 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Comparative Study of Transformers on Word Sense Disambiguation
Nov 30, 2021

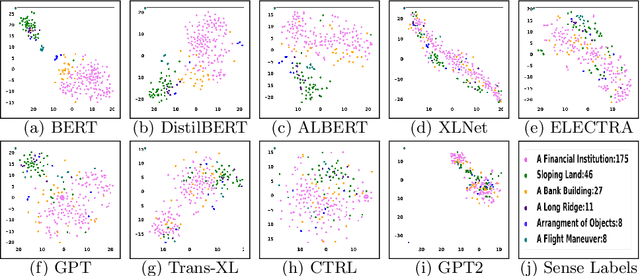
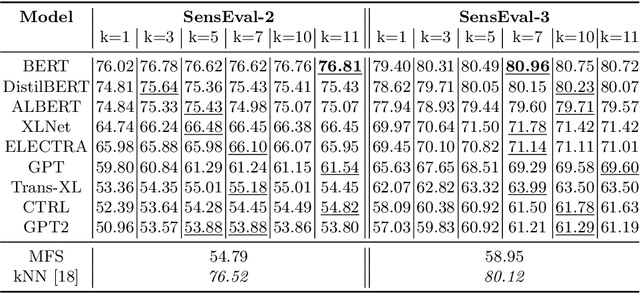
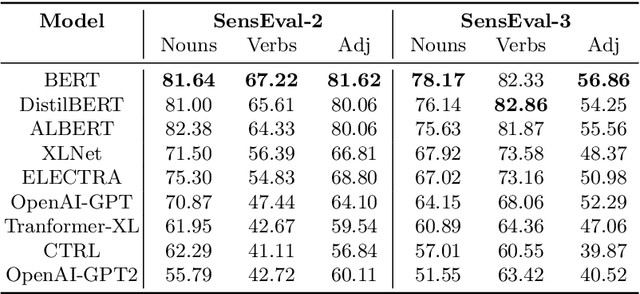
Recent years of research in Natural Language Processing (NLP) have witnessed dramatic growth in training large models for generating context-aware language representations. In this regard, numerous NLP systems have leveraged the power of neural network-based architectures to incorporate sense information in embeddings, resulting in Contextualized Word Embeddings (CWEs). Despite this progress, the NLP community has not witnessed any significant work performing a comparative study on the contextualization power of such architectures. This paper presents a comparative study and an extensive analysis of nine widely adopted Transformer models. These models are BERT, CTRL, DistilBERT, OpenAI-GPT, OpenAI-GPT2, Transformer-XL, XLNet, ELECTRA, and ALBERT. We evaluate their contextualization power using two lexical sample Word Sense Disambiguation (WSD) tasks, SensEval-2 and SensEval-3. We adopt a simple yet effective approach to WSD that uses a k-Nearest Neighbor (kNN) classification on CWEs. Experimental results show that the proposed techniques also achieve superior results over the current state-of-the-art on both the WSD tasks
Is Class-Incremental Enough for Continual Learning?
Dec 06, 2021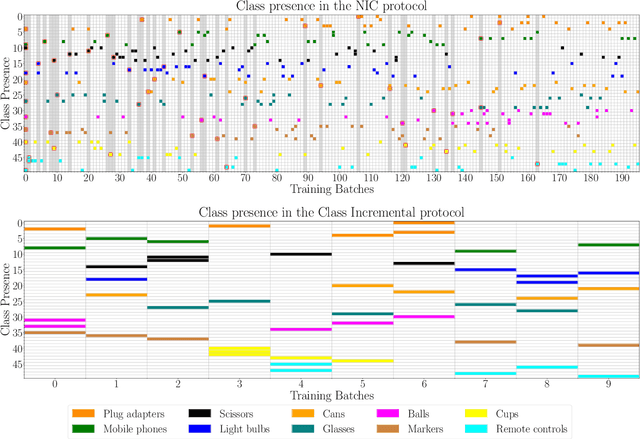
The ability of a model to learn continually can be empirically assessed in different continual learning scenarios. Each scenario defines the constraints and the opportunities of the learning environment. Here, we challenge the current trend in the continual learning literature to experiment mainly on class-incremental scenarios, where classes present in one experience are never revisited. We posit that an excessive focus on this setting may be limiting for future research on continual learning, since class-incremental scenarios artificially exacerbate catastrophic forgetting, at the expense of other important objectives like forward transfer and computational efficiency. In many real-world environments, in fact, repetition of previously encountered concepts occurs naturally and contributes to softening the disruption of previous knowledge. We advocate for a more in-depth study of alternative continual learning scenarios, in which repetition is integrated by design in the stream of incoming information. Starting from already existing proposals, we describe the advantages such class-incremental with repetition scenarios could offer for a more comprehensive assessment of continual learning models.
