 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeepAoANet: Learning Angle of Arrival from Software Defined Radios with Deep Neural Networks
Dec 01, 2021
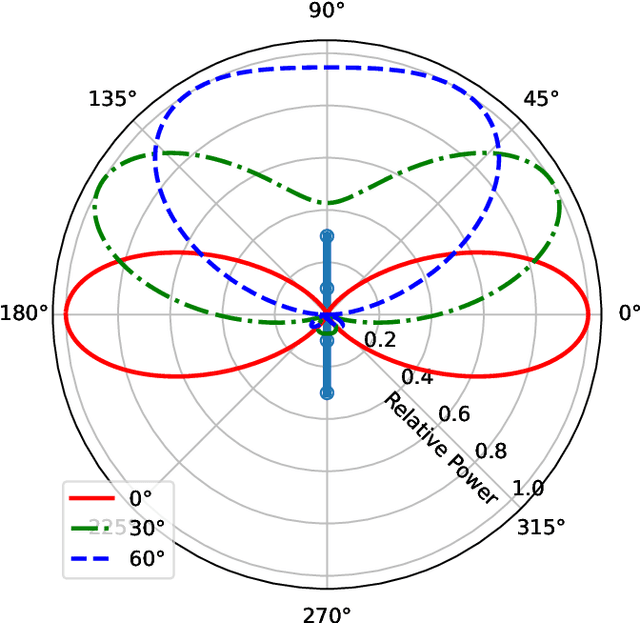
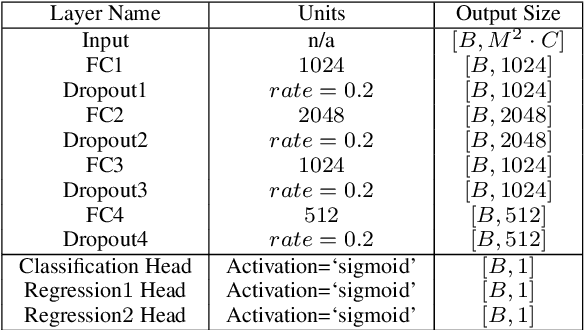
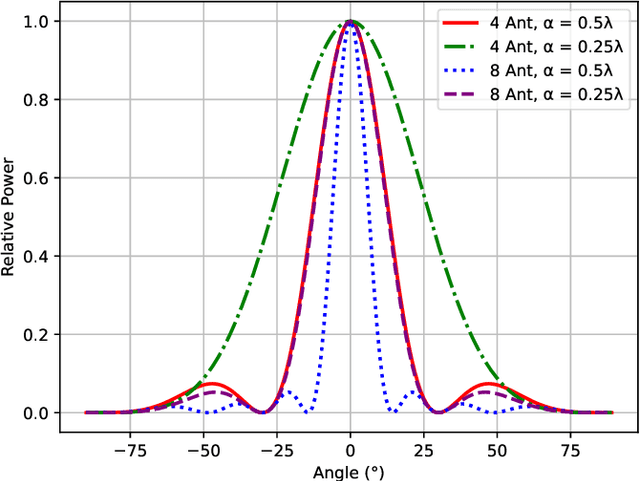
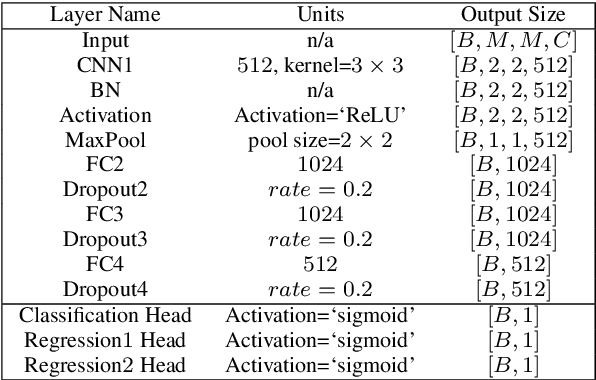
Direction finding and positioning systems based on RF signals are significantly impacted by multipath propagation, particularly in indoor environments. Existing algorithms (e.g MUSIC) perform poorly in resolving Angle of Arrival (AoA) in the presence of multipath or when operating in a weak signal regime. We note that digitally sampled RF frontends allow for the easy analysis of signals, and their delayed components. Low-cost Software-Defined Radio (SDR) modules enable Channel State Information (CSI) extraction across a wide spectrum, motivating the design of an enhanced Angle-of-Arrival (AoA) solution. We propose a Deep Learning approach to deriving AoA from a single snapshot of the SDR multichannel data. We compare and contrast deep-learning based angle classification and regression models, to estimate up to two AoAs accurately. We have implemented the inference engines on different platforms to extract AoAs in real-time, demonstrating the computational tractability of our approach. To demonstrate the utility of our approach we have collected IQ (In-phase and Quadrature components) samples from a four-element Universal Linear Array (ULA) in various Light-of-Sight (LOS) and Non-Line-of-Sight (NLOS) environments, and published the dataset. Our proposed method demonstrates excellent reliability in determining number of impinging signals and realized mean absolute AoA errors less than $2^{\circ}$.
Automated tabulation of clinical trial results: A joint entity and relation extraction approach with transformer-based language representations
