 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Agent Autonomy: Advancements and Challenges in Subterranean Exploration
Oct 08, 2021

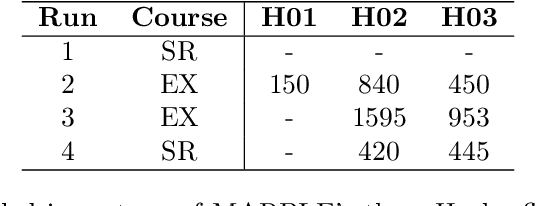
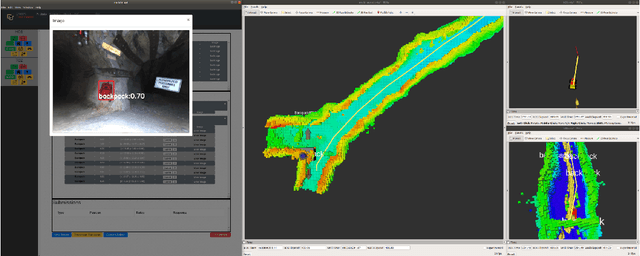
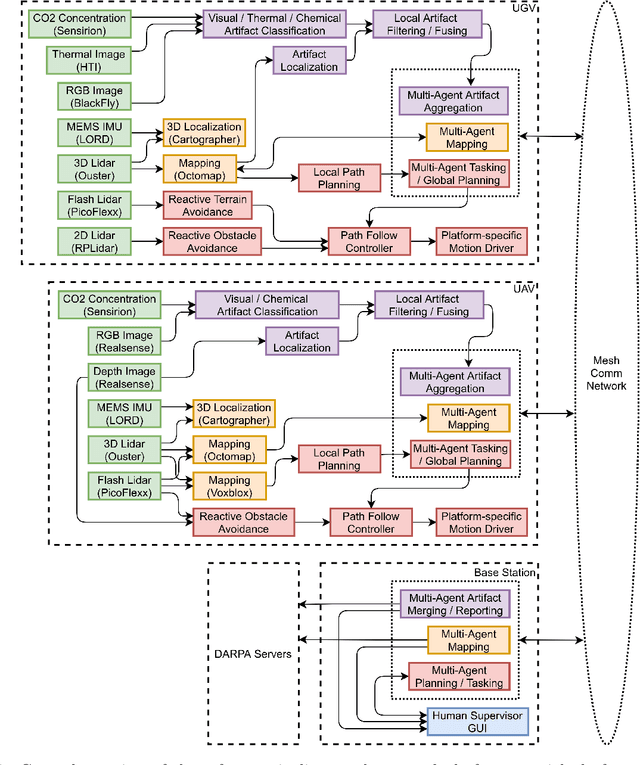
Artificial intelligence has undergone immense growth and maturation in recent years, though autonomous systems have traditionally struggled when fielded in diverse and previously unknown environments. DARPA is seeking to change that with the Subterranean Challenge, by providing roboticists the opportunity to support civilian and military first responders in complex and high-risk underground scenarios. The subterranean domain presents a handful of challenges, such as limited communication, diverse topology and terrain, and degraded sensing. Team MARBLE proposes a solution for autonomous exploration of unknown subterranean environments in which coordinated agents search for artifacts of interest. The team presents two navigation algorithms in the form of a metric-topological graph-based planner and a continuous frontier-based planner. To facilitate multi-agent coordination, agents share and merge new map information and candidate goal-points. Agents deploy communication beacons at different points in the environment, extending the range at which maps and other information can be shared. Onboard autonomy reduces the load on human supervisors, allowing agents to detect and localize artifacts and explore autonomously outside established communication networks. Given the scale, complexity, and tempo of this challenge, a range of lessons were learned, most importantly, that frequent and comprehensive field testing in representative environments is key to rapidly refining system performance.
