 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fully Automatic Deep Learning Framework for Pancreatic Ductal Adenocarcinoma Detection on Computed Tomography
Dec 02, 2021
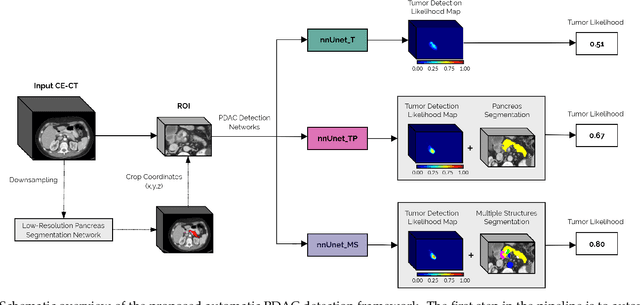

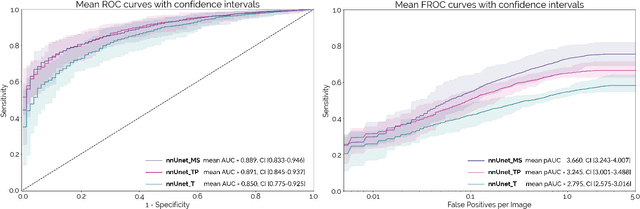
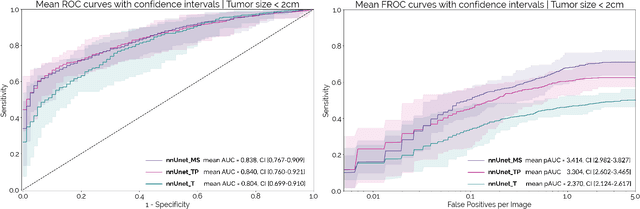
Early detection improves prognosis in pancreatic ductal adenocarcinoma (PDAC) but is challenging as lesions are often small and poorly defined on contrast-enhanced computed tomography scans (CE-CT). Deep learning can facilitate PDAC diagnosis, however current models still fail to identify small (<2cm) lesions. In this study, state-of-the-art deep learning models were used to develop an automatic framework for PDAC detection, focusing on small lesions. Additionally, the impact of integrating surrounding anatomy was investigated. CE-CT scans from a cohort of 119 pathology-proven PDAC patients and a cohort of 123 patients without PDAC were used to train a nnUnet for automatic lesion detection and segmentation (nnUnet_T). Two additional nnUnets were trained to investigate the impact of anatomy integration: (1) segmenting the pancreas and tumor (nnUnet_TP), (2) segmenting the pancreas, tumor, and multiple surrounding anatomical structures (nnUnet_MS). An external, publicly available test set was used to compare the performance of the three networks. The nnUnet_MS achieved the best performance, with an area under the receiver operating characteristic curve of 0.91 for the whole test set and 0.88 for tumors <2cm, showing that state-of-the-art deep learning can detect small PDAC and benefits from anatomy information.
A General Framework for Lifelong Localization and Mapping in Changing Environment
Nov 22, 2021
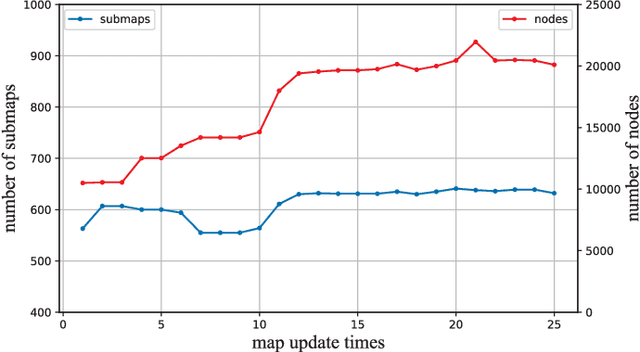
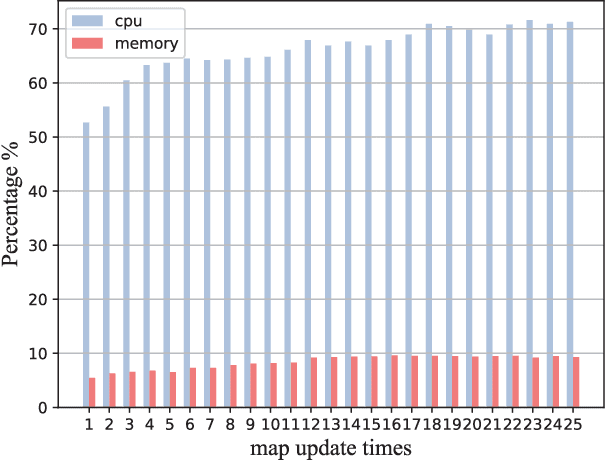
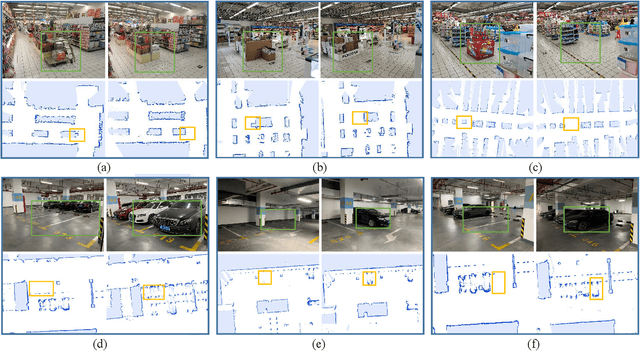
The environment of most real-world scenarios such as malls and supermarkets changes at all times. A pre-built map that does not account for these changes becomes out-of-date easily. Therefore, it is necessary to have an up-to-date model of the environment to facilitate long-term operation of a robot. To this end, this paper presents a general lifelong simultaneous localization and mapping (SLAM) framework. Our framework uses a multiple