Dec 10, 2021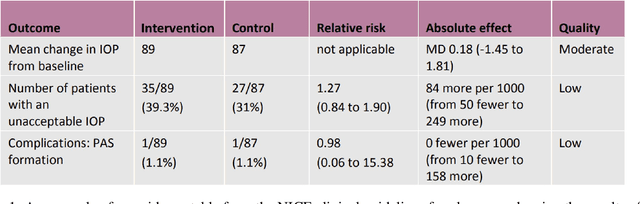

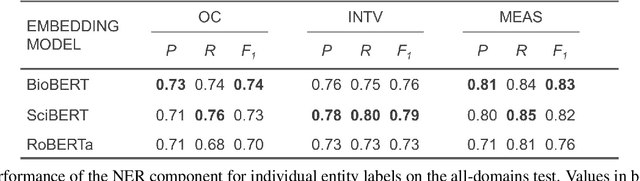
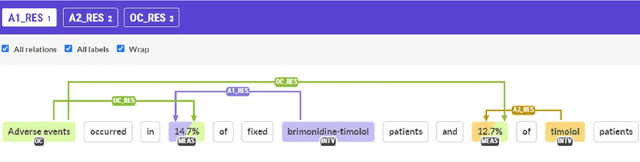
Evidence-based medicine, the practice in which healthcare professionals refer to the best available evidence when making decisions, forms the foundation of modern healthcare. However, it relies on labour-intensive systematic reviews, where domain specialists must aggregate and extract information from thousands of publications, primarily of randomised controlled trial (RCT) results, into evidence tables. This paper investigates automating evidence table generation by decomposing the problem across two language processing tasks: \textit{named entity recognition}, which identifies key entities within text, such as drug names, and \textit{relation extraction}, which maps their relationships for separating them into ordered tuples. We focus on the automatic tabulation of sentences from published RCT abstracts that report the results of the study outcomes. Two deep neural net models were developed as part of a joint extraction pipeline, using the principles of transfer learning and transformer-based language representations. To train and test these models, a new gold-standard corpus was developed, comprising almost 600 result sentences from six disease areas. This approach demonstrated significant advantages, with our system performing well across multiple natural language processing tasks and disease areas, as well as in generalising to disease domains unseen during training. Furthermore, we show these results were achievable through training our models on as few as 200 example sentences. The final system is a proof of concept that the generation of evidence tables can be semi-automated, representing a step towards fully automating systematic reviews.
