 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DSC-IITISM at FinCausal 2021: Combining POS tagging with Attention-based Contextual Representations for Identifying Causal Relationships in Financial Documents
Oct 31, 2021
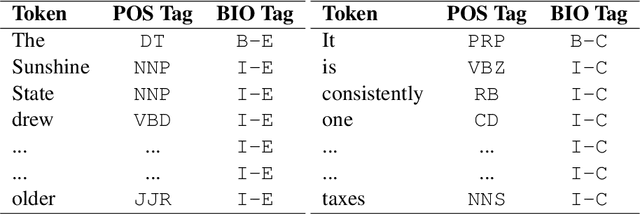

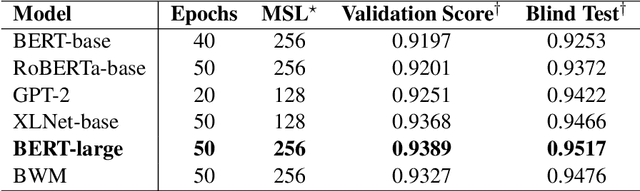

Causality detection draws plenty of attention in the field of Natural Language Processing and linguistics research. It has essential applications in information retrieval, event prediction, question answering, financial analysis, and market research. In this study, we explore several methods to identify and extract cause-effect pairs in financial documents using transformers. For this purpose, we propose an approach that combines POS tagging with the BIO scheme, which can be integrated with modern transformer models to address this challenge of identifying causality in a given text. Our best methodology achieves an F1-Score of 0.9551, and an Exact Match Score of 0.8777 on the blind test in the FinCausal-2021 Shared Task at the FinCausal 2021 Workshop.
Responding to Challenge Call of Machine Learning Model Development in Diagnosing Respiratory Disease Sounds
Nov 29, 2021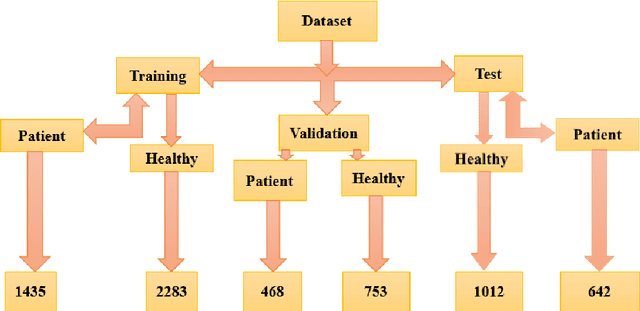
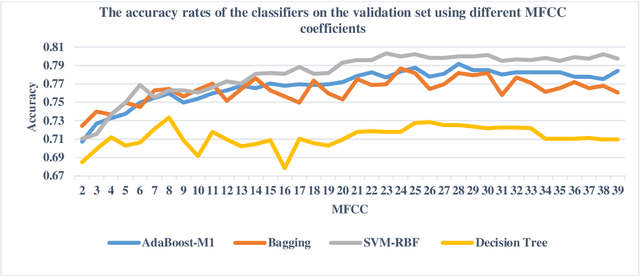
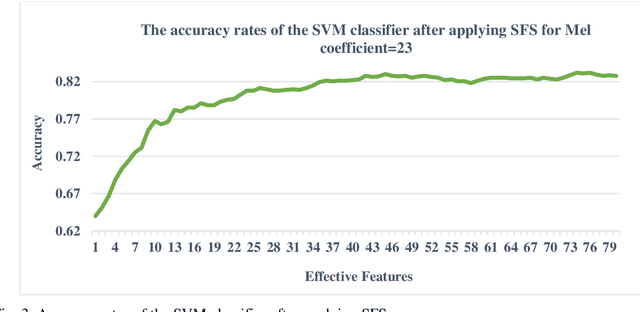
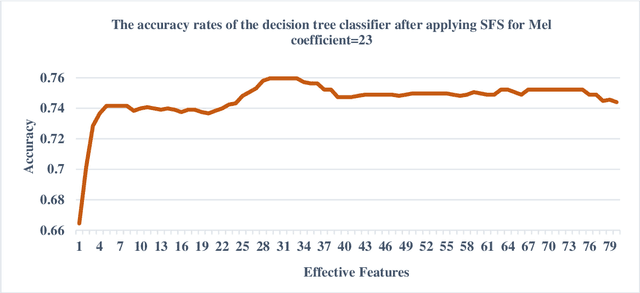
In this study, a machine learning model was developed for automatically detecting respiratory system sounds such as sneezing and coughing in disease diagnosis. The automatic model and approach development of breath sounds, which carry valuable information, results in early diagnosis and treatment. A successful machine learning model was developed in this study, which was a strong response to the challenge called the "Pfizer digital medicine challenge" on the "OSFHOME" open access platform. "Environmental sound classification" called ESC-50 and AudioSet sound files were used to prepare the dataset. In this dataset, which consisted of three parts, features that effectively showed coughing and sneezing sound analysis were extracted from training, testing and validating samples. Based on the Mel frequency cepstral coefficients (MFCC) feature extraction method, mathematical and statistical