Reliable Estimation of Individual Treatment Effect with Causal Information Bottleneck
Jun 07, 2019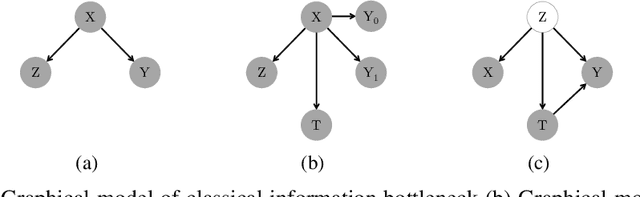
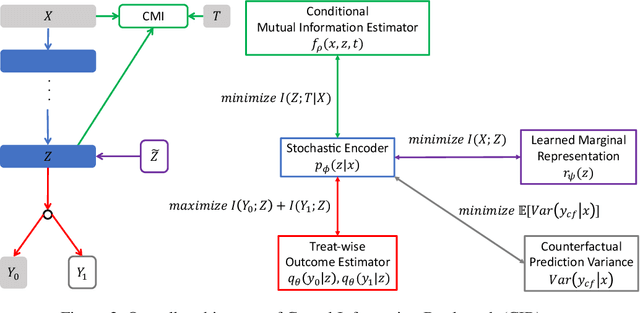

Estimating individual level treatment effects (ITE) from observational data is a challenging and important area in causal machine learning and is commonly considered in diverse mission-critical applications. In this paper, we propose an information theoretic approach in order to find more reliable representations for estimating ITE. We leverage the Information Bottleneck (IB) principle, which addresses the trade-off between conciseness and predictive power of representation. With the introduction of an extended graphical model for causal information bottleneck, we encourage the independence between the learned representation and the treatment type. We also introduce an additional form of a regularizer from the perspective of understanding ITE in the semi-supervised learning framework to ensure more reliable representations. Experimental results show that our model achieves the state-of-the-art results and exhibits more reliable prediction performances with uncertainty information on real-world datasets.
A Real-Time Energy and Cost Efficient Vehicle Route Assignment Neural Recommender System
Oct 21, 2021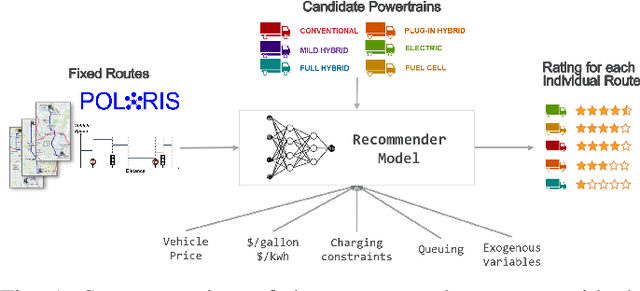
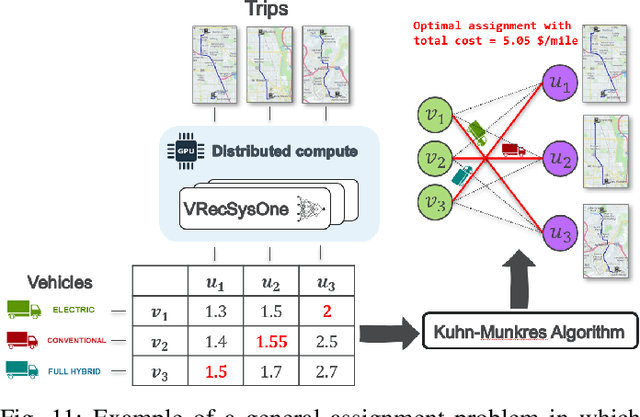
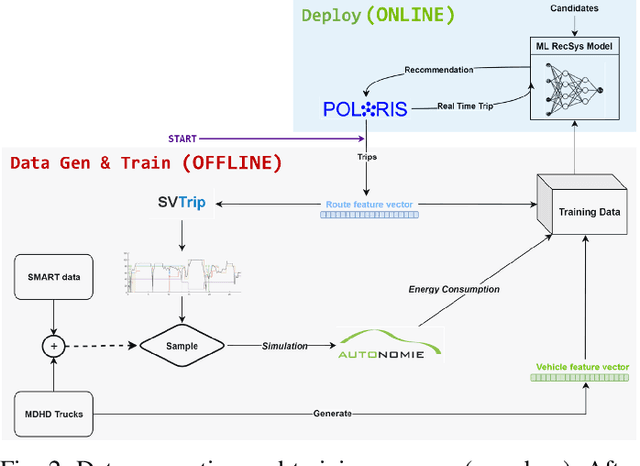
This paper presents a neural network recommender system algorithm for assigning vehicles to routes based on energy and cost criteria. In this work, we applied this new approach to efficiently identify the most cost-effective medium and heavy duty truck (MDHDT) powertrain technology, from a total cost of ownership (TCO) perspective, for given trips. We employ a machine learning based approach to efficiently estimate the energy consumption of various candidate