Federated Learning with Correlated Data: Taming the Tail for Age-Optimal Industrial IoT
Aug 17, 2021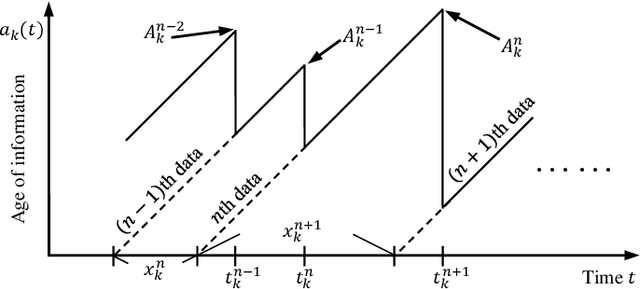

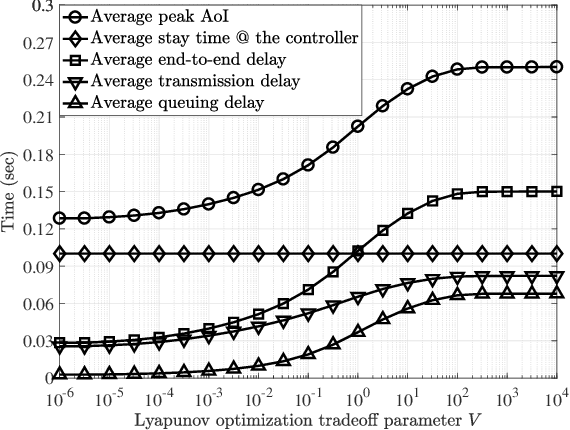
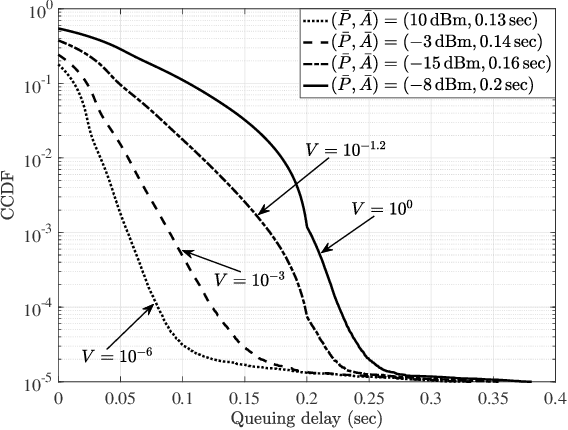
While information delivery in industrial Internet of things demands reliability and latency guarantees, the freshness of the controller's available information, measured by the age of information (AoI), is paramount for high-performing industrial automation. The problem in this work is cast as a sensor's transmit power minimization subject to the peak-AoI requirement and a probabilistic constraint on queuing latency. We further characterize the tail behavior of the latency by a generalized Pareto distribution (GPD) for solving the power allocation problem through Lyapunov optimization. As each sensor utilizes its own data to locally train the GPD model, we incorporate federated learning and propose a local-model selection approach which accounts for correlation among the sensor's training data. Numerical results show the tradeoff between the transmit power, peak AoI, and delay's tail distribution. Furthermore, we verify the superiority of the proposed correlation-aware approach for selecting the local models in federated learning over an existing baseline.
