 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Superpixel-Based Building Damage Detection from Post-earthquake Very High Resolution Imagery Using Deep Neural Networks
Dec 10, 2021
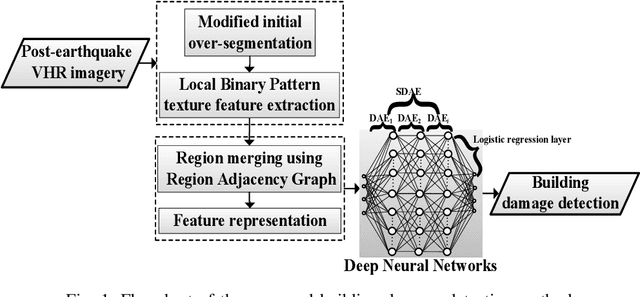
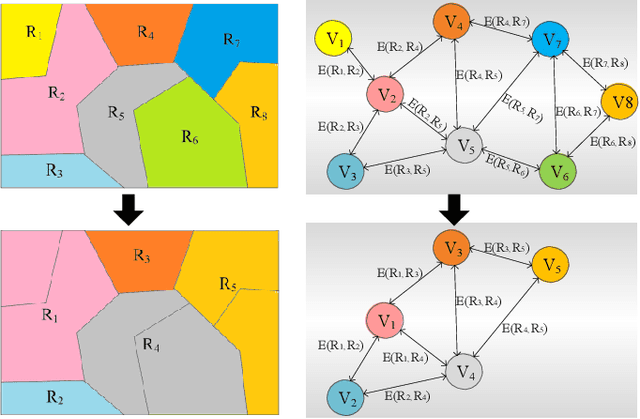
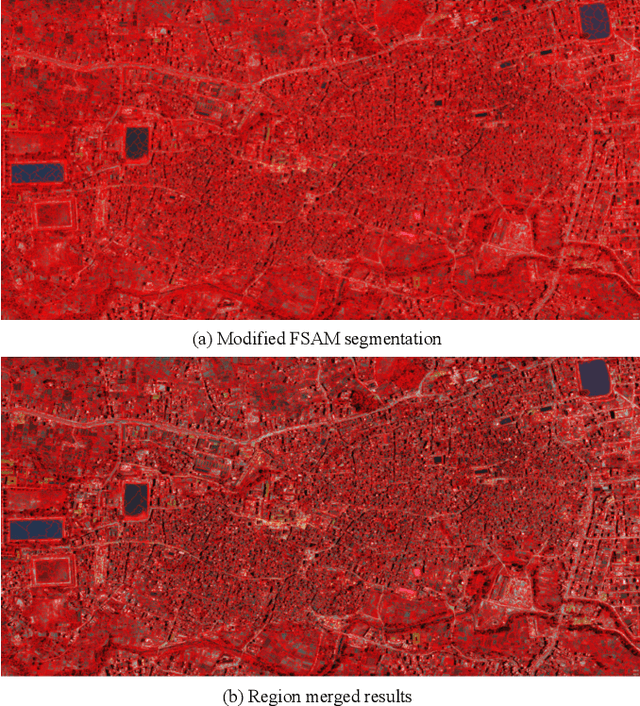
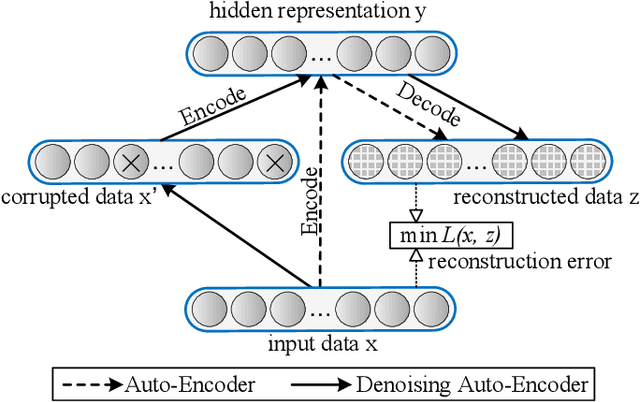
Building damage detection after natural disasters like earthquakes is crucial for initiating effective emergency response actions. Remotely sensed very high spatial resolution (VHR) imagery can provide vital information due to their ability to map the affected buildings with high geometric precision. Many approaches have been developed to detect damaged buildings due to earthquakes. However, little attention has been paid to exploiting rich features represented in VHR images using Deep Neural Networks (DNN). This paper presents a novel super-pixel based approach combining DNN and a modified segmentation method, to detect damaged buildings from VHR imagery. Firstly, a modified Fast Scanning and Adaptive Merging method is extended to create initial over-segmentation. Secondly, the segments are merged based on the Region Adjacent Graph (RAG), considered an improved semantic similarity criterion composed of Local Binary Patterns (LBP) texture, spectral, and shape features. Thirdly, a pre-trained DNN using Stacked Denoising Auto-Encoders called SDAE-DNN is presented, to exploit the rich semantic features for building damage detection. Deep-layer feature abstraction of SDAE-DNN could boost detection accuracy through learning more intrinsic and discriminative features, which outperformed other methods using state-of-the-art alternative classifiers. We demonstrate the feasibility and effectiveness of our method using a subset of WorldView-2 imagery, in the complex urban areas of Bhaktapur, Nepal, which was affected by the Nepal Earthquake of April 25, 2015.
