 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SSDL: Self-Supervised Dictionary Learning
Dec 03, 2021
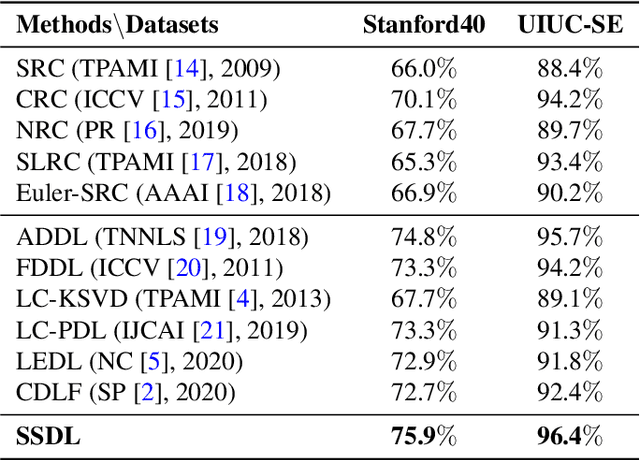
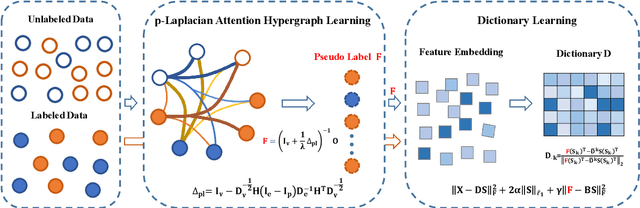
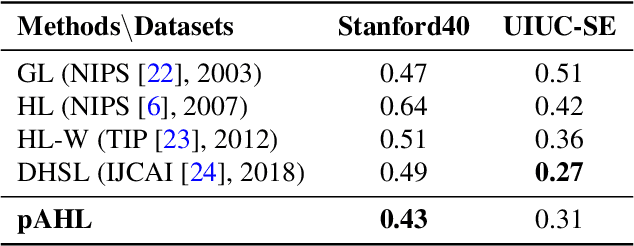
The label-embedded dictionary learning (DL) algorithms generate influential dictionaries by introducing discriminative information. However, there exists a limitation: All the label-embedded DL methods rely on the labels due that this way merely achieves ideal performances in supervised learning. While in semi-supervised and unsupervised learning, it is no longer sufficient to be effective. Inspired by the concept of self-supervised learning (e.g., setting the pretext task to generate a universal model for the downstream task), we propose a Self-Supervised Dictionary Learning (SSDL) framework to address this challenge. Specifically, we first design a $p$-Laplacian Attention Hypergraph Learning (pAHL) block as the pretext task to generate pseudo soft labels for DL. Then, we adopt the pseudo labels to train a dictionary from a primary label-embedded DL method. We evaluate our SSDL on two human activity recognition datasets. The comparison results with other state-of-the-art methods have demonstrated the efficiency of SSDL.
EIHW-MTG DiCOVA 2021 Challenge System Report
Oct 13, 2021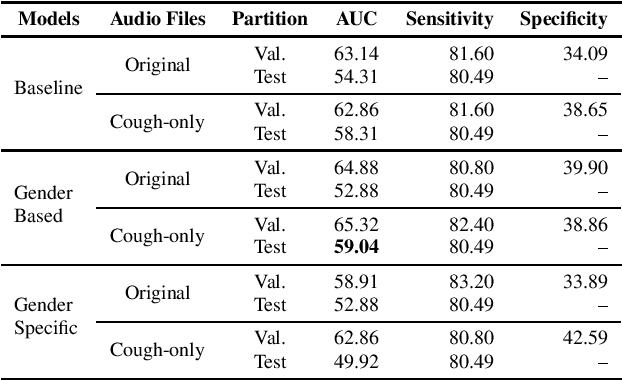
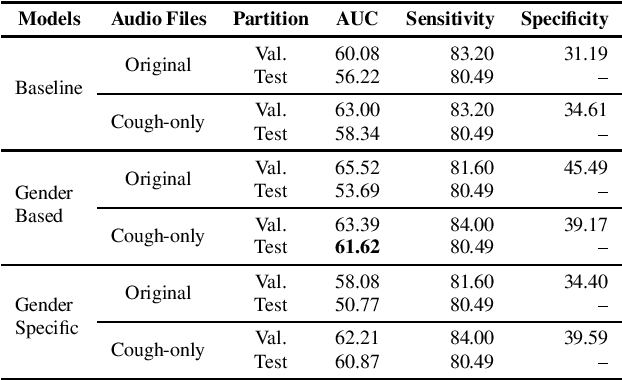
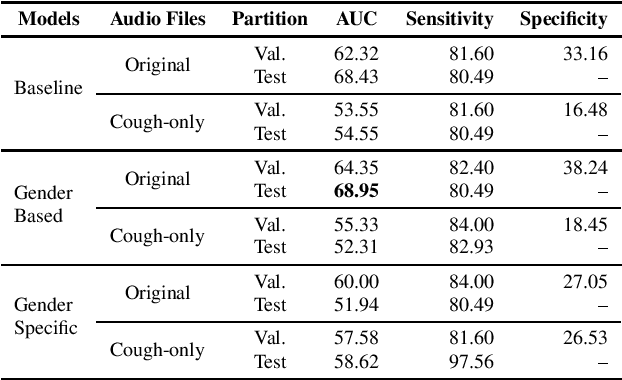
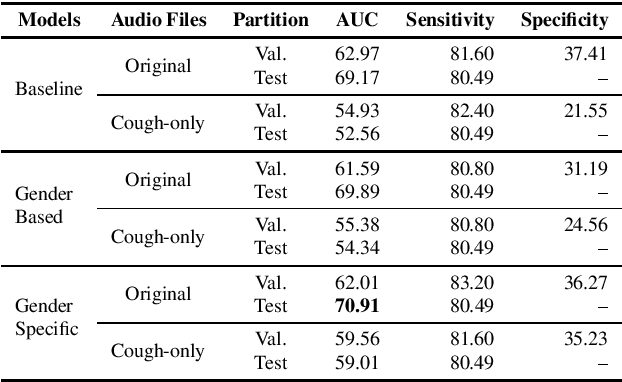
This paper aims to automatically detect COVID-19 patients by analysing the acoustic information embedded in coughs. COVID-19 affects the respiratory system, and, consequently, respiratory-related signals have the potential to contain salient information for the task at hand. We focus on analysing the spectrogram representations of coughing samples with the aim to investigate whether COVID-19 alters the frequency content of these signals. Furthermore, this work also assesses the impact of gender in the automatic detection of COVID-19. To extract deep learnt representations of the spectrograms, we compare the performance of a