 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Open Natural Language Processing Development Framework for EHR-based Clinical Research: A case demonstration using the National COVID Cohort Collaborative (N3C)
Oct 20, 2021
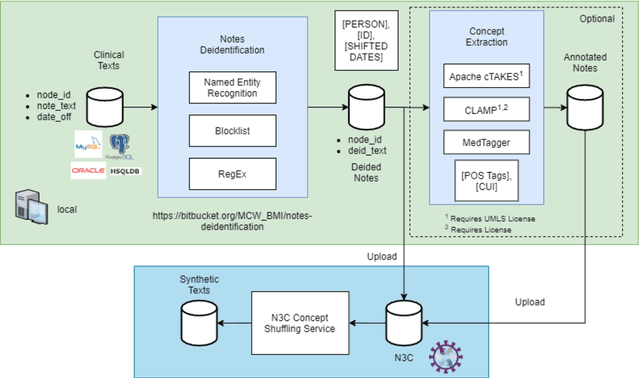

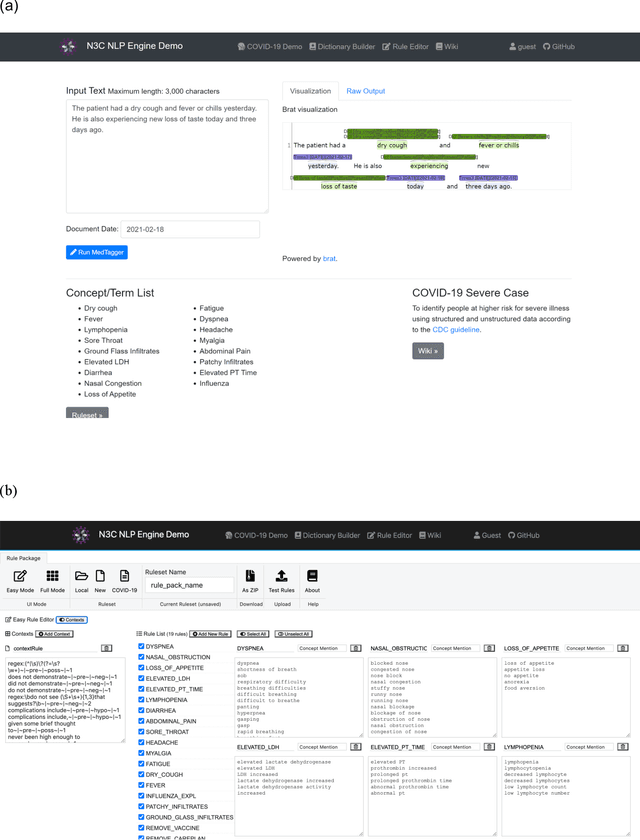
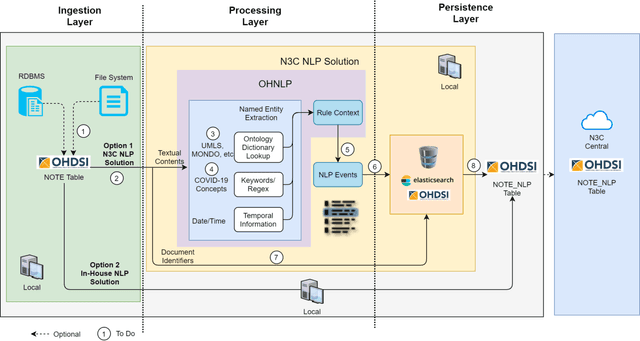
While we pay attention to the latest advances in clinical natural language processing (NLP), we can notice some resistance in the clinical and translational research community to adopt NLP models due to limited transparency, Interpretability and usability. Built upon our previous work, in this study, we proposed an open natural language processing development framework and evaluated it through the implementation of NLP algorithms for the National COVID Cohort Collaborative (N3C). Based on the interests in information extraction from COVID-19 related clinical notes, our work includes 1) an open data annotation process using COVID-19 signs and symptoms as the use case, 2) a community-driven ruleset composing platform, and 3) a synthetic text data generation workflow to generate texts for information extraction tasks without involving human subjects. The generated corpora derived out of the texts from multiple intuitions and gold standard annotation are tested on a single institution's rule set has the performances in F1 score of 0.876, 0.706 and 0.694, respectively. The study as a consortium effort of the N3C NLP subgroup demonstrates the feasibility of creating a federated NLP algorithm development and benchmarking platform to enhance multi-institution clinical NLP study.
