 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Molecular Graph Generation via Geometric Scattering
Oct 12, 2021
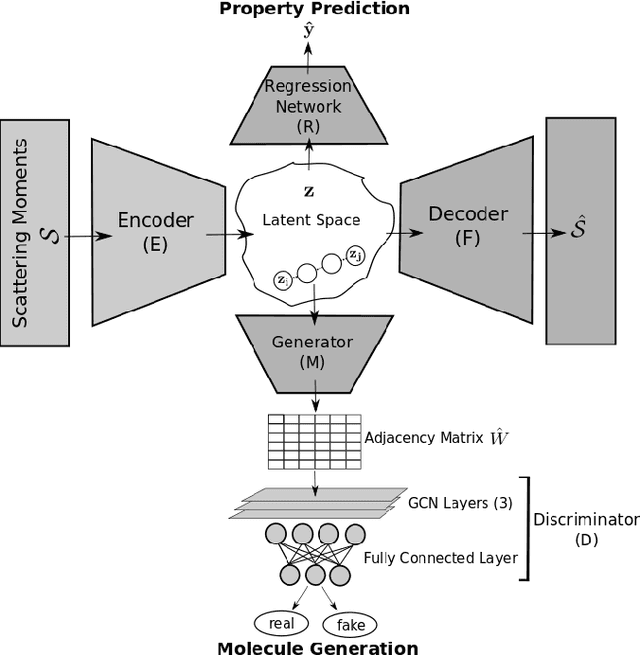
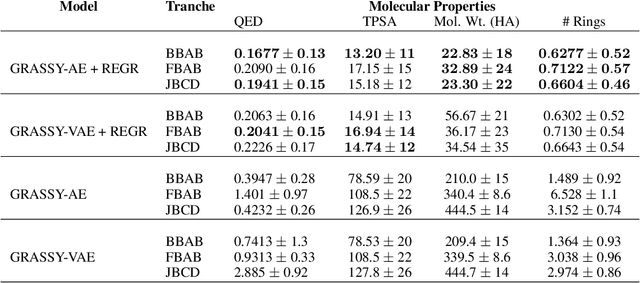
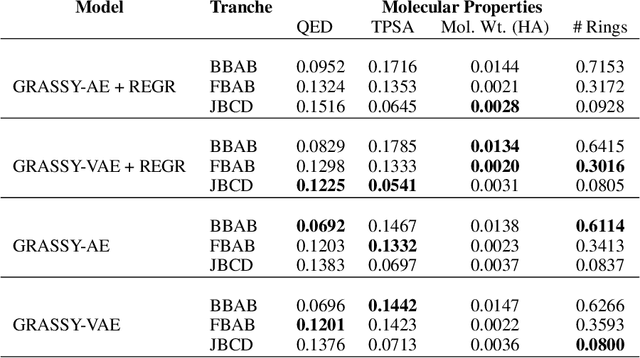
Graph neural networks (GNNs) have been used extensively for addressing problems in drug design and discovery. Both ligand and target molecules are represented as graphs with node and edge features encoding information about atomic elements and bonds respectively. Although existing deep learning models perform remarkably well at predicting physicochemical properties and binding affinities, the generation of new molecules with optimized properties remains challenging. Inherently, most GNNs perform poorly in whole-graph representation due to the limitations of the message-passing paradigm. Furthermore, step-by-step graph generation frameworks that use reinforcement learning or other sequential processing can be slow and result in a high proportion of invalid molecules with substantial post-processing needed in order to satisfy the principles of stoichiometry. To address these issues, we propose a representation-first approach to molecular graph generation. We guide the latent representation of an autoencoder by capturing graph structure information with the geometric scattering transform and apply penalties that structure the representation also by molecular properties. We show that this highly structured latent space can be directly used for molecular graph generation by the use of a GAN. We demonstrate that our architecture learns meaningful representations of drug datasets and provides a platform for goal-directed drug synthesis.
