 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Feature-Attending Recurrent Modules for Generalization in Reinforcement Learning
Dec 15, 2021
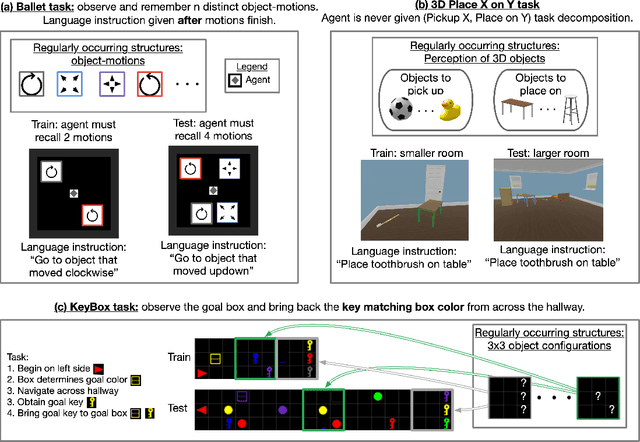
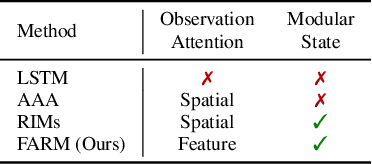
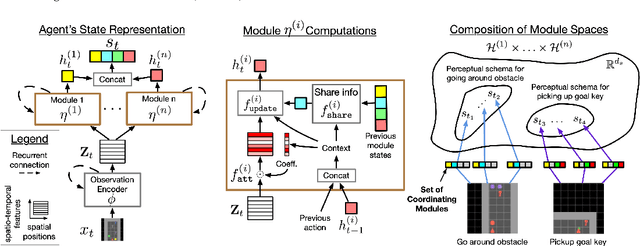
Deep reinforcement learning (Deep RL) has recently seen significant progress in developing algorithms for generalization. However, most algorithms target a single type of generalization setting. In this work, we study generalization across three disparate task structures: (a) tasks composed of spatial and temporal compositions of regularly occurring object motions; (b) tasks composed of active perception of and navigation towards regularly occurring 3D objects; and (c) tasks composed of remembering goal-information over sequences of regularly occurring object-configurations. These diverse task structures all share an underlying idea of compositionality: task completion always involves combining recurring segments of task-oriented perception and behavior. We hypothesize that an agent can generalize within a task structure if it can discover representations that capture these recurring task-segments. For our tasks, this corresponds to representations for recognizing individual object motions, for navigation towards 3D objects, and for navigating through object-configurations. Taking inspiration from cognitive science, we term representations for recurring segments of an agent's experience, "perceptual schemas". We propose Feature Attending Recurrent Modules (FARM), which learns a state representation where perceptual schemas are distributed across multiple, relatively small recurrent modules. We compare FARM to recurrent architectures that leverage spatial attention, which reduces observation features to a weighted average over spatial positions. Our experiments indicate that our feature-attention mechanism better enables FARM to generalize across the diverse object-centric domains we study.
