 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Denoised Internal Models: a Brain-Inspired Autoencoder against Adversarial Attacks
Nov 21, 2021
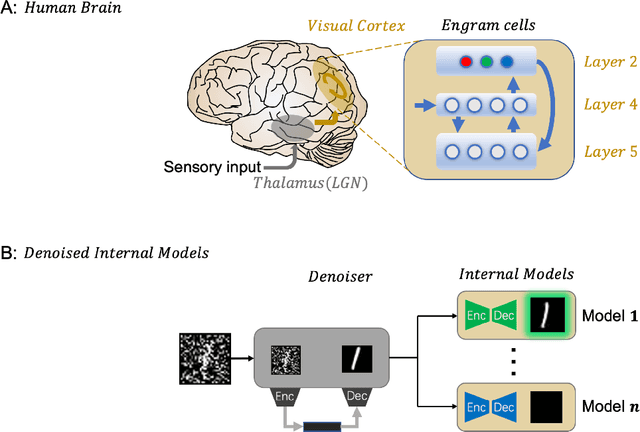
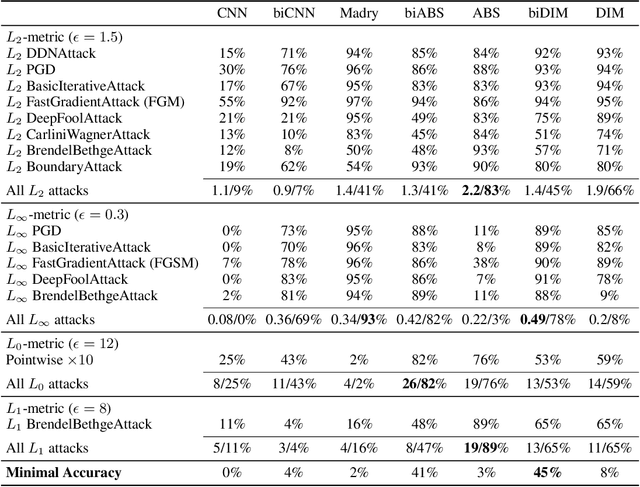
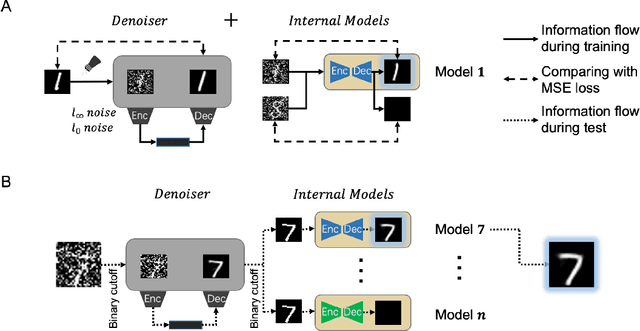
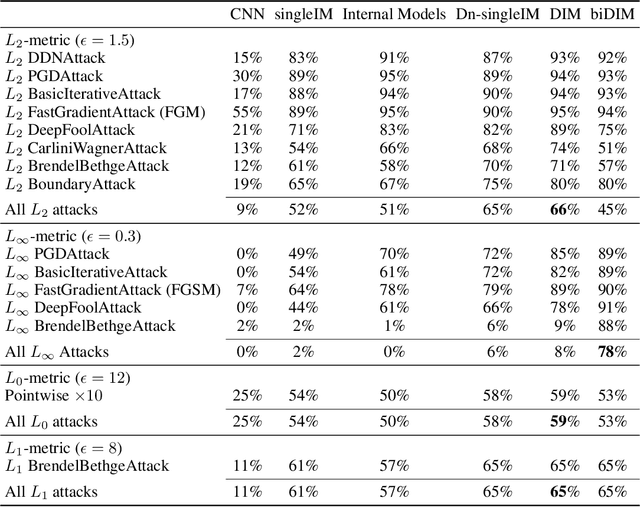
Despite its great success, deep learning severely suffers from robustness; that is, deep neural networks are very vulnerable to adversarial attacks, even the simplest ones. Inspired by recent advances in brain science, we propose the Denoised Internal Models (DIM), a novel generative autoencoder-based model to tackle this challenge. Simulating the pipeline in the human brain for visual signal processing, DIM adopts a two-stage approach. In the first stage, DIM uses a denoiser to reduce the noise and the dimensions of inputs, reflecting the information pre-processing in the thalamus. Inspired from the sparse coding of memory-related traces in the primary visual cortex, the second stage produces a set of internal models, one for each category. We evaluate DIM over 42 adversarial attacks, showing that DIM effectively defenses against all the attacks and outperforms the SOTA on the overall robustness.
