 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Softmax Is Not an Artificial Trick: An Information-Theoretic View of Softmax in Neural Networks
Oct 15, 2019
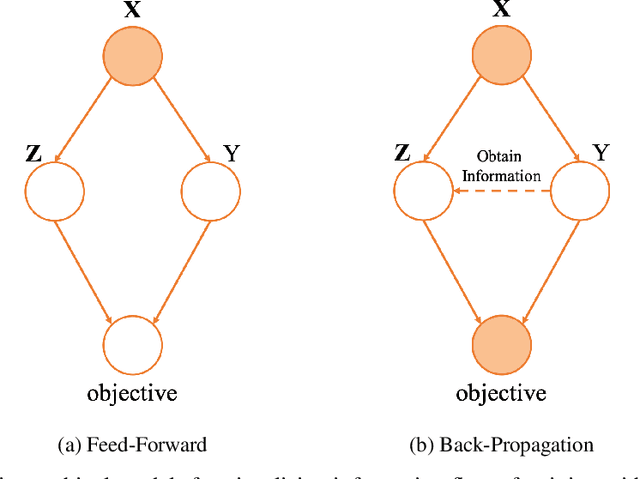
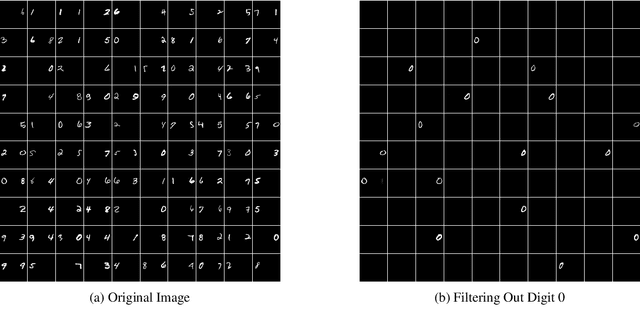
Despite great popularity of applying softmax to map the non-normalised outputs of a neural network to a probability distribution over predicting classes, this normalised exponential transformation still seems to be artificial. A theoretic framework that incorporates softmax as an intrinsic component is still lacking. In this paper, we view neural networks embedding softmax from an information-theoretic perspective. Under this view, we can naturally and mathematically derive log-softmax as an inherent component in a neural network for evaluating the conditional mutual information between network output vectors and labels given an input datum. We show that training deterministic neural networks through maximising log-softmax is equivalent to enlarging the conditional mutual information, i.e., feeding label information into network outputs. We also generalise our informative-theoretic perspective to neural networks with stochasticity and derive information upper and lower bounds of log-softmax. In theory, such an information-theoretic view offers rationality support for embedding softmax in neural networks; in practice, we eventually demonstrate a computer vision application example of how to employ our information-theoretic view to filter out targeted objects on images.
