 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Representation Learning via Neural Activation Coding
Dec 07, 2021
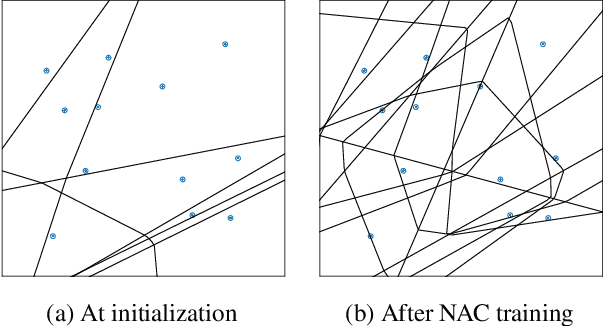
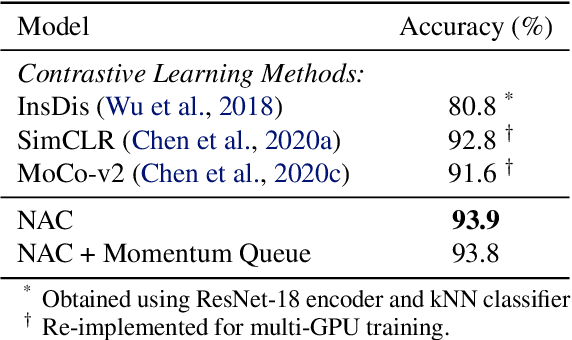
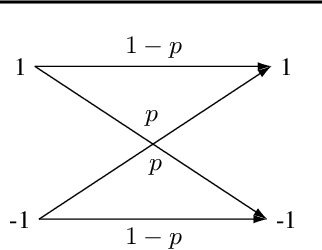
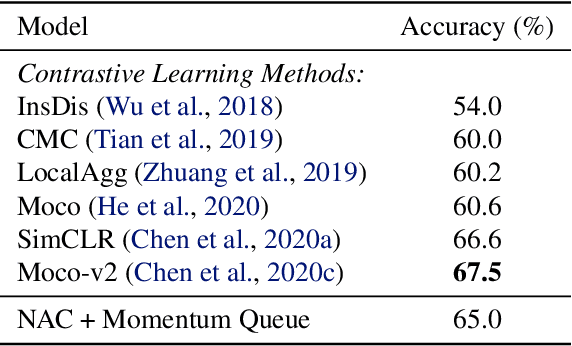
We present neural activation coding (NAC) as a novel approach for learning deep representations from unlabeled data for downstream applications. We argue that the deep encoder should maximize its nonlinear expressivity on the data for downstream predictors to take full advantage of its representation power. To this end, NAC maximizes the mutual information between activation patterns of the encoder and the data over a noisy communication channel. We show that learning for a noise-robust activation code increases the number of distinct linear regions of ReLU encoders, hence the maximum nonlinear expressivity. More interestingly, NAC learns both continuous and discrete representations of data, which we respectively evaluate on two downstream tasks: (i) linear classification on CIFAR-10 and ImageNet-1K and (ii) nearest neighbor retrieval on CIFAR-10 and FLICKR-25K. Empirical results show that NAC attains better or comparable performance on both tasks over recent baselines including SimCLR and DistillHash. In addition, NAC pretraining provides significant benefits to the training of deep generative models. Our code is available at https://github.com/yookoon/nac.