Material Classification Using Active Temperature Controllable Robotic Gripper
Nov 30, 2021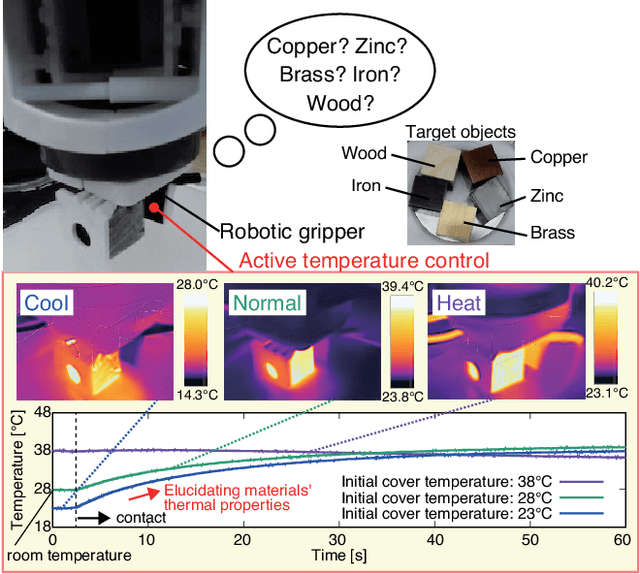

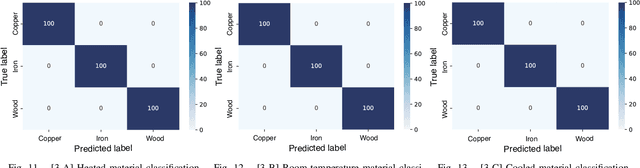
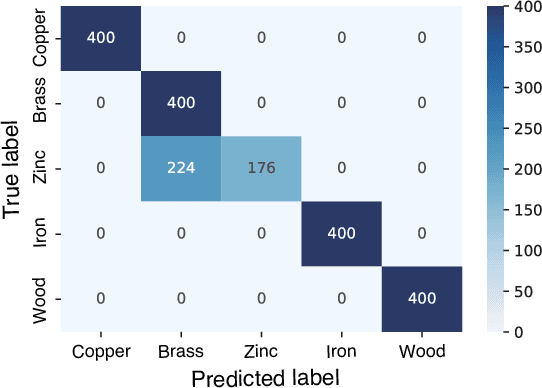
Recognition techniques allow robots to make proper planning and control strategies to manipulate various objects. Object recognition is more reliable when made by combining several percepts, e.g., vision and haptics. One of the distinguishing features of each object's material is its heat properties, and classification can exploit heat transfer, similarly to human thermal sensation. Thermal-based recognition has the advantage of obtaining contact surface information in realtime by simply capturing temperature change using a tiny and cheap sensor. However, heat transfer between a robot surface and a contact object is strongly affected by the initial temperature and environmental conditions. A given object's material cannot be recognized when its temperature is the same as the robotic grippertip. We present a material classification system using active temperature controllable robotic gripper to induce heat flow. Subsequently, our system can recognize materials independently from their ambient temperature. The robotic gripper surface can be regulated to any temperature that differentiates it from the touched object's surface. We conducted some experiments by integrating the temperature control system with the Academic SCARA Robot, classifying them based on a long short-term memory (LSTM) using temperature data obtained from grasping target objects.
