 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Unsupervised Deep Unfolding Framework for robust Symbol Level Precoding
Nov 15, 2021
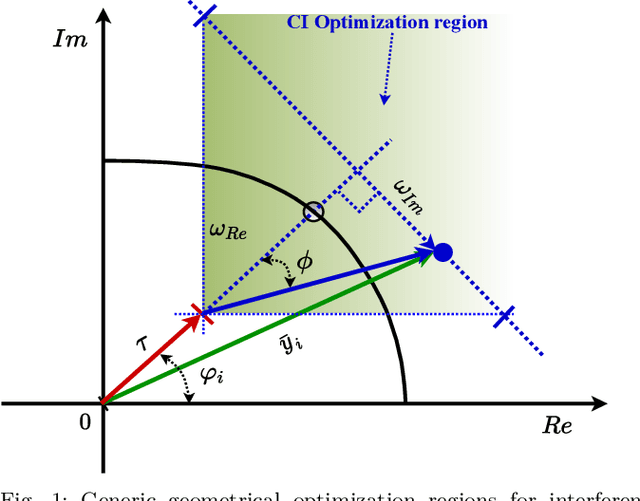
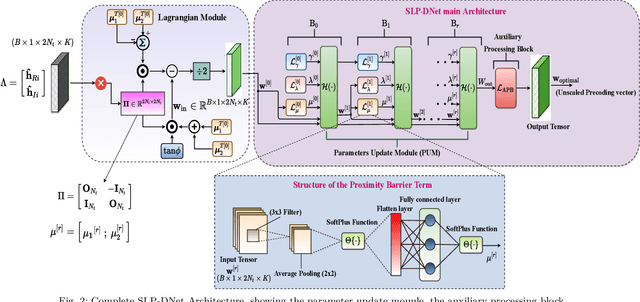
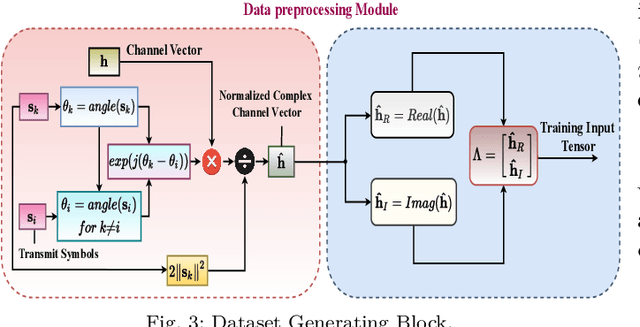

Symbol Level Precoding (SLP) has attracted significant research interest due to its ability to exploit interference for energy-efficient transmission. This paper proposes an unsupervised deep-neural network (DNN) based SLP framework. Instead of naively training a DNN architecture for SLP without considering the specifics of the optimization objective of the SLP domain, our proposal unfolds a power minimization SLP formulation based on the interior point method (IPM) proximal `log' barrier function. Furthermore, we extend our proposal to a robust precoding design under channel state information (CSI) uncertainty. The results show that our proposed learning framework provides near-optimal performance while reducing the computational cost from O(n7.5) to O(n3) for the symmetrical system case where n = number of transmit antennas = number of users. This significant complexity reduction is also reflected in a proportional decrease in the proposed approach's execution time compared to the SLP optimization-based solution.
A Priori Calibration of Transient Kinetics Data via Machine Learning
