 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Homogeneous Low-Resolution Face Recognition Method based Correlation Features
Nov 25, 2021
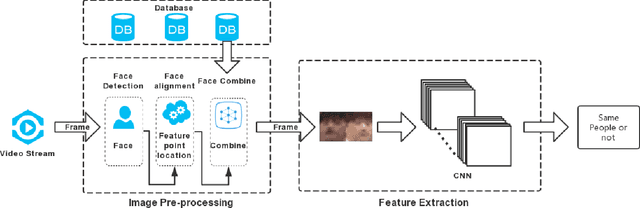

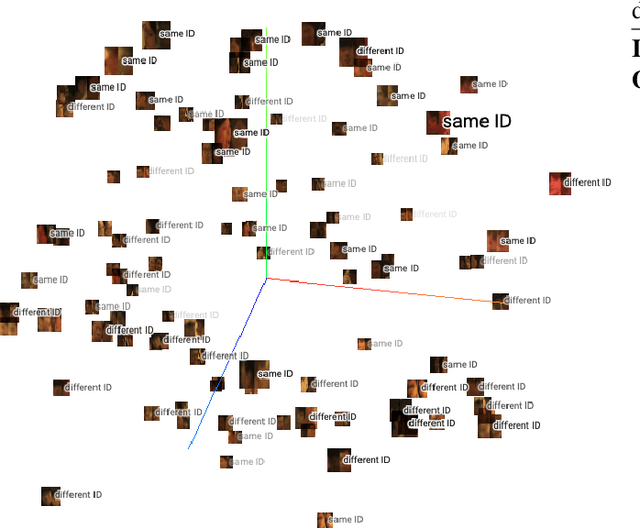
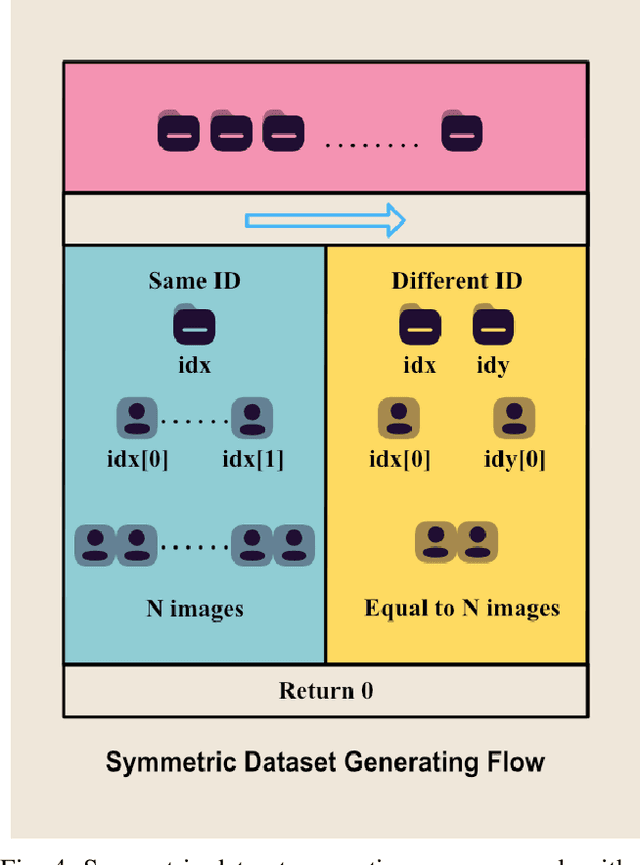
Face recognition technology has been widely adopted in many mission-critical scenarios like means of human identification, controlled admission, and mobile device access, etc. Security surveillance is a typical scenario of face recognition technology. Because the low-resolution feature of surveillance video and images makes it difficult for high-resolution face recognition algorithms to extract effective feature information, Algorithms applied to high-resolution face recognition are difficult to migrate directly to low-resolution situations. As face recognition in security surveillance becomes more important in the era of dense urbanization, it is essential to develop algorithms that are able to provide satisfactory performance in processing the video frames generated by low-resolution surveillance cameras. This paper study on the Correlation Features-based Face Recognition (CoFFaR) method which using for homogeneous low-resolution surveillance videos, the theory, experimental details, and experimental results are elaborated in detail. The experimental results validate the effectiveness of the correlation features method that improves the accuracy of homogeneous face recognition in surveillance security scenarios.
