 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ST2Vec: Spatio-Temporal Trajectory Similarity Learning in Road Networks
Dec 17, 2021
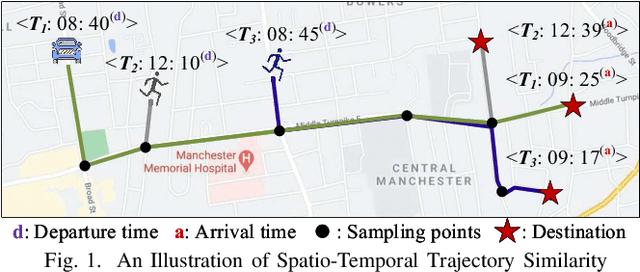

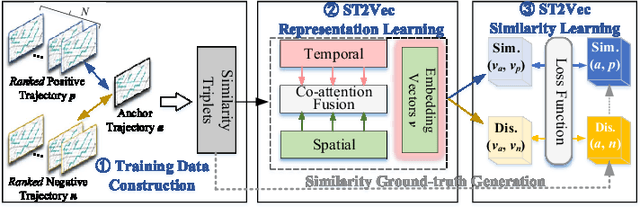
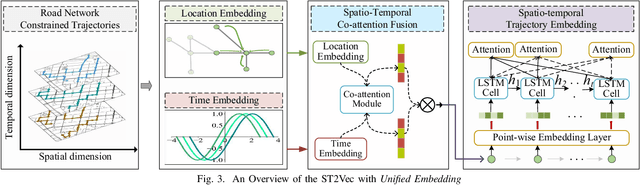
People and vehicle trajectories embody important information of transportation infrastructures, and trajectory similarity computation is functionality in many real-world applications involving trajectory data analysis. Recently, deep-learning based trajectory similarity techniques hold the potential to offer improved efficiency and adaptability over traditional similarity techniques. Nevertheless, the existing trajectory similarity learning proposals emphasize spatial similarity over temporal similarity, making them suboptimal for time-aware analyses. To this end, we propose ST2Vec, a trajectory-representation-learning based architecture that considers fine-grained spatial and temporal correlations between pairs of trajectories for spatio-temporal similarity learning in road networks. To the best of our knowledge, this is the first deep-learning proposal for spatio-temporal trajectory similarity analytics. Specifically, ST2Vec encompasses three phases: (i) training data preparation that selects representative training samples; (ii) spatial and temporal modeling that encode spatial and temporal characteristics of trajectories, where a generic temporal modeling module (TMM) is designed; and (iii) spatio-temporal co-attention fusion (STCF), where a unified fusion (UF) approach is developed to help generating unified spatio-temporal trajectory embeddings that capture the spatio-temporal similarity relations between trajectories. Further, inspired by curriculum concept, ST2Vec employs the curriculum learning for model optimization to improve both convergence and effectiveness. An experimental study offers evidence that ST2Vec outperforms all state-of-the-art competitors substantially in terms of effectiveness, efficiency, and scalability, while showing low parameter sensitivity and good model robustness.
