 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
M-BERT: Injecting Multimodal Information in the BERT Structure
Aug 15, 2019
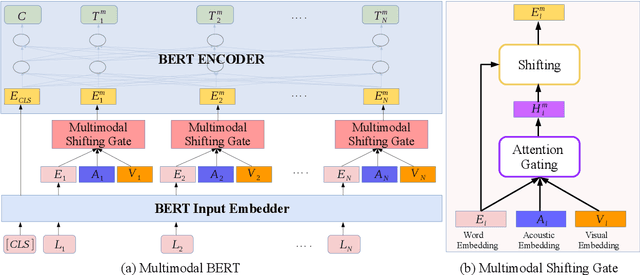
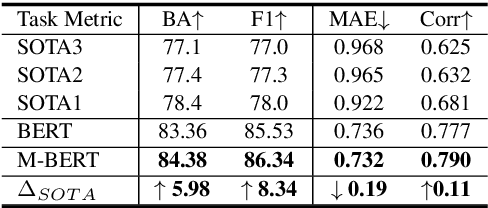
Multimodal language analysis is an emerging research area in natural language processing that models language in a multimodal manner. It aims to understand language from the modalities of text, visual, and acoustic by modeling both intra-modal and cross-modal interactions. BERT (Bidirectional Encoder Representations from Transformers) provides strong contextual language representations after training on large-scale unlabeled corpora. Fine-tuning the vanilla BERT model has shown promising results in building state-of-the-art models for diverse NLP tasks like question answering and language inference. However, fine-tuning BERT in the presence of information from other modalities remains an open research problem. In this paper, we inject multimodal information within the input space of BERT network for modeling multimodal language. The proposed injection method allows BERT to reach a new state of the art of $84.38\%$ binary accuracy on CMU-MOSI dataset (multimodal sentiment analysis) with a gap of 5.98 percent to the previous state of the art and 1.02 percent to the text-only BERT.
On Semantic Cognition, Inductive Generalization, and Language Models
Nov 04, 2021
My doctoral research focuses on understanding semantic knowledge in neural network models trained solely to predict natural language (referred to as language models, or LMs), by drawing on insights from the study of concepts and categories grounded in cognitive science. I propose a framework inspired by 'inductive reasoning,' a phenomenon that sheds light on how humans utilize background knowledge to make inductive leaps and generalize from new pieces of information about concepts and their properties. Drawing from experiments that study inductive reasoning, I propose to analyze semantic inductive generalization in LMs using phenomena observed in human-induction literature, investigate inductive behavior on tasks such as implicit reasoning and emergent feature recognition, and analyze and relate induction dynamics to the learned conceptual representation space.
Towards Empirical Sandwich Bounds on the Rate-Distortion Function
Nov 23, 2021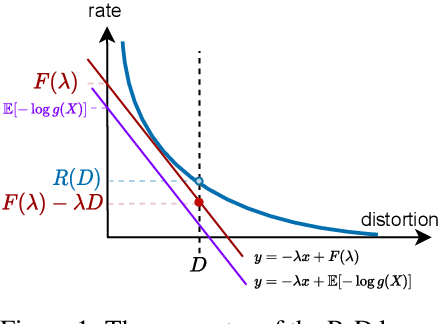
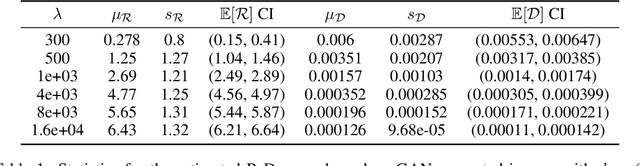
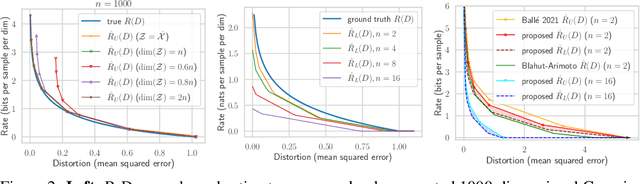
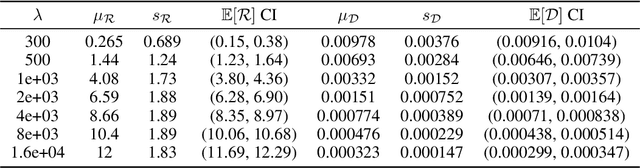
Rate-distortion (R-D) function, a key quantity in information theory, characterizes the fundamental limit of how much a data source can be compressed subject to a fidelity criterion, by any compression algorithm. As researchers push for ever-improving compression performance, establishing the R-D function of a given data source is not only of scientific interest, but also sheds light on the possible room for improving compression algorithms. Previous work on this problem relied on distributional assumptions on the data source (Gibson, 2017) or only applied to discrete data. By contrast, this paper makes the first attempt at an algorithm for sandwiching the R-D function of a general (not necessarily discrete) source requiring only i.i.d. data samples. We estimate R-D sandwich bounds on Gaussian and high-dimension banana-shaped sources, as well as GAN-generated images. Our R-D upper bound on natural images indicates room for improving the performance of state-of-the-art image compression methods by 1 dB in PSNR at various bitrates.