Controllable Neural Dialogue Summarization with Personal Named Entity Planning
Sep 27, 2021
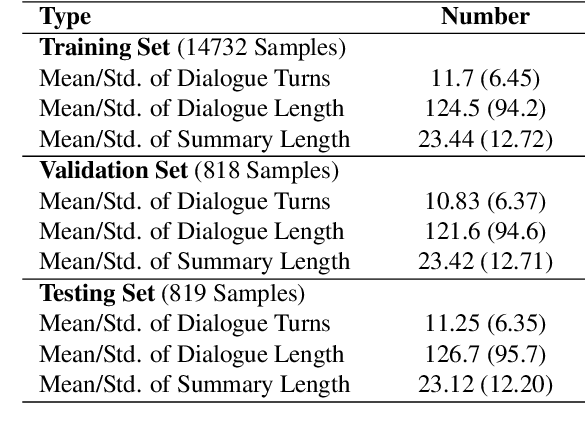

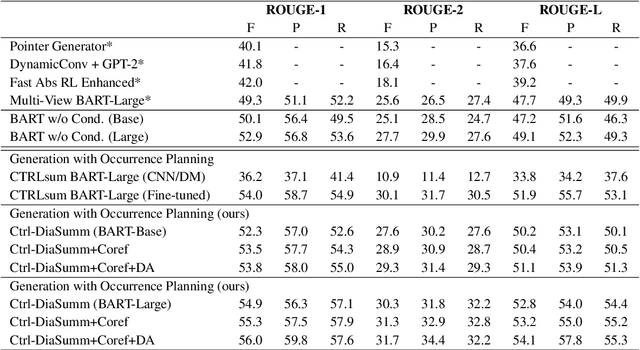
In this paper, we propose a controllable neural generation framework that can flexibly guide dialogue summarization with personal named entity planning. The conditional sequences are modulated to decide what types of information or what perspective to focus on when forming summaries to tackle the under-constrained problem in summarization tasks. This framework supports two types of use cases: (1) Comprehensive Perspective, which is a general-purpose case with no user-preference specified, considering summary points from all conversational interlocutors and all mentioned persons; (2) Focus Perspective, positioning the summary based on a user-specified personal named entity, which could be one of the interlocutors or one of the persons mentioned in the conversation. During training, we exploit occurrence planning of personal named entities and coreference information to improve temporal coherence and to minimize hallucination in neural generation. Experimental results show that our proposed framework generates fluent and factually consistent summaries under various planning controls using both objective metrics and human evaluations.
Dual-Neighborhood Deep Fusion Network for Point Cloud Analysis
Aug 20, 2021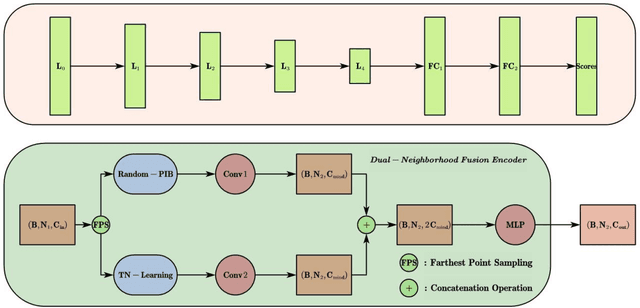
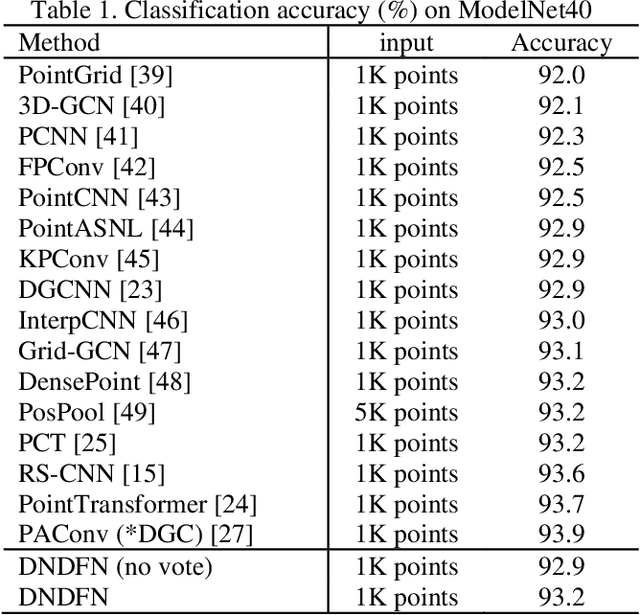
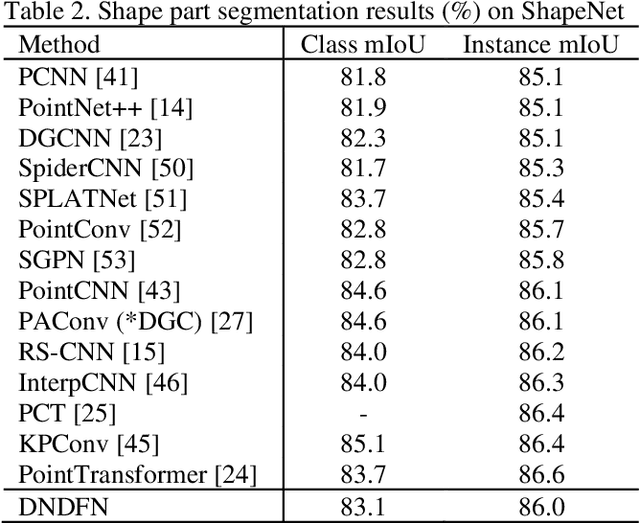

Convolutional neural network has made remarkable achievements in classification of idealized point cloud, however, non-idealized point cloud classification is still a challenging task. In this paper, DNDFN, namely, Dual-Neighborhood Deep Fusion Network, is proposed to deal with this problem. DNDFN has two key points. One is combination of local neighborhood and global neigh-borhood. nearest neighbor (kNN) or ball query can capture the local neighborhood but ignores long-distance dependencies. A trainable neighborhood learning meth-od called TN-Learning is proposed, which can capture the global neighborhood. TN-Learning is combined with them to obtain richer neighborhood information. The other is information transfer convolution (IT-Conv) which can learn the structural information between two points and transfer features through it. Extensive exper-iments on idealized and non-idealized benchmarks across four tasks verify DNDFN achieves the state of the arts.
