 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Effects of Data Distortion on Model Analysis and Training
Oct 26, 2021


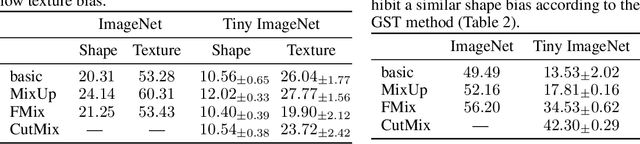
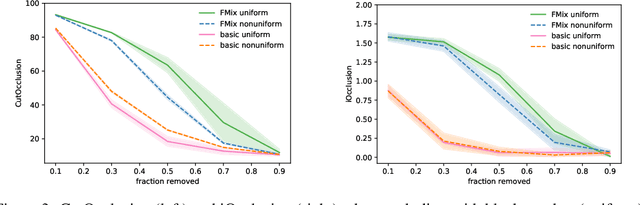
Data modification can introduce artificial information. It is often assumed that the resulting artefacts are detrimental to training, whilst being negligible when analysing models. We investigate these assumptions and conclude that in some cases they are unfounded and lead to incorrect results. Specifically, we show current shape bias identification methods and occlusion robustness measures are biased and propose a fairer alternative for the latter. Subsequently, through a series of experiments we seek to correct and strengthen the community's perception of how distorting data affects learning. Based on our empirical results we argue that the impact of the artefacts must be understood and exploited rather than eliminated.
Selective Differential Privacy for Language Modeling
Aug 30, 2021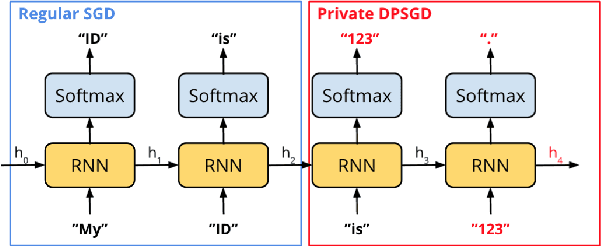

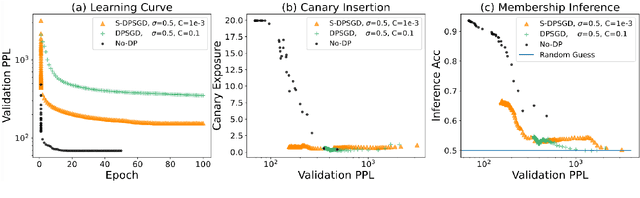

With the increasing adoption of language models in applications involving sensitive data, it has become crucial to protect these models from leaking private information. Previous work has attempted to tackle this challenge by training RNN-based language models with differential privacy guarantees. However, applying classical differential privacy to language models leads to poor model performance as the underlying privacy notion is over-pessimistic and provides undifferentiated protection for all tokens of the data. Given that the private information in natural language is sparse (for example, the bulk of an email might not carry personally identifiable information), we propose a new privacy notion, selective differential privacy, to provide rigorous privacy guarantees on the sensitive portion of the data to improve model utility. To realize such a new notion, we develop a corresponding privacy mechanism, Selective-DPSGD, for RNN-based language models. Besides language modeling, we also apply the method to a more concrete application -- dialog systems. Experiments on both language modeling and dialog system building show that the proposed privacy-preserving mechanism achieves better utilities while remaining safe under various privacy attacks compared to the baselines. The data, code and models are available at https://github.com/wyshi/lm_privacy.