cough-specific, and a Resnet18 pre-trained Convolutional Neural Network (CNN). Additionally, our approach explores the use of contextual attention, so the model can learn to highlight the most relevant deep learnt features extracted by the CNN. We conduct our experiments on the dataset released for the Cough Sound Track of the DiCOVA 2021 Challenge. The best performance on the test set is obtained using the Resnet18 pre-trained CNN with contextual attention, which scored an Area Under the Curve (AUC) of 70.91 at 80% sensitivity.
Teaching an Active Learner with Contrastive Examples
Oct 29, 2021
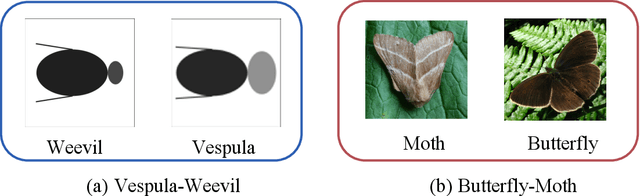
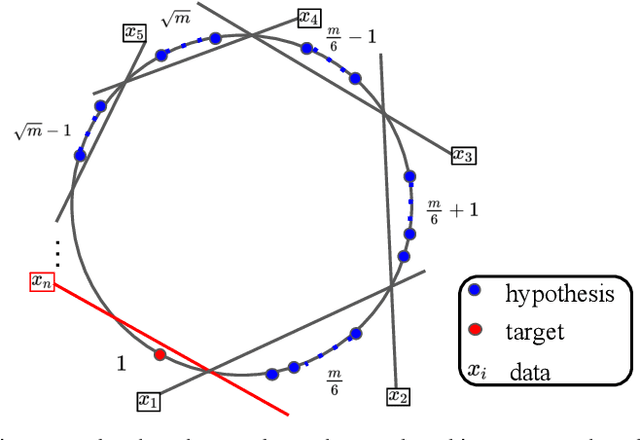
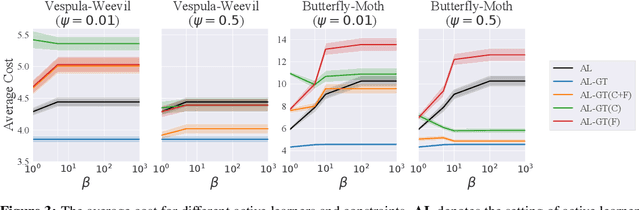
We study the problem of active learning with the added twist that the learner is assisted by a helpful teacher. We consider the following natural interaction protocol: At each round, the learner proposes a query asking for the label of an instance $x^q$, the teacher provides the requested label $\{x^q, y^q\}$ along with explanatory information to guide the learning process. In this paper, we view this information in the form of an additional contrastive example ($\{x^c, y^c\}$) where $x^c$ is picked from a set constrained by $x^q$ (e.g., dissimilar instances with the same label). Our focus is to design a teaching algorithm that can provide an informative sequence of contrastive examples to the learner to speed up the learning process. We show that this leads to a challenging sequence optimization problem where the algorithm's choices at a given round depend on the history of interactions. We investigate an efficient teaching algorithm that adaptively picks these contrastive examples. We derive strong performance guarantees for our algorithm based on two problem-dependent parameters and further show that for specific types of active learners (e.g., a generalized binary search learner), the proposed teaching algorithm exhibits strong approximation guarantees. Finally, we illustrate our bounds and demonstrate the effectiveness of our teaching framework via two numerical case studies.
