 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Information Centrality for Intrusion Detection in Large Networks
Apr 27, 2019
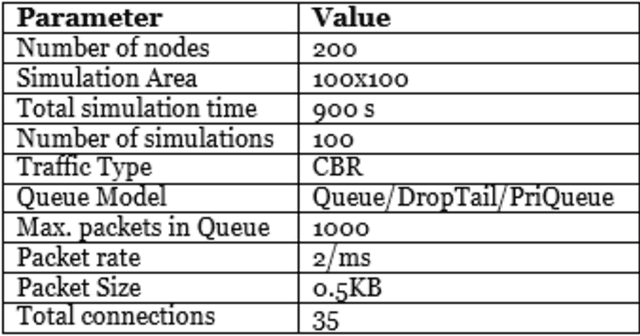
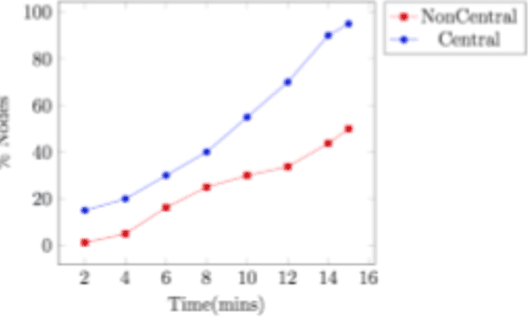
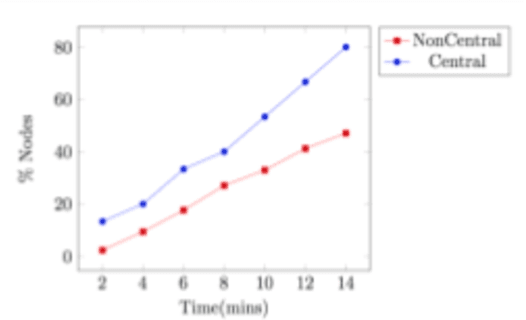
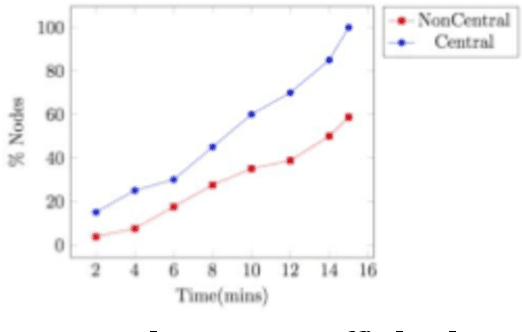
Modern networked systems are constantly under threat from systemic attacks. There has been a massive upsurge in the number of devices connected to a network as well as the associated traffic volume. This has intensified the need to better understand all possible attack vectors during system design and implementation. Further, it has increased the need to mine large data sets, analyzing which has become a daunting task. It is critical to scale monitoring infrastructures to match this need, but a difficult goal for the small and medium organization. Hence, there is a need to propose novel approaches that address the big data problem in security. Information Centrality (IC) labels network nodes with better vantage points for detecting network-based anomalies as central nodes and uses them for detecting a category of attacks called systemic attacks. The main idea is that since these central nodes already see a lot of information flowing through the network, they are in a good position to detect anomalies before other nodes. This research first dives into the importance of using graphs in understanding the topology and information flow. We then introduce the usage of information centrality, a centrality-based index, to reduce data collection in existing communication networks. Using IC-identified central nodes can accelerate outlier detection when armed with a suitable anomaly detection technique. We also come up with a more efficient way to compute Information centrality for large networks. Finally, we demonstrate that central nodes detect anomalous behavior much faster than other non-central nodes, given the anomalous behavior is systemic in nature.