Identifying Introductions in Podcast Episodes from Automatically Generated Transcripts
Oct 14, 2021
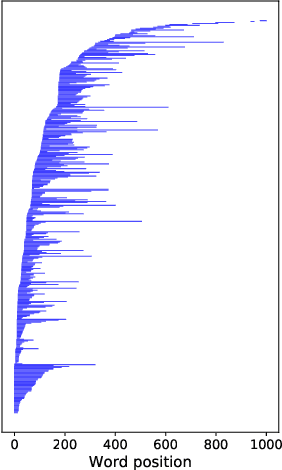
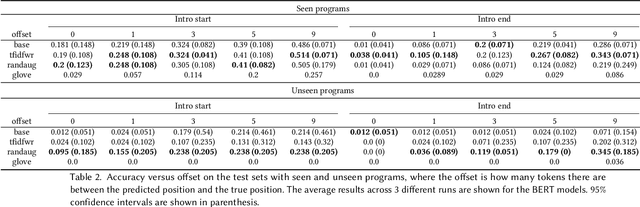
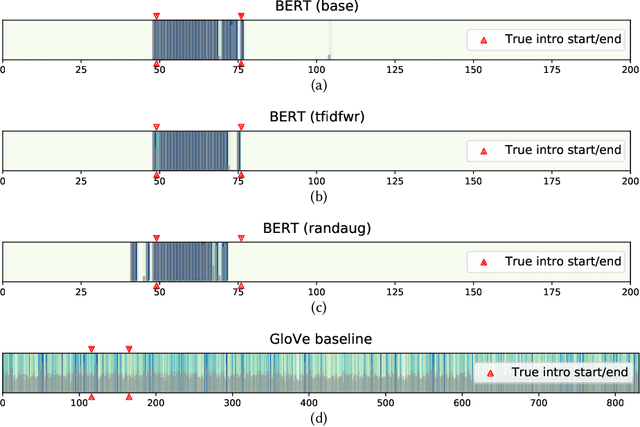
As the volume of long-form spoken-word content such as podcasts explodes, many platforms desire to present short, meaningful, and logically coherent segments extracted from the full content. Such segments can be consumed by users to sample content before diving in, as well as used by the platform to promote and recommend content. However, little published work is focused on the segmentation of spoken-word content, where the errors (noise) in transcripts generated by automatic speech recognition (ASR) services poses many challenges. Here we build a novel dataset of complete transcriptions of over 400 podcast episodes, in which we label the position of introductions in each episode. These introductions contain information about the episodes' topics, hosts, and guests, providing a valuable summary of the episode content, as it is created by the authors. We further augment our dataset with word substitutions to increase the amount of available training data. We train three Transformer models based on the pre-trained BERT and different augmentation strategies, which achieve significantly better performance compared with a static embedding model, showing that it is possible to capture generalized, larger-scale structural information from noisy, loosely-organized speech data. This is further demonstrated through an analysis of the models' inner architecture. Our methods and dataset can be used to facilitate future work on the structure-based segmentation of spoken-word content.
HeMI: Multi-view Embedding in Heterogeneous Graphs
Sep 14, 2021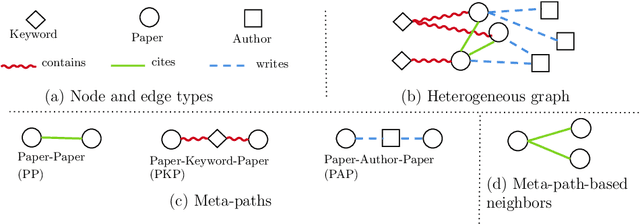
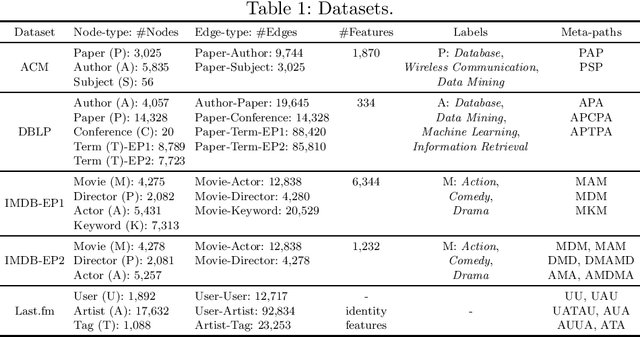
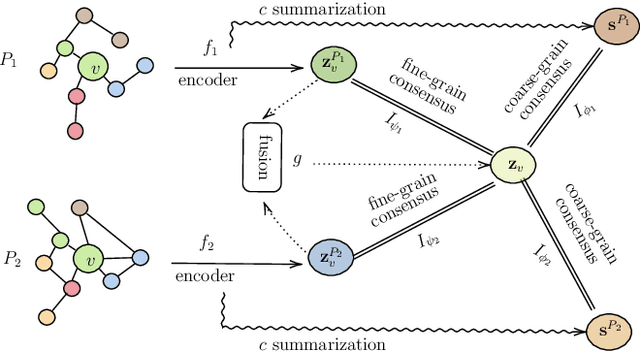
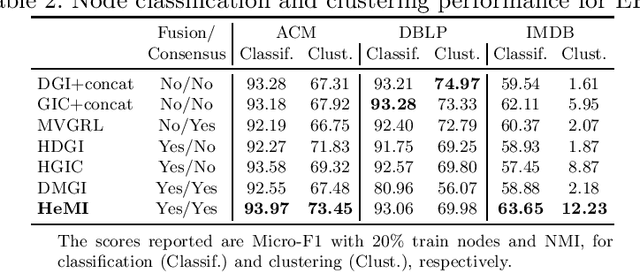