MT-TransUNet: Mediating Multi-Task Tokens in Transformers for Skin Lesion Segmentation and Classification
Dec 03, 2021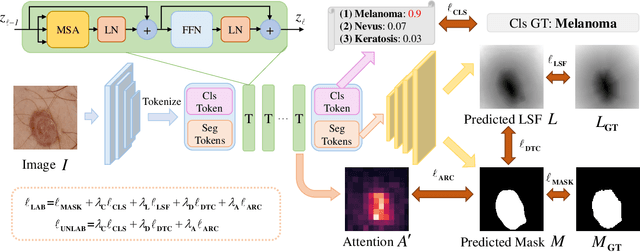
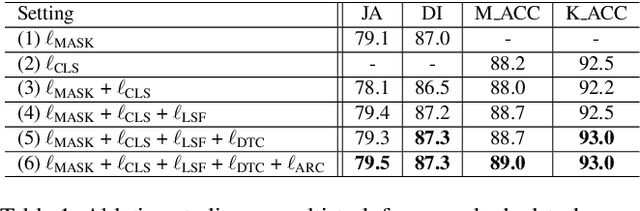
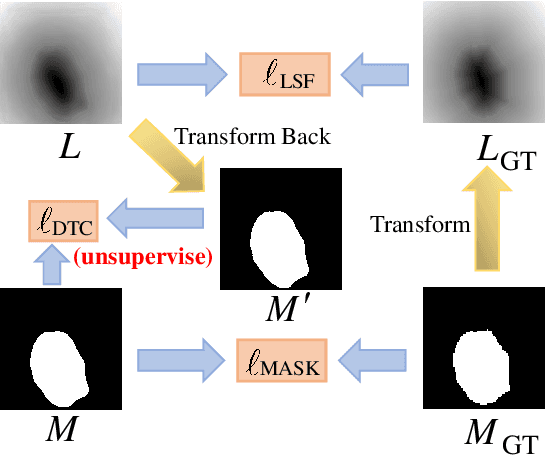
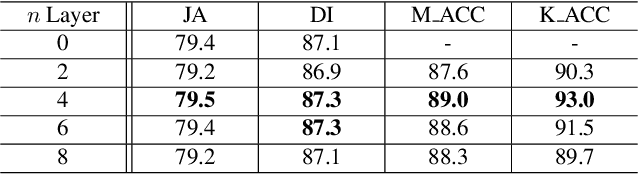
Recent advances in automated skin cancer diagnosis have yielded performance on par with board-certified dermatologists. However, these approaches formulated skin cancer diagnosis as a simple classification task, dismissing the potential benefit from lesion segmentation. We argue that an accurate lesion segmentation can supplement the classification task with additive lesion information, such as asymmetry, border, intensity, and physical size; in turn, a faithful lesion classification can support the segmentation task with discriminant lesion features. To this end, this paper proposes a new multi-task framework, named MT-TransUNet, which is capable of segmenting and classifying skin lesions collaboratively by mediating multi-task tokens in Transformers. Furthermore, we have introduced dual-task and attended region consistency losses to take advantage of those images without pixel-level annotation, ensuring the model's robustness when it encounters the same image with an account of augmentation. Our MT-TransUNet exceeds the previous state of the art for lesion segmentation and classification tasks in ISIC-2017 and PH2; more importantly, it preserves compelling computational efficiency regarding model parameters (48M~vs.~130M) and inference speed (0.17s~vs.~2.02s per image). Code will be available at https://github.com/JingyeChen/MT-TransUNet.
Hierarchical Soft Actor-Critic: Adversarial Exploration via Mutual Information Optimization
Jun 17, 2019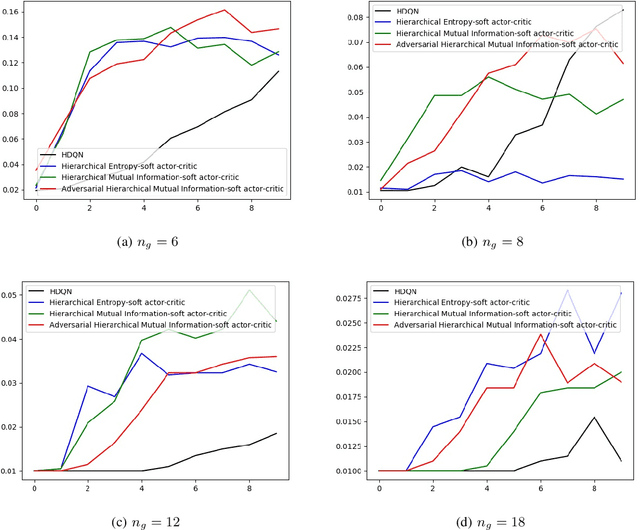
We describe a novel extension of soft actor-critics for hierarchical Deep Q-Networks (HDQN) architectures using mutual information metric. The proposed extension provides a suitable framework for encouraging explorations in such hierarchical networks. A natural utilization of this framework is an adversarial setting, where meta-controller and controller play minimax over the mutual information objective but cooperate on maximizing expected rewards.
