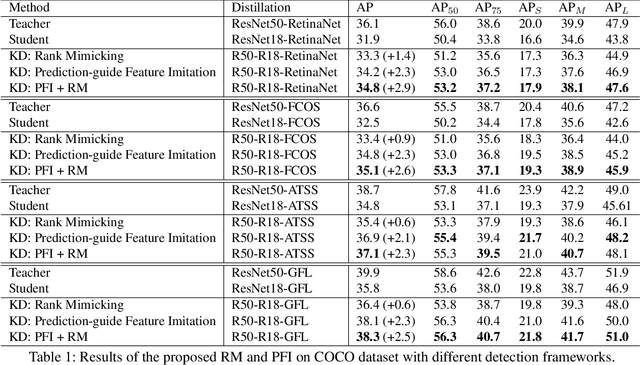
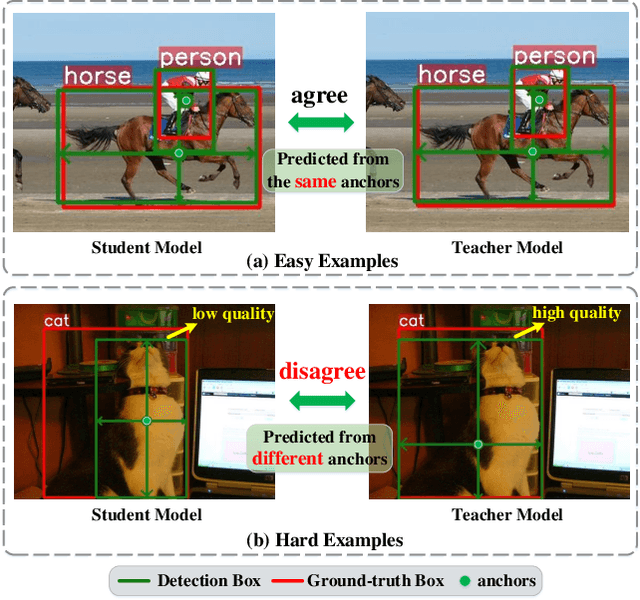
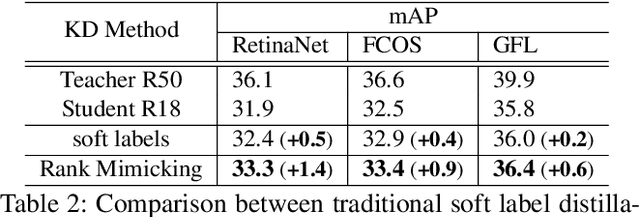
Knowledge Distillation (KD) is a widely-used technology to inherit information from cumbersome teacher models to compact student models, consequently realizing model compression and acceleration. Compared with image classification, object detection is a more complex task, and designing specific KD methods for object detection is non-trivial. In this work, we elaborately study the behaviour difference between the teacher and student detection models, and obtain two intriguing observations: First, the teacher and student rank their detected candidate boxes quite differently, which results in their precision discrepancy. Second, there is a considerable gap between the feature response differences and prediction differences between teacher and student, indicating that equally imitating all the feature maps of the teacher is the sub-optimal choice for improving the student's accuracy. Based on the two observations, we propose Rank Mimicking (RM) and Prediction-guided Feature Imitation (PFI) for distilling one-stage detectors, respectively. RM takes the rank of candidate boxes from teachers as a new form of knowledge to distill, which consistently outperforms the traditional soft label distillation. PFI attempts to correlate feature differences with prediction differences, making feature imitation directly help to improve the student's accuracy. On MS COCO and PASCAL VOC benchmarks, extensive experiments are conducted on various detectors with different backbones to validate the effectiveness of our method. Specifically, RetinaNet with ResNet50 achieves 40.4% mAP in MS COCO, which is 3.5% higher than its baseline, and also outperforms previous KD methods.