Many real-world graphs involve different types of nodes and relations between nodes, being heterogeneous by nature. The representation learning of heterogeneous graphs (HGs) embeds the rich structure and semantics of such graphs into a low-dimensional space and facilitates various data mining tasks, such as node classification, node clustering, and link prediction. In this paper, we propose a self-supervised method that learns HG representations by relying on knowledge exchange and discovery among different HG structural semantics (meta-paths). Specifically, by maximizing the mutual information of meta-path representations, we promote meta-path information fusion and consensus, and ensure that globally shared semantics are encoded. By extensive experiments on node classification, node clustering, and link prediction tasks, we show that the proposed self-supervision both outperforms and improves competing methods by 1% and up to 10% for all tasks.
Dynamic Allocation of Visual Attention for Vision-based Autonomous Navigation under Data Rate Constraints
Sep 27, 2021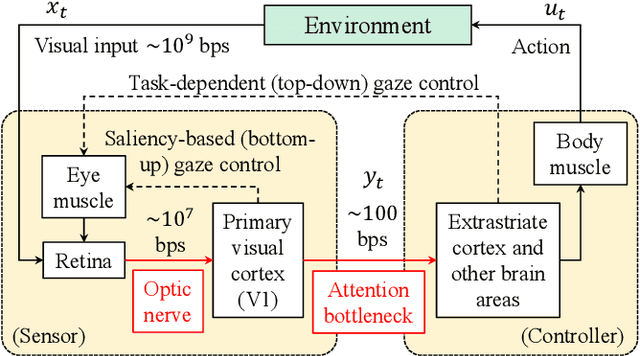

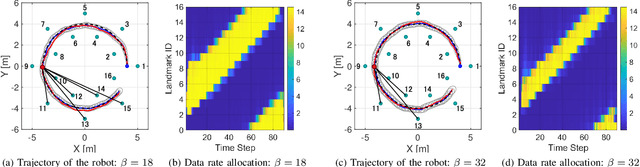
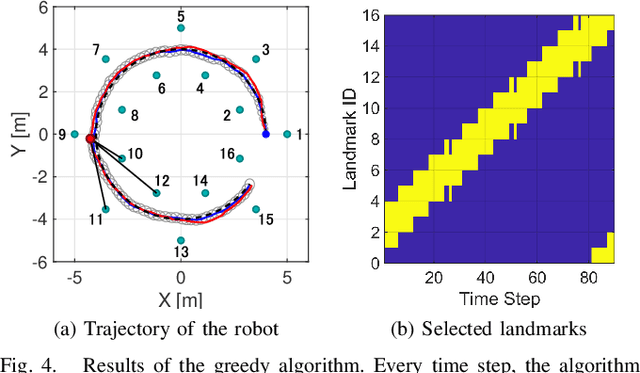
This paper considers the problem of task-dependent (top-down) attention allocation for vision-based autonomous navigation using known landmarks. Unlike the existing paradigm in which landmark selection is formulated as a combinatorial optimization problem, we model it as a resource allocation problem where the decision-maker (DM) is granted extra freedom to control the degree of attention to each landmark. The total resource available to DM is expressed in terms of the capacity limit of the in-take information flow, which is quantified by the directed information from the state of the environment to the DM's observation. We consider a receding horizon implementation of such a controlled sensing scheme in the Linear-Quadratic-Gaussian (LQG) regime. The convex-concave procedure is applied in each time step, whose time complexity is shown to be linear in the horizon length if the alternating direction method of multipliers (ADMM) is used. Numerical studies show that the proposed formulation is sparsity-promoting in the sense that it tends to allocate zero data rate to uninformative landmarks.