A Bayesian-Based Approach to Human Operator Intent Recognition in Remote Mobile Robot Navigation
Sep 24, 2021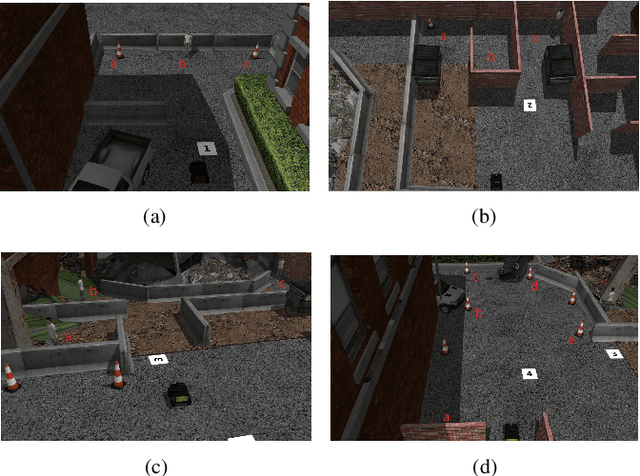
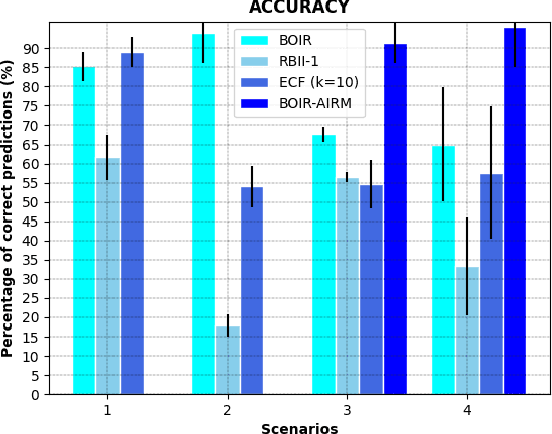
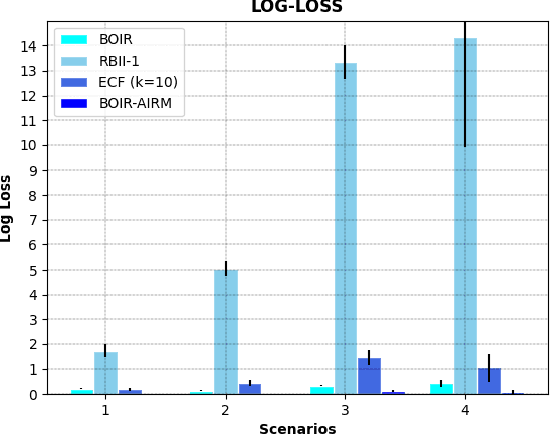
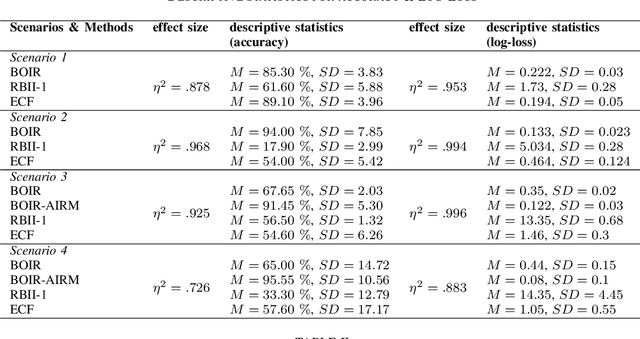
This paper addresses the problem of human operator intent recognition during teleoperated robot navigation. In this context, recognition of the operator's intended navigational goal, could enable an artificial intelligence (AI) agent to assist the operator in an advanced human-robot interaction framework. We propose a Bayesian Operator Intent Recognition (BOIR) probabilistic method that utilizes: (i) an observation model that fuses information as a weighting combination of multiple observation sources providing geometric information; (ii) a transition model that indicates the evolution of the state; and (iii) an action model, the Active Intent Recognition Model (AIRM), that enables the operator to communicate their explicit intent asynchronously. The proposed method is evaluated in an experiment where operators controlling a remote mobile robot are tasked with navigation and exploration under various scenarios with different map and obstacle layouts. Results demonstrate that BOIR outperforms two related methods from literature in terms of accuracy and uncertainty of the intent recognition.