An Extension of InfoMap to Absorbing Random Walks
Dec 21, 2021
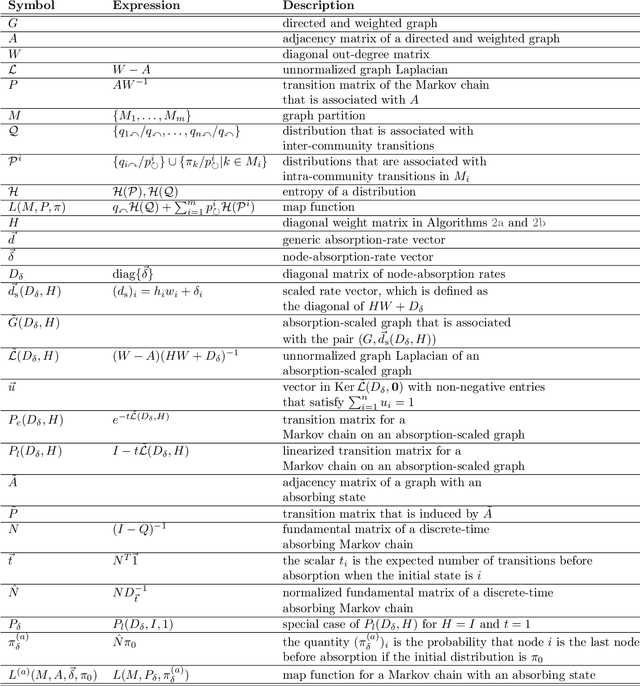
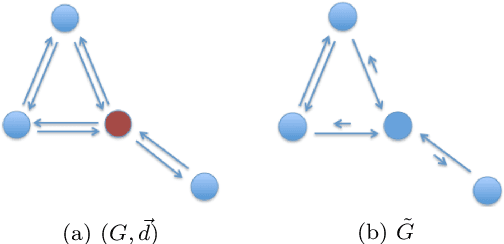
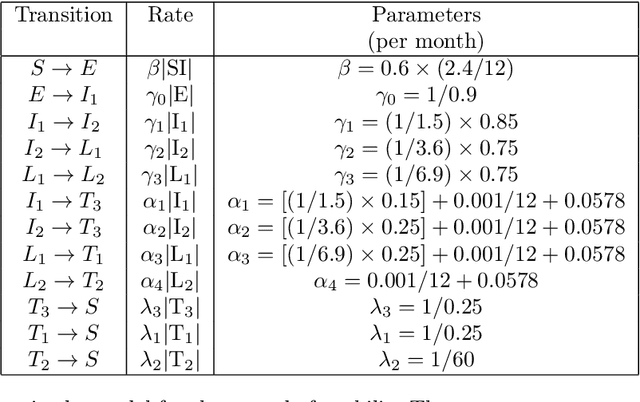
InfoMap is a popular approach for detecting densely connected "communities" of nodes in networks. To detect such communities, it builds on the standard type of Markov chain and ideas from information theory. Motivated by the dynamics of disease spread on networks, whose nodes may have heterogeneous disease-removal rates, we extend InfoMap to absorbing random walks. To do this, we use absorption-scaled graphs, in which the edge weights are scaled according to the absorption rates, along with Markov time sweeping. One of our extensions of InfoMap converges to the standard version of InfoMap in the limit in which the absorption rates approach $0$. We find that the community structure that one detects using our extensions of InfoMap can differ markedly from the community structure that one detects using methods that do not take node-absorption rates into account. Additionally, we demonstrate that the community structure that is induced by local dynamics can have important implications for susceptible-infected-recovered (SIR) dynamics on ring-lattice networks. For example, we find situations in which the outbreak duration is maximized when a moderate number of nodes have large node-absorption rates. We also use our extensions of InfoMap to study community structure in a sexual-contact network. We consider the community structure that corresponds to different absorption rates for homeless individuals in the network and the associated impact on syphilis dynamics on the network. We observe that the final outbreak size can be smaller when treatment rates are lower in the homeless population than in other populations than when they are the same in all populations.
