 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Intelligent Transportation Systems With The Use of External Infrastructure: A Literature Survey
Dec 15, 2021

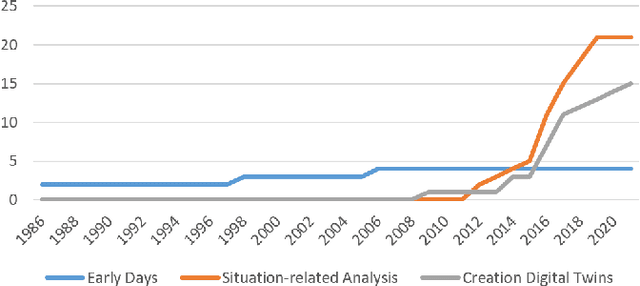
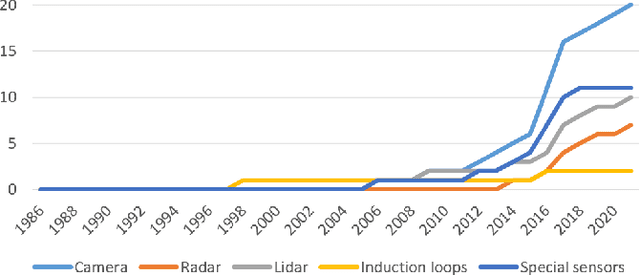
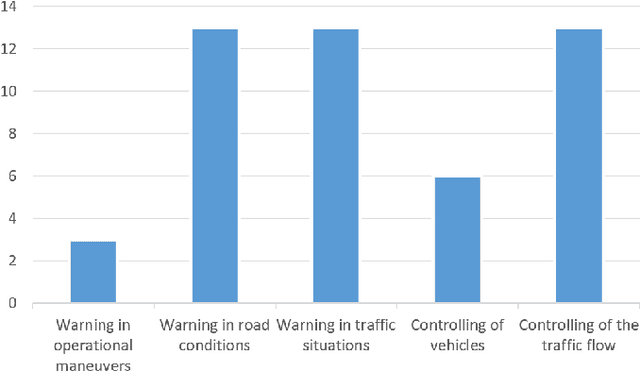
Increasing problems in the transportation segment are accidents, bad traffic flow and pollution. The Intelligent Transportation System with the use of external infrastructure (ITS) can tackle these problems. To the best of our knowledge, there exists no current systematic review of the existing solutions. To fill this knowledge gap, this paper provides an overview about existing ITS which use external infrastructure. Furthermore, this paper discovers the currently not adequately answered research questions. For this reason, we performed a literature review to documents, which describes existing ITS solutions since 2009 until today. We categorized the results according to his technology level and analyzed their properties. Thereby, we made the several ITS comparable and highlighted the past development as well as the current trends. According to the mentioned method, we analyzed more than 346 papers, which includes 40 test bed projects. In summary, the current ITS can deliver high accurate information about individuals in traffic situations in real-time. However, further research in ITS should focus on more reliable perception of the traffic with the use of modern sensors, plug and play mechanism as well as secure real-time distribution in decentralized manner for a high amount of data. With addressing these topics, the development of Intelligent Transportation Systems is in a correction direction for the comprehensive roll-out.