Temporal Feature Warping for Video Shadow Detection
Jul 29, 2021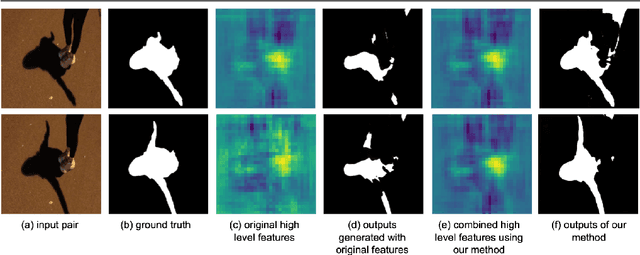
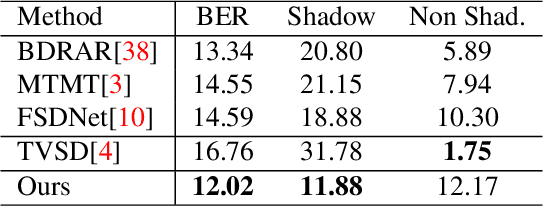
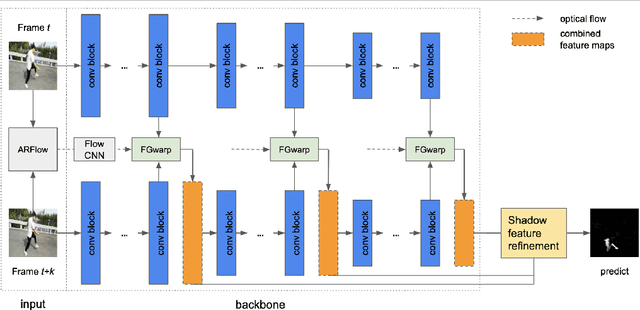
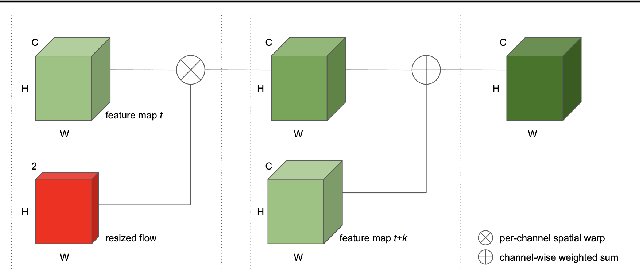
While single image shadow detection has been improving rapidly in recent years, video shadow detection remains a challenging task due to data scarcity and the difficulty in modelling temporal consistency. The current video shadow detection method achieves this goal via co-attention, which mostly exploits information that is temporally coherent but is not robust in detecting moving shadows and small shadow regions. In this paper, we propose a simple but powerful method to better aggregate information temporally. We use an optical flow based warping module to align and then combine features between frames. We apply this warping module across multiple deep-network layers to retrieve information from neighboring frames including both local details and high-level semantic information. We train and test our framework on the ViSha dataset. Experimental results show that our model outperforms the state-of-the-art video shadow detection method by 28%, reducing BER from 16.7 to 12.0.
Unsupervised Domain-Specific Deblurring using Scale-Specific Attention
Dec 12, 2021
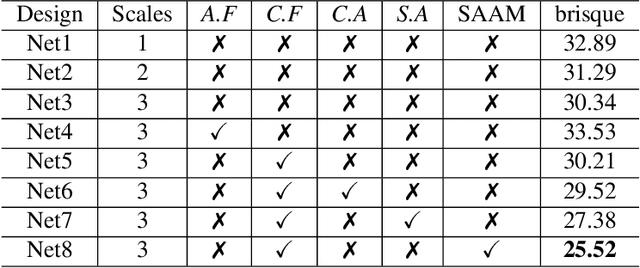
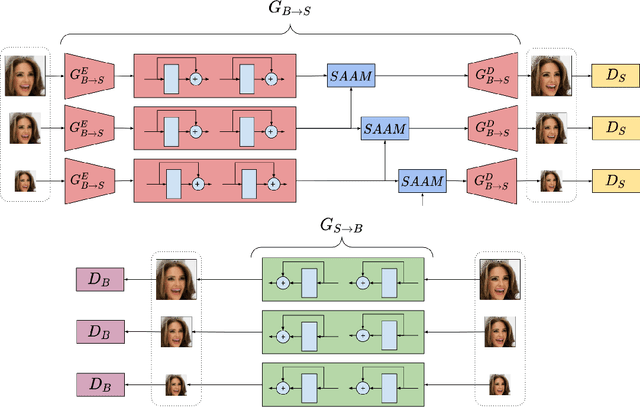
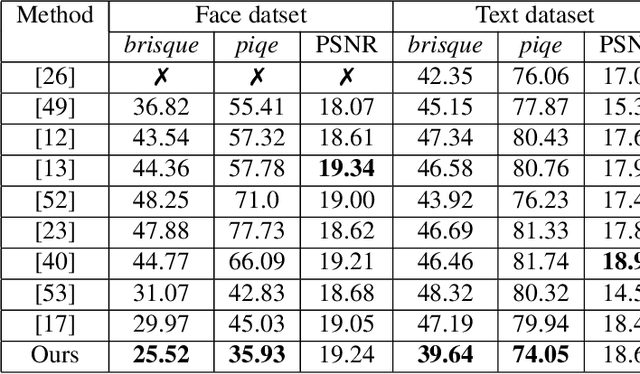
In the literature, coarse-to-fine or scale-recurrent approach i.e. progressively restoring a clean image from its low-resolution versions has been successfully employed for single image deblurring. However, a major disadvantage of existing methods is the need for paired data; i.e. sharpblur image pairs of the same scene, which is a complicated and cumbersome acquisition procedure. Additionally, due to strong supervision on loss functions, pre-trained models of such networks are strongly biased towards the blur experienced during training and tend to give sub-optimal performance when confronted by new blur kernels during inference time. To address the above issues, we propose unsupervised domain-specific deblurring using a scale-adaptive attention module (SAAM). Our network does not require supervised pairs for