M2H2: A Multimodal Multiparty Hindi Dataset For Humor Recognition in Conversations
Aug 03, 2021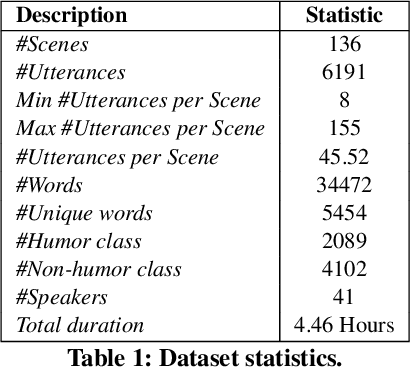


Humor recognition in conversations is a challenging task that has recently gained popularity due to its importance in dialogue understanding, including in multimodal settings (i.e., text, acoustics, and visual). The few existing datasets for humor are mostly in English. However, due to the tremendous growth in multilingual content, there is a great demand to build models and systems that support multilingual information access. To this end, we propose a dataset for Multimodal Multiparty Hindi Humor (M2H2) recognition in conversations containing 6,191 utterances from 13 episodes of a very popular TV series "Shrimaan Shrimati Phir Se". Each utterance is annotated with humor/non-humor labels and encompasses acoustic, visual, and textual modalities. We propose several strong multimodal baselines and show the importance of contextual and multimodal information for humor recognition in conversations. The empirical results on M2H2 dataset demonstrate that multimodal information complements unimodal information for humor recognition. The dataset and the baselines are available at http://www.iitp.ac.in/~ai-nlp-ml/resources.html and https://github.com/declare-lab/M2H2-dataset.
Responding to Challenge Call of Machine Learning Model Development in Diagnosing Respiratory Disease Sounds
Nov 29, 2021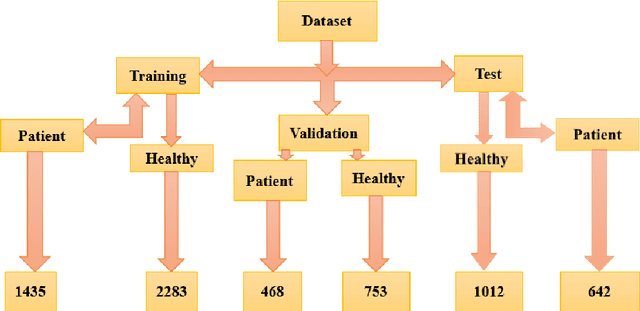
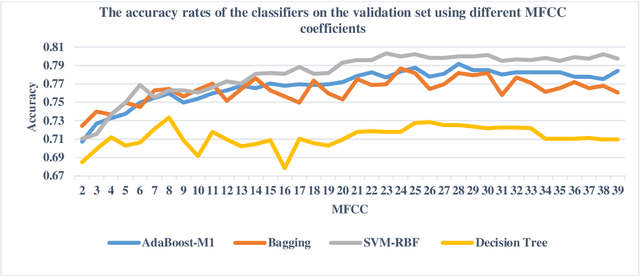
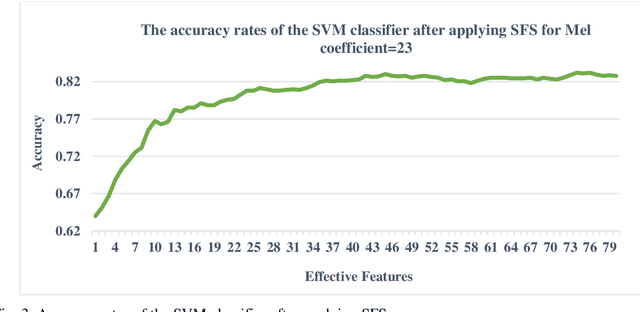
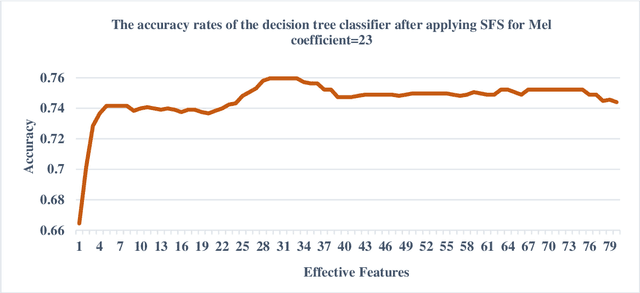
In this study, a machine learning model was developed for automatically detecting respiratory system sounds such as sneezing and coughing in disease diagnosis. The automatic model and approach development of breath sounds, which carry valuable information, results in early diagnosis and treatment. A successful machine learning model was developed in this study, which was a strong response to the challenge called the "Pfizer digital medicine challenge" on the "OSFHOME" open access platform. "Environmental sound classification" called ESC-50 and AudioSet sound files were used to prepare the dataset. In this dataset, which consisted of three parts, features that effectively showed coughing and sneezing sound analysis were extracted from training, testing and validating samples. Based on the Mel frequency cepstral coefficients (MFCC) feature extraction