Multi-agent Natural Actor-critic Reinforcement Learning Algorithms
Sep 03, 2021
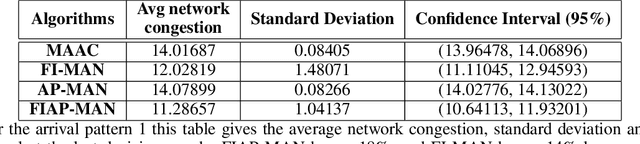
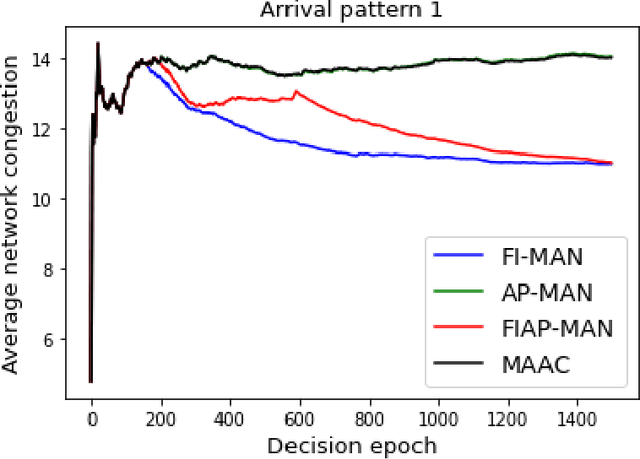
Both single-agent and multi-agent actor-critic algorithms are an important class of Reinforcement Learning algorithms. In this work, we propose three fully decentralized multi-agent natural actor-critic (MAN) algorithms. The agents' objective is to collectively learn a joint policy that maximizes the sum of averaged long-term returns of these agents. In the absence of a central controller, agents communicate the information to their neighbors via a time-varying communication network while preserving privacy. We prove the convergence of all the 3 MAN algorithms to a globally asymptotically stable point of the ODE corresponding to the actor update; these use linear function approximations. We use the Fisher information matrix to obtain the natural gradients. The Fisher information matrix captures the curvature of the Kullback-Leibler (KL) divergence between polices at successive iterates. We also show that the gradient of this KL divergence between policies of successive iterates is proportional to the objective function's gradient. Our MAN algorithms indeed use this \emph{representation} of the objective function's gradient. Under certain conditions on the Fisher information matrix, we prove that at each iterate, the optimal value via MAN algorithms can be better than that of the multi-agent actor-critic (MAAC) algorithm using the standard gradients. To validate the usefulness of our proposed algorithms, we implement all the 3 MAN algorithms on a bi-lane traffic network to reduce the average network congestion. We observe an almost 25% reduction in the average congestion in 2 MAN algorithms; the average congestion in another MAN algorithm is on par with the MAAC algorithm. We also consider a generic 15 agent MARL; the performance of the MAN algorithms is again as good as the MAAC algorithm. We attribute the better performance of the MAN algorithms to their use of the above representation.