A Face Recognition System's Worst Morph Nightmare, Theoretically
Nov 30, 2021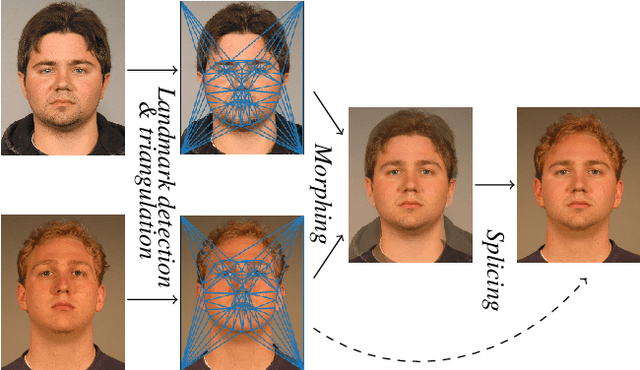
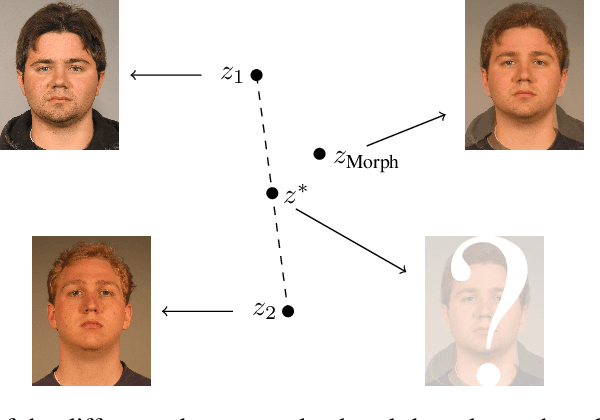
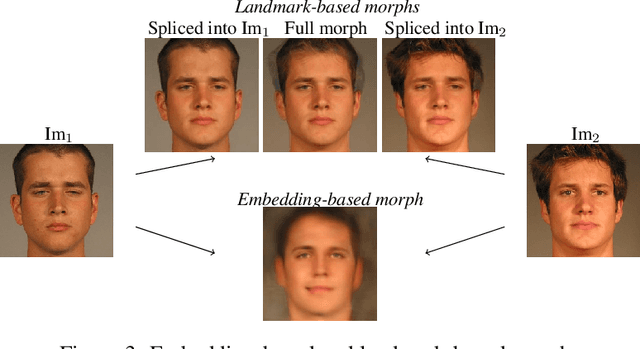
It has been shown that Face Recognition Systems (FRSs) are vulnerable to morphing attacks, but most research focusses on landmark-based morphs. A second method for generating morphs uses Generative Adversarial Networks, which results in convincingly real facial images that can be almost as challenging for FRSs as landmark-based attacks. We propose a method to create a third, different type of morph, that has the advantage of being easier to train. We introduce the theoretical concept of \textit{worst-case morphs}, which are those morphs that are most challenging for a fixed FRS. For a set of images and corresponding embeddings in an FRS's latent space, we generate images that approximate these worst-case morphs using a mapping from embedding space back to image space. While the resulting images are not yet as challenging as other morphs, they can provide valuable information in future research on Morphing Attack Detection (MAD) methods and on weaknesses of FRSs. Methods for MAD need to be validated on more varied morph databases. Our proposed method contributes to achieving such variation.
Task-Oriented Multi-User Semantic Communications
Dec 19, 2021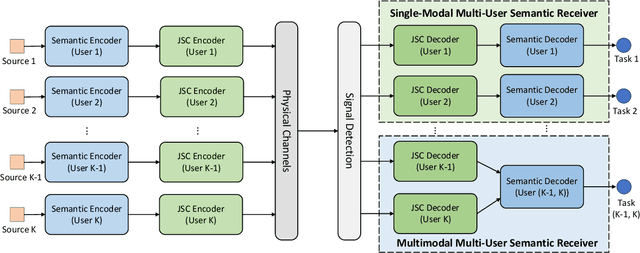


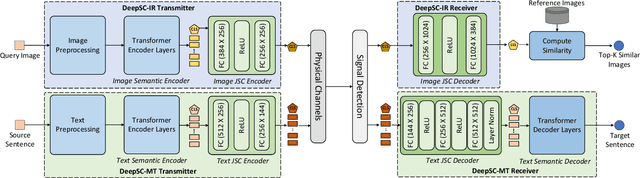
While semantic communications have shown the potential in the case of single-modal single-users, its applications to the multi-user scenario remain limited. In this paper, we investigate deep learning (DL) based multi-user semantic communication systems for transmitting single-modal data and multimodal data, respectively. We will adopt three intelligent tasks, including, image retrieval, machine translation, and visual question answering (VQA) as the transmission goal of semantic communication systems. We will then propose a Transformer based unique framework to unify the structure of transmitters for different tasks. For the single-modal multi-user system, we will propose two Transformer based models, named, DeepSC-IR and DeepSC-MT, to perform image retrieval and machine translation, respectively. In this case, DeepSC-IR is trained to optimize the distance in embedding space between images and DeepSC-MT is trained to minimize the semantic errors by recovering the semantic meaning of sentences. For the multimodal multi-user system, we develop a Transformer enabled model, named, DeepSC-VQA, for the VQA task by extracting text-image information at the transmitters and fusing it at the receiver. In particular, a novel layer-wise Transformer is designed to help fuse multimodal data by adding connection between each of the encoder and decoder layers. Numerical results will show that the proposed models are superior to traditional communications in terms of the robustness to channels, computational complexity, transmission delay, and the task-execution performance at various task-specific metrics.