Event-Aware Multimodal Mobility Nowcasting
Dec 14, 2021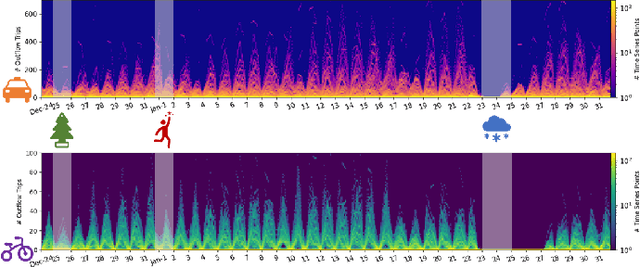
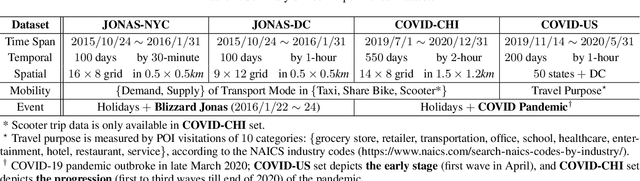
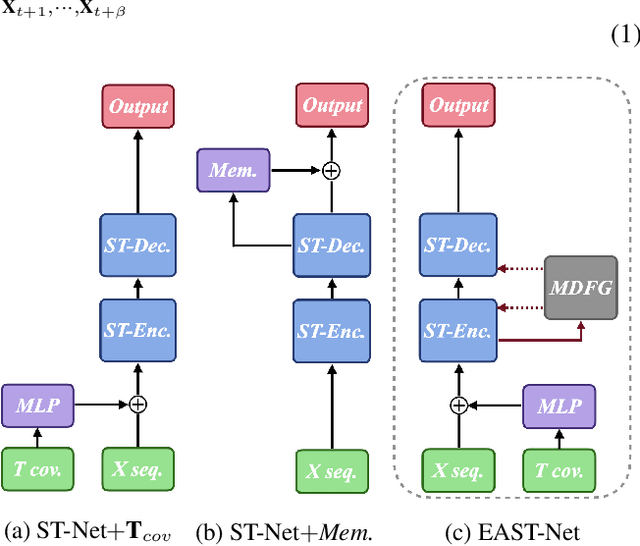
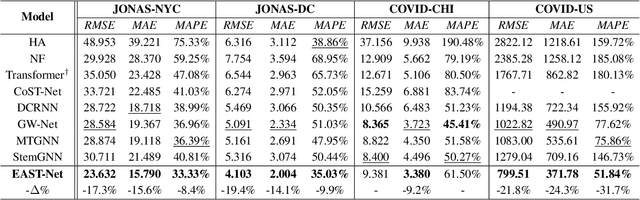
As a decisive part in the success of Mobility-as-a-Service (MaaS), spatio-temporal predictive modeling for crowd movements is a challenging task particularly considering scenarios where societal events drive mobility behavior deviated from the normality. While tremendous progress has been made to model high-level spatio-temporal regularities with deep learning, most, if not all of the existing methods are neither aware of the dynamic interactions among multiple transport modes nor adaptive to unprecedented volatility brought by potential societal events. In this paper, we are therefore motivated to improve the canonical spatio-temporal network (ST-Net) from two perspectives: (1) design a heterogeneous mobility information network (HMIN) to explicitly represent intermodality in multimodal mobility; (2) propose a memory-augmented dynamic filter generator (MDFG) to generate sequence-specific parameters in an on-the-fly fashion for various scenarios. The enhanced event-aware spatio-temporal network, namely EAST-Net, is evaluated on several real-world datasets with a wide variety and coverage of societal events. Both quantitative and qualitative experimental results verify the superiority of our approach compared with the state-of-the-art baselines. Code and data are published on https://github.com/underdoc-wang/EAST-Net.