vehicles over given routes, defined as sequences of links (road segments), with little information known about internal dynamics, i.e using high level macroscopic route information. A complete recommendation logic is then developed to allow for real-time optimum assignment for each route, subject to the operational constraints of the fleet. We show how this framework can be used to (1) efficiently provide a single trip recommendation with a top-$k$ vehicles star ranking system, and (2) engage in more general assignment problems where $n$ vehicles need to be deployed over $m \leq n$ trips. This new assignment system has been deployed and integrated into the POLARIS Transportation System Simulation Tool for use in research conducted by the Department of Energy's Systems and Modeling for Accelerated Research in Transportation (SMART) Mobility Consortium
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features
Nov 30, 2021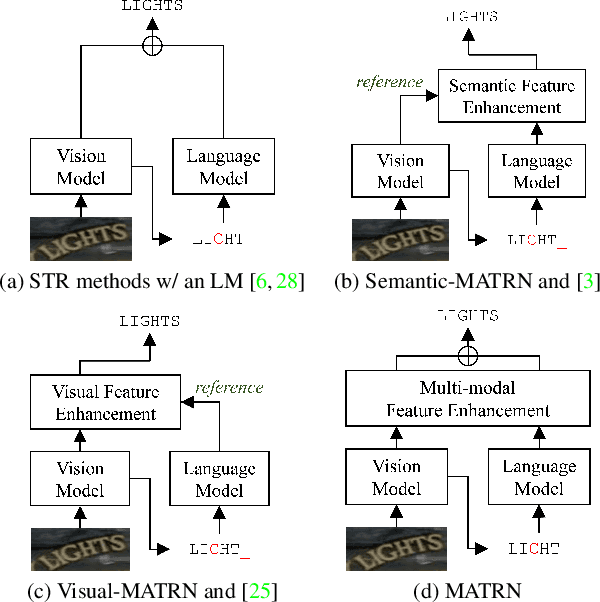
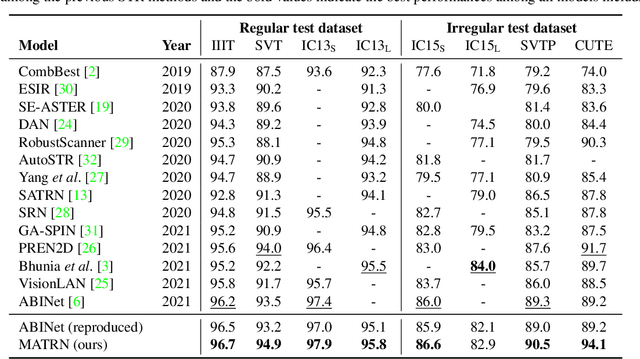
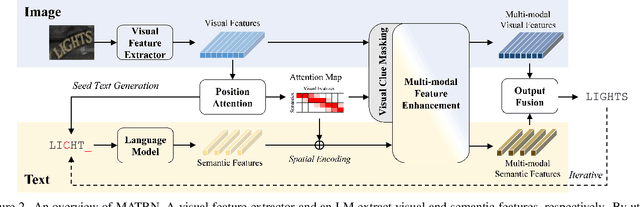
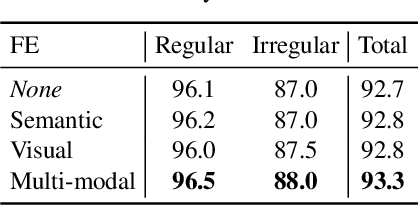
Linguistic knowledge has brought great benefits to scene text recognition by providing semantics to refine character sequences. However, since linguistic knowledge has been applied individually on the output sequence, previous methods have not fully utilized the semantics to understand visual clues for text recognition. This paper introduces a novel method, called Multi-modAl Text Recognition Network (MATRN), that enables interactions between visual and semantic features for better recognition performances. Specifically, MATRN identifies visual and semantic feature pairs and encodes spatial information into semantic features. Based on the spatial encoding, visual and semantic features are enhanced by referring to related features in the other modality. Furthermore, MATRN stimulates