Statistical limits of dictionary learning: random matrix theory and the spectral replica method
Sep 14, 2021

We consider increasingly complex models of matrix denoising and dictionary learning in the Bayes-optimal setting, in the challenging regime where the matrices to infer have a rank growing linearly with the system size. This is in contrast with most existing literature concerned with the low-rank (i.e., constant-rank) regime. We first consider a class of rotationally invariant matrix denoising problems whose mutual information and minimum mean-square error are computable using standard techniques from random matrix theory. Next, we analyze the more challenging models of dictionary learning. To do so we introduce a novel combination of the replica method from statistical mechanics together with random matrix theory, coined spectral replica method. It allows us to conjecture variational formulas for the mutual information between hidden representations and the noisy data as well as for the overlaps quantifying the optimal reconstruction error. The proposed methods reduce the number of degrees of freedom from $\Theta(N^2)$ (matrix entries) to $\Theta(N)$ (eigenvalues or singular values), and yield Coulomb gas representations of the mutual information which are reminiscent of matrix models in physics. The main ingredients are the use of HarishChandra-Itzykson-Zuber spherical integrals combined with a new replica symmetric decoupling ansatz at the level of the probability distributions of eigenvalues (or singular values) of certain overlap matrices.
Weakly-Supervised Opinion Summarization by Leveraging External Information
Nov 22, 2019
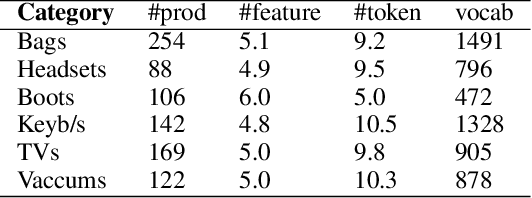

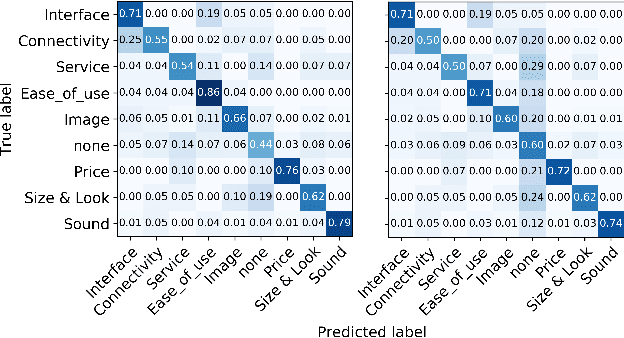
Opinion summarization from online product reviews is a challenging task, which involves identifying opinions related to various aspects of the product being reviewed. While previous works require additional human effort to identify relevant aspects, we instead apply domain knowledge from external sources to automatically achieve the same goal. This work proposes AspMem, a generative method that contains an array of memory cells to store aspect-related knowledge. This explicit memory can help obtain a better opinion representation and infer the aspect information more precisely. We evaluate this method on both aspect identification and opinion summarization tasks. Our experiments show that AspMem outperforms the state-of-the-art methods even though, unlike the baselines, it does not rely on human supervision which is carefully handcrafted for the given tasks.