training, and the deblurring mechanism is primarily guided by adversarial loss, thus making our network suitable for a distribution of blur functions. Given a blurred input image, different resolutions of the same image are used in our model during training and SAAM allows for effective flow of information across the resolutions. For network training at a specific scale, SAAM attends to lower scale features as a function of the current scale. Different ablation studies show that our coarse-to-fine mechanism outperforms end-to-end unsupervised models and SAAM is able to attend better compared to attention models used in literature. Qualitative and quantitative comparisons (on no-reference metrics) show that our method outperforms prior unsupervised methods.
Controversy Detection: a Text and Graph Neural Network Based Approach
Dec 03, 2021
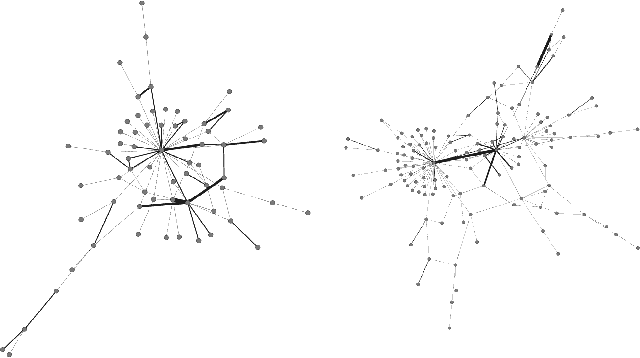
Controversial content refers to any content that attracts both positive and negative feedback. Its automatic identification, especially on social media, is a challenging task as it should be done on a large number of continuously evolving posts, covering a large variety of topics. Most of the existing approaches rely on the graph structure of a topic-discussion and/or the content of messages. This paper proposes a controversy detection approach based on both graph structure of a discussion and text features. Our proposed approach relies on Graph Neural Network (gnn) to encode the graph representation (including its texts) in an embedding vector before performing a graph classification task. The latter will classify the post as controversial or not. Two controversy detection strategies are proposed. The first one is based on a hierarchical graph representation learning. Graph user nodes are embedded hierarchically and iteratively to compute the whole graph embedding vector. The second one is based on the attention mechanism, which allows each user node to give more or less importance to its neighbors when computing node embeddings. We conduct experiments to evaluate our approach using different real-world datasets. Conducted experiments show the positive impact of combining textual features and structural information in terms of performance.