Feature-Attending Recurrent Modules for Generalization in Reinforcement Learning
Dec 15, 2021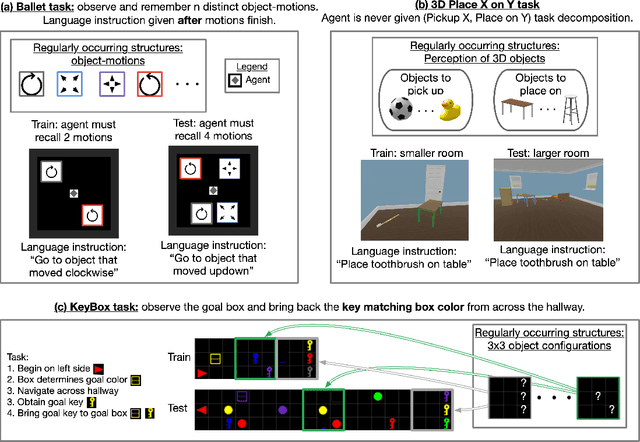
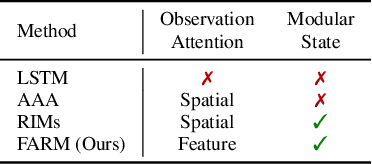
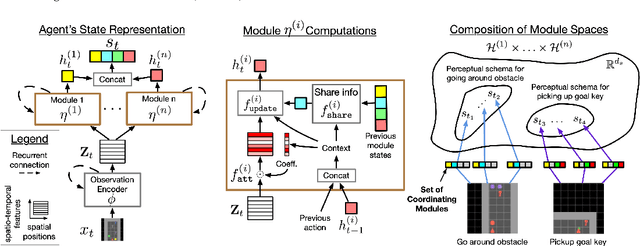
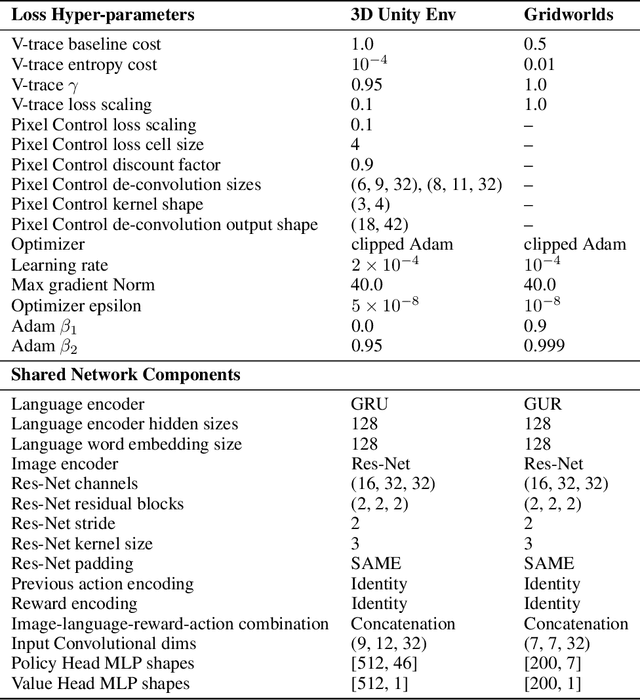
Deep reinforcement learning (Deep RL) has recently seen significant progress in developing algorithms for generalization. However, most algorithms target a single type of generalization setting. In this work, we study generalization across three disparate task structures: (a) tasks composed of spatial and temporal compositions of regularly occurring object motions; (b) tasks composed of active perception of and navigation towards regularly occurring 3D objects; and (c) tasks composed of remembering goal-information over sequences of regularly occurring object-configurations. These diverse task structures all share an underlying idea of compositionality: task completion always involves combining recurring segments of task-oriented perception and behavior. We hypothesize that an agent can generalize within a task structure if it can discover representations that capture these recurring task-segments. For our tasks, this corresponds to representations for recognizing individual object motions, for navigation towards 3D objects, and for navigating through object-configurations. Taking inspiration from cognitive science, we term representations for recurring segments of an agent's experience, "perceptual schemas". We