U-shaped Transformer with Frequency-Band Aware Attention for Speech Enhancement
Dec 11, 2021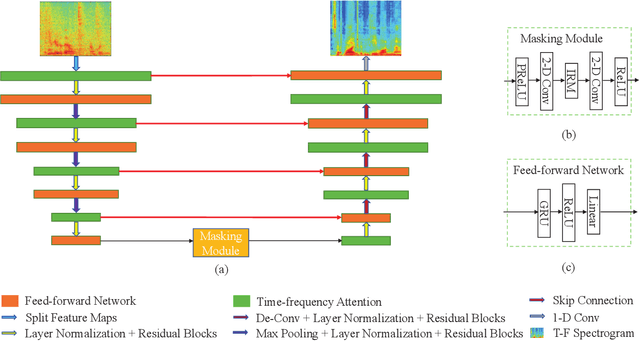
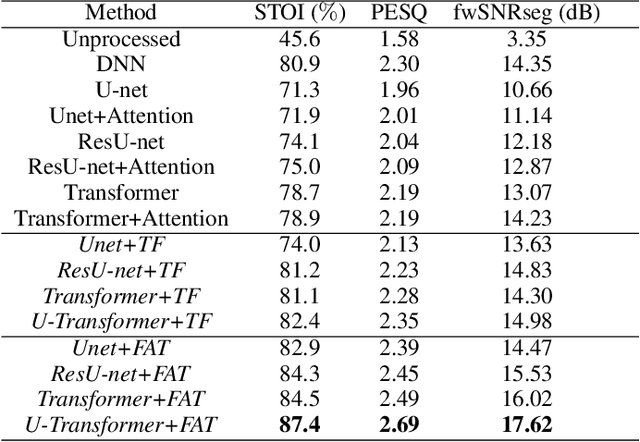
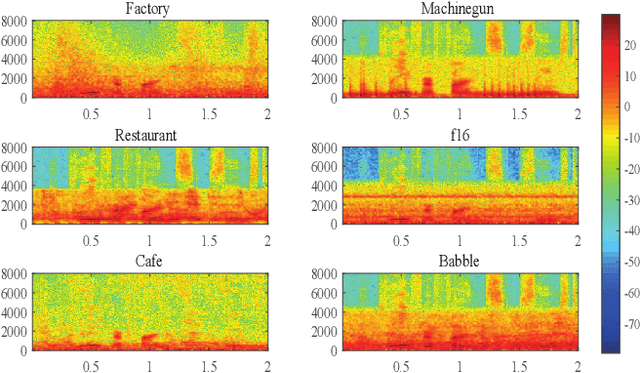
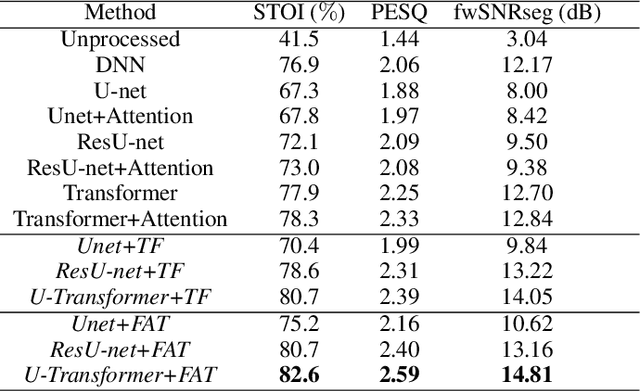
The state-of-the-art speech enhancement has limited performance in speech estimation accuracy. Recently, in deep learning, the Transformer shows the potential to exploit the long-range dependency in speech by self-attention. Therefore, it is introduced in speech enhancement to improve the speech estimation accuracy from a noise mixture. However, to address the computational cost issue in Transformer with self-attention, the axial attention is the option i.e., to split a 2D attention into two 1D attentions. Inspired by the axial attention, in the proposed method we calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps. Moreover, different from the axial attention, the proposed method provides two parallel multi-head attentions for time- and frequency-axis. Furthermore, it is proven in the literature that the lower frequency-band in speech, generally, contains more desired information than the higher frequency-band, in a noise mixture. Therefore, the frequency-band aware attention is proposed i.e., high frequency-band attention (HFA), and low frequency-band attention (LFA). The U-shaped Transformer is also first time introduced in the proposed method to further improve the speech estimation accuracy. The extensive evaluations over four public datasets, confirm the efficacy of the proposed method.
