 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Causal Representation for Face Transfer across Large Appearance Gap
Oct 17, 2021

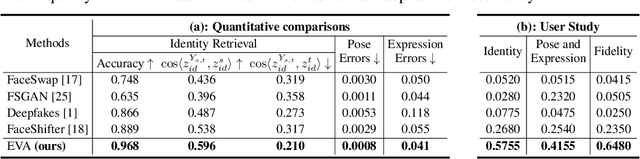
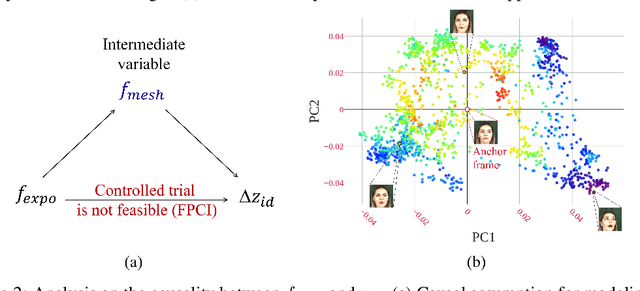
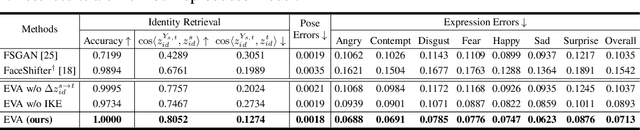
Identity transfer often faces the challenge of generalizing to new situations where large pose and expression or background gaps exist between source and target face images. To improve generalization in such situations, biases take a key role~\cite{mitchell_1980_bias}. This paper proposes an Errors-in-Variables Adapter (EVA) model to induce learning of proper generalizations by explicitly employing biases to identity estimation based on prior knowledge about the target situation. To better match the source face with the target situation in terms of pose, expression, and background factors, we model the bias as a causal effect of the target situation on source identity and estimate this effect through a controlled intervention trial. To achieve smoother transfer for the target face across the identity gap, we eliminate the target face specificity through multiple kernel regressions. The kernels are used to constrain the regressions to operate only on identity information in the internal representations of the target image, while leaving other perceptual information invariant. Combining these post-regression representations with the biased estimation for identity, EVA shows impressive performance even in the presence of large gaps, providing empirical evidence supporting the utility of the inductive biases in identity estimation.
Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation
Aug 17, 2021
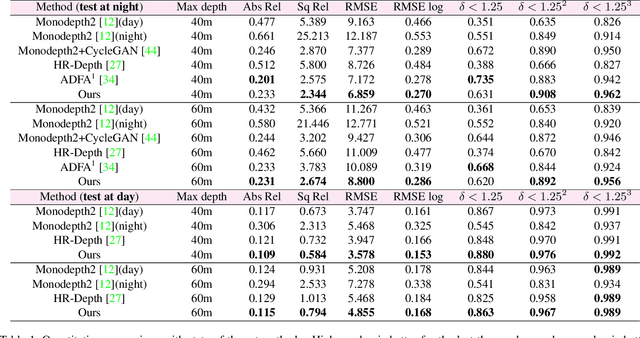
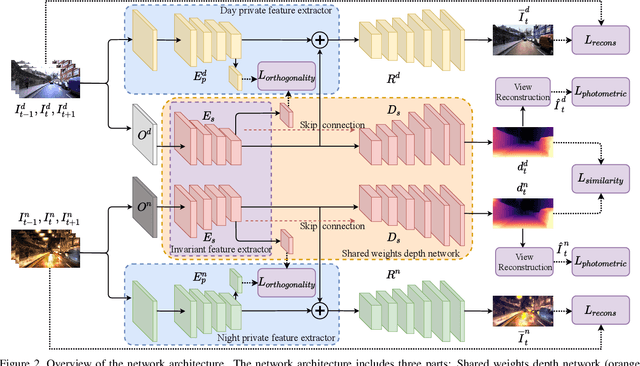
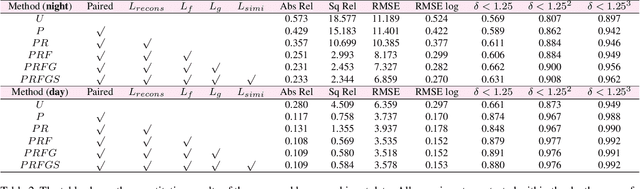
Remarkable results have been achieved by DCNN based self-supervised depth estimation approaches. However, most of these approaches can only handle either day-time or night-time images, while their performance degrades for all-day images due to large domain shift and the variation of illumination between day and night images. To relieve these limitations, we propose a domain-separated network for self-supervised depth estimation of all-day images. Specifically, to relieve the negative influence of disturbing terms (illumination, etc.), we partition the information of day and night image pairs into two complementary sub-spaces: private and invariant domains, where the former contains the