 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
How does AI play football? An analysis of RL and real-world football strategies
Nov 24, 2021
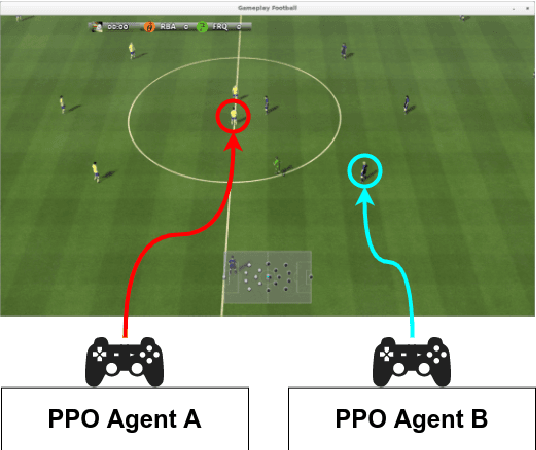

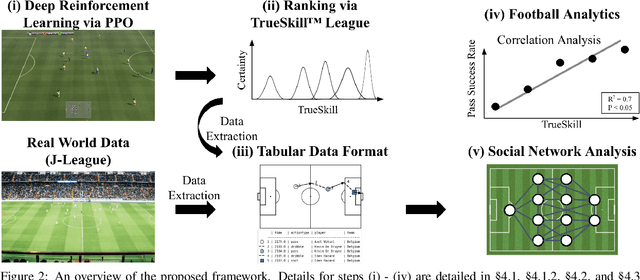
Recent advances in reinforcement learning (RL) have made it possible to develop sophisticated agents that excel in a wide range of applications. Simulations using such agents can provide valuable information in scenarios that are difficult to scientifically experiment in the real world. In this paper, we examine the play-style characteristics of football RL agents and uncover how strategies may develop during training. The learnt strategies are then compared with those of real football players. We explore what can be learnt from the use of simulated environments by using aggregated statistics and social network analysis (SNA). As a result, we found that (1) there are strong correlations between the competitiveness of an agent and various SNA metrics and (2) aspects of the RL agents play style become similar to real world footballers as the agent becomes more competitive. We discuss further advances that may be necessary to improve our understanding necessary to fully utilise RL for the analysis of football.
CLIP Meets Video Captioners: Attribute-Aware Representation Learning Promotes Accurate Captioning
Nov 30, 2021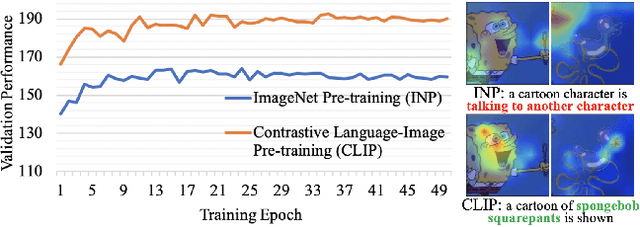
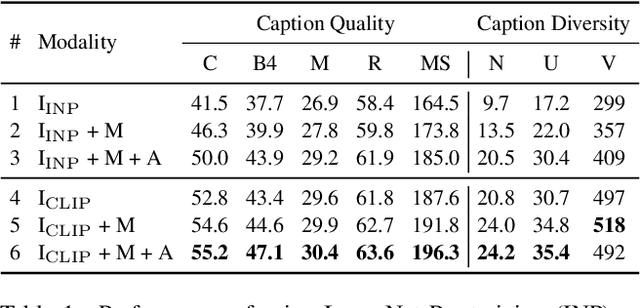
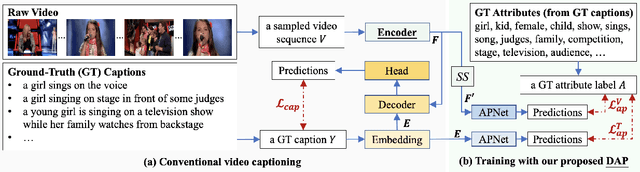

For video captioning, "pre-training and fine-tuning" has become a de facto paradigm, where ImageNet Pre-training (INP) is usually used to help encode the video content, and a task-oriented network is fine-tuned from scratch to cope with caption generation. Comparing INP with the recently proposed CLIP (Contrastive Language-Image Pre-training), this paper investigates the potential deficiencies of INP for video captioning and explores the key to generating accurate descriptions. Specifically, our empirical study on INP vs. CLIP shows that INP makes video caption models tricky to capture attributes' semantics and sensitive to irrelevant background information. By contrast, CLIP's significant boost in caption quality highlights the importance of attribute-aware representation learning. We are thus motivated to introduce Dual Attribute Prediction, an auxiliary task requiring a video caption model to learn the correspondence between video content and attributes and the co-occurrence relations between attributes. Extensive experiments on benchmark datasets demonstrate that our approach enables better learning of attribute-aware representations, bringing consistent improvements on models with different architectures and decoding algorithms.