Tipping the Scales: A Corpus-Based Reconstruction of Adjective Scales in the McGill Pain Questionnaire
Oct 06, 2021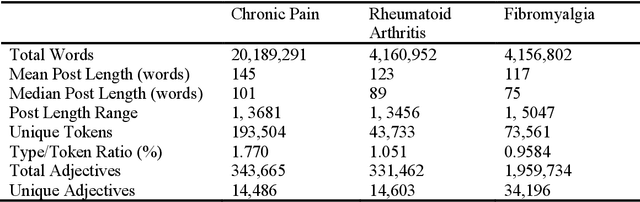
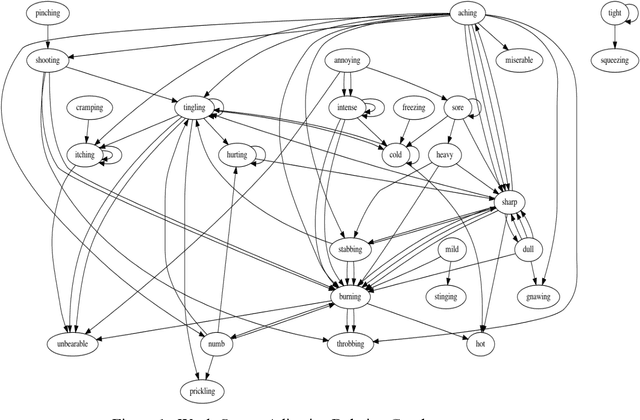

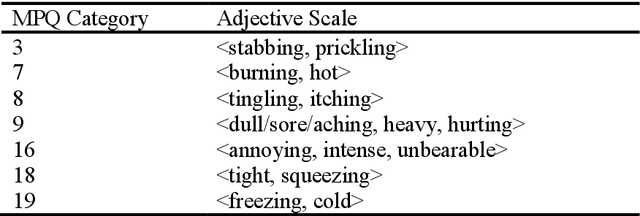
Modern medical diagnosis relies on precise pain assessment tools in translating clinical information from patient to physician. The McGill Pain Questionnaire (MPQ) is a clinical pain assessment technique that utilizes 78 adjectives of different intensities in 20 different categories to quantity a patient's pain. The questionnaire's efficacy depends on a predictable pattern of adjective use by patients experiencing pain. In this study, I recreate the MPQ's adjective intensity orderings using data gathered from patient forums and modern NLP techniques. I extract adjective intensity relationships by searching for key linguistic contexts, and then combine the relationship information to form robust adjective scales. Of 17 adjective relationships predicted by this research, only 4 diverge from the MPQ's orderings, which is statistically significant at the 0.1 alpha level. The results suggest predictable patterns of adjective use by people experiencing pain, but call into question the MPQ's categories for grouping adjectives.
Assessment of Amazon Comprehend Medical: Medication Information Extraction
Feb 02, 2020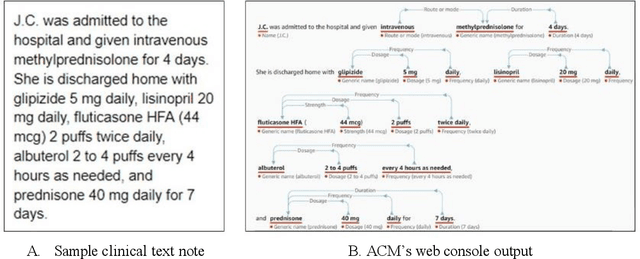
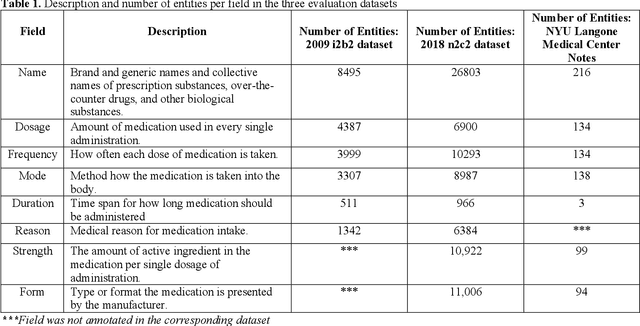

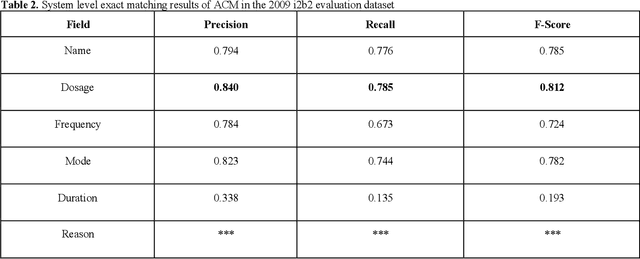
In November 27, 2018, Amazon Web Services (AWS) released Amazon Comprehend Medical (ACM), a deep learning based system that automatically extracts clinical concepts (which include anatomy, medical conditions, protected health information (PH)I, test names, treatment names, and medical procedures, and medications) from clinical text notes. Uptake and trust in any new data product relies on independent validation across benchmark datasets and tools to establish and confirm expected quality of results. This work focuses on the medication extraction task, and particularly, ACM was