Feature Concepts for Data Federative Innovations
Nov 05, 2021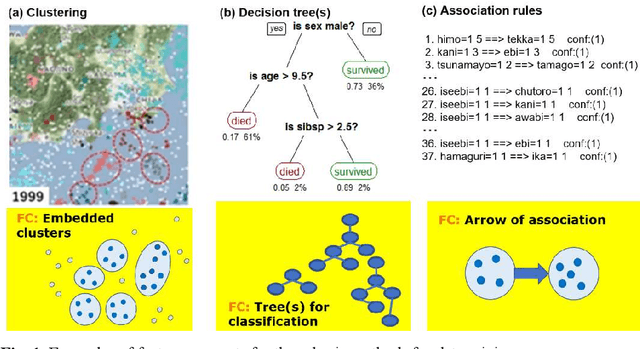
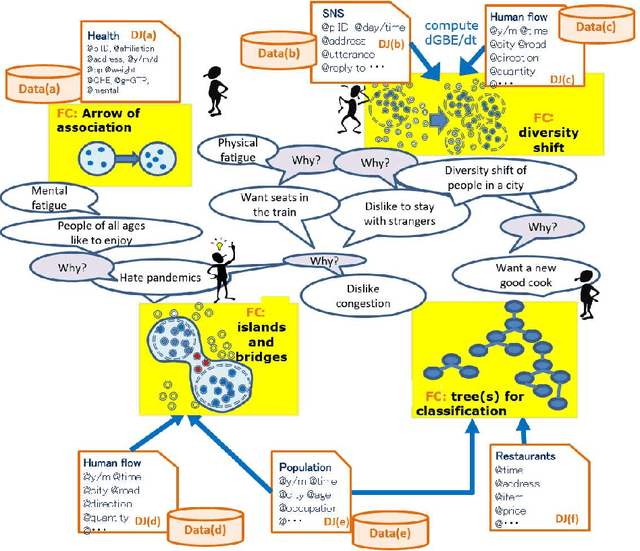
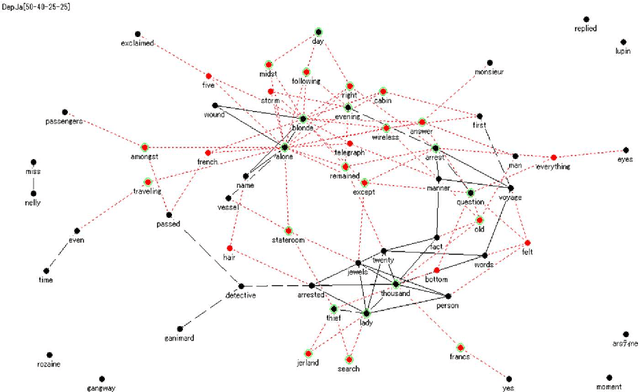
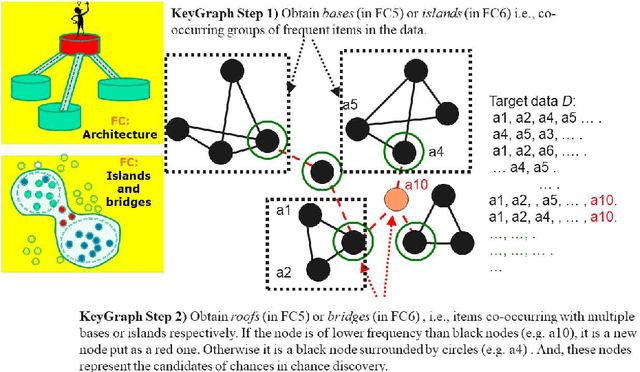
A feature concept, the essence of the data-federative innovation process, is presented as a model of the concept to be acquired from data. A feature concept may be a simple feature, such as a single variable, but is more likely to be a conceptual illustration of the abstract information to be obtained from the data. For example, trees and clusters are feature concepts for decision tree learning and clustering, respectively. Useful feature concepts for satis-fying the requirements of users of data have been elicited so far via creative communication among stakeholders in the market of data. In this short paper, such a creative communication is reviewed, showing a couple of appli-cations, for example, change explanation in markets and earthquakes, and highlight the feature concepts elicited in these cases.