method, mathematical and statistical features were prepared. Three different classification techniques were considered to perform successful respiratory sound classification in the dataset containing more than 3800 different sounds. Support vector machine (SVM) with radial basis function (RBF) kernels, ensemble aggregation and decision tree classification methods were used as classification techniques. In an attempt to classify coughing and sneezing sounds from other sounds, SVM with RBF kernels was achieved with 83% success.
Throughput Maximization for IRS-Aided MIMO FD-WPCN with Non-Linear EH Model
Dec 17, 2021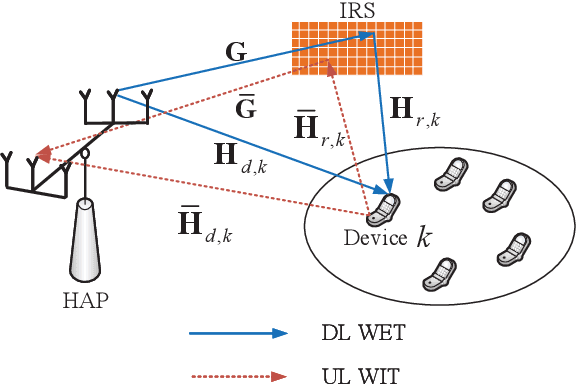
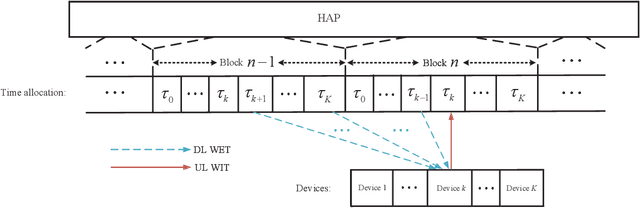
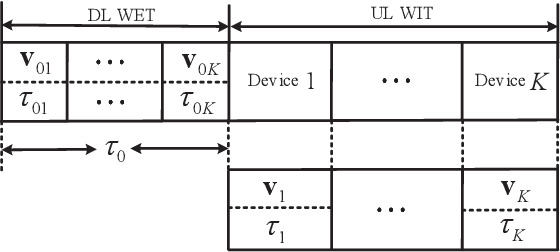
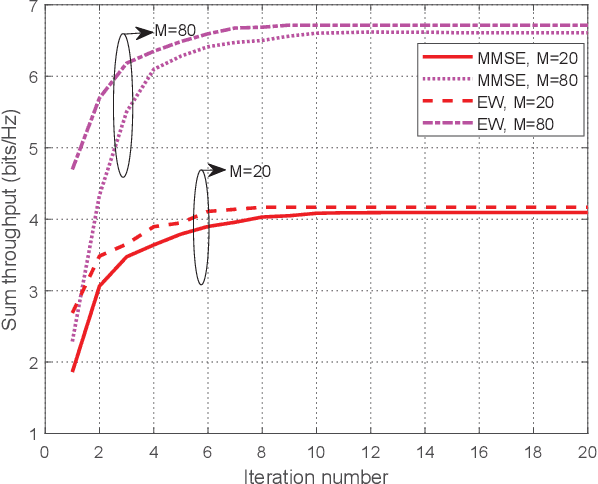
This paper studies an intelligent reflecting surface (IRS)-aided multiple-input-multiple-output (MIMO) full-duplex (FD) wireless-powered communication network (WPCN), where a hybrid access point (HAP) operating in FD broadcasts energy signals to multiple devices for their energy harvesting (EH) in the downlink (DL) and meanwhile receives information signals from devices in the uplink (UL) with the help of an IRS. Taking into account the practical finite self-interference (SI) and the non-linear EH model, we formulate the weighted sum throughput maximization optimization problem by jointly optimizing DL/UL time allocation, precoding matrices at devices, transmit covariance matrices at the HAP, and phase shifts at the IRS. Since the resulting optimization problem is non-convex, there are no standard methods to solve it optimally in general. To tackle this challenge, we first propose an element-wise (EW) based algorithm, where each IRS phase shift is alternately optimized in an iterative manner. To reduce the computational complexity, a minimum mean-square error (MMSE) based algorithm is proposed, where we transform the original problem into an equivalent form based on the MMSE method, which facilities the design of an efficient iterative algorithm. In particular, the IRS phase shift optimization problem is recast as an second-order cone program (SOCP), where all the IRS phase shifts are simultaneously optimized. For comparison, we also study two suboptimal IRS beamforming configurations in simulations, namely partially dynamic IRS beamforming (PDBF) and static IRS beamforming (SBF), which strike a balance between the system performance and practical complexity.