unique information (illumination, etc.) of day and night images and the latter contains essential shared information (texture, etc.). Meanwhile, to guarantee that the day and night images contain the same information, the domain-separated network takes the day-time images and corresponding night-time images (generated by GAN) as input, and the private and invariant feature extractors are learned by orthogonality and similarity loss, where the domain gap can be alleviated, thus better depth maps can be expected. Meanwhile, the reconstruction and photometric losses are utilized to estimate complementary information and depth maps effectively. Experimental results demonstrate that our approach achieves state-of-the-art depth estimation results for all-day images on the challenging Oxford RobotCar dataset, proving the superiority of our proposed approach.
Complementary Patch for Weakly Supervised Semantic Segmentation
Aug 09, 2021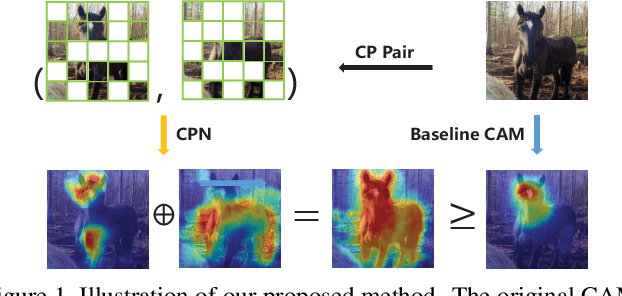
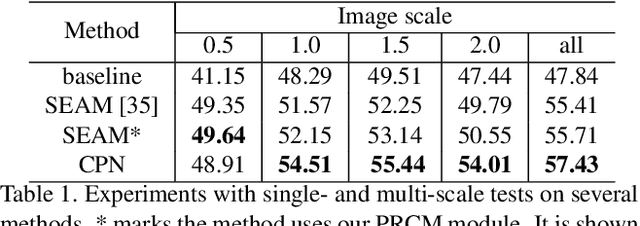
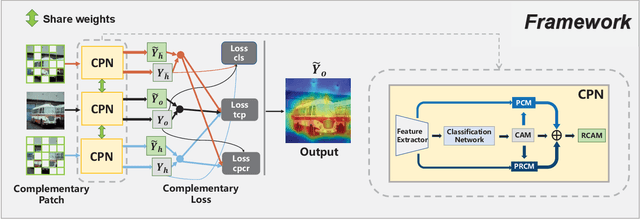

Weakly Supervised Semantic Segmentation (WSSS) based on image-level labels has been greatly advanced by exploiting the outputs of Class Activation Map (CAM) to generate the pseudo labels for semantic segmentation. However, CAM merely discovers seeds from a small number of regions, which may be insufficient to serve as pseudo masks for semantic segmentation. In this paper, we formulate the expansion of object regions in CAM as an increase in information. From the perspective of information theory, we propose a novel Complementary Patch (CP) Representation and prove that the information of the sum of the CAMs by a pair of input images with complementary hidden (patched) parts, namely CP Pair, is greater than or equal to the information of the baseline CAM. Therefore, a CAM with more information related to object seeds can be obtained by narrowing down the gap between the sum of CAMs generated by the CP Pair and the original CAM. We propose a CP Network (CPN) implemented by a triplet network and three regularization functions. To further improve the quality of the CAMs, we propose a Pixel-Region Correlation Module (PRCM) to augment the contextual information by using object-region relations between the feature maps and the CAMs. Experimental results on the PASCAL VOC 2012 datasets show that our proposed method achieves a new state-of-the-art in WSSS, validating the effectiveness of our CP Representation and CPN.