ARMAS: Active Reconstruction of Missing Audio Segments
Nov 21, 2021

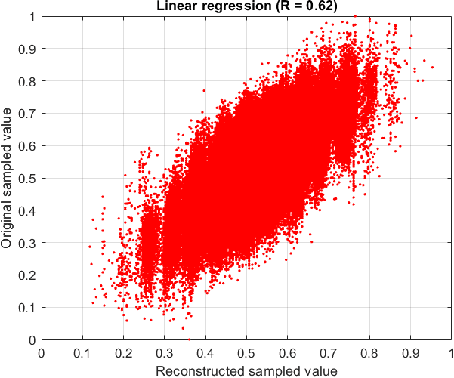
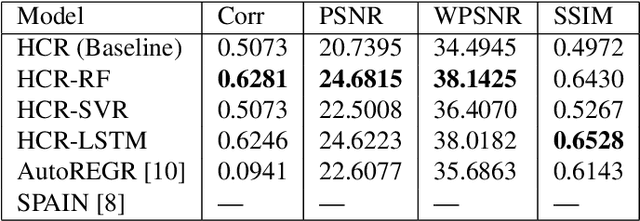
Digital audio signal reconstruction of lost or corrupt segment using deep learning algorithms has been explored intensively in the recent years. Nevertheless, prior traditional methods with linear interpolation, phase coding and tone insertion techniques are still in vogue. However, we found no research work on the reconstruction of audio signals with the fusion of dithering, steganography, and machine learning regressors. Therefore, this paper proposes the combination of steganography, halftoning (dithering), and state-of-the-art shallow (RF- Random Forest and SVR- Support Vector Regression) and deep learning (LSTM- Long Short-Term Memory) methods. The results (including comparison to the SPAIN and Autoregressive methods) are evaluated with four different metrics. The observations from the results show that the proposed solution is effective and can enhance the reconstruction of audio signals performed by the side information (noisy-latent representation) steganography provides. This work may trigger interest in the optimization of this approach and/or in transferring it to different domains (i.e., image reconstruction).
A Trainable Spectral-Spatial Sparse Coding Model for Hyperspectral Image Restoration
Nov 18, 2021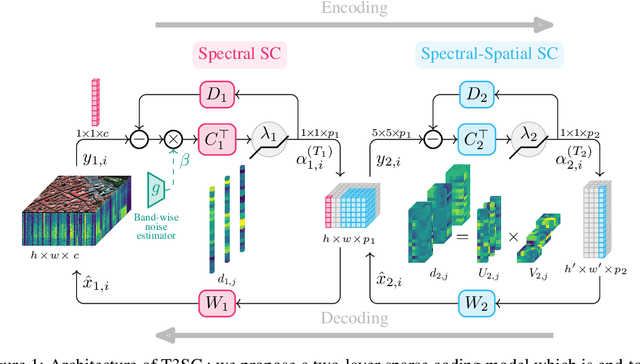

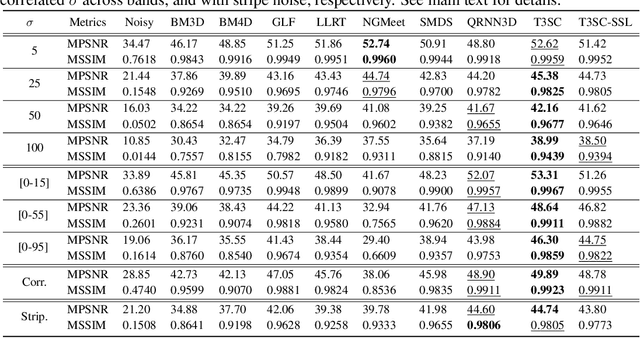

Hyperspectral imaging offers new perspectives for diverse applications, ranging from the monitoring of the environment using airborne or satellite remote sensing, precision farming, food safety, planetary exploration, or astrophysics. Unfortunately, the spectral diversity of information comes at the expense of various sources of degradation, and the lack of accurate ground-truth "clean" hyperspectral signals acquired on the spot makes restoration tasks challenging. In particular, training deep neural networks for restoration is difficult, in contrast to traditional RGB imaging problems where deep models tend to shine. In this paper, we advocate instead for a hybrid approach based on sparse coding principles that retains the interpretability of classical techniques encoding domain knowledge with handcrafted image priors, while allowing to train model parameters end-to-end without massive amounts of data. We show on various denoising benchmarks that our method is computationally efficient and significantly outperforms the state of the art.
