 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Impact of User Demographics and Task Types on Cross-App Mobile Search
Sep 14, 2021
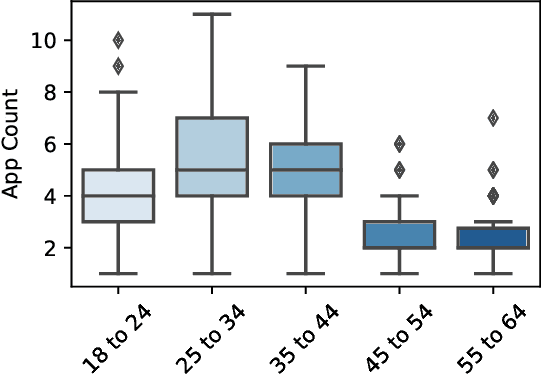
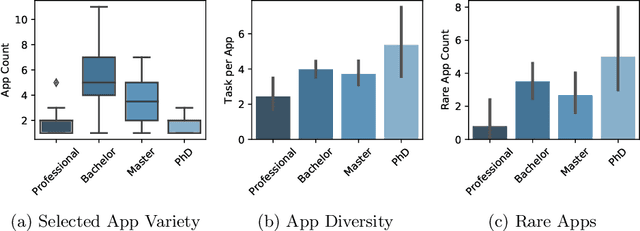
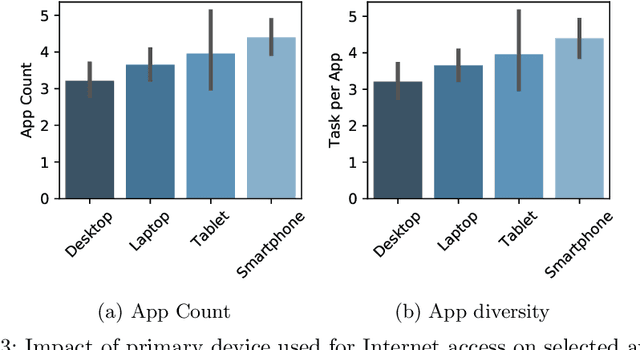
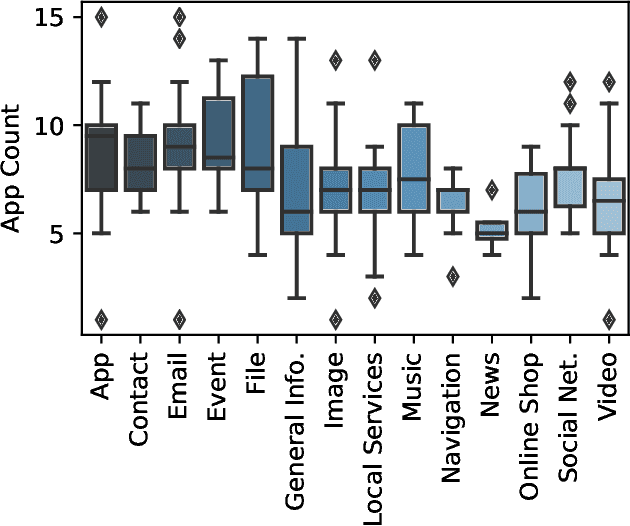
Recent developments in the mobile app industry have resulted in various types of mobile apps, each targeting a different need and a specific audience. Consequently, users access distinct apps to complete their information need tasks. This leads to the use of various apps not only separately, but also collaboratively in the same session to achieve a single goal. Recent work has argued the need for a unified mobile search system that would act as metasearch on users' mobile devices. The system would identify the target apps for the user's query, submit the query to the apps, and present the results to the user in a unified way. In this work, we aim to deepen our understanding of user behavior while accessing information on their mobile phones by conducting an extensive analysis of various aspects related to the search process. In particular, we study the effect of task type and user demographics on their behavior in interacting with mobile apps. Our findings reveal trends and patterns that can inform the design of a more effective mobile information access environment.