propose Feature Attending Recurrent Modules (FARM), which learns a state representation where perceptual schemas are distributed across multiple, relatively small recurrent modules. We compare FARM to recurrent architectures that leverage spatial attention, which reduces observation features to a weighted average over spatial positions. Our experiments indicate that our feature-attention mechanism better enables FARM to generalize across the diverse object-centric domains we study.
Dual-Neighborhood Deep Fusion Network for Point Cloud Analysis
Aug 20, 2021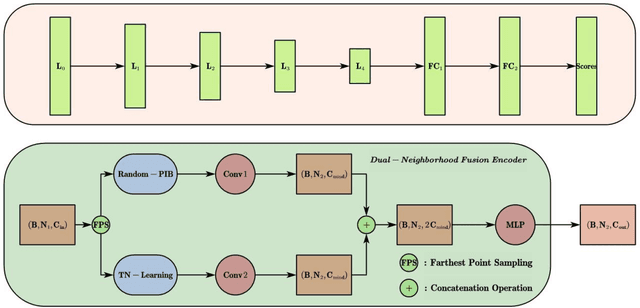
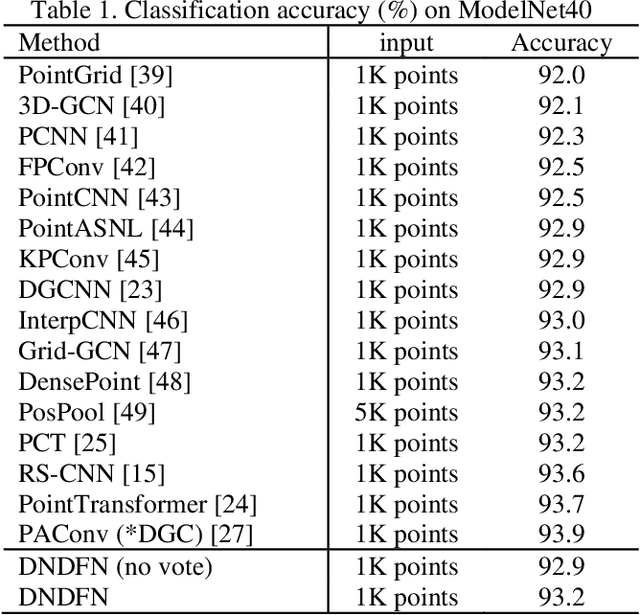
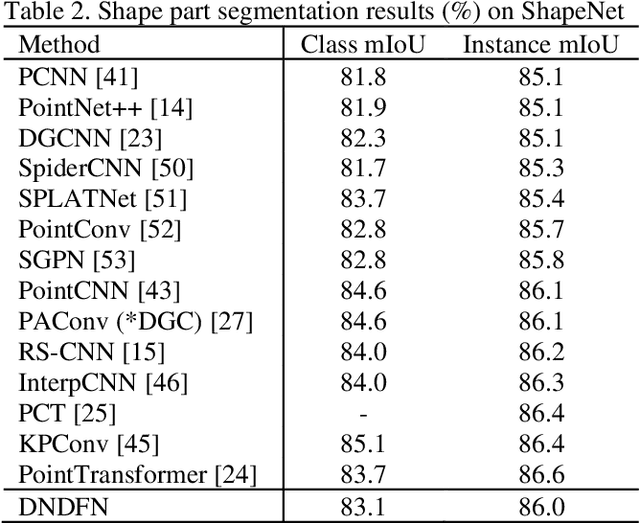

Convolutional neural network has made remarkable achievements in classification of idealized point cloud, however, non-idealized point cloud classification is still a challenging task. In this paper, DNDFN, namely, Dual-Neighborhood Deep Fusion Network, is proposed to deal with this problem. DNDFN has two key points. One is combination of local neighborhood and global neigh-borhood. nearest neighbor (kNN) or ball query can capture the local neighborhood but ignores long-distance dependencies. A trainable neighborhood learning meth-od called TN-Learning is proposed, which can capture the global neighborhood. TN-Learning is combined with them to obtain richer neighborhood information. The other is information transfer convolution (IT-Conv) which can learn the structural information between two points and transfer features through it. Extensive exper-iments on idealized and non-idealized benchmarks across four tasks verify DNDFN achieves the state of the arts.