Multi-task manifold learning for small sample size datasets
Nov 24, 2021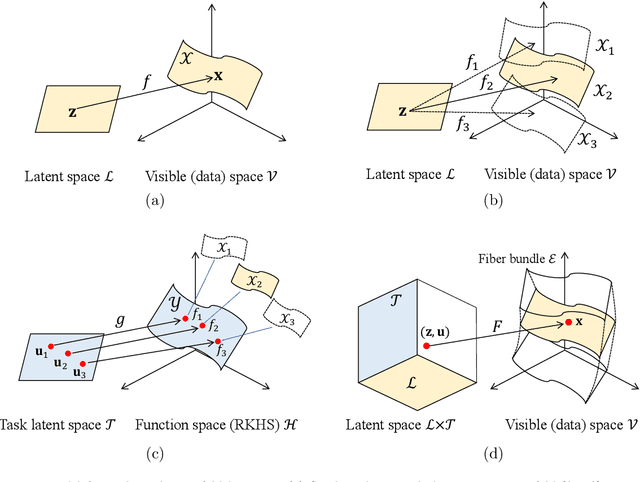
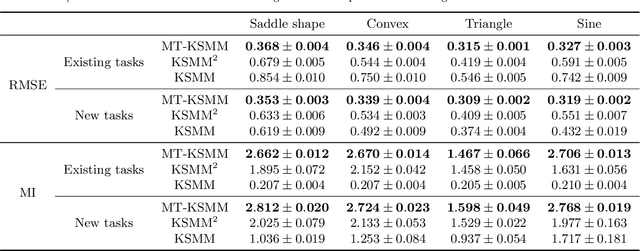
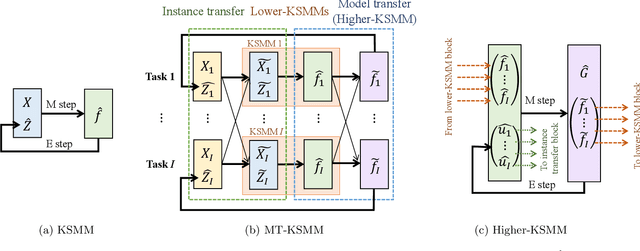

In this study, we develop a method for multi-task manifold learning. The method aims to improve the performance of manifold learning for multiple tasks, particularly when each task has a small number of samples. Furthermore, the method also aims to generate new samples for new tasks, in addition to new samples for existing tasks. In the proposed method, we use two different types of information transfer: instance transfer and model transfer. For instance transfer, datasets are merged among similar tasks, whereas for model transfer, the manifold models are averaged among similar tasks. For this purpose, the proposed method consists of a set of generative manifold models corresponding to the tasks, which are integrated into a general model of a fiber bundle. We applied the proposed method to artificial datasets and face image sets, and the results showed that the method was able to estimate the manifolds, even for a tiny number of samples.