session map representation, and exploits an efficient map updating strategy that includes map building, pose graph refinement and sparsification. To mitigate the unbounded increase of memory usage, we propose a map-trimming method based on the Chow-Liu maximum-mutual-information spanning tree. The proposed SLAM framework has been comprehensively validated by over a month of robot deployment in real supermarket environment. Furthermore, we release the dataset collected from the indoor and outdoor changing environment with the hope to accelerate lifelong SLAM research in the community. Our dataset is available at https://github.com/sanduan168/lifelong-SLAM-dataset.
Spatio-Temporal Joint Graph Convolutional Networks for Traffic Forecasting
Dec 02, 2021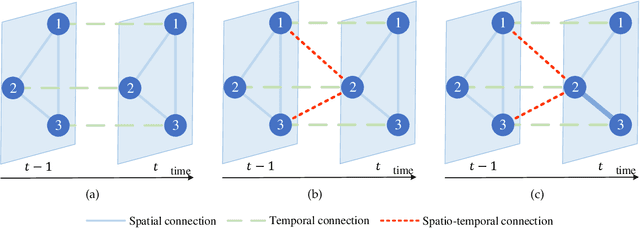
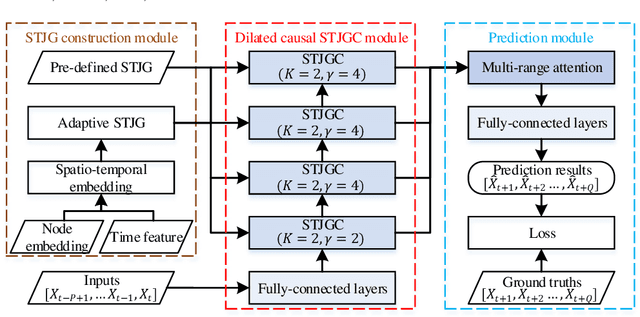
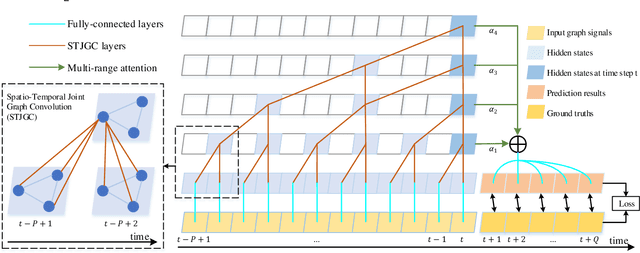
Recent studies focus on formulating the traffic forecasting as a spatio-temporal graph modeling problem. They typically construct a static spatial graph at each time step and then connect each node with itself between adjacent time steps to construct the spatio-temporal graph. In such a graph, the correlations between different nodes at different time steps are not explicitly reflected, which may restrict the learning ability of graph neural networks. Meanwhile, those models ignore the dynamic spatio-temporal correlations among nodes as they use the same adjacency matrix at different time steps. To overcome these limitations, we propose a Spatio-Temporal Joint Graph Convolutional Networks (STJGCN) for traffic forecasting over several time steps ahead on a road network. Specifically, we construct both pre-defined and adaptive spatio-temporal joint graphs (STJGs) between any two time steps, which represent comprehensive and dynamic spatio-temporal correlations. We further design dilated causal spatio-temporal joint graph convolution layers on STJG to capture the spatio-temporal dependencies from distinct perspectives with multiple ranges. A multi-range attention mechanism is proposed to aggregate the information of different ranges. Experiments on four public traffic datasets demonstrate that STJGCN is computationally efficient and outperforms 11 state-of-the-art baseline methods.