Sound-Guided Semantic Image Manipulation
Nov 30, 2021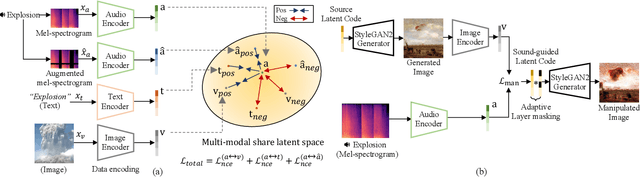
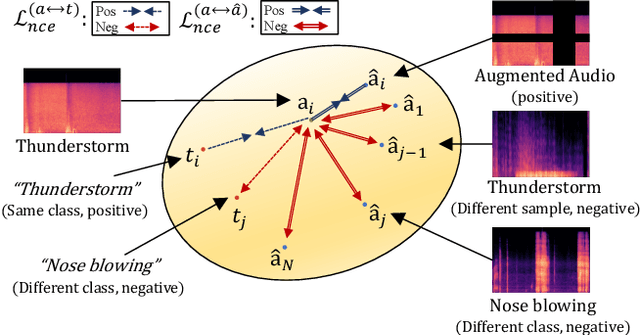


The recent success of the generative model shows that leveraging the multi-modal embedding space can manipulate an image using text information. However, manipulating an image with other sources rather than text, such as sound, is not easy due to the dynamic characteristics of the sources. Especially, sound can convey vivid emotions and dynamic expressions of the real world. Here, we propose a framework that directly encodes sound into the multi-modal (image-text) embedding space and manipulates an image from the space. Our audio encoder is trained to produce a latent representation from an audio input, which is forced to be aligned with image and text representations in the multi-modal embedding space. We use a direct latent optimization method based on aligned embeddings for sound-guided image manipulation. We also show that our method can mix text and audio modalities, which enrich the variety of the image modification. We verify the effectiveness of our sound-guided image manipulation quantitatively and qualitatively. We also show that our method can mix different modalities, i.e., text and audio, which enrich the variety of the image modification. The experiments on zero-shot audio classification and semantic-level image classification show that our proposed model outperforms other text and sound-guided state-of-the-art methods.
Fast and Real-time End to End Control in Autonomous Racing Cars Through Representation Learning
Nov 30, 2021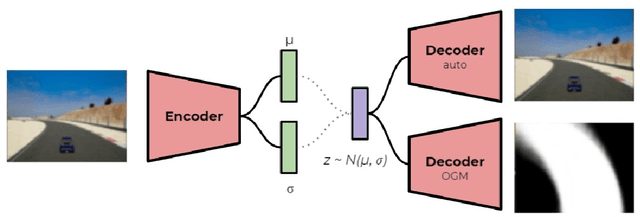

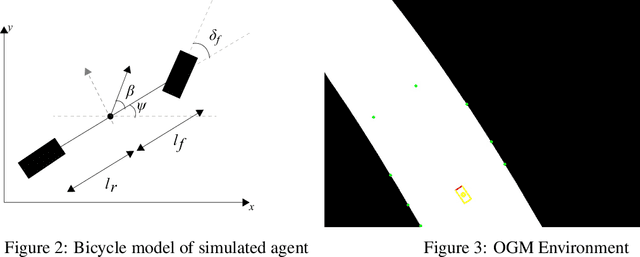
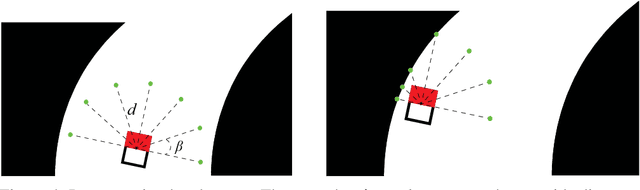
The challenges presented in an autonomous racing situation are distinct from those faced in regular autonomous driving and require faster end-to-end algorithms and consideration of a longer horizon in determining optimal current actions keeping in mind upcoming maneuvers and situations. In this paper, we propose an end-to-end method for autonomous racing that takes in as inputs video information from an onboard camera and determines final steering and throttle control actions. We use the following split to construct such a method (1) learning a low dimensional representation of the scene, (2) pre-generating the optimal trajectory for the given scene, and (3) tracking the predicted trajectory using a classical control method. In learning a low-dimensional representation of the scene, we use intermediate representations with a novel unsupervised trajectory planner to generate expert trajectories, and hence utilize them to directly predict race lines from a given front-facing input image. Thus, the proposed algorithm employs the best of two worlds - the robustness of learning-based approaches to perception and the accuracy of optimization-based approaches for trajectory generation in an end-to-end learning-based framework. We deploy and demonstrate our framework on CARLA, a photorealistic simulator for testing self-driving cars in realistic environments.