Sep 27, 2021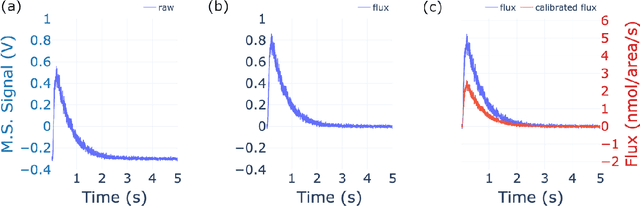
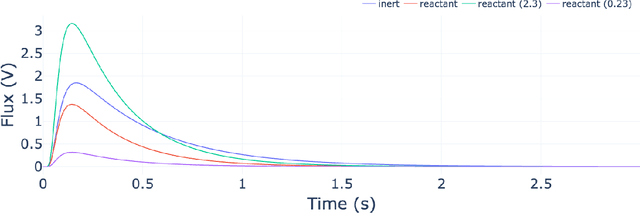
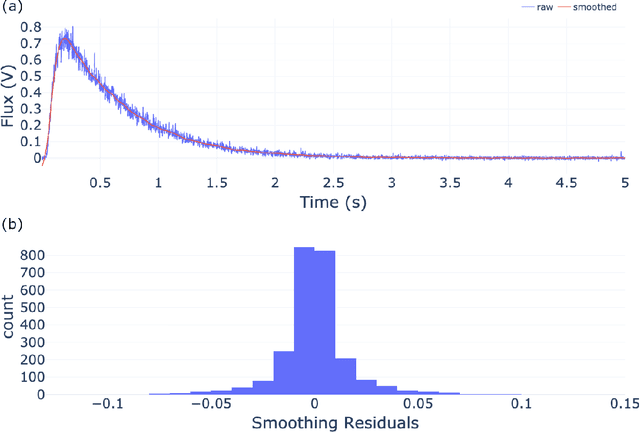
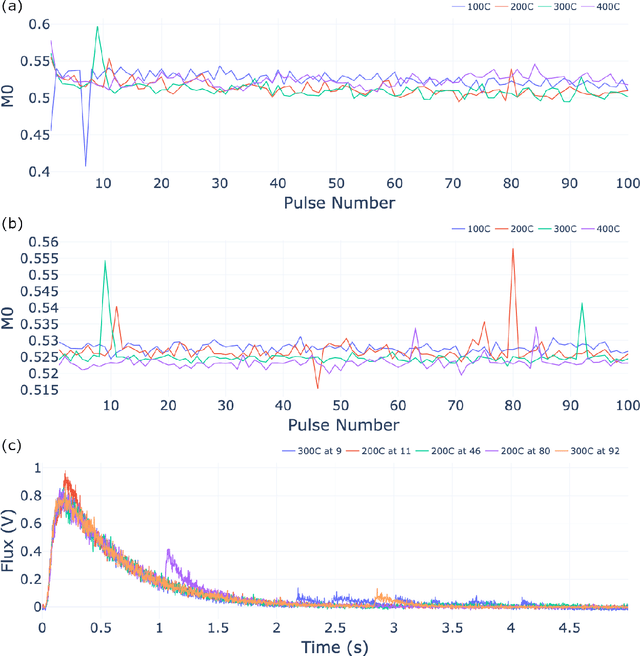
The temporal analysis of products reactor provides a vast amount of transient kinetic information that may be used to describe a variety of chemical features including the residence time distribution, kinetic coefficients, number of active sites, and the reaction mechanism. However, as with any measurement device, the TAP reactor signal is convoluted with noise. To reduce the uncertainty of the kinetic measurement and any derived parameters or mechanisms, proper preprocessing must be performed prior to any advanced analysis. This preprocessing consists of baseline correction, i.e., a shift in the voltage response, and calibration, i.e., a scaling of the flux response based on prior experiments. The current methodology of preprocessing requires significant user discretion and reliance on previous experiments that may drift over time. Herein we use machine learning techniques combined with physical constraints to convert the raw instrument signal to chemical information. As such, the proposed methodology demonstrates clear benefits over the traditional preprocessing in the calibration of the inert and feed mixture products without need of prior calibration experiments or heuristic input from the user.