* 14 pages, 4 figures, 18th Annual Security Conference
Quality-Aware Multimodal Biometric Recognition
Dec 10, 2021
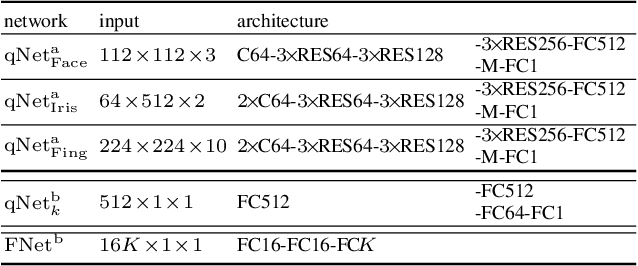
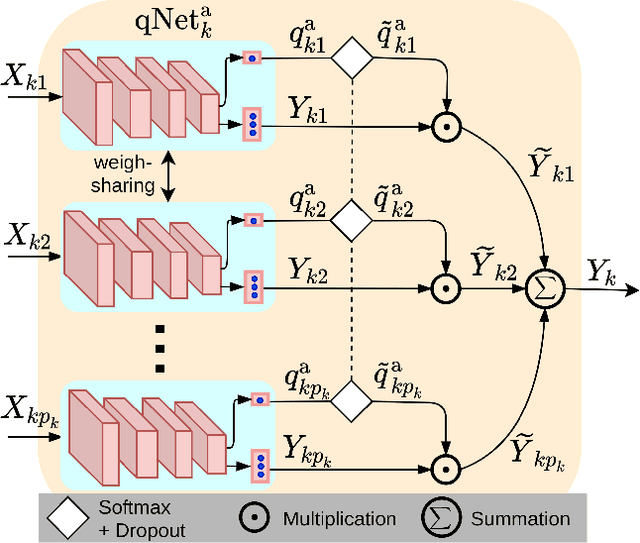
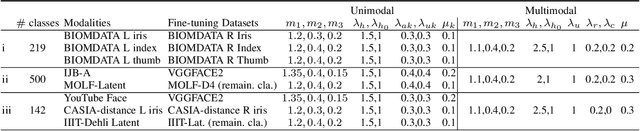
We present a quality-aware multimodal recognition framework that combines representations from multiple biometric traits with varying quality and number of samples to achieve increased recognition accuracy by extracting complimentary identification information based on the quality of the samples. We develop a quality-aware framework for fusing representations of input modalities by weighting their importance using quality scores estimated in a weakly-supervised fashion. This framework utilizes two fusion blocks, each represented by a set of quality-aware and aggregation networks. In addition to architecture modifications, we propose two task-specific loss functions: multimodal separability loss and multimodal compactness loss. The first loss assures that the representations of modalities for a class have comparable magnitudes to provide a better quality estimation, while the multimodal representations of different classes are distributed to achieve maximum discrimination in the embedding space. The second loss, which is considered to regularize the network weights, improves the generalization performance by regularizing the framework. We evaluate the performance by considering three multimodal datasets consisting of face, iris, and fingerprint modalities. The efficacy of the framework is demonstrated through comparison with the state-of-the-art algorithms. In particular, our framework outperforms the rank- and score-level fusion of modalities of BIOMDATA by more than 30% for true acceptance rate at false acceptance rate of $10^{-4}$.
Detection and Localization of Multiple Image Splicing Using MobileNet V1
Aug 22, 2021
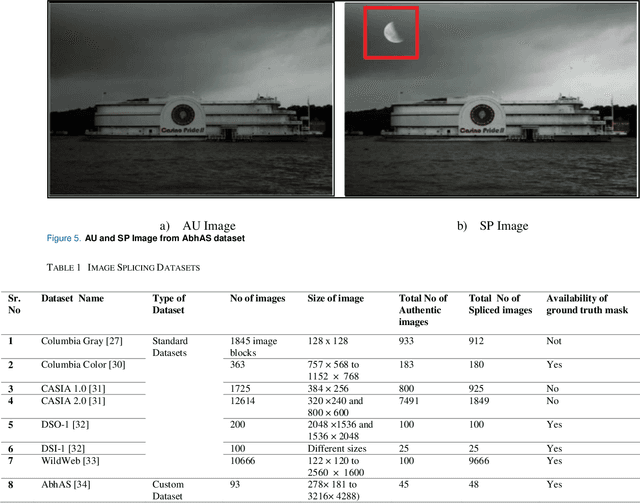


In modern society, digital images have become a prominent source of information and medium of communication. They can, however, be simply altered using freely available image editing software. Two or more images are combined to generate a new image that can transmit information across social media platforms to influence the people in the society. This information may have both positive and negative consequences. Hence there is a need to develop a technique that will detect and locates a multiple image splicing forgery in an image. This research work proposes multiple image splicing forgery detection using Mask R-CNN, with a backbone as a MobileNet V1. It also calculates the percentage score of a forged region of multiple spliced images. The comparative analysis of the proposed work with the variants of ResNet is performed. The proposed model is trained and tested using our MISD (Multiple Image Splicing Dataset), and it is observed that the proposed model outperforms the variants of ResNet models (ResNet 51,101 and 151).