Video Content Swapping Using GAN
Nov 21, 2021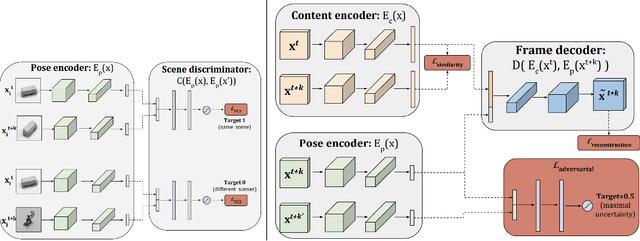
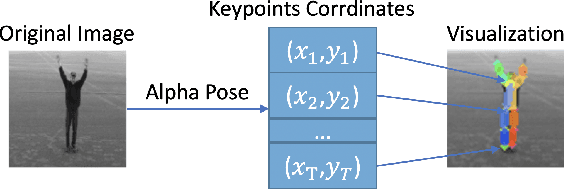
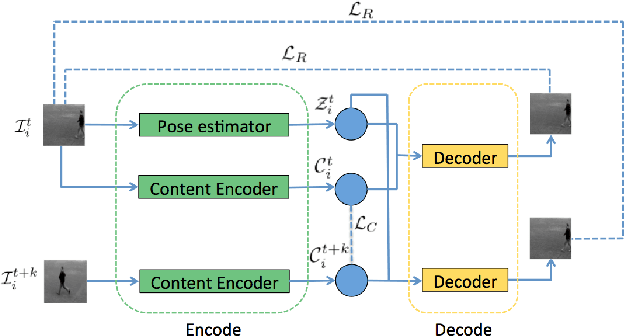
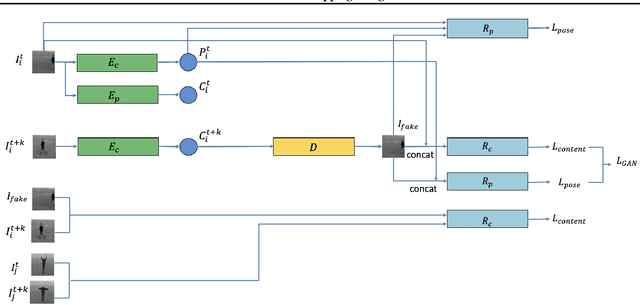
Video generation is an interesting problem in computer vision. It is quite popular for data augmentation, special effect in move, AR/VR and so on. With the advances of deep learning, many deep generative models have been proposed to solve this task. These deep generative models provide away to utilize all the unlabeled images and videos online, since it can learn deep feature representations with unsupervised manner. These models can also generate different kinds of images, which have great value for visual application. However generating a video would be much more challenging since we need to model not only the appearances of objects in the video but also their temporal motion. In this work, we will break down any frame in the video into content and pose. We first extract the pose information from a video using a pre-trained human pose detection and use a generative model to synthesize the video based on the content code and pose code.
Smelting Gold and Silver for Improved Multilingual AMR-to-Text Generation
Sep 08, 2021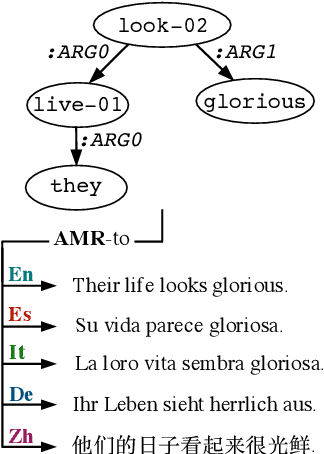
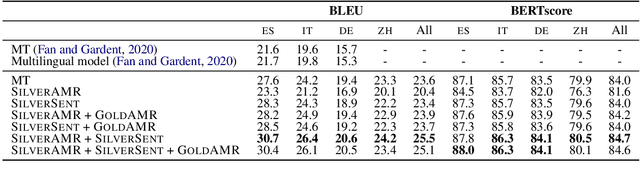
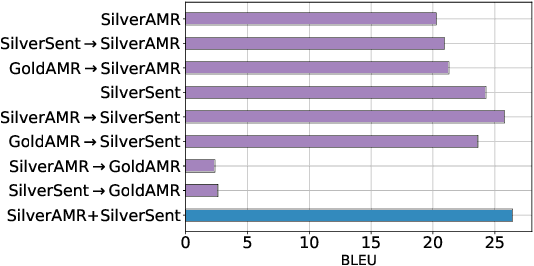

Recent work on multilingual AMR-to-text generation has exclusively focused on data augmentation strategies that utilize silver AMR. However, this assumes a high quality of generated AMRs, potentially limiting the transferability to the target task. In this paper, we investigate different techniques for automatically generating AMR annotations, where we aim to study which source of information yields better multilingual results. Our models trained on gold AMR with silver (machine translated) sentences outperform approaches which leverage generated silver AMR. We find that combining both complementary sources of information further improves multilingual AMR-to-text generation. Our models surpass the previous state of the art for German, Italian, Spanish, and Chinese by a large margin.