Nuclei Segmentation in Histopathology Images using Deep Learning with Local and Global Views
Dec 07, 2021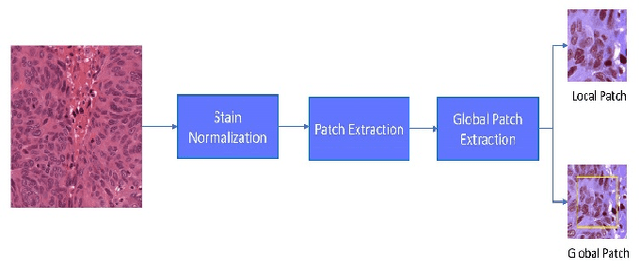
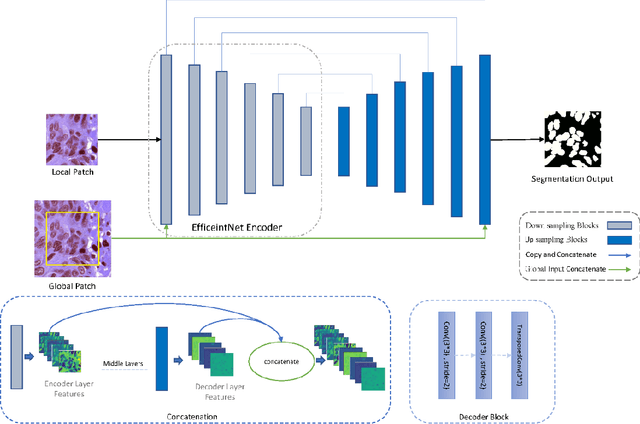
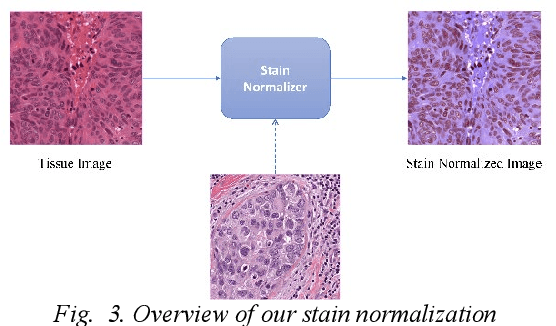
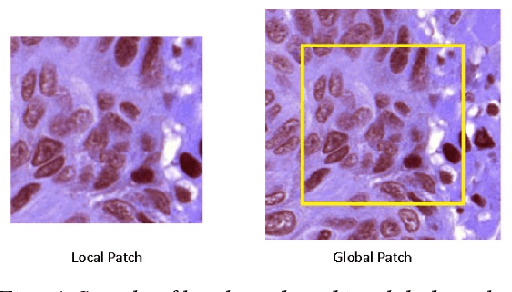
Digital pathology is one of the most significant developments in modern medicine. Pathological examinations are the gold standard of medical protocols and play a fundamental role in diagnosis. Recently, with the advent of digital scanners, tissue histopathology slides can now be digitized and stored as digital images. As a result, digitized histopathological tissues can be used in computer-aided image analysis programs and machine learning techniques. Detection and segmentation of nuclei are some of the essential steps in the diagnosis of cancers. Recently, deep learning has been used for nuclei segmentation. However, one of the problems in deep learning methods for nuclei segmentation is the lack of information from out of the patches. This paper proposes a deep learning-based approach for nuclei segmentation, which addresses the problem of misprediction in patch border areas. We use both local and global patches to predict the final segmentation map. Experimental results on the Multi-organ histopathology dataset demonstrate that our method outperforms the baseline nuclei segmentation and popular segmentation models.
Digital Audio Processing Tools for Music Corpus Studies
Nov 06, 2021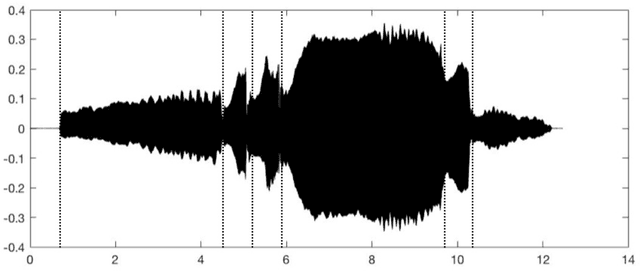
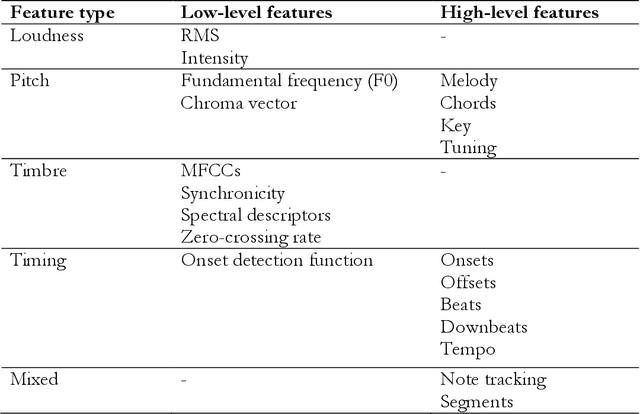
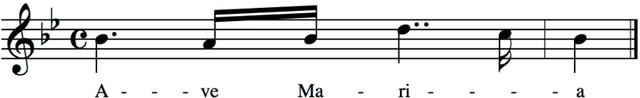
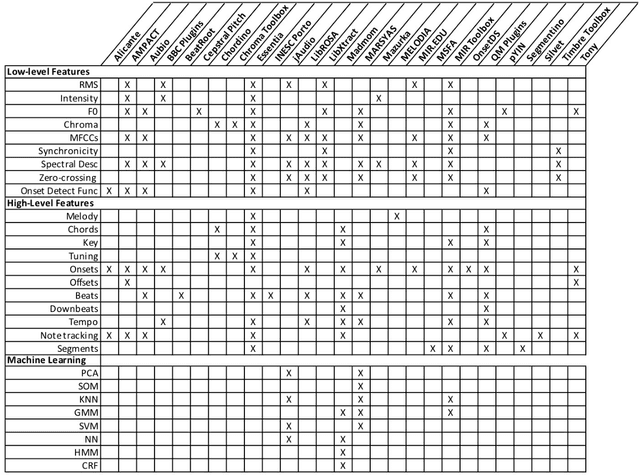
Digital audio processing tools offer music researchers the opportunity to examine both non-notated music and music as performance. This chapter summarises the types of information that can be extracted from audio as well as currently available audio tools for music corpus studies. The survey of extraction methods includes both a primer on signal processing and background theory on audio feature extraction. The survey of audio tools focuses on widely used tools, including both those with a graphical user interface, namely Audacity and Sonic Visualiser, and code-based tools written in the C/C++, Java, MATLAB, and Python computer programming languages.