An Image Patch is a Wave: Phase-Aware Vision MLP
Nov 25, 2021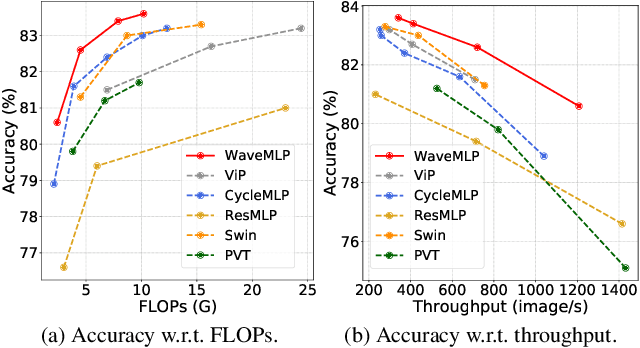
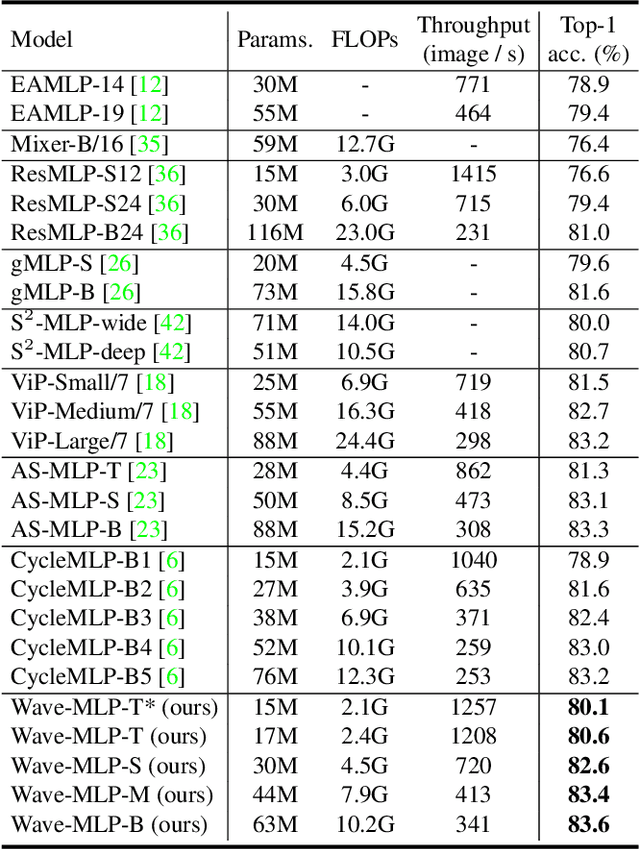
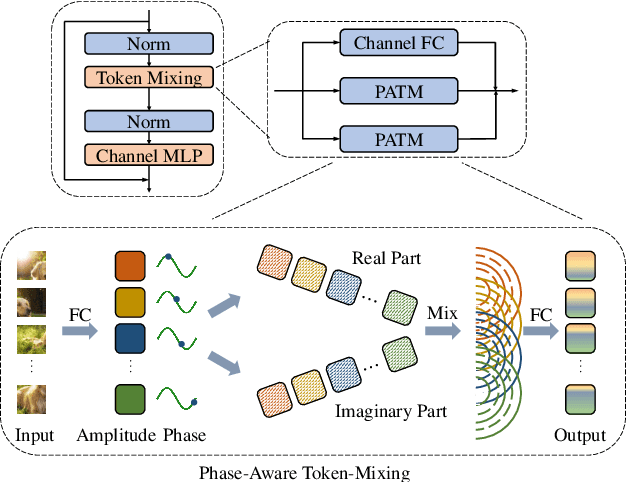
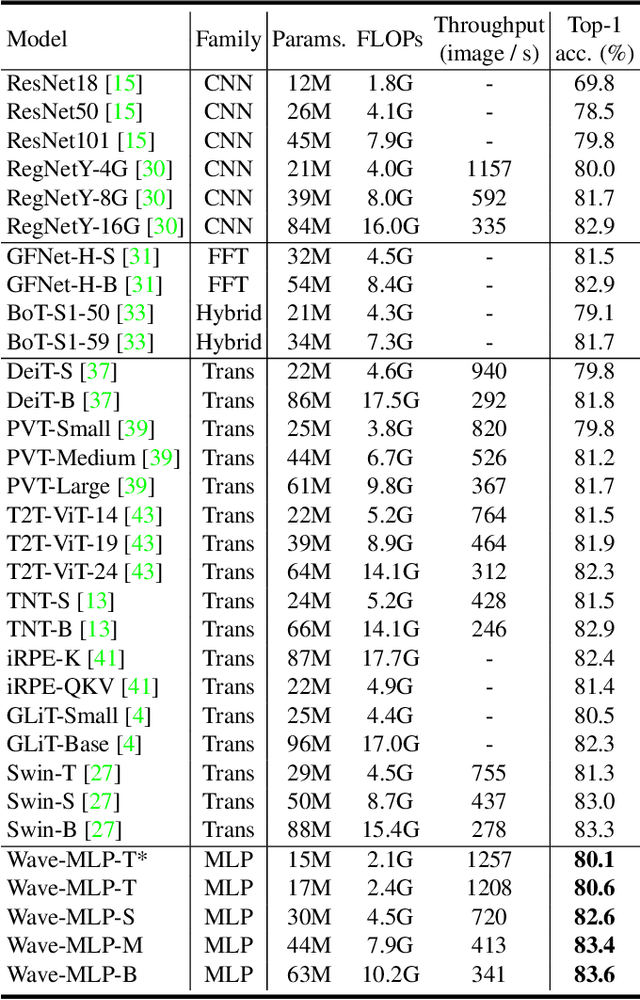
Different from traditional convolutional neural network (CNN) and vision transformer, the multilayer perceptron (MLP) is a new kind of vision model with extremely simple architecture that only stacked by fully-connected layers. An input image of vision MLP is usually split into multiple tokens (patches), while the existing MLP models directly aggregate them with fixed weights, neglecting the varying semantic information of tokens from different images. To dynamically aggregate tokens, we propose to represent each token as a wave function with two parts, amplitude and phase. Amplitude is the original feature and the phase term is a complex value changing according to the semantic contents of input images. Introducing the phase term can dynamically modulate the relationship between tokens and fixed weights in MLP. Based on the wave-like token representation, we establish a novel Wave-MLP architecture for vision tasks. Extensive experiments demonstrate that the proposed Wave-MLP is superior to the state-of-the-art MLP architectures on various vision tasks such as image classification, object detection and semantic segmentation.