An Image Patch is a Wave: Phase-Aware Vision MLP
Nov 25, 2021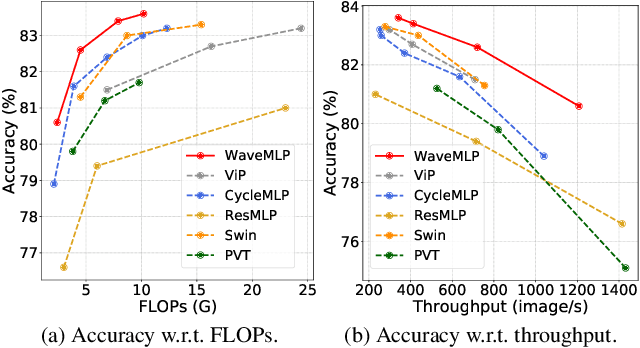
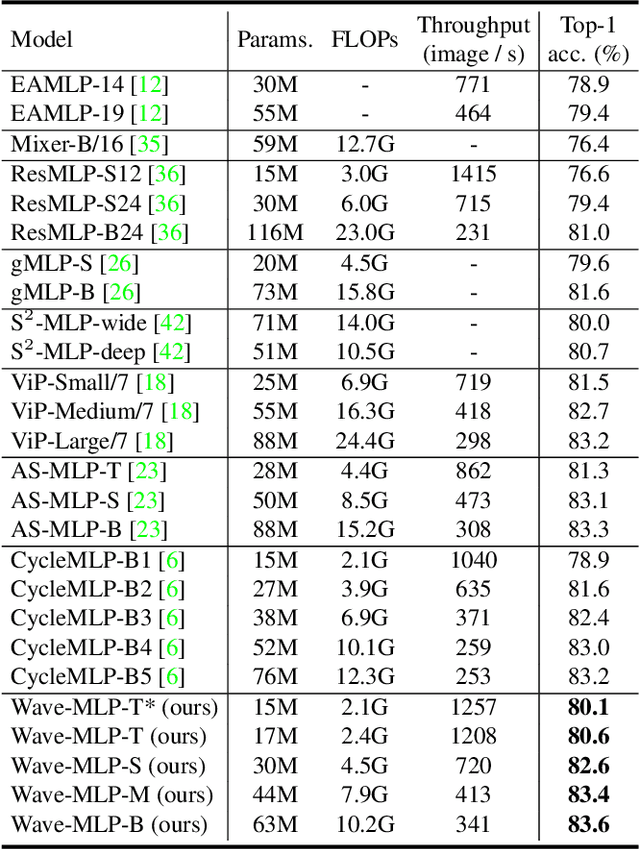
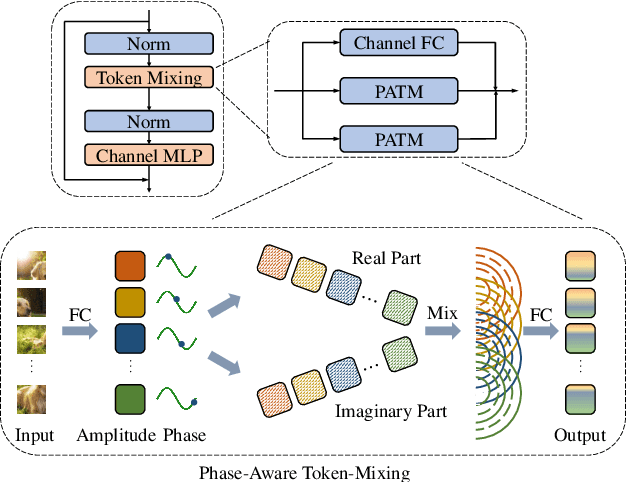
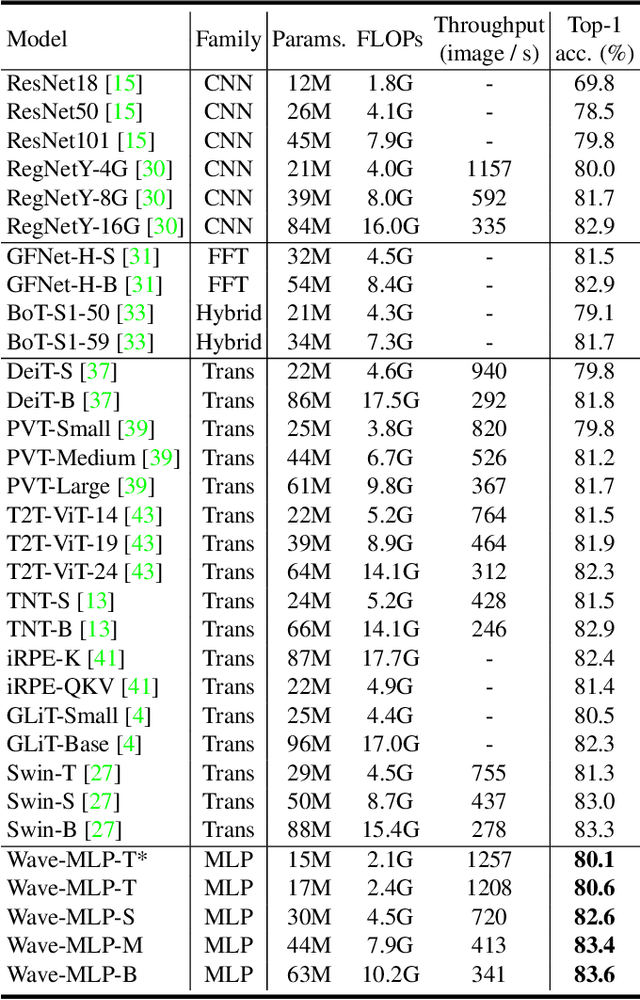
Different from traditional convolutional neural network (CNN) and vision transformer, the multilayer perceptron (MLP) is a new kind of vision model with extremely simple architecture that only stacked by fully-connected layers. An input image of vision MLP is usually split into multiple tokens (patches), while the existing MLP models directly aggregate them with fixed weights, neglecting the varying semantic information of tokens from different images. To dynamically aggregate tokens, we propose to represent each token as a wave function with two parts, amplitude and phase. Amplitude is the original feature and the phase term is a complex value changing according to the semantic contents of input images. Introducing the phase term can dynamically modulate the relationship between tokens and fixed weights in MLP. Based on the wave-like token representation, we establish a novel Wave-MLP architecture for vision tasks. Extensive experiments demonstrate that the proposed Wave-MLP is superior to the state-of-the-art MLP architectures on various vision tasks such as image classification, object detection and semantic segmentation.