Controllable Neural Dialogue Summarization with Personal Named Entity Planning
Sep 27, 2021
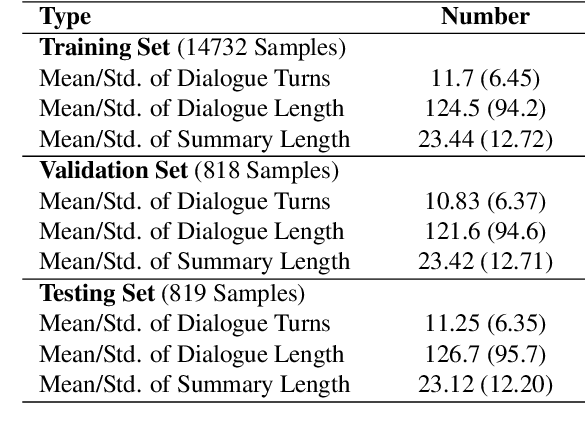

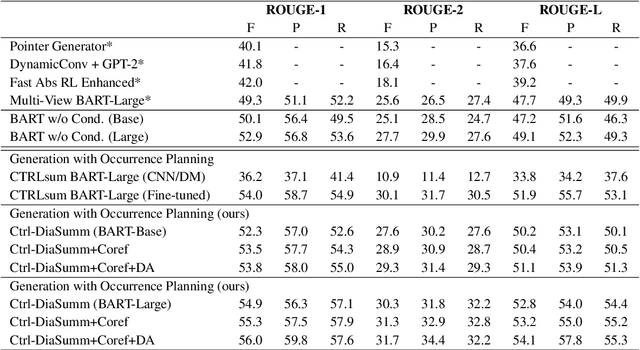
In this paper, we propose a controllable neural generation framework that can flexibly guide dialogue summarization with personal named entity planning. The conditional sequences are modulated to decide what types of information or what perspective to focus on when forming summaries to tackle the under-constrained problem in summarization tasks. This framework supports two types of use cases: (1) Comprehensive Perspective, which is a general-purpose case with no user-preference specified, considering summary points from all conversational interlocutors and all mentioned persons; (2) Focus Perspective, positioning the summary based on a user-specified personal named entity, which could be one of the interlocutors or one of the persons mentioned in the conversation. During training, we exploit occurrence planning of personal named entities and coreference information to improve temporal coherence and to minimize hallucination in neural generation. Experimental results show that our proposed framework generates fluent and factually consistent summaries under various planning controls using both objective metrics and human evaluations.