Task-Oriented Communication for Multi-Device Cooperative Edge Inference
Sep 01, 2021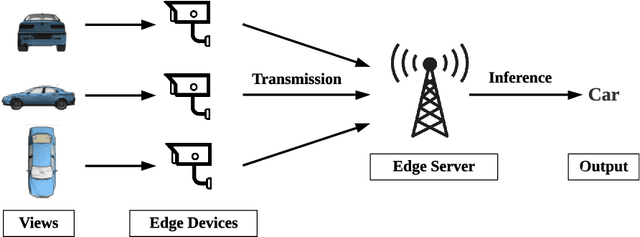
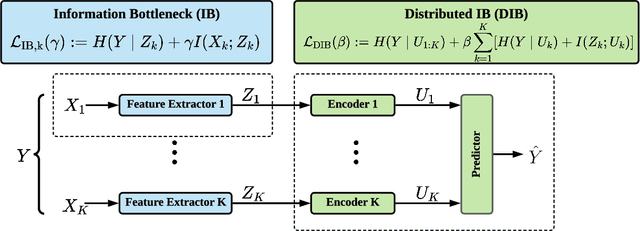
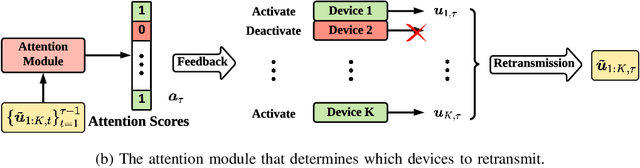
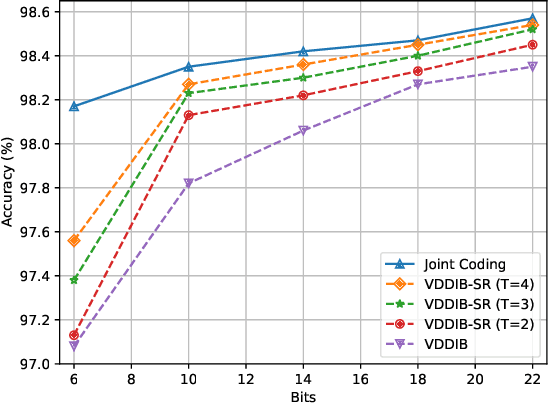
This paper investigates task-oriented communication for multi-device cooperative edge inference, where a group of distributed low-end edge devices transmit the extracted features of local samples to a powerful edge server for inference. While cooperative edge inference can overcome the limited sensing capability of a single device, it substantially increases the communication overhead and may incur excessive latency. To enable low-latency cooperative inference, we propose a learning-based communication scheme that optimizes local feature extraction and distributed feature encoding in a task-oriented manner, i.e., to remove data redundancy and transmit information that is essential for the downstream inference task rather than reconstructing the data samples at the edge server. Specifically, we leverage an information bottleneck (IB) principle to extract the task-relevant feature at each edge device and adopt a distributed information bottleneck (DIB) framework to formalize a single-letter characterization of the optimal rate-relevance tradeoff for distributed feature encoding. To admit flexible control of the communication overhead, we extend the DIB framework to a distributed deterministic information bottleneck (DDIB) objective that explicitly incorporates the representational costs of the encoded features. As the IB-based objectives are computationally prohibitive for high-dimensional data, we adopt variational approximations to make the optimization problems tractable. To compensate the potential performance loss due to the variational approximations, we also develop a selective retransmission (SR) mechanism to identify the redundancy in the encoded features of multiple edge devices to attain additional communication overhead reduction. Extensive experiments evidence that the proposed task-oriented communication scheme achieves a better rate-relevance tradeoff than baseline methods.
ACE-BERT: Adversarial Cross-modal Enhanced BERT for E-commerce Retrieval
Dec 14, 2021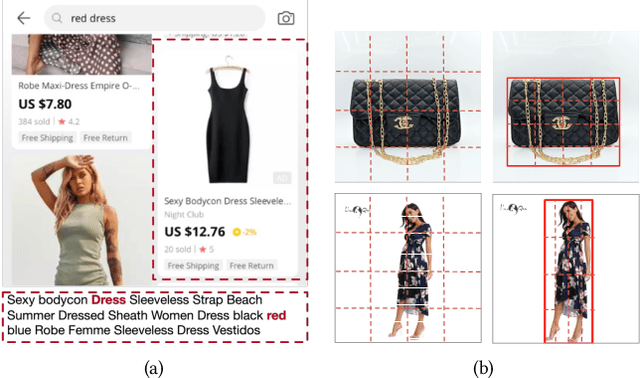

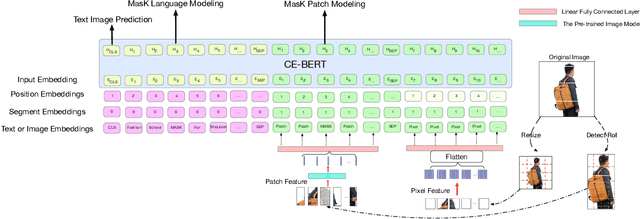

Nowadays on E-commerce platforms, products are presented to the customers with multiple modalities. These multiple modalities are significant for a retrieval system while providing attracted products for customers. Therefore, how to take into account those multiple modalities simultaneously to boost the retrieval performance is crucial. This problem is a huge challenge to us due to the following reasons: (1) the way of extracting patch features with the pre-trained image model (e.g., CNN-based model) has much inductive bias. It is difficult to capture the efficient information from the product image in E-commerce. (2) The heterogeneity of multimodal data makes it challenging to construct the representations of query text and product including title and image in a common subspace. We propose a novel Adversarial Cross-modal Enhanced BERT (ACE-BERT) for efficient E-commerce retrieval. In detail, ACE-BERT leverages the patch features and pixel features as image representation. Thus the Transformer architecture can be applied directly to the raw image sequences. With the pre-trained enhanced BERT as the backbone network, ACE-BERT further adopts adversarial learning by adding a domain classifier to ensure the distribution consistency of different modality representations for the purpose of narrowing down the representation gap between query and product. Experimental results demonstrate that ACE-BERT outperforms the state-of-the-art approaches on the retrieval task. It is remarkable that ACE-BERT has already been deployed in our E-commerce's search engine, leading to 1.46% increase in revenue.