RepBin: Constraint-based Graph Representation Learning for Metagenomic Binning
Dec 22, 2021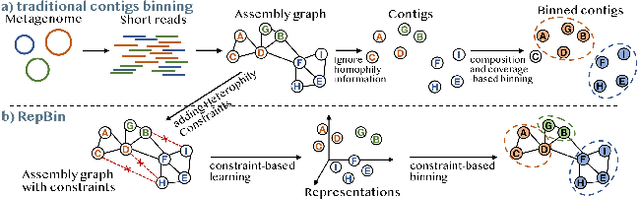
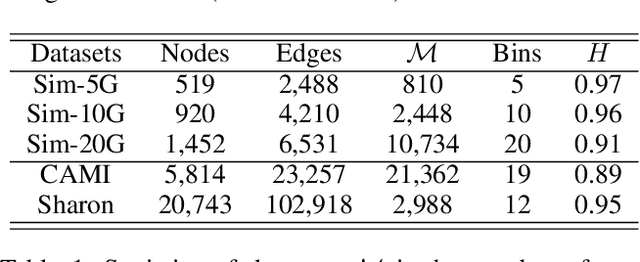
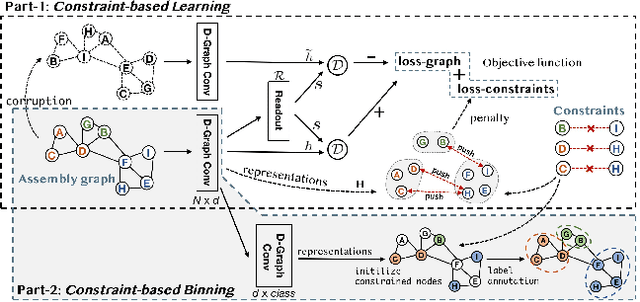
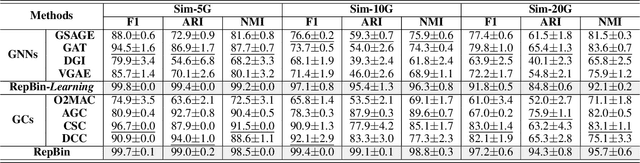
Mixed communities of organisms are found in many environments (from the human gut to marine ecosystems) and can have profound impact on human health and the environment. Metagenomics studies the genomic material of such communities through high-throughput sequencing that yields DNA subsequences for subsequent analysis. A fundamental problem in the standard workflow, called binning, is to discover clusters, of genomic subsequences, associated with the unknown constituent organisms. Inherent noise in the subsequences, various biological constraints that need to be imposed on them and the skewed cluster size distribution exacerbate the difficulty of this unsupervised learning problem. In this paper, we present a new formulation using a graph where the nodes are subsequences and edges represent homophily information. In addition, we model biological constraints providing heterophilous signal about nodes that cannot be clustered together. We solve the binning problem by developing new algorithms for (i) graph representation learning that preserves both homophily relations and heterophily constraints (ii) constraint-based graph clustering method that addresses the problems of skewed cluster size distribution. Extensive experiments, on real and synthetic datasets, demonstrate that our approach, called RepBin, outperforms a wide variety of competing methods. Our constraint-based graph representation learning and clustering methods, that may be useful in other domains as well, advance the state-of-the-art in both metagenomics binning and graph representation learning.
