 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
NeSF: Neural Shading Field for Image Harmonization
Dec 02, 2021
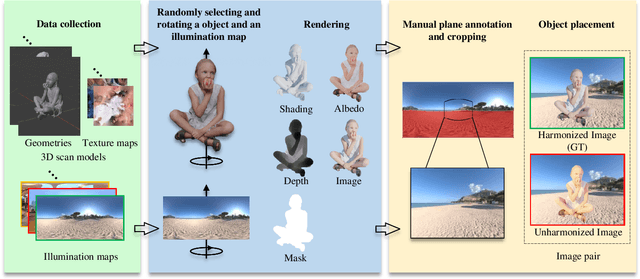

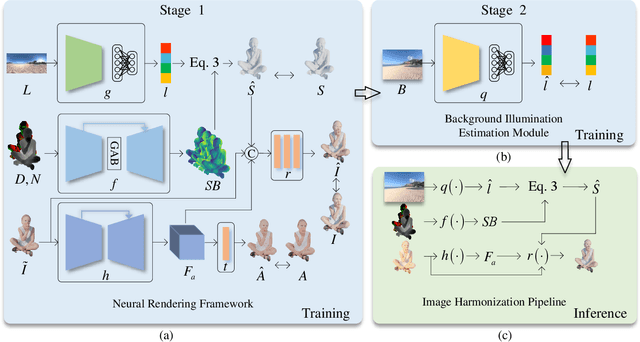
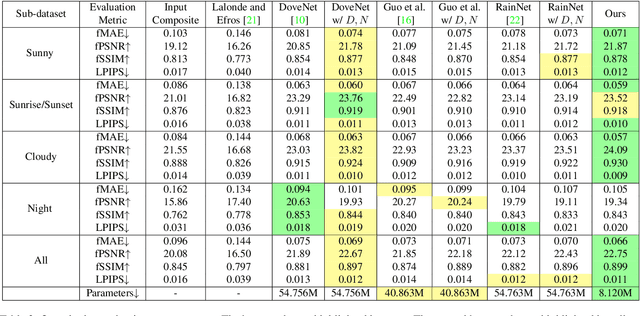
Image harmonization aims at adjusting the appearance of the foreground to make it more compatible with the background. Due to a lack of understanding of the background illumination direction, existing works are incapable of generating a realistic foreground shading. In this paper, we decompose the image harmonization into two sub-problems: 1) illumination estimation of background images and 2) rendering of foreground objects. Before solving these two sub-problems, we first learn a direction-aware illumination descriptor via a neural rendering framework, of which the key is a Shading Module that decomposes the shading field into multiple shading components given depth information. Then we design a Background Illumination Estimation Module to extract the direction-aware illumination descriptor from the background. Finally, the illumination descriptor is used in conjunction with the neural rendering framework to generate the harmonized foreground image containing a novel harmonized shading. Moreover, we construct a photo-realistic synthetic image harmonization dataset that contains numerous shading variations by image-based lighting. Extensive experiments on this dataset demonstrate the effectiveness of the proposed method. Our dataset and code will be made publicly available.
Open-Domain, Content-based, Multi-modal Fact-checking of Out-of-Context Images via Online Resources
Dec 07, 2021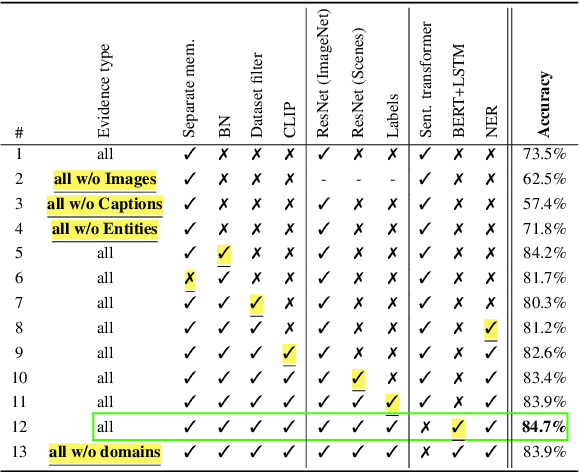
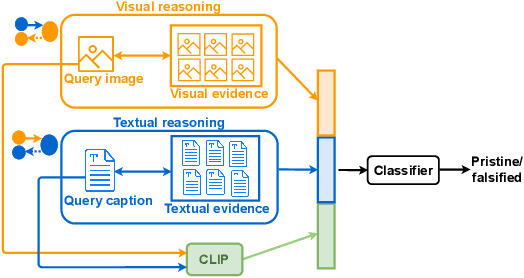
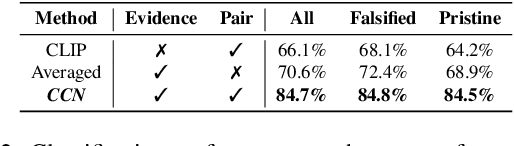
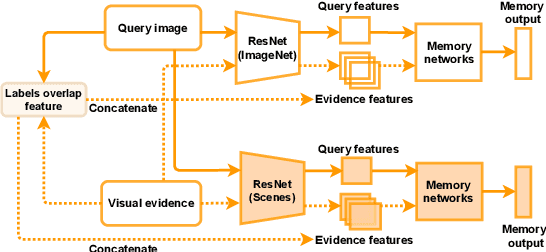
Misinformation is now a major problem due to its potential high risks to our core democratic and societal values and orders. Out-of-context misinformation is one of the easiest and effective ways used by adversaries to spread viral false stories. In this threat, a real image is re-purposed to support other narratives by misrepresenting its context and/or elements. The internet is being used as the go-to way to verify information using different sources and modalities. Our goal is an inspectable method that automates this time-consuming and reasoning-intensive process by fact-checking the image-caption pairing