Segmentation of Lung Tumor from CT Images using Deep Supervision
Nov 17, 2021
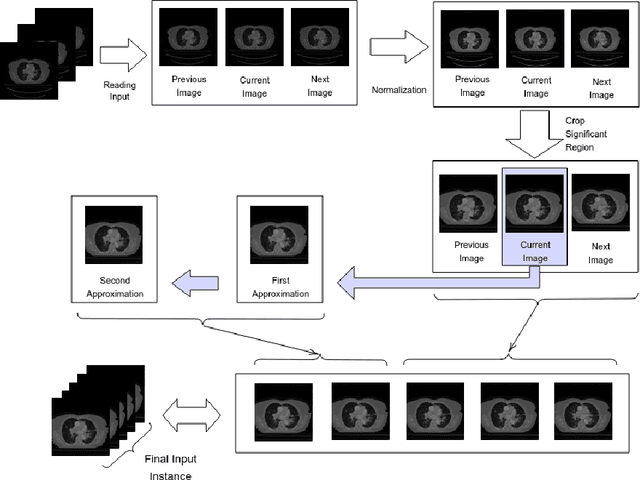

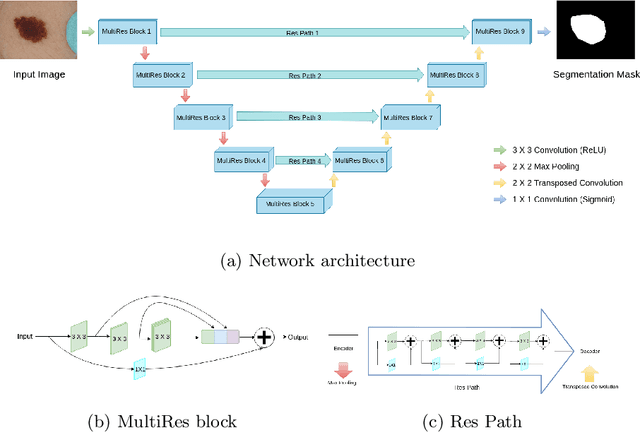
Lung cancer is a leading cause of death in most countries of the world. Since prompt diagnosis of tumors can allow oncologists to discern their nature, type and the mode of treatment, tumor detection and segmentation from CT Scan images is a crucial field of study worldwide. This paper approaches lung tumor segmentation by applying two-dimensional discrete wavelet transform (DWT) on the LOTUS dataset for more meticulous texture analysis whilst integrating information from neighboring CT slices before feeding them to a Deeply Supervised MultiResUNet model. Variations in learning rates, decay and optimization algorithms while training the network have led to different dice co-efficients, the detailed statistics of which have been included in this paper. We also discuss the challenges in this dataset and how we opted to overcome them. In essence, this study aims to maximize the success rate of predicting tumor regions from two dimensional CT Scan slices by experimenting with a number of adequate networks, resulting in a dice co-efficient of 0.8472.
