 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Classification of sums of complex exponentials
Nov 09, 2021

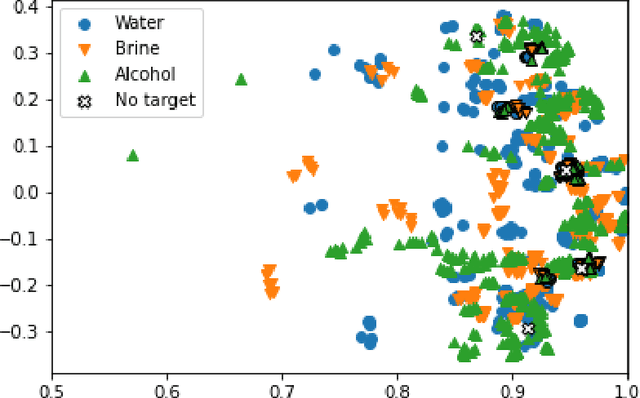
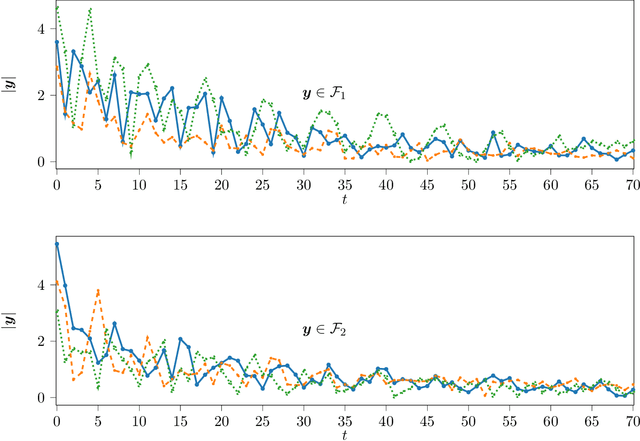
Numerous signals in relevant signal processing applications can be modeled as a sum of complex exponentials. Each exponential term entails a particular property of the modeled physical system, and it is possible to define families of signals that are associated with the complex exponentials. In this paper, we formulate a classification problem for this guiding principle and we propose a data processing strategy. In particular, we exploit the information obtained from the analytical model by combining it with data-driven learning techniques. As a result, we obtain a classification strategy that is robust under modeling uncertainties and experimental perturbations. To assess the performance of the new scheme, we test it with experimental data obtained from the scattering response of targets illuminated with an impulse radio ultra-wideband radar.
Hierarchical transfer learning with applications for electricity load forecasting
Nov 19, 2021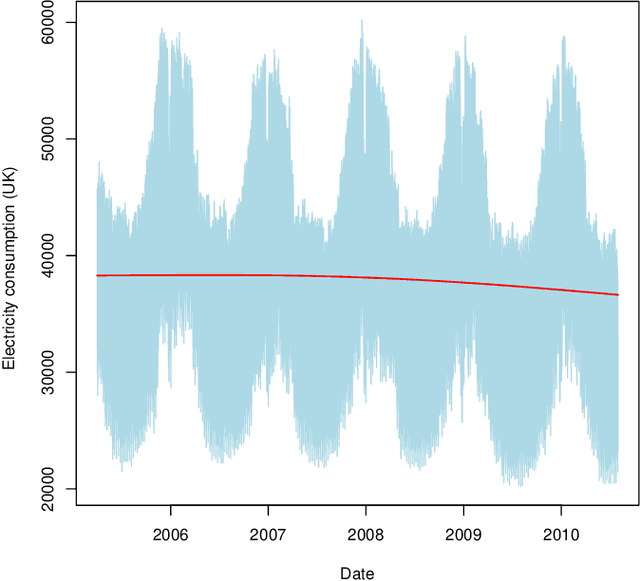

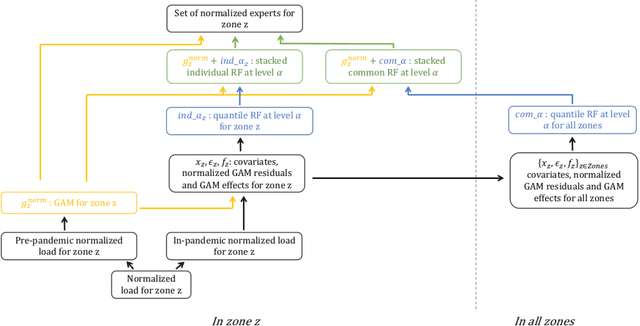

The recent abundance of data on electricity consumption at different scales opens new challenges and highlights the need for new techniques to leverage information present at finer scales in order to improve forecasts at wider scales. In this work, we take advantage of the similarity between this hierarchical prediction problem and multi-scale transfer learning. We develop two methods for hierarchical transfer learning, based respectively on the stacking of generalized additive models and random forests, and on the use of aggregation of experts. We apply these methods to two problems of electricity load forecasting at national scale, using smart meter data in the first case, and regional data in the second case. For these two usecases, we compare the performances of our methods to that of benchmark algorithms, and we investigate their behaviour using variable importance analysis. Our results demonstrate the interest of both methods, which lead to a significant improvement of the predictions.