VMNet: Voxel-Mesh Network for Geodesic-Aware 3D Semantic Segmentation
Jul 29, 2021
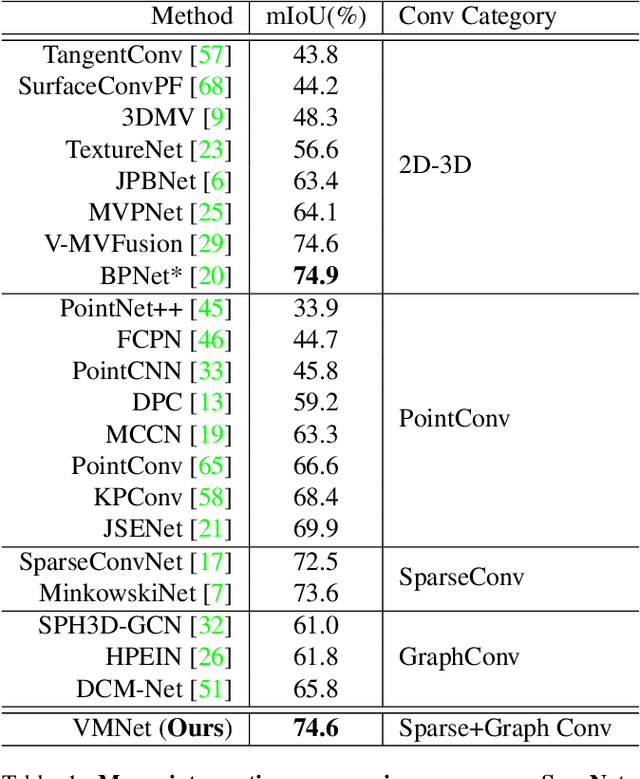
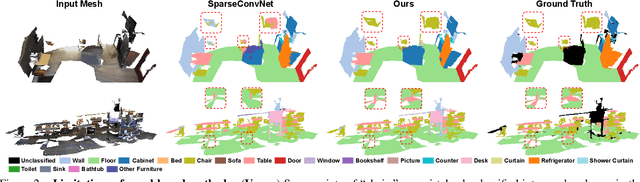

In recent years, sparse voxel-based methods have become the state-of-the-arts for 3D semantic segmentation of indoor scenes, thanks to the powerful 3D CNNs. Nevertheless, being oblivious to the underlying geometry, voxel-based methods suffer from ambiguous features on spatially close objects and struggle with handling complex and irregular geometries due to the lack of geodesic information. In view of this, we present Voxel-Mesh Network (VMNet), a novel 3D deep architecture that operates on the voxel and mesh representations leveraging both the Euclidean and geodesic information. Intuitively, the Euclidean information extracted from voxels can offer contextual cues representing interactions between nearby objects, while the geodesic information extracted from meshes can help separate objects that are spatially close but have disconnected surfaces. To incorporate such information from the two domains, we design an intra-domain attentive module for effective feature aggregation and an inter-domain attentive module for adaptive feature fusion. Experimental results validate the effectiveness of VMNet: specifically, on the challenging ScanNet dataset for large-scale segmentation of indoor scenes, it outperforms the state-of-the-art SparseConvNet and MinkowskiNet (74.6% vs 72.5% and 73.6% in mIoU) with a simpler network structure (17M vs 30M and 38M parameters). Code release: https://github.com/hzykent/VMNet
On Lyapunov Exponents for RNNs: Understanding Information Propagation Using Dynamical Systems Tools
Jun 25, 2020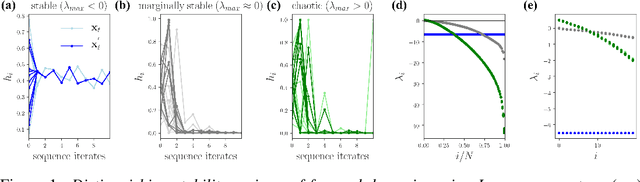

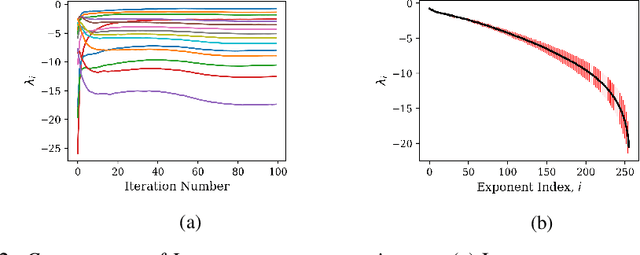
Recurrent neural networks (RNNs) have been successfully applied to a variety of problems involving sequential data, but their optimization is sensitive to parameter initialization, architecture, and optimizer hyperparameters. Considering RNNs as dynamical systems, a natural way to capture stability, i.e., the growth and decay over long iterates, are the Lyapunov Exponents (LEs), which form the Lyapunov spectrum. The LEs have a bearing on stability of RNN training dynamics because forward propagation of information is related to the backward propagation of error gradients. LEs measure the asymptotic rates of expansion and contraction of nonlinear system trajectories, and generalize stability analysis to the time-varying attractors structuring