DORA: Distributed Online Risk-Aware Explorer
Sep 29, 2021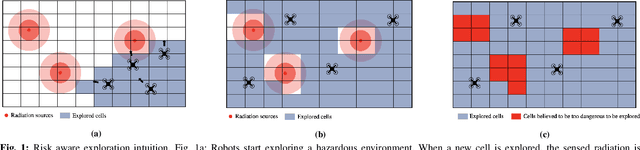
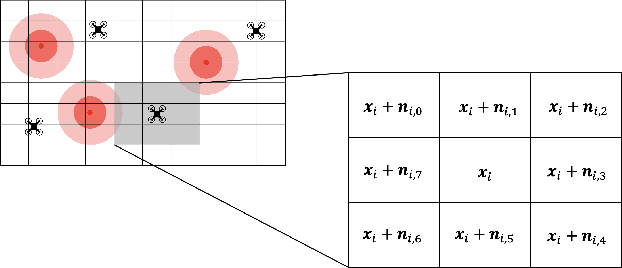

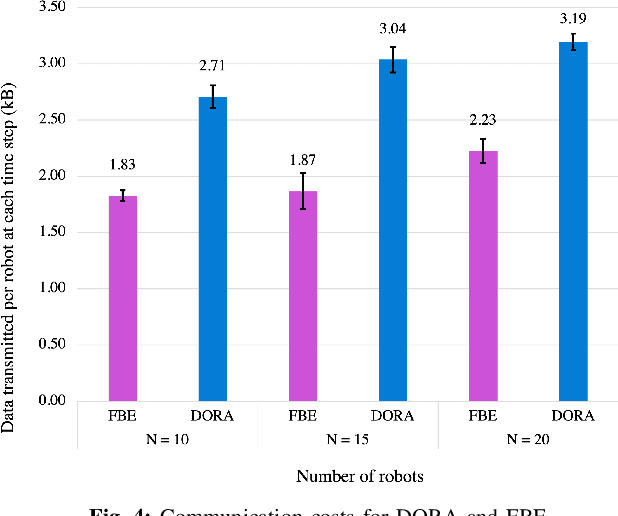
Exploration of unknown environments is an important challenge in the field of robotics. While a single robot can achieve this task alone, evidence suggests it could be accomplished more efficiently by groups of robots, with advantages in terms of terrain coverage as well as robustness to failures. Exploration can be guided through belief maps, which provide probabilistic information about which part of the terrain is interesting to explore (either based on risk management or reward). This process can be centrally coordinated by building a collective belief map on a common server. However, relying on a central processing station creates a communication bottleneck and single point of failure for the system. In this paper, we present Distributed Online Risk-Aware (DORA) Explorer, an exploration system that leverages decentralized information sharing to update a common risk belief map. DORA Explorer allows a group of robots to explore an unknown environment discretized as a 2D grid with obstacles, with high coverage while minimizing exposure to risk, effectively reducing robot failures
Efficient Single Image Super-Resolution Using Dual Path Connections with Multiple Scale Learning
Dec 31, 2021
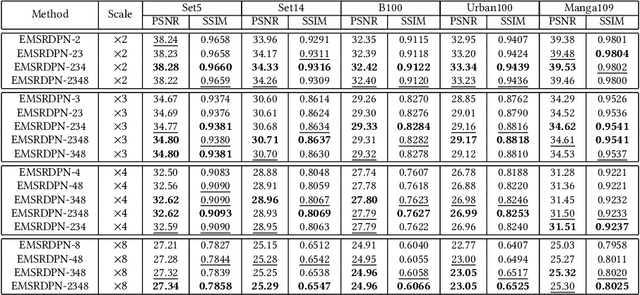
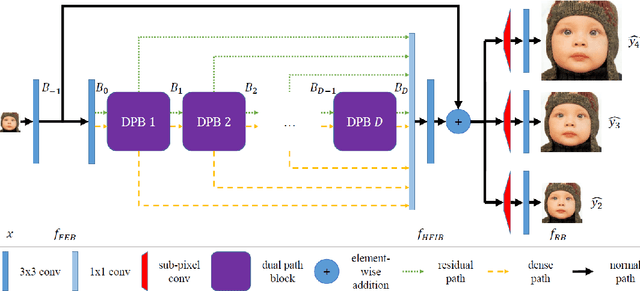
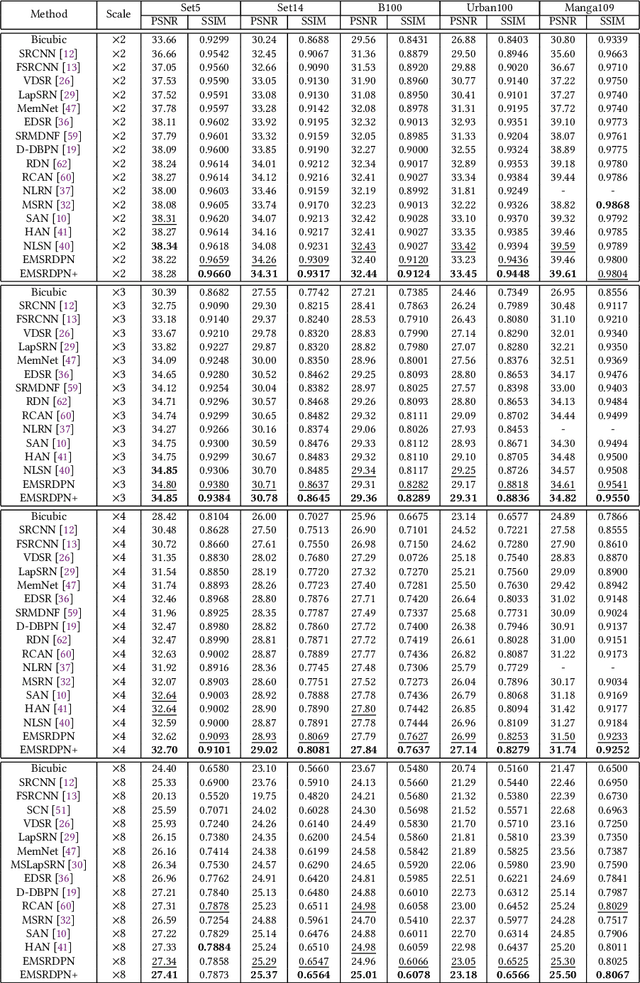