evaluated using the official test sets from the 2009 i2b2 Medication Extraction Challenge and 2018 n2c2 Track 2: Adverse Drug Events and Medication Extraction in EHRs. Overall, ACM achieved F-scores of 0.768 and 0.828. These scores ranked the lowest when compared to the three best systems in the respective challenges. To further establish the generalizability of its medication extraction performance, a set of random internal clinical text notes from NYU Langone Medical Center were also included in this work. And in this corpus, ACM garnered an F-score of 0.753.
Analysis and Evaluation of Kinect-based Action Recognition Algorithms
Dec 16, 2021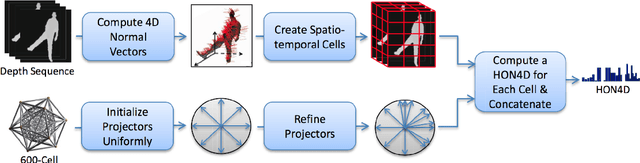

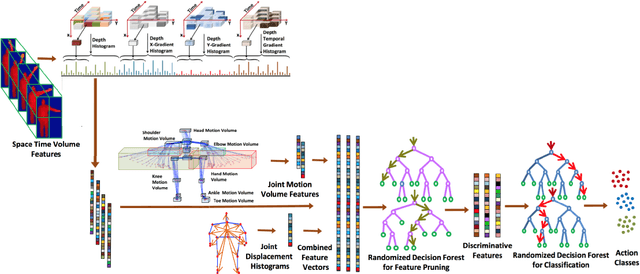

Human action recognition still exists many challenging problems such as different viewpoints, occlusion, lighting conditions, human body size and the speed of action execution, although it has been widely used in different areas. To tackle these challenges, the Kinect depth sensor has been developed to record real time depth sequences, which are insensitive to the color of human clothes and illumination conditions. Many methods on recognizing human action have been reported in the literature such as HON4D, HOPC, RBD and HDG, which use the 4D surface normals, pointclouds, skeleton-based model and depth gradients respectively to capture discriminative information from depth videos or skeleton data. In this research project, the performance of four aforementioned algorithms will be analyzed and evaluated using five benchmark datasets, which cover challenging issues such as noise, change of viewpoints, background clutters and occlusions. We also implemented and improved the HDG algorithm, and applied it in cross-view action recognition using the UWA3D Multiview Activity dataset. Moreover, we used different combinations of individual feature vectors in HDG for performance evaluation. The experimental results show that our improvement of HDG outperforms other three state-of-the-art algorithms for cross-view action recognition.