Multimodal Pre-Training Model for Sequence-based Prediction of Protein-Protein Interaction
Dec 09, 2021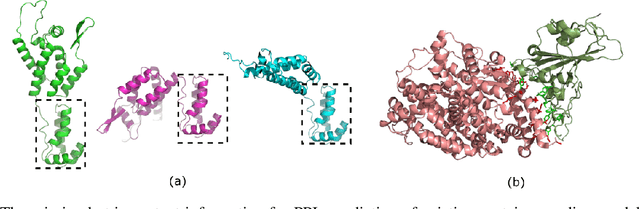

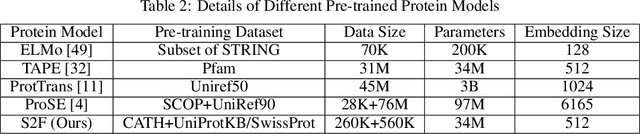
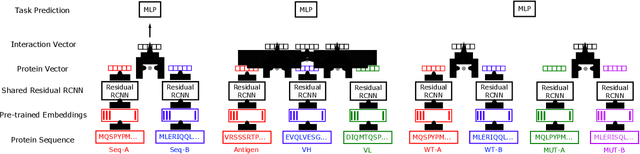
Protein-protein interactions (PPIs) are essentials for many biological processes where two or more proteins physically bind together to achieve their functions. Modeling PPIs is useful for many biomedical applications, such as vaccine design, antibody therapeutics, and peptide drug discovery. Pre-training a protein model to learn effective representation is critical for PPIs. Most pre-training models for PPIs are sequence-based, which naively adopt the language models used in natural language processing to amino acid sequences. More advanced works utilize the structure-aware pre-training technique, taking advantage of the contact maps of known protein structures. However, neither sequences nor contact maps can fully characterize structures and functions of the proteins, which are closely related to the PPI problem. Inspired by this insight, we propose a multimodal protein pre-training model with three modalities: sequence, structure, and function (S2F). Notably, instead of using contact maps to learn the amino acid-level rigid structures, we encode the structure feature with the topology complex of point clouds of heavy atoms. It allows our model to learn structural information about not only the backbones but also the side chains. Moreover, our model incorporates the knowledge from the functional description of proteins extracted from literature or manual annotations. Our experiments show that the S2F learns protein embeddings that achieve good performances on a variety of PPIs tasks, including cross-species PPI, antibody-antigen affinity prediction, antibody neutralization prediction for SARS-CoV-2, and mutation-driven binding affinity change prediction.
Structure-aware generation of drug-like molecules
Nov 07, 2021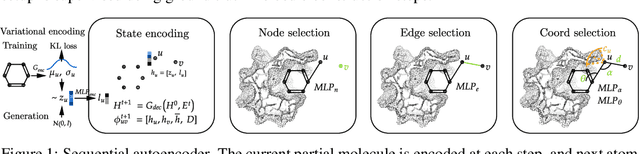
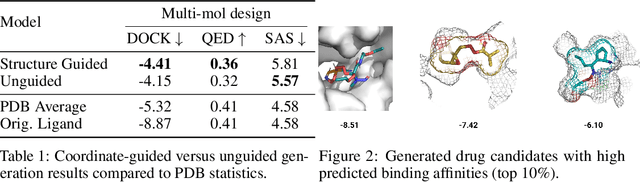
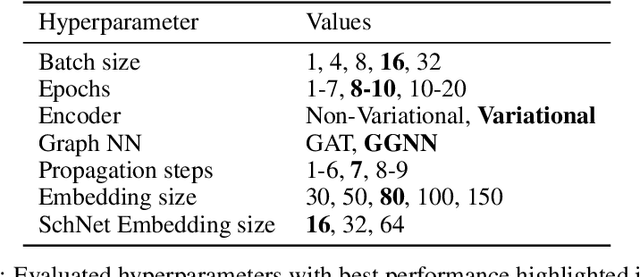
Structure-based drug design involves finding ligand molecules that exhibit structural and chemical complementarity to protein pockets. Deep generative methods have shown promise in proposing novel molecules from scratch (de-novo design), avoiding exhaustive virtual screening of chemical space. Most generative de-novo models fail to incorporate detailed ligand-protein interactions and 3D pocket structures. We propose a novel supervised model that generates molecular graphs jointly with 3D pose in a discretised molecular space. Molecules are built atom-by-atom inside pockets, guided by structural information from crystallographic data. We evaluate our model using a docking benchmark and find that guided generation improves predicted binding affinities by 8% and drug-likeness scores by 10% over the baseline. Furthermore, our model proposes molecules with binding scores exceeding some known ligands, which could be useful in future wet-lab studies.