Improved YOLOv5 network for real-time multi-scale traffic sign detection
Dec 23, 2021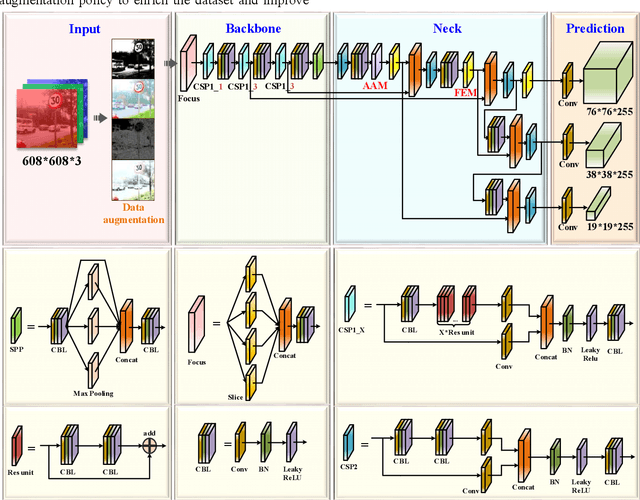
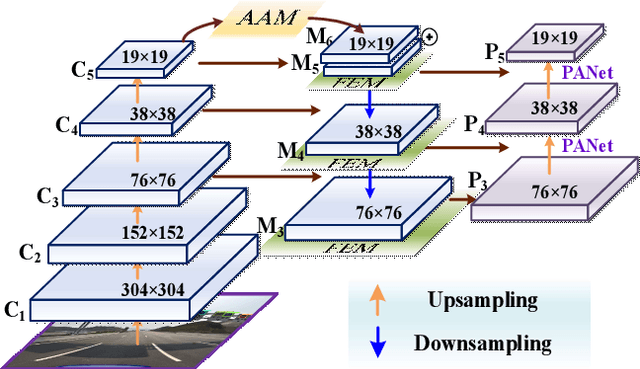

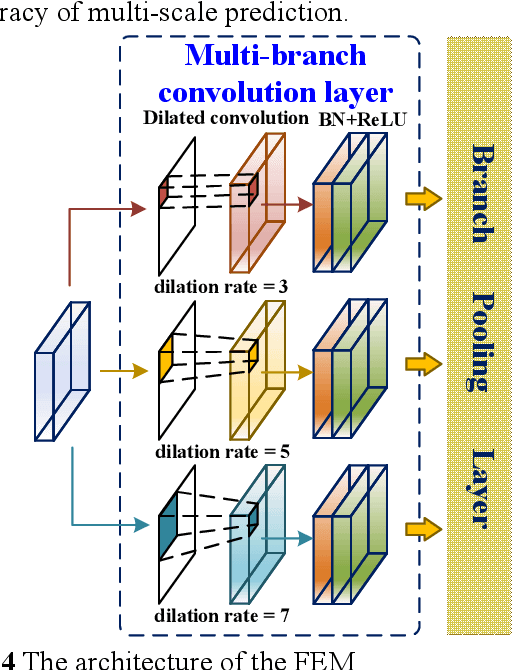
Traffic sign detection is a challenging task for the unmanned driving system, especially for the detection of multi-scale targets and the real-time problem of detection. In the traffic sign detection process, the scale of the targets changes greatly, which will have a certain impact on the detection accuracy. Feature pyramid is widely used to solve this problem but it might break the feature consistency across different scales of traffic signs. Moreover, in practical application, it is difficult for common methods to improve the detection accuracy of multi-scale traffic signs while ensuring real-time detection. In this paper, we propose an improved feature pyramid model, named AF-FPN, which utilizes the adaptive attention module (AAM) and feature enhancement module (FEM) to reduce the information loss in the process of feature map generation and enhance the representation ability of the feature pyramid. We replaced the original feature pyramid network in YOLOv5 with AF-FPN, which improves the detection performance for multi-scale targets of the YOLOv5 network under the premise of ensuring real-time detection. Furthermore, a new automatic learning data augmentation method is proposed to enrich the dataset and improve the robustness of the model to make it more suitable for practical scenarios. Extensive experimental results on the Tsinghua-Tencent 100K (TT100K) dataset demonstrate the effectiveness and superiority of the proposed method when compared with several state-of-the-art methods.
TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation
Oct 18, 2021
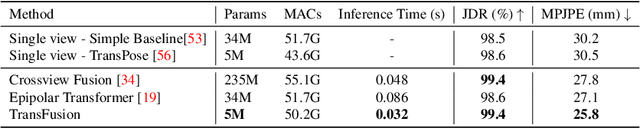
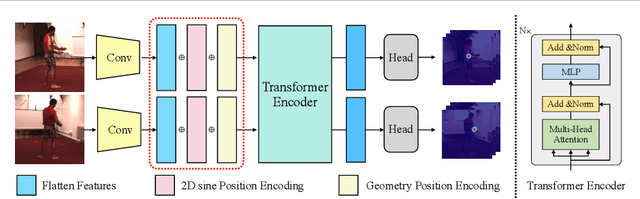

Estimating the 2D human poses in each view is typically the first step in calibrated multi-view 3D pose estimation. But the performance of 2D pose detectors suffers from challenging situations such as occlusions and oblique viewing angles. To address these challenges, previous works derive point-to-point correspondences between different views from epipolar geometry and utilize the correspondences to merge prediction heatmaps or feature representations. Instead of post-prediction merge/calibration, here we introduce a transformer framework for multi-view 3D pose estimation, aiming at directly improving individual 2D predictors by integrating information from different views. Inspired by previous multi-modal transformers, we design a unified transformer architecture, named TransFusion, to fuse cues from both current views and neighboring views. Moreover, we propose the concept of epipolar field to encode 3D positional information into the transformer model. The 3D position encoding guided by the epipolar field provides an efficient way of encoding correspondences between pixels of different views. Experiments on Human 3.6M and Ski-Pose show that our method is more efficient and has consistent improvements compared to other fusion methods. Specifically, we achieve 25.8 mm MPJPE on Human 3.6M with only 5M parameters on 256 x 256 resolution.
An Autonomous Self-Incremental Learning Approach for Detection of Cyber Attacks on Unmanned Aerial Vehicles (UAVs)
Dec 18, 2021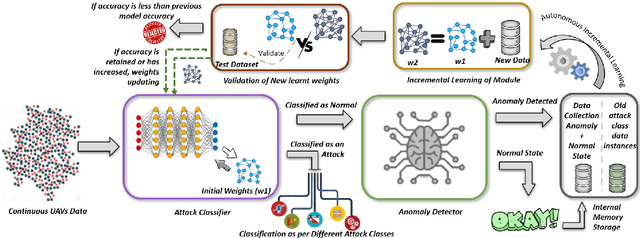