LIF-Seg: LiDAR and Camera Image Fusion for 3D LiDAR Semantic Segmentation
Aug 17, 2021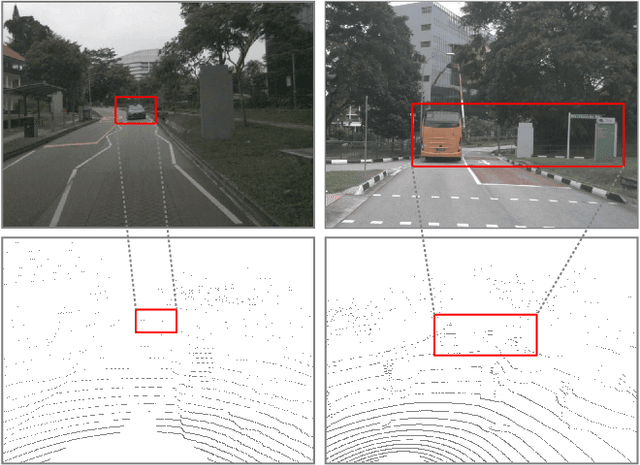

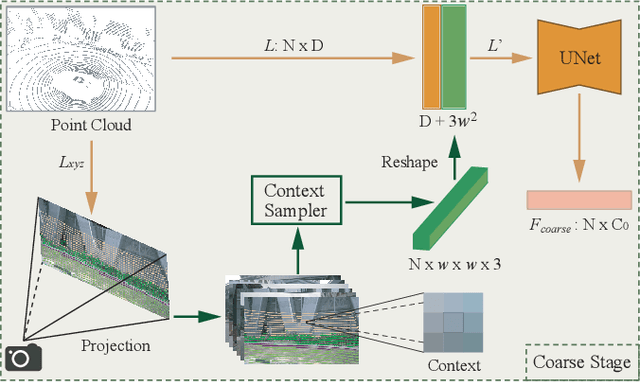
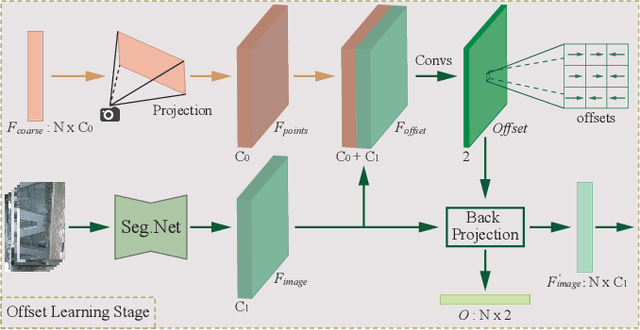
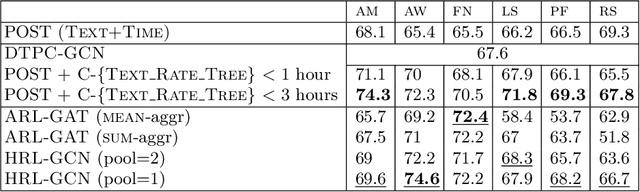
Camera and 3D LiDAR sensors have become indispensable devices in modern autonomous driving vehicles, where the camera provides the fine-grained texture, color information in 2D space and LiDAR captures more precise and farther-away distance measurements of the surrounding environments. The complementary information from these two sensors makes the two-modality fusion be a desired option. However, two major issues of the fusion between camera and LiDAR hinder its performance, \ie, how to effectively fuse these two modalities and how to precisely align them (suffering from the weak spatiotemporal synchronization problem). In this paper, we propose a coarse-to-fine LiDAR and camera fusion-based network (termed as LIF-Seg) for LiDAR segmentation. For the first issue, unlike these previous works fusing the point cloud and image information in a one-to-one manner, the proposed method fully utilizes the contextual information of images and introduces a simple but effective early-fusion strategy. Second, due to the weak spatiotemporal synchronization problem, an offset rectification approach is designed to align these two-modality features. The cooperation of these two components leads to the success of the effective camera-LiDAR fusion. Experimental results on the nuScenes dataset show the superiority of the proposed LIF-Seg over existing methods with a large margin. Ablation studies and analyses demonstrate that our proposed LIF-Seg can effectively tackle the weak spatiotemporal synchronization problem.