combining semantic features into visual features by hiding visual clues related to the character in the training phase. Our experiments demonstrate that MATRN achieves state-of-the-art performances on seven benchmarks with large margins, while naive combinations of two modalities show marginal improvements. Further ablative studies prove the effectiveness of our proposed components. Our implementation will be publicly available.
Learning to Control Complex Robots Using High-Dimensional Interfaces: Preliminary Insights
Oct 09, 2021
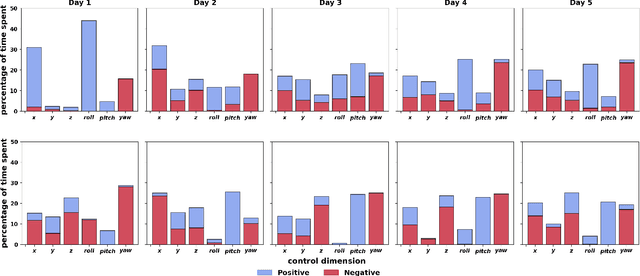
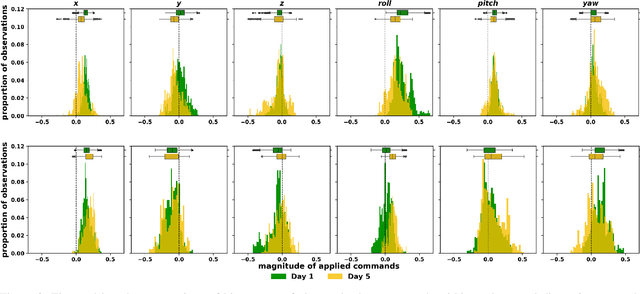
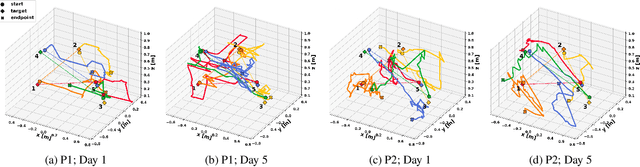
Human body motions can be captured as a high-dimensional continuous signal using motion sensor technologies. The resulting data can be surprisingly rich in information, even when captured from persons with limited mobility. In this work, we explore the use of limited upper-body motions, captured via motion sensors, as inputs to control a 7 degree-of-freedom assistive robotic arm. It is possible that even dense sensor signals lack the salient information and independence necessary for reliable high-dimensional robot control. As the human learns over time in the context of this limitation, intelligence on the robot can be leveraged to better identify key learning challenges, provide useful feedback, and support individuals until the challenges are managed. In this short paper, we examine two uninjured participants' data from an ongoing study, to extract preliminary results and share insights. We observe opportunities for robot intelligence to step in, including the identification of inconsistencies in time spent across all control dimensions, asymmetries in individual control dimensions, and user progress in learning. Machine reasoning about these situations may facilitate novel interface learning in the future.
