 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Point-of-Interest Type Prediction using Text and Images
Sep 01, 2021

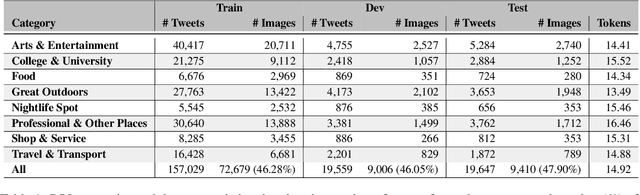
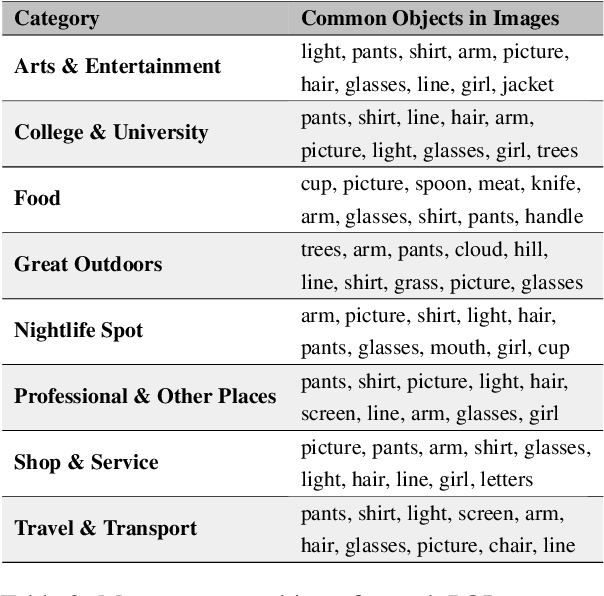
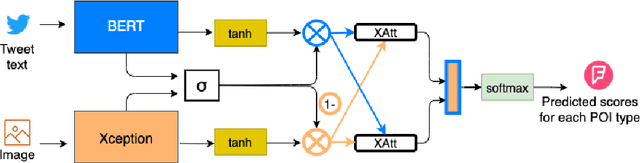
Point-of-interest (POI) type prediction is the task of inferring the type of a place from where a social media post was shared. Inferring a POI's type is useful for studies in computational social science including sociolinguistics, geosemiotics, and cultural geography, and has applications in geosocial networking technologies such as recommendation and visualization systems. Prior efforts in POI type prediction focus solely on text, without taking visual information into account. However in reality, the variety of modalities, as well as their semiotic relationships with one another, shape communication and interactions in social media. This paper presents a study on POI type prediction using multimodal information from text and images available at posting time. For that purpose, we enrich a currently available data set for POI type prediction with the images that accompany the text messages. Our proposed method extracts relevant information from each modality to effectively capture interactions between text and image achieving a macro F1 of 47.21 across eight categories significantly outperforming the state-of-the-art method for POI type prediction based on text-only methods. Finally, we provide a detailed analysis to shed light on cross-modal interactions and the limitations of our best performing model.