Point-of-Interest Type Prediction using Text and Images
Sep 01, 2021
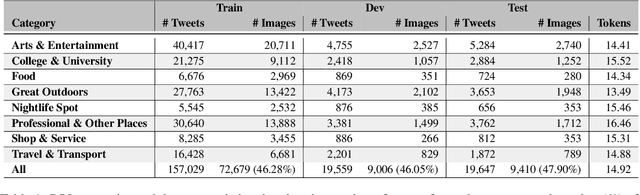
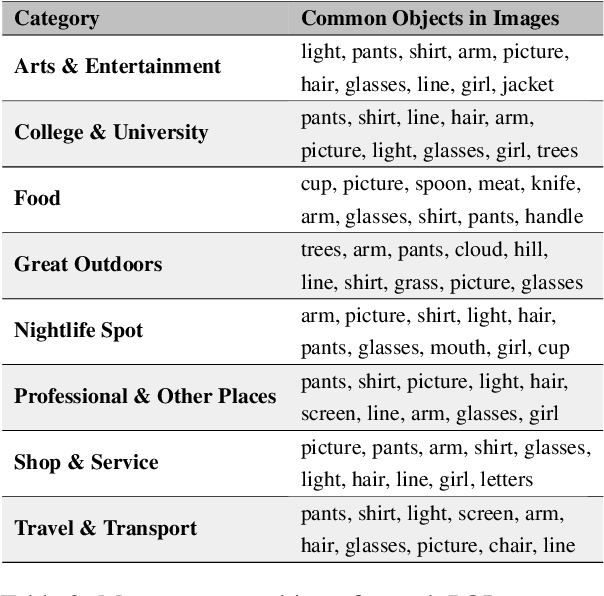
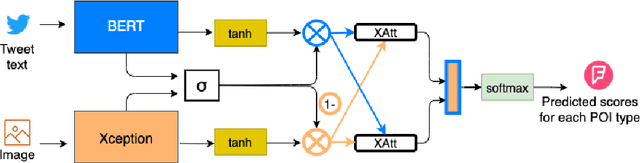
Point-of-interest (POI) type prediction is the task of inferring the type of a place from where a social media post was shared. Inferring a POI's type is useful for studies in computational social science including sociolinguistics, geosemiotics, and cultural geography, and has applications in geosocial networking technologies such as recommendation and visualization systems. Prior efforts in POI type prediction focus solely on text, without taking visual information into account. However in reality, the variety of modalities, as well as their semiotic relationships with one another, shape communication and interactions in social media. This paper presents a study on POI type prediction using multimodal information from text and images available at posting time. For that purpose, we enrich a currently available data set for POI type prediction with the images that accompany the text messages. Our proposed method extracts relevant information from each modality to effectively capture interactions between text and image achieving a macro F1 of 47.21 across eight categories significantly outperforming the state-of-the-art method for POI type prediction based on text-only methods. Finally, we provide a detailed analysis to shed light on cross-modal interactions and the limitations of our best performing model.
How do kernel-based sensor fusion algorithms behave under high dimensional noise?