the non-autonomous dynamics of data-driven RNNs. As a tool to understand and exploit stability of training dynamics, the Lyapunov spectrum fills an existing gap between prescriptive mathematical approaches of limited scope and computationally-expensive empirical approaches. To leverage this tool, we implement an efficient way to compute LEs for RNNs during training, discuss the aspects specific to standard RNN architectures driven by typical sequential datasets, and show that the Lyapunov spectrum can serve as a robust readout of training stability across hyperparameters. With this exposition-oriented contribution, we hope to draw attention to this understudied, but theoretically grounded tool for understanding training stability in RNNs.
ACE-BERT: Adversarial Cross-modal Enhanced BERT for E-commerce Retrieval
Dec 14, 2021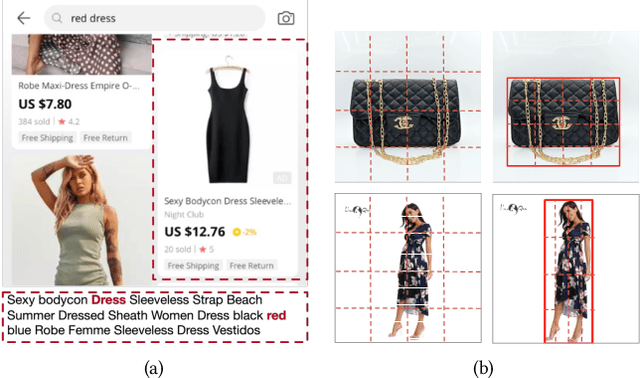

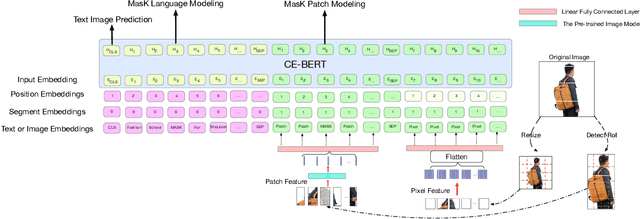

Nowadays on E-commerce platforms, products are presented to the customers with multiple modalities. These multiple modalities are significant for a retrieval system while providing attracted products for customers. Therefore, how to take into account those multiple modalities simultaneously to boost the retrieval performance is crucial. This problem is a huge challenge to us due to the following reasons: (1) the way of extracting patch features with the pre-trained image model (e.g., CNN-based model) has much inductive bias. It is difficult to capture the efficient information from the product image in E-commerce. (2) The heterogeneity of multimodal data makes it challenging to construct the representations of query text and product including title and image in a common subspace. We propose a novel Adversarial Cross-modal Enhanced BERT (ACE-BERT) for efficient E-commerce retrieval. In detail, ACE-BERT leverages the patch features and pixel features as image representation. Thus the Transformer architecture can be applied directly to the raw image sequences. With the pre-trained enhanced BERT as the backbone network, ACE-BERT further adopts adversarial learning by adding a domain classifier to ensure the distribution consistency of different modality representations for the purpose of narrowing down the representation gap between query and product. Experimental results demonstrate that ACE-BERT outperforms the state-of-the-art approaches on the retrieval task. It is remarkable that ACE-BERT has already been deployed in our E-commerce's search engine, leading to 1.46% increase in revenue.