Distill and De-bias: Mitigating Bias in Face Recognition using Knowledge Distillation
Dec 17, 2021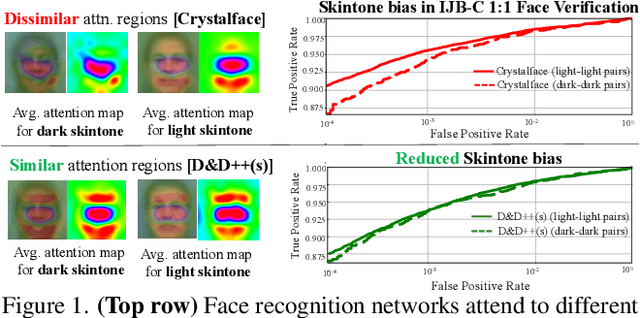
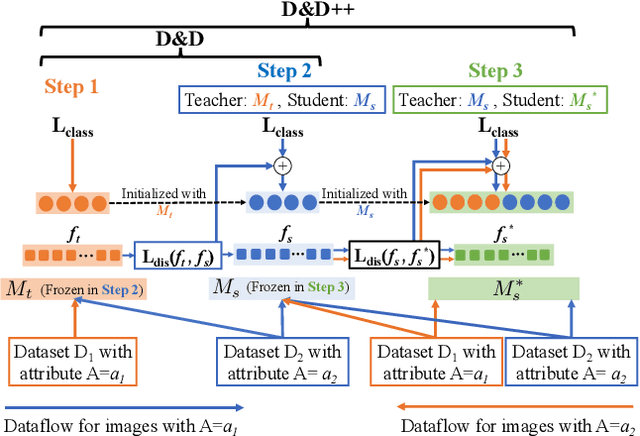
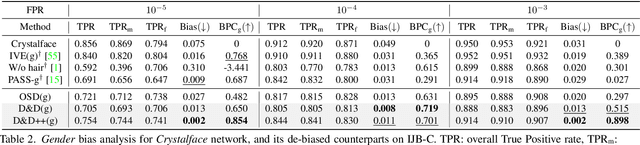
Face recognition networks generally demonstrate bias with respect to sensitive attributes like gender, skintone etc. For gender and skintone, we observe that the regions of the face that a network attends to vary by the category of an attribute. This might contribute to bias. Building on this intuition, we propose a novel distillation-based approach called Distill and De-bias (D&D) to enforce a network to attend to similar face regions, irrespective of the attribute category. In D&D, we train a teacher network on images from one category of an attribute; e.g. light skintone. Then distilling information from the teacher, we train a student network on images of the remaining category; e.g., dark skintone. A feature-level distillation loss constrains the student network to generate teacher-like representations. This allows the student network to attend to similar face regions for all attribute categories and enables it to reduce bias. We also propose a second distillation step on top of D&D, called D&D++. For the D&D++ network, we distill the `un-biasedness' of the D&D network into a new student network, the D&D++ network. We train the new network on all attribute categories; e.g., both light and dark skintones. This helps us train a network that is less biased for an attribute, while obtaining higher face verification performance than D&D. We show that D&D++ outperforms existing baselines in reducing gender and skintone bias on the IJB-C dataset, while obtaining higher face verification performance than existing adversarial de-biasing methods. We evaluate the effectiveness of our proposed methods on two state-of-the-art face recognition networks: Crystalface and ArcFace.
Causal Order Identification to Address Confounding: Binary Variables
Aug 10, 2021

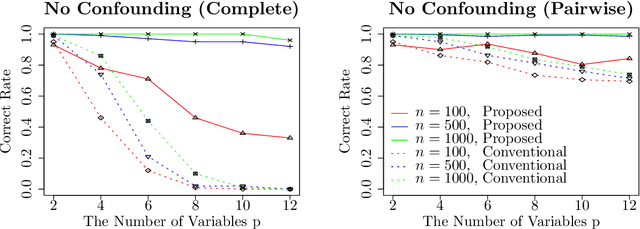
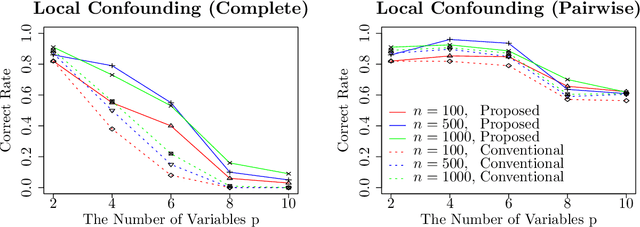
This paper considers an extension of the linear non-Gaussian acyclic model (LiNGAM) that determines the causal order among variables from a dataset when the variables are expressed by a set of linear equations, including noise. In particular, we assume that the variables are binary. The existing LiNGAM assumes that no confounding is present, which is restrictive in practice. Based on the concept of independent component analysis (ICA), this paper proposes an extended framework in which the mutual information among the noises is minimized. Another significant contribution is to reduce the realization of the shortest path problem. The distance between each pair of nodes expresses an associated mutual information value, and the path with the minimum sum (KL divergence) is sought. Although $p!$ mutual information values should be compared, this paper dramatically reduces the computation when no confounding is present. The proposed algorithm finds the globally optimal solution, while the existing locally greedily seek the order based on hypothesis testing. We use the best estimator in the sense of Bayes/MDL that correctly detects independence for mutual information estimation. Experiments using artificial and actual data show that the proposed version of LiNGAM achieves significantly better performance, particularly when confounding is present.