Anomaly Clustering: Grouping Images into Coherent Clusters of Anomaly Types
Dec 21, 2021

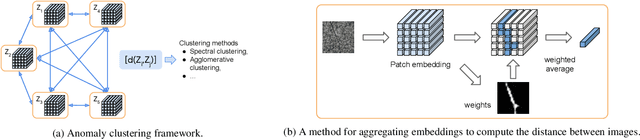
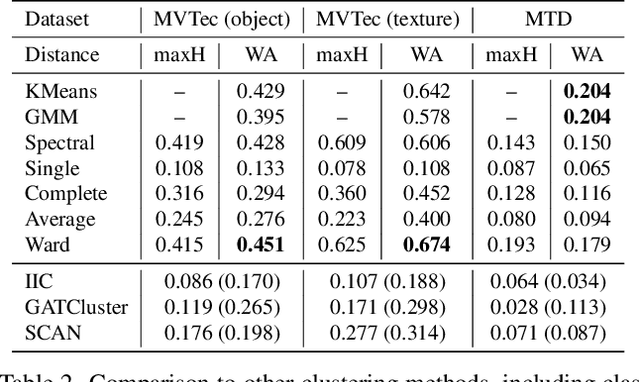
We introduce anomaly clustering, whose goal is to group data into semantically coherent clusters of anomaly types. This is different from anomaly detection, whose goal is to divide anomalies from normal data. Unlike object-centered image clustering applications, anomaly clustering is particularly challenging as anomalous patterns are subtle and local. We present a simple yet effective clustering framework using a patch-based pretrained deep embeddings and off-the-shelf clustering methods. We define a distance function between images, each of which is represented as a bag of embeddings, by the Euclidean distance between weighted averaged embeddings. The weight defines the importance of instances (i.e., patch embeddings) in the bag, which may highlight defective regions. We compute weights in an unsupervised way or in a semi-supervised way if labeled normal data is available. Extensive experimental studies show the effectiveness of the proposed clustering framework along with a novel distance function upon existing multiple instance or deep clustering frameworks. Overall, our framework achieves 0.451 and 0.674 normalized mutual information scores on MVTec object and texture categories and further improve with a few labeled normal data (0.577, 0.669), far exceeding the baselines (0.244, 0.273) or state-of-the-art deep clustering methods (0.176, 0.277).