Learnability for the Information Bottleneck
Jul 17, 2019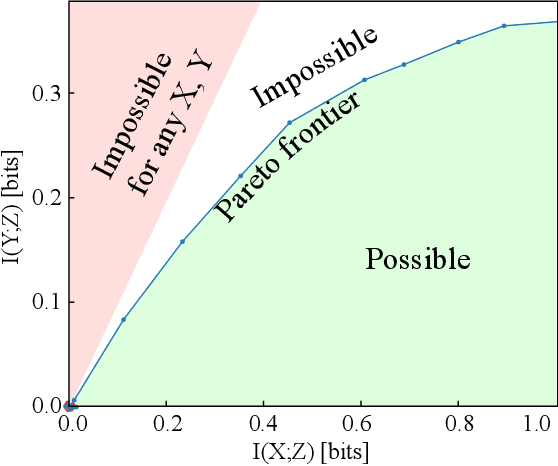
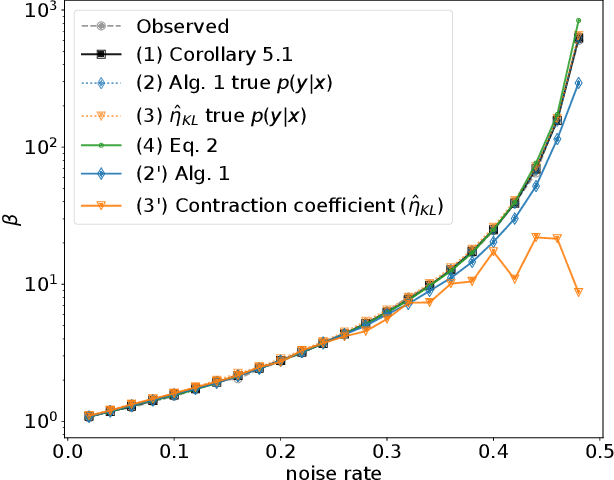
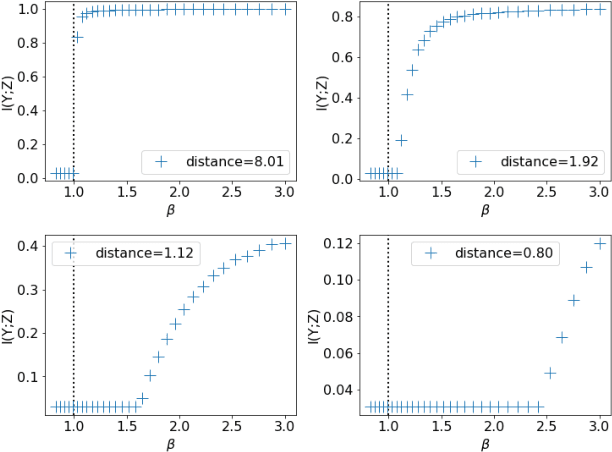
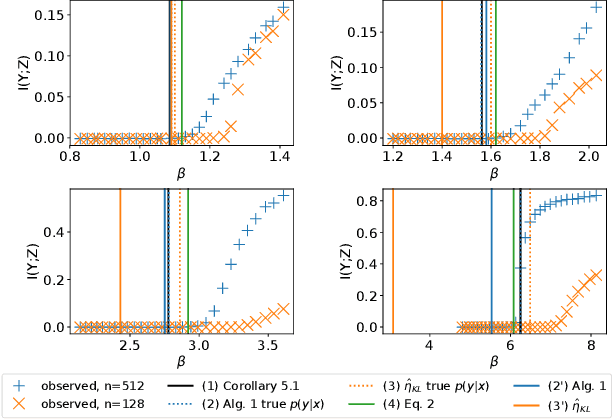
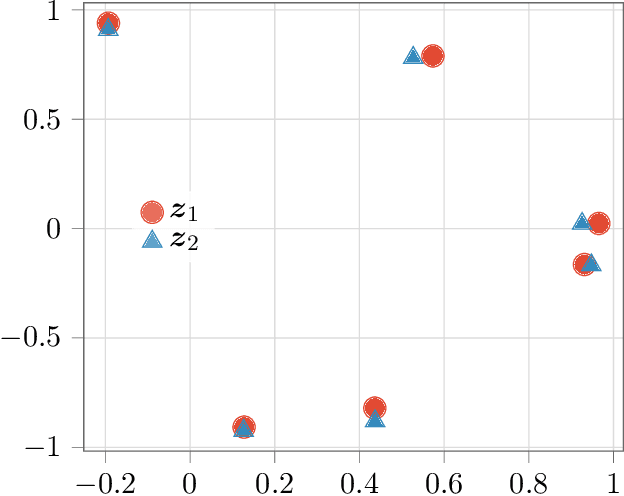
The Information Bottleneck (IB) method (\cite{tishby2000information}) provides an insightful and principled approach for balancing compression and prediction for representation learning. The IB objective $I(X;Z)-\beta I(Y;Z)$ employs a Lagrange multiplier $\beta$ to tune this trade-off. However, in practice, not only is $\beta$ chosen empirically without theoretical guidance, there is also a lack of theoretical understanding between $\beta$, learnability, the intrinsic nature of the dataset and model capacity. In this paper, we show that if $\beta$ is improperly chosen, learning cannot happen -- the trivial representation $P(Z|X)=P(Z)$ becomes the global minimum of the IB objective. We show how this can be avoided, by identifying a sharp phase transition between the unlearnable and the learnable which arises as $\beta$ is varied. This phase transition defines the concept of IB-Learnability. We prove several sufficient conditions for IB-Learnability, which provides theoretical guidance for choosing a good $\beta$. We further show that IB-learnability is determined by the largest confident, typical, and imbalanced subset of the examples (the conspicuous