Multi-Band Wi-Fi Sensing with Matched Feature Granularity
Dec 28, 2021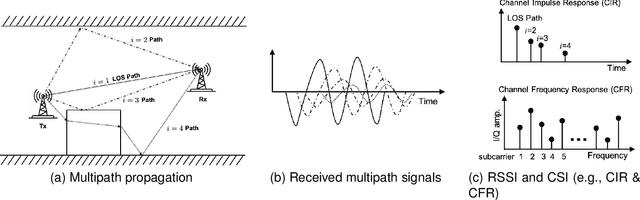
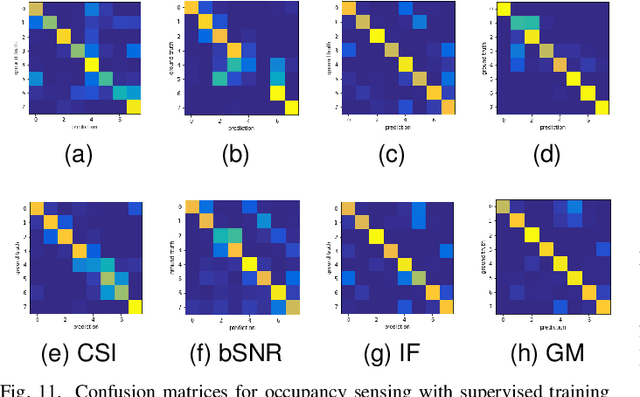
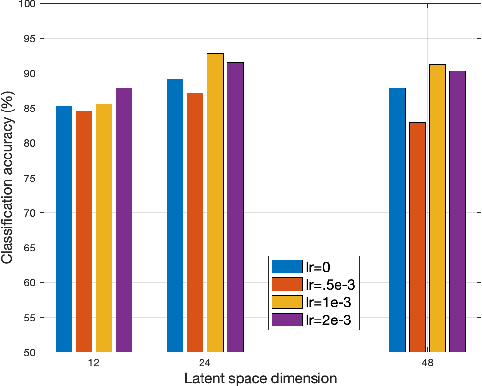
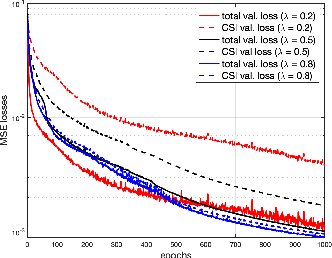
Complementary to the fine-grained channel state information (CSI) from the physical layer and coarse-grained received signal strength indicator (RSSI) measurements, the mid-grained spatial beam attributes (e.g., beam SNR) that are available at millimeter-wave (mmWave) bands during the mandatory beam training phase can be repurposed for Wi-Fi sensing applications. In this paper, we propose a multi-band Wi-Fi fusion method for Wi-Fi sensing that hierarchically fuses the features from both the fine-grained CSI at sub-6 GHz and the mid-grained beam SNR at 60 GHz in a granularity matching framework. The granularity matching is realized by pairing two feature maps from the CSI and beam SNR at different granularity levels and linearly combining all paired feature maps into a fused feature map with learnable weights. To further address the issue of limited labeled training data, we propose an autoencoder-based multi-band Wi-Fi fusion network that can be pre-trained in an unsupervised fashion. Once the autoencoder-based fusion network is pre-trained, we detach the decoders and append multi-task sensing heads to the fused feature map by fine-tuning the fusion block and re-training the multi-task heads from the scratch. The multi-band Wi-Fi fusion framework is thoroughly validated by in-house experimental Wi-Fi sensing datasets spanning three tasks: 1) pose recognition; 2) occupancy sensing; and 3) indoor localization. Comparison to four baseline methods (i.e., CSI-only, beam SNR-only, input fusion, and feature fusion) demonstrates the granularity matching improves the multi-task sensing performance. Quantitative performance is evaluated as a function of the number of labeled training data, latent space dimension, and fine-tuning learning rates.