using Web evidence. To integrate evidence and cues from both modalities, we introduce the concept of 'multi-modal cycle-consistency check'; starting from the image/caption, we gather textual/visual evidence, which will be compared against the other paired caption/image, respectively. Moreover, we propose a novel architecture, Consistency-Checking Network (CCN), that mimics the layered human reasoning across the same and different modalities: the caption vs. textual evidence, the image vs. visual evidence, and the image vs. caption. Our work offers the first step and benchmark for open-domain, content-based, multi-modal fact-checking, and significantly outperforms previous baselines that did not leverage external evidence.
Studying squeeze-and-excitation used in CNN for speaker verification
Sep 13, 2021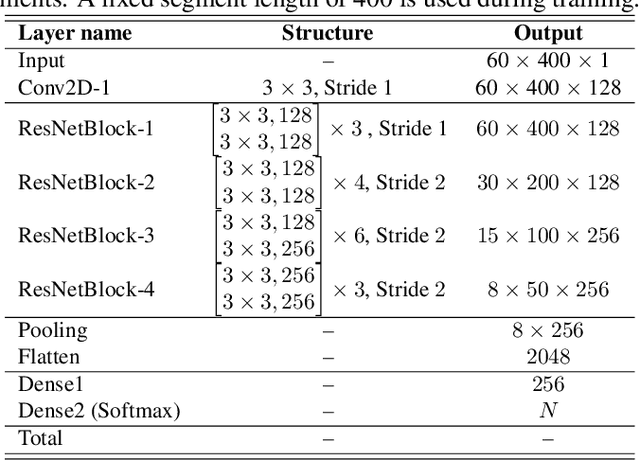
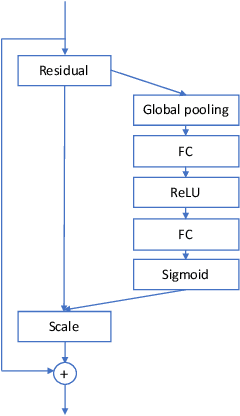
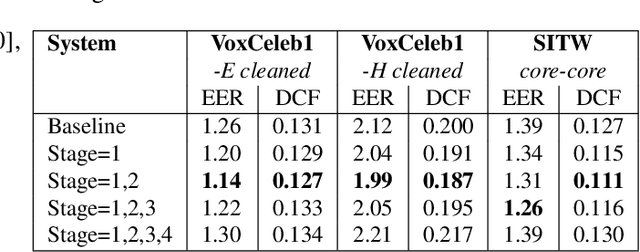
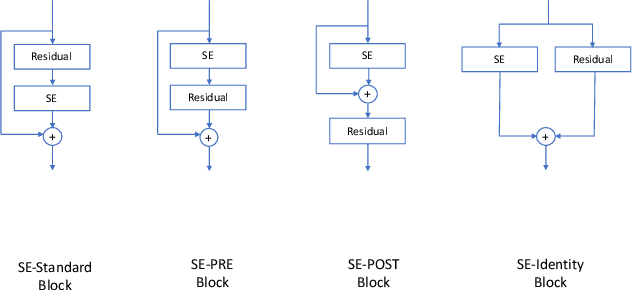
In speaker verification, the extraction of voice representations is mainly based on the Residual Neural Network (ResNet) architecture. ResNet is built upon convolution layers which learn filters to capture local spatial patterns along all the input, then generate feature maps that jointly encode the spatial and channel information. Unfortunately, all feature maps in a convolution layer are learnt independently (the convolution layer does not exploit the dependencies between feature maps) and locally. This problem has first been tackled in image processing. A channel attention mechanism, called squeeze-and-excitation (SE), has recently been proposed in convolution layers and applied to speaker verification. This mechanism re-weights the information extracted across features maps. In this paper, we first propose an original qualitative study about the influence and the role of the SE mechanism applied to the speaker verification task at different stages of the ResNet, and then evaluate several SE architectures. We finally propose to improve the SE approach with a new pool- ing variant based on the concatenation of mean- and standard- deviation-pooling. Results showed that applying SE only on the first stages of the ResNet allows to better capture speaker information for the verification task, and that significant discrimination gains on Voxceleb1-E, Voxceleb1-H and SITW evaluation tasks have been noted using the proposed pooling variant.