A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
Nov 30, 2021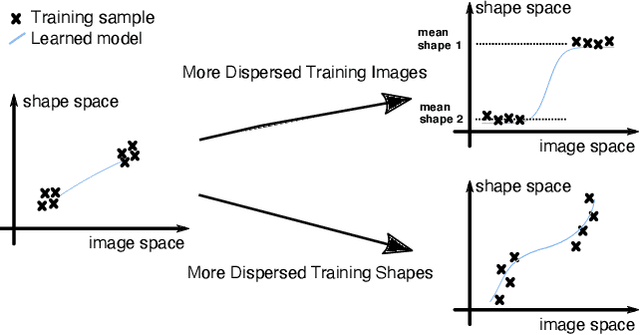
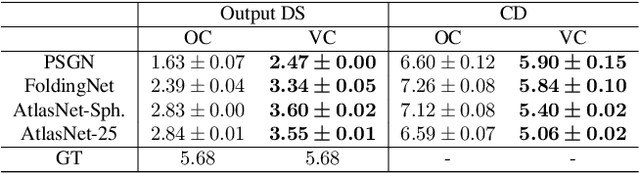
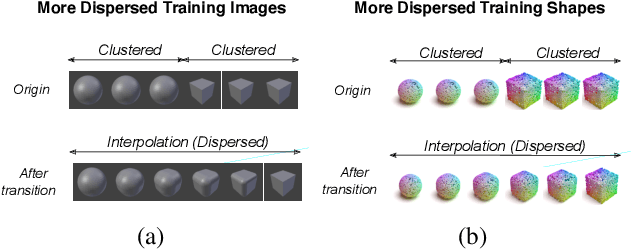
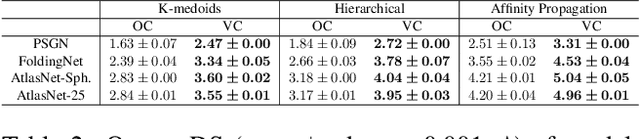
Neural networks (NN) for single-view 3D reconstruction (SVR) have gained in popularity. Recent work points out that for SVR, most cutting-edge NNs have limited performance on reconstructing unseen objects because they rely primarily on recognition (i.e., classification-based methods) rather than shape reconstruction. To understand this issue in depth, we provide a systematic study on when and why NNs prefer recognition to reconstruction and vice versa. Our finding shows that a leading factor in determining recognition versus reconstruction is how dispersed the training data is. Thus, we introduce the dispersion score, a new data-driven metric, to quantify this leading factor and study its effect on NNs. We hypothesize that NNs are biased toward recognition when training images are more dispersed and training shapes are less dispersed. Our hypothesis is supported and the dispersion score is proved effective through our experiments on synthetic and benchmark datasets. We show that the proposed metric is a principal way to analyze reconstruction quality and provides novel information in addition to the conventional reconstruction score.