Nov 22, 2021We study the behavior of two kernel based sensor fusion algorithms, nonparametric canonical correlation analysis (NCCA) and alternating diffusion (AD), under the nonnull setting that the clean datasets collected from two sensors are modeled by a common low dimensional manifold embedded in a high dimensional Euclidean space and the datasets are corrupted by high dimensional noise. We establish the asymptotic limits and convergence rates for the eigenvalues of the associated kernel matrices assuming that the sample dimension and sample size are comparably large, where NCCA and AD are conducted using the Gaussian kernel. It turns out that both the asymptotic limits and convergence rates depend on the signal-to-noise ratio (SNR) of each sensor and selected bandwidths. On one hand, we show that if NCCA and AD are directly applied to the noisy point clouds without any sanity check, it may generate artificial information that misleads scientists' interpretation. On the other hand, we prove that if the bandwidths are selected adequately, both NCCA and AD can be made robust to high dimensional noise when the SNRs are relatively large.
Handshakes AI Research at CASE 2021 Task 1: Exploring different approaches for multilingual tasks
Oct 29, 2021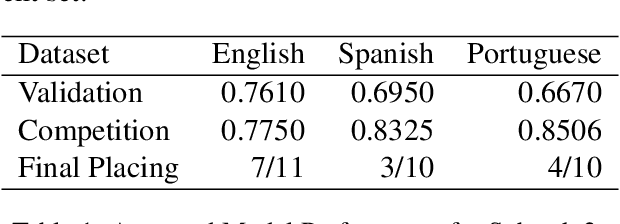
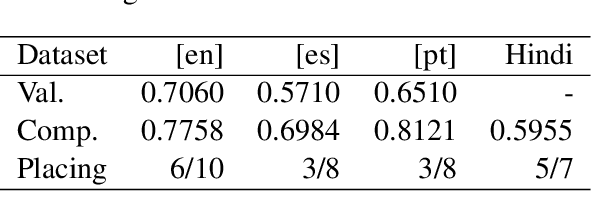
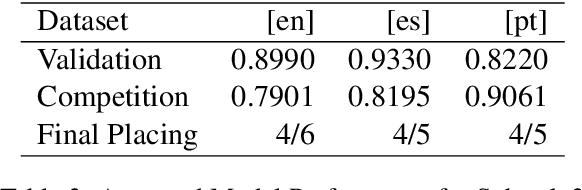

The aim of the CASE 2021 Shared Task 1 (H\"urriyeto\u{g}lu et al., 2021) was to detect and classify socio-political and crisis event information at document, sentence, cross-sentence, and token levels in a multilingual setting, with each of these subtasks being evaluated separately in each test language. Our submission contained entries in all of the subtasks, and the scores obtained validated our research finding: That the multilingual aspect of the tasks should be embraced, so that modeling and training regimes use the multilingual nature of the tasks to their mutual benefit, rather than trying to tackle the different languages separately. Our code is available at https://github.com/HandshakesByDC/case2021/
* Accepted paper for CASE 2021 workshop at ACL-IJCNLP 2021. (6 pages including references)
Low-resource Learning with Knowledge Graphs: A Comprehensive Survey
Dec 22, 2021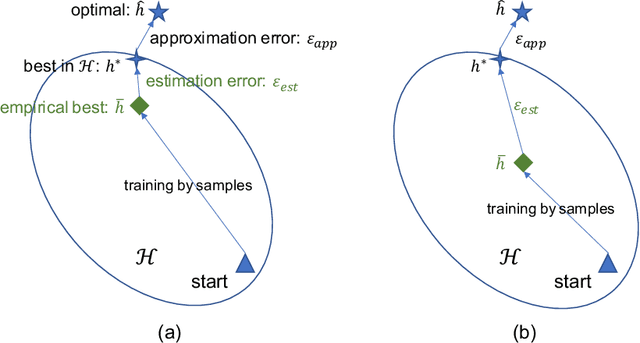
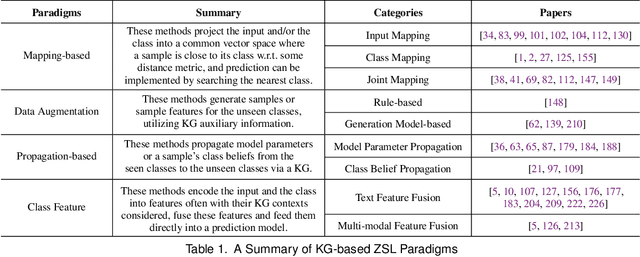
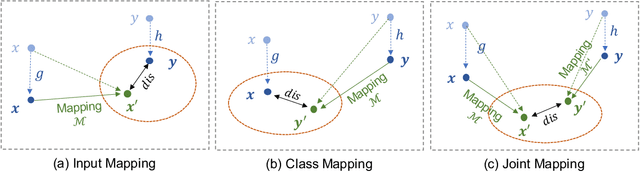
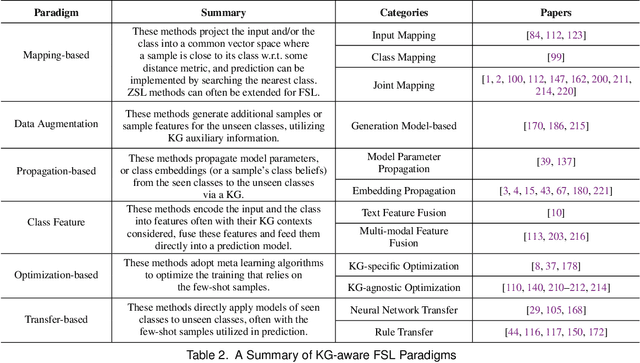