Zero-Shot Semantic Segmentation via Spatial and Multi-Scale Aware Visual Class Embedding
Nov 30, 2021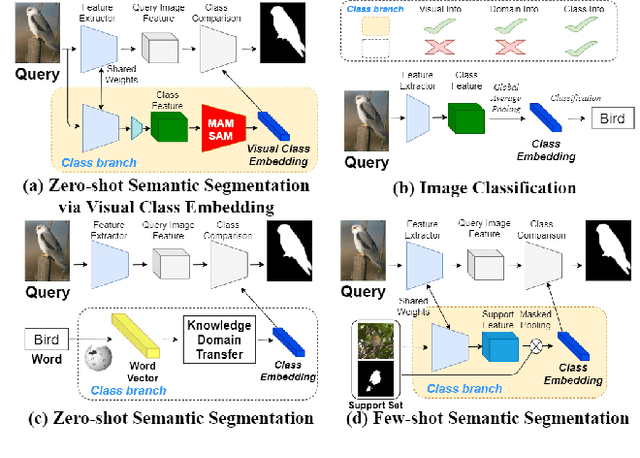
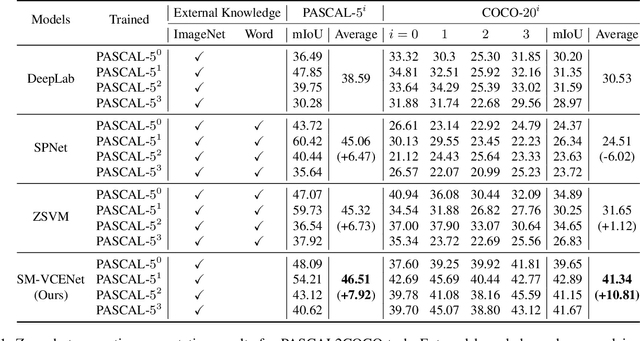
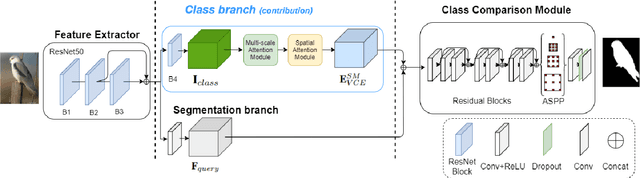
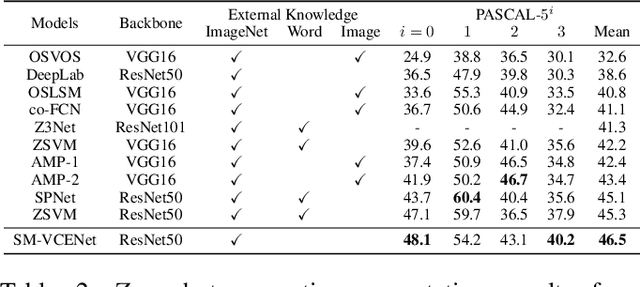
Fully supervised semantic segmentation technologies bring a paradigm shift in scene understanding. However, the burden of expensive labeling cost remains as a challenge. To solve the cost problem, recent studies proposed language model based zero-shot semantic segmentation (L-ZSSS) approaches. In this paper, we address L-ZSSS has a limitation in generalization which is a virtue of zero-shot learning. Tackling the limitation, we propose a language-model-free zero-shot semantic segmentation framework, Spatial and Multi-scale aware Visual Class Embedding Network (SM-VCENet). Furthermore, leveraging vision-oriented class embedding SM-VCENet enriches visual information of the class embedding by multi-scale attention and spatial attention. We also propose a novel benchmark (PASCAL2COCO) for zero-shot semantic segmentation, which provides generalization evaluation by domain adaptation and contains visually challenging samples. In experiments, our SM-VCENet outperforms zero-shot semantic segmentation state-of-the-art by a relative margin in PASCAL-5i benchmark and shows generalization-robustness in PASCAL2COCO benchmark.