MECT: Multi-Metadata Embedding based Cross-Transformer for Chinese Named Entity Recognition
Jul 12, 2021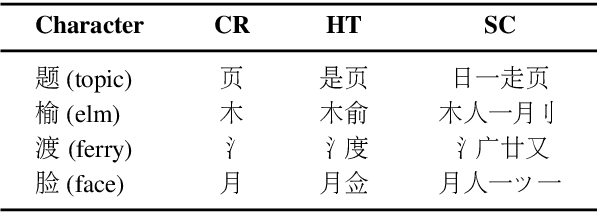
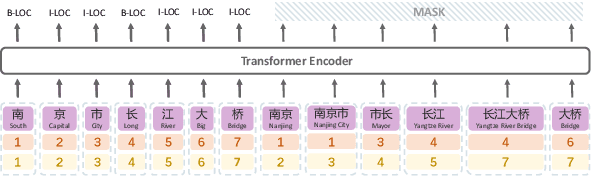

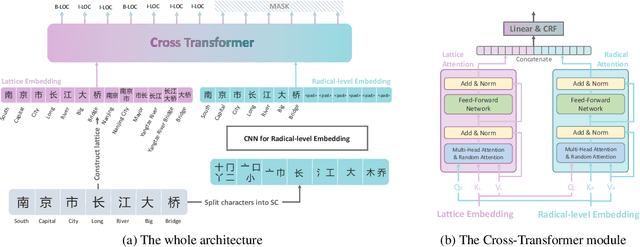
Recently, word enhancement has become very popular for Chinese Named Entity Recognition (NER), reducing segmentation errors and increasing the semantic and boundary information of Chinese words. However, these methods tend to ignore the information of the Chinese character structure after integrating the lexical information. Chinese characters have evolved from pictographs since ancient times, and their structure often reflects more information about the characters. This paper presents a novel Multi-metadata Embedding based Cross-Transformer (MECT) to improve the performance of Chinese NER by fusing the structural information of Chinese characters. Specifically, we use multi-metadata embedding in a two-stream Transformer to integrate Chinese character features with the radical-level embedding. With the structural characteristics of Chinese characters, MECT can better capture the semantic information of Chinese characters for NER. The experimental results obtained on several well-known benchmarking datasets demonstrate the merits and superiority of the proposed MECT method.\footnote{The source code of the proposed method is publicly available at https://github.com/CoderMusou/MECT4CNER.