Deep convolutional neural networks have been demonstrated to be effective for SISR in recent years. On the one hand, residual connections and dense connections have been used widely to ease forward information and backward gradient flows to boost performance. However, current methods use residual connections and dense connections separately in most network layers in a sub-optimal way. On the other hand, although various networks and methods have been designed to improve computation efficiency, save parameters, or utilize training data of multiple scale factors for each other to boost performance, it either do super-resolution in HR space to have a high computation cost or can not share parameters between models of different scale factors to save parameters and inference time. To tackle these challenges, we propose an efficient single image super-resolution network using dual path connections with multiple scale learning named as EMSRDPN. By introducing dual path connections inspired by Dual Path Networks into EMSRDPN, it uses residual connections and dense connections in an integrated way in most network layers. Dual path connections have the benefits of both reusing common features of residual connections and exploring new features of dense connections to learn a good representation for SISR. To utilize the feature correlation of multiple scale factors, EMSRDPN shares all network units in LR space between different scale factors to learn shared features and only uses a separate reconstruction unit for each scale factor, which can utilize training data of multiple scale factors to help each other to boost performance, meanwhile which can save parameters and support shared inference for multiple scale factors to improve efficiency. Experiments show EMSRDPN achieves better performance and comparable or even better parameter and inference efficiency over SOTA methods.