You Only Need End-to-End Training for Long-Tailed Recognition
Dec 14, 2021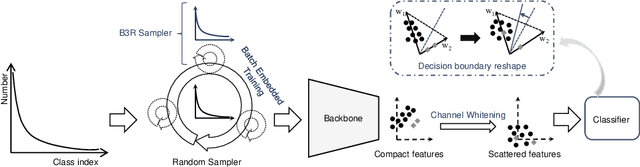
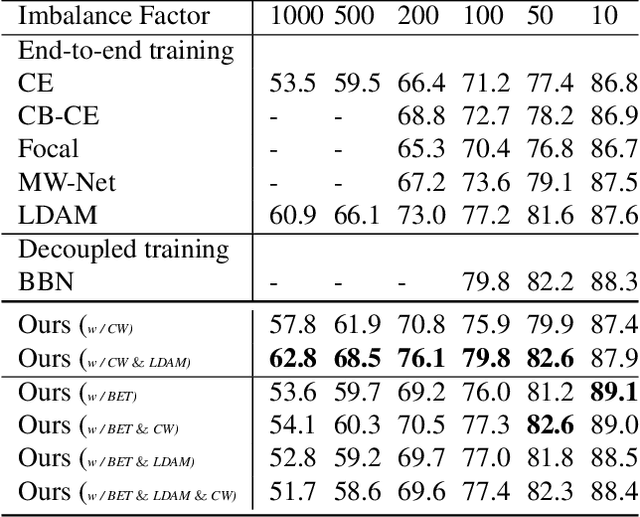
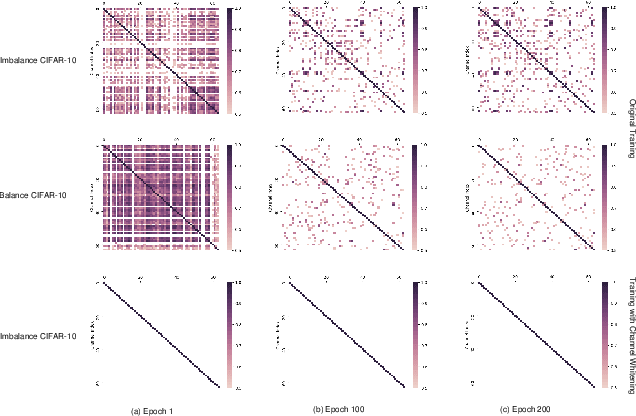
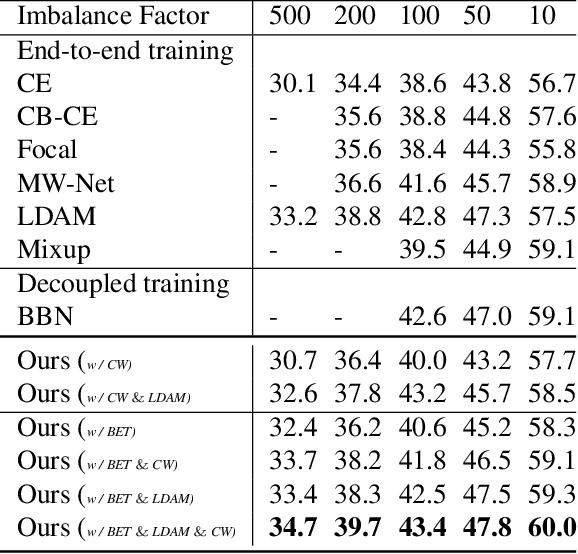
The generalization gap on the long-tailed data sets is largely owing to most categories only occupying a few training samples. Decoupled training achieves better performance by training backbone and classifier separately. What causes the poorer performance of end-to-end model training (e.g., logits margin-based methods)? In this work, we identify a key factor that affects the learning of the classifier: the channel-correlated features with low entropy before inputting into the classifier. From the perspective of information theory, we analyze why cross-entropy loss tends to produce highly correlated features on the imbalanced data. In addition, we theoretically analyze and prove its impacts on the gradients of classifier weights, the condition number of Hessian, and logits margin-based approach. Therefore, we firstly propose to use Channel Whitening to decorrelate ("scatter") the classifier's inputs for decoupling the weight update and reshaping the skewed decision boundary, which achieves satisfactory results combined with logits margin-based method. However, when the number of minor classes are large, batch imbalance and more participation in training cause over-fitting of the major classes. We also propose two novel modules, Block-based Relatively Balanced Batch Sampler (B3RS) and Batch Embedded Training (BET) to solve the above problems, which makes the end-to-end training achieve even better performance than decoupled training. Experimental results on the long-tailed classification benchmarks, CIFAR-LT and ImageNet-LT, demonstrate the effectiveness of our method.
Mitigating Information Leakage in Image Representations: A Maximum Entropy Approach
Apr 11, 2019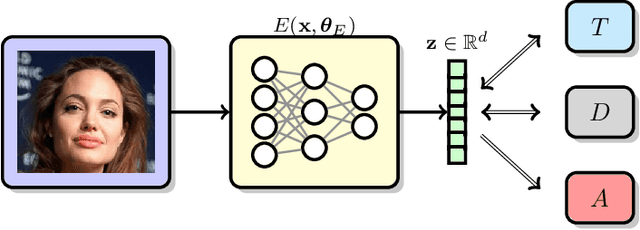
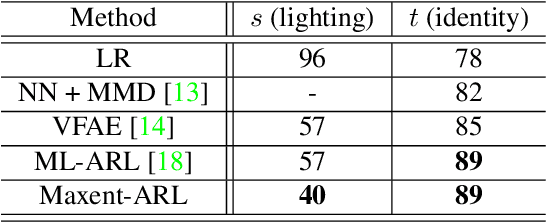
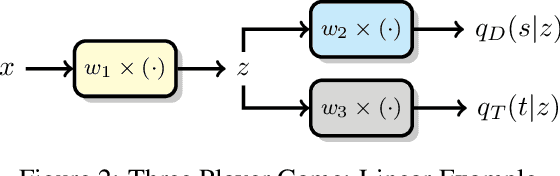
Image recognition systems have demonstrated tremendous progress over the past few decades thanks, in part, to our ability of learning compact and robust representations of images. As we witness the wide spread adoption of these systems, it is imperative to consider the problem of unintended leakage of information from an image representation, which might compromise the privacy of the data owner. This paper investigates the problem of learning an image representation that minimizes such leakage of user information. We formulate the problem as an adversarial non-zero sum game of finding a good embedding function with two competing goals: to retain as much task dependent discriminative image information as possible, while simultaneously minimizing the amount of information, as measured by entropy, about other sensitive attributes of the user. We analyze the stability and convergence dynamics of the proposed formulation using tools from non-linear systems theory and compare to that of the corresponding adversarial zero-sum game formulation that optimizes likelihood as a measure of information content. Numerical experiments on UCI, Extended Yale B, CIFAR-10 and CIFAR-100 datasets indicate that our proposed approach is able to learn image representations that exhibit high task performance while mitigating leakage of predefined sensitive information.