One to Transfer All: A Universal Transfer Framework for Vision Foundation Model with Few Data
Nov 24, 2021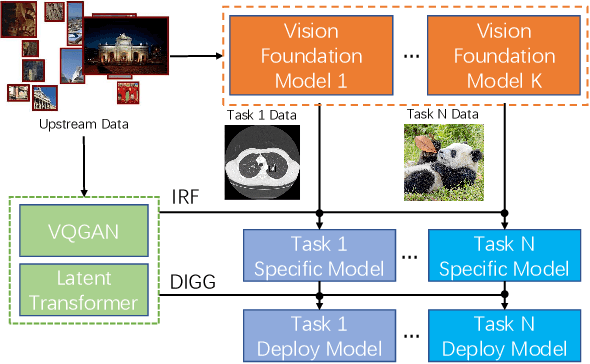
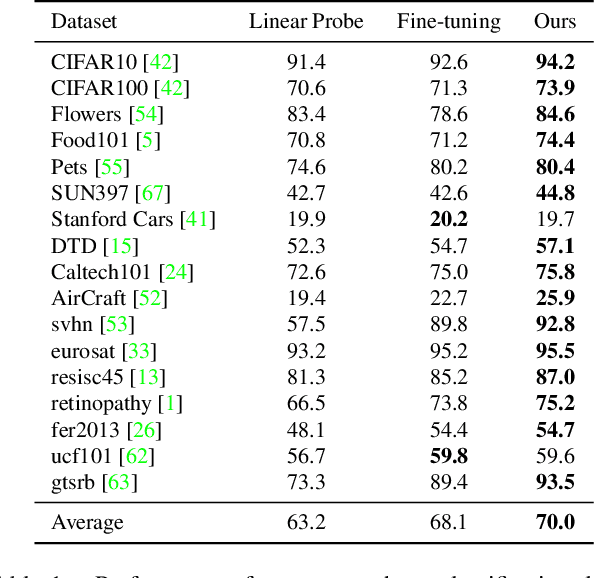
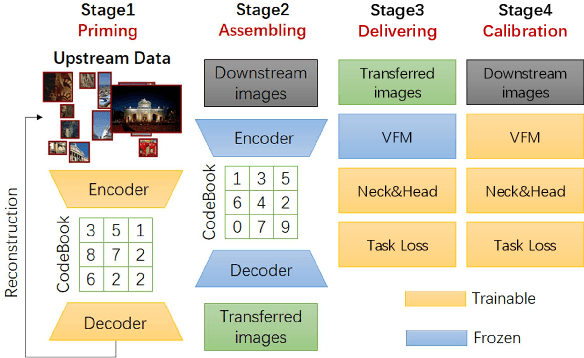

The foundation model is not the last chapter of the model production pipeline. Transferring with few data in a general way to thousands of downstream tasks is becoming a trend of the foundation model's application. In this paper, we proposed a universal transfer framework: One to Transfer All (OTA) to transfer any Vision Foundation Model (VFM) to any downstream tasks with few downstream data. We first transfer a VFM to a task-specific model by Image Re-representation Fine-tuning (IRF) then distilling knowledge from a task-specific model to a deployed model with data produced by Downstream Image-Guided Generation (DIGG). OTA has no dependency on upstream data, VFM, and downstream tasks when transferring. It also provides a way for VFM researchers to release their upstream information for better transferring but not leaking data due to privacy requirements. Massive experiments validate the effectiveness and superiority of our methods in few data setting. Our code will be released.