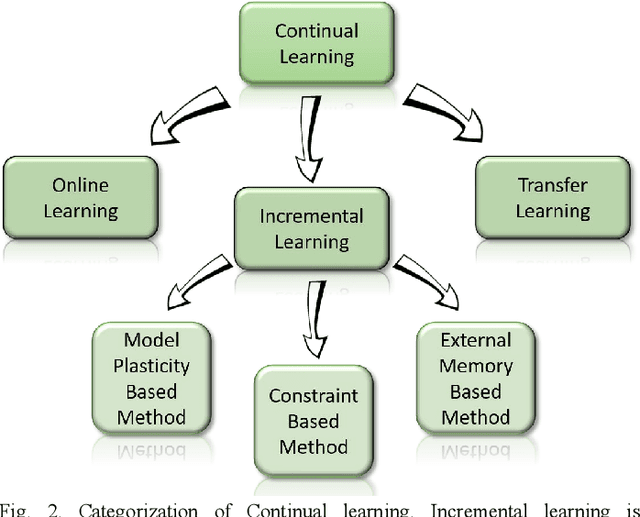
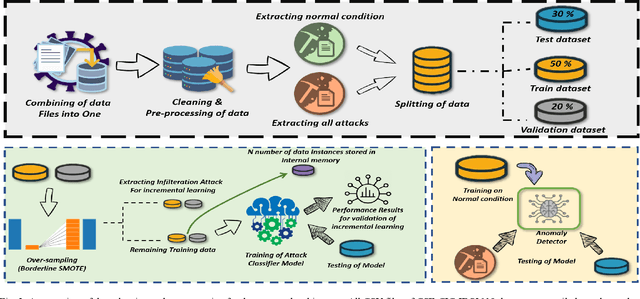
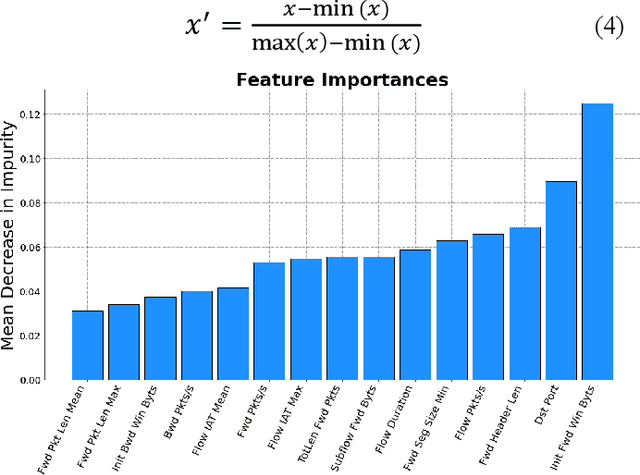
As the technological advancement and capabilities of automated systems have increased drastically, the usage of unmanned aerial vehicles for performing human-dependent tasks without human indulgence has also spiked. Since unmanned aerial vehicles are heavily dependent on Information and Communication Technology, they are highly prone to cyber-attacks. With time more advanced and new attacks are being developed and employed. However, the current Intrusion detection system lacks detection and classification of new and unknown attacks. Therefore, for having an autonomous and reliable operation of unmanned aerial vehicles, more robust and automated cyber detection and protection schemes are needed. To address this, we have proposed an autonomous self-incremental learning architecture, capable of detecting known and unknown cyber-attacks on its own without any human interference. In our approach, we have combined signature-based detection along with anomaly detection in such a way that the signature-based detector autonomously updates its attack classes with the help of an anomaly detector. To achieve this, we have implemented an incremental learning approach, updating our model to incorporate new classes without forgetting the old ones. To validate the applicability and effectiveness of our proposed architecture, we have implemented it in a trial scenario and then compared it with the traditional offline learning approach. Moreover, our anomaly-based detector has achieved a 100% detection rate for attacks.