features were prepared. Three different classification techniques were considered to perform successful respiratory sound classification in the dataset containing more than 3800 different sounds. Support vector machine (SVM) with radial basis function (RBF) kernels, ensemble aggregation and decision tree classification methods were used as classification techniques. In an attempt to classify coughing and sneezing sounds from other sounds, SVM with RBF kernels was achieved with 83% success.
Channel Exchanging Networks for Multimodal and Multitask Dense Image Prediction
Dec 04, 2021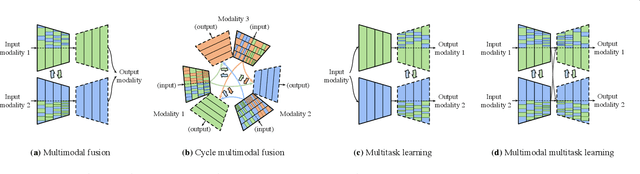
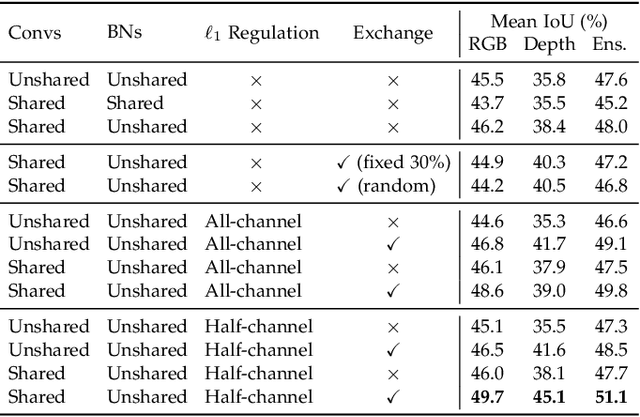
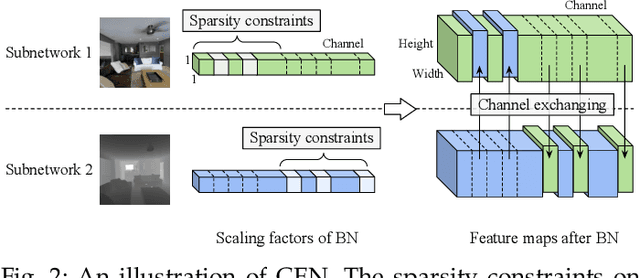
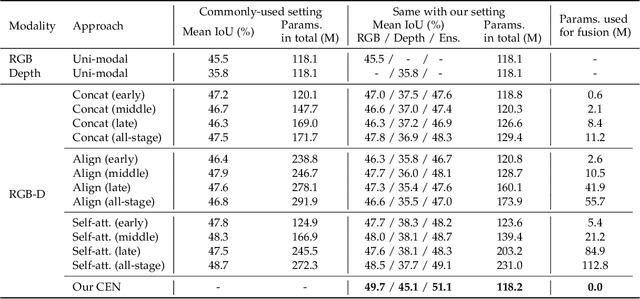
Multimodal fusion and multitask learning are two vital topics in machine learning. Despite the fruitful progress, existing methods for both problems are still brittle to the same challenge -- it remains dilemmatic to integrate the common information across modalities (resp. tasks) meanwhile preserving the specific patterns of each modality (resp. task). Besides, while they are actually closely related to each other, multimodal fusion and multitask learning are rarely explored within the same methodological framework before. In this paper, we propose Channel-Exchanging-Network (CEN) which is self-adaptive, parameter-free, and more importantly, applicable for both multimodal fusion and multitask learning. At its core, CEN dynamically exchanges channels between subnetworks of different modalities. Specifically, the channel exchanging process is self-guided by individual channel importance that is measured by the magnitude of Batch-Normalization (BN) scaling factor during training. For the application of dense image prediction, the validity of CEN is tested by four different scenarios: multimodal fusion, cycle multimodal fusion, multitask learning, and multimodal multitask learning. Extensive experiments on semantic segmentation via RGB-D data and image translation through multi-domain input verify the effectiveness of our CEN compared to current state-of-the-art methods. Detailed ablation studies have also been carried out, which provably affirm the advantage of each component we propose.