Learning to Navigate from Simulation via Spatial and Semantic Information Synthesis
Oct 13, 2019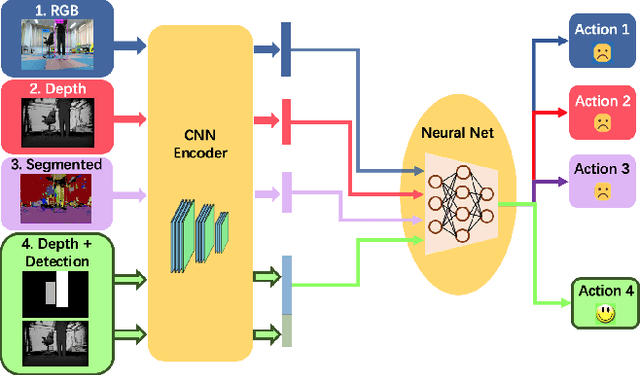
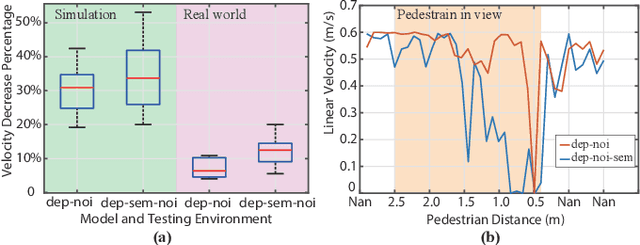

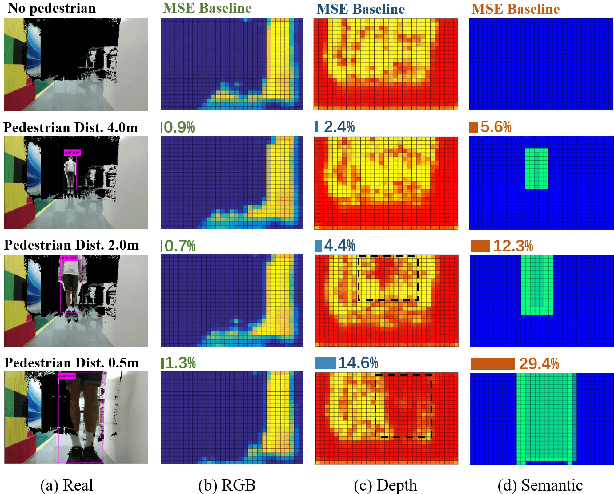
While training an end-to-end navigation network in the real world is usually of high cost, simulations provide a safe and cheap environment in this training stage. However, training neural network models in simulations brings up the problem of how to effectively transfer the model from simulations to the real world (sim-to-real). We regard the environment representation as a crucial element in this transfer process. In this work, we propose a visual information pyramid (VIP) theory to systematically investigate a practical environment representation. A representation composed of spatial and semantic information synthesis is established based on this theory. Specifically, the spatial information is presented by a noise-model-assisted depth image while the semantic information is expressed with a categorized detection image. To explore the effectiveness of this representation, we first extract different representations from a same dataset collected from expert operations, then feed them to the same or very similar neural networks to train the network parameters, and finally evaluate the trained neural networks in simulated and real world navigation tasks. Results suggest that our proposed environment representation behaves best compared with representations popularly used in the literature. With mere one-hour-long training data collected from simulation, the network model trained with our representation can successfully navigate the robot in various scenarios with obstacles. Furthermore, an analysis on the feature map is implemented to investigate the effectiveness through inner reaction, which could be irradiative for future researches on end-to-end navigation.