Boosting Active Learning via Improving Test Performance
Dec 10, 2021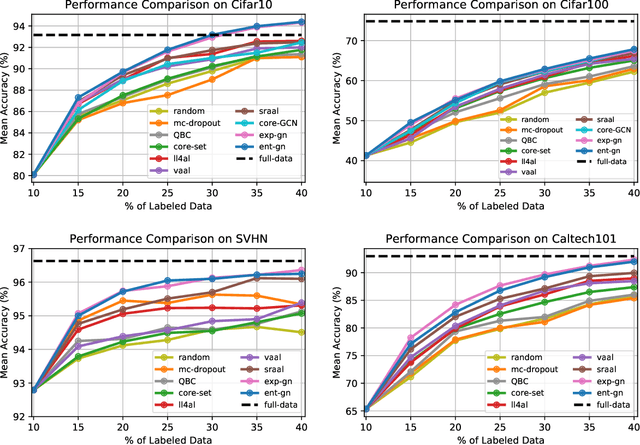

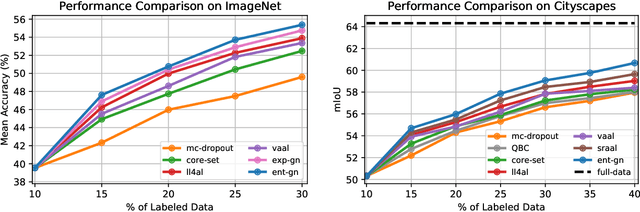
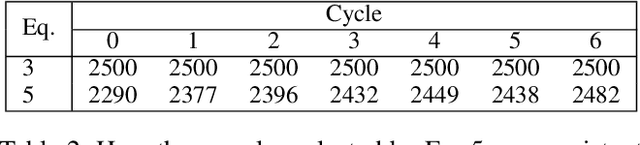
Central to active learning (AL) is what data should be selected for annotation. Existing works attempt to select highly uncertain or informative data for annotation. Nevertheless, it remains unclear how selected data impacts the test performance of the task model used in AL. In this work, we explore such an impact by theoretically proving that selecting unlabeled data of higher gradient norm leads to a lower upper bound of test loss, resulting in a better test performance. However, due to the lack of label information, directly computing gradient norm for unlabeled data is infeasible. To address this challenge, we propose two schemes, namely expected-gradnorm and entropy-gradnorm. The former computes the gradient norm by constructing an expected empirical loss while the latter constructs an unsupervised loss with entropy. Furthermore, we integrate the two schemes in a universal AL framework. We evaluate our method on classical image classification and semantic segmentation tasks. To demonstrate its competency in domain applications and its robustness to noise, we also validate our method on a cellular imaging analysis task, namely cryo-Electron Tomography subtomogram classification. Results demonstrate that our method achieves superior performance against the state-of-the-art. Our source code is available at https://github.com/xulabs/aitom
* 13 pages
MECT: Multi-Metadata Embedding based Cross-Transformer for Chinese Named Entity Recognition
Jul 12, 2021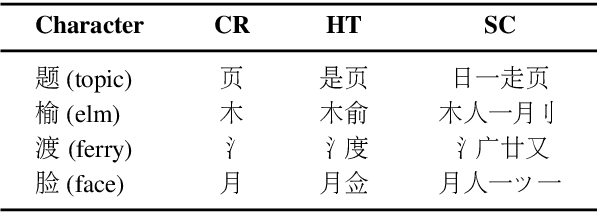
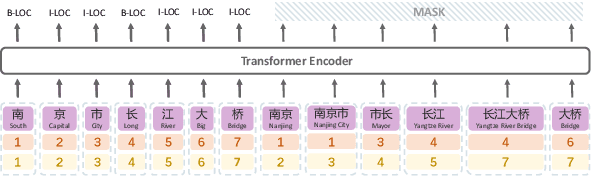

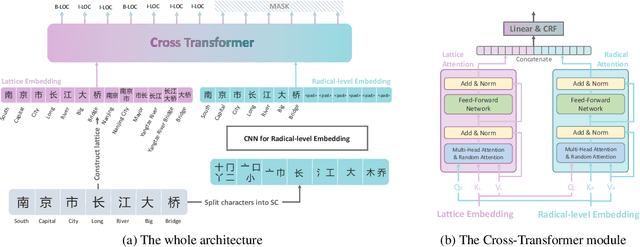
Recently, word enhancement has become very popular for Chinese Named Entity Recognition (NER), reducing segmentation errors and increasing the semantic and boundary information of Chinese words. However, these methods tend to ignore the information of the Chinese character structure after integrating the lexical information. Chinese characters have evolved from pictographs since ancient times, and their structure often reflects more information about the characters. This paper presents a novel Multi-metadata Embedding based Cross-Transformer (MECT) to improve the performance of Chinese NER by fusing the structural information of Chinese characters. Specifically, we use multi-metadata embedding in a two-stream Transformer to integrate Chinese character features with the radical-level embedding. With the structural characteristics of Chinese characters, MECT can better capture the semantic information of Chinese characters for NER. The experimental results obtained on several well-known benchmarking datasets demonstrate the merits and superiority of the proposed MECT method.\footnote{The source code of the proposed method is publicly available at https://github.com/CoderMusou/MECT4CNER.