Mega-NeRF: Scalable Construction of Large-Scale NeRFs for Virtual Fly-Throughs
Dec 20, 2021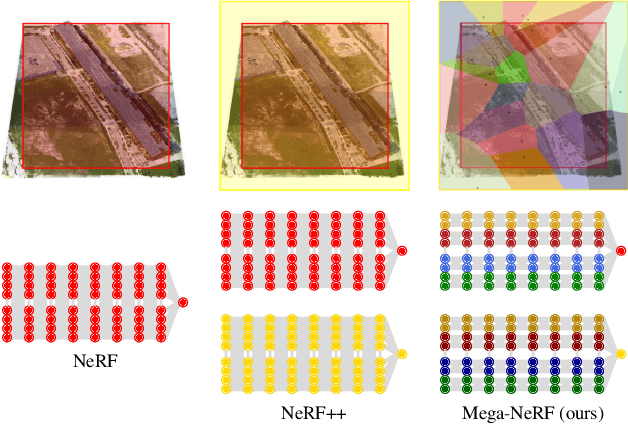
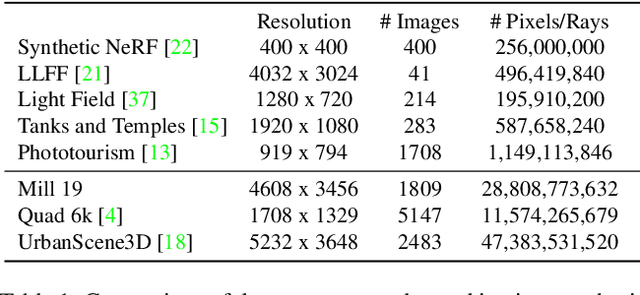
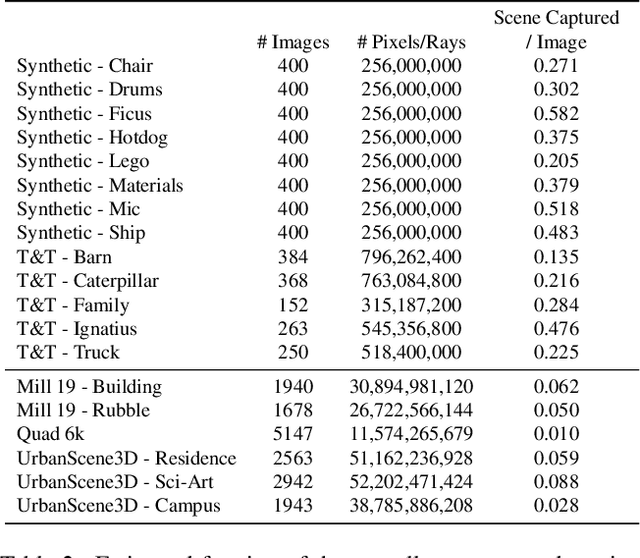

We explore how to leverage neural radiance fields (NeRFs) to build interactive 3D environments from large-scale visual captures spanning buildings or even multiple city blocks collected primarily from drone data. In contrast to the single object scenes against which NeRFs have been traditionally evaluated, this setting poses multiple challenges including (1) the need to incorporate thousands of images with varying lighting conditions, all of which capture only a small subset of the scene, (2) prohibitively high model capacity and ray sampling requirements beyond what can be naively trained on a single GPU, and (3) an arbitrarily large number of possible viewpoints that make it unfeasible to precompute all relevant information beforehand (as real-time NeRF renderers typically do). To address these challenges, we begin by analyzing visibility statistics for large-scale scenes, motivating a sparse network structure where parameters are specialized to different regions of the scene. We introduce a simple geometric clustering algorithm that partitions training images (or rather pixels) into different NeRF submodules that can be trained in parallel. We evaluate our approach across scenes taken from the Quad 6k and UrbanScene3D datasets as well as against our own drone footage and show a 3x training speedup while improving PSNR by over 11% on average. We subsequently perform an empirical evaluation of recent NeRF fast renderers on top of Mega-NeRF and introduce a novel method that exploits temporal coherence. Our technique achieves a 40x speedup over conventional NeRF rendering while remaining within 0.5 db in PSNR quality, exceeding the fidelity of existing fast renderers.