A Variational U-Net for Weather Forecasting
Nov 05, 2021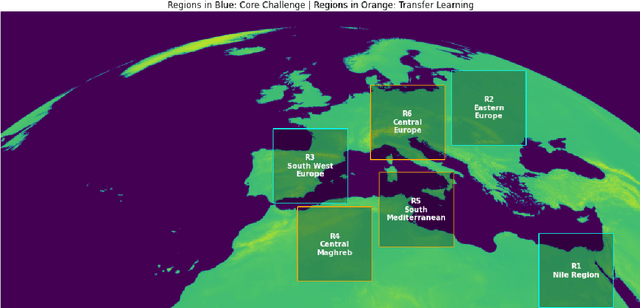

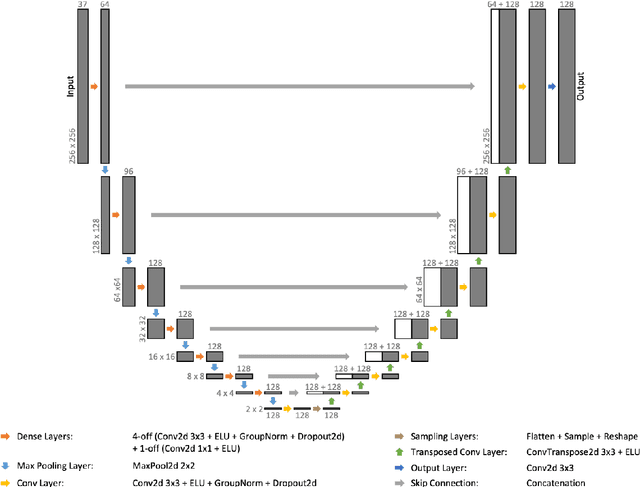

Not only can discovering patterns and insights from atmospheric data enable more accurate weather predictions, but it may also provide valuable information to help tackle climate change. Weather4cast is an open competition that aims to evaluate machine learning algorithms' capability to predict future atmospheric states. Here, we describe our third-place solution to Weather4cast. We present a novel Variational U-Net that combines a Variational Autoencoder's ability to consider the probabilistic nature of data with a U-Net's ability to recover fine-grained details. This solution is an evolution from our fourth-place solution to Traffic4cast 2020 with many commonalities, suggesting its applicability to vastly different domains, such as weather and traffic.
NeurSF: Neural Shading Field for Image Harmonization
Dec 04, 2021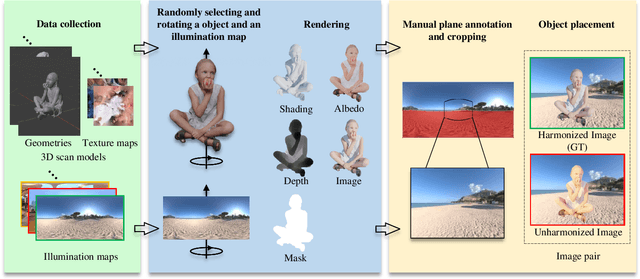

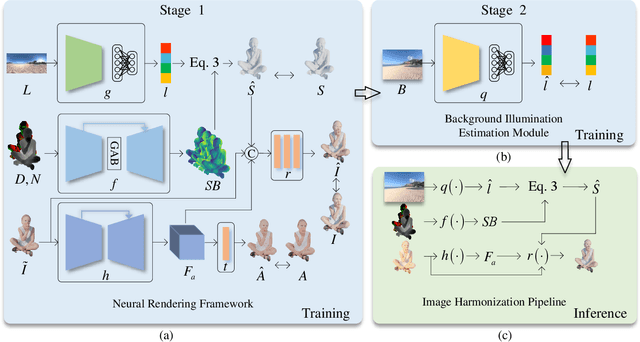
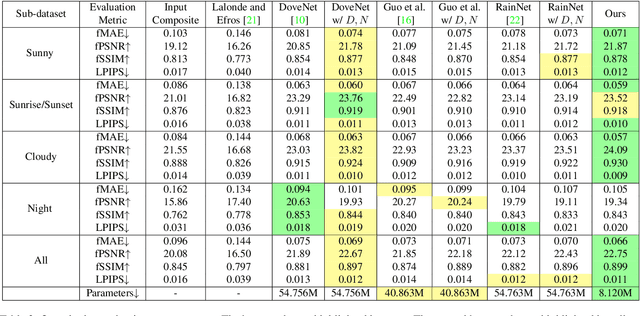
Image harmonization aims at adjusting the appearance of the foreground to make it more compatible with the background. Due to a lack of understanding of the background illumination direction, existing works are incapable of generating a realistic foreground shading. In this paper, we decompose the image harmonization into two sub-problems: 1) illumination estimation of background images and 2) rendering of foreground objects. Before solving these two sub-problems, we first learn a direction-aware illumination descriptor via a neural rendering framework, of which the key is a Shading Module that decomposes the shading field into multiple shading components given depth information. Then we design a Background Illumination Estimation Module to extract the direction-aware illumination descriptor from the background. Finally, the illumination descriptor is used in conjunction with the neural rendering framework to generate the harmonized foreground image containing a novel harmonized shading. Moreover, we construct a photo-realistic synthetic image harmonization dataset that contains numerous shading variations by image-based lighting. Extensive experiments on this dataset demonstrate the effectiveness of the proposed method. Our dataset and code will be made publicly available.