Explainable Artificial Intelligence for Pharmacovigilance: What Features Are Important When Predicting Adverse Outcomes?
Dec 25, 2021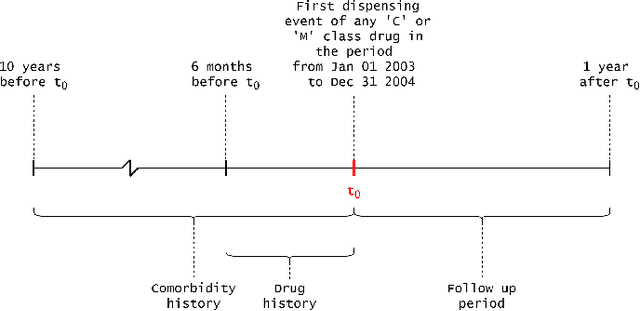

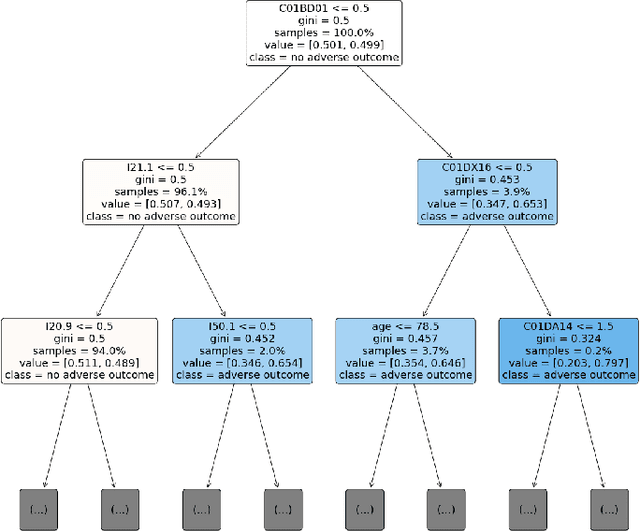
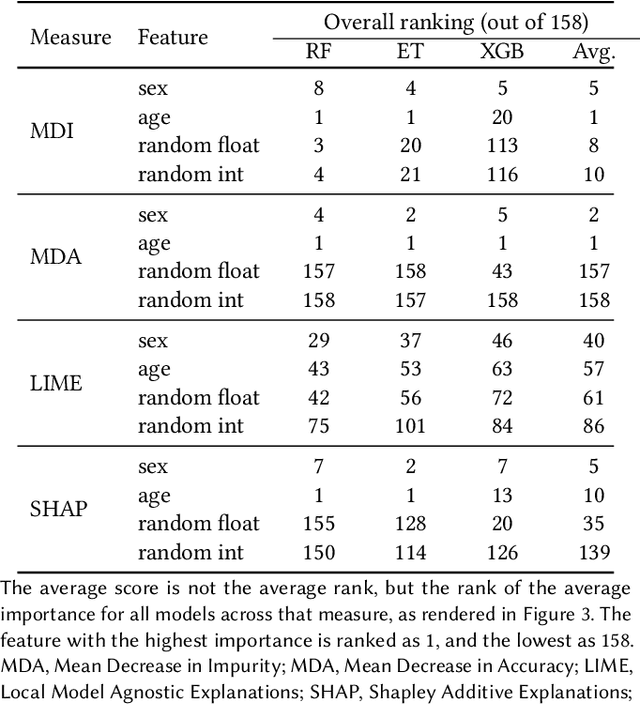
Explainable Artificial Intelligence (XAI) has been identified as a viable method for determining the importance of features when making predictions using Machine Learning (ML) models. In this study, we created models that take an individual's health information (e.g. their drug history and comorbidities) as inputs, and predict the probability that the individual will have an Acute Coronary Syndrome (ACS) adverse outcome. Using XAI, we quantified the contribution that specific drugs had on these ACS predictions, thus creating an XAI-based technique for pharmacovigilance monitoring, using ACS as an example of the adverse outcome to detect. Individuals aged over 65 who were supplied Musculo-skeletal system (anatomical therapeutic chemical (ATC) class M) or Cardiovascular system (ATC class C) drugs between 1993 and 2009 were identified, and their drug histories, comorbidities, and other key features were extracted from linked Western Australian datasets. Multiple ML models were trained to predict if these individuals would have an ACS related adverse outcome (i.e., death or hospitalisation with a discharge diagnosis of ACS), and a variety of ML and XAI techniques were used to calculate which features -- specifically which drugs -- led to these predictions. The drug dispensing features for rofecoxib and celecoxib were found to have a greater than zero contribution to ACS related adverse outcome predictions (on average), and it was found that ACS related adverse outcomes can be predicted with 72% accuracy. Furthermore, the XAI libraries LIME and SHAP were found to successfully identify both important and unimportant features, with SHAP slightly outperforming LIME. ML models trained on linked administrative health datasets in tandem with XAI algorithms can successfully quantify feature importance, and with further development, could potentially be used as pharmacovigilance monitoring techniques.