subset), and discuss its relation with model capacity. We give practical algorithms to estimate the minimum $\beta$ for a given dataset. We also empirically demonstrate our theoretical conditions with analyses of synthetic datasets, MNIST, and CIFAR10.
Varifocal Multiview Images: Capturing and Visual Tasks
Nov 19, 2021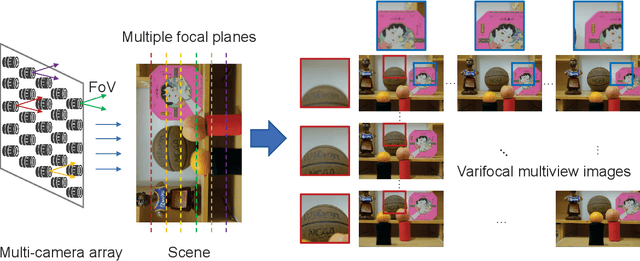
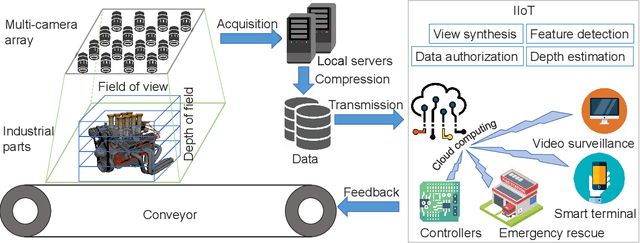


Multiview images have flexible field of view (FoV) but inflexible depth of field (DoF). To overcome the limitation of multiview images on visual tasks, in this paper, we present varifocal multiview (VFMV) images with flexible DoF. VFMV images are captured by focusing a scene on distinct depths by varying focal planes, and each view only focused on one single plane.Therefore, VFMV images contain more information in focal dimension than multiview images, and can provide a rich representation for 3D scene by considering both FoV and DoF. The characteristics of VFMV images are useful for visual tasks to achieve high quality scene representation. Two experiments are conducted to validate the advantages of VFMV images in 4D light field feature detection and 3D reconstruction. Experiment results show that VFMV images can detect more light field features and achieve higher reconstruction quality due to informative focus cues. This work demonstrates that VFMV images have definite advantages over multiview images in visual tasks.