M-FasterSeg: An Efficient Semantic Segmentation Network Based on Neural Architecture Search
Dec 15, 2021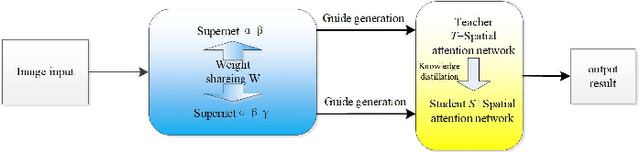
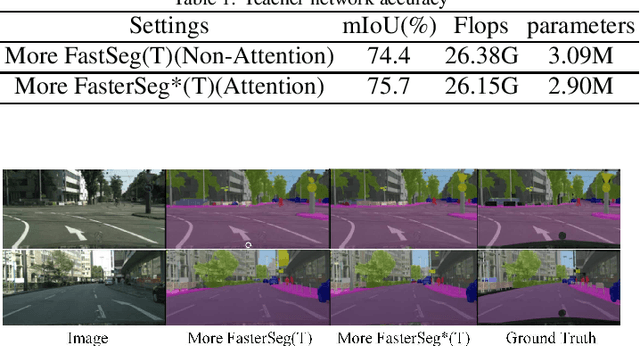
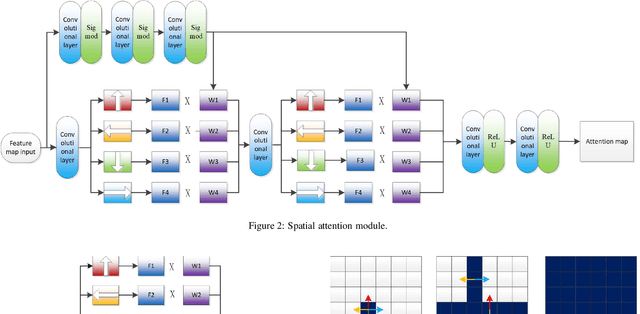
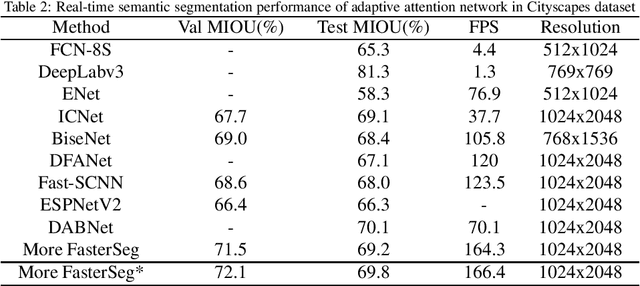
Image semantic segmentation technology is one of the key technologies for intelligent systems to understand natural scenes. As one of the important research directions in the field of visual intelligence, this technology has broad application scenarios in the fields of mobile robots, drones, smart driving, and smart security. However, in the actual application of mobile robots, problems such as inaccurate segmentation semantic label prediction and loss of edge information of segmented objects and background may occur. This paper proposes an improved structure of a semantic segmentation network based on a deep learning network that combines self-attention neural network and neural network architecture search methods. First, a neural network search method NAS (Neural Architecture Search) is used to find a semantic segmentation network with multiple resolution branches. In the search process, combine the self-attention network structure module to adjust the searched neural network structure, and then combine the semantic segmentation network searched by different branches to form a fast semantic segmentation network structure, and input the picture into the network structure to get the final forecast result. The experimental results on the Cityscapes dataset show that the accuracy of the algorithm is 69.8%, and the segmentation speed is 48/s. It achieves a good balance between real-time and accuracy, can optimize edge segmentation, and has a better performance in complex scenes. Good robustness is suitable for practical application.
FAIR Geovisualizations: Definitions, Challenges, and the Road Ahead
Nov 14, 2021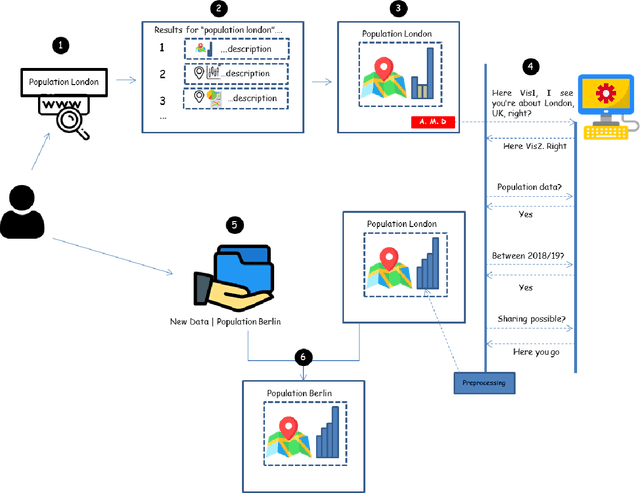
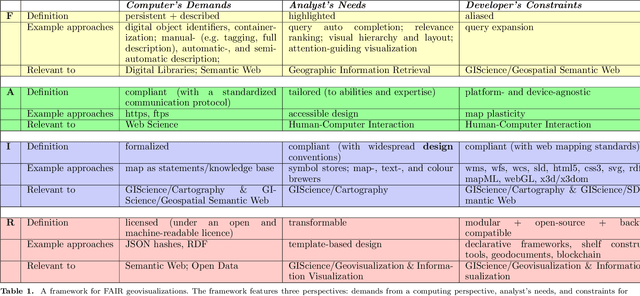
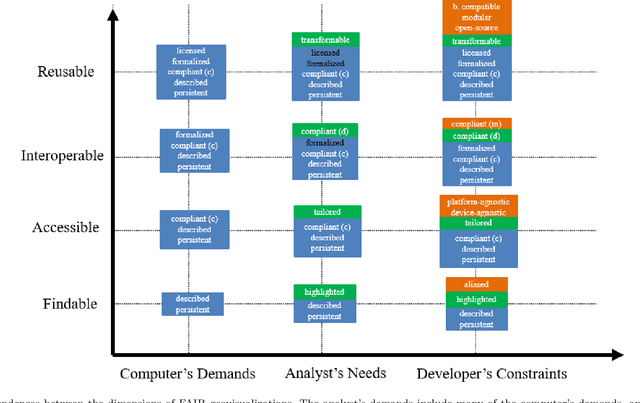
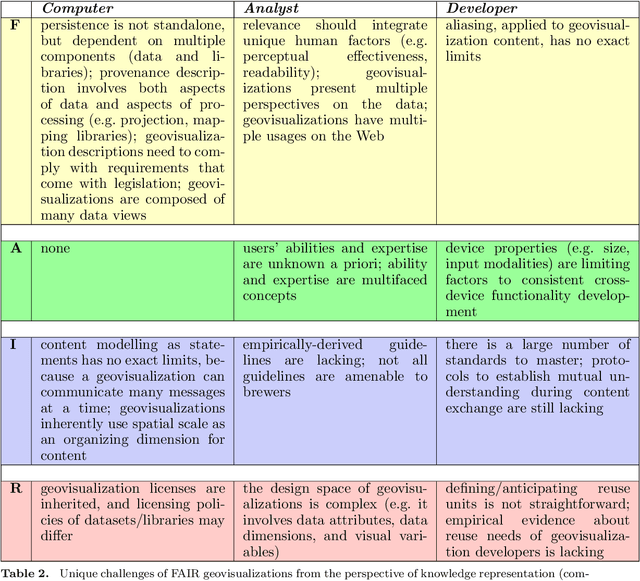