On Lyapunov Exponents for RNNs: Understanding Information Propagation Using Dynamical Systems Tools
Jun 25, 2020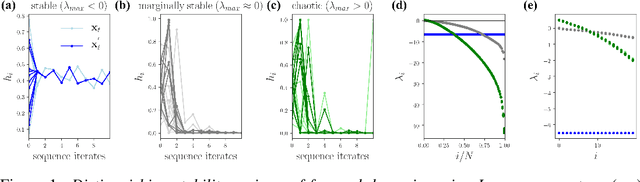

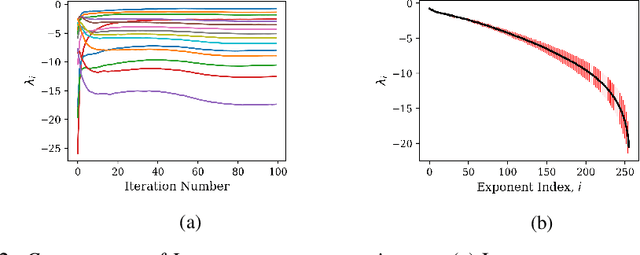
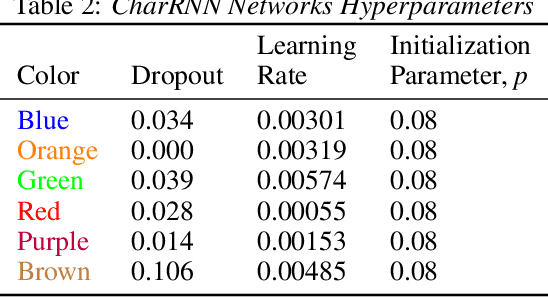
Recurrent neural networks (RNNs) have been successfully applied to a variety of problems involving sequential data, but their optimization is sensitive to parameter initialization, architecture, and optimizer hyperparameters. Considering RNNs as dynamical systems, a natural way to capture stability, i.e., the growth and decay over long iterates, are the Lyapunov Exponents (LEs), which form the Lyapunov spectrum. The LEs have a bearing on stability of RNN training dynamics because forward propagation of information is related to the backward propagation of error gradients. LEs measure the asymptotic rates of expansion and contraction of nonlinear system trajectories, and generalize stability analysis to the time-varying attractors structuring the non-autonomous dynamics of data-driven RNNs. As a tool to understand and exploit stability of training dynamics, the Lyapunov spectrum fills an existing gap between prescriptive mathematical approaches of limited scope and computationally-expensive empirical approaches. To leverage this tool, we implement an efficient way to compute LEs for RNNs during training, discuss the aspects specific to standard RNN architectures driven by typical sequential datasets, and show that the Lyapunov spectrum can serve as a robust readout of training stability across hyperparameters. With this exposition-oriented contribution, we hope to draw attention to this understudied, but theoretically grounded tool for understanding training stability in RNNs.