All-photon Polarimetric Time-of-Flight Imaging
Dec 17, 2021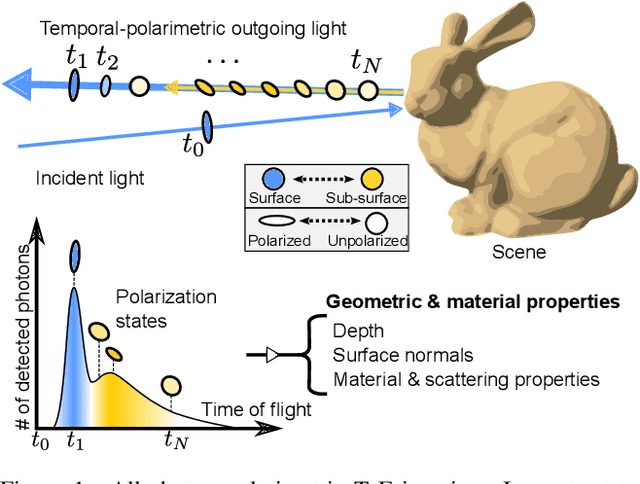
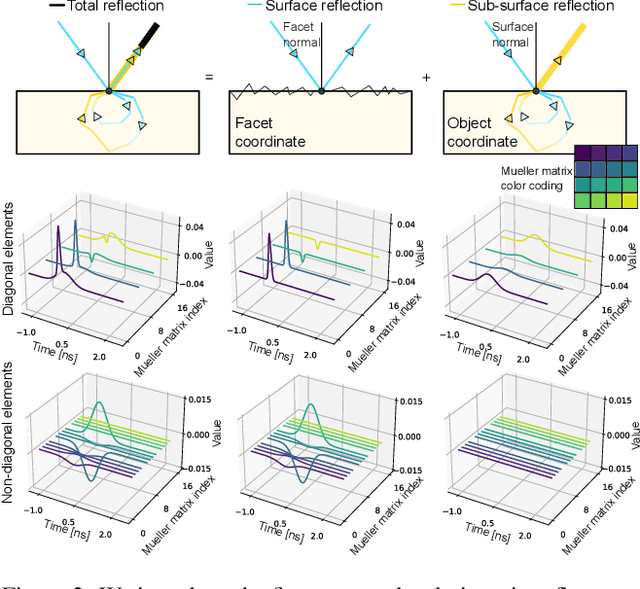
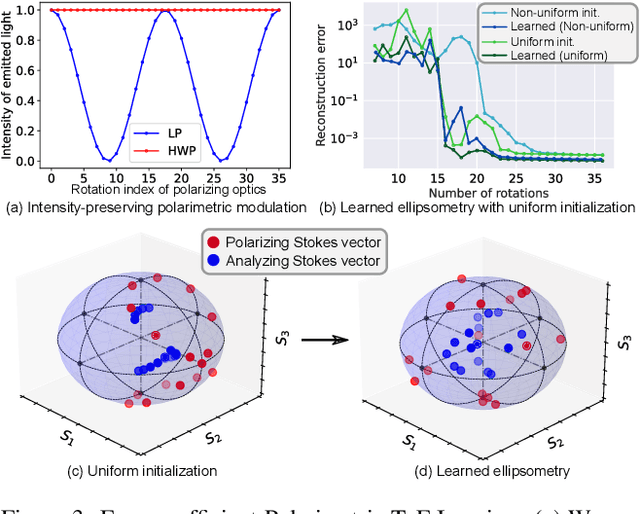
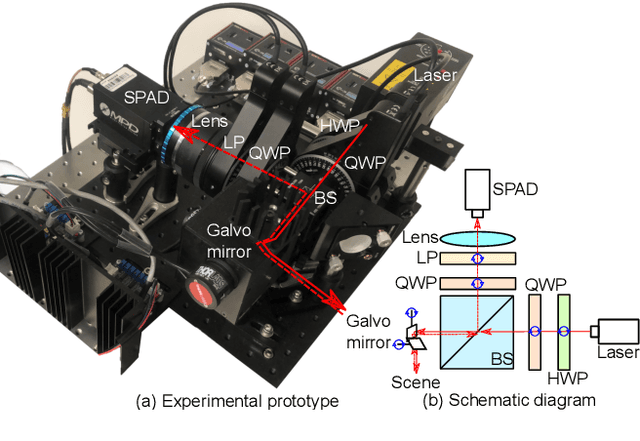
Time-of-flight (ToF) sensors provide an imaging modality fueling diverse applications, including LiDAR in autonomous driving, robotics, and augmented reality. Conventional ToF imaging methods estimate the depth by sending pulses of light into a scene and measuring the ToF of the first-arriving photons directly reflected from a scene surface without any temporal delay. As such, all photons following this first response are typically considered as unwanted noise. In this paper, we depart from the principle of using first-arriving photons and propose an all-photon ToF imaging method by incorporating the temporal-polarimetric analysis of first- and late-arriving photons, which possess rich scene information about its geometry and material. To this end, we propose a novel temporal-polarimetric reflectance model, an efficient capture method, and a reconstruction method that exploits the temporal-polarimetric changes of light reflected by the surface and sub-surface reflection. The proposed all-photon polarimetric ToF imaging method allows for acquiring depth, surface normals, and material parameters of a scene by utilizing all photons captured by the system, whereas conventional ToF imaging only obtains coarse depth from the first-arriving photons. We validate our method in simulation and experimentally with a prototype.
InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
Dec 02, 2021
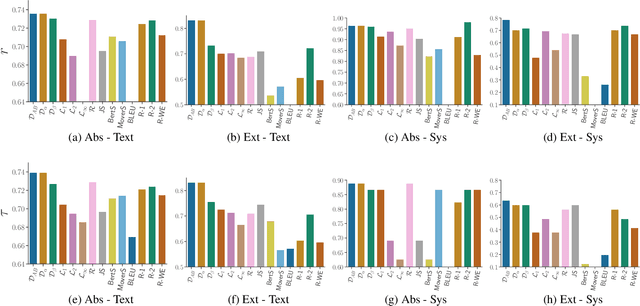
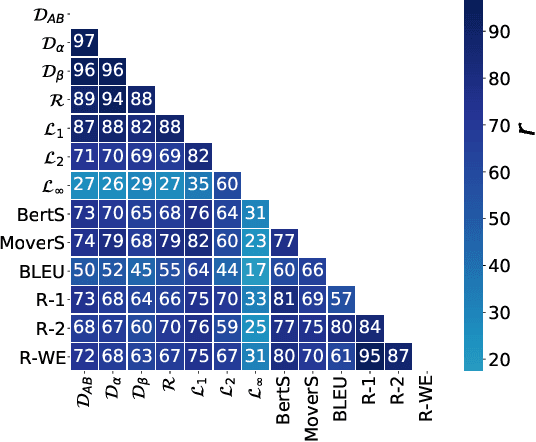
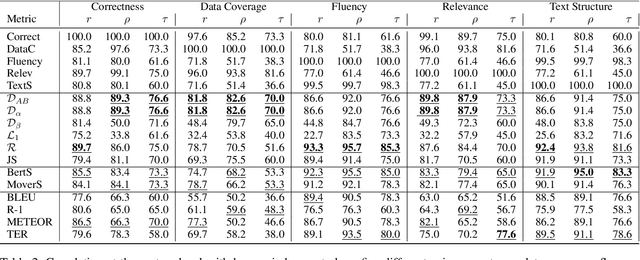
Assessing the quality of natural language generation systems through human annotation is very expensive. Additionally, human annotation campaigns are time-consuming and include non-reusable human labour. In practice, researchers rely on automatic metrics as a proxy of quality. In the last decade, many string-based metrics (e.g., BLEU) have been introduced. However, such metrics usually rely on exact matches and thus, do not robustly handle synonyms. In this paper, we introduce InfoLM a family of untrained metrics that can be viewed as a string-based metric that addresses the aforementioned flaws thanks to a pre-trained masked language model. This family of metrics also makes use of information measures allowing the adaptation of InfoLM to various evaluation criteria. Using direct assessment, we demonstrate that InfoLM achieves statistically significant improvement and over $10$ points of correlation gains in many configurations on both summarization and data2text generation.
Understanding over-squashing and bottlenecks on graphs via curvature
Nov 29, 2021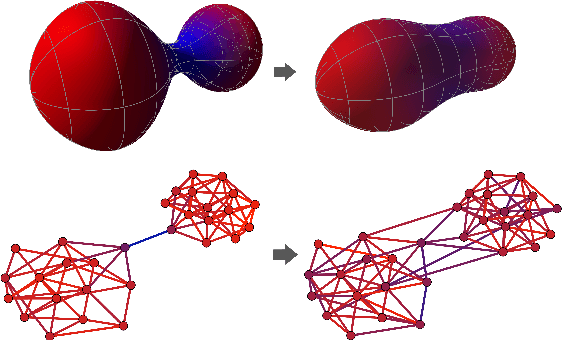
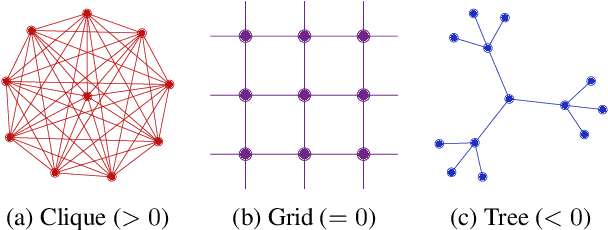

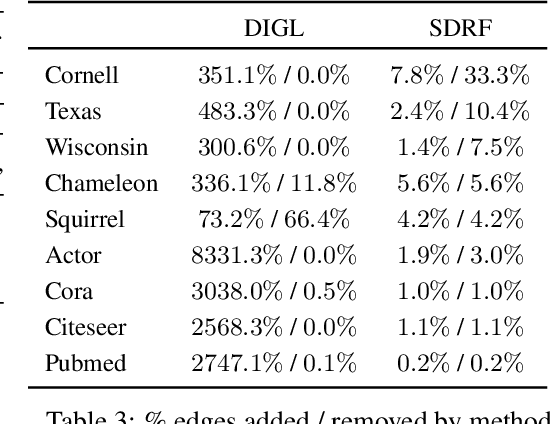
Most graph neural networks (GNNs) use the message passing paradigm, in which node features are propagated on the input graph. Recent works pointed to the distortion of information flowing from distant nodes as a factor limiting the efficiency of message passing for tasks relying on long-distance interactions. This phenomenon, referred to as 'over-squashing', has been heuristically attributed to graph bottlenecks where the number of $k$-hop neighbors grows rapidly with $k$. We provide a precise description of the over-squashing phenomenon in GNNs and analyze how it arises from bottlenecks in the graph. For this purpose, we introduce a new edge-based combinatorial curvature and prove that negatively curved edges are responsible for the over-squashing issue. We also propose and experimentally test a curvature-based graph rewiring method to alleviate the over-squashing.