Deep MAGSAC++
Nov 28, 2021
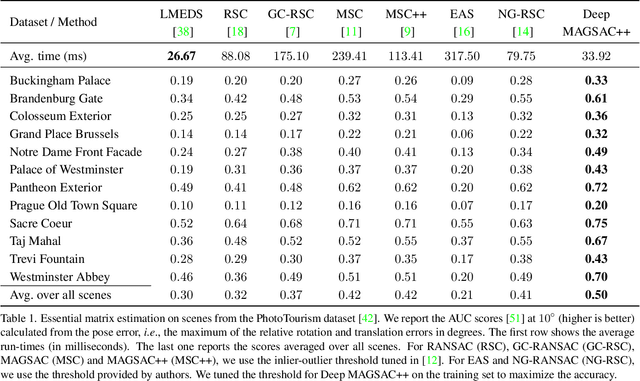
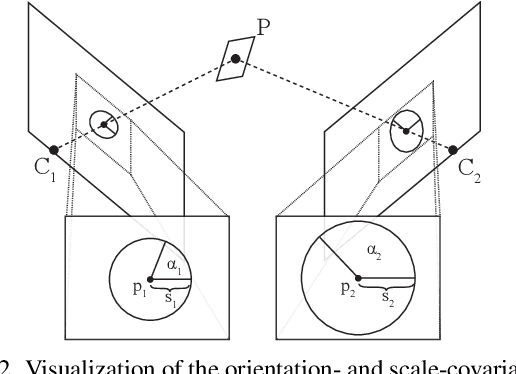
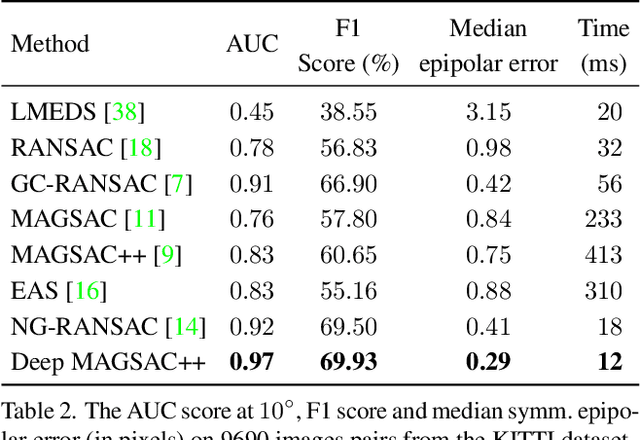
We propose Deep MAGSAC++ combining the advantages of traditional and deep robust estimators. We introduce a novel loss function that exploits the orientation and scale from partially affine covariant features, e.g., SIFT, in a geometrically justifiable manner. The new loss helps in learning higher-order information about the underlying scene geometry. Moreover, we propose a new sampler for RANSAC that always selects the sample with the highest probability of consisting only of inliers. After every unsuccessful iteration, the probabilities are updated in a principled way via a Bayesian approach. The prediction of the deep network is exploited as prior inside the sampler. Benefiting from the new loss, the proposed sampler, and a number of technical advancements, Deep MAGSAC++ is superior to the state-of-the-art both in terms of accuracy and run-time on thousands of image pairs from publicly available datasets for essential and fundamental matrix estimation.
FilterAugment: An Acoustic Environmental Data Augmentation Method
Oct 11, 2021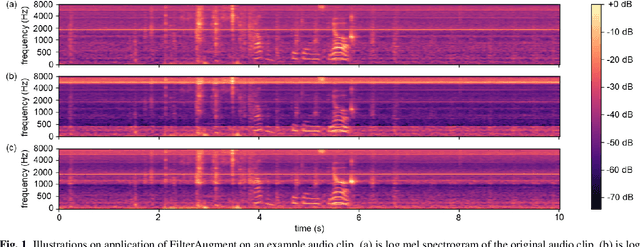
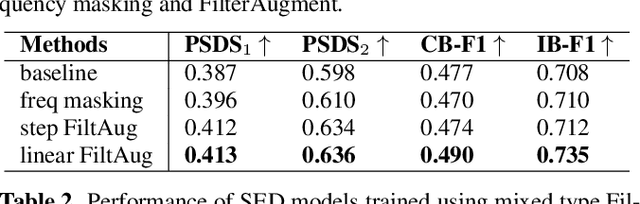
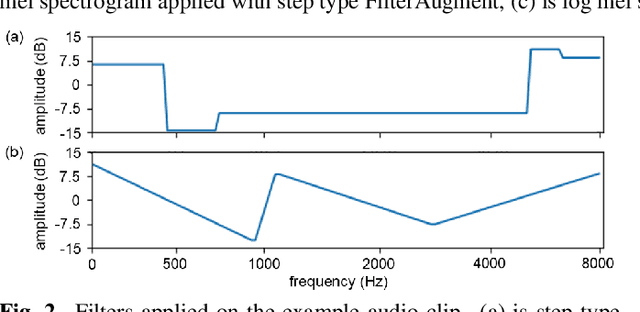
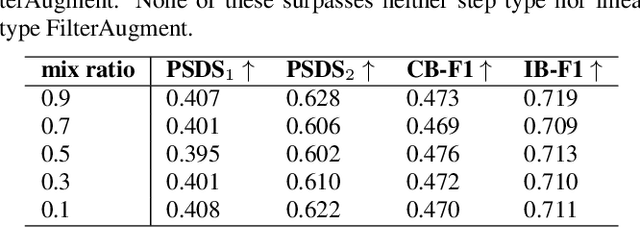
Acoustic environments affect acoustic characteristics of sound to be recognized under physically interaction with sound wave propagation. Thus, training acoustic models for audio and speech tasks requires regularization on various acoustic environments in order to achieve robust performance in real life applications. We propose FilterAugment, a data augmentation method for regularization of acoustic models on various acoustic environments. FilterAugment mimics acoustic filters by applying different weights on frequency bands, therefore enables model to extract relevant information from wider frequency region. It is an improved version of frequency masking which masks information on random frequency bands. FilterAugment improved sound event detection (SED) model performance by 6.50% while frequency masking only improved 2.13% in terms of polyphonic sound detection score (PSDS). It achieved equal error rate (EER) of 1.22% when applied to a text-independent speaker verification model, outperforming model used frequency masking with EER of 1.26%. Prototype of FilterAugment was applied in our participation in DCASE 2021 challenge task 4, and played a major role in achieving the 3rd rank.