Raising context awareness in motion forecasting
Sep 16, 2021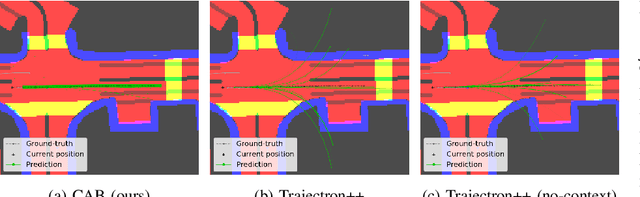
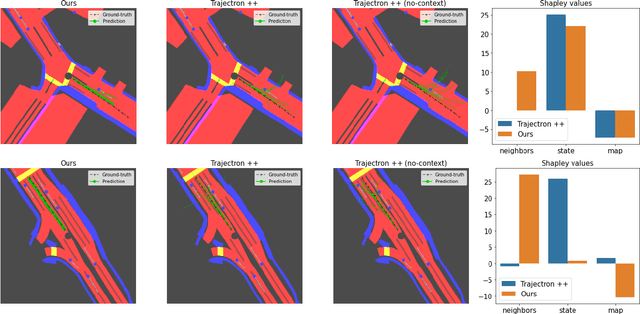
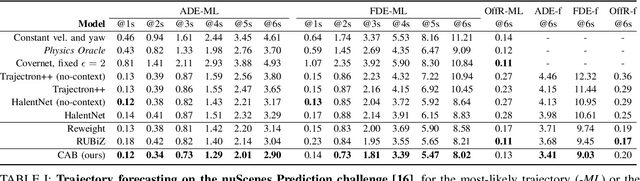
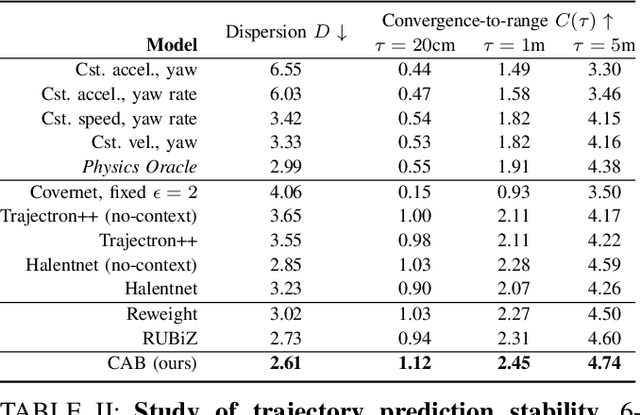
Learning-based trajectory prediction models have encountered great success, with the promise of leveraging contextual information in addition to motion history. Yet, we find that state-of-the-art forecasting methods tend to overly rely on the agent's dynamics, failing to exploit the semantic cues provided at its input. To alleviate this issue, we introduce CAB, a motion forecasting model equipped with a training procedure designed to promote the use of semantic contextual information. We also introduce two novel metrics -- dispersion and convergence-to-range -- to measure the temporal consistency of successive forecasts, which we found missing in standard metrics. Our method is evaluated on the widely adopted nuScenes Prediction benchmark.
MSP : Refine Boundary Segmentation via Multiscale Superpixel
Dec 03, 2021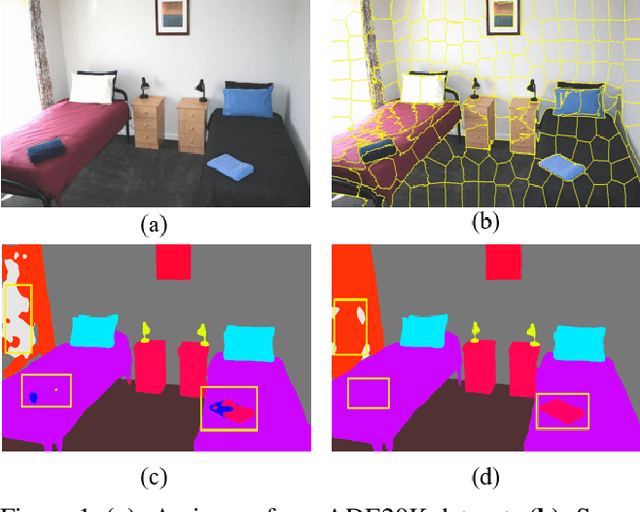

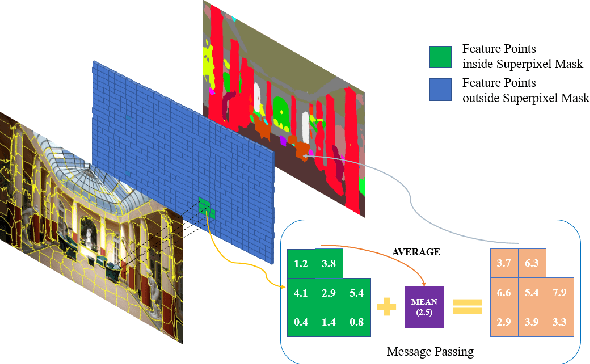
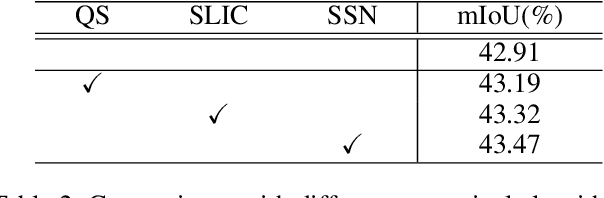
In this paper, we propose a simple but effective message passing method to improve the boundary quality for the semantic segmentation result. Inspired by the generated sharp edges of superpixel blocks, we employ superpixel to guide the information passing within feature map. Simultaneously, the sharp boundaries of the blocks also restrict the message passing scope. Specifically, we average features that the superpixel block covers within feature map, and add the result back to each feature vector. Further, to obtain sharper edges and farther spatial dependence, we develop a multiscale superpixel module (MSP) by a cascade of different scales superpixel blocks. Our method can be served as a plug-and-play module and easily inserted into any segmentation network without introducing new parameters. Extensive experiments are conducted on three strong baselines, namely PSPNet, DeeplabV3, and DeepLabV3+, and four challenging scene parsing datasets including ADE20K, Cityscapes, PASCAL VOC, and PASCAL Context. The experimental results verify its effectiveness and generalizability.