RPT: Toward Transferable Model on Heterogeneous Researcher Data via Pre-Training
Oct 08, 2021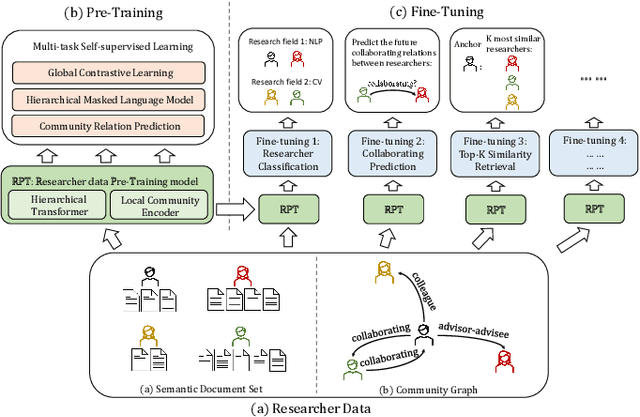
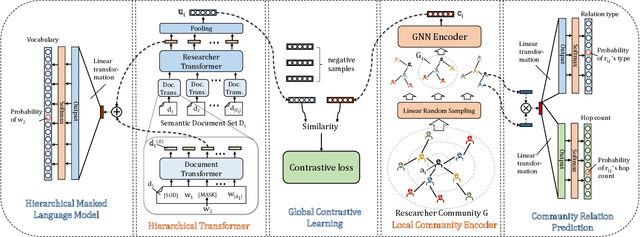
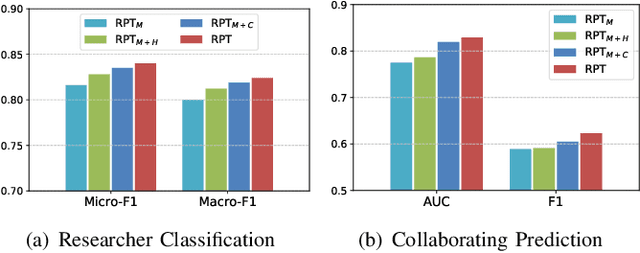
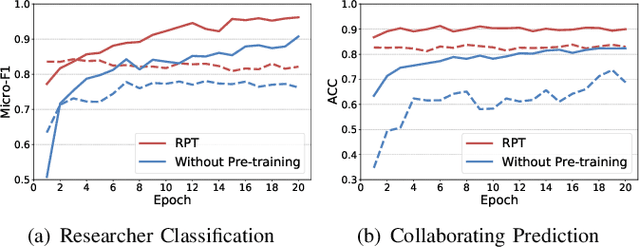
With the growth of the academic engines, the mining and analysis acquisition of massive researcher data, such as collaborator recommendation and researcher retrieval, has become indispensable. It can improve the quality of services and intelligence of academic engines. Most of the existing studies for researcher data mining focus on a single task for a particular application scenario and learning a task-specific model, which is usually unable to transfer to out-of-scope tasks. The pre-training technology provides a generalized and sharing model to capture valuable information from enormous unlabeled data. The model can accomplish multiple downstream tasks via a few fine-tuning steps. In this paper, we propose a multi-task self-supervised learning-based researcher data pre-training model named RPT. Specifically, we divide the researchers' data into semantic document sets and community graph. We design the hierarchical Transformer and the local community encoder to capture information from the two categories of data, respectively. Then, we propose three self-supervised learning objectives to train the whole model. Finally, we also propose two transfer modes of RPT for fine-tuning in different scenarios. We conduct extensive experiments to evaluate RPT, results on three downstream tasks verify the effectiveness of pre-training for researcher data mining.