BERT based Transformers lead the way in Extraction of Health Information from Social Media
Apr 15, 2021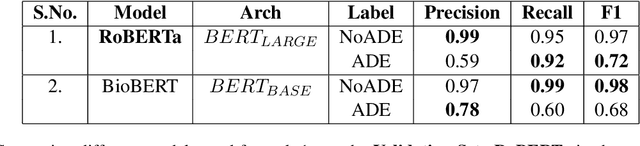
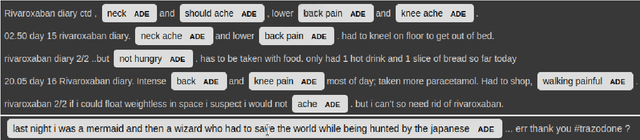
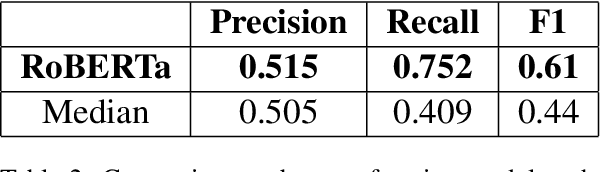

This paper describes our submissions for the Social Media Mining for Health (SMM4H)2021 shared tasks. We participated in 2 tasks:(1) Classification, extraction and normalization of adverse drug effect (ADE) mentions in English tweets (Task-1) and (2) Classification of COVID-19 tweets containing symptoms(Task-6). Our approach for the first task uses the language representation model RoBERTa with a binary classification head. For the second task, we use BERTweet, based on RoBERTa. Fine-tuning is performed on the pre-trained models for both tasks. The models are placed on top of a custom domain-specific processing pipeline. Our system ranked first among all the submissions for subtask-1(a) with an F1-score of 61%. For subtask-1(b), our system obtained an F1-score of 50% with improvements up to +8% F1 over the score averaged across all submissions. The BERTweet model achieved an F1 score of 94% on SMM4H 2021 Task-6.
MIA-Former: Efficient and Robust Vision Transformers via Multi-grained Input-Adaptation
Dec 21, 2021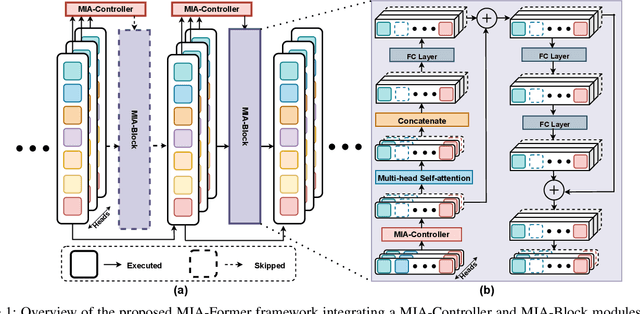
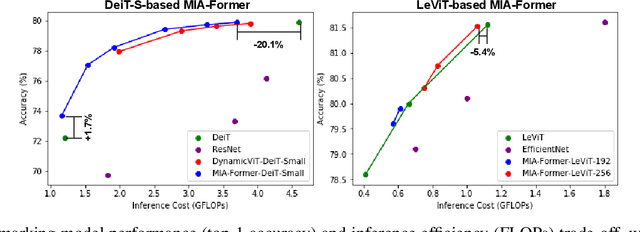
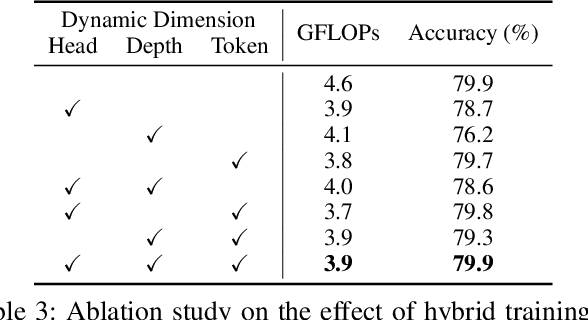
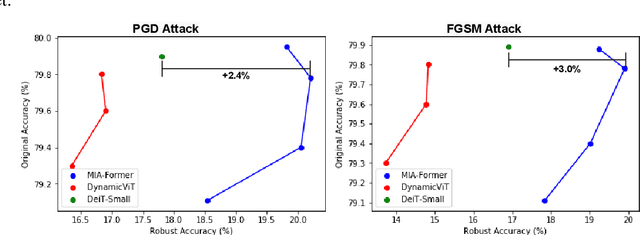
ViTs are often too computationally expensive to be fitted onto real-world resource-constrained devices, due to (1) their quadratically increased complexity with the number of input tokens and (2) their overparameterized self-attention heads and model depth. In parallel, different images are of varied complexity and their different regions can contain various levels of visual information, indicating that treating all regions/tokens equally in terms of model complexity is unnecessary while such opportunities for trimming down ViTs' complexity have not been fully explored. To this end, we propose a Multi-grained Input-adaptive Vision Transformer framework dubbed MIA-Former that can input-adaptively adjust the structure of ViTs at three coarse-to-fine-grained granularities (i.e., model depth and the number of model heads/tokens). In particular, our MIA-Former adopts a low-cost network trained with a hybrid supervised and reinforcement training method to skip unnecessary layers, heads, and tokens in an input adaptive manner, reducing the overall computational cost. Furthermore, an interesting side effect of our MIA-Former is that its resulting ViTs are naturally equipped with improved robustness against adversarial attacks over their static counterparts, because MIA-Former's multi-grained dynamic control improves the model diversity similar to the effect of ensemble and thus increases the difficulty of adversarial attacks against all its sub-models. Extensive experiments and ablation studies validate that the proposed MIA-Former framework can effectively allocate computation budgets adaptive to the difficulty of input images meanwhile increase robustness, achieving state-of-the-art (SOTA) accuracy-efficiency trade-offs, e.g., 20% computation savings with the same or even a higher accuracy compared with SOTA dynamic transformer models.