Joint Audio-Text Model for Expressive Speech-Driven 3D Facial Animation
Dec 07, 2021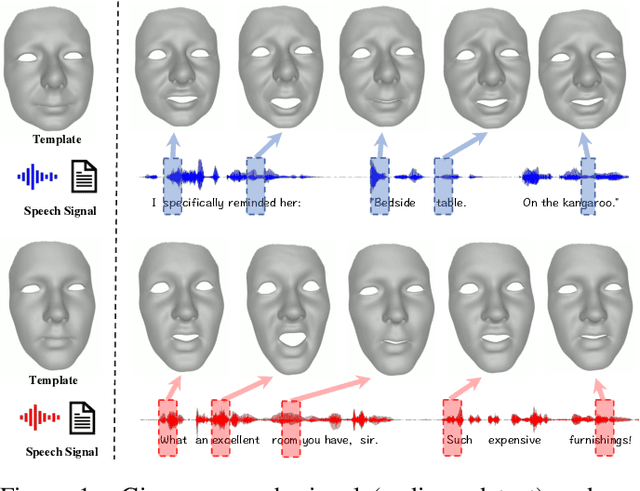
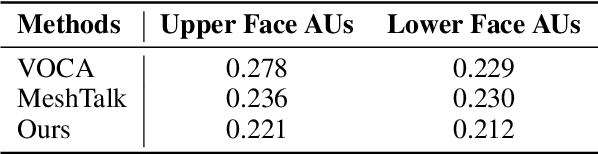
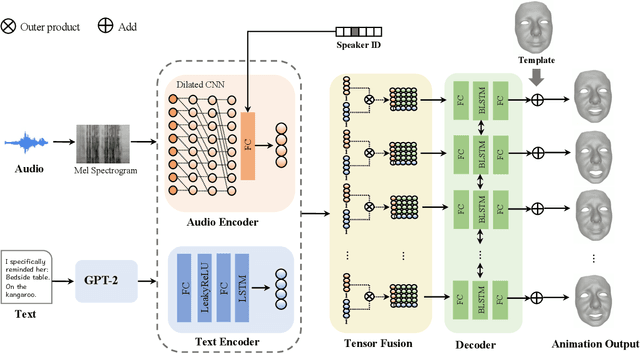
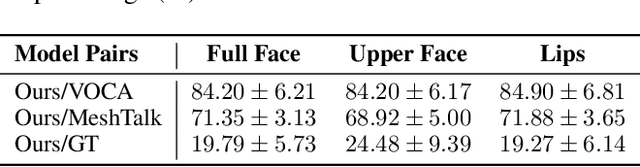
Speech-driven 3D facial animation with accurate lip synchronization has been widely studied. However, synthesizing realistic motions for the entire face during speech has rarely been explored. In this work, we present a joint audio-text model to capture the contextual information for expressive speech-driven 3D facial animation. The existing datasets are collected to cover as many different phonemes as possible instead of sentences, thus limiting the capability of the audio-based model to learn more diverse contexts. To address this, we propose to leverage the contextual text embeddings extracted from the powerful pre-trained language model that has learned rich contextual representations from large-scale text data. Our hypothesis is that the text features can disambiguate the variations in upper face expressions, which are not strongly correlated with the audio. In contrast to prior approaches which learn phoneme-level features from the text, we investigate the high-level contextual text features for speech-driven 3D facial animation. We show that the combined acoustic and textual modalities can synthesize realistic facial expressions while maintaining audio-lip synchronization. We conduct the quantitative and qualitative evaluations as well as the perceptual user study. The results demonstrate the superior performance of our model against existing state-of-the-art approaches.