HHF: Hashing-guided Hinge Function for Deep Hashing Retrieval
Dec 04, 2021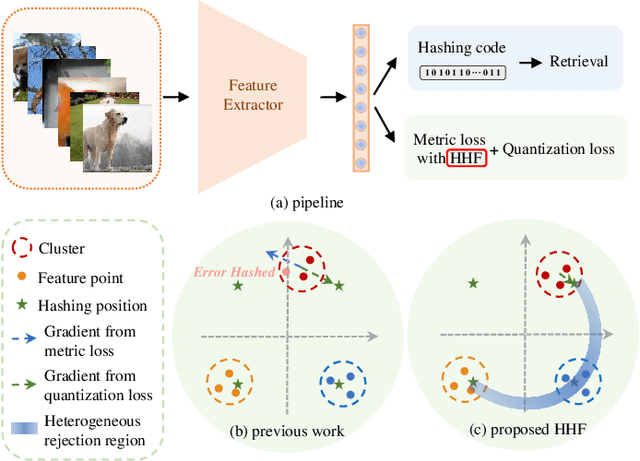

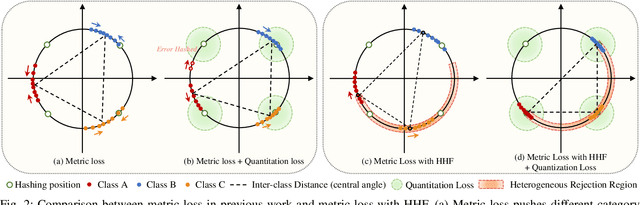
Deep hashing has shown promising performance in large-scale image retrieval. However, latent codes extracted by \textbf{D}eep \textbf{N}eural \textbf{N}etwork (DNN) will inevitably lose semantic information during the binarization process, which damages the retrieval efficiency and make it challenging. Although many existing approaches perform regularization to alleviate quantization errors, we figure out an incompatible conflict between the metric and quantization losses. The metric loss penalizes the inter-class distances to push different classes unconstrained far away. Worse still, it tends to map the latent code deviate from ideal binarization point and generate severe ambiguity in the binarization process. Based on the minimum distance of the binary linear code, \textbf{H}ashing-guided \textbf{H}inge \textbf{F}unction (HHF) is proposed to avoid such conflict. In detail, we carefully design a specific inflection point, which relies on the hash bit length and category numbers to balance metric learning and quantization learning. Such a modification prevents the network from falling into local metric optimal minima in deep hashing. Extensive experiments in CIFAR-10, CIFAR-100, ImageNet, and MS-COCO show that HHF consistently outperforms existing techniques, and is robust and flexible to transplant into other methods.