Co-domain Symmetry for Complex-Valued Deep Learning
Dec 02, 2021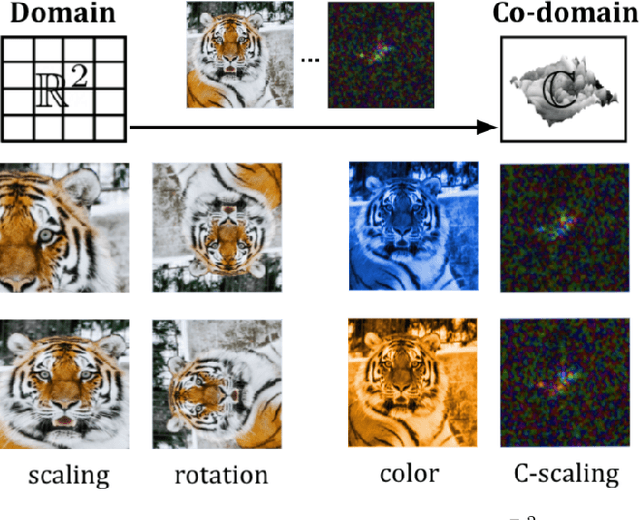
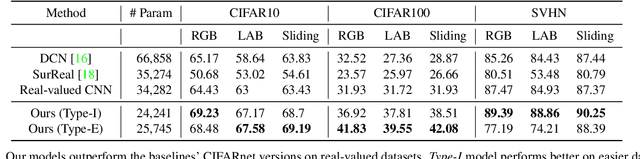
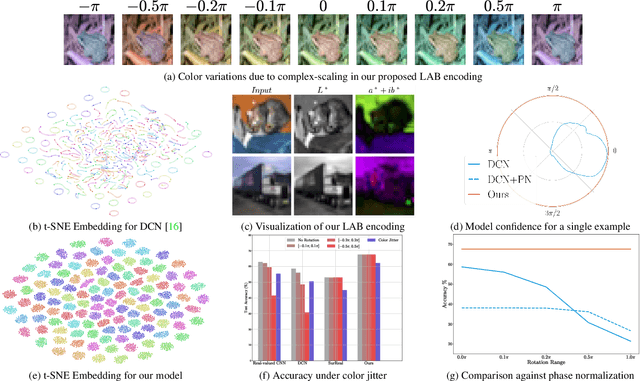
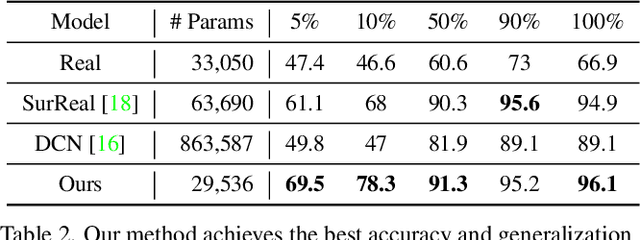
We study complex-valued scaling as a type of symmetry natural and unique to complex-valued measurements and representations. Deep Complex Networks (DCN) extends real-valued algebra to the complex domain without addressing complex-valued scaling. SurReal takes a restrictive manifold view of complex numbers, adopting a distance metric to achieve complex-scaling invariance while losing rich complex-valued information. We analyze complex-valued scaling as a co-domain transformation and design novel equivariant and invariant neural network layer functions for this special transformation. We also propose novel complex-valued representations of RGB images, where complex-valued scaling indicates hue shift or correlated changes across color channels. Benchmarked on MSTAR, CIFAR10, CIFAR100, and SVHN, our co-domain symmetric (CDS) classifiers deliver higher accuracy, better generalization, robustness to co-domain transformations, and lower model bias and variance than DCN and SurReal with far fewer parameters.