Salient Object Detection by LTP Texture Characterization on Opposing Color Pairs under SLICO Superpixel Constraint
Jan 03, 2022
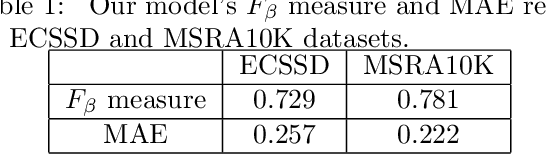
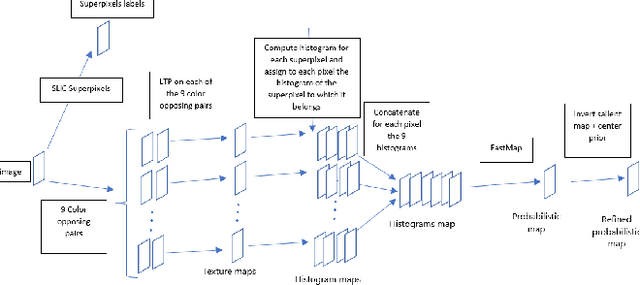

The effortless detection of salient objects by humans has been the subject of research in several fields, including computer vision as it has many applications. However, salient object detection remains a challenge for many computer models dealing with color and textured images. Herein, we propose a novel and efficient strategy, through a simple model, almost without internal parameters, which generates a robust saliency map for a natural image. This strategy consists of integrating color information into local textural patterns to characterize a color micro-texture. Most models in the literature that use the color and texture features treat them separately. In our case, it is the simple, yet powerful LTP (Local Ternary Patterns) texture descriptor applied to opposing color pairs of a color space that allows us to achieve this end. Each color micro-texture is represented by vector whose components are from a superpixel obtained by SLICO (Simple Linear Iterative Clustering with zero parameter) algorithm which is simple, fast and exhibits state-of-the-art boundary adherence. The degree of dissimilarity between each pair of color micro-texture is computed by the FastMap method, a fast version of MDS (Multi-dimensional Scaling), that considers the color micro-textures non-linearity while preserving their distances. These degrees of dissimilarity give us an intermediate saliency map for each RGB, HSL, LUV and CMY color spaces. The final saliency map is their combination to take advantage of the strength of each of them. The MAE (Mean Absolute Error) and F$_{\beta}$ measures of our saliency maps, on the complex ECSSD dataset show that our model is both simple and efficient, outperforming several state-of-the-art models.