How does AI play football? An analysis of RL and real-world football strategies
Nov 24, 2021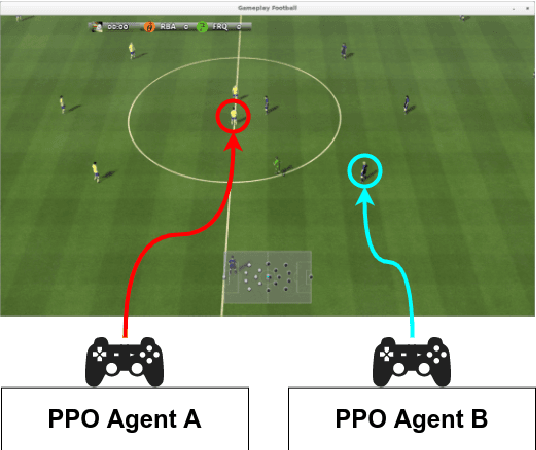

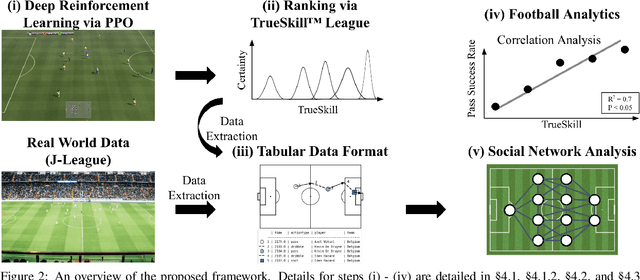
Recent advances in reinforcement learning (RL) have made it possible to develop sophisticated agents that excel in a wide range of applications. Simulations using such agents can provide valuable information in scenarios that are difficult to scientifically experiment in the real world. In this paper, we examine the play-style characteristics of football RL agents and uncover how strategies may develop during training. The learnt strategies are then compared with those of real football players. We explore what can be learnt from the use of simulated environments by using aggregated statistics and social network analysis (SNA). As a result, we found that (1) there are strong correlations between the competitiveness of an agent and various SNA metrics and (2) aspects of the RL agents play style become similar to real world footballers as the agent becomes more competitive. We discuss further advances that may be necessary to improve our understanding necessary to fully utilise RL for the analysis of football.
CLIP Meets Video Captioners: Attribute-Aware Representation Learning Promotes Accurate Captioning
Nov 30, 2021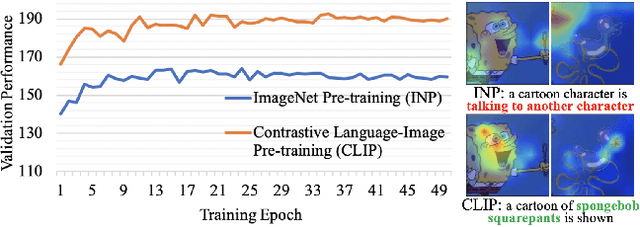
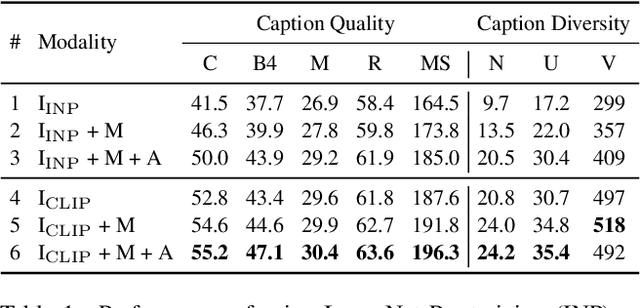
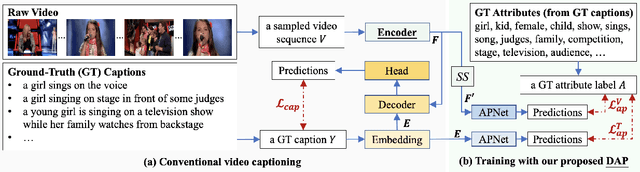

For video captioning, "pre-training and fine-tuning" has become a de facto paradigm, where ImageNet Pre-training (INP) is usually used to help encode the video content, and a task-oriented network is fine-tuned from scratch to cope with caption generation. Comparing INP with the recently proposed CLIP (Contrastive Language-Image Pre-training), this paper investigates the potential deficiencies of INP for video captioning and explores the key to generating accurate descriptions. Specifically, our empirical study on INP vs. CLIP shows that INP makes video caption models tricky to capture