False Negative Distillation and Contrastive Learning for Personalized Outfit Recommendation
Oct 13, 2021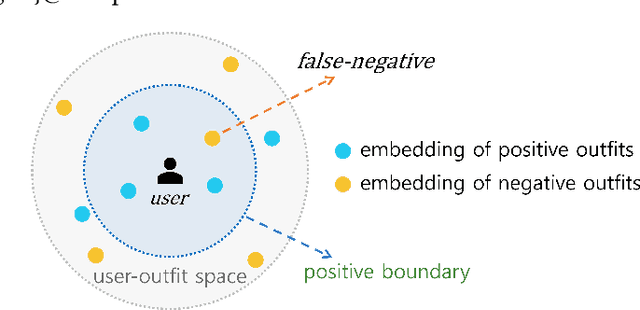
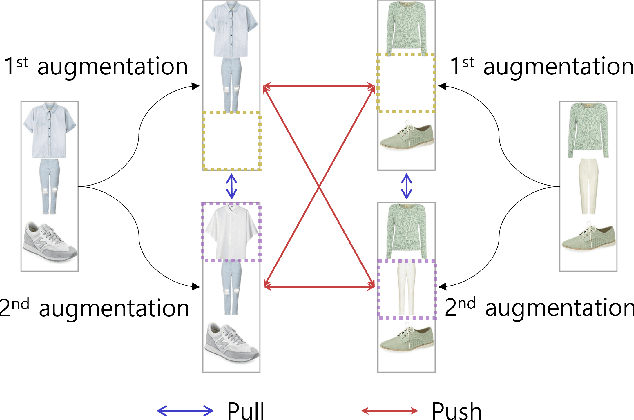
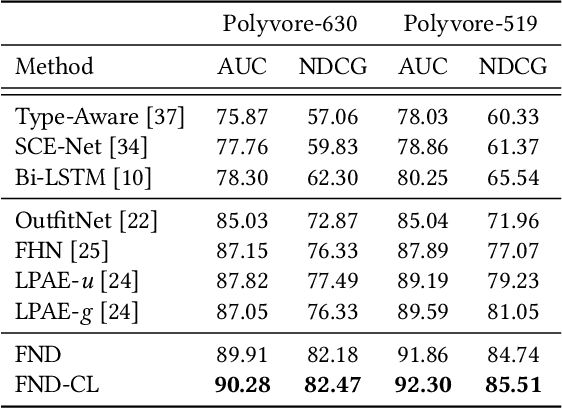
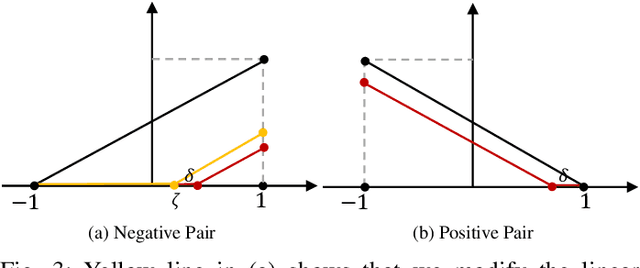
Personalized outfit recommendation has recently been in the spotlight with the rapid growth of the online fashion industry. However, recommending outfits has two significant challenges that should be addressed. The first challenge is that outfit recommendation often requires a complex and large model that utilizes visual information, incurring huge memory and time costs. One natural way to mitigate this problem is to compress such a cumbersome model with knowledge distillation (KD) techniques that leverage knowledge from a pretrained teacher model. However, it is hard to apply existing KD approaches in recommender systems (RS) to the outfit recommendation because they require the ranking of all possible outfits while the number of outfits grows exponentially to the number of consisting clothing items. Therefore, we propose a new KD framework for outfit recommendation, called False Negative Distillation (FND), which exploits false-negative information from the teacher model while not requiring the ranking of all candidates. The second challenge is that the explosive number of outfit candidates amplifying the data sparsity problem, often leading to poor outfit representation. To tackle this issue, inspired by the recent success of contrastive learning (CL), we introduce a CL framework for outfit representation learning with two proposed data augmentation methods. Quantitative and qualitative experiments on outfit recommendation datasets demonstrate the effectiveness and soundness of our proposed methods.
Improved Knowledge Graph Embedding using Background Taxonomic Information
Dec 07, 2018



Knowledge graphs are used to represent relational information in terms of triples. To enable learning about domains, embedding models, such as tensor factorization models, can be used to make predictions of new triples. Often there is background taxonomic information (in terms of subclasses and subproperties) that should also be taken into account. We show that existing fully expressive (a.k.a. universal) models cannot provably respect subclass and subproperty information. We show that minimal modifications to an existing knowledge graph completion method enables injection of taxonomic information. Moreover, we prove that our model is fully expressive, assuming a lower-bound on the size of the embeddings. Experimental results on public knowledge graphs show that despite its simplicity our approach is surprisingly effective.