Fast Uncertainty Quantification for Active Graph SLAM
Oct 04, 2021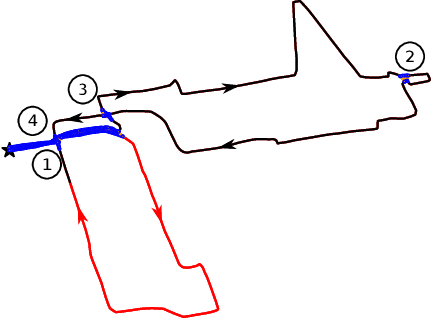
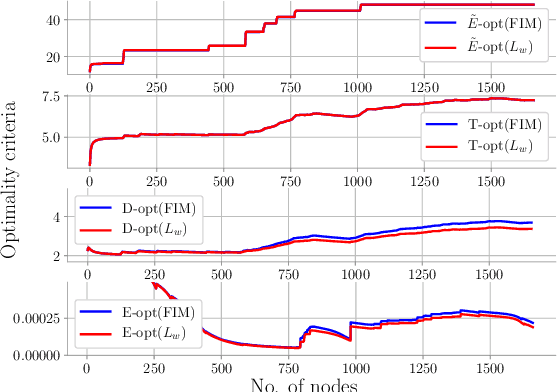
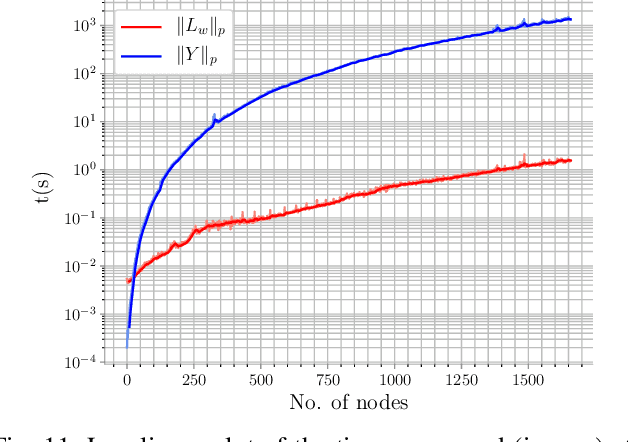
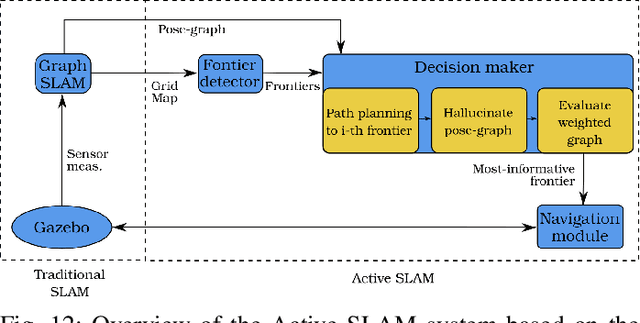
Quantifying uncertainty is a key stage in autonomous robotic exploration, since it allows to identify the most informative actions to execute. However, dealing with full Fisher Information matrices (FIM) is computationally heavy and may become intractable for online systems. In this work, we study the paradigm of Active graph SLAM formulated over $\textit{SE(n)}$, and propose a general relationship between the full FIM and the Laplacian matrix of the underlying pose-graph. Therefore, the optimal set of actions can be estimated by maximizing optimality criteria of the weighted Laplacian instead of that of the FIM. Experimental validation proves our method leads to equivalent results in a fraction of the time traditional methods require. Based on the former, we present an online Active graph SLAM system capable of selecting D-optimal actions and that outperforms other state-of-the-art methods that rely on slower computations. Also, we propose the use of such indices as stopping criterion, making our system capable of autonomously determining when the exploration strategy is no longer adding information to the graph SLAM algorithm and it should be either changed or terminated.