attributes' semantics and sensitive to irrelevant background information. By contrast, CLIP's significant boost in caption quality highlights the importance of attribute-aware representation learning. We are thus motivated to introduce Dual Attribute Prediction, an auxiliary task requiring a video caption model to learn the correspondence between video content and attributes and the co-occurrence relations between attributes. Extensive experiments on benchmark datasets demonstrate that our approach enables better learning of attribute-aware representations, bringing consistent improvements on models with different architectures and decoding algorithms.
A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
Nov 30, 2021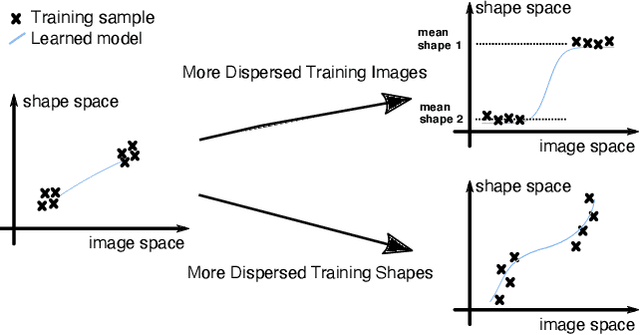
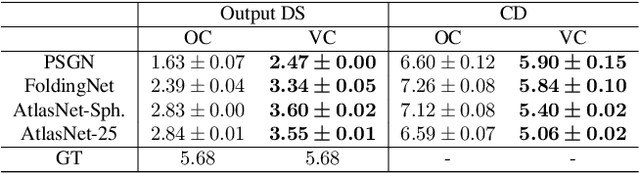
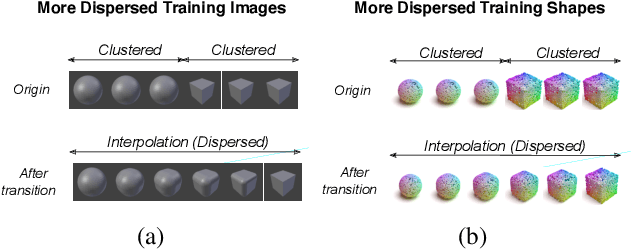
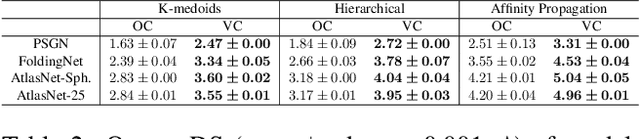
Neural networks (NN) for single-view 3D reconstruction (SVR) have gained in popularity. Recent work points out that for SVR, most cutting-edge NNs have limited performance on reconstructing unseen objects because they rely primarily on recognition (i.e., classification-based methods) rather than shape reconstruction. To understand this issue in depth, we provide a systematic study on when and why NNs prefer recognition to reconstruction and vice versa. Our finding shows that a leading factor in determining recognition versus reconstruction is how dispersed the training data is. Thus, we introduce the dispersion score, a new data-driven metric, to quantify this leading factor and study its effect on NNs. We hypothesize that NNs are biased toward recognition when training images are more dispersed and training shapes are less dispersed. Our hypothesis is supported and the dispersion score is proved effective through our experiments on synthetic and benchmark datasets. We show that the proposed metric is a principal way to analyze reconstruction quality and provides novel information in addition to the conventional reconstruction score.