Data-driven Set-based Estimation of Polynomial Systems with Application to SIR Epidemics
Nov 08, 2021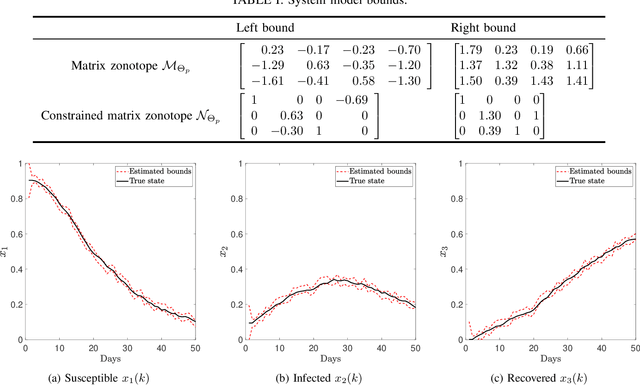
This paper proposes a data-driven set-based estimation algorithm for a class of nonlinear systems with polynomial nonlinearities. Using the system's input-output data, the proposed method computes in real-time a set that guarantees the inclusion of the system's state. Although the system is assumed to be polynomial type, the exact polynomial functions and their coefficients need not be known. To this end, the estimator relies on offline and online phases. The offline phase utilizes past input-output data to estimate a set of possible coefficients of the polynomial system. Then, using this estimated set of coefficients and the side information about the system, the online phase provides a set estimate of the state. Finally, the proposed methodology is evaluated through its application on SIR (Susceptible, Infected, Recovered) epidemic model.
Mitigating Information Leakage in Image Representations: A Maximum Entropy Approach
Apr 11, 2019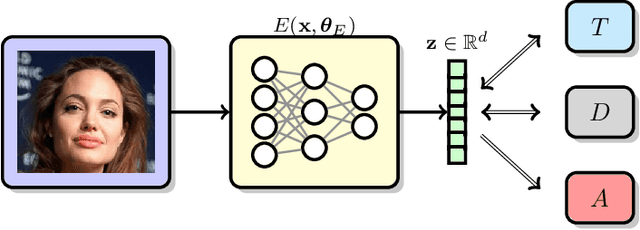
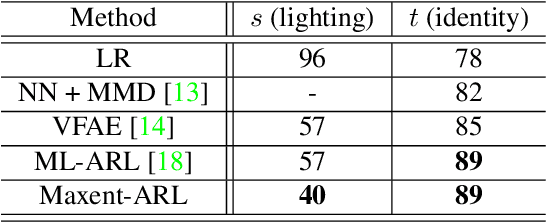
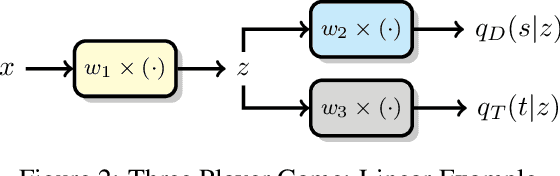
Image recognition systems have demonstrated tremendous progress over the past few decades thanks, in part, to our ability of learning compact and robust representations of images. As we witness the wide spread adoption of these systems, it is imperative to consider the problem of unintended leakage of information from an image representation, which might compromise the privacy of the data owner. This paper investigates the problem of learning an image representation that minimizes such leakage of user information. We formulate the problem as an adversarial non-zero sum game of finding a good embedding function with two competing goals: to retain as much task dependent discriminative image information as possible, while simultaneously minimizing the amount of information, as measured by entropy, about other sensitive attributes of the user. We analyze the stability and convergence dynamics of the proposed formulation using tools from non-linear systems theory and compare to that of the corresponding adversarial zero-sum game formulation that optimizes likelihood as a measure of information content. Numerical experiments on UCI, Extended Yale B, CIFAR-10 and CIFAR-100 datasets indicate that our proposed approach is able to learn image representations that exhibit high task performance while mitigating leakage of predefined sensitive information.