Maximizing Information Gain in Partially Observable Environments via Prediction Reward
May 11, 2020
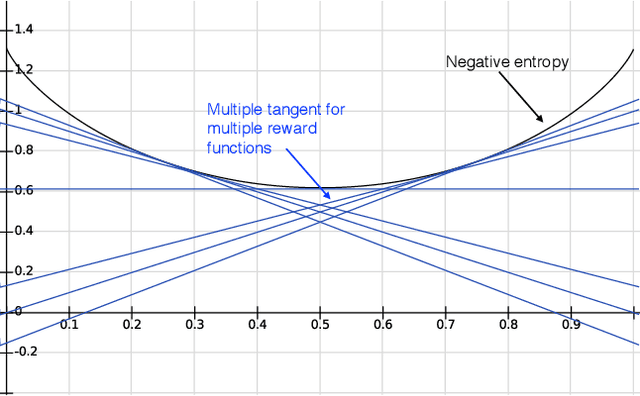
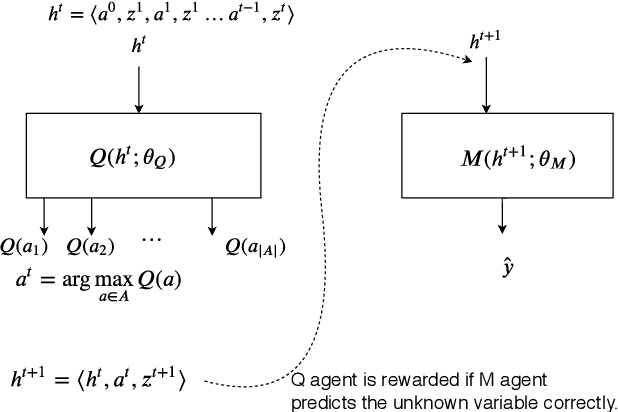
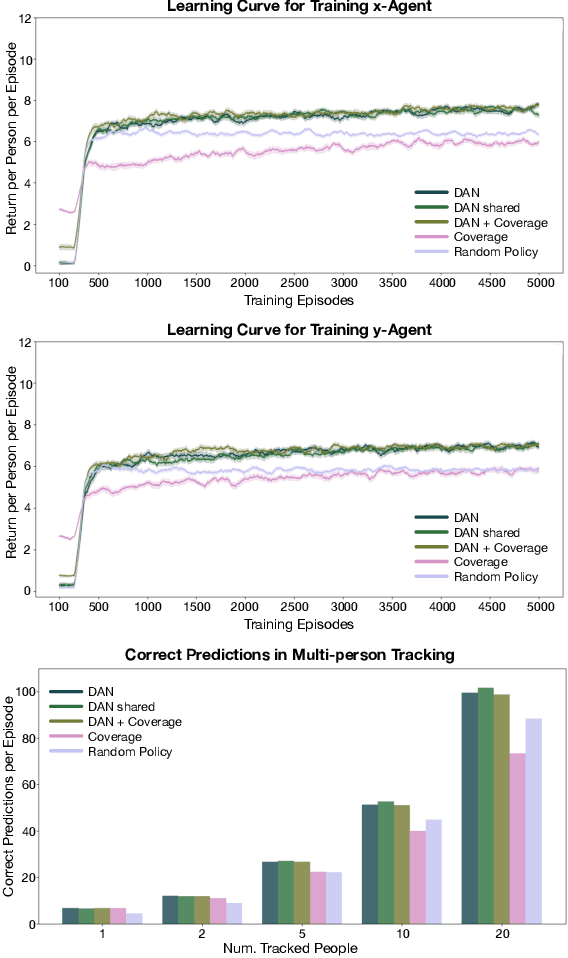
Information gathering in a partially observable environment can be formulated as a reinforcement learning (RL), problem where the reward depends on the agent's uncertainty. For example, the reward can be the negative entropy of the agent's belief over an unknown (or hidden) variable. Typically, the rewards of an RL agent are defined as a function of the state-action pairs and not as a function of the belief of the agent; this hinders the direct application of deep RL methods for such tasks. This paper tackles the challenge of using belief-based rewards for a deep RL agent, by offering a simple insight that maximizing any convex function of the belief of the agent can be approximated by instead maximizing a prediction reward: a reward based on prediction accuracy. In particular, we derive the exact error between negative entropy and the expected prediction reward. This insight provides theoretical motivation for several fields using prediction rewards---namely visual attention, question answering systems, and intrinsic motivation---and highlights their connection to the usually distinct fields of active perception, active sensing, and sensor placement. Based on this insight we present deep anticipatory networks (DANs), which enables an agent to take actions to reduce its uncertainty without performing explicit belief inference. We present two applications of DANs: building a sensor selection system for tracking people in a shopping mall and learning discrete models of attention on fashion MNIST and MNIST digit classification.