Understanding Convolutional Neural Network Training with Information Theory
Oct 12, 2018
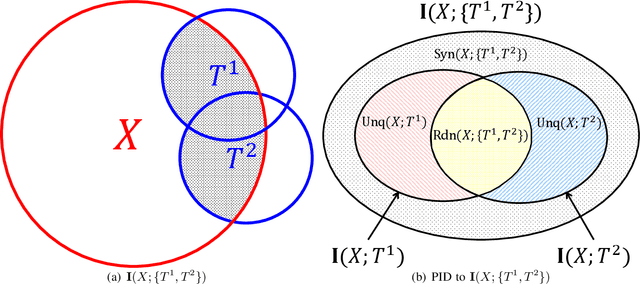

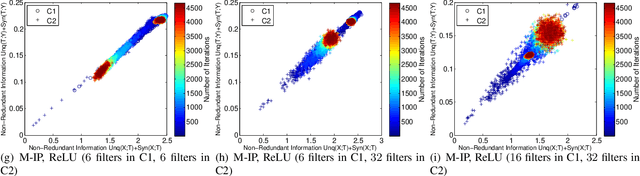
Using information theoretic concepts to understand and explore the inner organization of deep neural networks (DNNs) remains a big challenge. Recently, the concept of an information plane (coupled with the famed information bottleneck principle) began to shed light on the analysis of multilayer perceptrons (MLPs). We provided an in-depth insight into stacked autoencoders (SAEs) using a novel matrix-based Renyi's {\alpha}-entropy functional, enabling for the first time the analysis of the dynamics of learning using information flow in the real-world scenario involving complex network architecture and large data. Despite the great potential of these past works, there are several open questions when it comes to applying information theoretic concepts to understand convolutional neural networks (CNNs). These include for instance the accurate estimation of information quantities among multiple variables, and the many different training methodologies. By extending the novel matrix-based Renyi's {\alpha}-entropy functional to a multivariate scenario and introducing the partial information decomposition (PID) framework, this paper presents a systematic method to analyze CNNs training using information theory. Our results validate two fundamental data processing inequalities in CNNs, and also reveals some fundamental issues embedded in the training phase of CNNs.
Smelting Gold and Silver for Improved Multilingual AMR-to-Text Generation
Sep 08, 2021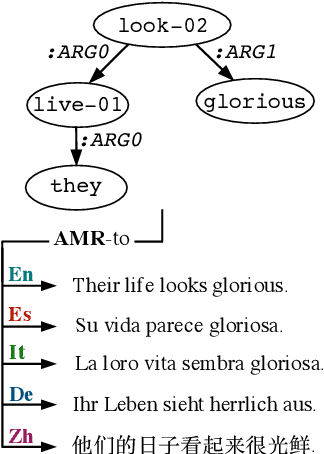
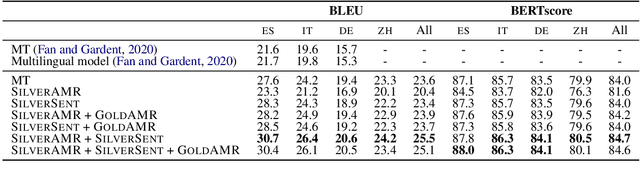
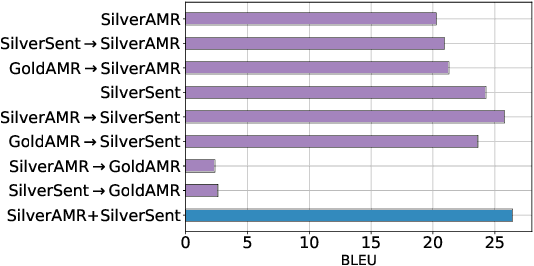

Recent work on multilingual AMR-to-text generation has exclusively focused on data augmentation strategies that utilize silver AMR. However, this assumes a high quality of generated AMRs, potentially limiting the transferability to the target task. In this paper, we investigate different techniques for automatically generating AMR annotations, where we aim to study which source of information yields better multilingual results. Our models trained on gold AMR with silver (machine translated) sentences outperform approaches which leverage generated silver AMR. We find that combining both complementary sources of information further improves multilingual AMR-to-text generation. Our models surpass the previous state of the art for German, Italian, Spanish, and Chinese by a large margin.