Enhanced countering adversarial attacks via input denoising and feature restoring
Nov 19, 2021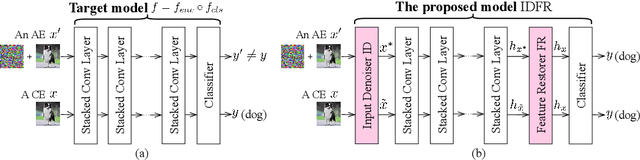
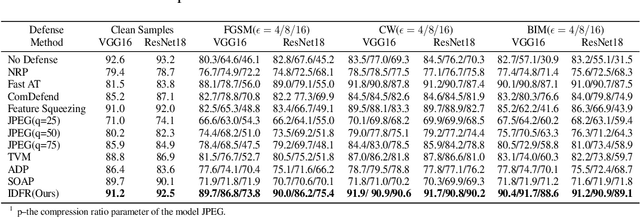
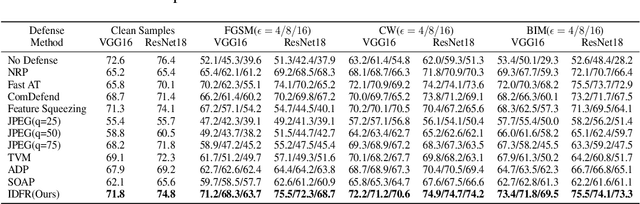
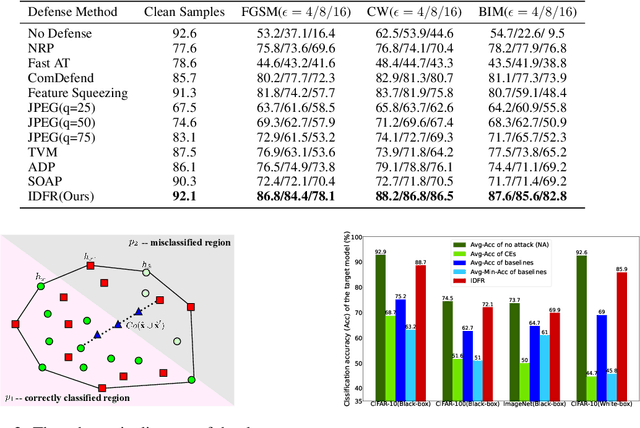
Despite the fact that deep neural networks (DNNs) have achieved prominent performance in various applications, it is well known that DNNs are vulnerable to adversarial examples/samples (AEs) with imperceptible perturbations in clean/original samples. To overcome the weakness of the existing defense methods against adversarial attacks, which damages the information on the original samples, leading to the decrease of the target classifier accuracy, this paper presents an enhanced countering adversarial attack method IDFR (via Input Denoising and Feature Restoring). The proposed IDFR is made up of an enhanced input denoiser (ID) and a hidden lossy feature restorer (FR) based on the convex hull optimization. Extensive experiments conducted on benchmark datasets show that the proposed IDFR outperforms the various state-of-the-art defense methods, and is highly effective for protecting target models against various adversarial black-box or white-box attacks. \footnote{Souce code is released at: \href{https://github.com/ID-FR/IDFR}{https://github.com/ID-FR/IDFR}}
Extracting and Measuring Uncertain Biomedical Knowledge from Scientific Statements
Dec 05, 2021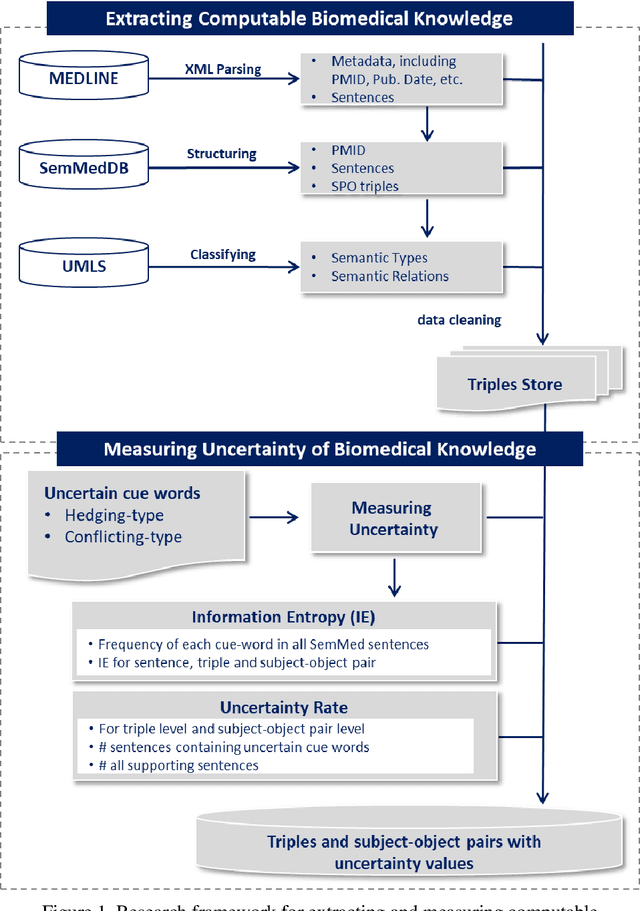

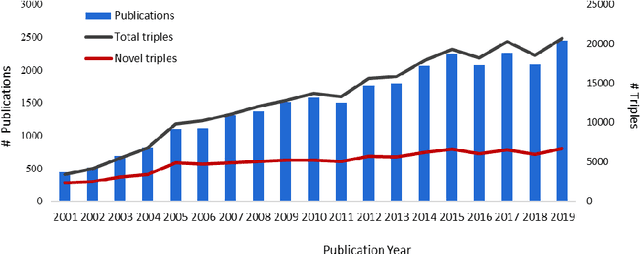