Multi-task manifold learning for small sample size datasets
Nov 24, 2021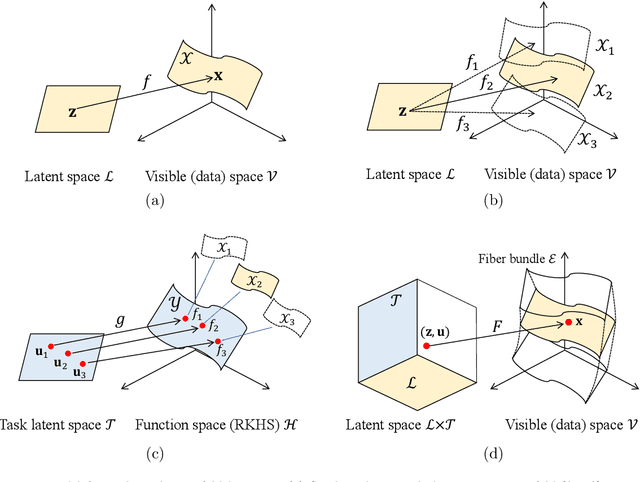
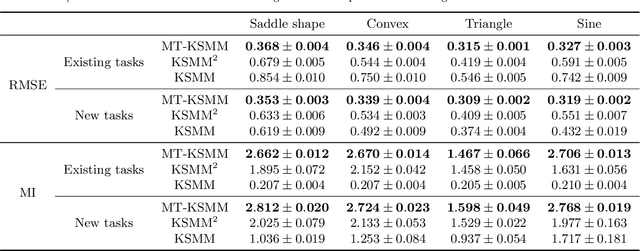
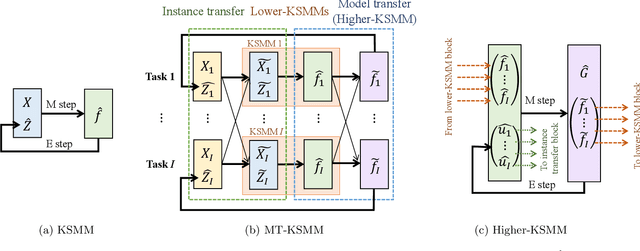

In this study, we develop a method for multi-task manifold learning. The method aims to improve the performance of manifold learning for multiple tasks, particularly when each task has a small number of samples. Furthermore, the method also aims to generate new samples for new tasks, in addition to new samples for existing tasks. In the proposed method, we use two different types of information transfer: instance transfer and model transfer. For instance transfer, datasets are merged among similar tasks, whereas for model transfer, the manifold models are averaged among similar tasks. For this purpose, the proposed method consists of a set of generative manifold models corresponding to the tasks, which are integrated into a general model of a fiber bundle. We applied the proposed method to artificial datasets and face image sets, and the results showed that the method was able to estimate the manifolds, even for a tiny number of samples.
One to Transfer All: A Universal Transfer Framework for Vision Foundation Model with Few Data
Nov 24, 2021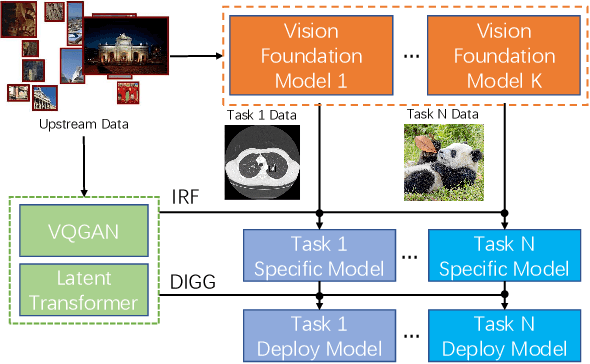
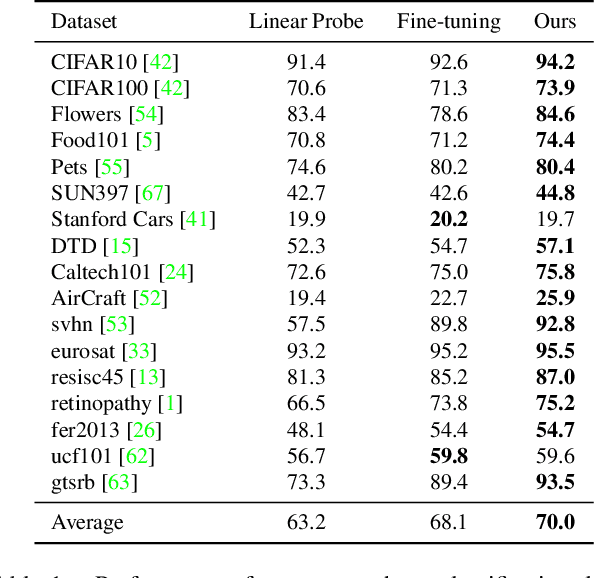
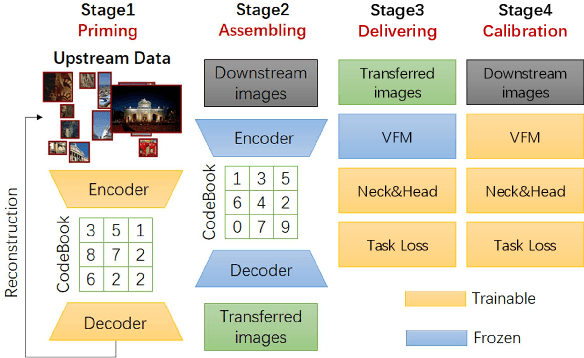

The foundation model is not the last chapter of the model production pipeline. Transferring with few data in a general way to thousands of downstream tasks is becoming a trend of the foundation model's application. In this paper, we proposed a universal transfer framework: One to Transfer All (OTA) to transfer any Vision Foundation Model (VFM) to any downstream tasks with few downstream data. We first transfer a VFM to a task-specific model by Image