Power efficient analog features for audio recognition
Oct 07, 2021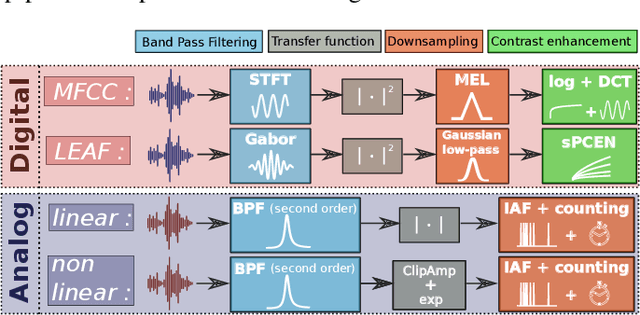
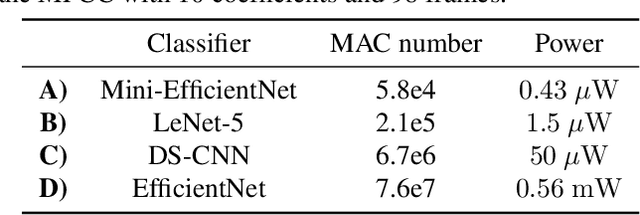
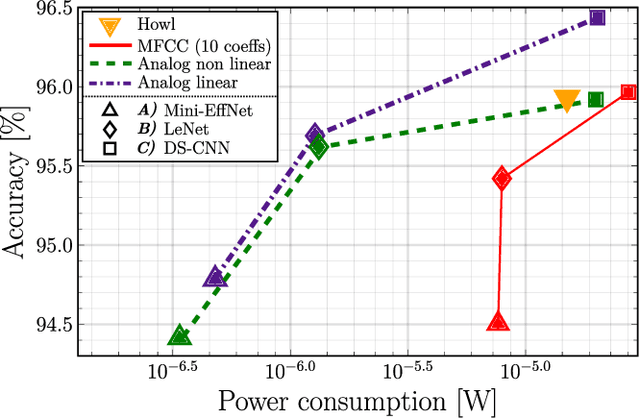
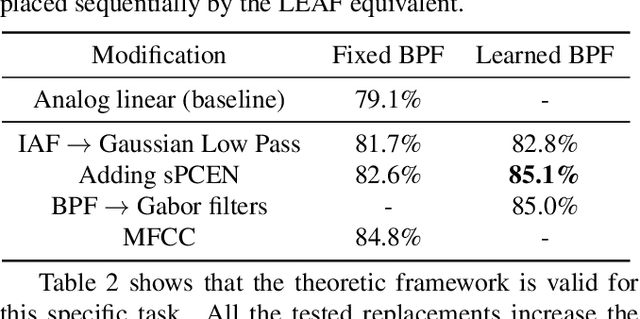
The digital signal processing-based representations like the Mel-Frequency Cepstral Coefficient are well known to be a solid basis for various audio processing tasks. Alternatively, analog feature representations, relying on analog-electronics-feasible bandpass filtering, allow much lower system power consumption compared with the digital counterpart, while parity performance on traditional tasks like voice activity detection can be achieved. This work explores the possibility of using analog features on multiple speech processing tasks that vary in time dependencies: wake word detection, keyword spotting, and speaker identification. The results of this evaluation show that the analog features are still more power-efficient and competitive on simpler tasks than digital features but yield an increasing performance drop on more complex tasks when long-time correlations are present. We also introduce a novel theoretical framework based on information theory to understand this performance drop by quantifying information flow in feature calculation which helps identify the performance bottlenecks. The theoretical claims are experimentally validated, leading to a maximum of 6% increase of keyword spotting accuracy, even surpassing the digital baseline features. The proposed analog-feature-based systems could pave the way to achieving best-in-class accuracy and power consumption simultaneously.