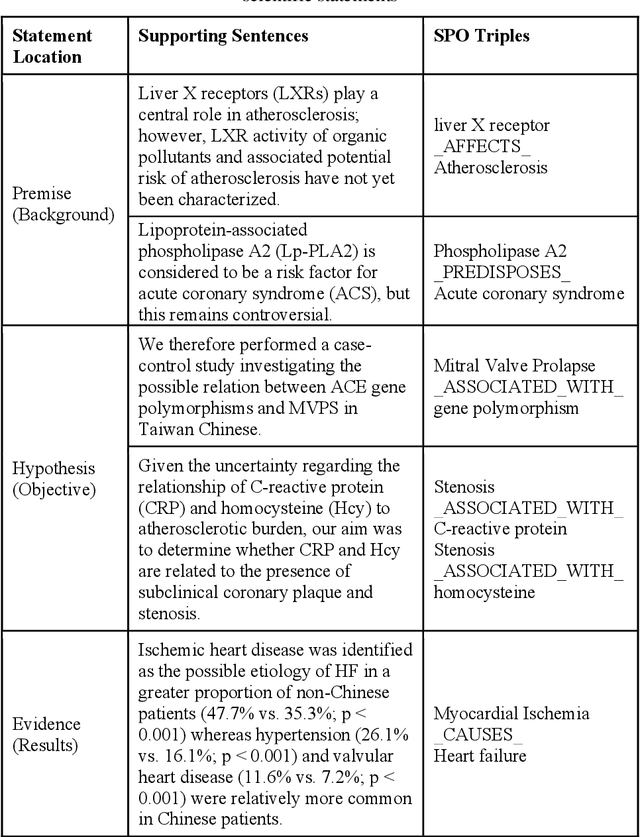
Purpose: This study aims to develop a novel approach to extracting and measuring uncertain biomedical knowledge from scientific statements. Design/methodology/approach: Taking cardiovascular research publications in China as a sample, we extracted the SPO triples as knowledge unit and the hedging/conflicting uncertainties as the knowledge context. We introduced Information Entropy and Uncertainty Rate as potential metrics to quantity the uncertainty of biomedical knowledge claims represented at different levels, such as the SPO triples (micro level), as well as the semantic type pairs (micro-level). Findings: The results indicated that while the number of scientific publications and total SPO triples showed a liner growth, the novel SPO triples occurring per year remained stable. After examining the frequency of uncertain cue words in different part of scientific statements, we found hedging words tend to appear in conclusive and purposeful sentences, whereas conflicting terms often appear in background and act as the premise (e.g., unsettled scientific issues) of the work to be investigated. Practical implications: Our approach identified major uncertain knowledge areas, such as diagnostic biomarkers, genetic characteristics, and pharmacologic therapies surrounding cardiovascular diseases in China. These areas are suggested to be prioritized in which new hypotheses need to be verified, and disputes, conflicts, as well as contradictions to be settled further.