ADD: Frequency Attention and Multi-View based Knowledge Distillation to Detect Low-Quality Compressed Deepfake Images
Dec 07, 2021
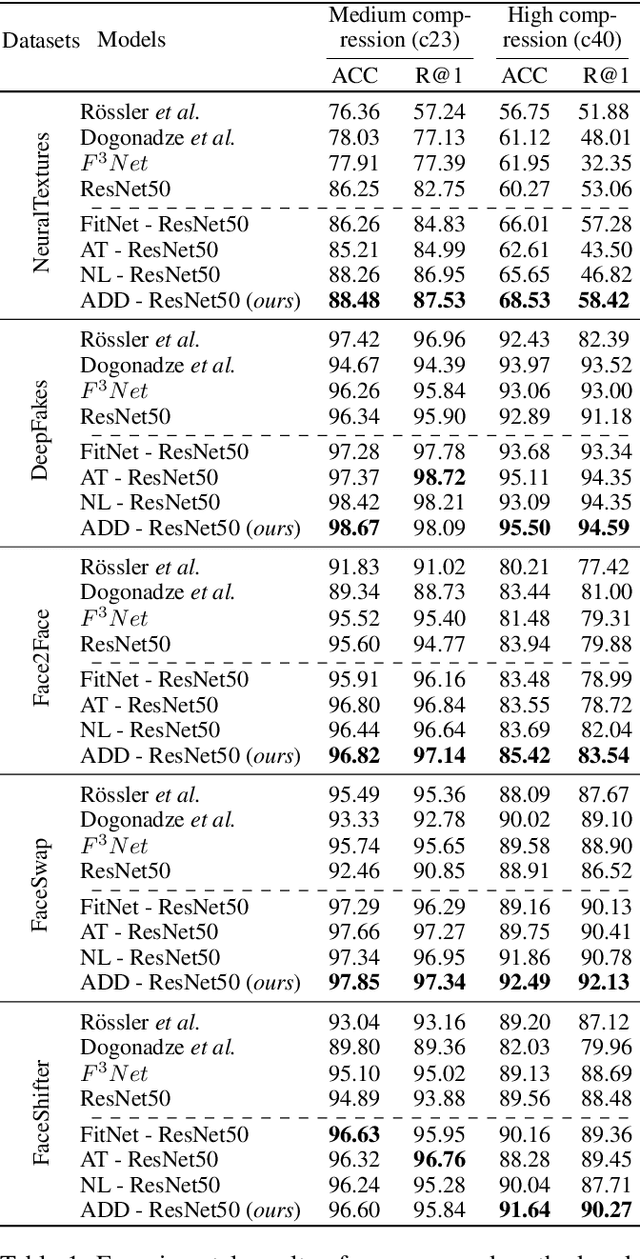
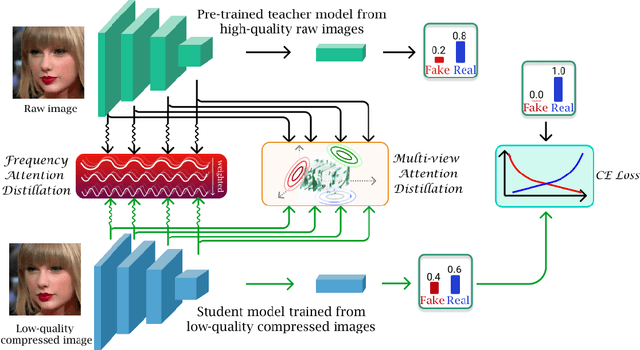

Despite significant advancements of deep learning-based forgery detectors for distinguishing manipulated deepfake images, most detection approaches suffer from moderate to significant performance degradation with low-quality compressed deepfake images. Because of the limited information in low-quality images, detecting low-quality deepfake remains an important challenge. In this work, we apply frequency domain learning and optimal transport theory in knowledge distillation (KD) to specifically improve the detection of low-quality compressed deepfake images. We explore transfer learning capability in KD to enable a student network to learn discriminative features from low-quality images effectively. In particular, we propose the Attention-based Deepfake detection Distiller (ADD), which consists of two novel distillations: 1) frequency attention distillation that effectively retrieves the removed high-frequency components in the student network, and 2) multi-view attention distillation that creates multiple attention vectors by slicing the teacher's and student's tensors under different views to transfer the teacher tensor's distribution to the student more efficiently. Our extensive experimental results demonstrate that our approach outperforms state-of-the-art baselines in detecting low-quality compressed deepfake images.