Modeling Endorsement for Multi-Document Abstractive Summarization
Oct 15, 2021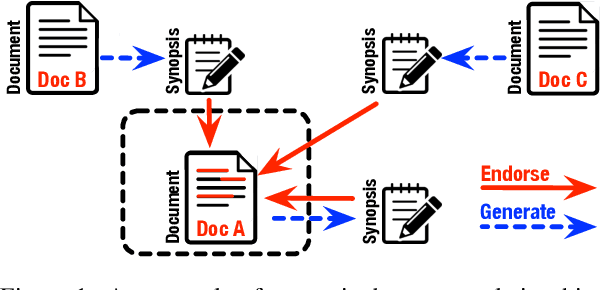
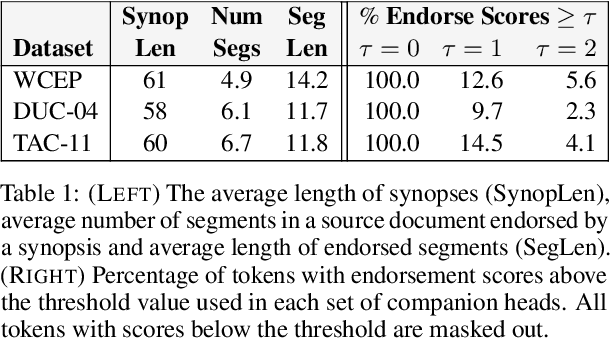
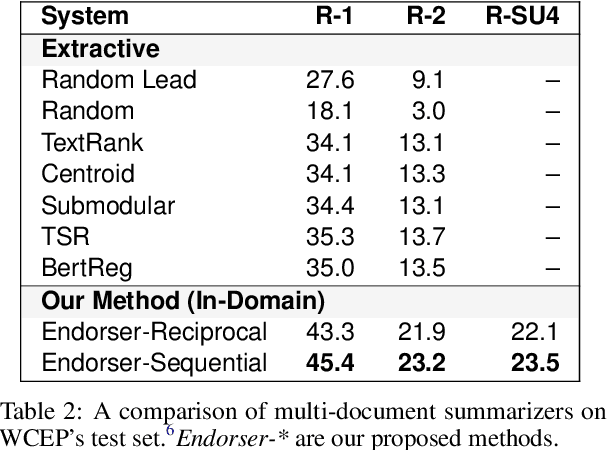
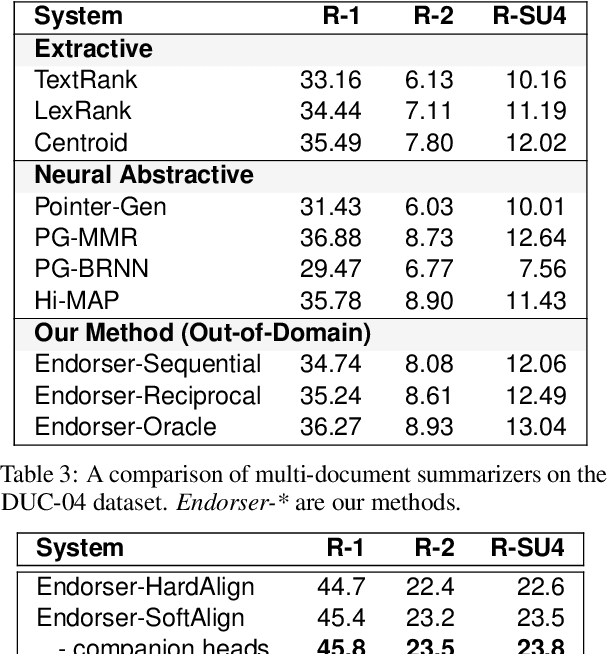
A crucial difference between single- and multi-document summarization is how salient content manifests itself in the document(s). While such content may appear at the beginning of a single document, essential information is frequently reiterated in a set of documents related to a particular topic, resulting in an endorsement effect that increases information salience. In this paper, we model the cross-document endorsement effect and its utilization in multiple document summarization. Our method generates a synopsis from each document, which serves as an endorser to identify salient content from other documents. Strongly endorsed text segments are used to enrich a neural encoder-decoder model to consolidate them into an abstractive summary. The method has a great potential to learn from fewer examples to identify salient content, which alleviates the need for costly retraining when the set of documents is dynamically adjusted. Through extensive experiments on benchmark multi-document summarization datasets, we demonstrate the effectiveness of our proposed method over strong published baselines. Finally, we shed light on future research directions and discuss broader challenges of this task using a case study.