The availability of open data and of tools to create visualizations on top of these open datasets have led to an ever-growing amount of geovisualizations on the Web. There is thus an increasing need for techniques to make geovisualizations FAIR - Findable, Accessible, Interoperable, and Reusable. This article explores what it would mean for a geovisualization to be FAIR, presents relevant approaches to FAIR geovisualizations and lists open research questions on the road towards FAIR geovisualizations. The discussion is done using three complementary perspectives: the computer, which stores geovisualizations digitally; the analyst, who uses them for sensemaking; and the developer, who creates them. The framework for FAIR geovisualizations proposed, and the open questions identified are relevant to researchers working on findable, accessible, interoperable, and reusable online visualizations of geographic information.
A Dynamic Keypoints Selection Network for 6DoF Pose Estimation
Oct 24, 2021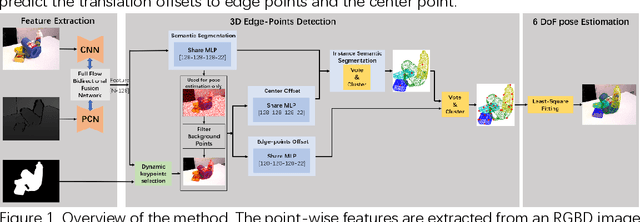
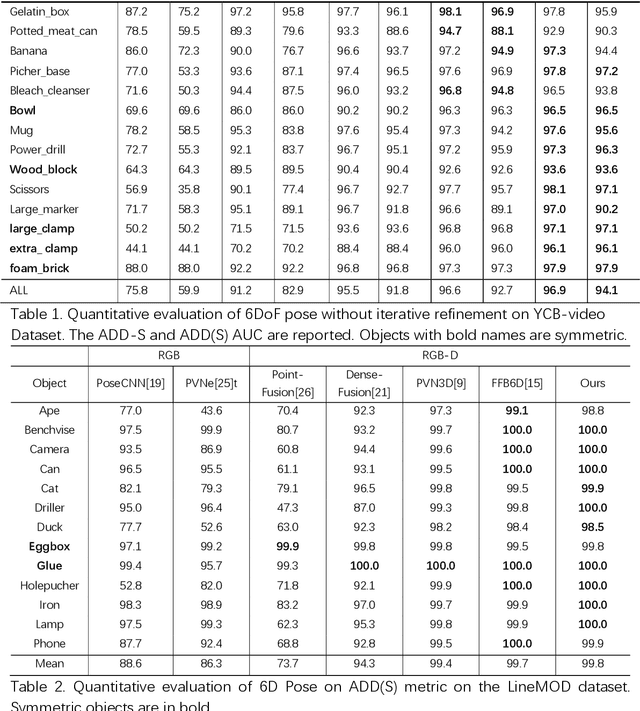


6 DoF poses estimation problem aims to estimate the rotation and translation parameters between two coordinates, such as object world coordinate and camera world coordinate. Although some advances are made with the help of deep learning, how to full use scene information is still a problem. Prior works tackle the problem by pixel-wise feature fusion but need to randomly selecte numerous points from images, which can not satisfy the demands of fast inference simultaneously and accurate pose estimation. In this work, we present a novel deep neural network based on dynamic keypoints selection designed for 6DoF pose estimation from a single RGBD image. Our network includes three parts, instance semantic segmentation, edge points detection and 6DoF pose estimation. Given an RGBD image, our network is trained to predict pixel category and the translation to edge points and center points. Then, a least-square fitting manner is applied to estimate the 6DoF pose parameters. Specifically, we propose a dynamic keypoints selection algorithm to choose keypoints from the foreground feature map. It allows us to leverage geometric and appearance information. During 6DoF pose estimation, we utilize the