Value of Information Analysis via Active Learning and Knowledge Sharing in Error-Controlled Adaptive Kriging
Feb 06, 2020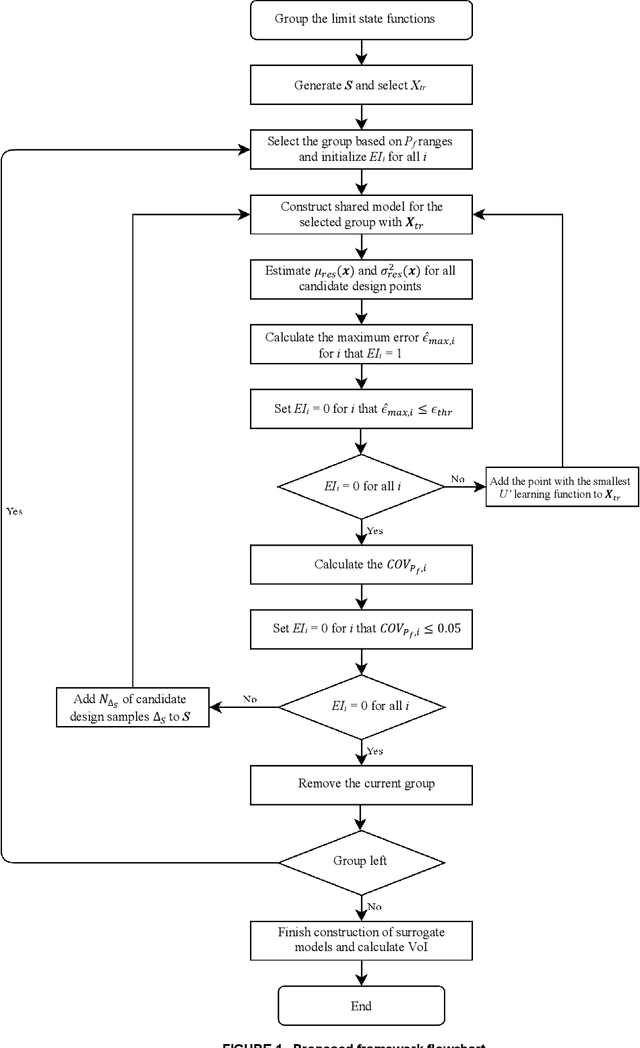
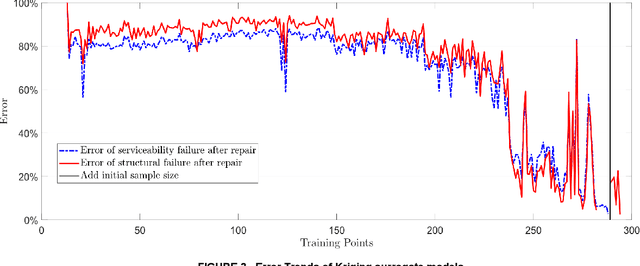
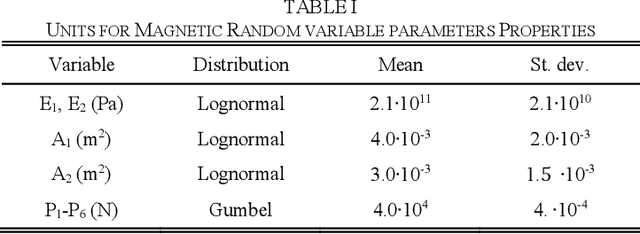
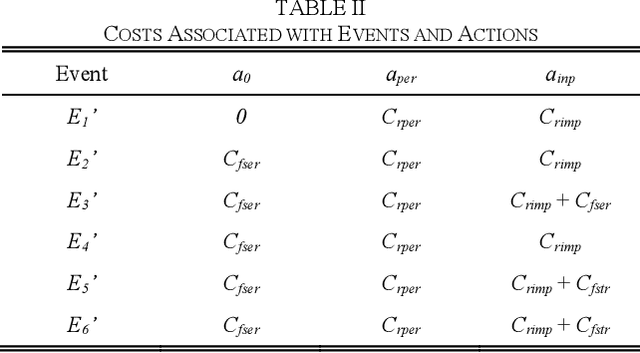
Large uncertainties in many phenomena of interest have challenged the reliability of pertaining decisions. Collecting additional information to better characterize involved uncertainties is among decision alternatives. Value of information (VoI) analysis is a mathematical decision framework that quantifies expected potential benefits of new data and assists with optimal allocation of resources for information collection. However, a primary challenge facing VoI analysis is the very high computational cost of the underlying Bayesian inference especially for equality-type information. This paper proposes the first surrogate-based framework for VoI analysis. Instead of modeling the limit state functions describing events of interest for decision making, which is commonly pursued in surrogate model-based reliability methods, the proposed framework models system responses. This approach affords sharing equality-type information from observations among surrogate models to update likelihoods of multiple events of interest. Moreover, two knowledge sharing schemes called model and training points sharing are proposed to most effectively take advantage of the knowledge offered by costly model evaluations. Both schemes are integrated with an error rate-based adaptive training approach to efficiently generate accurate Kriging surrogate models. The proposed VoI analysis framework is applied for an optimal decision-making problem involving