Camera Condition Monitoring and Readjustment by means of Noise and Blur
Dec 10, 2021

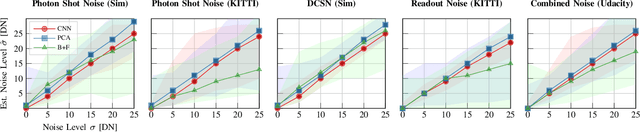
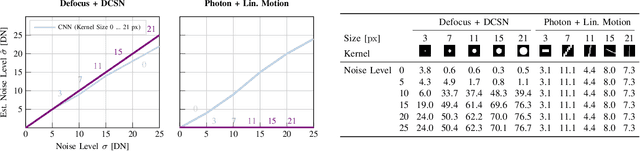
Autonomous vehicles and robots require increasingly more robustness and reliability to meet the demands of modern tasks. These requirements specially apply to cameras because they are the predominant sensors to acquire information about the environment and support actions. A camera must maintain proper functionality and take automatic countermeasures if necessary. However, there is little work that examines the practical use of a general condition monitoring approach for cameras and designs countermeasures in the context of an envisaged high-level application. We propose a generic and interpretable self-health-maintenance framework for cameras based on data- and physically-grounded models. To this end, we determine two reliable, real-time capable estimators for typical image effects of a camera in poor condition (defocus blur, motion blur, different noise phenomena and most common combinations) by comparing traditional and retrained machine learning-based approaches in extensive experiments. Furthermore, we demonstrate how one can adjust the camera parameters (e.g., exposure time and ISO gain) to achieve optimal whole-system capability based on experimental (non-linear and non-monotonic) input-output performance curves, using object detection, motion blur and sensor noise as examples. Our framework not only provides a practical ready-to-use solution to evaluate and maintain the health of cameras, but can also serve as a basis for extensions to tackle more sophisticated problems that combine additional data sources (e.g., sensor or environment parameters) empirically in order to attain fully reliable and robust machines.
Edge but not Least: Cross-View Graph Pooling
Sep 24, 2021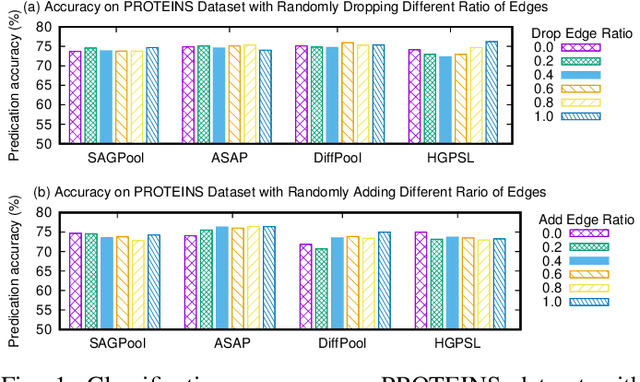
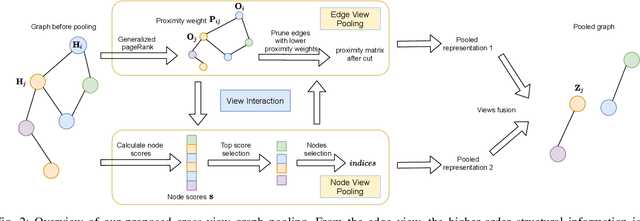
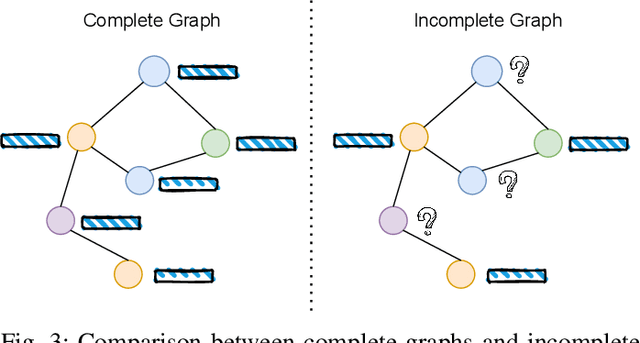
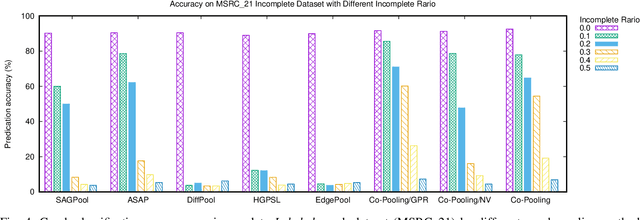
Graph neural networks have emerged as a powerful model for graph representation learning to undertake graph-level prediction tasks. Various graph pooling methods have been developed to coarsen an input graph into a succinct graph-level representation through aggregating node embeddings obtained via graph convolution. However, most graph pooling methods are heavily node-centric and are unable to fully leverage the crucial information contained in global graph structure. This paper presents a cross-view graph pooling (Co-Pooling) method to better exploit crucial graph structure information. The proposed Co-Pooling fuses pooled representations learnt from both node view and edge view. Through cross-view interaction, edge-view pooling and node-view pooling seamlessly reinforce each other to learn more informative graph-level representations. Co-Pooling has the advantage of handling various graphs with different types of node attributes. Extensive experiments on a total of 15 graph benchmark datasets validate the effectiveness of our proposed method, demonstrating its superior performance over state-of-the-art pooling methods on both graph classification and graph regression tasks.