Multi-label Classification of Aircraft Heading Changes Using Neural Network to Resolve Conflicts
Sep 18, 2021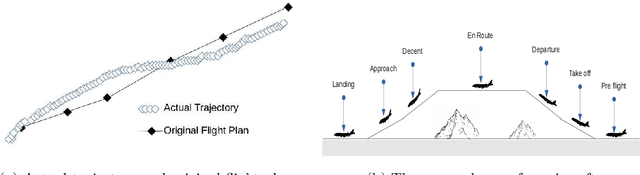

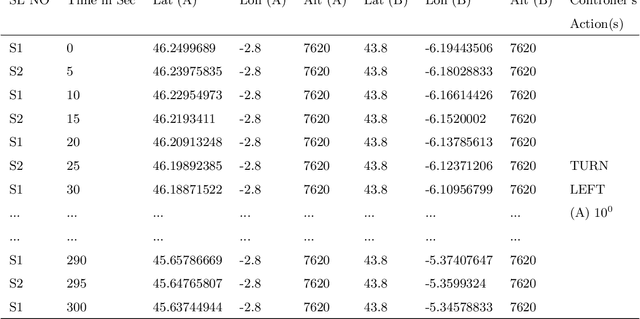
An aircraft conflict occurs when two or more aircraft cross at a certain distance at the same time. Specific air traffic controllers are assigned to solve such conflicts. A controller needs to consider various types of information in order to solve a conflict. The most common and preliminary information is the coordinate position of the involved aircraft. Additionally, a controller has to take into account more information such as flight planning, weather, restricted territory, etc. The most important challenges a controller has to face are: to think about the issues involved and make a decision in a very short time. Due to the increased number of aircraft, it is crucial to reduce the workload of the controllers and help them make quick decisions. A conflict can be solved in many ways, therefore, we consider this problem as a multi-label classification problem. In doing so, we are proposing a multi-label classification model which provides multiple heading advisories for a given conflict. This model we named CRMLnet is based on a novel application of a multi-layer neural network and helps the controllers in their decisions. When compared to other machine learning models, our CRMLnet has achieved the best results with an accuracy of 98.72% and ROC of 0.999. The simulated data set that we have developed and used in our experiments will be delivered to the research community.