MTLTS: A Multi-Task Framework To Obtain Trustworthy Summaries From Crisis-Related Microblogs
Dec 10, 2021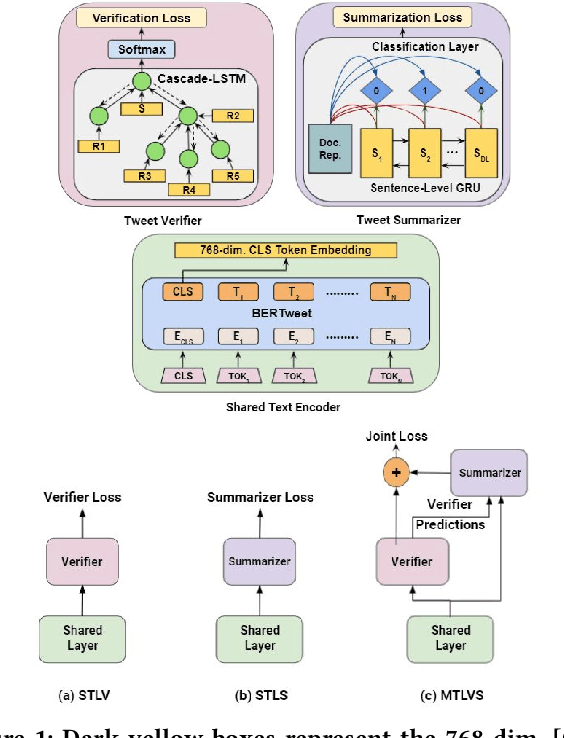
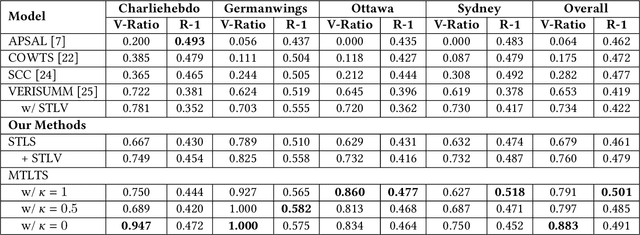
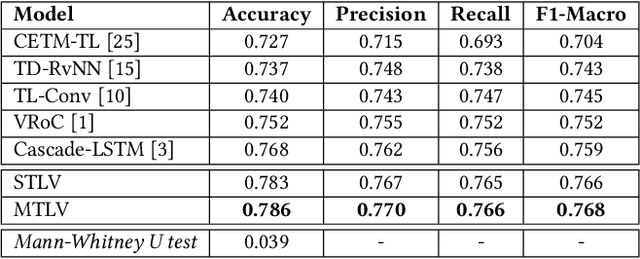
Occurrences of catastrophes such as natural or man-made disasters trigger the spread of rumours over social media at a rapid pace. Presenting a trustworthy and summarized account of the unfolding event in near real-time to the consumers of such potentially unreliable information thus becomes an important task. In this work, we propose MTLTS, the first end-to-end solution for the task that jointly determines the credibility and summary-worthiness of tweets. Our credibility verifier is designed to recursively learn the structural properties of a Twitter conversation cascade, along with the stances of replies towards the source tweet. We then take a hierarchical multi-task learning approach, where the verifier is trained at a lower layer, and the summarizer is trained at a deeper layer where it utilizes the verifier predictions to determine the salience of a tweet. Different from existing disaster-specific summarizers, we model tweet summarization as a supervised task. Such an approach can automatically learn summary-worthy features, and can therefore generalize well across domains. When trained on the PHEME dataset [29], not only do we outperform the strongest baselines for the auxiliary task of verification/rumour detection, we also achieve 21 - 35% gains in the verified ratio of summary tweets, and 16 - 20% gains in ROUGE1-F1 scores over the existing state-of-the-art solutions for the primary task of trustworthy summarization.