MELONS: generating melody with long-term structure using transformers and structure graph
Nov 03, 2021

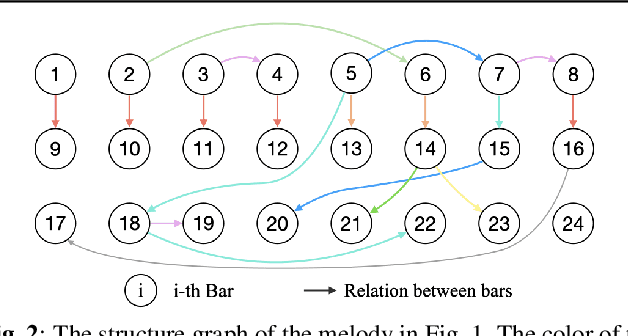
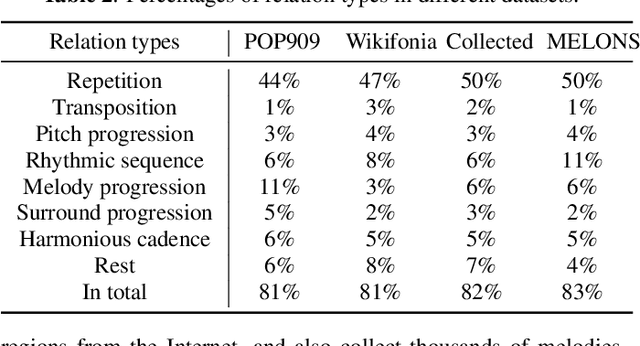
The creation of long melody sequences requires effective expression of coherent musical structure. However, there is no clear representation of musical structure. Recent works on music generation have suggested various approaches to deal with the structural information of music, but generating a full-song melody with clear long-term structure remains a challenge. In this paper, we propose MELONS, a melody generation framework based on a graph representation of music structure which consists of eight types of bar-level relations. MELONS adopts a multi-step generation method with transformer-based networks by factoring melody generation into two sub-problems: structure generation and structure conditional melody generation. Experimental results show that MELONS can produce structured melodies with high quality and rich contents.
Auxiliary Learning for Self-Supervised Video Representation via Similarity-based Knowledge Distillation
Dec 07, 2021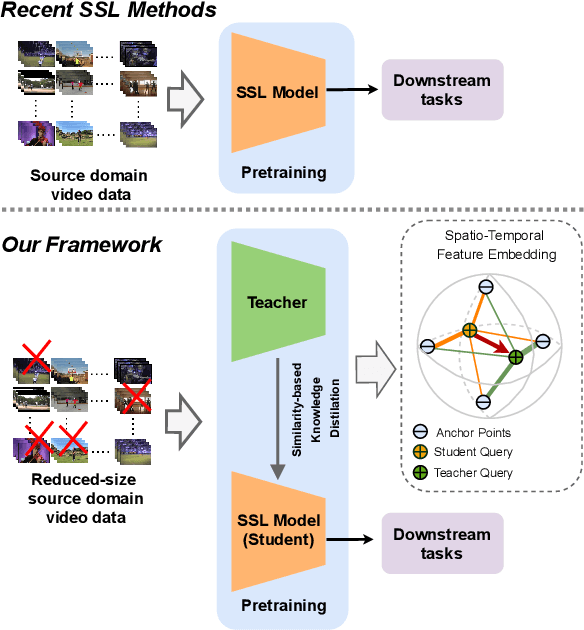
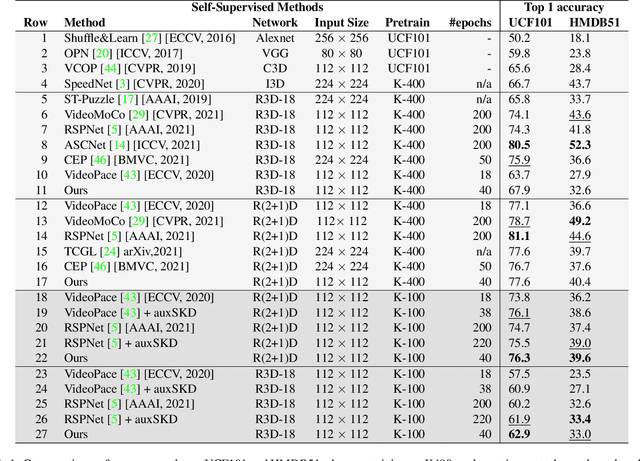
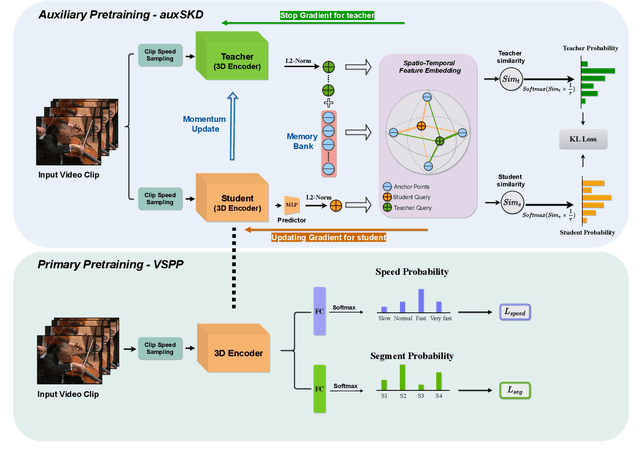
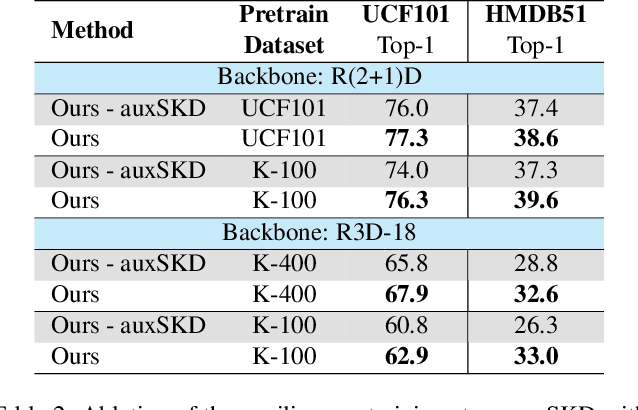
Despite the outstanding success of self-supervised pretraining methods for video representation learning, they generalise poorly when the unlabeled dataset for pretraining is small or the domain difference between unlabelled data in source task (pretraining) and labeled data in target task (finetuning) is significant. To mitigate these issues, we propose a novel approach to complement self-supervised pretraining via an auxiliary pretraining phase, based on knowledge similarity distillation, auxSKD, for better generalisation with a significantly smaller amount of video data, e.g. Kinetics-100 rather than Kinetics-400. Our method deploys a teacher network that iteratively distils its knowledge to the student model by capturing the similarity information between segments of unlabelled video data. The student model then solves a pretext task by exploiting this prior knowledge. We also introduce a novel pretext task, Video Segment Pace Prediction or VSPP, which requires our model to predict the playback speed of a randomly selected segment of the input video to provide more reliable self-supervised representations. Our experimental results show superior results to the state of the art on both UCF101 and HMDB51 datasets when pretraining on K100. Additionally, we show that our auxiliary pertaining, auxSKD, when added as an extra pretraining phase to recent state of the art self-supervised methods (e.g. VideoPace and RSPNet), improves their results on UCF101 and HMDB51. Our code will be released soon.