BottleSum: Unsupervised and Self-supervised Sentence Summarization using the Information Bottleneck Principle
Sep 16, 2019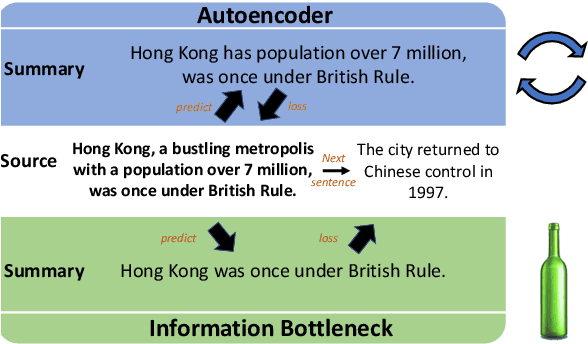
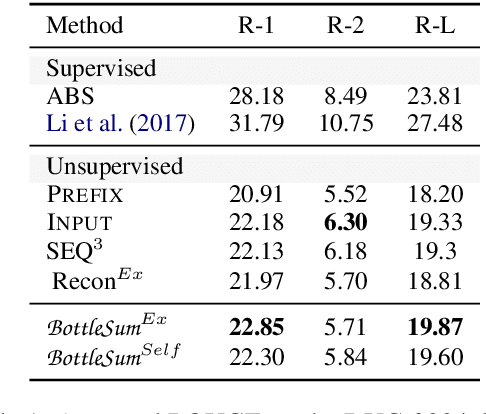
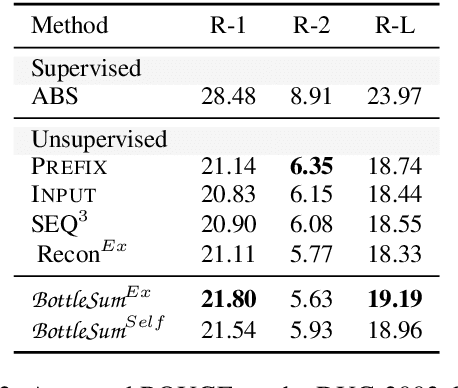
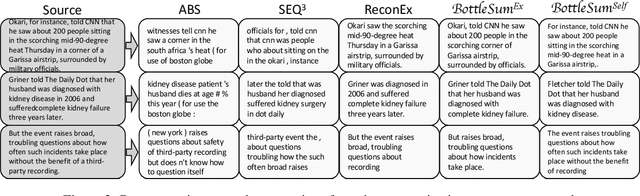
The principle of the Information Bottleneck (Tishby et al. 1999) is to produce a summary of information X optimized to predict some other relevant information Y. In this paper, we propose a novel approach to unsupervised sentence summarization by mapping the Information Bottleneck principle to a conditional language modelling objective: given a sentence, our approach seeks a compressed sentence that can best predict the next sentence. Our iterative algorithm under the Information Bottleneck objective searches gradually shorter subsequences of the given sentence while maximizing the probability of the next sentence conditioned on the summary. Using only pretrained language models with no direct supervision, our approach can efficiently perform extractive sentence summarization over a large corpus. Building on our unsupervised extractive summarization (BottleSumEx), we then present a new approach to self-supervised abstractive summarization (BottleSumSelf), where a transformer-based language model is trained on the output summaries of our unsupervised method. Empirical results demonstrate that our extractive method outperforms other unsupervised models on multiple automatic metrics. In addition, we find that our self-supervised abstractive model outperforms unsupervised baselines (including our own) by human evaluation along multiple attributes.