Multifield Cosmology with Artificial Intelligence
Sep 20, 2021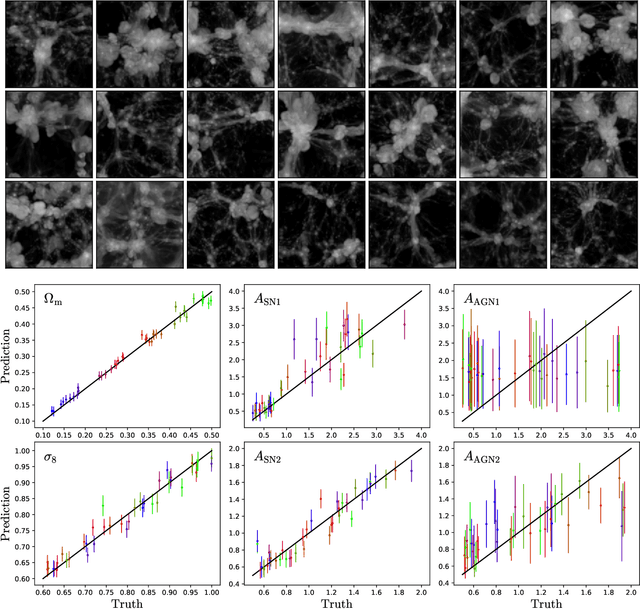
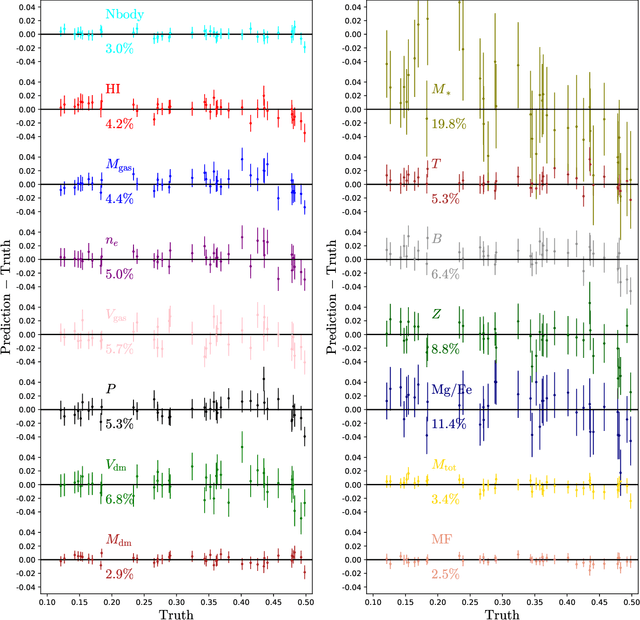
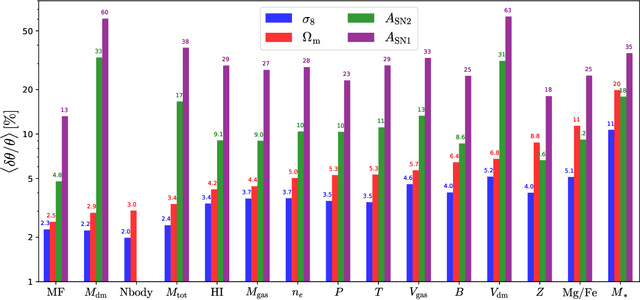
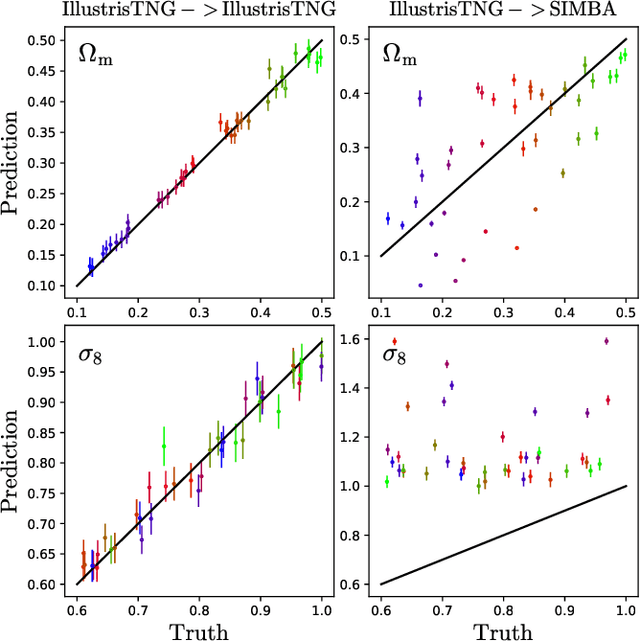
Astrophysical processes such as feedback from supernovae and active galactic nuclei modify the properties and spatial distribution of dark matter, gas, and galaxies in a poorly understood way. This uncertainty is one of the main theoretical obstacles to extract information from cosmological surveys. We use 2,000 state-of-the-art hydrodynamic simulations from the CAMELS project spanning a wide variety of cosmological and astrophysical models and generate hundreds of thousands of 2-dimensional maps for 13 different fields: from dark matter to gas and stellar properties. We use these maps to train convolutional neural networks to extract the maximum amount of cosmological information while marginalizing over astrophysical effects at the field level. Although our maps only cover a small area of $(25~h^{-1}{\rm Mpc})^2$, and the different fields are contaminated by astrophysical effects in very different ways, our networks can infer the values of $\Omega_{\rm m}$ and $\sigma_8$ with a few percent level precision for most of the fields. We find that the marginalization performed by the network retains a wealth of cosmological information compared to a model trained on maps from gravity-only N-body simulations that are not contaminated by astrophysical effects. Finally, we train our networks on multifields -- 2D maps that contain several fields as different colors or channels -- and find that not only they can infer the value of all parameters with higher accuracy than networks trained on individual fields, but they can constrain the value of $\Omega_{\rm m}$ with higher accuracy than the maps from the N-body simulations.