Causal Order Identification to Address Confounding: Binary Variables
Aug 13, 2021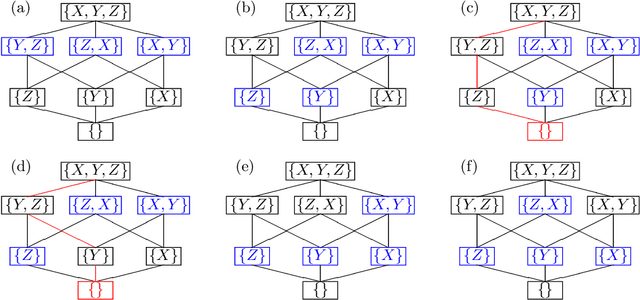

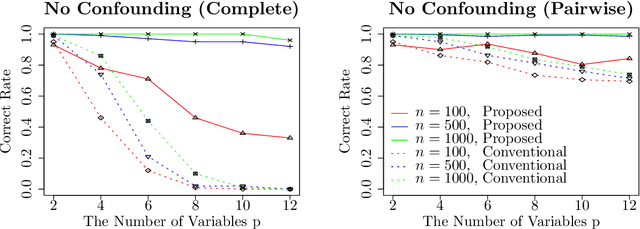
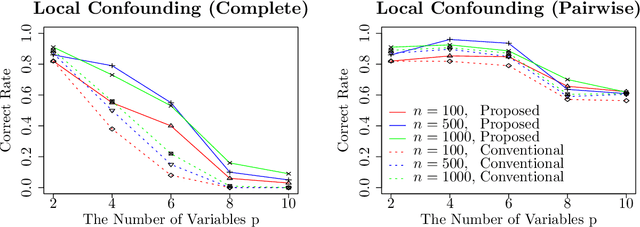
This paper considers an extension of the linear non-Gaussian acyclic model (LiNGAM) that determines the causal order among variables from a dataset when the variables are expressed by a set of linear equations, including noise. In particular, we assume that the variables are binary. The existing LiNGAM assumes that no confounding is present, which is restrictive in practice. Based on the concept of independent component analysis (ICA), this paper proposes an extended framework in which the mutual information among the noises is minimized. Another significant contribution is to reduce the realization of the shortest path problem. The distance between each pair of nodes expresses an associated mutual information value, and the path with the minimum sum (KL divergence) is sought. Although $p!$ mutual information values should be compared, this paper dramatically reduces the computation when no confounding is present. The proposed algorithm finds the globally optimal solution, while the existing locally greedily seek the order based on hypothesis testing. We use the best estimator in the sense of Bayes/MDL that correctly detects independence for mutual information estimation. Experiments using artificial and actual data show that the proposed version of LiNGAM achieves significantly better performance, particularly when confounding is present.
SynCoBERT: Syntax-Guided Multi-Modal Contrastive Pre-Training for Code Representation
Sep 09, 2021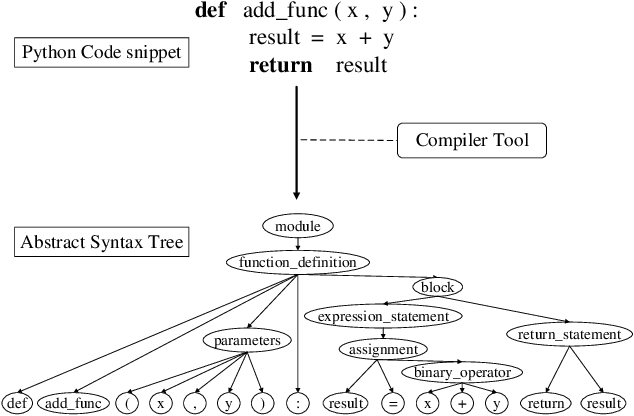
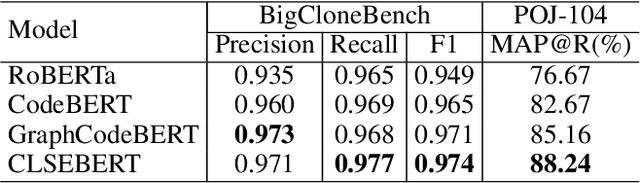


Code representation learning, which aims to encode the semantics of source code into distributed vectors, plays an important role in recent deep-learning-based models for code intelligence. Recently, many pre-trained language models for source code (e.g., CuBERT and CodeBERT) have been proposed to model the context of code and serve as a basis for downstream code intelligence tasks such as code search, code clone detection, and program translation. Current approaches typically consider the source code as a plain sequence of tokens, or inject the structure information (e.g., AST and data-flow) into the sequential model pre-training. To further explore the properties of programming languages, this paper proposes SynCoBERT, a syntax-guided multi-modal contrastive pre-training approach for better code representations. Specially, we design two novel pre-training objectives originating from the symbolic and syntactic properties of source code, i.e., Identifier Prediction (IP) and AST Edge Prediction (TEP), which are designed to predict identifiers, and edges between two nodes of AST, respectively. Meanwhile, to exploit the complementary information in semantically equivalent modalities (i.e., code, comment, AST) of the code, we propose a multi-modal contrastive learning strategy to maximize the mutual information among different modalities. Extensive experiments on four downstream tasks related to code intelligence show that SynCoBERT advances the state-of-the-art with the same pre-training corpus and model size.