Applying Surface Normal Information in Drivable Area and Road Anomaly Detection for Ground Mobile Robots
Aug 26, 2020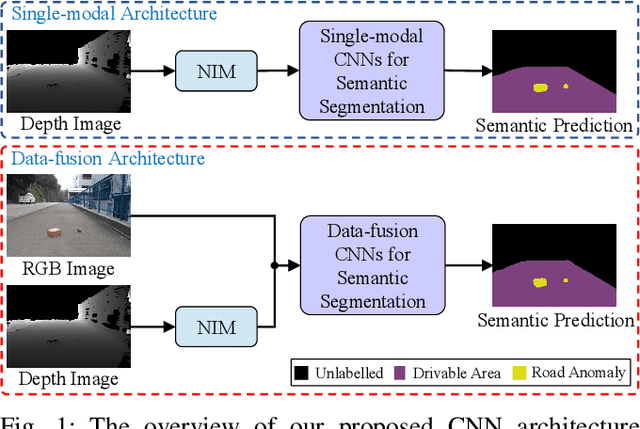
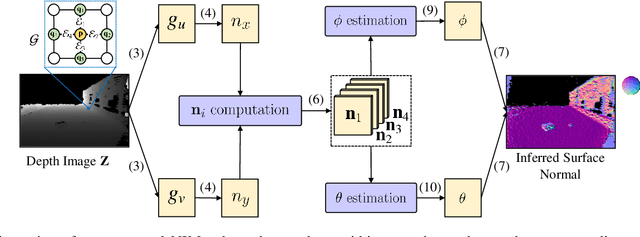
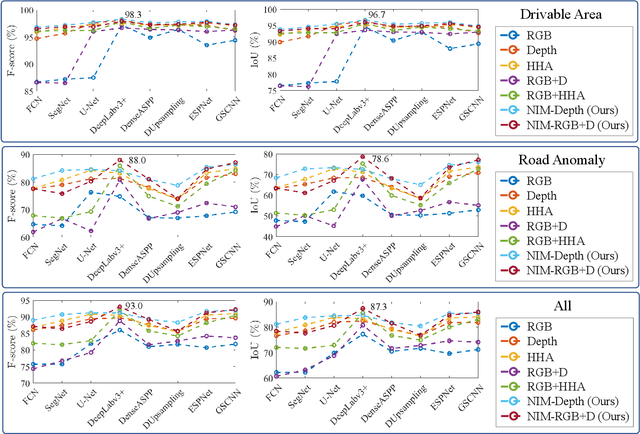
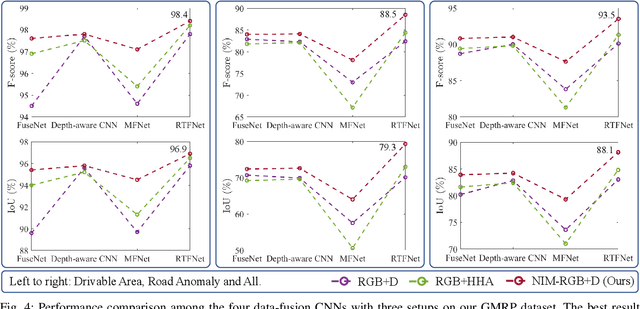
The joint detection of drivable areas and road anomalies is a crucial task for ground mobile robots. In recent years, many impressive semantic segmentation networks, which can be used for pixel-level drivable area and road anomaly detection, have been developed. However, the detection accuracy still needs improvement. Therefore, we develop a novel module named the Normal Inference Module (NIM), which can generate surface normal information from dense depth images with high accuracy and efficiency. Our NIM can be deployed in existing convolutional neural networks (CNNs) to refine the segmentation performance. To evaluate the effectiveness and robustness of our NIM, we embed it in twelve state-of-the-art CNNs. The experimental results illustrate that our NIM can greatly improve the performance of the CNNs for drivable area and road anomaly detection. Furthermore, our proposed NIM-RTFNet ranks 8th on the KITTI road benchmark and exhibits a real-time inference speed.