Improving Spectral Graph Convolution for Learning Graph-level Representation
Dec 14, 2021
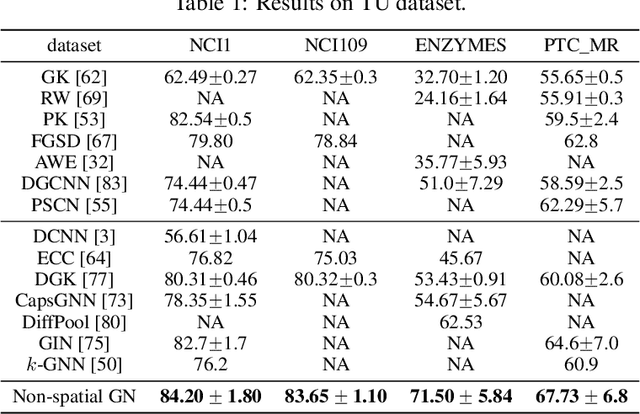
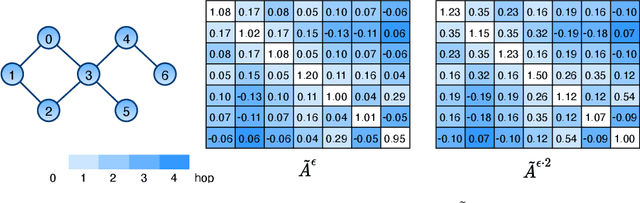
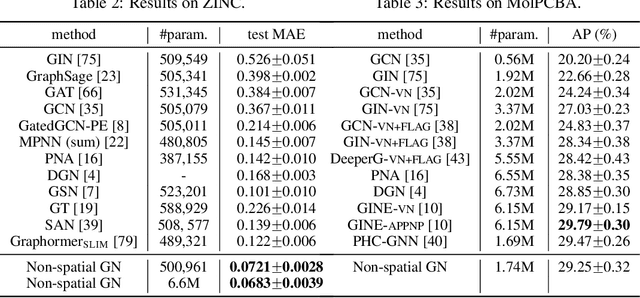
From the original theoretically well-defined spectral graph convolution to the subsequent spatial bassed message-passing model, spatial locality (in vertex domain) acts as a fundamental principle of most graph neural networks (GNNs). In the spectral graph convolution, the filter is approximated by polynomials, where a $k$-order polynomial covers $k$-hop neighbors. In the message-passing, various definitions of neighbors used in aggregations are actually an extensive exploration of the spatial locality information. For learning node representations, the topological distance seems necessary since it characterizes the basic relations between nodes. However, for learning representations of the entire graphs, is it still necessary to hold? In this work, we show that such a principle is not necessary, it hinders most existing GNNs from efficiently encoding graph structures. By removing it, as well as the limitation of polynomial filters, the resulting new architecture significantly boosts performance on learning graph representations. We also study the effects of graph spectrum on signals and interpret various existing improvements as different spectrum smoothing techniques. It serves as a spatial understanding that quantitatively measures the effects of the spectrum to input signals in comparison to the well-known spectral understanding as high/low-pass filters. More importantly, it sheds the light on developing powerful graph representation models.
Data-driven discovery of Bäcklund transforms and soliton evolution equations via deep neural network learning schemes
Nov 18, 2021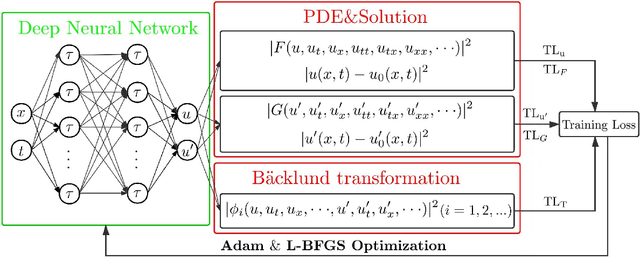
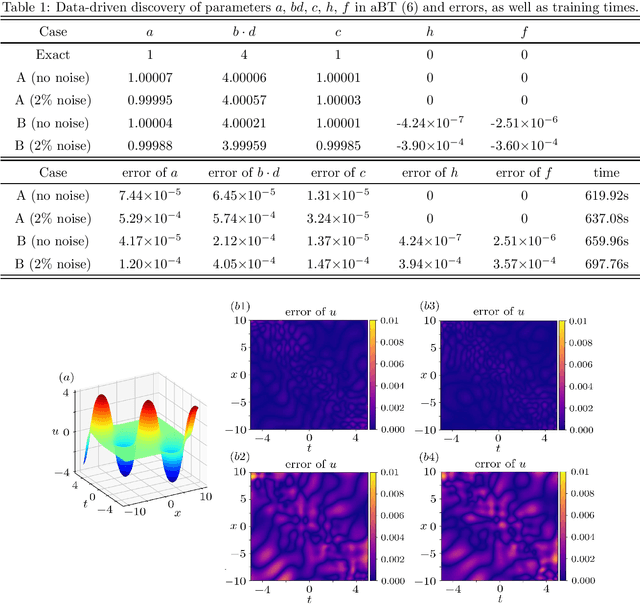
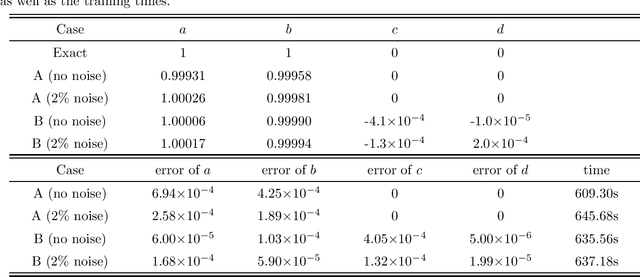

We introduce a deep neural network learning scheme to learn the B\"acklund transforms (BTs) of soliton evolution equations and an enhanced deep learning scheme for data-driven soliton equation discovery based on the known BTs, respectively. The first scheme takes advantage of some solution (or soliton equation) information to study the data-driven BT of sine-Gordon equation, and complex and real Miura transforms between the defocusing (focusing) mKdV equation and KdV equation, as well as the data-driven mKdV equation discovery via the Miura transforms. The second deep learning scheme uses the explicit/implicit BTs generating the higher-order solitons to train the data-driven discovery of mKdV and sine-Gordon equations, in which the high-order solution informations are more powerful for the enhanced leaning soliton equations with higher accurates.