instance semantic segmentation result to filter out background points and only use foreground points to finish edge points detection and 6DoF pose estimation. Experiments on two commonly used 6DoF estimation benchmark datasets, YCB-Video and LineMoD, demonstrate that our method outperforms the state-of-the-art methods and achieves significant improvements over other same category methods time efficiency.
Knowledge-Rich Self-Supervised Entity Linking
Dec 15, 2021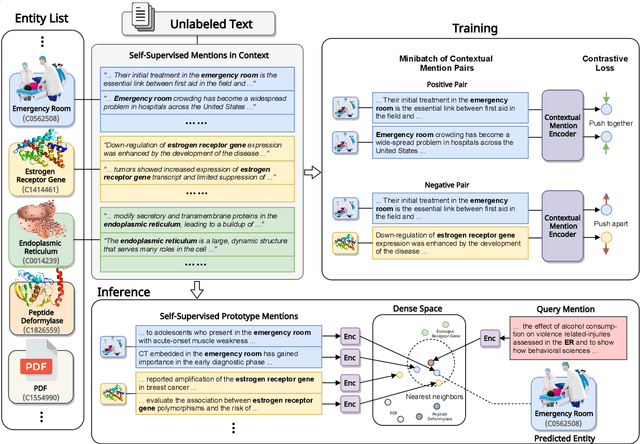
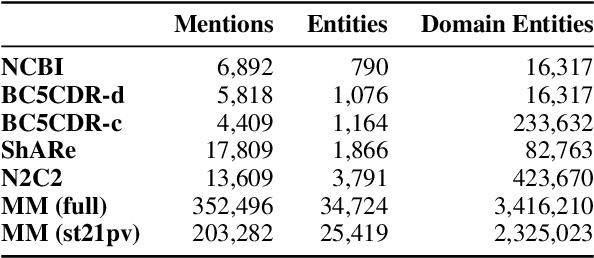
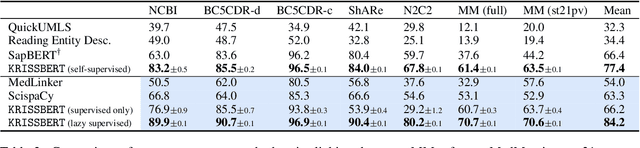
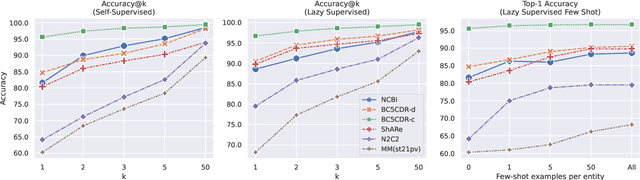
Entity linking faces significant challenges, such as prolific variations and prevalent ambiguities, especially in high-value domains with myriad entities. Standard classification approaches suffer from the annotation bottleneck and cannot effectively handle unseen entities. Zero-shot entity linking has emerged as a promising direction for generalizing to new entities, but it still requires example gold entity mentions during training and canonical descriptions for all entities, both of which are rarely available outside of Wikipedia. In this paper, we explore Knowledge-RIch Self-Supervision ($\tt KRISS$) for entity linking, by leveraging readily available domain knowledge. In training, it generates self-supervised mention examples on unlabeled text using a domain ontology and trains a contextual encoder using contrastive learning. For inference, it samples self-supervised mentions as prototypes for each entity and conducts linking by mapping the test mention to the most similar prototype. Our approach subsumes zero-shot and few-shot methods, and can easily incorporate entity descriptions and gold mention labels if available. Using biomedicine as a case study, we conducted extensive experiments on seven standard datasets spanning biomedical literature and clinical notes. Without using any labeled information, our method produces $\tt KRISSBERT$, a universal entity linker for four million UMLS entities, which attains new state of the art, outperforming prior self-supervised methods by as much as over 20 absolute points in accuracy.