DA-FDFtNet: Dual Attention Fake Detection Fine-tuning Network to Detect Various AI-Generated Fake Images
Dec 22, 2021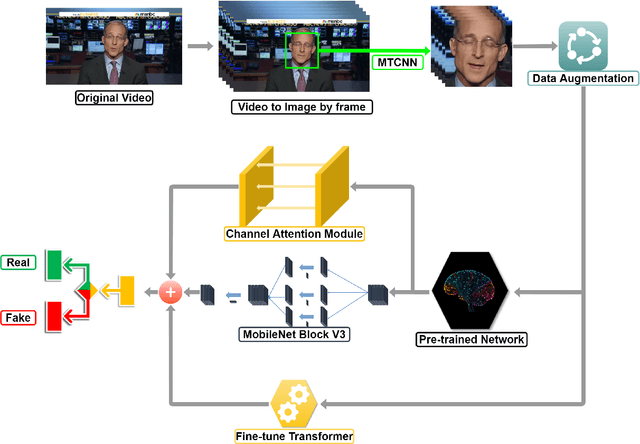

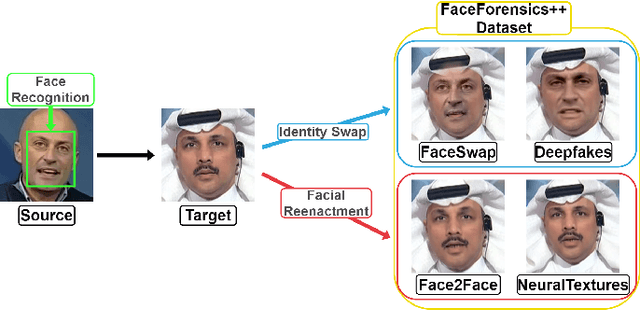

Due to the advancement of Generative Adversarial Networks (GAN), Autoencoders, and other AI technologies, it has been much easier to create fake images such as "Deepfakes". More recent research has introduced few-shot learning, which uses a small amount of training data to produce fake images and videos more effectively. Therefore, the ease of generating manipulated images and the difficulty of distinguishing those images can cause a serious threat to our society, such as propagating fake information. However, detecting realistic fake images generated by the latest AI technology is challenging due to the reasons mentioned above. In this work, we propose Dual Attention Fake Detection Fine-tuning Network (DA-FDFtNet) to detect the manipulated fake face images from the real face data. Our DA-FDFtNet integrates the pre-trained model with Fine-Tune Transformer, MBblockV3, and a channel attention module to improve the performance and robustness across different types of fake images. In particular, Fine-Tune Transformer consists of multiple numbers of an image-based self-attention module and a down-sampling layer. The channel attention module is also connected with the pre-trained model to capture the fake images feature space. We experiment with our DA-FDFtNet with the FaceForensics++ dataset and various GAN-generated datasets, and we show that our approach outperforms the previous baseline models.
Interpreting Active Learning Methods Through Information Losses
Feb 25, 2019
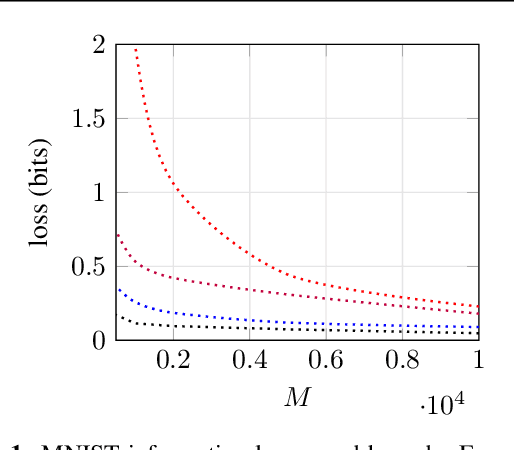
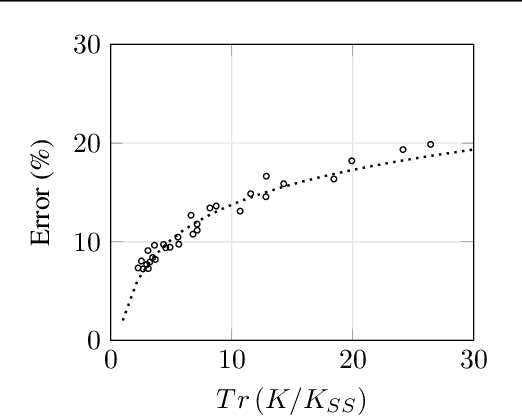
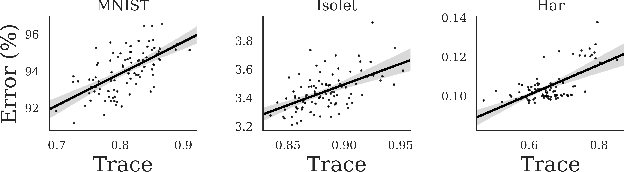
We propose a new way of interpreting active learning methods by analyzing the information `lost' upon sampling a random variable. We use some recent analytical developments of these losses to formally prove that facility location methods reduce these losses under mild assumptions, and to derive a new data dependent bound on information losses that can be used to evaluate other active learning methods. We show that this new bound is extremely tight to experiment, and further show that the bound has a decent predictive power for classification accuracy.