Exploiting a Zoo of Checkpoints for Unseen Tasks
Nov 05, 2021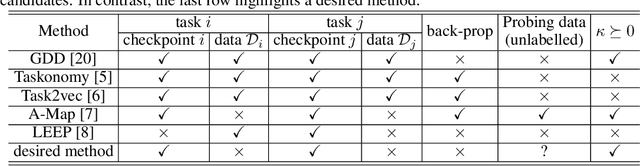
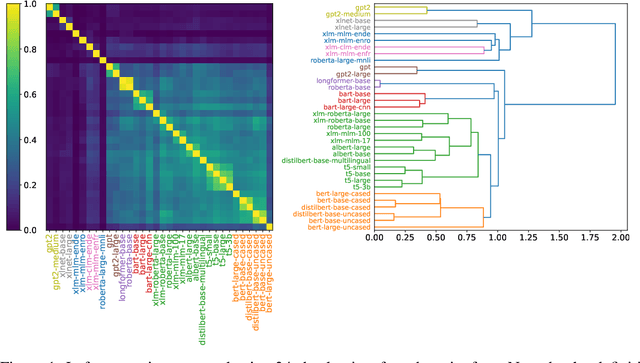
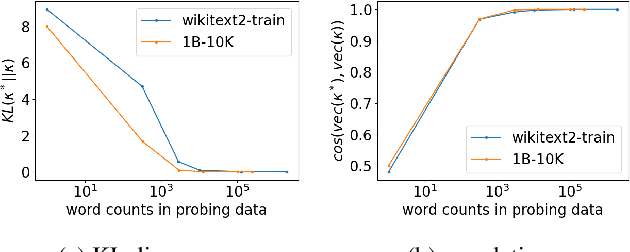

There are so many models in the literature that it is difficult for practitioners to decide which combinations are likely to be effective for a new task. This paper attempts to address this question by capturing relationships among checkpoints published on the web. We model the space of tasks as a Gaussian process. The covariance can be estimated from checkpoints and unlabeled probing data. With the Gaussian process, we can identify representative checkpoints by a maximum mutual information criterion. This objective is submodular. A greedy method identifies representatives that are likely to "cover" the task space. These representatives generalize to new tasks with superior performance. Empirical evidence is provided for applications from both computational linguistics as well as computer vision.
Mutual Information-based State-Control for Intrinsically Motivated Reinforcement Learning
Feb 05, 2020

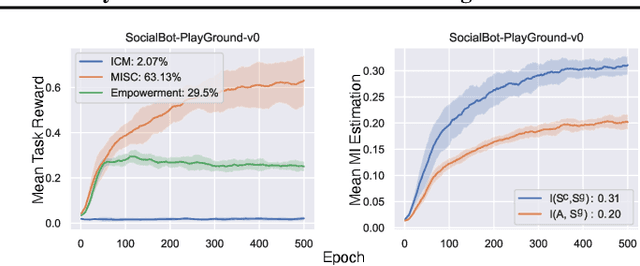
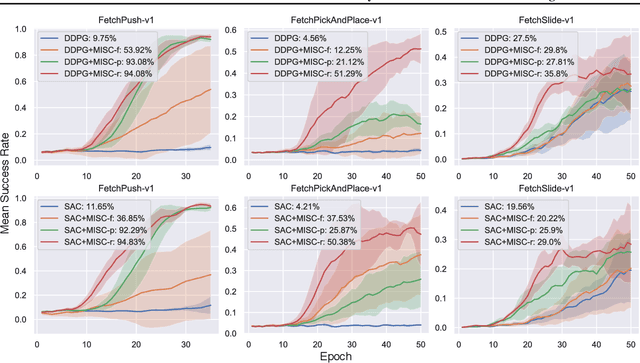
In reinforcement learning, an agent learns to reach a set of goals by means of an external reward signal. In the natural world, intelligent organisms learn from internal drives, bypassing the need for external signals, which is beneficial for a wide range of tasks. Motivated by this observation, we propose to formulate an intrinsic objective as the mutual information between the goal states and the controllable states. This objective encourages the agent to take control of its environment. Subsequently, we derive a surrogate objective of the proposed reward function, which can be optimized efficiently. Lastly, we evaluate the developed framework in different robotic manipulation and navigation tasks and demonstrate the efficacy of our approach. A video showing experimental results is available at \url{https://youtu.be/CT4CKMWBYz0}.