Learnability for the Information Bottleneck
Jul 17, 2019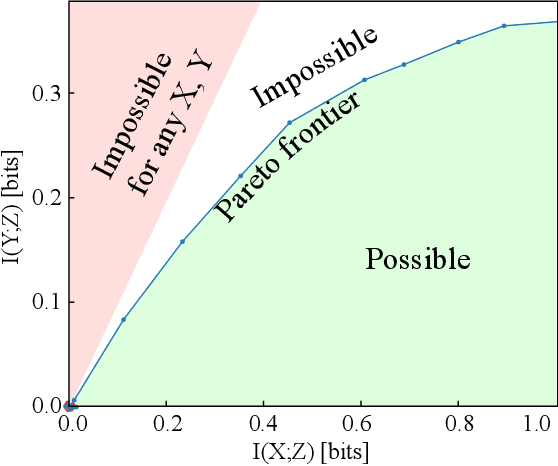
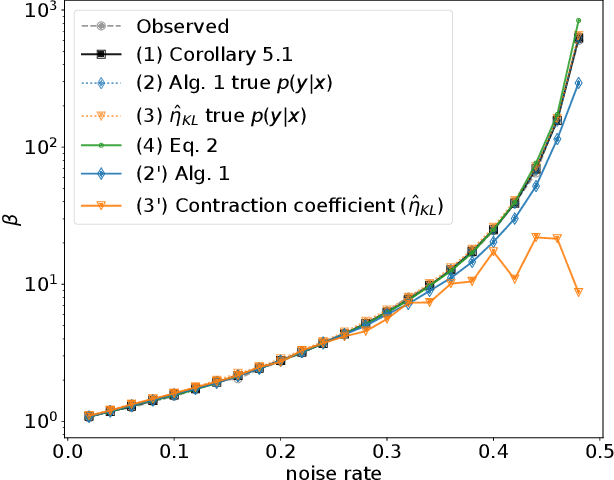
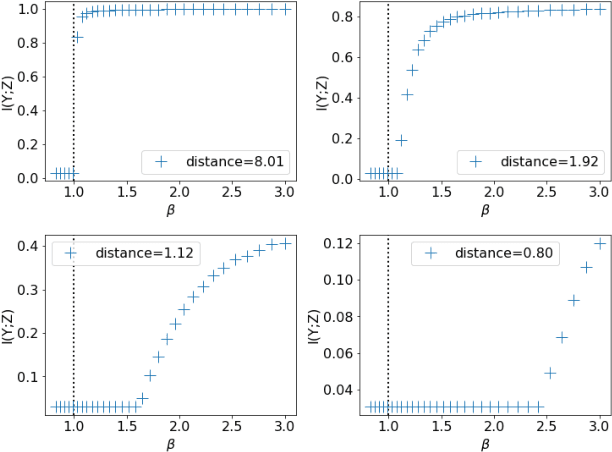
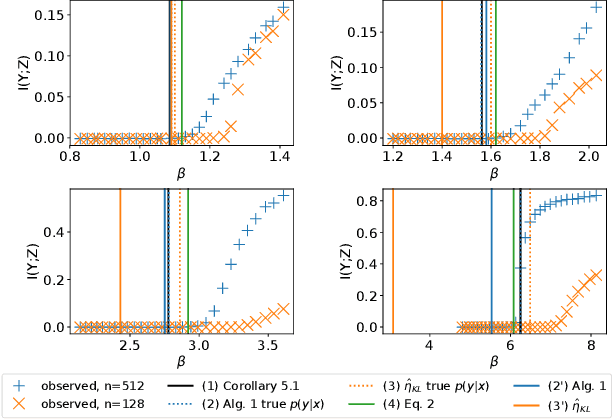
The Information Bottleneck (IB) method (\cite{tishby2000information}) provides an insightful and principled approach for balancing compression and prediction for representation learning. The IB objective $I(X;Z)-\beta I(Y;Z)$ employs a Lagrange multiplier $\beta$ to tune this trade-off. However, in practice, not only is $\beta$ chosen empirically without theoretical guidance, there is also a lack of theoretical understanding between $\beta$, learnability, the intrinsic nature of the dataset and model capacity. In this paper, we show that if $\beta$ is improperly chosen, learning cannot happen -- the trivial representation $P(Z|X)=P(Z)$ becomes the global minimum of the IB objective. We show how this can be avoided, by identifying a sharp phase transition between the unlearnable and the learnable which arises as $\beta$ is varied. This phase transition defines the concept of IB-Learnability. We prove several sufficient conditions for IB-Learnability, which provides theoretical guidance for choosing a good $\beta$. We further show that IB-learnability is determined by the largest confident, typical, and imbalanced subset of the examples (the conspicuous subset), and discuss its relation with model capacity. We give practical algorithms to estimate the minimum $\beta$ for a given dataset. We also empirically demonstrate our theoretical conditions with analyses of synthetic datasets, MNIST, and CIFAR10.