Digital Audio Processing Tools for Music Corpus Studies
Nov 09, 2021
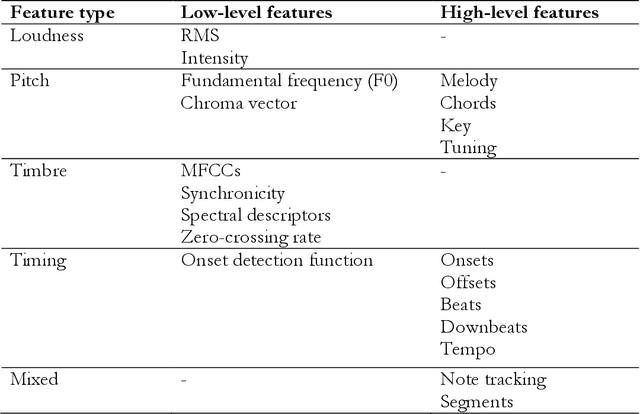
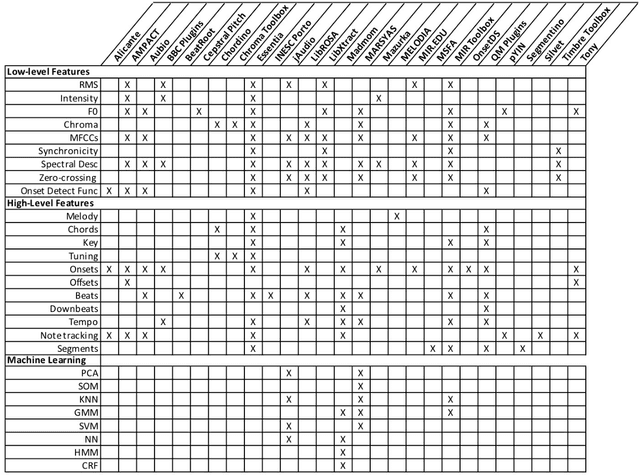
Digital audio processing tools offer music researchers the opportunity to examine both non-notated music and music as performance. This chapter summarises the types of information that can be extracted from audio as well as currently available audio tools for music corpus studies. The survey of extraction methods includes both a primer on signal processing and background theory on audio feature extraction. The survey of audio tools focuses on widely used tools, including both those with a graphical user interface, namely Audacity and Sonic Visualiser, and code-based tools written in the C/C++, Java, MATLAB, and Python computer programming languages.
FIgLib & SmokeyNet: Dataset and Deep Learning Model for Real-Time Wildland Fire Smoke Detection
Dec 16, 2021
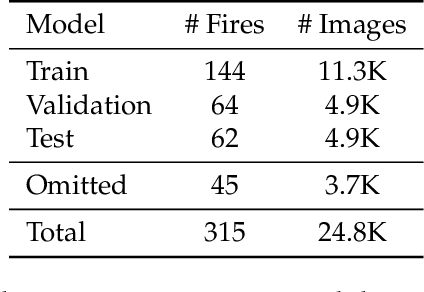
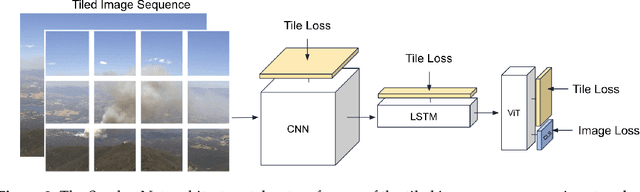
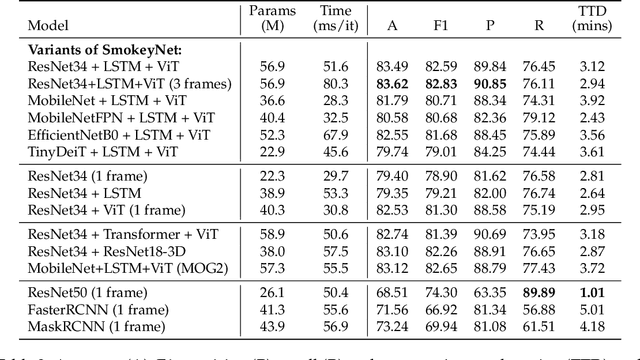
The size and frequency of wildland fires in the western United States have dramatically increased in recent years. On high fire-risk days, a small fire ignition can rapidly grow and get out of control. Early detection of fire ignitions from initial smoke can assist the response to such fires before they become difficult to manage. Past deep learning approaches for wildfire smoke detection have suffered from small or unreliable datasets that make it difficult to extrapolate performance to real-world scenarios. In this work, we present the Fire Ignition Library (FIgLib), a publicly-available dataset of nearly 25,000 labeled wildfire smoke images as seen from fixed-view cameras deployed in Southern California. We also introduce SmokeyNet, a novel deep learning architecture using spatio-temporal information from camera imagery for real-time wildfire smoke detection. When trained on the FIgLib dataset, SmokeyNet outperforms comparable baselines and rivals human performance. We hope that the availability of the FIgLib dataset and the SmokeyNet architecture will inspire further research into deep learning methods for wildfire smoke detection, leading to automated notification systems that reduce the time to wildfire response.