Harnessing Cross-lingual Features to Improve Cognate Detection for Low-resource Languages
Dec 16, 2021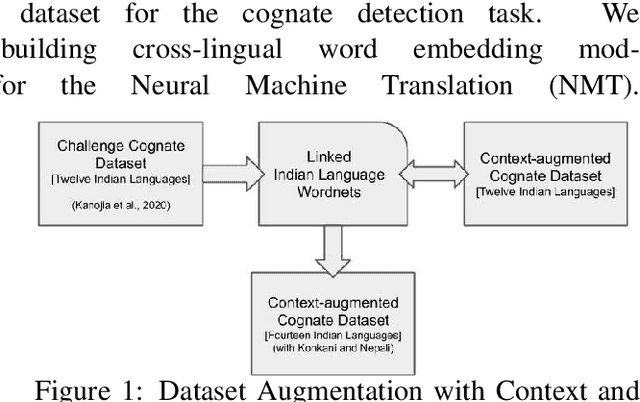
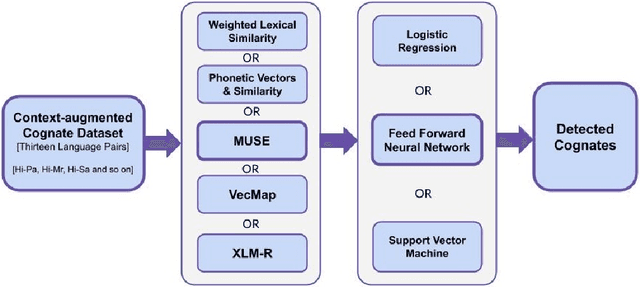
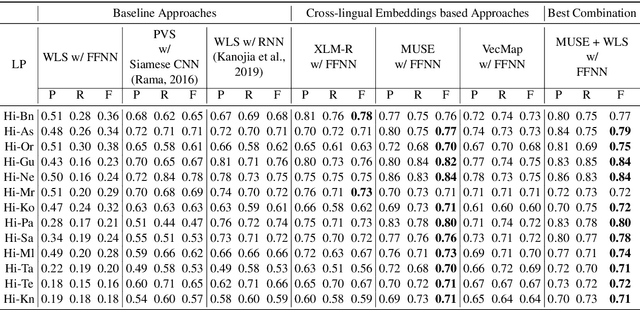

Cognates are variants of the same lexical form across different languages; for example 'fonema' in Spanish and 'phoneme' in English are cognates, both of which mean 'a unit of sound'. The task of automatic detection of cognates among any two languages can help downstream NLP tasks such as Cross-lingual Information Retrieval, Computational Phylogenetics, and Machine Translation. In this paper, we demonstrate the use of cross-lingual word embeddings for detecting cognates among fourteen Indian Languages. Our approach introduces the use of context from a knowledge graph to generate improved feature representations for cognate detection. We, then, evaluate the impact of our cognate detection mechanism on neural machine translation (NMT), as a downstream task. We evaluate our methods to detect cognates on a challenging dataset of twelve Indian languages, namely, Sanskrit, Hindi, Assamese, Oriya, Kannada, Gujarati, Tamil, Telugu, Punjabi, Bengali, Marathi, and Malayalam. Additionally, we create evaluation datasets for two more Indian languages, Konkani and Nepali. We observe an improvement of up to 18% points, in terms of F-score, for cognate detection. Furthermore, we observe that cognates extracted using our method help improve NMT quality by up to 2.76 BLEU. We also release our code, newly constructed datasets and cross-lingual models publicly.