VoRTX: Volumetric 3D Reconstruction With Transformers for Voxelwise View Selection and Fusion
Dec 01, 2021
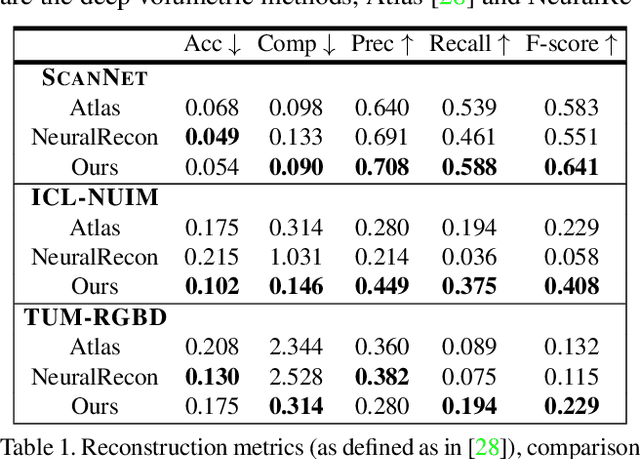
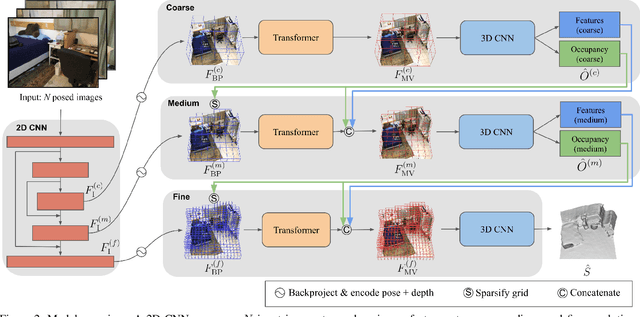
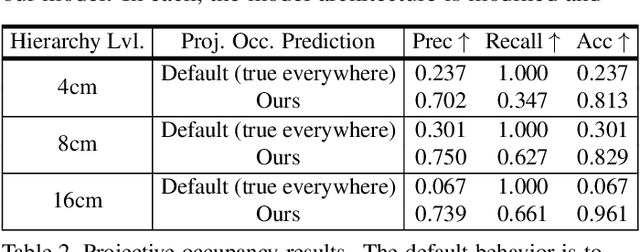
Recent volumetric 3D reconstruction methods can produce very accurate results, with plausible geometry even for unobserved surfaces. However, they face an undesirable trade-off when it comes to multi-view fusion. They can fuse all available view information by global averaging, thus losing fine detail, or they can heuristically cluster views for local fusion, thus restricting their ability to consider all views jointly. Our key insight is that greater detail can be retained without restricting view diversity by learning a view-fusion function conditioned on camera pose and image content. We propose to learn this multi-view fusion using a transformer. To this end, we introduce VoRTX, an end-to-end volumetric 3D reconstruction network using transformers for wide-baseline, multi-view feature fusion. Our model is occlusion-aware, leveraging the transformer architecture to predict an initial, projective scene geometry estimate. This estimate is used to avoid backprojecting image features through surfaces into occluded regions. We train our model on ScanNet and show that it produces better reconstructions than state-of-the-art methods. We also demonstrate generalization without any fine-tuning, outperforming the same state-of-the-art methods on two other datasets, TUM-RGBD and ICL-NUIM.