Automated Side Channel Analysis of Media Software with Manifold Learning
Dec 10, 2021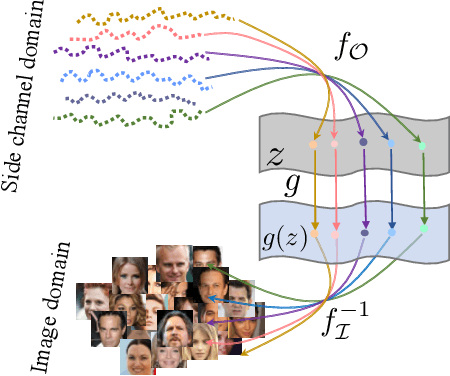

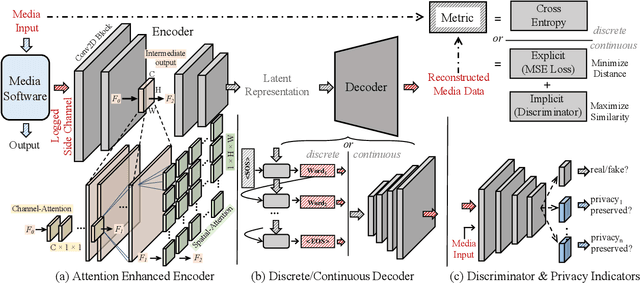

The prosperous development of cloud computing and machine learning as a service has led to the widespread use of media software to process confidential media data. This paper explores an adversary's ability to launch side channel analyses (SCA) against media software to reconstruct confidential media inputs. Recent advances in representation learning and perceptual learning inspired us to consider the reconstruction of media inputs from side channel traces as a cross-modality manifold learning task that can be addressed in a unified manner with an autoencoder framework trained to learn the mapping between media inputs and side channel observations. We further enhance the autoencoder with attention to localize the program points that make the primary contribution to SCA, thus automatically pinpointing information-leakage points in media software. We also propose a novel and highly effective defensive technique called perception blinding that can perturb media inputs with perception masks and mitigate manifold learning-based SCA. Our evaluation exploits three popular media software to reconstruct inputs in image, audio, and text formats. We analyze three common side channels - cache bank, cache line, and page tables - and userspace-only cache set accesses logged by standard Prime+Probe. Our framework successfully reconstructs high-quality confidential inputs from the assessed media software and automatically pinpoint their vulnerable program points, many of which are unknown to the public. We further show that perception blinding can mitigate manifold learning-based SCA with negligible extra cost.
A novel knowledge graph development for industry design: A case study on indirect coal liquefaction process
Dec 17, 2021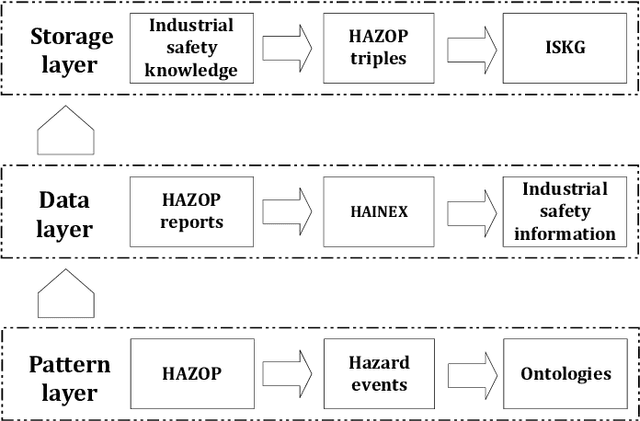
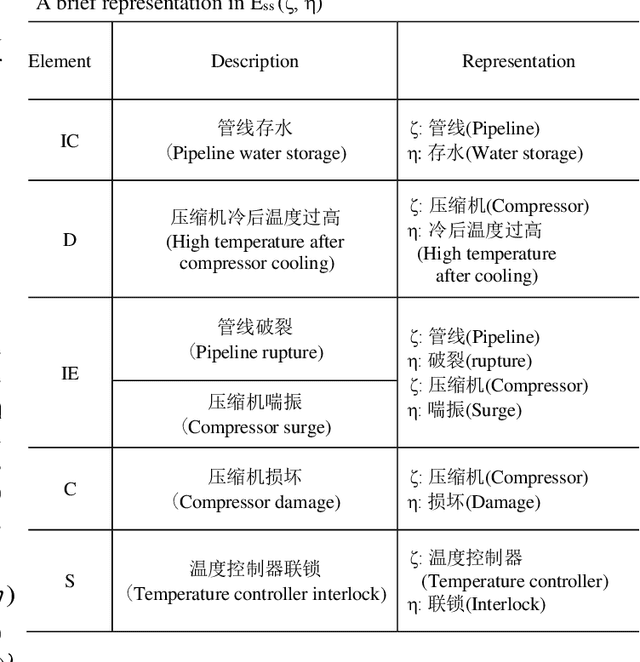

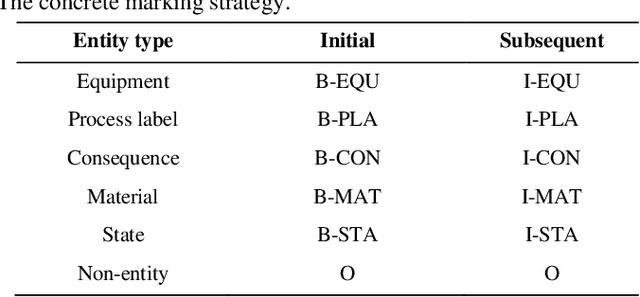