AVA-AVD: Audio-visual Speaker Diarization in the Wild
Dec 01, 2021

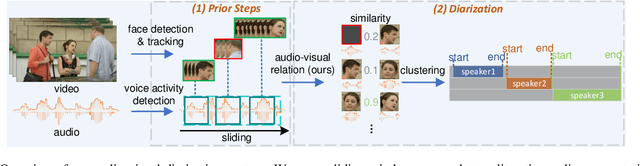
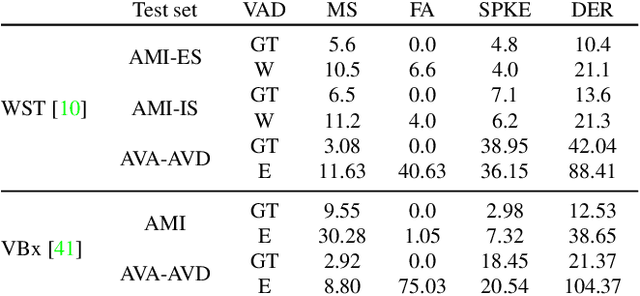
Audio-visual speaker diarization aims at detecting ``who spoken when`` using both auditory and visual signals. Existing audio-visual diarization datasets are mainly focused on indoor environments like meeting rooms or news studios, which are quite different from in-the-wild videos in many scenarios such as movies, documentaries, and audience sitcoms. To create a testbed that can effectively compare diarization methods on videos in the wild, we annotate the speaker diarization labels on the AVA movie dataset and create a new benchmark called AVA-AVD. This benchmark is challenging due to the diverse scenes, complicated acoustic conditions, and completely off-screen speakers. Yet, how to deal with off-screen and on-screen speakers together still remains a critical challenge. To overcome it, we propose a novel Audio-Visual Relation Network (AVR-Net) which introduces an effective modality mask to capture discriminative information based on visibility. Experiments have shown that our method not only can outperform state-of-the-art methods but also is more robust as varying the ratio of off-screen speakers. Ablation studies demonstrate the advantages of the proposed AVR-Net and especially the modality mask on diarization. Our data and code will be made publicly available at https://github.com/zcxu-eric/AVA-AVD.