Domain Adaptation on Point Clouds via Geometry-Aware Implicits
Dec 17, 2021
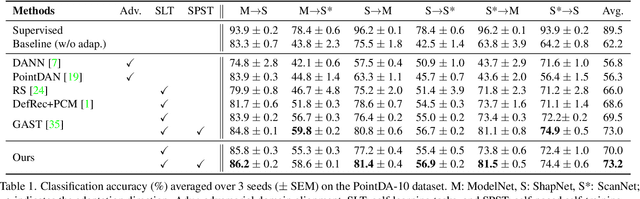
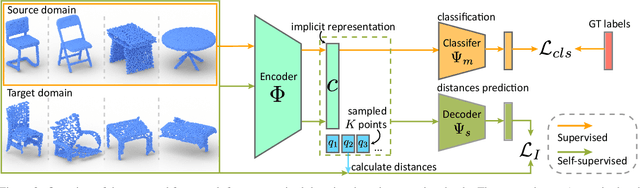
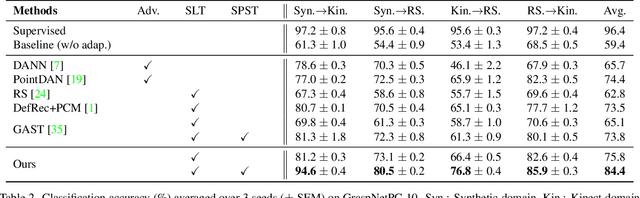
As a popular geometric representation, point clouds have attracted much attention in 3D vision, leading to many applications in autonomous driving and robotics. One important yet unsolved issue for learning on point cloud is that point clouds of the same object can have significant geometric variations if generated using different procedures or captured using different sensors. These inconsistencies induce domain gaps such that neural networks trained on one domain may fail to generalize on others. A typical technique to reduce the domain gap is to perform adversarial training so that point clouds in the feature space can align. However, adversarial training is easy to fall into degenerated local minima, resulting in negative adaptation gains. Here we propose a simple yet effective method for unsupervised domain adaptation on point clouds by employing a self-supervised task of learning geometry-aware implicits, which plays two critical roles in one shot. First, the geometric information in the point clouds is preserved through the implicit representations for downstream tasks. More importantly, the domain-specific variations can be effectively learned away in the implicit space. We also propose an adaptive strategy to compute unsigned distance fields for arbitrary point clouds due to the lack of shape models in practice. When combined with a task loss, the proposed outperforms state-of-the-art unsupervised domain adaptation methods that rely on adversarial domain alignment and more complicated self-supervised tasks. Our method is evaluated on both PointDA-10 and GraspNet datasets. The code and trained models will be publicly available.
Learning to Find Correlated Features by Maximizing Information Flow in Convolutional Neural Networks
Jun 30, 2019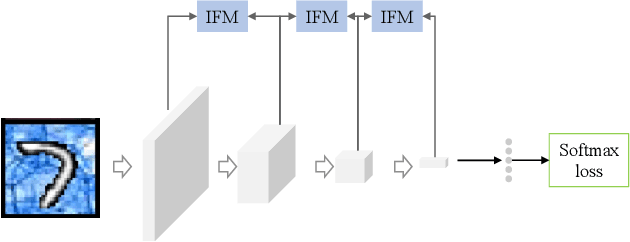

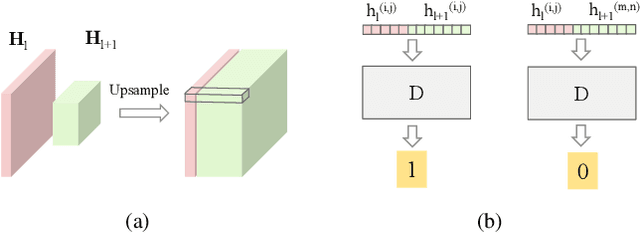

Training convolutional neural networks for image classification tasks usually causes information loss. Although most of the time the information lost is redundant with respect to the target task, there are still cases where discriminative information is also discarded. For example, if the samples that belong to the same category have multiple correlated features, the model may only learn a subset of the features and ignore the rest. This may not be a problem unless the classification in the test set highly depends on the ignored features. We argue that the discard of the correlated discriminative information is partially caused by the fact that the minimization of the classification loss doesn't ensure to learn the overall discriminative information but only the most discriminative information. To address this problem, we propose an information flow maximization (IFM) loss as a regularization term to find the discriminative correlated features. With less information loss the classifier can make predictions based on more informative features. We validate our method on the shiftedMNIST dataset and show the effectiveness of IFM loss in learning representative and discriminative features.