DILF-EN framework for Class-Incremental Learning
Dec 23, 2021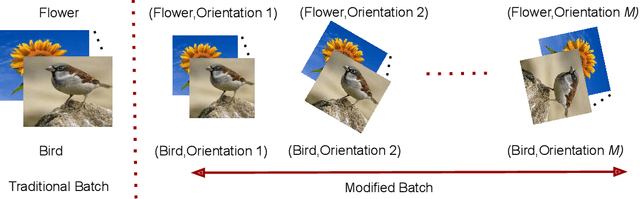
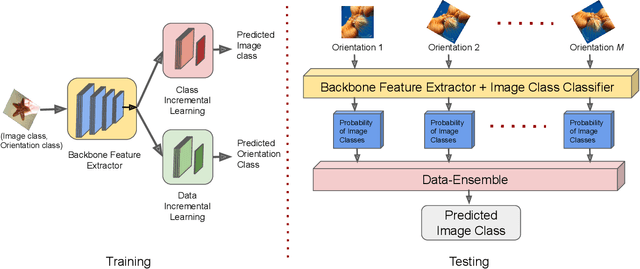


Deep learning models suffer from catastrophic forgetting of the classes in the older phases as they get trained on the classes introduced in the new phase in the class-incremental learning setting. In this work, we show that the effect of catastrophic forgetting on the model prediction varies with the change in orientation of the same image, which is a novel finding. Based on this, we propose a novel data-ensemble approach that combines the predictions for the different orientations of the image to help the model retain further information regarding the previously seen classes and thereby reduce the effect of forgetting on the model predictions. However, we cannot directly use the data-ensemble approach if the model is trained using traditional techniques. Therefore, we also propose a novel dual-incremental learning framework that involves jointly training the network with two incremental learning objectives, i.e., the class-incremental learning objective and our proposed data-incremental learning objective. In the dual-incremental learning framework, each image belongs to two classes, i.e., the image class (for class-incremental learning) and the orientation class (for data-incremental learning). In class-incremental learning, each new phase introduces a new set of classes, and the model cannot access the complete training data from the older phases. In our proposed data-incremental learning, the orientation classes remain the same across all the phases, and the data introduced by the new phase in class-incremental learning acts as new training data for these orientation classes. We empirically demonstrate that the dual-incremental learning framework is vital to the data-ensemble approach. We apply our proposed approach to state-of-the-art class-incremental learning methods and empirically show that our framework significantly improves the performance of these methods.
Communication-Efficient Federated Learning for Neural Machine Translation
Dec 12, 2021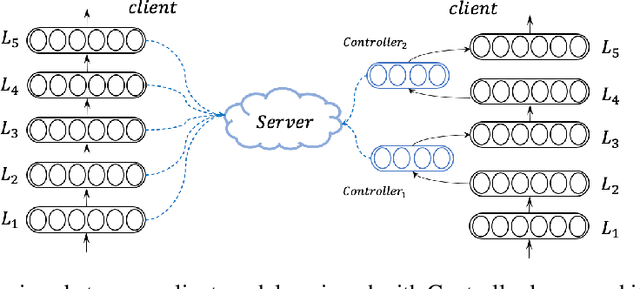
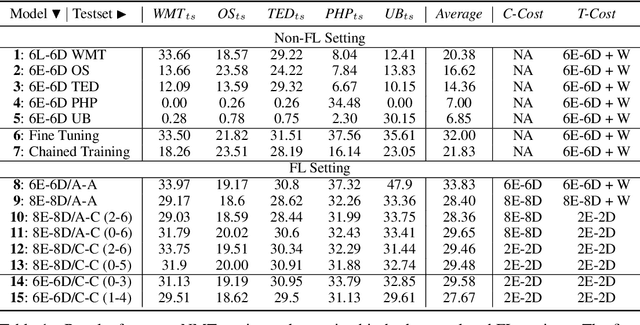
Training neural machine translation (NMT) models in federated learning (FL) settings could be inefficient both computationally and communication-wise, due to the large size of translation engines as well as the multiple rounds of updates required to train clients and a central server. In this paper, we explore how to efficiently build NMT models in an FL setup by proposing a novel solution. In order to reduce the communication overhead, out of all neural layers we only exchange what we term "Controller" layers. Controllers are a small number of additional neural components connected to our pre-trained architectures. These new components are placed in between original layers. They act as liaisons to communicate with the central server and learn minimal information that is sufficient enough to update clients. We evaluated the performance of our models on five datasets from different domains to translate from German into English. We noted that the models equipped with Controllers preform on par with those trained in a central and non-FL setting. In addition, we observed a substantial reduction in the communication traffic of the FL pipeline, which is a direct consequence of using Controllers. Based on our experiments, Controller-based models are ~6 times less expensive than their other peers. This reduction is significantly important when we consider the number of parameters in large models and it becomes even more critical when such parameters need to be exchanged for multiple rounds in FL settings.