Superpixel-Based Building Damage Detection from Post-earthquake Very High Resolution Imagery Using Deep Neural Networks
Dec 10, 2021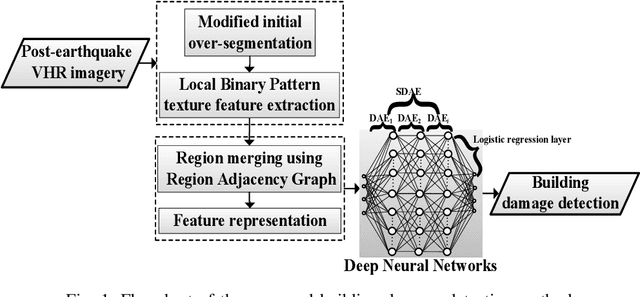
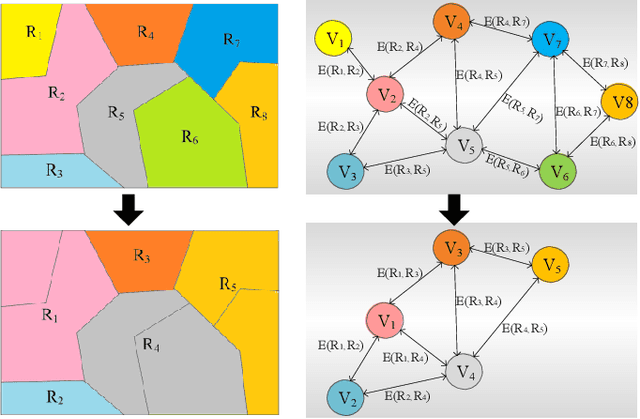
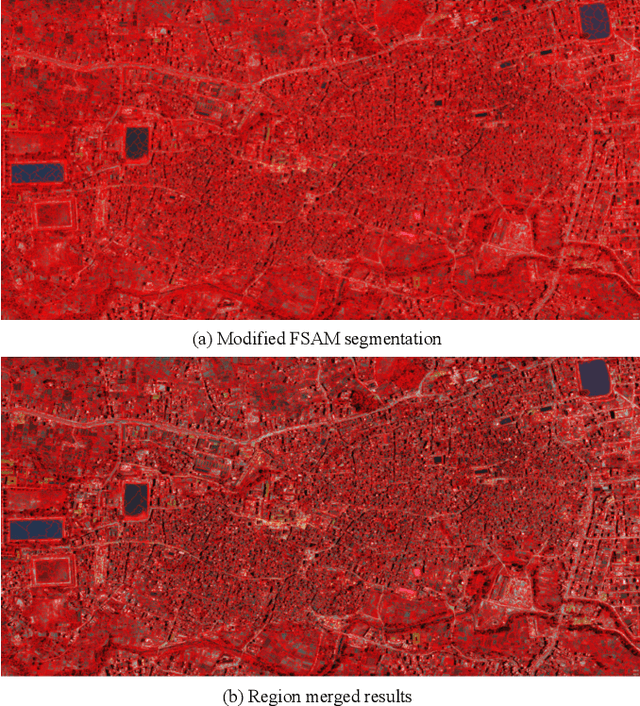
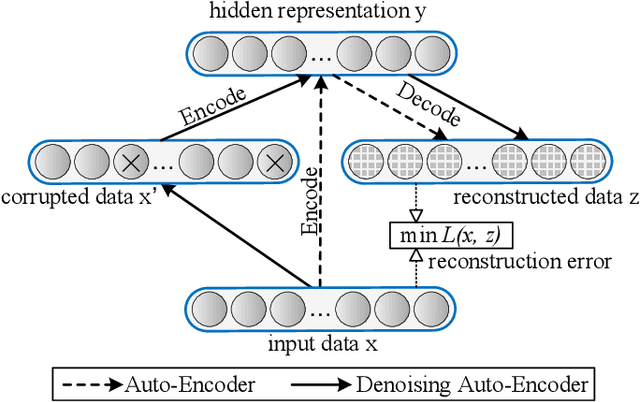
Building damage detection after natural disasters like earthquakes is crucial for initiating effective emergency response actions. Remotely sensed very high spatial resolution (VHR) imagery can provide vital information due to their ability to map the affected buildings with high geometric precision. Many approaches have been developed to detect damaged buildings due to earthquakes. However, little attention has been paid to exploiting rich features represented in VHR images using Deep Neural Networks (DNN). This paper presents a novel super-pixel based approach combining DNN and a modified segmentation method, to detect damaged buildings from VHR imagery. Firstly, a modified Fast Scanning and Adaptive Merging method is extended to create initial over-segmentation. Secondly, the segments are merged based on the Region Adjacent Graph (RAG), considered an improved semantic similarity criterion composed of Local Binary Patterns (LBP) texture, spectral, and shape features. Thirdly, a pre-trained DNN using Stacked Denoising Auto-Encoders called SDAE-DNN is presented, to exploit the rich semantic features for building damage detection. Deep-layer feature abstraction of SDAE-DNN could boost detection accuracy through learning more intrinsic and discriminative features, which outperformed other methods using state-of-the-art alternative classifiers. We demonstrate the feasibility and effectiveness of our method using a subset of WorldView-2 imagery, in the complex urban areas of Bhaktapur, Nepal, which was affected by the Nepal Earthquake of April 25, 2015.