Machine learning methods especially deep neural networks have achieved great success but many of them often rely on a number of labeled samples for training. In real-world applications, we often need to address sample shortage due to e.g., dynamic contexts with emerging prediction targets and costly sample annotation. Therefore, low-resource learning, which aims to learn robust prediction models with no enough resources (especially training samples), is now being widely investigated. Among all the low-resource learning studies, many prefer to utilize some auxiliary information in the form of Knowledge Graph (KG), which is becoming more and more popular for knowledge representation, to reduce the reliance on labeled samples. In this survey, we very comprehensively reviewed over $90$ papers about KG-aware research for two major low-resource learning settings -- zero-shot learning (ZSL) where new classes for prediction have never appeared in training, and few-shot learning (FSL) where new classes for prediction have only a small number of labeled samples that are available. We first introduced the KGs used in ZSL and FSL studies as well as the existing and potential KG construction solutions, and then systematically categorized and summarized KG-aware ZSL and FSL methods, dividing them into different paradigms such as the mapping-based, the data augmentation, the propagation-based and the optimization-based. We next presented different applications, including not only KG augmented tasks in Computer Vision and Natural Language Processing (e.g., image classification, text classification and knowledge extraction), but also tasks for KG curation (e.g., inductive KG completion), and some typical evaluation resources for each task. We eventually discussed some challenges and future directions on aspects such as new learning and reasoning paradigms, and the construction of high quality KGs.
Accelerated Almost-Sure Convergence Rates for Nonconvex Stochastic Gradient Descent using Stochastic Learning Rates
Oct 25, 2021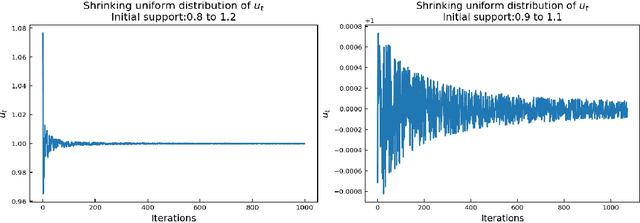
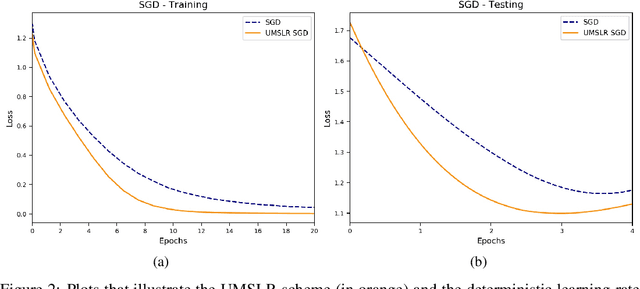
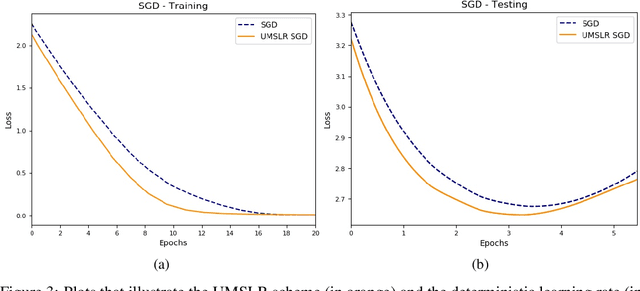
Large-scale optimization problems require algorithms both effective and efficient. One such popular and proven algorithm is Stochastic Gradient Descent which uses first-order gradient information to solve these problems. This paper studies almost-sure convergence rates of the Stochastic Gradient Descent method when instead of deterministic, its learning rate becomes stochastic. In particular, its learning rate is equipped with a multiplicative stochasticity, producing a stochastic learning rate scheme. Theoretical results show accelerated almost-sure convergence rates of Stochastic Gradient Descent in a nonconvex setting when using an appropriate stochastic learning rate, compared to a deterministic-learning-rate scheme. The theoretical results are verified empirically.