A CNN-BiLSTM Model with Attention Mechanism for Earthquake Prediction
Dec 26, 2021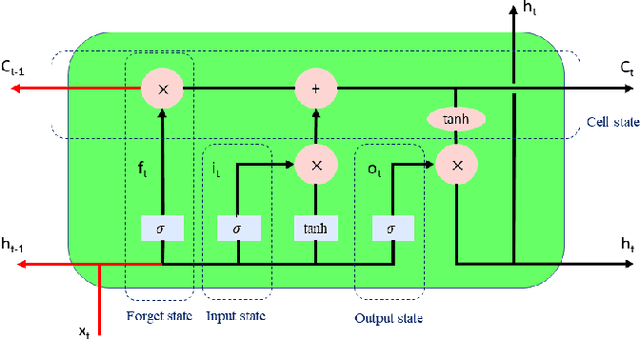
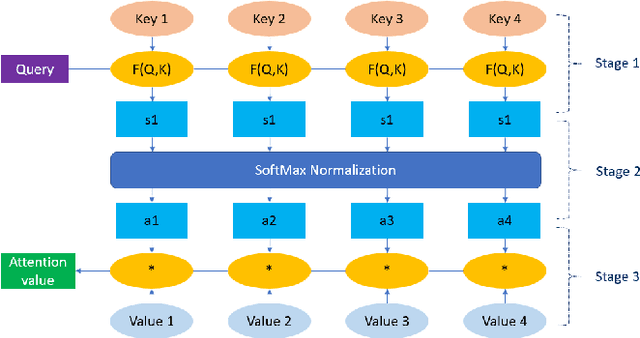
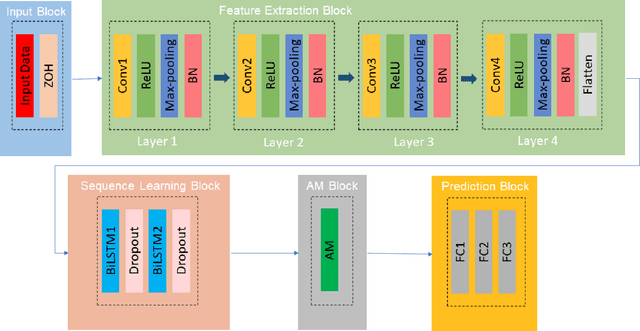
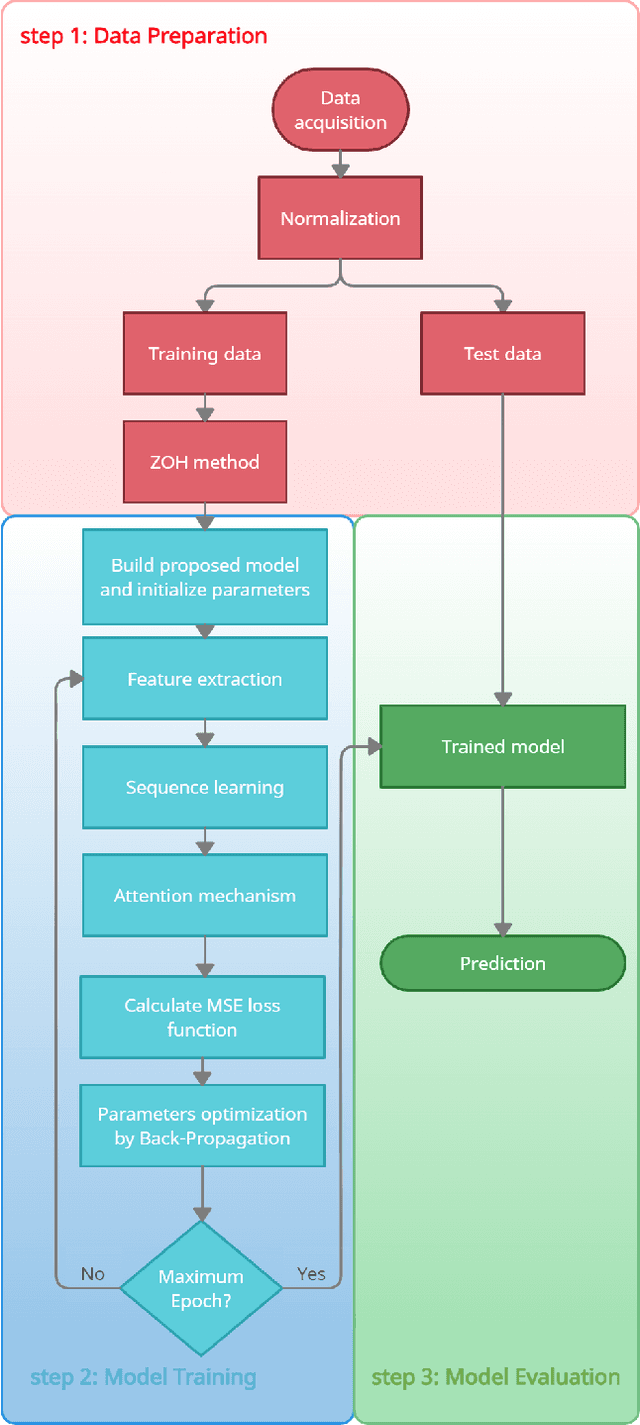
Earthquakes, as natural phenomena, have continuously caused damage and loss of human life historically. Earthquake prediction is an essential aspect of any society's plans and can increase public preparedness and reduce damage to a great extent. Nevertheless, due to the stochastic character of earthquakes and the challenge of achieving an efficient and dependable model for earthquake prediction, efforts have been insufficient thus far, and new methods are required to solve this problem. Aware of these issues, this paper proposes a novel prediction method based on attention mechanism (AM), convolution neural network (CNN), and bi-directional long short-term memory (BiLSTM) models, which can predict the number and maximum magnitude of earthquakes in each area of mainland China-based on the earthquake catalog of the region. This model takes advantage of LSTM and CNN with an attention mechanism to better focus on effective earthquake characteristics and produce more accurate predictions. Firstly, the zero-order hold technique is applied as pre-processing on earthquake data, making the model's input data more proper. Secondly, to effectively use spatial information and reduce dimensions of input data, the CNN is used to capture the spatial dependencies between earthquake data. Thirdly, the Bi-LSTM layer is employed to capture the temporal dependencies. Fourthly, the AM layer is introduced to highlight its important features to achieve better prediction performance. The results show that the proposed method has better performance and generalize ability than other prediction methods.