Re-representation Fine-tuning (IRF) then distilling knowledge from a task-specific model to a deployed model with data produced by Downstream Image-Guided Generation (DIGG). OTA has no dependency on upstream data, VFM, and downstream tasks when transferring. It also provides a way for VFM researchers to release their upstream information for better transferring but not leaking data due to privacy requirements. Massive experiments validate the effectiveness and superiority of our methods in few data setting. Our code will be released.
Information processing constraints in travel behaviour modelling: A generative learning approach
Jul 16, 2019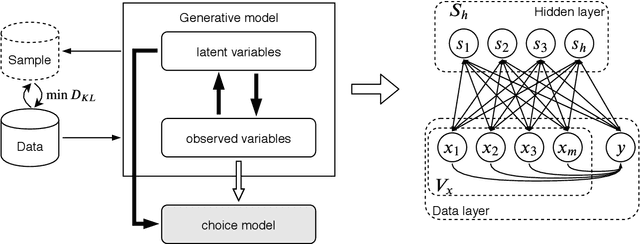
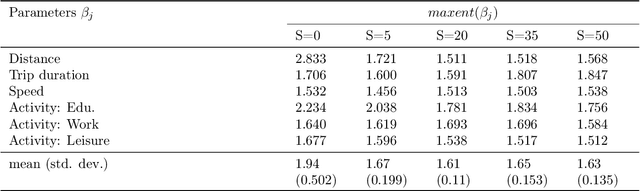
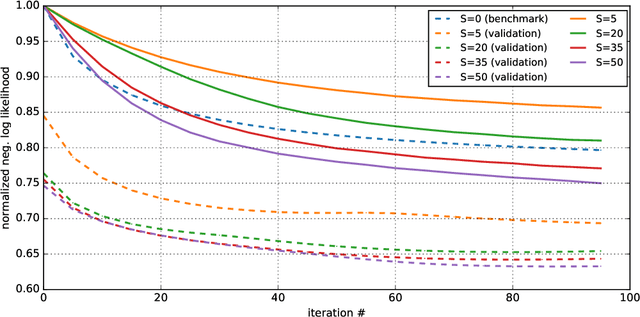
Travel decisions tend to exhibit sensitivity to uncertainty and information processing constraints. These behavioural conditions can be characterized by a generative learning process. We propose a data-driven generative model version of rational inattention theory to emulate these behavioural representations. We outline the methodology of the generative model and the associated learning process as well as provide an intuitive explanation of how this process captures the value of prior information in the choice utility specification. We demonstrate the effects of information heterogeneity on a travel choice, analyze the econometric interpretation, and explore the properties of our generative model. Our findings indicate a strong correlation with rational inattention behaviour theory, which suggest that individuals may ignore certain exogenous variables and rely on prior information for evaluating decisions under uncertainty. Finally, the principles demonstrated in this study can be formulated as a generalized entropy and utility based multinomial logit model.