Boosting Neural Image Compression for Machines Using Latent Space Masking
Dec 15, 2021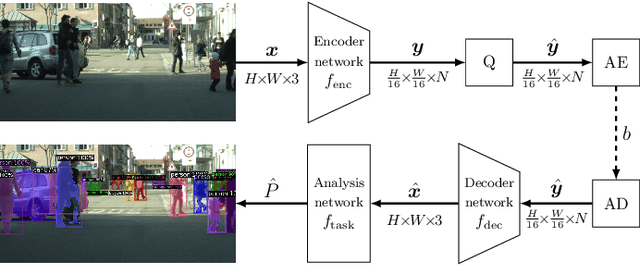
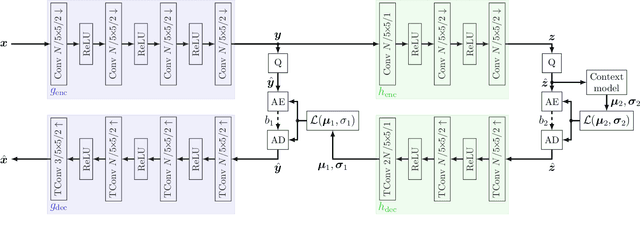
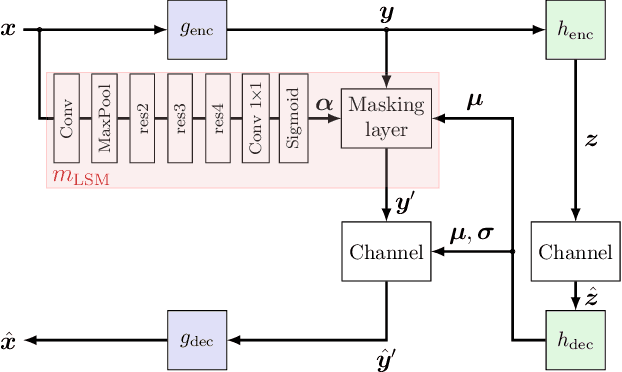
Today, many image coding scenarios do not have a human as final intended user, but rather a machine fulfilling computer vision tasks on the decoded image. Thereby, the primary goal is not to keep visual quality but maintain the task accuracy of the machine for a given bitrate. Due to the tremendous progress of deep neural networks setting benchmarking results, mostly neural networks are employed to solve the analysis tasks at the decoder side. Moreover, neural networks have also found their way into the field of image compression recently. These two developments allow for an end-to-end training of the neural compression network for an analysis network as information sink. Therefore, we first roll out such a training with a task-specific loss to enhance the coding performance of neural compression networks. Compared to the standard VVC, 41.4 % of bitrate are saved by this method for Mask R-CNN as analysis network on the uncompressed Cityscapes dataset. As a main contribution, we propose LSMnet, a network that runs in parallel to the encoder network and masks out elements of the latent space that are presumably not required for the analysis network. By this approach, additional 27.3 % of bitrate are saved compared to the basic neural compression network optimized with the task loss. In addition, we propose a feature-based loss, which allows for a training without annotated data. We provide extensive analyses on the Cityscapes dataset including cross-evaluation with different analysis networks and present exemplary visual results.