Simple data balancing achieves competitive worst-group-accuracy
Oct 27, 2021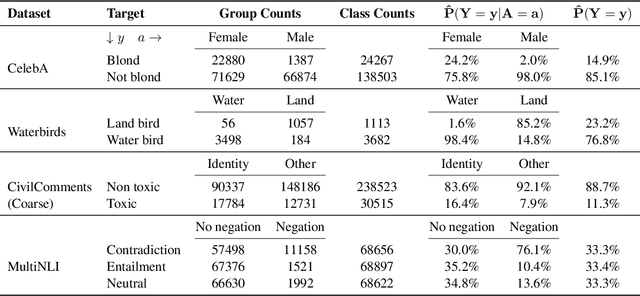
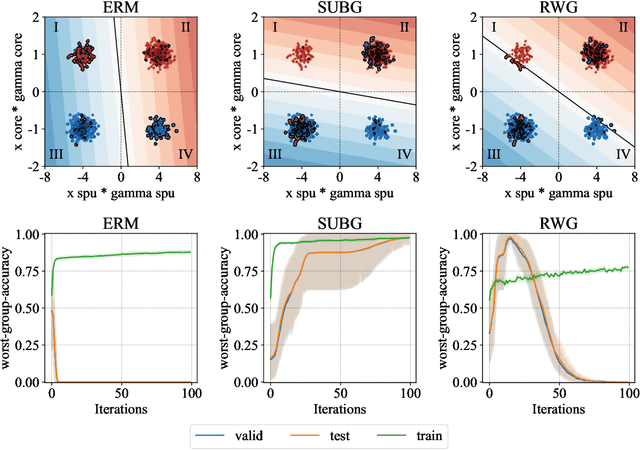
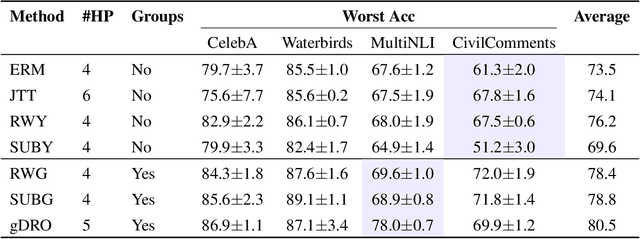
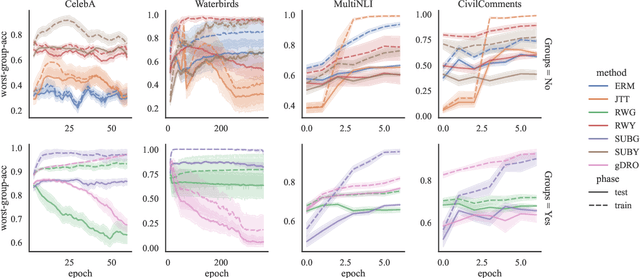
We study the problem of learning classifiers that perform well across (known or unknown) groups of data. After observing that common worst-group-accuracy datasets suffer from substantial imbalances, we set out to compare state-of-the-art methods to simple balancing of classes and groups by either subsampling or reweighting data. Our results show that these data balancing baselines achieve state-of-the-art-accuracy, while being faster to train and requiring no additional hyper-parameters. In addition, we highlight that access to group information is most critical for model selection purposes, and not so much during training. All in all, our findings beg closer examination of benchmarks and methods for research in worst-group-accuracy optimization.