Scalable Kernel Learning via the Discriminant Information
Sep 23, 2019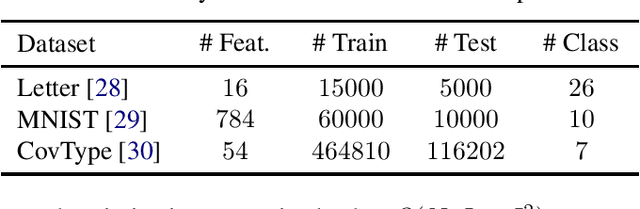
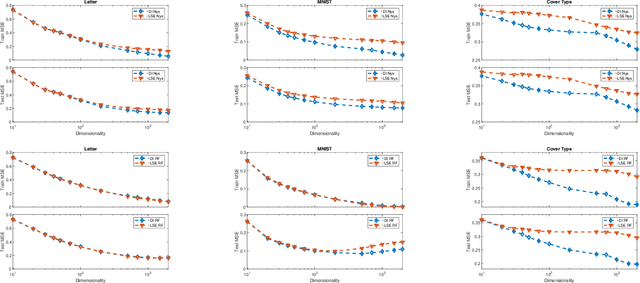
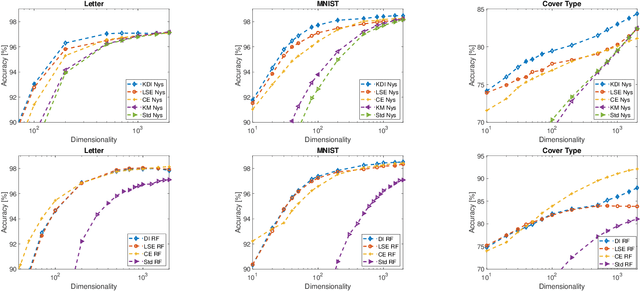
Kernel approximation methods have been popular techniques for scalable kernel based learning. They create explicit, low-dimensional kernel feature maps to deal with the high computational and memory complexity of standard techniques. This work studies a supervised kernel learning methodology to optimize such mappings. We utilize the Discriminant Information criterion, a measure of class separability, which is extended to cover a wider range of kernels. By exploiting the connection of this criterion to the minimum Kernel Ridge Regression loss, we propose a novel training strategy that is especially suitable for stochastic gradient methods, allowing kernel optimization to scale to large datasets. Experimental results on 3 datasets showcase that our techniques can improve optimization and generalization performances over state of the art kernel learning methods.
Controlling Wasserstein distances by Kernel norms with application to Compressive Statistical Learning
Dec 01, 2021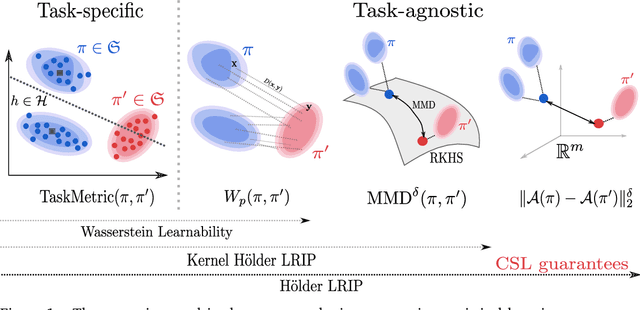
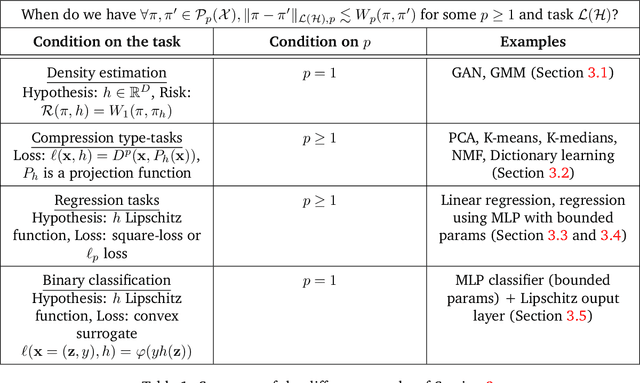
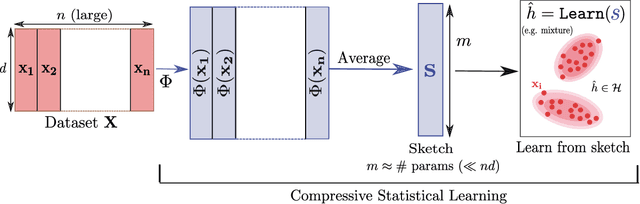

Comparing probability distributions is at the crux of many machine learning algorithms. Maximum Mean Discrepancies (MMD) and Optimal Transport distances (OT) are two classes of distances between probability measures that have attracted abundant attention in past years. This paper establishes some conditions under which the Wasserstein distance can be controlled by MMD norms. Our work is motivated by the compressive statistical learning (CSL) theory, a general framework for resource-efficient large scale learning in which the training data is summarized in a single vector (called sketch) that captures the information relevant to the considered learning task. Inspired by existing results in CSL, we introduce the H\"older Lower Restricted Isometric Property (H\"older LRIP) and show that this property comes with interesting guarantees for compressive statistical learning. Based on the relations between the MMD and the Wasserstein distance, we provide guarantees for compressive statistical learning by introducing and studying the concept of Wasserstein learnability of the learning task, that is when some task-specific metric between probability distributions can be bounded by a Wasserstein distance.