Hazard and operability analysis (HAZOP) is a remarkable representative in industrial safety engineering. However, a great storehouse of industrial safety knowledge (ISK) in HAZOP reports has not been thoroughly exploited. In order to reuse and unlock the value of ISK and optimize HAZOP, we have developed a novel knowledge graph for industrial safety (ISKG) with HAZOP as the carrier through bridging data science (DS) and engineering design (ED). Specifically, firstly, considering that the knowledge contained in HAZOP reports of different processes in industry is not the same, we have creatively developed a general ISK standardization framework (ISKSF), ISKSF provides a practical scheme for the standardization of HAZOP reports in various processes and the unified representation of different types of ISK, which realizes the integration and circulation of ISK. Secondly, we conceive a novel and reliable information extraction model (HAINEX) based on deep learning combined with DS. HAINEX can effectively mine ISK from HAZOP reports, which alleviates the obstacle of ISK extraction caused by the particularity of HAZOP text. Finally, we build ISK triples based on ISKSF and HAINEX and store them in the Neo4j graph database. We take indirect coal liquefaction process as a case study to develop ISKG, and its oriented applications can optimize HAZOP and mine the potential of ISK, which is of great significance to improve the security of the system and enhance prevention awareness for people. ISKG containing ISKSF and HAINEX sets an example of the interaction between DS and ED for industrial safety, which can enlighten other researchers committed to DS for ED and extend the perspectives of industrial safety.
Instrumented shoulder functional assessment using inertial measurement units for frozen shoulder
Nov 26, 2021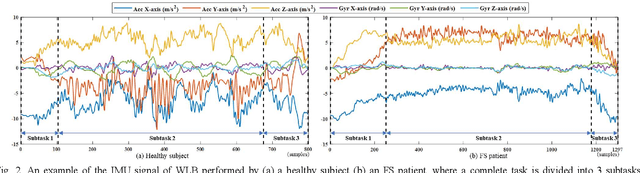
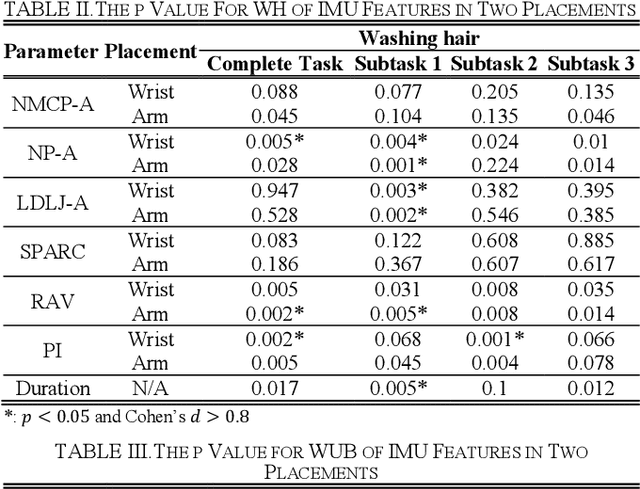
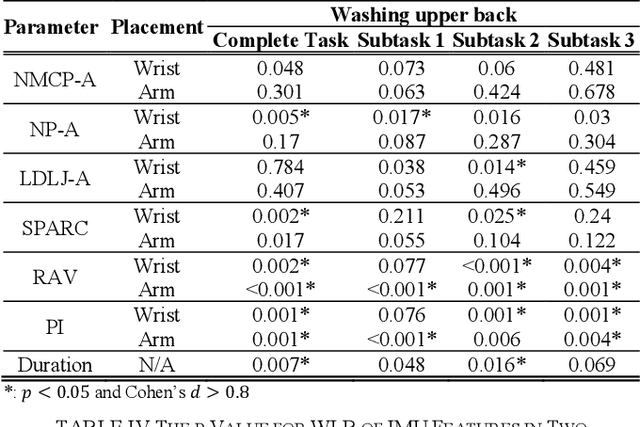