load testing of a truss bridge. While state-of-the-art methods based on importance sampling and adaptive Kriging Monte Carlo simulation are unable to solve this problem, the proposed method is shown to offer accurate and robust estimates of VoI with a limited number of model evaluations. Therefore, the proposed method facilitates the application of VoI for complex decision problems.
Quantifying Uncertainty in Deep Learning Approaches to Radio Galaxy Classification
Jan 04, 2022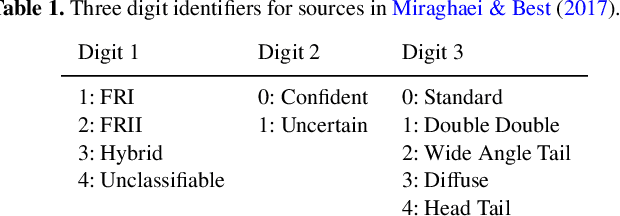
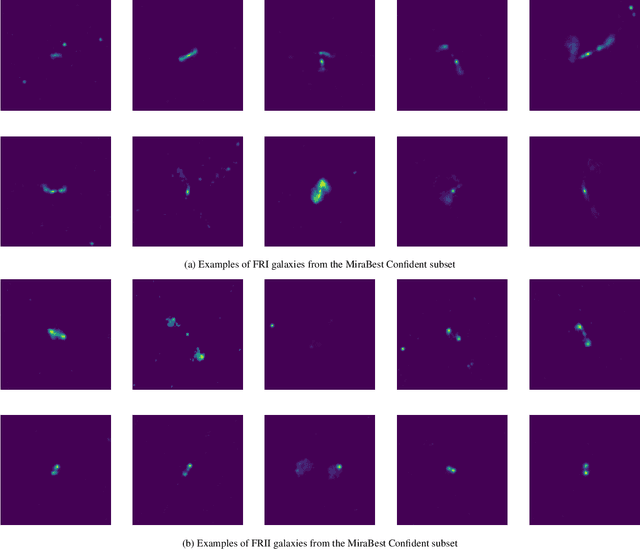
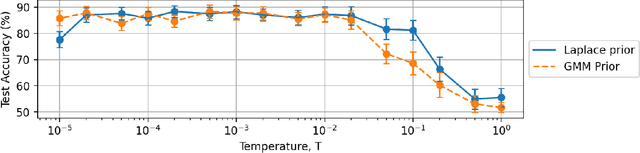
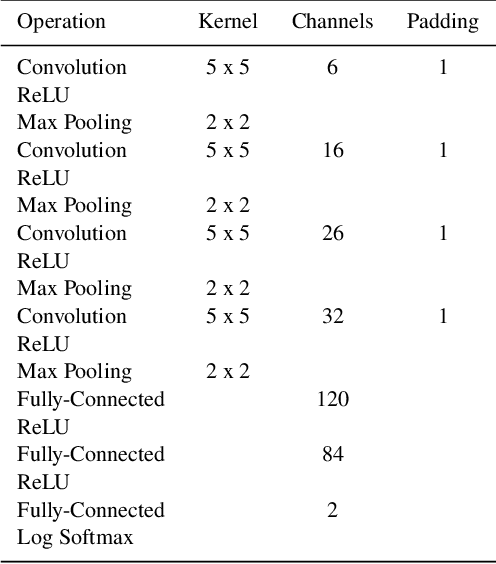
In this work we use variational inference to quantify the degree of uncertainty in deep learning model predictions of radio galaxy classification. We show that the level of model posterior variance for individual test samples is correlated with human uncertainty when labelling radio galaxies. We explore the model performance and uncertainty calibration for a variety of different weight priors and suggest that a sparse prior produces more well-calibrated uncertainty estimates. Using the posterior distributions for individual weights, we show that we can prune 30% of the fully-connected layer weights without significant loss of performance by removing the weights with the lowest signal-to-noise ratio (SNR). We demonstrate that a larger degree of pruning can be achieved using a Fisher information based ranking, but we note that both pruning methods affect the uncertainty calibration for Fanaroff-Riley type I and type II radio galaxies differently. Finally we show that, like other work in this field, we experience a cold posterior effect, whereby the posterior must be