Retrieving Sequential Information for Non-Autoregressive Neural Machine Translation
Jun 22, 2019
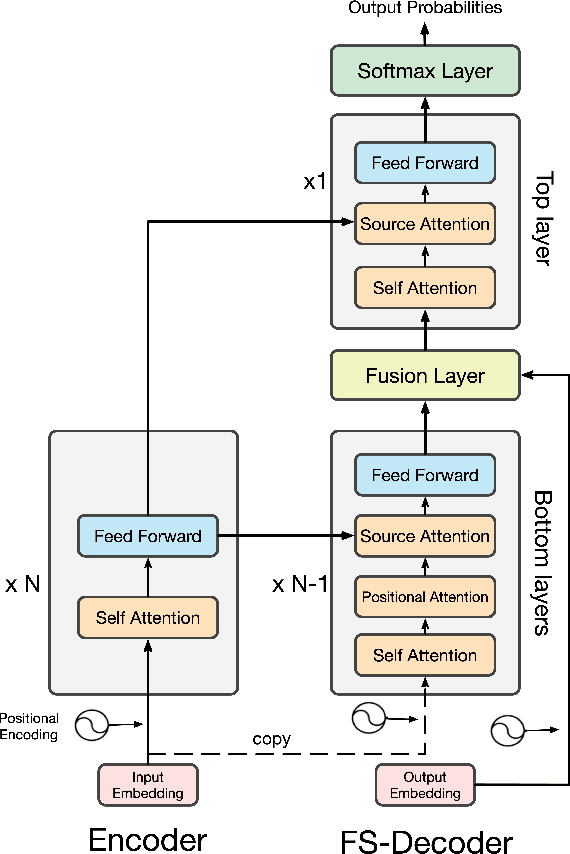
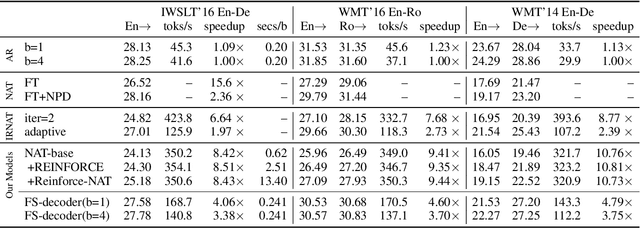
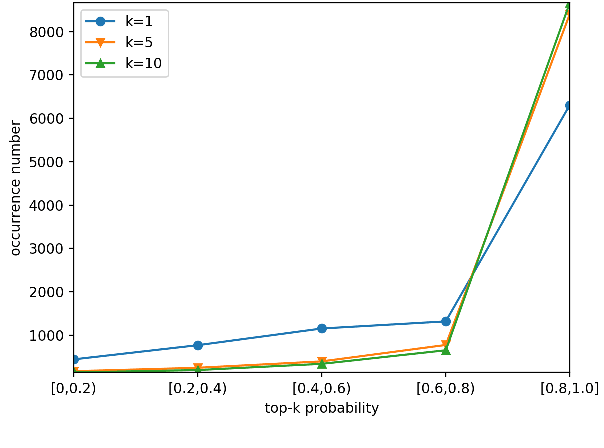
Non-Autoregressive Transformer (NAT) aims to accelerate the Transformer model through discarding the autoregressive mechanism and generating target words independently, which fails to exploit the target sequential information. Over-translation and under-translation errors often occur for the above reason, especially in the long sentence translation scenario. In this paper, we propose two approaches to retrieve the target sequential information for NAT to enhance its translation ability while preserving the fast-decoding property. Firstly, we propose a sequence-level training method based on a novel reinforcement algorithm for NAT (Reinforce-NAT) to reduce the variance and stabilize the training procedure. Secondly, we propose an innovative Transformer decoder named FS-decoder to fuse the target sequential information into the top layer of the decoder. Experimental results on three translation tasks show that the Reinforce-NAT surpasses the baseline NAT system by a significant margin on BLEU without decelerating the decoding speed and the FS-decoder achieves comparable translation performance to the autoregressive Transformer with considerable speedup.