Frozen shoulder (FS) is a shoulder condition that leads to pain and loss of shoulder range of motion. FS patients have difficulties in independently performing daily activities. Inertial measurement units (IMUs) have been developed to objectively measure upper limb range of motion (ROM) and shoulder function. In this work, we propose an IMU-based shoulder functional task assessment with kinematic parameters (e.g., smoothness, power, speed, and duration) in FS patients and analyze the functional performance on complete shoulder tasks and subtasks. Twenty FS patients and twenty healthy subjects were recruited in this study. Five shoulder functional tasks are performed by participants, such as washing hair (WH), washing upper back (WUB), washing lower back (WLB), placing an object on a high shelf (POH), and removing an object from back pocket (ROP). The results demonstrate that the used smoothness features can reflect the differences of movement fluency between FS patients and healthy controls (p < 0.05 and effect size > 0.8). Moreover, features of subtasks provided subtle information related to clinical conditions that have not been revealed in features of a complete task, especially the defined subtask 1 and 2 of each task.
A Deep Neural Information Fusion Architecture for Textual Network Embeddings
Aug 29, 2019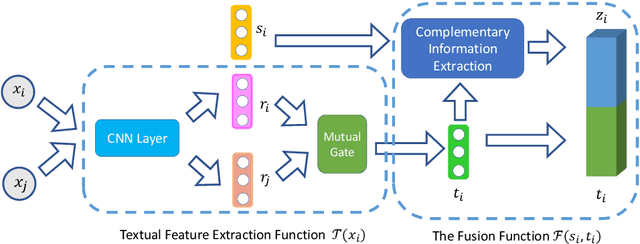
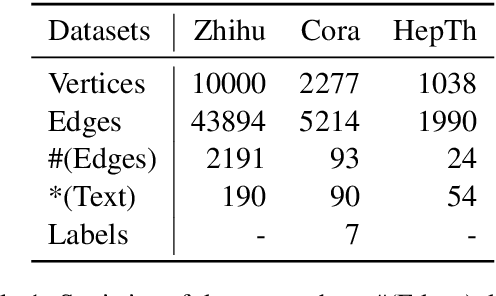
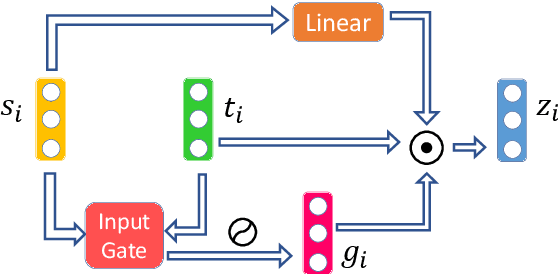
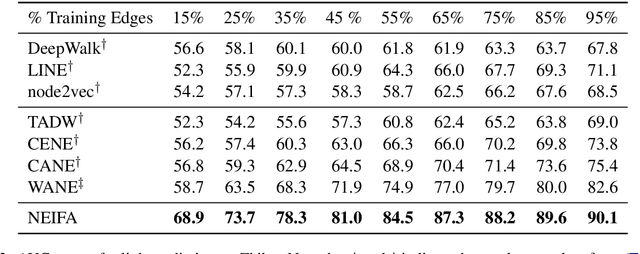
Textual network embeddings aim to learn a low-dimensional representation for every node in the network so that both the structural and textual information from the networks can be well preserved in the representations. Traditionally, the structural and textual embeddings were learned by models that rarely take the mutual influences between them into account. In this paper, a deep neural architecture is proposed to effectively fuse the two kinds of informations into one representation. The novelties of the proposed architecture are manifested in the aspects of a newly defined objective function, the complementary information fusion method for structural and textual features, and the mutual gate mechanism for textual feature extraction. Experimental results show that the proposed model outperforms the comparing methods on all three datasets.