Intelligent Transportation Systems With The Use of External Infrastructure: A Literature Survey
Dec 10, 2021
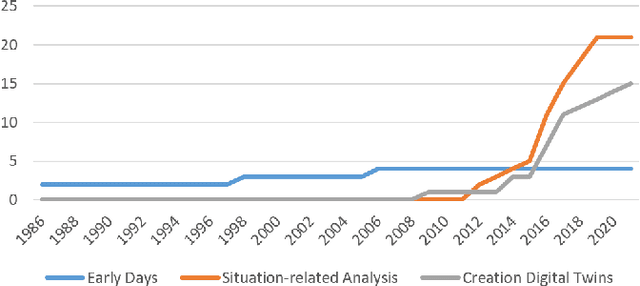
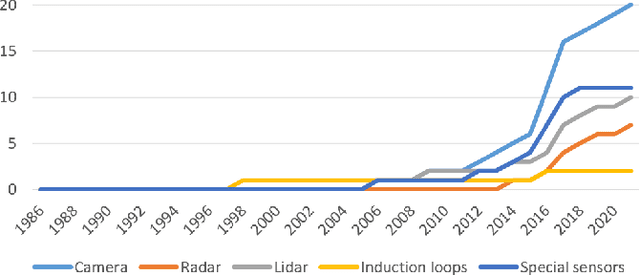
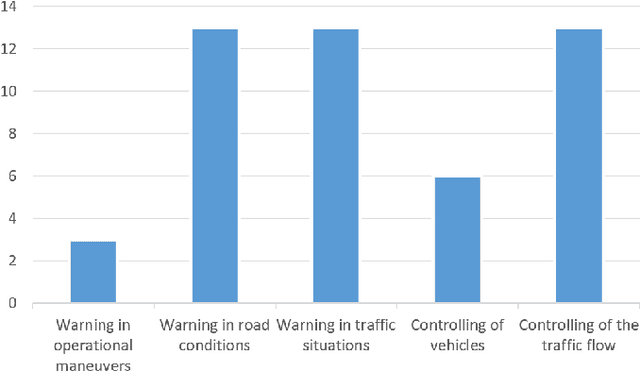
Increasing problems in the transportation segment are accidents, bad traffic flow and pollution. The Intelligent Transportation System with the use of external infrastructure (ITS) can tackle these problems. To the best of our knowledge, there exists no current systematic review of the existing solutions. To fill this knowledge gap, this paper provides an overview about existing ITS which use external infrastructure. Furthermore, this paper discovers the currently not adequately answered research questions. For this reason, we performed a literature review to documents, which describes existing ITS solutions since 2009 until today. We categorized the results according to his technology level and analyzed their properties. Thereby, we made the several ITS comparable and highlighted the past development as well as the current trends. According to the mentioned method, we analyzed more than 346 papers, which includes 40 test bed projects. In summary, the current ITS can deliver high accurate information about individuals in traffic situations in real-time. However, further research in ITS should focus on more reliable perception of the traffic with the use of modern sensors, plug and play mechanism as well as secure real-time distribution in decentralized manner for a high amount of data. With addressing these topics, the development of Intelligent Transportation Systems is in a correction direction for the comprehensive roll-out.
Language bias in Visual Question Answering: A Survey and Taxonomy
Nov 16, 2021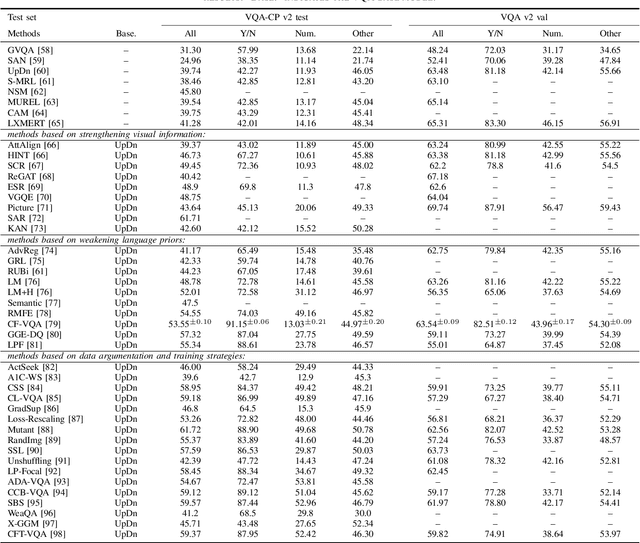
Visual question answering (VQA) is a challenging task, which has attracted more and more attention in the field of computer vision and natural language processing. However, the current visual question answering has the problem of language bias, which reduces the robustness of the model and has an adverse impact on the practical application of visual question answering. In this paper, we conduct a comprehensive review and analysis of this field for the first time, and classify the existing methods according to three categories, including enhancing visual information, weakening language priors, data enhancement and training strategies. At the same time, the relevant representative methods are introduced, summarized and analyzed in turn. The causes of language bias are revealed and classified. Secondly, this paper introduces the datasets mainly used for testing, and reports the experimental results of various existing methods. Finally, we discuss the possible future research directions in this field.