Classifying COVID-19 Spike Sequences from Geographic Location Using Deep Learning
Oct 09, 2021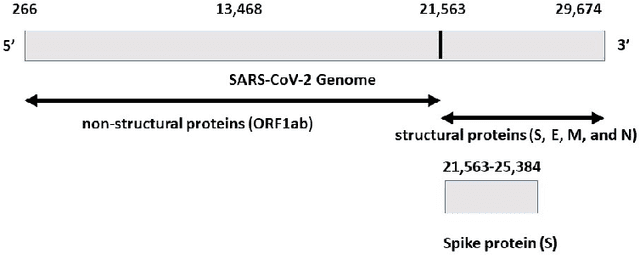
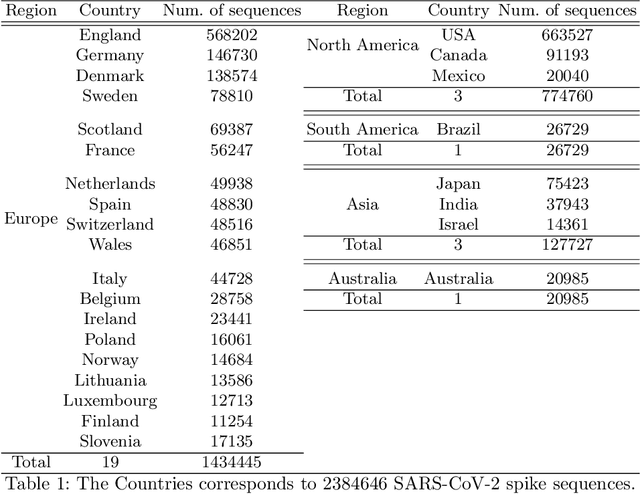
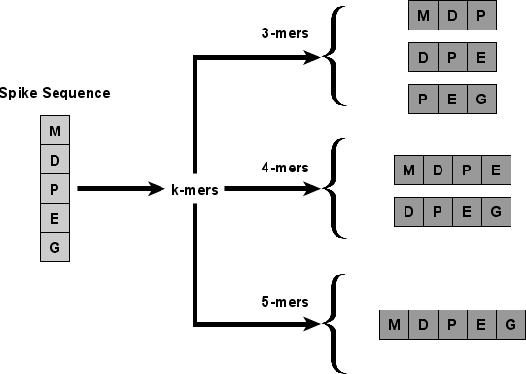
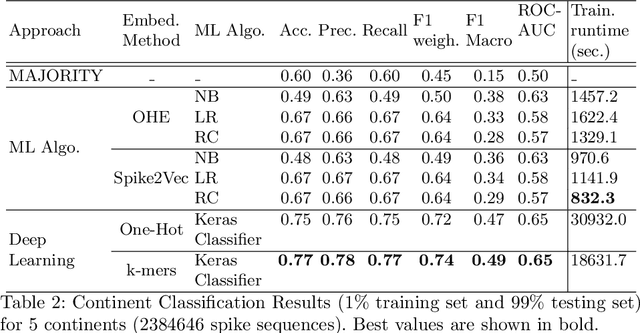
With the rapid spread of COVID-19 worldwide, viral genomic data is available in the order of millions of sequences on public databases such as GISAID. This \emph{Big Data} creates a unique opportunity for analysis towards the research of effective vaccine development for current pandemics, and avoiding or mitigating future pandemics. One piece of information that comes with every such viral sequence is the geographical location where it was collected -- the patterns found between viral variants and geographic location surely being an important part of this analysis. One major challenge that researchers face is processing such huge, highly dimensional data to get useful insights as quickly as possible. Most of the existing methods face scalability issues when dealing with the magnitude of such data. In this paper, we propose an algorithm that first computes a numerical representation of the spike protein sequence of SARS-CoV-2 using $k$-mers substrings) and then uses a deep learning-based model to classify the sequences in terms of geographical location. We show that our proposed model significantly outperforms the baselines. We also show the importance of different amino acids in the spike sequences by computing the information gain corresponding to the true class labels.