Astrocytes mediate analogous memory in a multi-layer neuron-astrocytic network
Aug 31, 2021
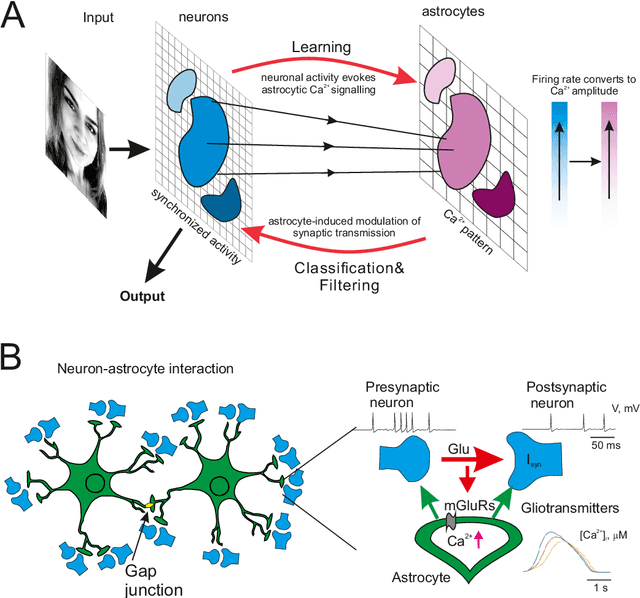


Modeling the neuronal processes underlying short-term working memory remains the focus of many theoretical studies in neuroscience. Here we propose a mathematical model of spiking neuron network (SNN) demonstrating how a piece of information can be maintained as a robust activity pattern for several seconds then completely disappear if no other stimuli come. Such short-term memory traces are preserved due to the activation of astrocytes accompanying the SNN. The astrocytes exhibit calcium transients at a time scale of seconds. These transients further modulate the efficiency of synaptic transmission and, hence, the firing rate of neighboring neurons at diverse timescales through gliotransmitter release. We show how such transients continuously encode frequencies of neuronal discharges and provide robust short-term storage of analogous information. This kind of short-term memory can keep operative information for seconds, then completely forget it to avoid overlapping with forthcoming patterns. The SNN is inter-connected with the astrocytic layer by local inter-cellular diffusive connections. The astrocytes are activated only when the neighboring neurons fire quite synchronously, e.g. when an information pattern is loaded. For illustration, we took greyscale photos of people's faces where the grey level encoded the level of applied current stimulating the neurons. The astrocyte feedback modulates (facilitates) synaptic transmission by varying the frequency of neuronal firing. We show how arbitrary patterns can be loaded, then stored for a certain interval of time, and retrieved if the appropriate clue pattern is applied to the input.
Unsupervised Domain Adaptation for Semantic Image Segmentation: a Comprehensive Survey
Dec 06, 2021
Semantic segmentation plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. Yet, the state-of-the-art models rely on large amount of annotated samples, which are more expensive to obtain than in tasks such as image classification. Since unlabelled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation reached a broad success within the semantic segmentation community. This survey is an effort to summarize five years of this incredibly rapidly growing field, which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. We present the most important semantic segmentation methods; we provide a comprehensive survey on domain adaptation techniques for semantic segmentation; we unveil newer trends such as multi-domain learning, domain generalization, test-time adaptation or source-free domain adaptation; we conclude this survey by describing datasets and benchmarks most widely used in semantic segmentation research. We hope that this survey will provide researchers across academia and industry with a comprehensive reference guide and will help them in fostering new research directions in the field.