down-weighted to achieve good predictive performance. We examine whether adapting the cost function to accommodate model misspecification can compensate for this effect, but find that it does not make a significant difference. We also examine the effect of principled data augmentation and find that this improves upon the baseline but also does not compensate for the observed effect. We interpret this as the cold posterior effect being due to the overly effective curation of our training sample leading to likelihood misspecification, and raise this as a potential issue for Bayesian deep learning approaches to radio galaxy classification in future.
Quantum adaptive agents with efficient long-term memories
Aug 24, 2021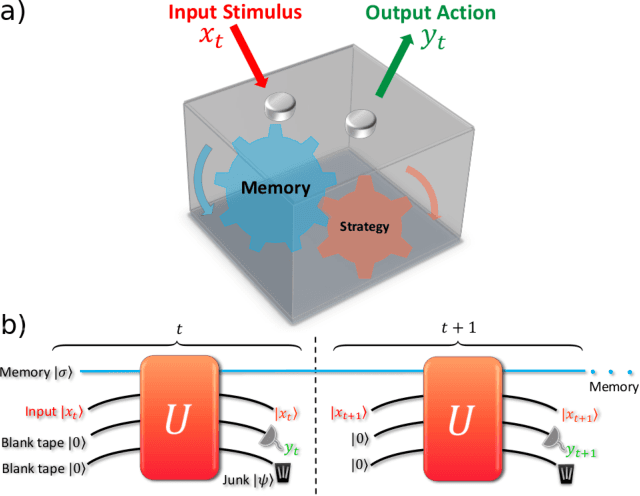
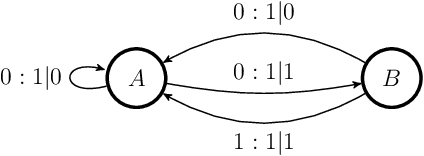
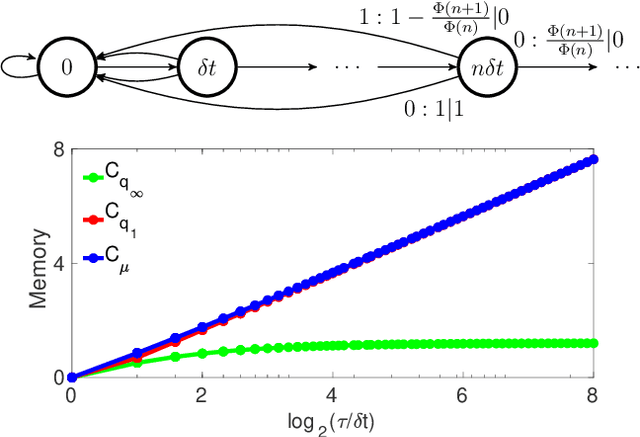
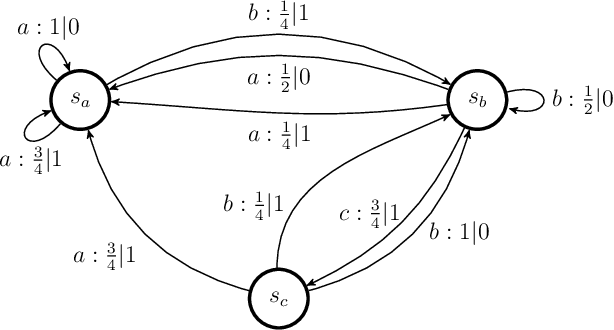
Central to the success of adaptive systems is their ability to interpret signals from their environment and respond accordingly -- they act as agents interacting with their surroundings. Such agents typically perform better when able to execute increasingly complex strategies. This comes with a cost: the more information the agent must recall from its past experiences, the more memory it will need. Here we investigate the power of agents capable of quantum information processing. We uncover the most general form a quantum agent need adopt to maximise memory compression advantages, and provide a systematic means of encoding their memory states. We show these encodings can exhibit extremely favourable scaling advantages relative to memory-minimal classical agents when information must be retained about events increasingly far into the past.