An Integrated Framework for the Heterogeneous Spatio-Spectral-Temporal Fusion of Remote Sensing Images
Sep 01, 2021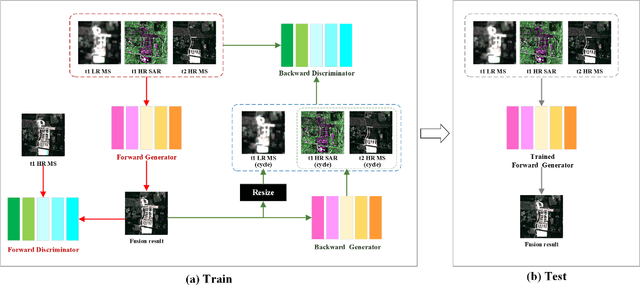
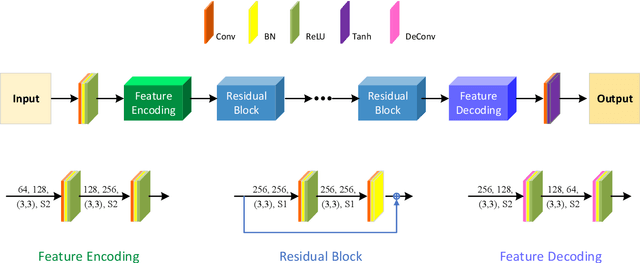
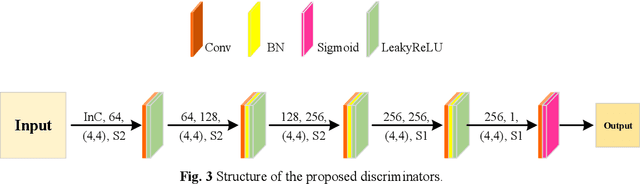
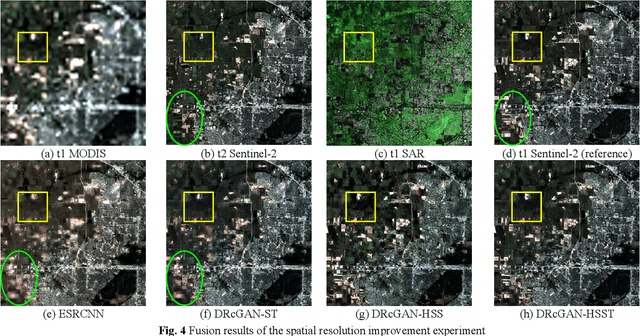
Image fusion technology is widely used to fuse the complementary information between multi-source remote sensing images. Inspired by the frontier of deep learning, this paper first proposes a heterogeneous-integrated framework based on a novel deep residual cycle GAN. The proposed network consists of a forward fusion part and a backward degeneration feedback part. The forward part generates the desired fusion result from the various observations; the backward degeneration feedback part considers the imaging degradation process and regenerates the observations inversely from the fusion result. The proposed network can effectively fuse not only the homogeneous but also the heterogeneous information. In addition, for the first time, a heterogeneous-integrated fusion framework is proposed to simultaneously merge the complementary heterogeneous spatial, spectral and temporal information of multi-source heterogeneous observations. The proposed heterogeneous-integrated framework also provides a uniform mode that can complete various fusion tasks, including heterogeneous spatio-spectral fusion, spatio-temporal fusion, and heterogeneous spatio-spectral-temporal fusion. Experiments are conducted for two challenging scenarios of land cover changes and thick cloud coverage. Images from many remote sensing satellites, including MODIS, Landsat-8, Sentinel-1, and Sentinel-2, are utilized in the experiments. Both qualitative and quantitative evaluations confirm the effectiveness of the proposed method.