Segmentation of Lung Tumor from CT Images using Deep Supervision
Nov 17, 2021
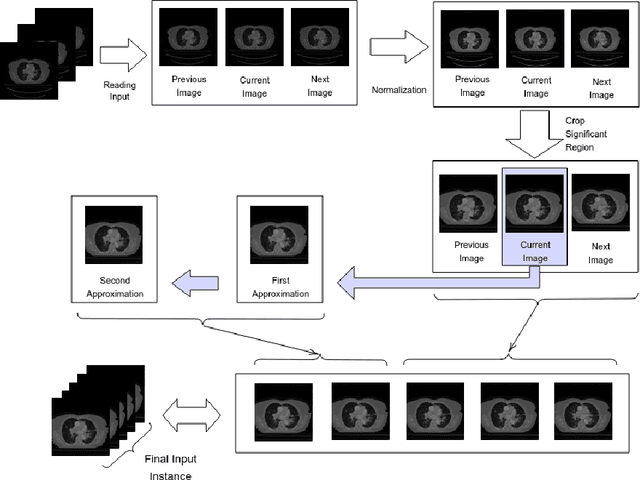

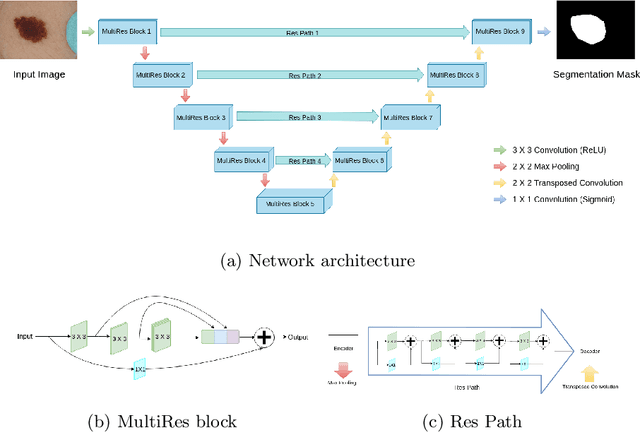
Lung cancer is a leading cause of death in most countries of the world. Since prompt diagnosis of tumors can allow oncologists to discern their nature, type and the mode of treatment, tumor detection and segmentation from CT Scan images is a crucial field of study worldwide. This paper approaches lung tumor segmentation by applying two-dimensional discrete wavelet transform (DWT) on the LOTUS dataset for more meticulous texture analysis whilst integrating information from neighboring CT slices before feeding them to a Deeply Supervised MultiResUNet model. Variations in learning rates, decay and optimization algorithms while training the network have led to different dice co-efficients, the detailed statistics of which have been included in this paper. We also discuss the challenges in this dataset and how we opted to overcome them. In essence, this study aims to maximize the success rate of predicting tumor regions from two dimensional CT Scan slices by experimenting with a number of adequate networks, resulting in a dice co-efficient of 0.8472.