Material Classification Using Active Temperature Controllable Robotic Gripper
Nov 30, 2021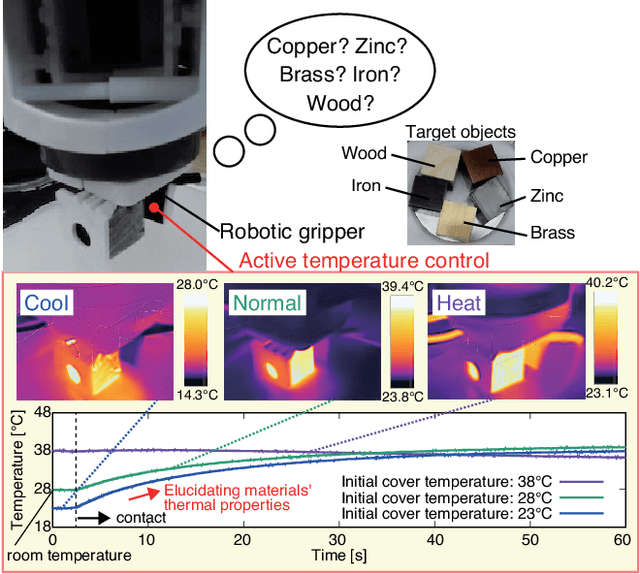

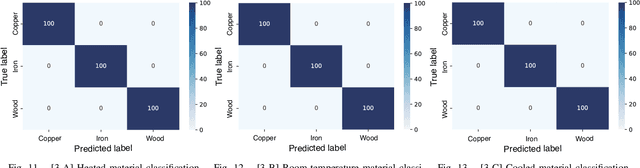
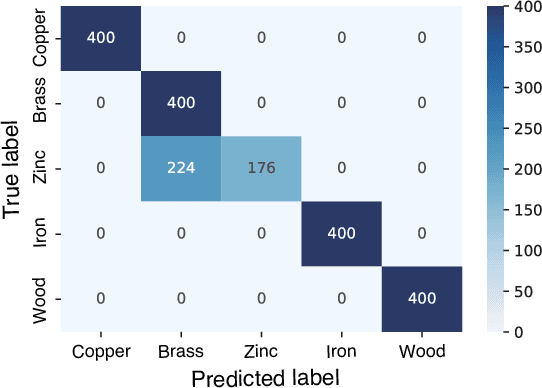
Recognition techniques allow robots to make proper planning and control strategies to manipulate various objects. Object recognition is more reliable when made by combining several percepts, e.g., vision and haptics. One of the distinguishing features of each object's material is its heat properties, and classification can exploit heat transfer, similarly to human thermal sensation. Thermal-based recognition has the advantage of obtaining contact surface information in realtime by simply capturing temperature change using a tiny and cheap sensor. However, heat transfer between a robot surface and a contact object is strongly affected by the initial temperature and environmental conditions. A given object's material cannot be recognized when its temperature is the same as the robotic grippertip. We present a material classification system using active temperature controllable robotic gripper to induce heat flow. Subsequently, our system can recognize materials independently from their ambient temperature. The robotic gripper surface can be regulated to any temperature that differentiates it from the touched object's surface. We conducted some experiments by integrating the temperature control system with the Academic SCARA Robot, classifying them based on a long short-term memory (LSTM) using temperature data obtained from grasping target objects.
Extracting and Measuring Uncertain Biomedical Knowledge from Scientific Statements
Dec 05, 2021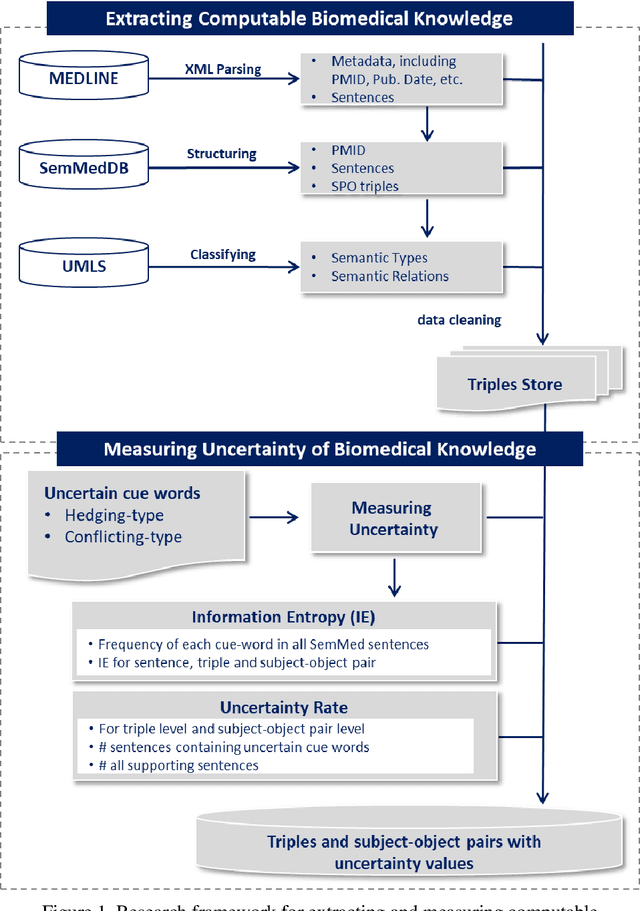

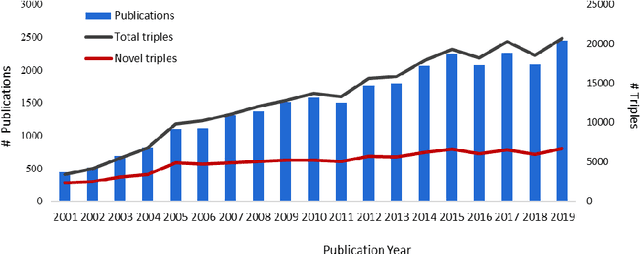
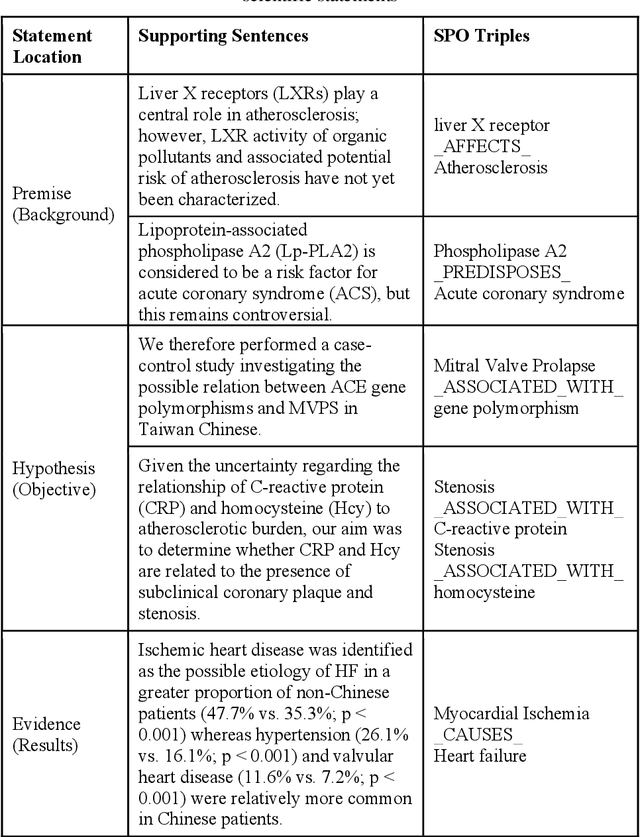
Purpose: This study aims to develop a novel approach to extracting and measuring uncertain biomedical knowledge from scientific statements. Design/methodology/approach: Taking cardiovascular research publications in China as a sample, we extracted the SPO triples as knowledge unit and the hedging/conflicting uncertainties as the knowledge context. We introduced Information Entropy and Uncertainty Rate as potential