META: Mimicking Embedding via oThers' Aggregation for Generalizable Person Re-identification
Dec 16, 2021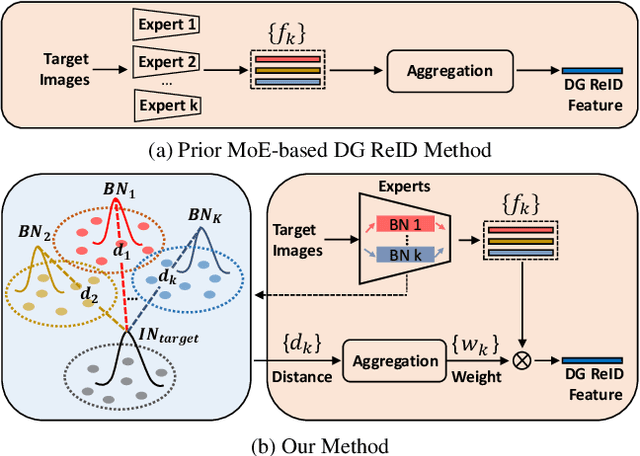
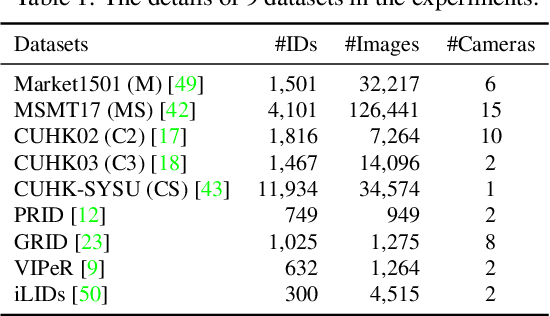
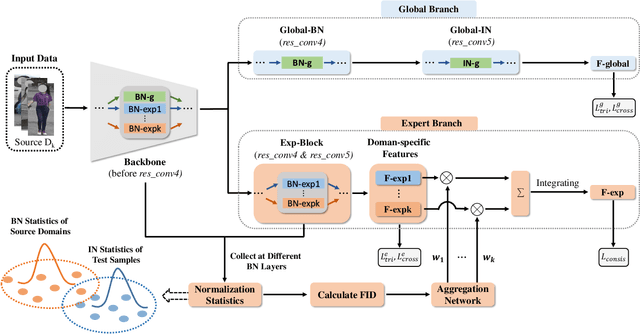
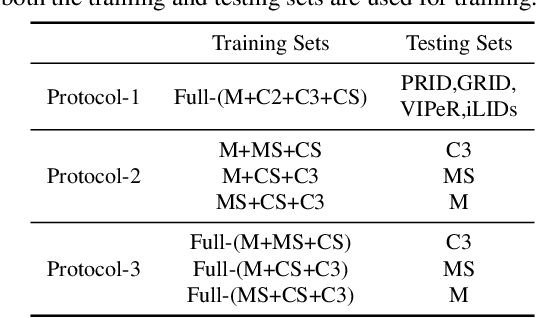
Domain generalizable (DG) person re-identification (ReID) aims to test across unseen domains without access to the target domain data at training time, which is a realistic but challenging problem. In contrast to methods assuming an identical model for different domains, Mixture of Experts (MoE) exploits multiple domain-specific networks for leveraging complementary information between domains, obtaining impressive results. However, prior MoE-based DG ReID methods suffer from a large model size with the increase of the number of source domains, and most of them overlook the exploitation of domain-invariant characteristics. To handle the two issues above, this paper presents a new approach called Mimicking Embedding via oThers' Aggregation (META) for DG ReID. To avoid the large model size, experts in META do not add a branch network for each source domain but share all the parameters except for the batch normalization layers. Besides multiple experts, META leverages Instance Normalization (IN) and introduces it into a global branch to pursue invariant features across domains. Meanwhile, META considers the relevance of an unseen target sample and source domains via normalization statistics and develops an aggregation network to adaptively integrate multiple experts for mimicking unseen target domain. Benefiting from a proposed consistency loss and an episodic training algorithm, we can expect META to mimic embedding for a truly unseen target domain. Extensive experiments verify that META surpasses state-of-the-art DG ReID methods by a large margin.