Federated Learning for Internet of Things: Applications, Challenges, and Opportunities
Nov 15, 2021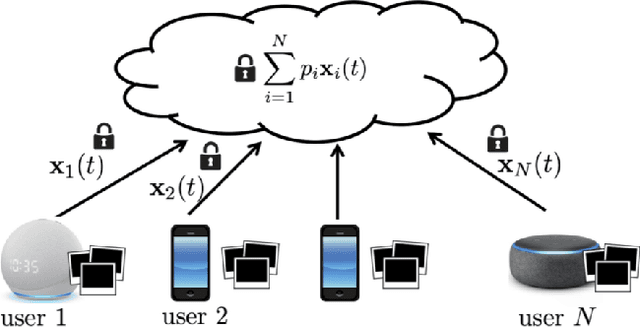
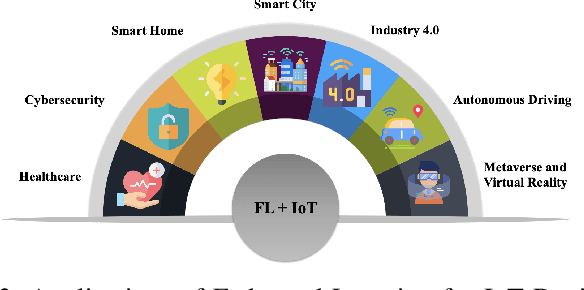
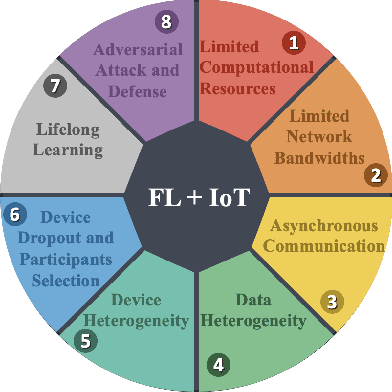
Billions of IoT devices will be deployed in the near future, taking advantage of the faster Internet speed and the possibility of orders of magnitude more endpoints brought by 5G/6G. With the blooming of IoT devices, vast quantities of data that may contain private information of users will be generated. The high communication and storage costs, mixed with privacy concerns, will increasingly be challenging the traditional ecosystem of centralized over-the-cloud learning and processing for IoT platforms. Federated Learning (FL) has emerged as the most promising alternative approach to this problem. In FL, training of data-driven machine learning models is an act of collaboration between multiple clients without requiring the data to be brought to a central point, hence alleviating communication and storage costs and providing a great degree of user-level privacy. We discuss the opportunities and challenges of FL for IoT platforms, as well as how it can enable future IoT applications.
Point-of-Interest Type Prediction using Text and Images
Sep 01, 2021
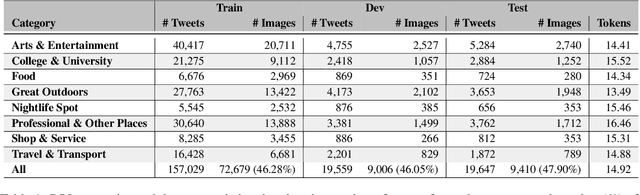
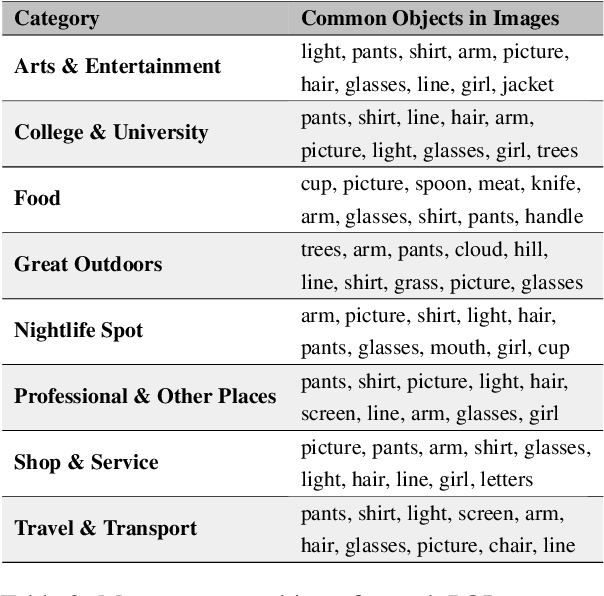
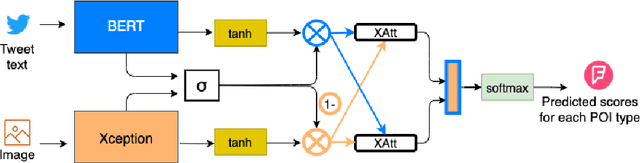
Point-of-interest (POI) type prediction is the task of inferring the type of a place from where a social media post was shared. Inferring a POI's type is useful for studies in computational social science including sociolinguistics, geosemiotics, and cultural geography, and has applications in geosocial networking technologies such as recommendation and visualization systems. Prior efforts in POI type prediction focus solely on text, without taking visual information into account. However in reality, the variety of modalities, as well as their semiotic relationships with one another, shape communication and interactions in social media. This paper presents a study on POI type prediction using multimodal information from text and images available at posting time. For that purpose, we enrich a currently available data set for POI type prediction with the images that accompany the text messages. Our proposed method extracts relevant information from each modality to effectively capture interactions between text and image achieving a macro F1 of 47.21 across eight categories significantly outperforming the state-of-the-art method for POI type prediction based on text-only methods. Finally, we provide a detailed analysis to shed light on cross-modal interactions and the limitations of our best performing model.