Statistical limits of dictionary learning: random matrix theory and the spectral replica method
Sep 14, 2021

We consider increasingly complex models of matrix denoising and dictionary learning in the Bayes-optimal setting, in the challenging regime where the matrices to infer have a rank growing linearly with the system size. This is in contrast with most existing literature concerned with the low-rank (i.e., constant-rank) regime. We first consider a class of rotationally invariant matrix denoising problems whose mutual information and minimum mean-square error are computable using standard techniques from random matrix theory. Next, we analyze the more challenging models of dictionary learning. To do so we introduce a novel combination of the replica method from statistical mechanics together with random matrix theory, coined spectral replica method. It allows us to conjecture variational formulas for the mutual information between hidden representations and the noisy data as well as for the overlaps quantifying the optimal reconstruction error. The proposed methods reduce the number of degrees of freedom from $\Theta(N^2)$ (matrix entries) to $\Theta(N)$ (eigenvalues or singular values), and yield Coulomb gas representations of the mutual information which are reminiscent of matrix models in physics. The main ingredients are the use of HarishChandra-Itzykson-Zuber spherical integrals combined with a new replica symmetric decoupling ansatz at the level of the probability distributions of eigenvalues (or singular values) of certain overlap matrices.
Using Contextual Information to Improve Blood Glucose Prediction
Aug 24, 2019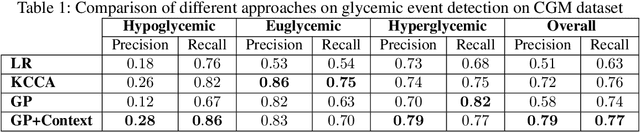
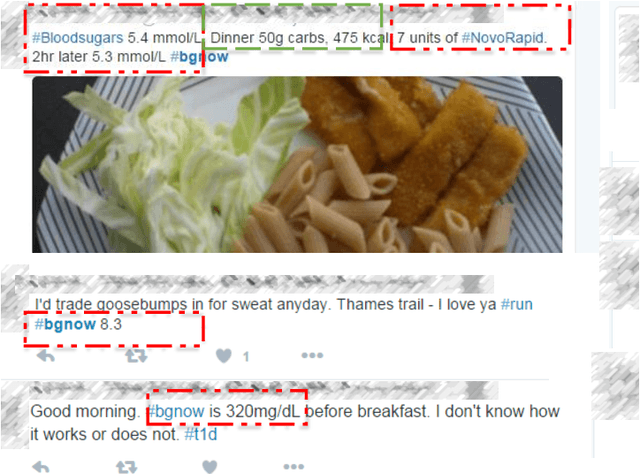
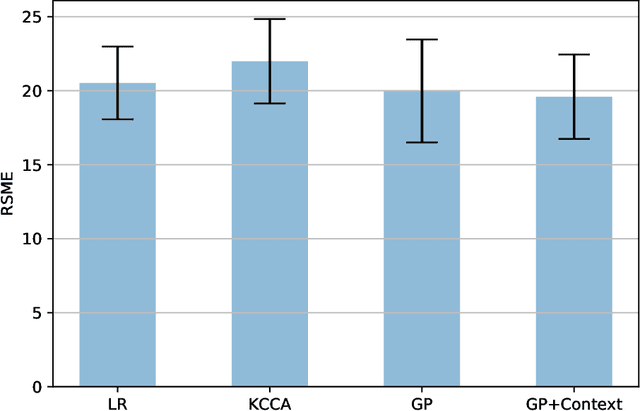
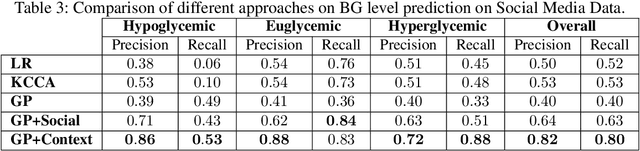
Blood glucose value prediction is an important task in diabetes management. While it is reported that glucose concentration is sensitive to social context such as mood, physical activity, stress, diet, alongside the influence of diabetes pathologies, we need more research on data and methodologies to incorporate and evaluate signals about such temporal context into prediction models. Person-generated data sources, such as actively contributed