TEGDetector: A Phishing Detector that Knows Evolving Transaction Behaviors
Nov 26, 2021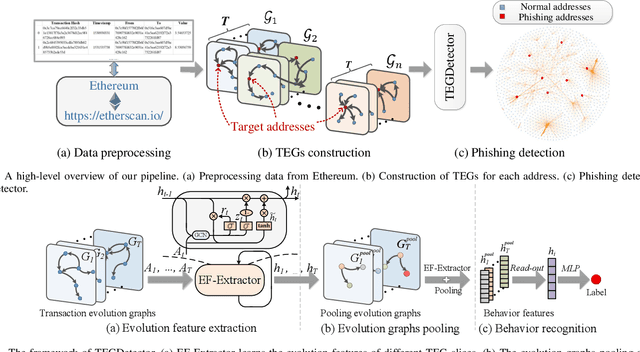
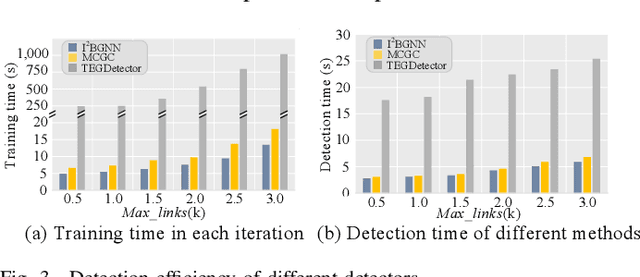
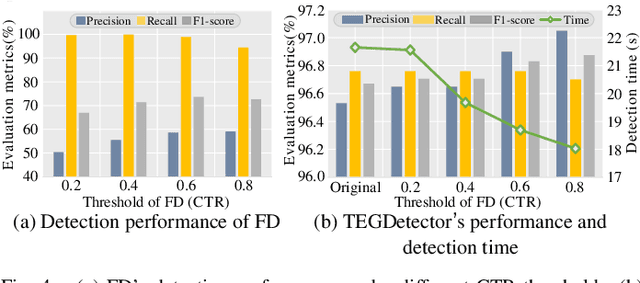
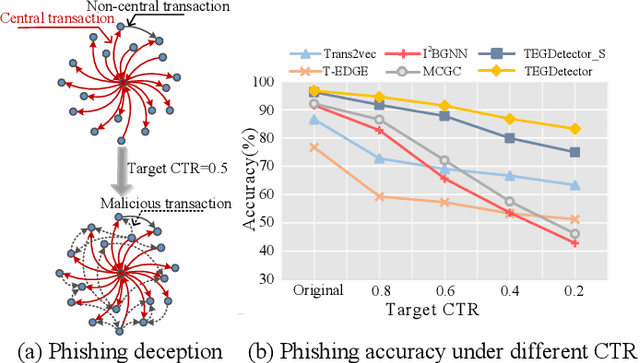
Recently, phishing scams have posed a significant threat to blockchains. Phishing detectors direct their efforts in hunting phishing addresses. Most of the detectors extract target addresses' transaction behavior features by random walking or constructing static subgraphs. The random walking methods,unfortunately, usually miss structural information due to limited sampling sequence length, while the static subgraph methods tend to ignore temporal features lying in the evolving transaction behaviors. More importantly, their performance undergoes severe degradation when the malicious users intentionally hide phishing behaviors. To address these challenges, we propose TEGDetector, a dynamic graph classifier that learns the evolving behavior features from transaction evolution graphs (TEGs). First, we cast the transaction series into multiple time slices, capturing the target address's transaction behaviors in different periods. Then, we provide a fast non-parametric phishing detector to narrow down the search space of suspicious addresses. Finally, TEGDetector considers both the spatial and temporal evolutions towards a complete characterization of the evolving transaction behaviors. Moreover, TEGDetector utilizes adaptively learnt time coefficient to pay distinct attention to different periods, which provides several novel insights. Extensive experiments on the large-scale Ethereum transaction dataset demonstrate that the proposed method achieves state-of-the-art detection performance.