A Role-Selected Sharing Network for Joint Machine-Human Chatting Handoff and Service Satisfaction Analysis
Sep 17, 2021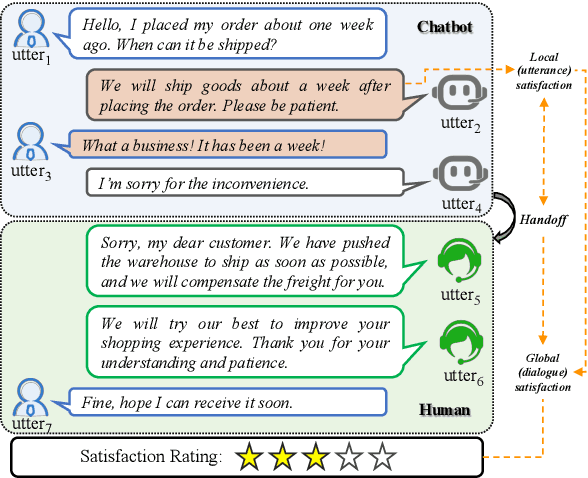
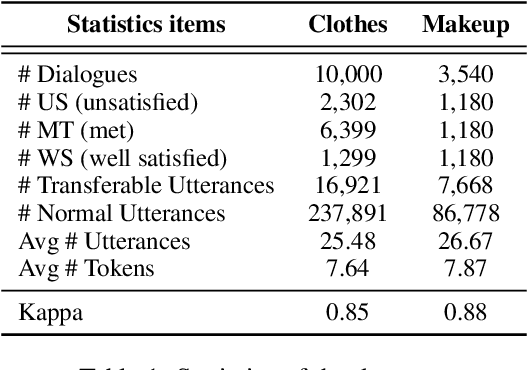
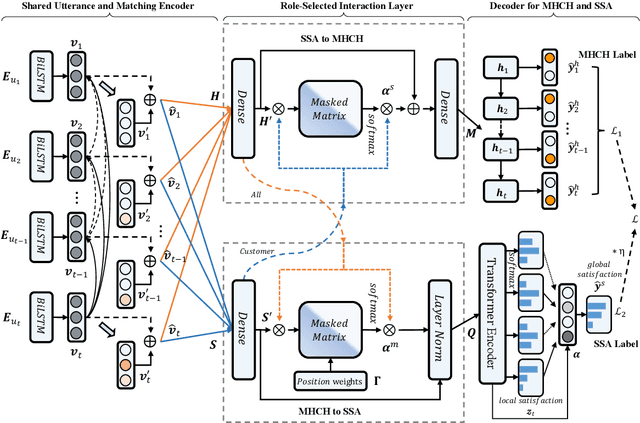
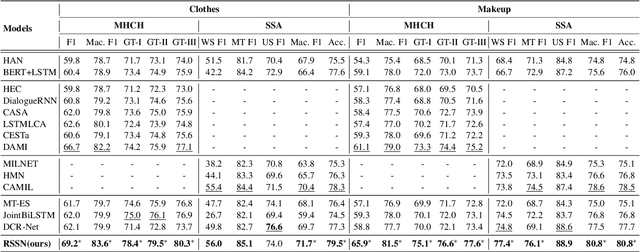
Chatbot is increasingly thriving in different domains, however, because of unexpected discourse complexity and training data sparseness, its potential distrust hatches vital apprehension. Recently, Machine-Human Chatting Handoff (MHCH), predicting chatbot failure and enabling human-algorithm collaboration to enhance chatbot quality, has attracted increasing attention from industry and academia. In this study, we propose a novel model, Role-Selected Sharing Network (RSSN), which integrates both dialogue satisfaction estimation and handoff prediction in one multi-task learning framework. Unlike prior efforts in dialog mining, by utilizing local user satisfaction as a bridge, global satisfaction detector and handoff predictor can effectively exchange critical information. Specifically, we decouple the relation and interaction between the two tasks by the role information after the shared encoder. Extensive experiments on two public datasets demonstrate the effectiveness of our model.