Degree-Based Random Walk Approach for Graph Embedding
Oct 21, 2021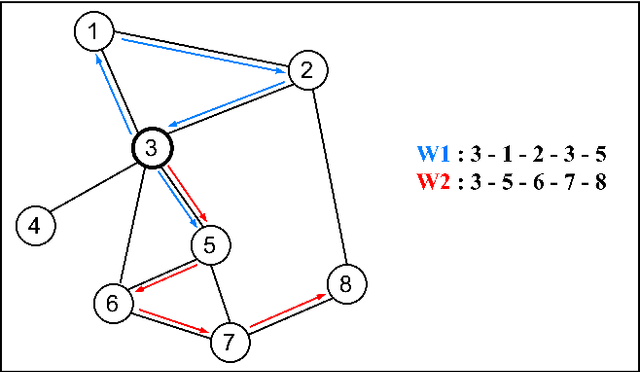
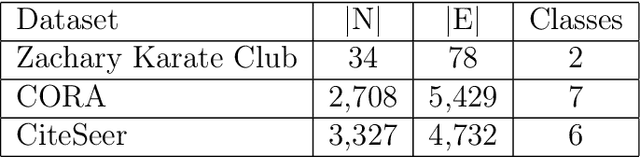
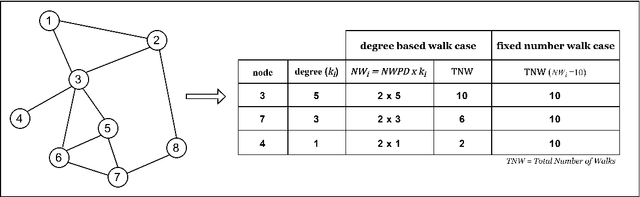
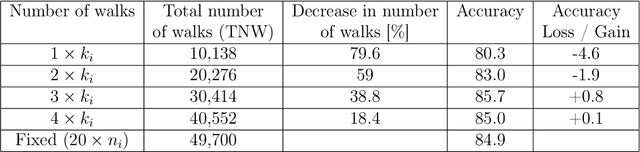
Graph embedding, representing local and global neighborhood information by numerical vectors, is a crucial part of the mathematical modeling of a wide range of real-world systems. Among the embedding algorithms, random walk-based algorithms have proven to be very successful. These algorithms collect information by creating numerous random walks with a redefined number of steps. Creating random walks is the most demanding part of the embedding process. The computation demand increases with the size of the network. Moreover, for real-world networks, considering all nodes on the same footing, the abundance of low-degree nodes creates an imbalanced data problem. In this work, a computationally less intensive and node connectivity aware uniform sampling method is proposed. In the proposed method, the number of random walks is created proportionally with the degree of the node. The advantages of the proposed algorithm become more enhanced when the algorithm is applied to large graphs. A comparative study by using two networks namely CORA and CiteSeer is presented. Comparing with the fixed number of walks case, the proposed method requires 50% less computational effort to reach the same accuracy for node classification and link prediction calculations.