surveys as well as passively mined data from social media offer opportunity to capture such context, however the self-reported nature and sparsity of such data mean that such data are noisier and less specific than physiological measures such as blood glucose values themselves. Therefore, here we propose a Gaussian Process model to both address these data challenges and combine blood glucose and latent feature representations of contextual data for a novel multi-signal blood glucose prediction task. We find this approach outperforms common methods for multi-variate data, as well as using the blood glucose values in isolation. Given a robust evaluation across two blood glucose datasets with different forms of contextual information, we conclude that multi-signal Gaussian Processes can improve blood glucose prediction by using contextual information and may provide a significant shift in blood glucose prediction research and practice.
Approximate Inference via Clustering
Nov 28, 2021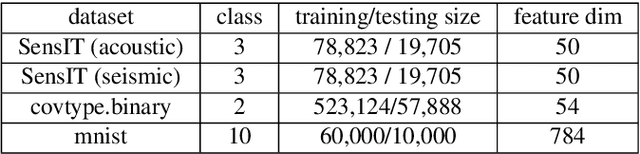
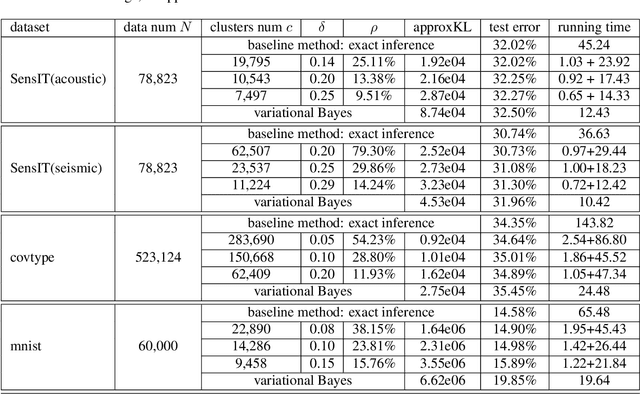
In recent years, large-scale Bayesian learning draws a great deal of attention. However, in big-data era, the amount of data we face is growing much faster than our ability to deal with it. Fortunately, it is observed that large-scale datasets usually own rich internal structure and is somewhat redundant. In this paper, we attempt to simplify the Bayesian posterior via exploiting this structure. Specifically, we restrict our interest to the so-called well-clustered datasets and construct an \emph{approximate posterior} according to the clustering information. Fortunately, the clustering structure can be efficiently obtained via a particular clustering algorithm. When constructing the approximate posterior, the data points in the same cluster are all replaced by the centroid of the cluster. As a result, the posterior can be significantly simplified. Theoretically, we show that under certain conditions the approximate posterior we construct is close (measured by KL divergence) to the exact posterior. Furthermore, thorough experiments are conducted to validate the fact that the constructed posterior is a good approximation to the true posterior and much easier to sample from.