Joint speaker diarisation and tracking in switching state-space model
Sep 23, 2021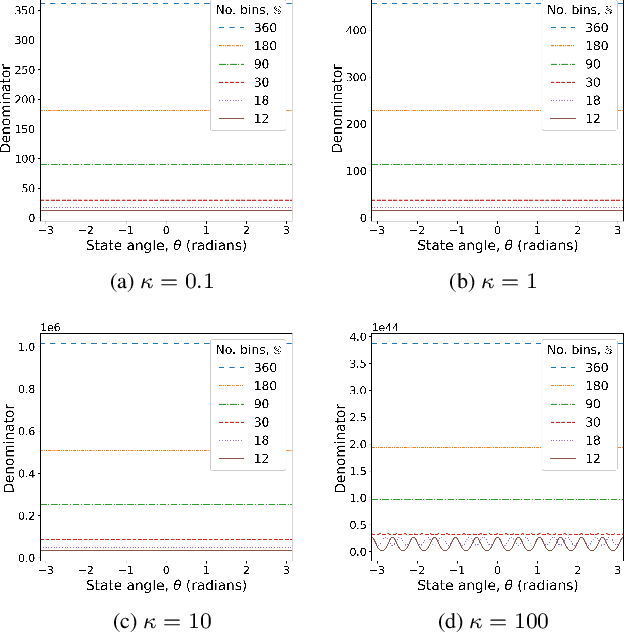

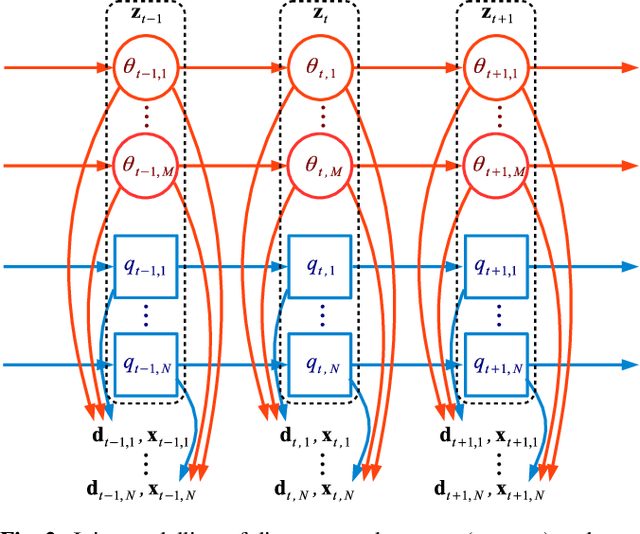
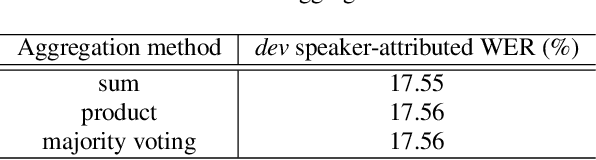
Speakers may move around while diarisation is being performed. When a microphone array is used, the instantaneous locations of where the sounds originated from can be estimated, and previous investigations have shown that such information can be complementary to speaker embeddings in the diarisation task. However, these approaches often assume that speakers are fairly stationary throughout a meeting. This paper relaxes this assumption, by proposing to explicitly track the movements of speakers while jointly performing diarisation within a unified model. A state-space model is proposed, where the hidden state expresses the identity of the current active speaker and the predicted locations of all speakers. The model is implemented as a particle filter. Experiments on a Microsoft rich meeting transcription task show that the proposed joint location tracking and diarisation approach is able to perform comparably with other methods that use location information.