PartGlot: Learning Shape Part Segmentation from Language Reference Games
Dec 13, 2021
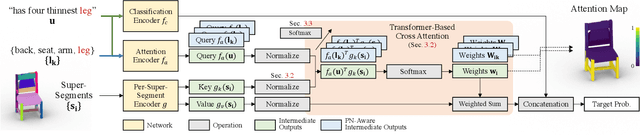
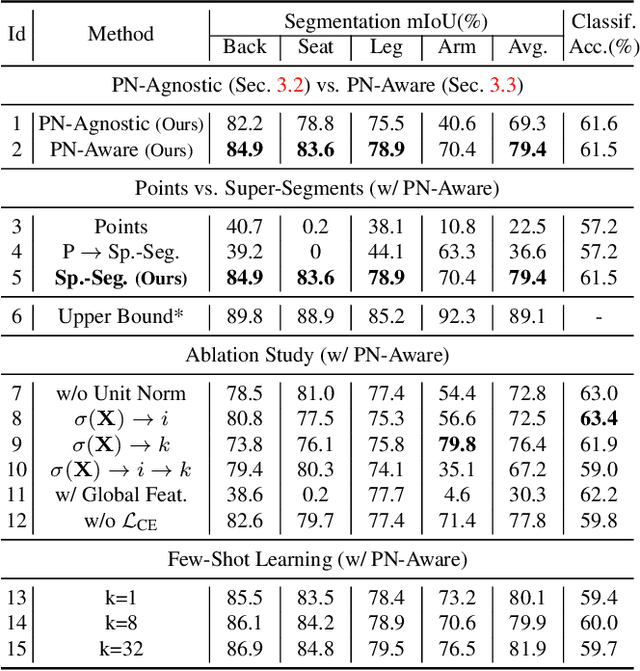

We introduce PartGlot, a neural framework and associated architectures for learning semantic part segmentation of 3D shape geometry, based solely on part referential language. We exploit the fact that linguistic descriptions of a shape can provide priors on the shape's parts -- as natural language has evolved to reflect human perception of the compositional structure of objects, essential to their recognition and use. For training, we use the paired geometry / language data collected in the ShapeGlot work for their reference game, where a speaker creates an utterance to differentiate a target shape from two distractors and the listener has to find the target based on this utterance. Our network is designed to solve this target discrimination problem, carefully incorporating a Transformer-based attention module so that the output attention can precisely highlight the semantic part or parts described in the language. Furthermore, the network operates without any direct supervision on the 3D geometry itself. Surprisingly, we further demonstrate that the learned part information is generalizable to shape classes unseen during training. Our approach opens the possibility of learning 3D shape parts from language alone, without the need for large-scale part geometry annotations, thus facilitating annotation acquisition.