metrics to quantity the uncertainty of biomedical knowledge claims represented at different levels, such as the SPO triples (micro level), as well as the semantic type pairs (micro-level). Findings: The results indicated that while the number of scientific publications and total SPO triples showed a liner growth, the novel SPO triples occurring per year remained stable. After examining the frequency of uncertain cue words in different part of scientific statements, we found hedging words tend to appear in conclusive and purposeful sentences, whereas conflicting terms often appear in background and act as the premise (e.g., unsettled scientific issues) of the work to be investigated. Practical implications: Our approach identified major uncertain knowledge areas, such as diagnostic biomarkers, genetic characteristics, and pharmacologic therapies surrounding cardiovascular diseases in China. These areas are suggested to be prioritized in which new hypotheses need to be verified, and disputes, conflicts, as well as contradictions to be settled further.
LOLNeRF: Learn from One Look
Nov 19, 2021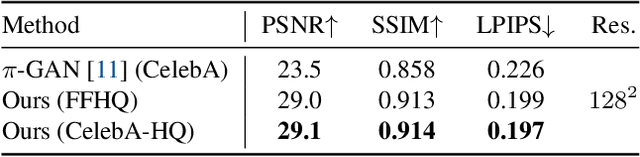
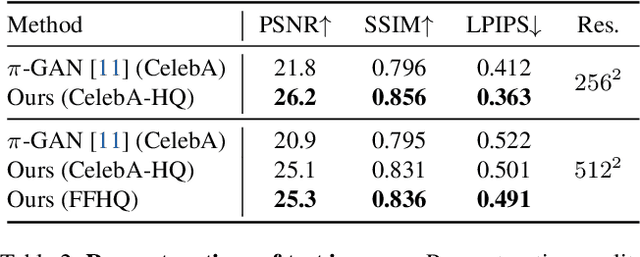

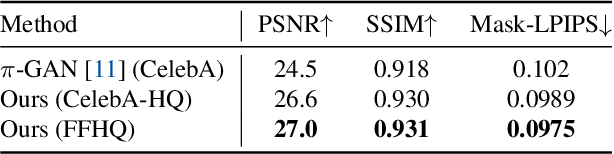
We present a method for learning a generative 3D model based on neural radiance fields, trained solely from data with only single views of each object. While generating realistic images is no longer a difficult task, producing the corresponding 3D structure such that they can be rendered from different views is non-trivial. We show that, unlike existing methods, one does not need multi-view data to achieve this goal. Specifically, we show that by reconstructing many images aligned to an approximate canonical pose with a single network conditioned on a shared latent space, you can learn a space of radiance fields that models shape and appearance for a class of objects. We demonstrate this by training models to reconstruct object categories using datasets that contain only one view of each subject without depth or geometry information. Our experiments show that we achieve state-of-the-art results in novel view synthesis and competitive results for monocular depth prediction.