The Impact of Main Content Extraction on Near-Duplicate Detection
Nov 21, 2021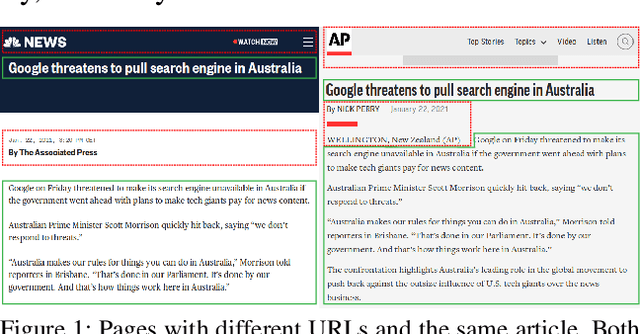
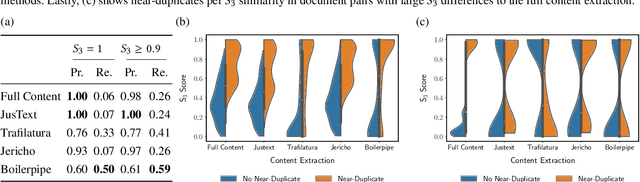
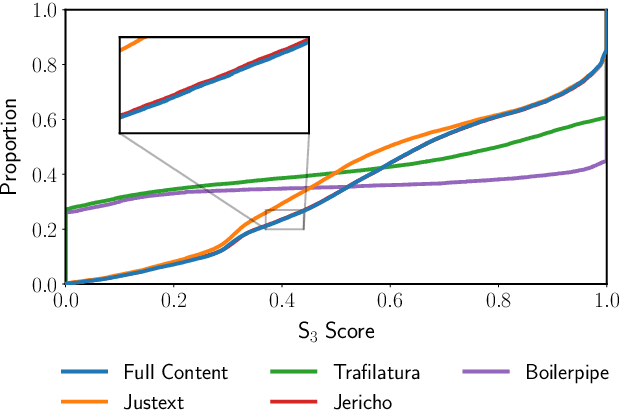
Commercial web search engines employ near-duplicate detection to ensure that users see each relevant result only once, albeit the underlying web crawls typically include (near-)duplicates of many web pages. We revisit the risks and potential of near-duplicates with an information retrieval focus, motivating that current efforts toward an open and independent European web search infrastructure should maintain metadata on duplicate and near-duplicate documents in its index. Near-duplicate detection implemented in an open web search infrastructure should provide a suitable similarity threshold, a difficult choice since identical pages may substantially differ in parts of a page that are irrelevant to searchers (templates, advertisements, etc.). We study this problem by comparing the similarity of pages for five (main) content extraction methods in two studies on the ClueWeb crawls. We find that the full content of pages serves precision-oriented near-duplicate-detection, while main content extraction is more recall-oriented.