Algorithmic Probability of Large Datasets and the Simplicity Bubble Problem in Machine Learning
Dec 22, 2021When mining large datasets in order to predict new data, limitations of the principles behind statistical machine learning pose a serious challenge not only to the Big Data deluge, but also to the traditional assumptions that data generating processes are biased toward low algorithmic complexity. Even when one assumes an underlying algorithmic-informational bias toward simplicity in finite dataset generators, we show that fully automated, with or without access to pseudo-random generators, computable learning algorithms, in particular those of statistical nature used in current approaches to machine learning (including deep learning), can always be deceived, naturally or artificially, by sufficiently large datasets. In particular, we demonstrate that, for every finite learning algorithm, there is a sufficiently large dataset size above which the algorithmic probability of an unpredictable deceiver is an upper bound (up to a multiplicative constant that only depends on the learning algorithm) for the algorithmic probability of any other larger dataset. In other words, very large and complex datasets are as likely to deceive learning algorithms into a "simplicity bubble" as any other particular dataset. These deceiving datasets guarantee that any prediction will diverge from the high-algorithmic-complexity globally optimal solution while converging toward the low-algorithmic-complexity locally optimal solution. We discuss the framework and empirical conditions for circumventing this deceptive phenomenon, moving away from statistical machine learning towards a stronger type of machine learning based on, or motivated by, the intrinsic power of algorithmic information theory and computability theory.
Machine-Learned Prediction Equilibrium for Dynamic Traffic Assignment
Sep 14, 2021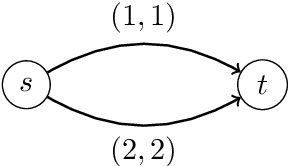
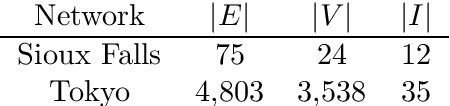
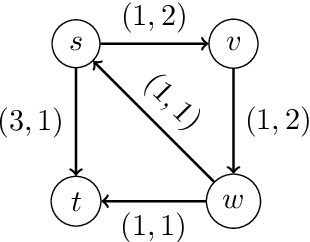
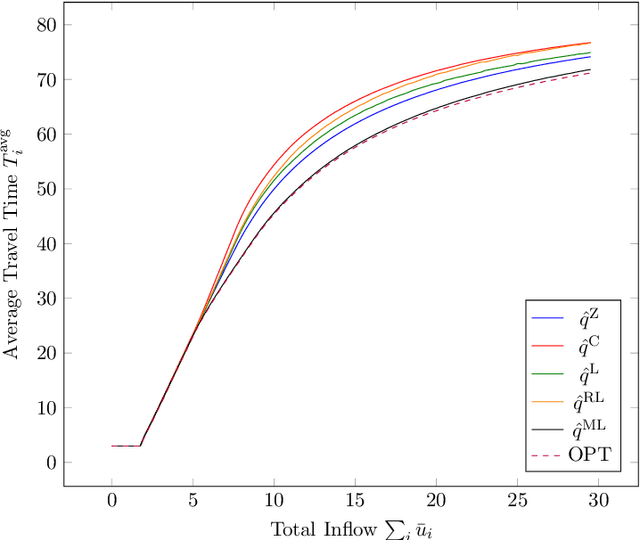
We study a dynamic traffic assignment model, where agents base their instantaneous routing decisions on real-time delay predictions. We formulate a mathematically concise model and derive properties of the predictors that ensure a dynamic prediction equilibrium exists. We demonstrate the versatility of our framework by showing that it subsumes the well-known full information and instantaneous information models, in addition to admitting further realistic predictors as special cases. We complement our theoretical analysis by an experimental study, in which we systematically compare the induced average travel times of different predictors, including a machine-learning model trained on data gained from previously computed equilibrium flows, both on a synthetic and a real road network.