Information Aggregation for Multi-Head Attention with Routing-by-Agreement
Apr 05, 2019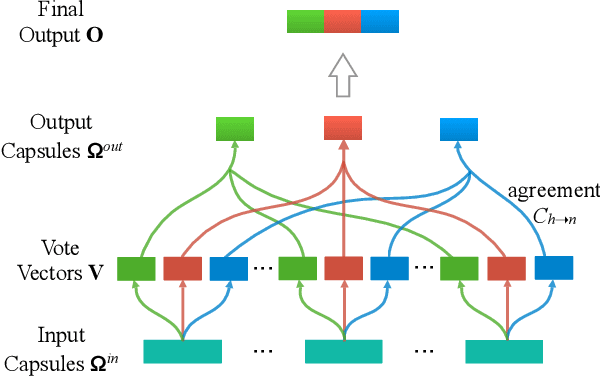

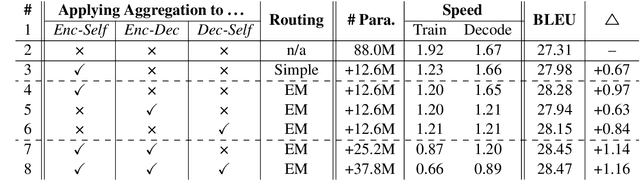
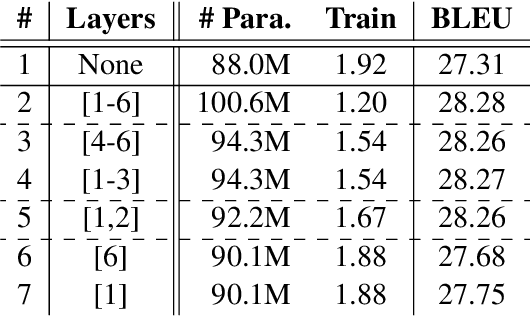
Multi-head attention is appealing for its ability to jointly extract different types of information from multiple representation subspaces. Concerning the information aggregation, a common practice is to use a concatenation followed by a linear transformation, which may not fully exploit the expressiveness of multi-head attention. In this work, we propose to improve the information aggregation for multi-head attention with a more powerful routing-by-agreement algorithm. Specifically, the routing algorithm iteratively updates the proportion of how much a part (i.e. the distinct information learned from a specific subspace) should be assigned to a whole (i.e. the final output representation), based on the agreement between parts and wholes. Experimental results on linguistic probing tasks and machine translation tasks prove the superiority of the advanced information aggregation over the standard linear transformation.
Efficient Context-Aware Network for Abdominal Multi-organ Segmentation
Sep 22, 2021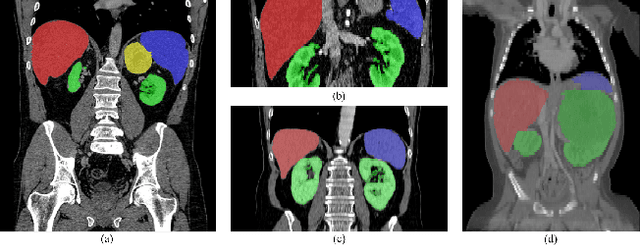
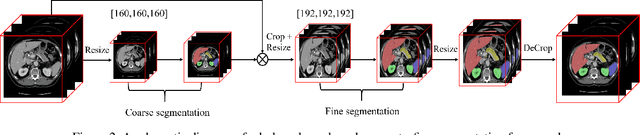
The contextual information, presented in abdominal CT scan, is relative consistent. In order to make full use of the overall 3D context, we develop a whole-volumebased coarse-to-fine framework for efficient and effective abdominal multi-organ segmentation. We propose a new efficientSegNet network, which is composed of encoder, decoder and context block. For the decoder module, anisotropic convolution with a k*k*1 intra-slice convolution and a 1*1*k inter-slice convolution, is designed to reduce the computation burden. For the context block, we propose strip pooling module to capture anisotropic and long-range contextual information, which exists in abdominal scene. Quantitative evaluation on the FLARE2021 validation cases, this method achieves the average dice similarity coefficient (DSC) of 0.895 and average normalized surface distance (NSD) of 0.775. The average running time is 9.8 s per case in inference phase, and maximum used GPU memory is 1017 MB.