Softmax Is Not an Artificial Trick: An Information-Theoretic View of Softmax in Neural Networks
Oct 15, 2019
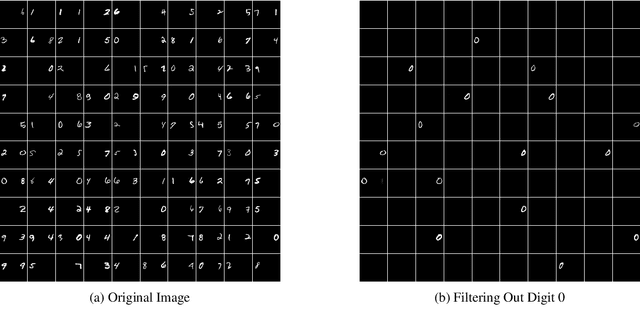
Despite great popularity of applying softmax to map the non-normalised outputs of a neural network to a probability distribution over predicting classes, this normalised exponential transformation still seems to be artificial. A theoretic framework that incorporates softmax as an intrinsic component is still lacking. In this paper, we view neural networks embedding softmax from an information-theoretic perspective. Under this view, we can naturally and mathematically derive log-softmax as an inherent component in a neural network for evaluating the conditional mutual information between network output vectors and labels given an input datum. We show that training deterministic neural networks through maximising log-softmax is equivalent to enlarging the conditional mutual information, i.e., feeding label information into network outputs. We also generalise our informative-theoretic perspective to neural networks with stochasticity and derive information upper and lower bounds of log-softmax. In theory, such an information-theoretic view offers rationality support for embedding softmax in neural networks; in practice, we eventually demonstrate a computer vision application example of how to employ our information-theoretic view to filter out targeted objects on images.
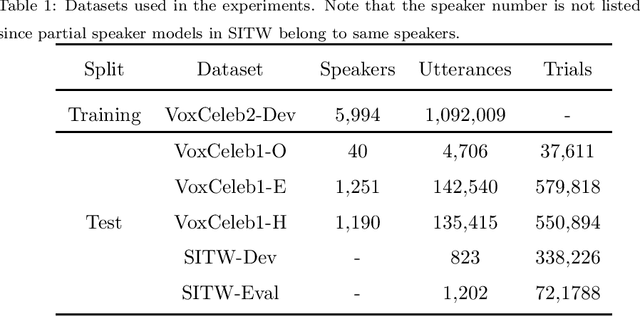
RSKNet-MTSP: Effective and Portable Deep Architecture for Speaker Verification
Aug 30, 2021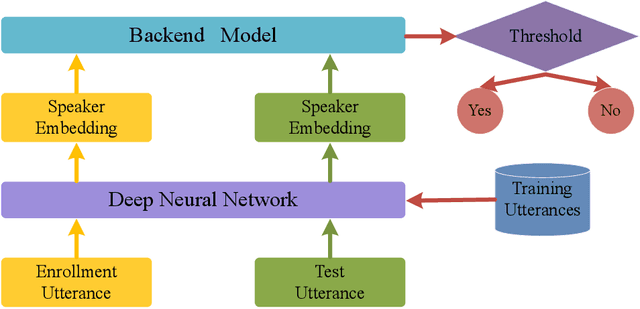
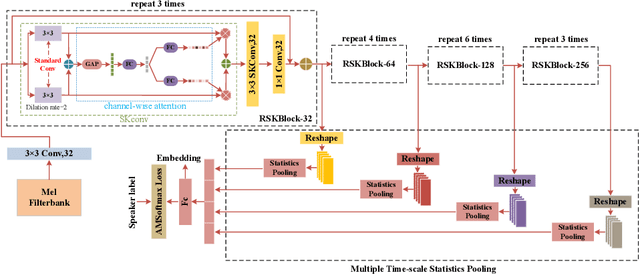

The convolutional neural network (CNN) based approaches have shown great success for speaker verification (SV) tasks, where modeling long temporal context and reducing information loss of speaker characteristics are two important challenges significantly affecting the verification performance. Previous works have introduced dilated convolution and multi-scale aggregation methods to address above challenges. However, such methods are also hard to make full use of some valuable information, which make it difficult to substantially improve the verification performance. To address above issues, we construct a novel CNN-based architecture for SV, called RSKNet-MTSP, where a residual selective kernel block (RSKBlock) and a multiple time-scale statistics pooling (MTSP) module are first proposed. The RSKNet-MTSP can capture both long temporal context and neighbouring information, and gather more speaker-discriminative information from multi-scale features. In order to design a portable model for real applications with limited resources, we then present a lightweight version of RSKNet-MTSP, namely RSKNet-MTSP-L, which employs a combination technique associating the depthwise separable convolutions with low-rank factorization of weight matrices. Extensive experiments are conducted on two public SV datasets, VoxCeleb and Speaker in the Wild (SITW). The results demonstrate that 1) RSKNet-MTSP outperforms the state-of-the-art deep embedding architectures by at least 9%-26% in all test sets. 2) RSKNet-MTSP-L achieves competitive performance compared with baseline models with 17%-39% less network parameters. The ablation experiments further illustrate that our proposed approaches can achieve substantial improvement over prior methods.