Video-Text Pre-training with Learned Regions
Dec 02, 2021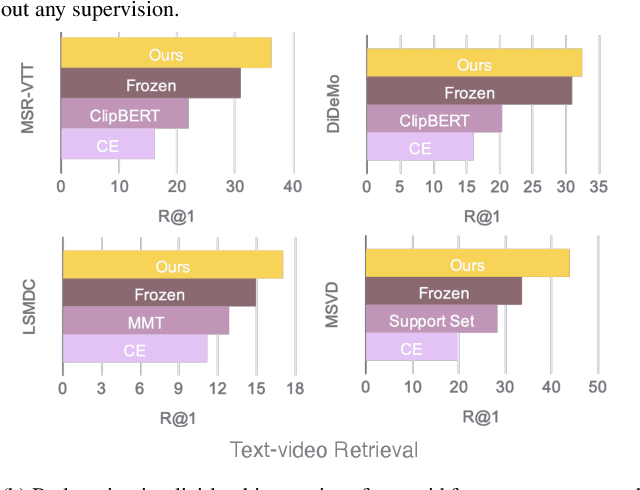
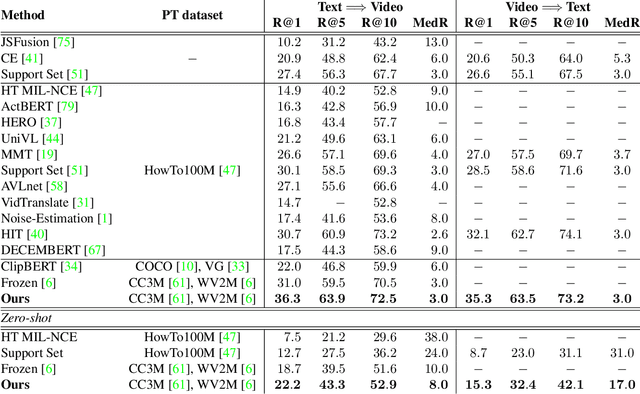
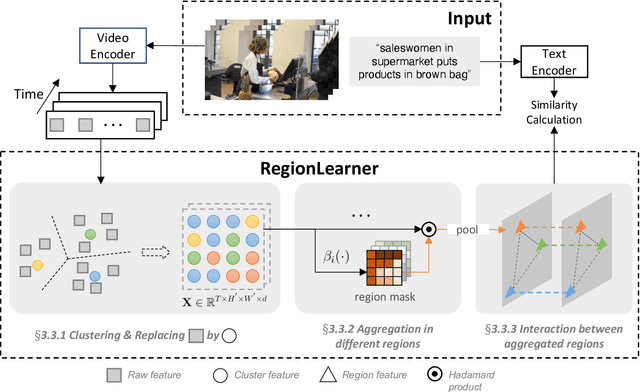
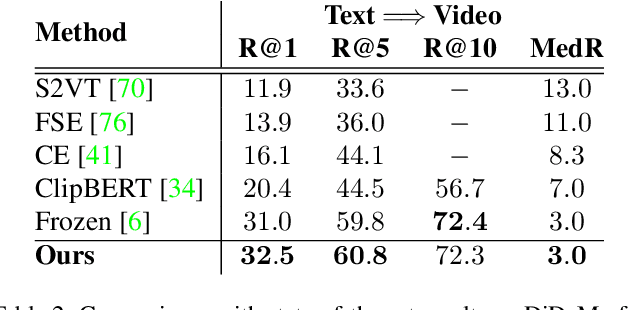
Video-Text pre-training aims at learning transferable representations from large-scale video-text pairs via aligning the semantics between visual and textual information. State-of-the-art approaches extract visual features from raw pixels in an end-to-end fashion. However, these methods operate at frame-level directly and thus overlook the spatio-temporal structure of objects in video, which yet has a strong synergy with nouns in textual descriptions. In this work, we propose a simple yet effective module for video-text representation learning, namely RegionLearner, which can take into account the structure of objects during pre-training on large-scale video-text pairs. Given a video, our module (1) first quantizes visual features into semantic clusters, then (2) generates learnable masks and uses them to aggregate the features belonging to the same semantic region, and finally (3) models the interactions between different aggregated regions. In contrast to using off-the-shelf object detectors, our proposed module does not require explicit supervision and is much more computationally efficient. We pre-train the proposed approach on the public WebVid2M and CC3M datasets. Extensive evaluations on four downstream video-text retrieval benchmarks clearly demonstrate the effectiveness of our RegionLearner. The code will be available at https://github.com/ruiyan1995/Region_Learner.