Estimating Information Flow in Neural Networks
Oct 16, 2018
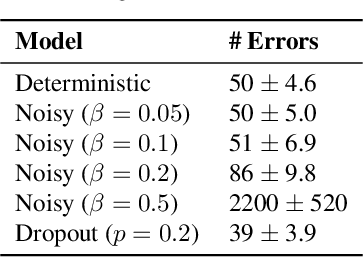
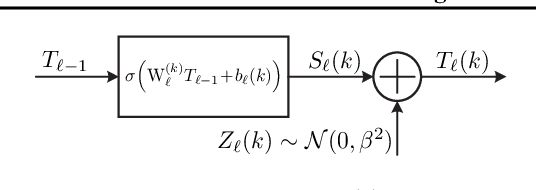
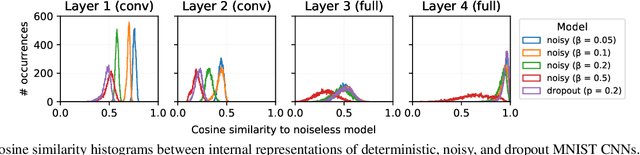
We study the flow of information and the evolution of internal representations during deep neural network (DNN) training, aiming to demystify the compression aspect of the information bottleneck theory. The theory suggests that DNN training comprises a rapid fitting phase followed by a slower compression phase, in which the mutual information $I(X;T)$ between the input $X$ and internal representations $T$ decreases. Several papers observe compression of estimated mutual information on different DNN models, but the true $I(X;T)$ over these networks is provably either constant (discrete $X$) or infinite (continuous $X$). This work explains the discrepancy between theory and experiments, and clarifies what was actually measured by these past works. To this end, we introduce an auxiliary (noisy) DNN framework for which $I(X;T)$ is a meaningful quantity that depends on the network's parameters. This noisy framework is shown to be a good proxy for the original (deterministic) DNN both in terms of performance and the learned representations. We then develop a rigorous estimator for $I(X;T)$ in noisy DNNs and observe compression in various models. By relating $I(X;T)$ in the noisy DNN to an information-theoretic communication problem, we show that compression is driven by the progressive clustering of hidden representations of inputs from the same class. Several methods to directly monitor clustering of hidden representations, both in noisy and deterministic DNNs, are used to show that meaningful clusters form in the $T$ space. Finally, we return to the estimator of $I(X;T)$ employed in past works, and demonstrate that while it fails to capture the true (vacuous) mutual information, it does serve as a measure for clustering. This clarifies the past observations of compression and isolates the geometric clustering of hidden representations as the true phenomenon of interest.
Evaluating Privacy-Preserving Machine Learning in Critical Infrastructures: A Case Study on Time-Series Classification
Nov 29, 2021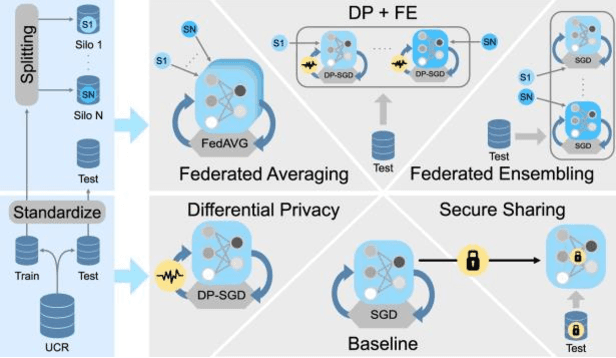
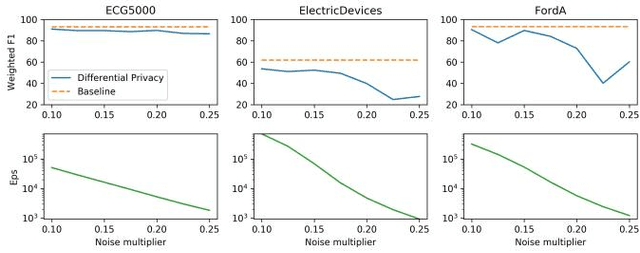
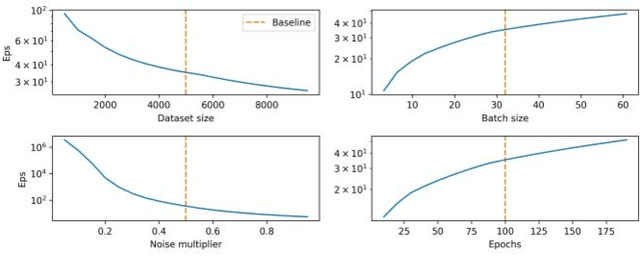
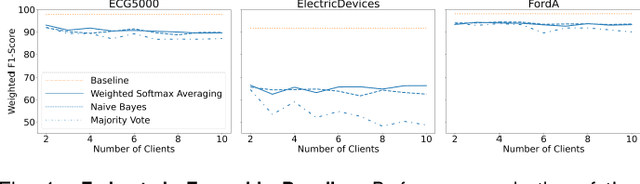
With the advent of machine learning in applications of critical infrastructure such as healthcare and energy, privacy is a growing concern in the minds of stakeholders. It is pivotal to ensure that neither the model nor the data can be used to extract sensitive information used by attackers against individuals or to harm whole societies through the exploitation of critical infrastructure. The applicability of machine learning in these domains is mostly limited due to a lack of trust regarding the transparency and the privacy constraints. Various safety-critical use cases (mostly relying on time-series data) are currently underrepresented in privacy-related considerations. By evaluating several privacy-preserving methods regarding their applicability on time-series data, we validated the inefficacy of encryption for deep learning, the strong dataset dependence of differential privacy, and the broad applicability of federated methods.