One-shot Voice Conversion For Style Transfer Based On Speaker Adaptation
Nov 24, 2021One-shot style transfer is a challenging task, since training on one utterance makes model extremely easy to over-fit to training data and causes low speaker similarity and lack of expressiveness. In this paper, we build on the recognition-synthesis framework and propose a one-shot voice conversion approach for style transfer based on speaker adaptation. First, a speaker normalization module is adopted to remove speaker-related information in bottleneck features extracted by ASR. Second, we adopt weight regularization in the adaptation process to prevent over-fitting caused by using only one utterance from target speaker as training data. Finally, to comprehensively decouple the speech factors, i.e., content, speaker, style, and transfer source style to the target, a prosody module is used to extract prosody representation. Experiments show that our approach is superior to the state-of-the-art one-shot VC systems in terms of style and speaker similarity; additionally, our approach also maintains good speech quality.
PACMAN: PAC-style bounds accounting for the Mismatch between Accuracy and Negative log-loss
Dec 10, 2021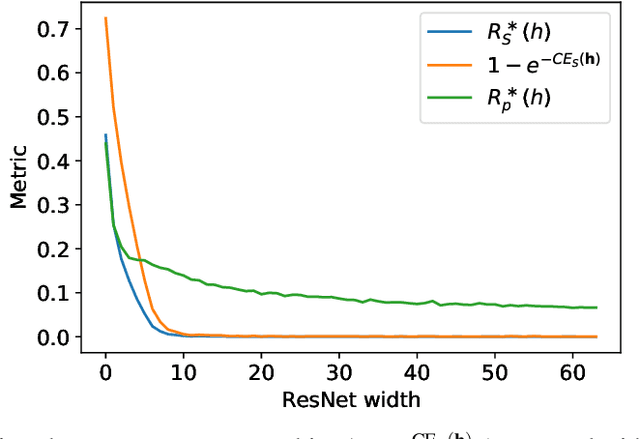
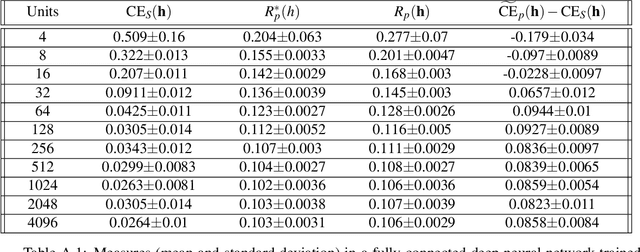
The ultimate performance of machine learning algorithms for classification tasks is usually measured in terms of the empirical error probability (or accuracy) based on a testing dataset. Whereas, these algorithms are optimized through the minimization of a typically different--more convenient--loss function based on a training set. For classification tasks, this loss function is often the negative log-loss that leads to the well-known cross-entropy risk which is typically better behaved (from a numerical perspective) than the error probability. Conventional studies on the generalization error do not usually take into account the underlying mismatch between losses at training and testing phases. In this work, we introduce an analysis based on point-wise PAC approach over the generalization gap considering the mismatch of testing based on the accuracy metric and training on the negative log-loss. We label this analysis PACMAN. Building on the fact that the mentioned mismatch can be written as a likelihood ratio, concentration inequalities can be used to provide some insights for the generalization problem in terms of some point-wise PAC bounds depending on some meaningful information-theoretic quantities. An analysis of the obtained bounds and a comparison with available results in the literature are also provided.