Clinical Utility of the Automatic Phenotype Annotation in Unstructured Clinical Notes: ICU Use Cases
Jul 24, 2021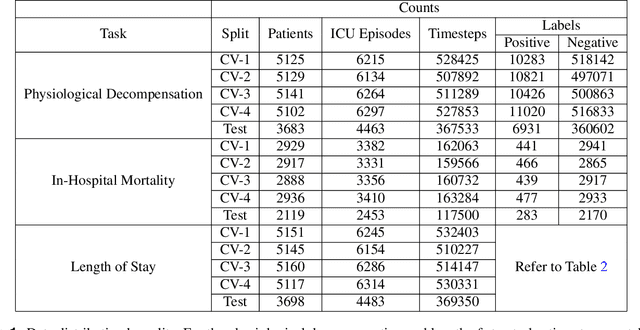
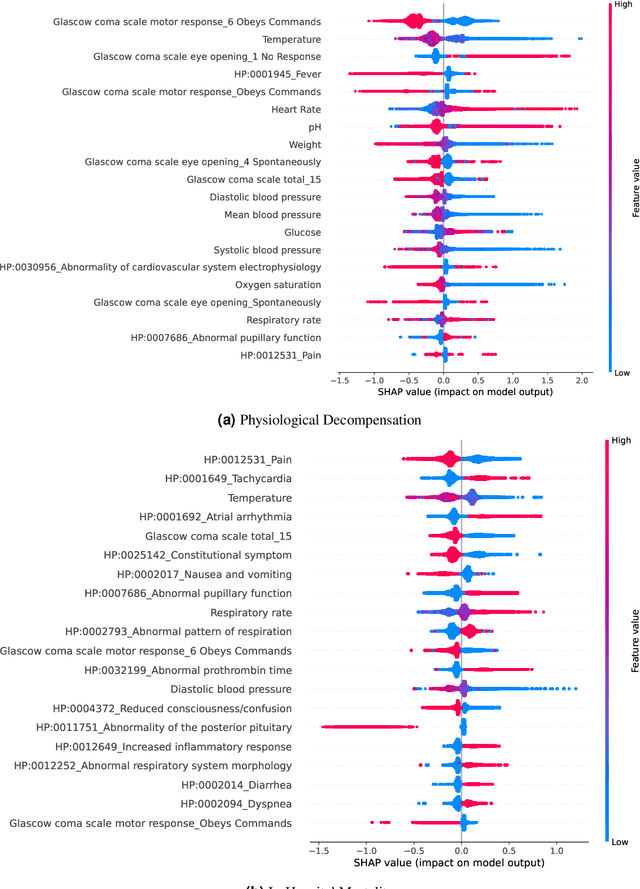
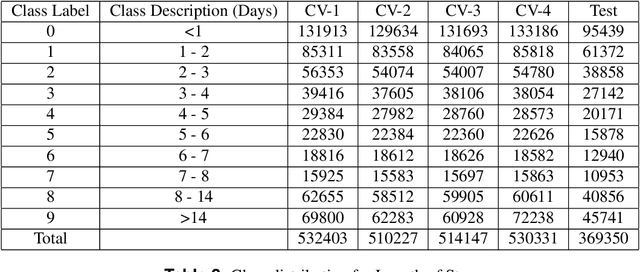
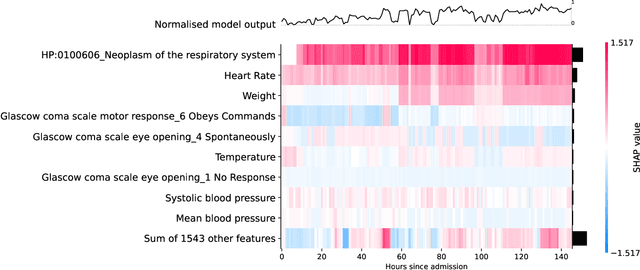
Clinical notes contain information not present elsewhere, including drug response and symptoms, all of which are highly important when predicting key outcomes in acute care patients. We propose the automatic annotation of phenotypes from clinical notes as a method to capture essential information to predict outcomes in the Intensive Care Unit (ICU). This information is complementary to typically used vital signs and laboratory test results. We demonstrate and validate our approach conducting experiments on the prediction of in-hospital mortality, physiological decompensation and length of stay in the ICU setting for over 24,000 patients. The prediction models incorporating phenotypic information consistently outperform the baseline models leveraging only vital signs and laboratory test results. Moreover, we conduct a thorough interpretability study, showing that phenotypes provide valuable insights at the patient and cohort levels. Our approach illustrates the viability of using phenotypes to determine outcomes in the ICU.