Learning Query Expansion over the Nearest Neighbor Graph
Dec 05, 2021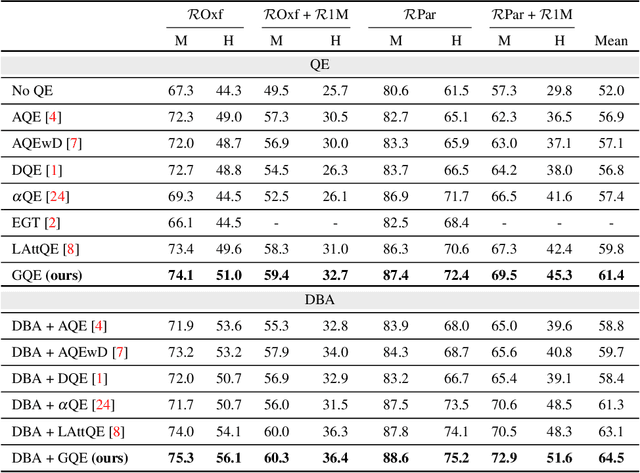
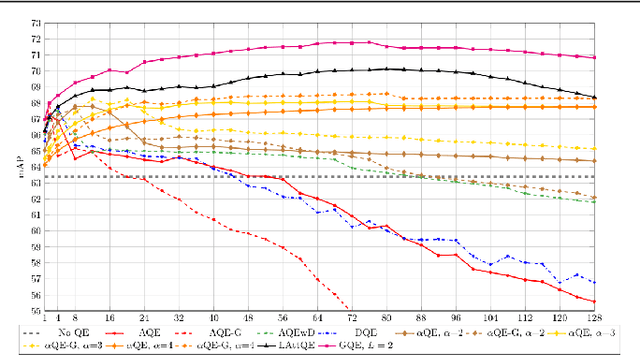
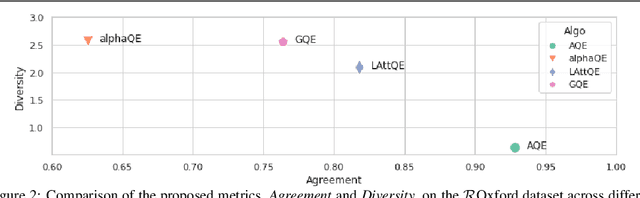
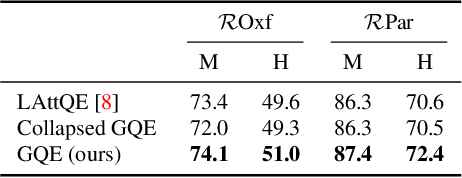
Query Expansion (QE) is a well established method for improving retrieval metrics in image search applications. When using QE, the search is conducted on a new query vector, constructed using an aggregation function over the query and images from the database. Recent works gave rise to QE techniques in which the aggregation function is learned, whereas previous techniques were based on hand-crafted aggregation functions, e.g., taking the mean of the query's nearest neighbors. However, most QE methods have focused on aggregation functions that work directly over the query and its immediate nearest neighbors. In this work, a hierarchical model, Graph Query Expansion (GQE), is presented, which is learned in a supervised manner and performs aggregation over an extended neighborhood of the query, thus increasing the information used from the database when computing the query expansion, and using the structure of the nearest neighbors graph. The technique achieves state-of-the-art results over known benchmarks.