Emily: Developing An Emotion-affective Open-Domain Chatbot with Knowledge Graph-based Persona
Sep 18, 2021
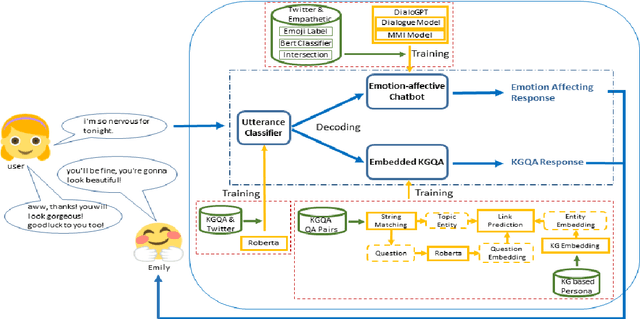
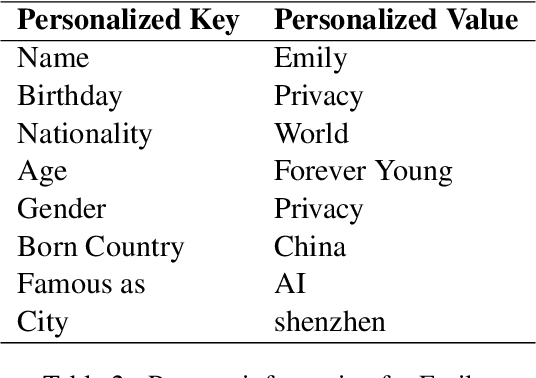
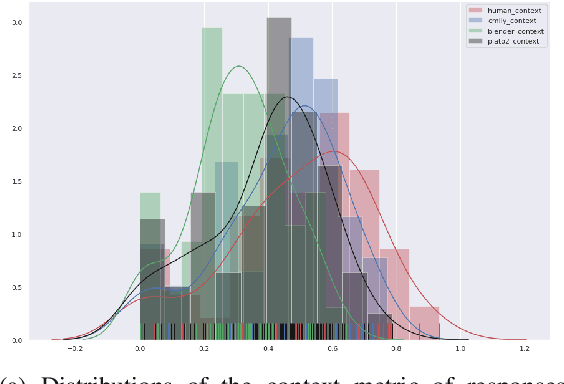
In this paper, we describe approaches for developing Emily, an emotion-affective open-domain chatbot. Emily can perceive a user's negative emotion state and offer supports by positively converting the user's emotion states. This is done by finetuning a pretrained dialogue model upon data capturing dialogue contexts and desirable emotion states transition across turns. Emily can differentiate a general open-domain dialogue utterance with questions relating to personal information. By leveraging a question-answering approach based on knowledge graphs to handle personal information, Emily maintains personality consistency. We evaluate Emily against a few state-of-the-art open-domain chatbots and show the effects of the proposed approaches in emotion affecting and addressing personality inconsistency.