RadFusion: Benchmarking Performance and Fairness for Multimodal Pulmonary Embolism Detection from CT and EHR
Nov 27, 2021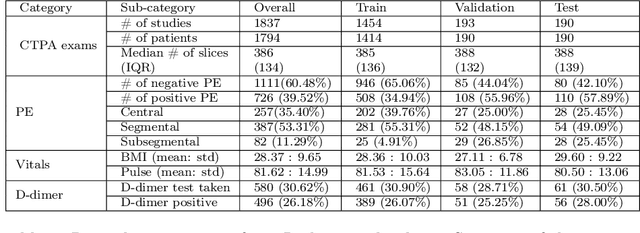
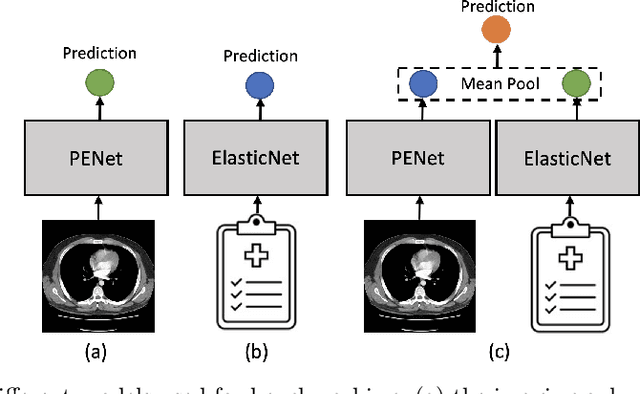
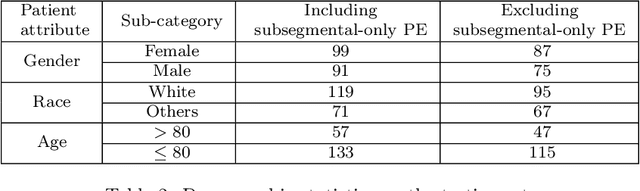
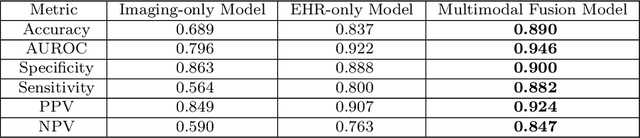
Despite the routine use of electronic health record (EHR) data by radiologists to contextualize clinical history and inform image interpretation, the majority of deep learning architectures for medical imaging are unimodal, i.e., they only learn features from pixel-level information. Recent research revealing how race can be recovered from pixel data alone highlights the potential for serious biases in models which fail to account for demographics and other key patient attributes. Yet the lack of imaging datasets which capture clinical context, inclusive of demographics and longitudinal medical history, has left multimodal medical imaging underexplored. To better assess these challenges, we present RadFusion, a multimodal, benchmark dataset of 1794 patients with corresponding EHR data and high-resolution computed tomography (CT) scans labeled for pulmonary embolism. We evaluate several representative multimodal fusion models and benchmark their fairness properties across protected subgroups, e.g., gender, race/ethnicity, age. Our results suggest that integrating imaging and EHR data can improve classification performance and robustness without introducing large disparities in the true positive rate between population groups.