The Tensor Brain: A Unified Theory of Perception, Memory and Semantic Decoding
Sep 27, 2021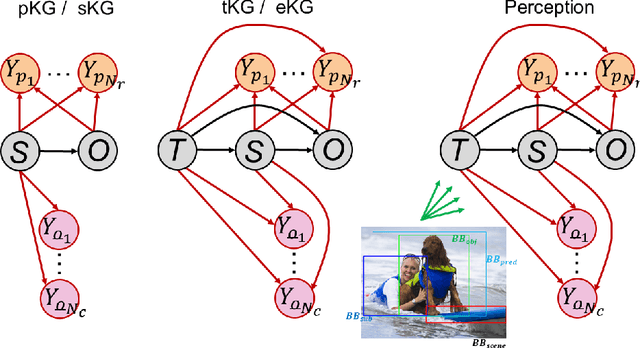

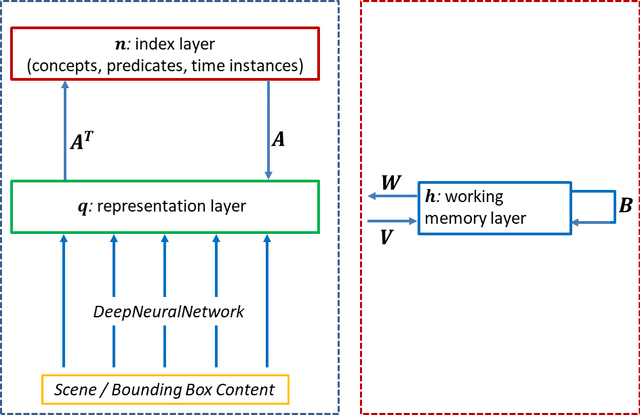
We present a unified computational theory of perception and memory. In our model, perception, episodic memory, and semantic memory are realized by different functional and operational modes of the oscillating interactions between an index layer and a representation layer in a bilayer tensor network (BTN). The memoryless semantic {representation layer} broadcasts information. In cognitive neuroscience, it would be the "mental canvas", or the "global workspace" and reflects the cognitive brain state. The symbolic {index layer} represents concepts and past episodes, whose semantic embeddings are implemented in the connection weights between both layers. In addition, we propose a {working memory layer} as a processing center and information buffer. Episodic and semantic memory realize memory-based reasoning, i.e., the recall of relevant past information to enrich perception, and are personalized to an agent's current state, as well as to an agent's unique memories. Episodic memory stores and retrieves past observations and provides provenance and context. Recent episodic memory enriches perception by the retrieval of perceptual experiences, which provide the agent with a sense about the here and now: to understand its own state, and the world's semantic state in general, the agent needs to know what happened recently, in recent scenes, and on recently perceived entities. Remote episodic memory retrieves relevant past experiences, contributes to our conscious self, and, together with semantic memory, to a large degree defines who we are as individuals.