Structure-Preserving Graph Kernel for Brain Network Classification
Nov 21, 2021
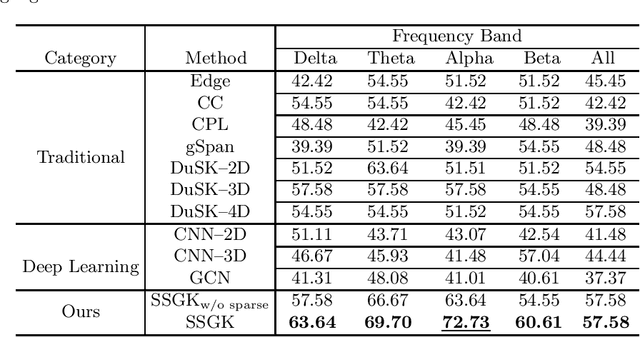
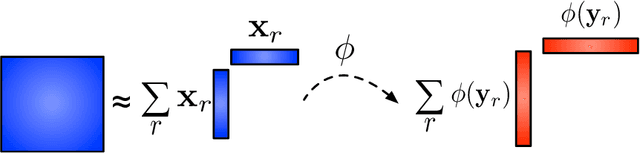
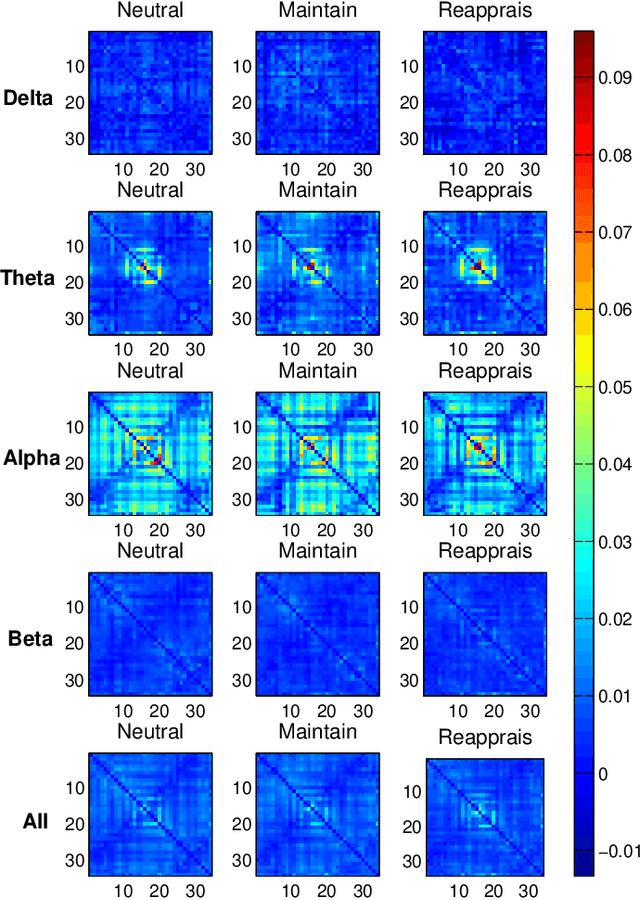
This paper presents a novel graph-based kernel learning approach for connectome analysis. Specifically, we demonstrate how to leverage the naturally available structure within the graph representation to encode prior knowledge in the kernel. We first proposed a matrix factorization to directly extract structural features from natural symmetric graph representations of connectome data. We then used them to derive a structure-persevering graph kernel to be fed into the support vector machine. The proposed approach has the advantage of being clinically interpretable. Quantitative evaluations on challenging HIV disease classification (DTI- and fMRI-derived connectome data) and emotion recognition (EEG-derived connectome data) tasks demonstrate the superior performance of our proposed methods against the state-of-the-art. Results showed that relevant EEG-connectome information is primarily encoded in the alpha band during the emotion regulation task.