Compensating trajectory bias for unsupervised patient stratification using adversarial recurrent neural networks
Dec 14, 2021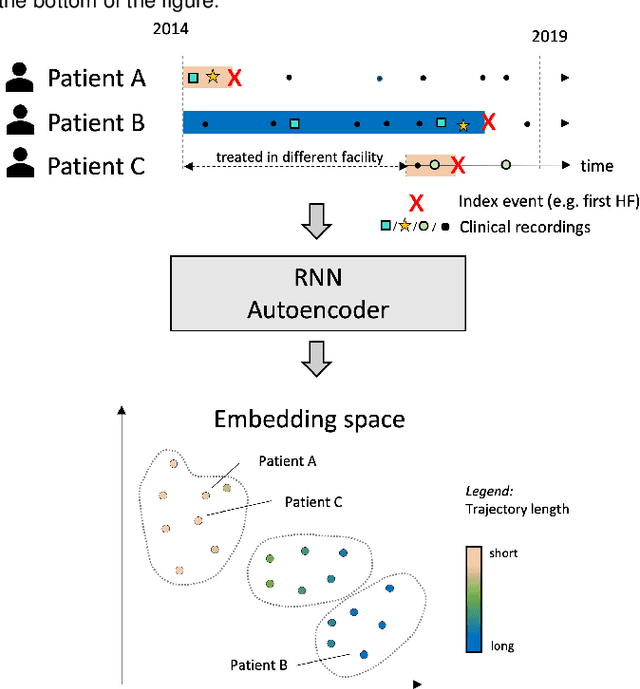
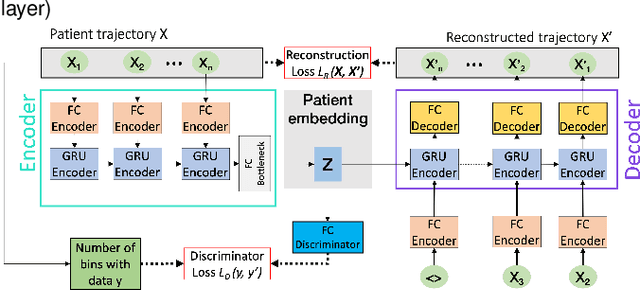
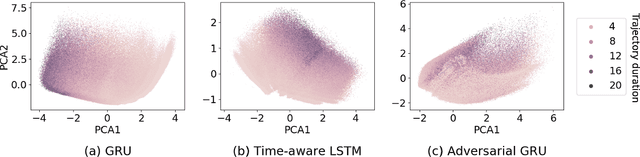
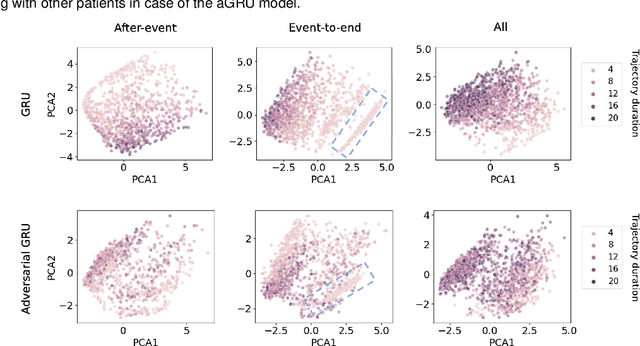
Electronic healthcare records are an important source of information which can be used in patient stratification to discover novel disease phenotypes. However, they can be challenging to work with as data is often sparse and irregularly sampled. One approach to solve these limitations is learning dense embeddings that represent individual patient trajectories using a recurrent neural network autoencoder (RNN-AE). This process can be susceptible to unwanted data biases. We show that patient embeddings and clusters using previously proposed RNN-AE models might be impacted by a trajectory bias, meaning that results are dominated by the amount of data contained in each patients trajectory, instead of clinically relevant details. We investigate this bias on 2 datasets (from different hospitals) and 2 disease areas as well as using different parts of the patient trajectory. Our results using 2 previously published baseline methods indicate a particularly strong bias in case of an event-to-end trajectory. We present a method that can overcome this issue using an adversarial training scheme on top of a RNN-AE. Our results show that our approach can reduce the trajectory bias in all cases.