OW-DETR: Open-world Detection Transformer
Dec 09, 2021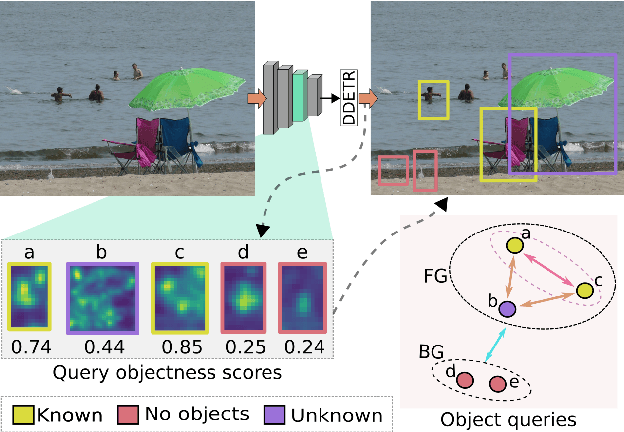
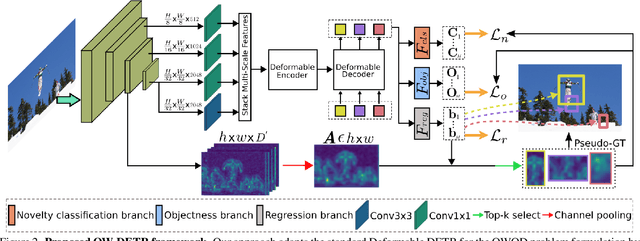
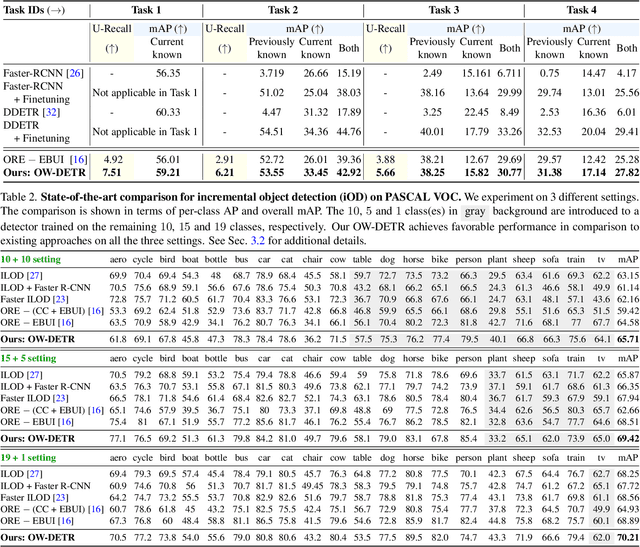
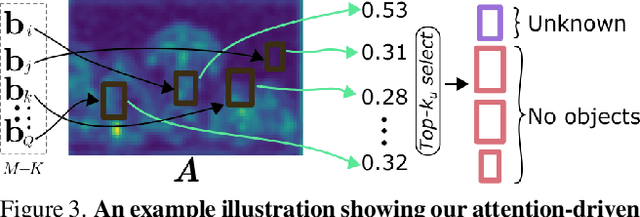
Open-world object detection (OWOD) is a challenging computer vision problem, where the task is to detect a known set of object categories while simultaneously identifying unknown objects. Additionally, the model must incrementally learn new classes that become known in the next training episodes. Distinct from standard object detection, the OWOD setting poses significant challenges for generating quality candidate proposals on potentially unknown objects, separating the unknown objects from the background and detecting diverse unknown objects. Here, we introduce a novel end-to-end transformer-based framework, OW-DETR, for open-world object detection. The proposed OW-DETR comprises three dedicated components namely, attention-driven pseudo-labeling, novelty classification and objectness scoring to explicitly address the aforementioned OWOD challenges. Our OW-DETR explicitly encodes multi-scale contextual information, possesses less inductive bias, enables knowledge transfer from known classes to the unknown class and can better discriminate between unknown objects and background. Comprehensive experiments are performed on two benchmarks: MS-COCO and PASCAL VOC. The extensive ablations reveal the merits of our proposed contributions. Further, our model outperforms the recently introduced OWOD approach, ORE, with absolute gains ranging from 1.8% to 3.3% in terms of unknown recall on the MS-COCO benchmark. In the case of incremental object detection, OW-DETR outperforms the state-of-the-art for all settings on the PASCAL VOC benchmark. Our codes and models will be publicly released.