SVG-Net: An SVG-based Trajectory Prediction Model
Oct 11, 2021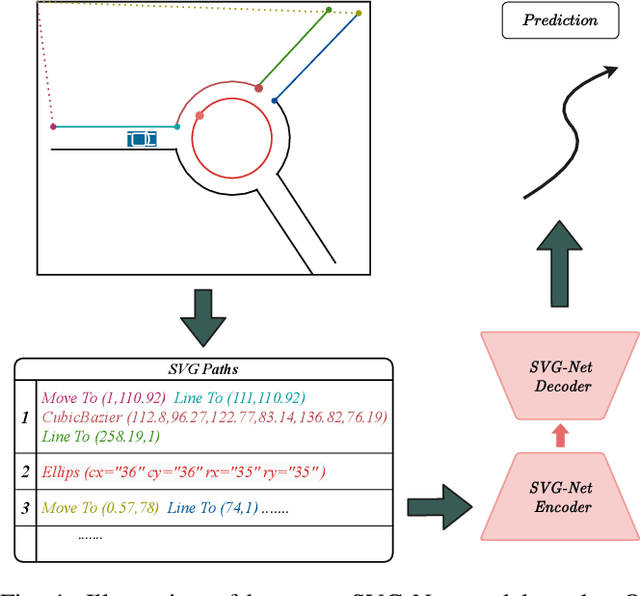
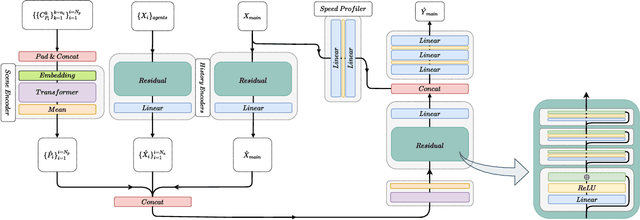
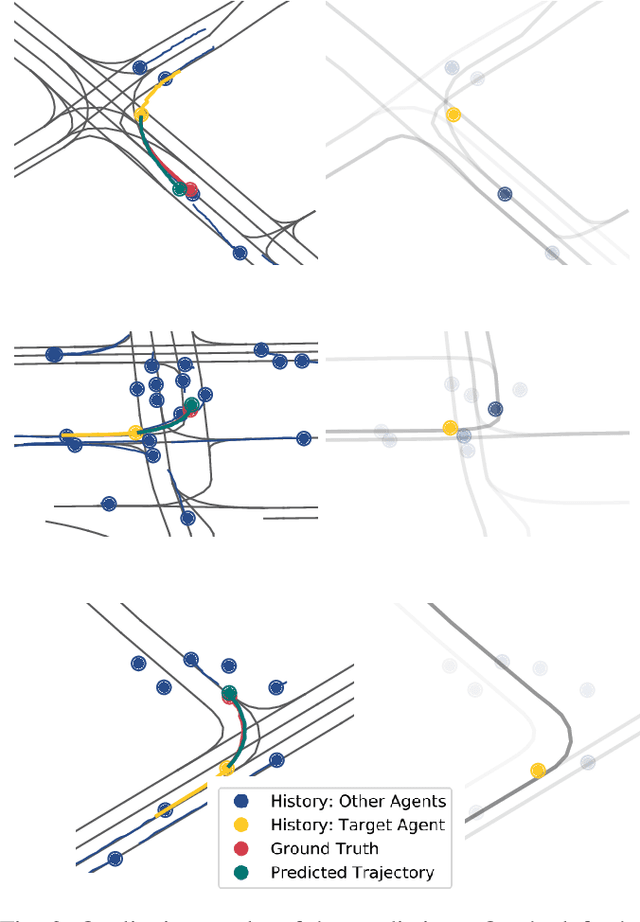
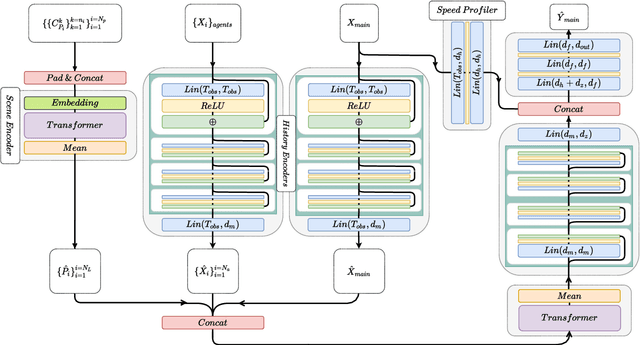
Anticipating motions of vehicles in a scene is an essential problem for safe autonomous driving systems. To this end, the comprehension of the scene's infrastructure is often the main clue for predicting future trajectories. Most of the proposed approaches represent the scene with a rasterized format and some of the more recent approaches leverage custom vectorized formats. In contrast, we propose representing the scene's information by employing Scalable Vector Graphics (SVG). SVG is a well-established format that matches the problem of trajectory prediction better than rasterized formats while being more general than arbitrary vectorized formats. SVG has the potential to provide the convenience and generality of raster-based solutions if coupled with a powerful tool such as CNNs, for which we introduce SVG-Net. SVG-Net is a Transformer-based Neural Network that can effectively capture the scene's information from SVG inputs. Thanks to the self-attention mechanism in its Transformers, SVG-Net can also adequately apprehend relations amongst the scene and the agents. We demonstrate SVG-Net's effectiveness by evaluating its performance on the publicly available Argoverse forecasting dataset. Finally, we illustrate how, by using SVG, one can benefit from datasets and advancements in other research fronts that also utilize the same input format. Our code is available at https://vita-epfl.github.io/SVGNet/.