Joint 3D Object Detection and Tracking Using Spatio-Temporal Representation of Camera Image and LiDAR Point Clouds
Dec 14, 2021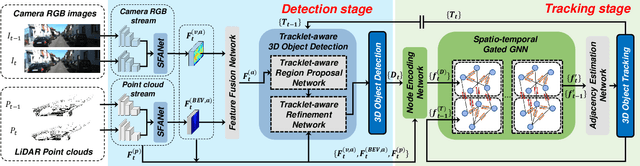

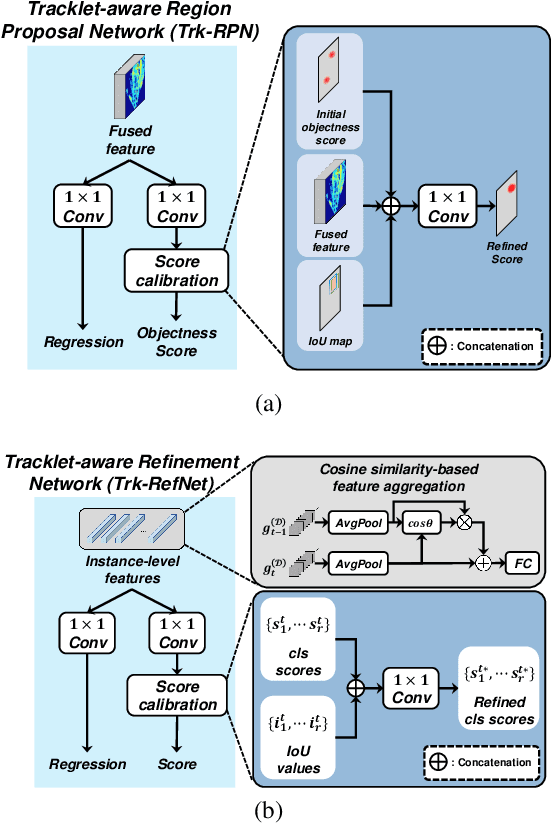

In this paper, we propose a new joint object detection and tracking (JoDT) framework for 3D object detection and tracking based on camera and LiDAR sensors. The proposed method, referred to as 3D DetecTrack, enables the detector and tracker to cooperate to generate a spatio-temporal representation of the camera and LiDAR data, with which 3D object detection and tracking are then performed. The detector constructs the spatio-temporal features via the weighted temporal aggregation of the spatial features obtained by the camera and LiDAR fusion. Then, the detector reconfigures the initial detection results using information from the tracklets maintained up to the previous time step. Based on the spatio-temporal features generated by the detector, the tracker associates the detected objects with previously tracked objects using a graph neural network (GNN). We devise a fully-connected GNN facilitated by a combination of rule-based edge pruning and attention-based edge gating, which exploits both spatial and temporal object contexts to improve tracking performance. The experiments conducted on both KITTI and nuScenes benchmarks demonstrate that the proposed 3D DetecTrack achieves significant improvements in both detection and tracking performances over baseline methods and achieves state-of-the-art performance among existing methods through collaboration between the detector and tracker.