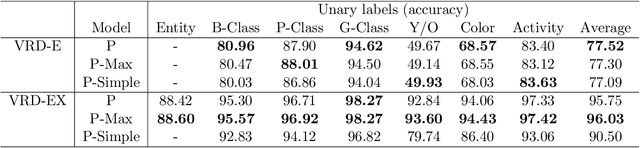
Next Day Wildfire Spread: A Machine Learning Data Set to Predict Wildfire Spreading from Remote-Sensing Data
Dec 04, 2021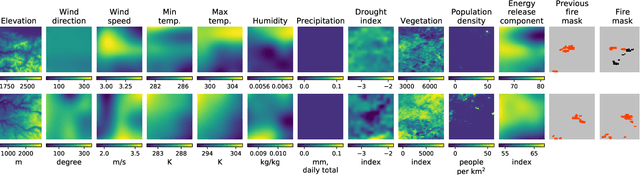
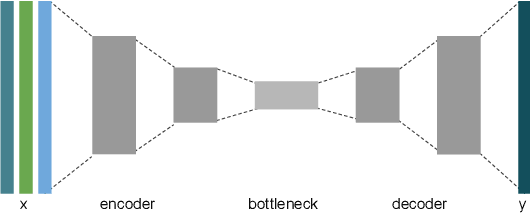
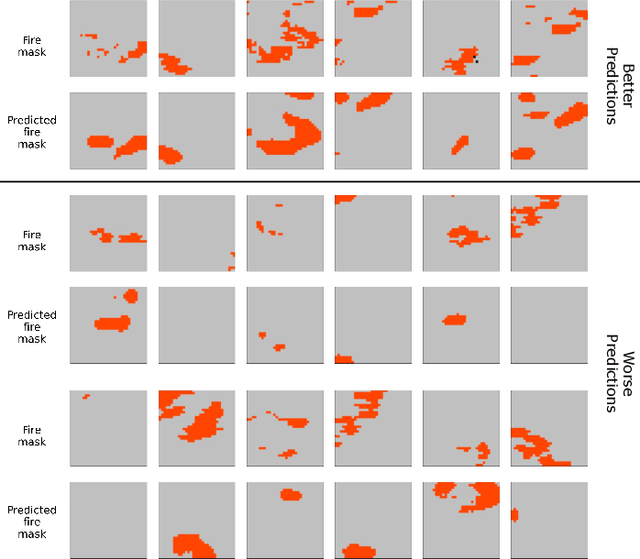
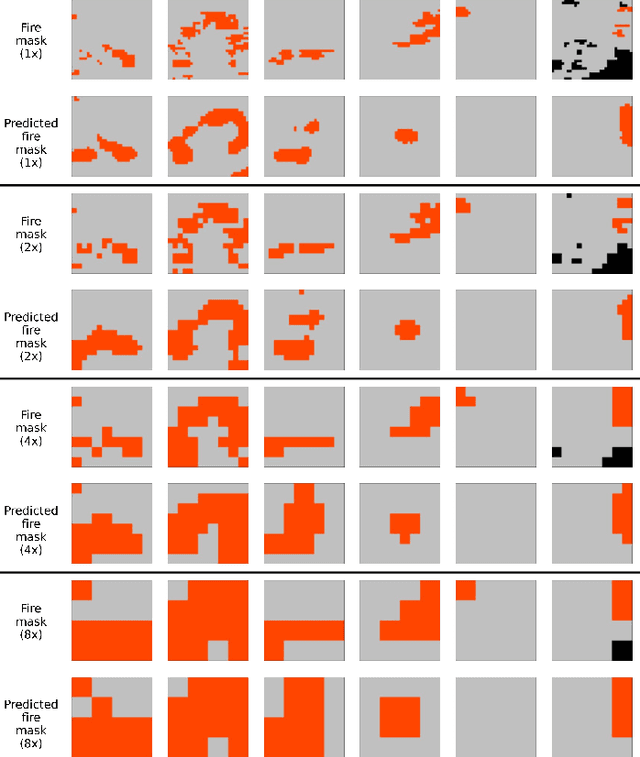
Predicting wildfire spread is critical for land management and disaster preparedness. To this end, we present `Next Day Wildfire Spread,' a curated, large-scale, multivariate data set of historical wildfires aggregating nearly a decade of remote-sensing data across the United States. In contrast to existing fire data sets based on Earth observation satellites, our data set combines 2D fire data with multiple explanatory variables (e.g., topography, vegetation, weather, drought index, population density) aligned over 2D regions, providing a feature-rich data set for machine learning. To demonstrate the usefulness of this data set, we implement a convolutional autoencoder that takes advantage of the spatial information of this data to predict wildfire spread. We compare the performance of the neural network with other machine learning models: logistic regression and random forest. This data set can be used as a benchmark for developing wildfire propagation models based on remote sensing data for a lead time of one day.