Hierarchical Topometric Representation of 3D Robotic Maps
Nov 16, 2021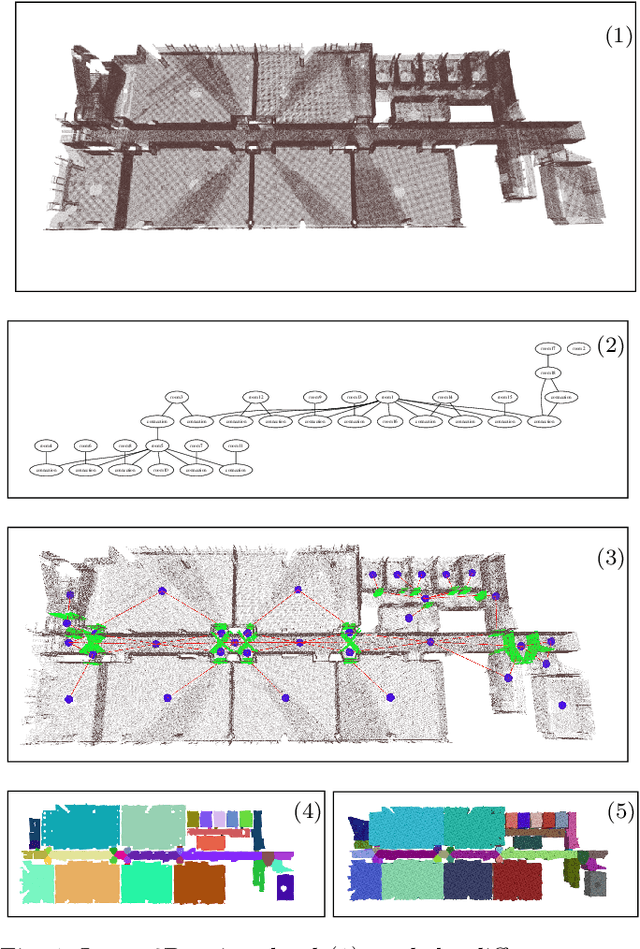

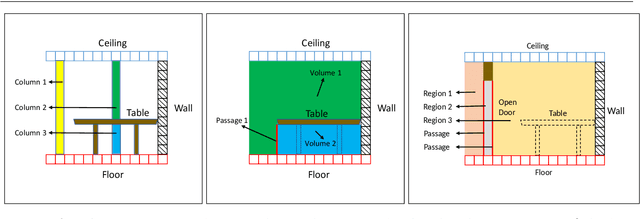
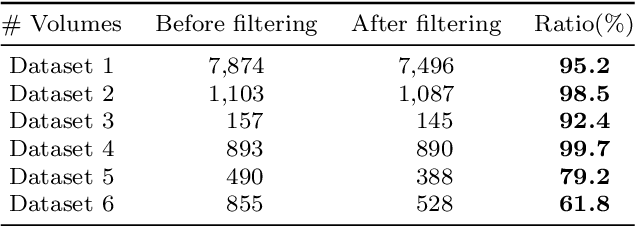
In this paper, we propose a method for generating a hierarchical, volumetric topological map from 3D point clouds. There are three basic hierarchical levels in our map: $storey - region - volume$. The advantages of our method are reflected in both input and output. In terms of input, we accept multi-storey point clouds and building structures with sloping roofs or ceilings. In terms of output, we can generate results with metric information of different dimensionality, that are suitable for different robotics applications. The algorithm generates the volumetric representation by generating $volumes$ from a 3D voxel occupancy map. We then add $passage$s (connections between $volumes$), combine small $volumes$ into a big $region$ and use a 2D segmentation method for better topological representation. We evaluate our method on several freely available datasets. The experiments highlight the advantages of our approach.
* Temporarily