SVG-Net: An SVG-based Trajectory Prediction Model
Oct 11, 2021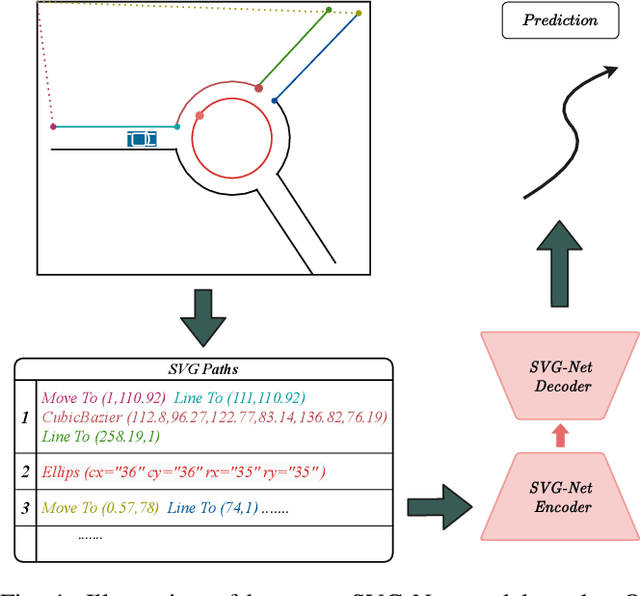
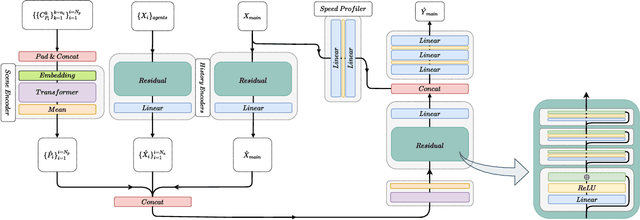
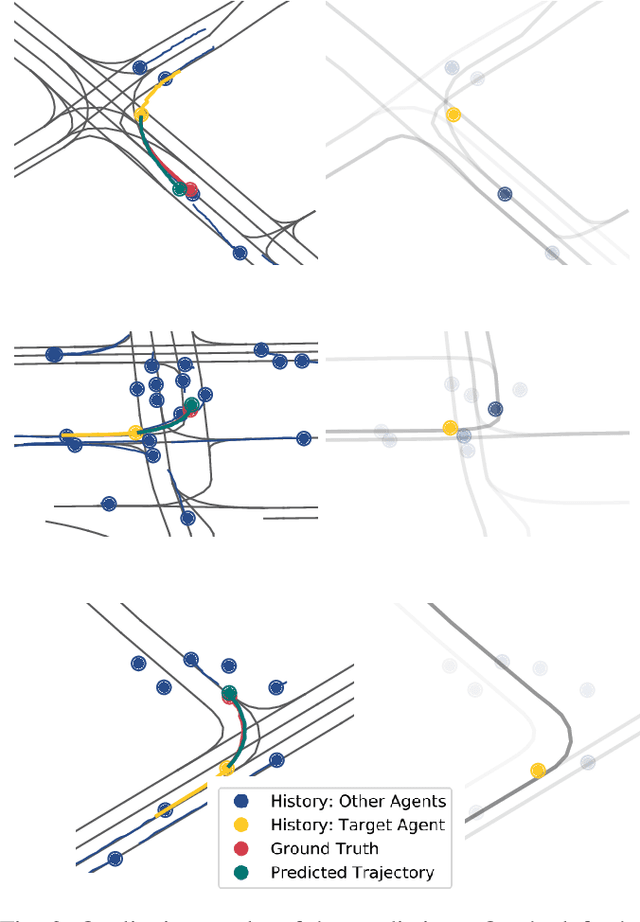
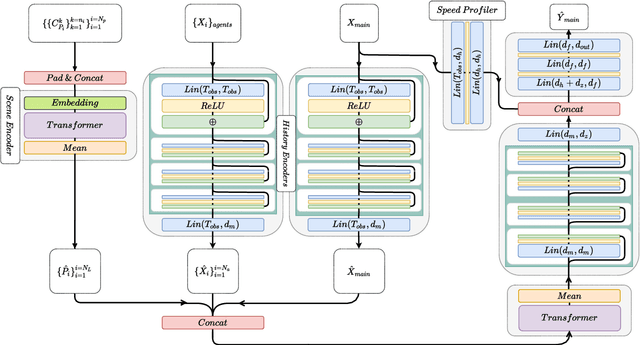
Anticipating motions of vehicles in a scene is an essential problem for safe autonomous driving systems. To this end, the comprehension of the scene's infrastructure is often the main clue for predicting future trajectories. Most of the proposed approaches represent the scene with a rasterized format and some of the more recent approaches leverage custom vectorized formats. In contrast, we propose representing the scene's information by employing Scalable Vector Graphics (SVG). SVG is a well-established format that matches the problem of trajectory prediction better than rasterized formats while being more general than arbitrary vectorized formats. SVG has the potential to provide the convenience and generality of raster-based solutions if coupled with a powerful tool such as CNNs, for which we introduce SVG-Net. SVG-Net is a Transformer-based Neural Network that can effectively capture the scene's information from SVG inputs. Thanks to the self-attention mechanism in its Transformers, SVG-Net can also adequately apprehend relations amongst the scene and the agents. We demonstrate SVG-Net's effectiveness by evaluating its performance on the publicly available Argoverse forecasting dataset. Finally, we illustrate how, by using SVG, one can benefit from datasets and advancements in other research fronts that also utilize the same input format. Our code is available at https://vita-epfl.github.io/SVGNet/.
Handwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning
Dec 07, 2021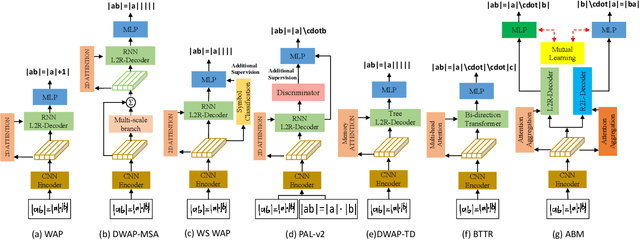
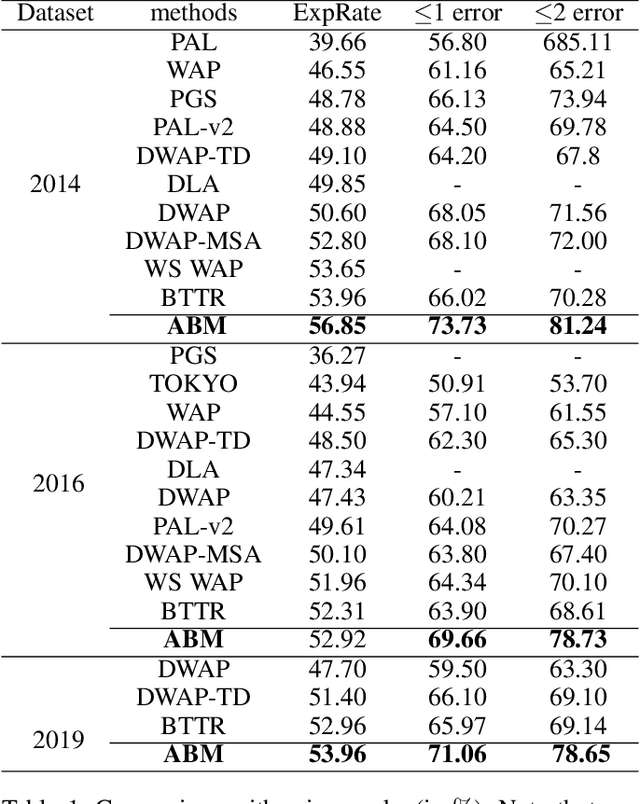
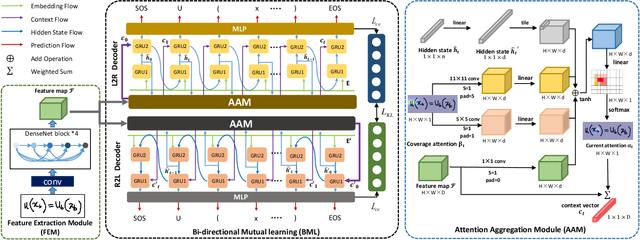
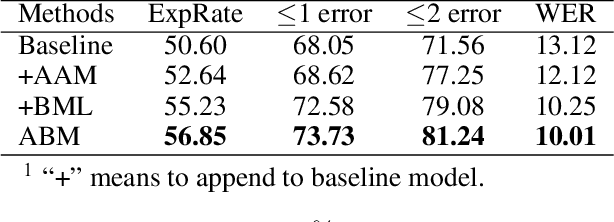
Handwritten mathematical expression recognition aims to automatically generate LaTeX sequences from given images. Currently, attention-based encoder-decoder models are widely used in this task. They typically generate target sequences in a left-to-right (L2R) manner, leaving the right-to-left (R2L) contexts unexploited. In this paper, we propose an Attention aggregation based Bi-directional Mutual learning Network (ABM) which consists of one shared encoder and two parallel inverse decoders (L2R and R2L). The two decoders are enhanced via mutual distillation, which involves one-to-one knowledge transfer at each training step, making full use of the complementary information from two inverse directions. Moreover, in order to deal with mathematical symbols in diverse scales, an Attention Aggregation Module (AAM) is proposed to effectively integrate multi-scale coverage attentions. Notably, in the inference phase, given that the model already learns knowledge from two inverse directions, we only use the L2R branch for inference, keeping the original parameter size and inference speed. Extensive experiments demonstrate that our proposed approach achieves the recognition accuracy of 56.85 % on CROHME 2014, 52.92 % on CROHME 2016, and 53.96 % on CROHME 2019 without data augmentation and model ensembling, substantially outperforming the state-of-the-art methods. The source code is available in the supplementary materials.
* 9 pages,5 figures, to be published in AAAI 2022