IR-Net: Forward and Backward Information Retention for Highly Accurate Binary Neural Networks
Sep 25, 2019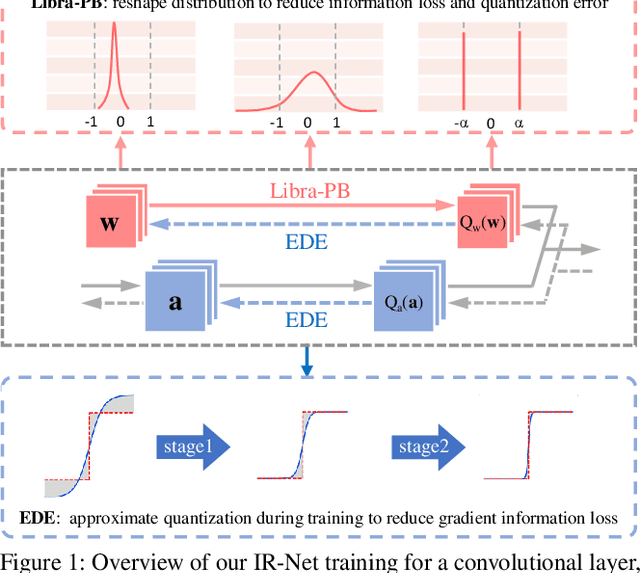

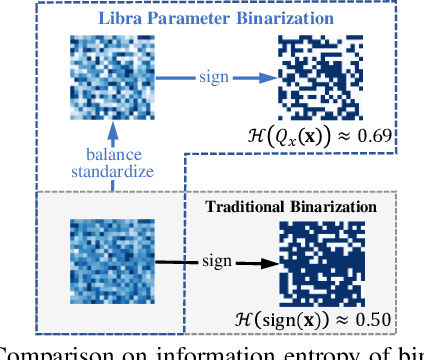
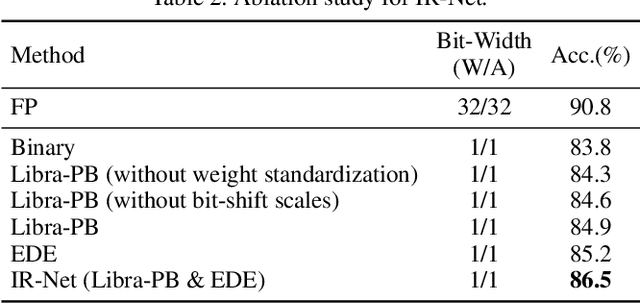
Weight and activation binarization is an effective approach to deep neural network compression and can accelerate the inference by leveraging bitwise operations. Although many binarization methods have improved the accuracy of the model by minimizing the quantization error in forward propagation, there remains a noticeable performance gap between the binarized model and the full-precision one. Our empirical study indicates that the quantization brings information loss in both forward and backward propagation, which is the bottleneck of training highly accurate binary neural networks. To address these issues, we propose an Information Retention Network (IR-Net) to retain the information that consists in the forward activations and backward gradients. IR-Net mainly relies on two technical contributions: (1) Libra Parameter Binarization (Libra-PB): minimize both quantization error and information loss of parameters by balanced and standardized weights in forward propagation; (2) Error Decay Estimator (EDE): minimize the information loss of gradients by gradually approximating the sign function in backward propagation, jointly considering the updating ability and accurate gradients. Comprehensive experiments with various network structures on CIFAR-10 and ImageNet datasets manifest that the proposed IR-Net can consistently outperform state-of-the-art quantization methods.