ARMAS: Active Reconstruction of Missing Audio Segments
Nov 21, 2021

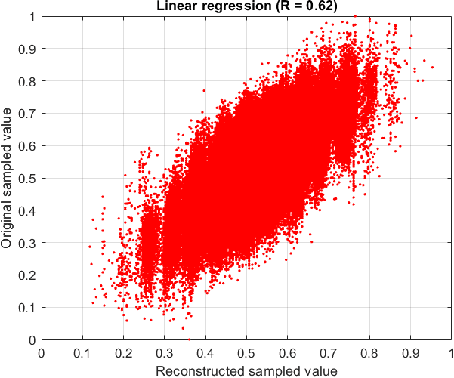
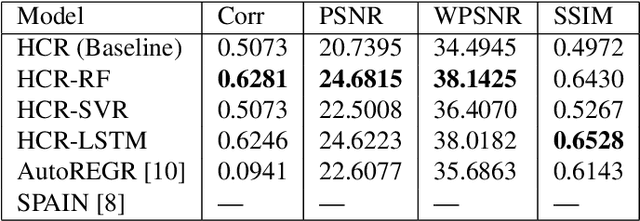
Digital audio signal reconstruction of lost or corrupt segment using deep learning algorithms has been explored intensively in the recent years. Nevertheless, prior traditional methods with linear interpolation, phase coding and tone insertion techniques are still in vogue. However, we found no research work on the reconstruction of audio signals with the fusion of dithering, steganography, and machine learning regressors. Therefore, this paper proposes the combination of steganography, halftoning (dithering), and state-of-the-art shallow (RF- Random Forest and SVR- Support Vector Regression) and deep learning (LSTM- Long Short-Term Memory) methods. The results (including comparison to the SPAIN and Autoregressive methods) are evaluated with four different metrics. The observations from the results show that the proposed solution is effective and can enhance the reconstruction of audio signals performed by the side information (noisy-latent representation) steganography provides. This work may trigger interest in the optimization of this approach and/or in transferring it to different domains (i.e., image reconstruction).
The Impact of Main Content Extraction on Near-Duplicate Detection
Nov 21, 2021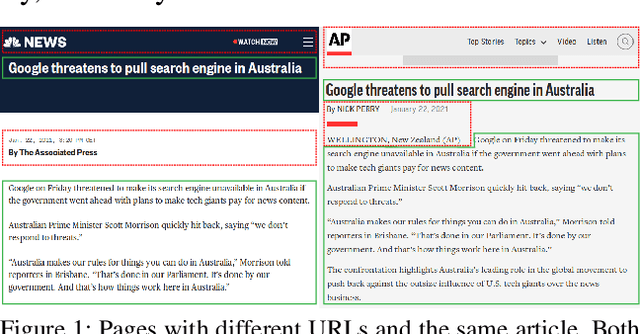
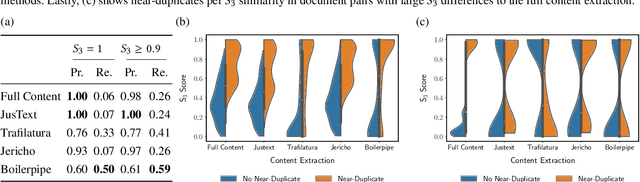
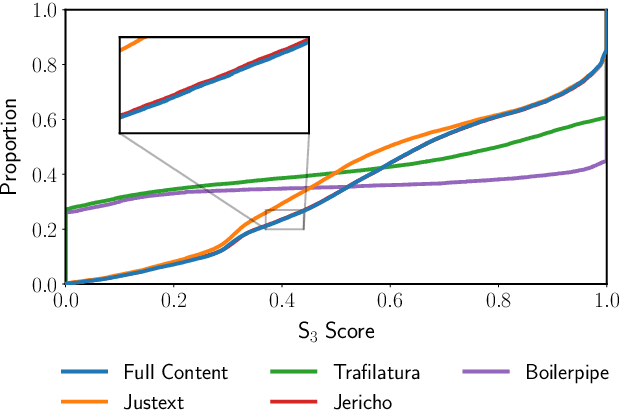
Commercial web search engines employ near-duplicate detection to ensure that users see each relevant result only once, albeit the underlying web crawls typically include (near-)duplicates of many web pages. We revisit the risks and potential of near-duplicates with an information retrieval focus, motivating that current efforts toward an open and independent European web search infrastructure should maintain metadata on duplicate and near-duplicate documents in its index. Near-duplicate detection implemented in an open web search infrastructure should provide a suitable similarity threshold, a difficult choice since identical pages may substantially differ in parts of a page that are irrelevant to searchers (templates, advertisements, etc.). We study this problem by comparing the similarity of pages for five (main) content extraction methods in two studies on the ClueWeb crawls. We find that the full content of pages serves precision-oriented near-duplicate-detection, while main content extraction is more recall-oriented.