Per-Link Parallel and Distributed Hybrid Beamforming for Multi-Cell Massive MIMO Millimeter Wave Full Duplex
Dec 25, 2021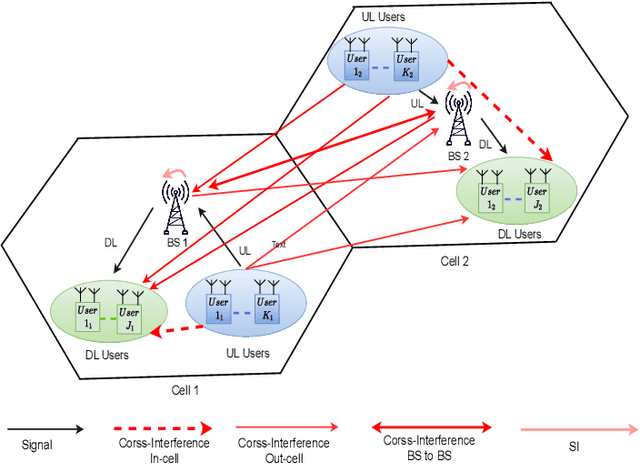
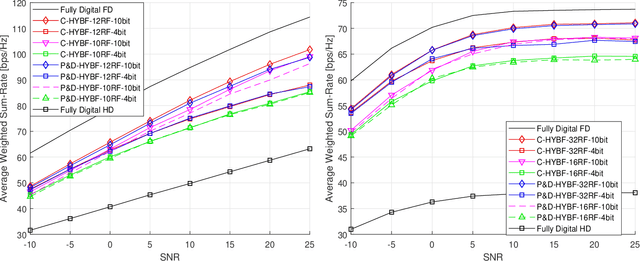
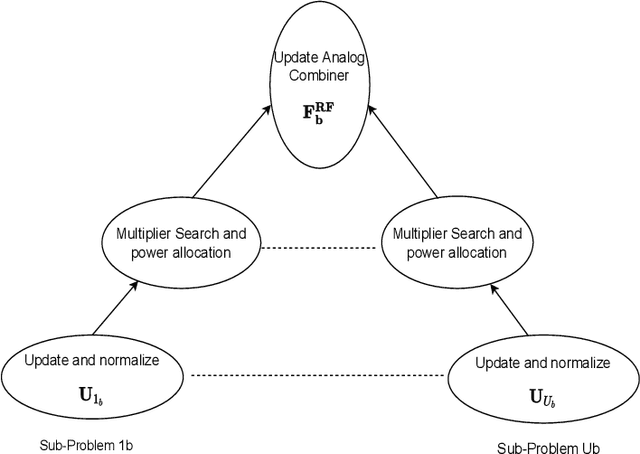
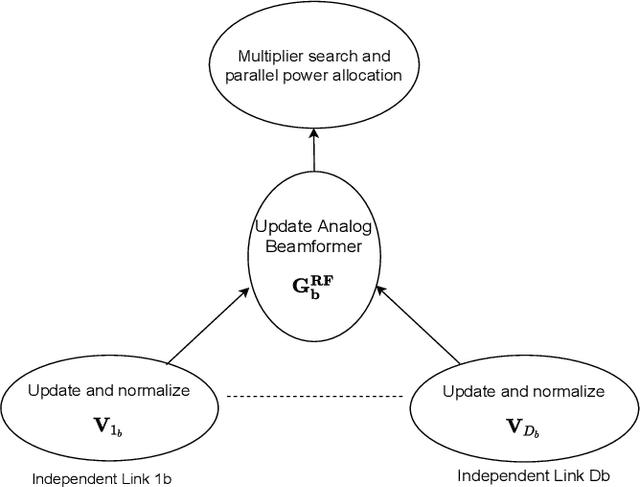
This paper presents two hybrid beamforming (HYBF) designs for a multi-cell massive multiple-input-multiple-output (mMIMO) millimeter (mmWave) full duplex (FD) system under limited dynamic range (LDR). Firstly, we present a centralized HYBF (C-HYBF) scheme based on alternating optimization. In general, the complexity of C-HYBF schemes scales quadratically as a function of the number of users and cells, which may limit their scalability. Another major drawback is that significant communication overhead is required to transfer complete channel state information (CSI) to the central node every channel coherence time. The central node also requires very high computational power to jointly optimize many variables for the uplink (UL) and downlink (DL) users. To overcome these drawbacks, we present a very low-complexity and scalable cooperative per-link parallel and distributed (P$\&$D)-HYBF scheme. It allows each FD base station (BS) to update the beamformers for its users independently in parallel on different computational processors. Its complexity scales only linearly as the network size grows, making it desirable for the next generation of large and dense mmWave FD networks. Simulation results show that both designs significantly outperform the fully digital half duplex (HD) system with only a few radio-frequency (RF) chains, achieve similar performance, and the P$\&$D-HYBF design requires considerably less execution time.