Embracing Single Stride 3D Object Detector with Sparse Transformer
Dec 13, 2021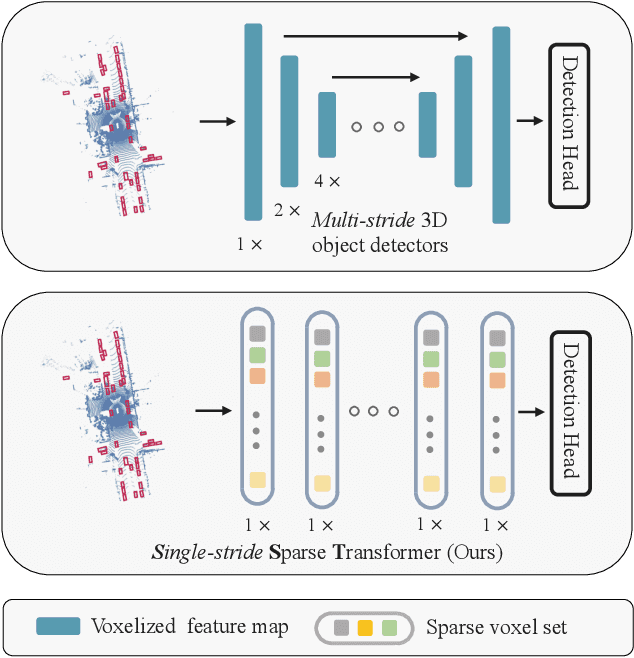
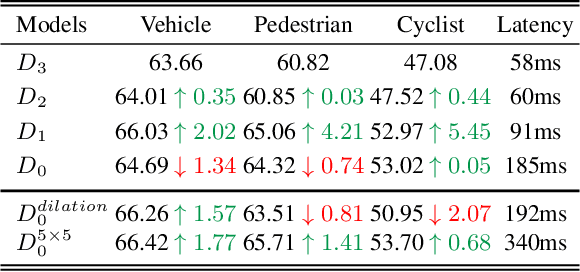
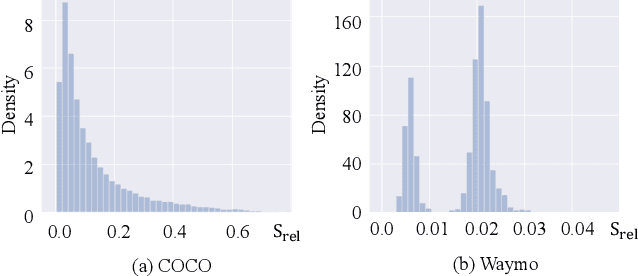
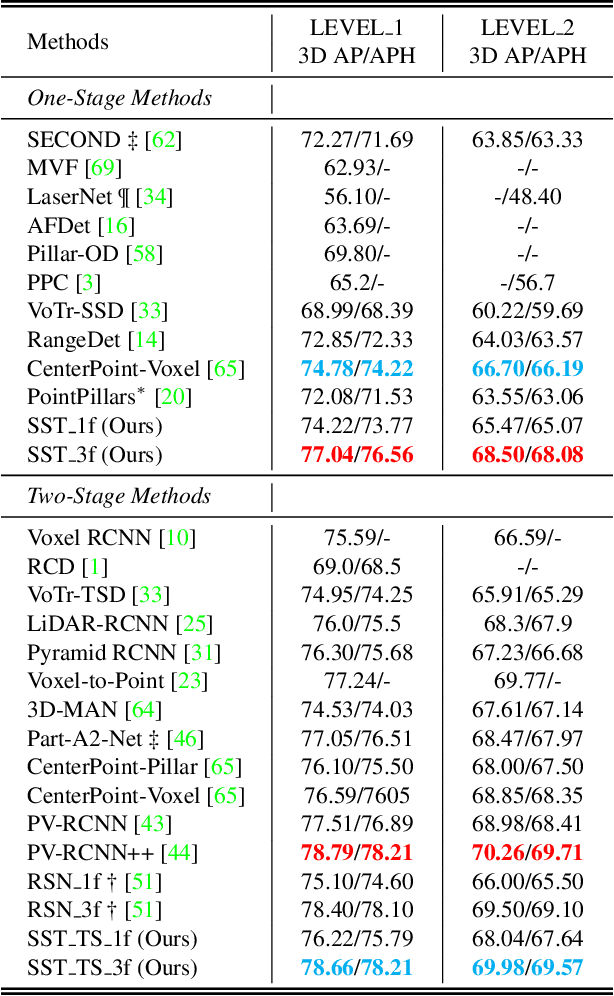
In LiDAR-based 3D object detection for autonomous driving, the ratio of the object size to input scene size is significantly smaller compared to 2D detection cases. Overlooking this difference, many 3D detectors directly follow the common practice of 2D detectors, which downsample the feature maps even after quantizing the point clouds. In this paper, we start by rethinking how such multi-stride stereotype affects the LiDAR-based 3D object detectors. Our experiments point out that the downsampling operations bring few advantages, and lead to inevitable information loss. To remedy this issue, we propose Single-stride Sparse Transformer (SST) to maintain the original resolution from the beginning to the end of the network. Armed with transformers, our method addresses the problem of insufficient receptive field in single-stride architectures. It also cooperates well with the sparsity of point clouds and naturally avoids expensive computation. Eventually, our SST achieves state-of-the-art results on the large scale Waymo Open Dataset. It is worth mentioning that our method can achieve exciting performance (83.8 LEVEL 1 AP on validation split) on small object (pedestrian) detection due to the characteristic of single stride. Codes will be released at https://github.com/TuSimple/SST