Towards autonomous artificial agents with an active self: modeling sense of control in situated action
Dec 10, 2021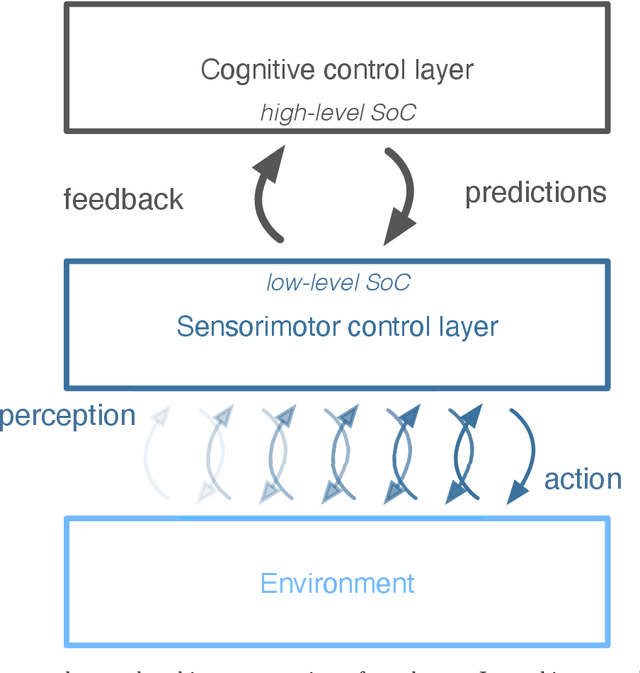
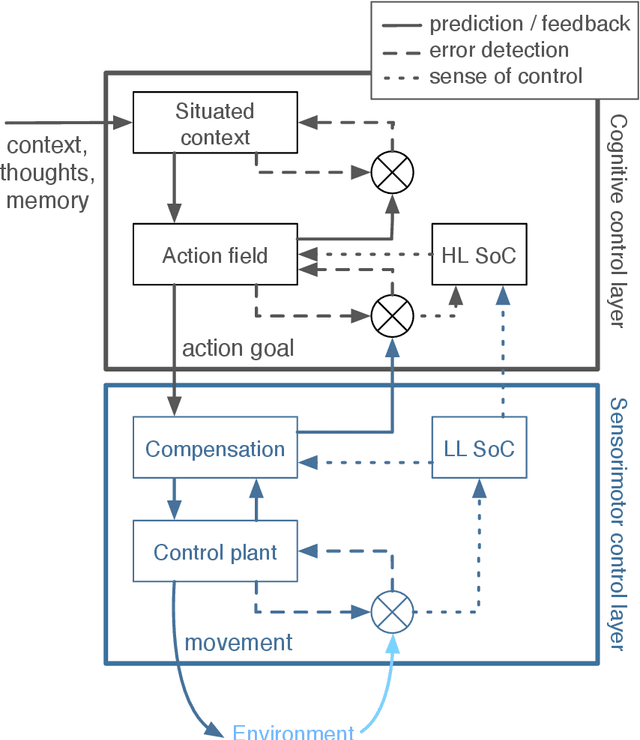
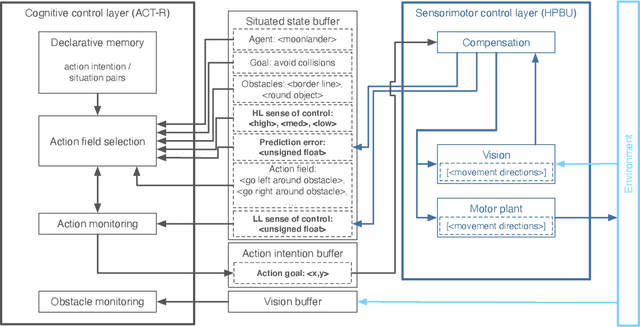
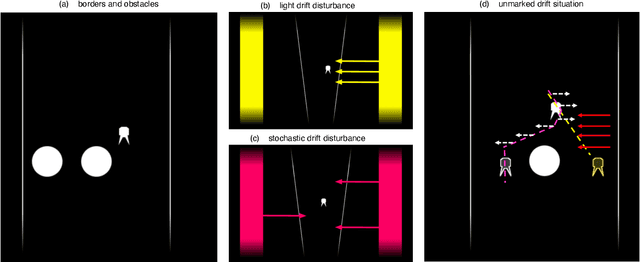
In this paper we present a computational modeling account of an active self in artificial agents. In particular we focus on how an agent can be equipped with a sense of control and how it arises in autonomous situated action and, in turn, influences action control. We argue that this requires laying out an embodied cognitive model that combines bottom-up processes (sensorimotor learning and fine-grained adaptation of control) with top-down processes (cognitive processes for strategy selection and decision-making). We present such a conceptual computational architecture based on principles of predictive processing and free energy minimization. Using this general model, we describe how a sense of control can form across the levels of a control hierarchy and how this can support action control in an unpredictable environment. We present an implementation of this model as well as first evaluations in a simulated task scenario, in which an autonomous agent has to cope with un-/predictable situations and experiences corresponding sense of control. We explore different model parameter settings that lead to different ways of combining low-level and high-level action control. The results show the importance of appropriately weighting information in situations where the need for low/high-level action control varies and they demonstrate how the sense of control can facilitate this.