DProST: 6-DoF Object Pose Estimation Using Space Carving and Dynamic Projective Spatial Transformer
Dec 16, 2021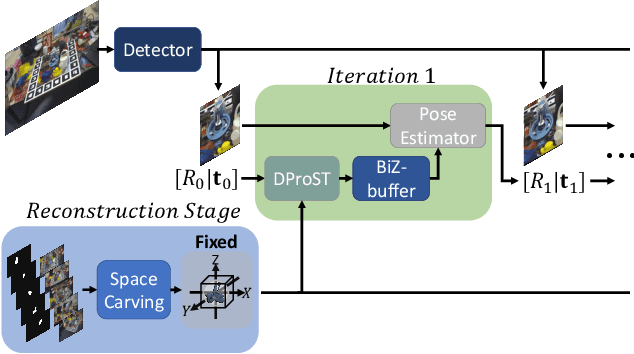
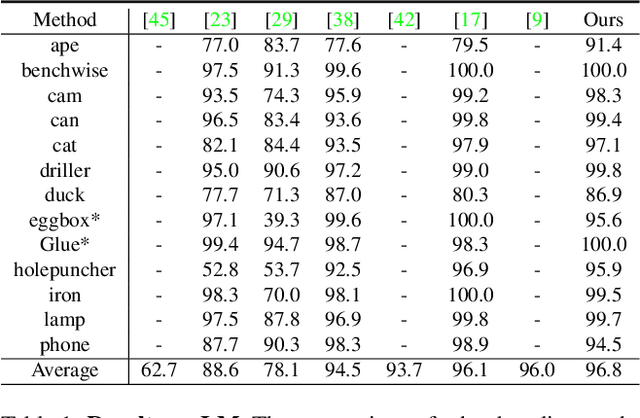
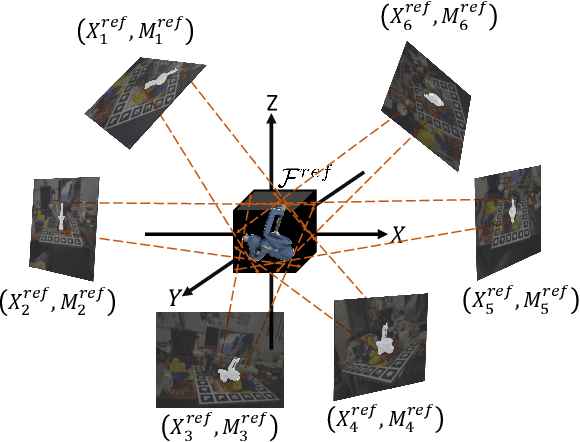
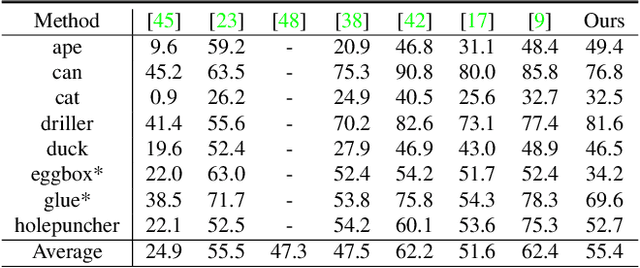
Predicting the pose of an object is a core computer vision task. Most deep learning-based pose estimation methods require CAD data to use 3D intermediate representations or project 2D appearance. However, these methods cannot be used when CAD data for objects of interest are unavailable. Besides, the existing methods did not precisely reflect the perspective distortion to the learning process. In addition, information loss due to self-occlusion has not been studied well. In this regard, we propose a new pose estimation system consisting of a space carving module that reconstructs a reference 3D feature to replace the CAD data. Moreover, Our new transformation module, Dynamic Projective Spatial Transformer (DProST), transforms a reference 3D feature to reflect the pose while considering perspective distortion. Also, we overcome the self-occlusion problem by a new Bidirectional Z-buffering (BiZ-buffer) method, which extracts both the front view and the self-occluded back view of the object. Lastly, we suggest a Perspective Grid Distance Loss (PGDL), enabling stable learning of the pose estimator without CAD data. Experimental results show that our method outperforms the state-of-the-art method on the LINEMOD dataset and comparable performance on LINEMOD-OCCLUSION dataset even compared to the methods that require CAD data in network training.