A Hybrid Spatial-temporal Deep Learning Architecture for Lane Detection
Oct 14, 2021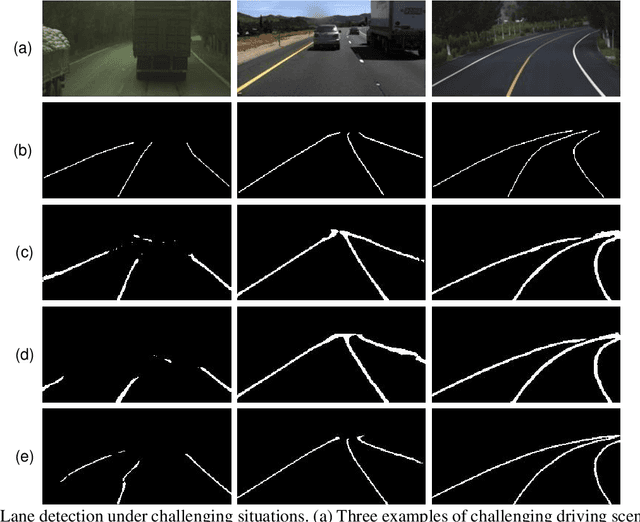
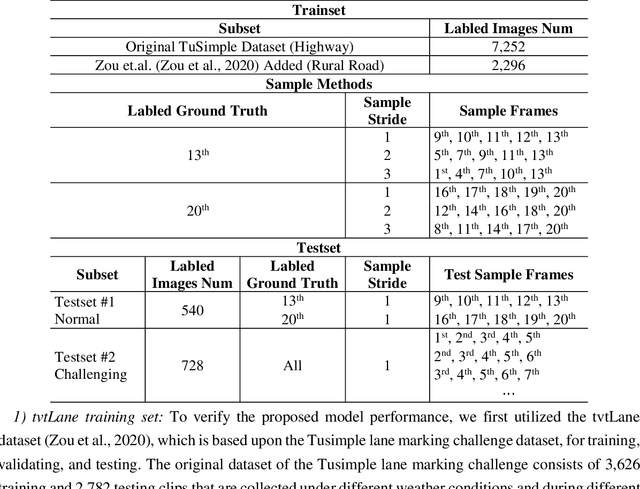
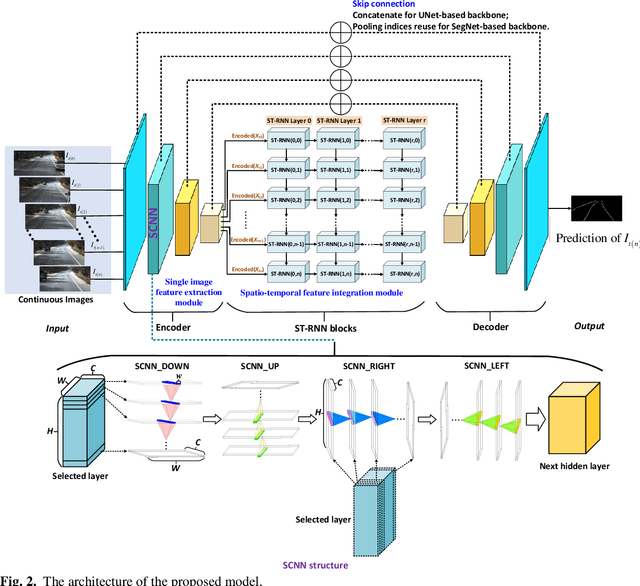
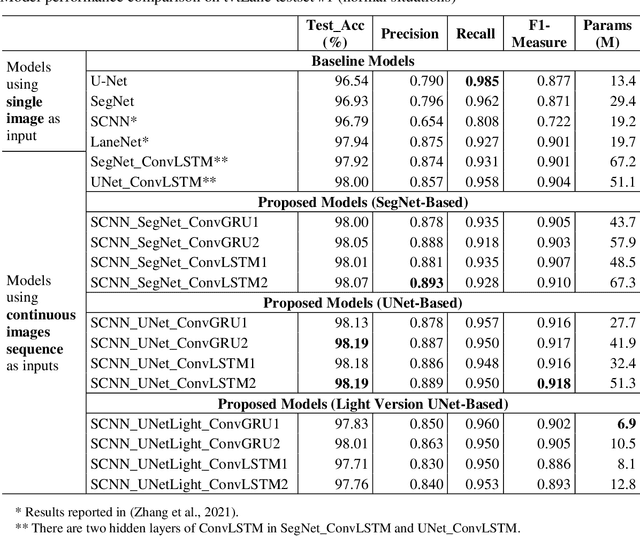
Reliable and accurate lane detection is of vital importance for the safe performance of Lane Keeping Assistance and Lane Departure Warning systems. However, under certain challenging peculiar circumstances, it is difficult to get satisfactory performance in accurately detecting the lanes from one single image which is often the case in current literature. Since lane markings are continuous lines, the lanes that are difficult to be accurately detected in the single current image can potentially be better deduced if information from previous frames is incorporated. This study proposes a novel hybrid spatial-temporal sequence-to-one deep learning architecture making full use of the spatial-temporal information in multiple continuous image frames to detect lane markings in the very last current frame. Specifically, the hybrid model integrates the single image feature extraction module with the spatial convolutional neural network (SCNN) embedded for excavating spatial features and relationships in one single image, the spatial-temporal feature integration module with spatial-temporal recurrent neural network (ST-RNN), which can capture the spatial-temporal correlations and time dependencies among image sequences, and the encoder-decoder structure, which makes this image segmentation problem work in an end-to-end supervised learning format. Extensive experiments reveal that the proposed model can effectively handle challenging driving scenes and outperforms available state-of-the-art methods with a large margin.