Causal Order Identification to Address Confounding: Binary Variables
Aug 10, 2021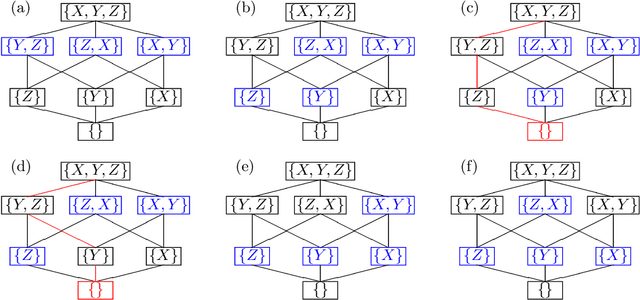

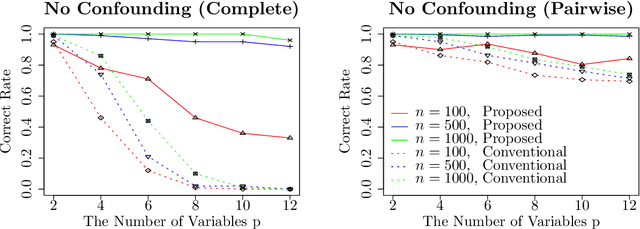
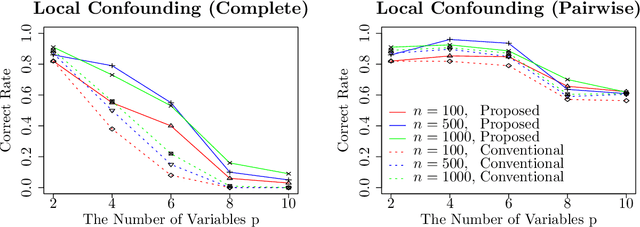
This paper considers an extension of the linear non-Gaussian acyclic model (LiNGAM) that determines the causal order among variables from a dataset when the variables are expressed by a set of linear equations, including noise. In particular, we assume that the variables are binary. The existing LiNGAM assumes that no confounding is present, which is restrictive in practice. Based on the concept of independent component analysis (ICA), this paper proposes an extended framework in which the mutual information among the noises is minimized. Another significant contribution is to reduce the realization of the shortest path problem. The distance between each pair of nodes expresses an associated mutual information value, and the path with the minimum sum (KL divergence) is sought. Although $p!$ mutual information values should be compared, this paper dramatically reduces the computation when no confounding is present. The proposed algorithm finds the globally optimal solution, while the existing locally greedily seek the order based on hypothesis testing. We use the best estimator in the sense of Bayes/MDL that correctly detects independence for mutual information estimation. Experiments using artificial and actual data show that the proposed version of LiNGAM achieves significantly better performance, particularly when confounding is present.