 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Long-Range Thermal 3D Perception in Low Contrast Environments
Dec 10, 2021

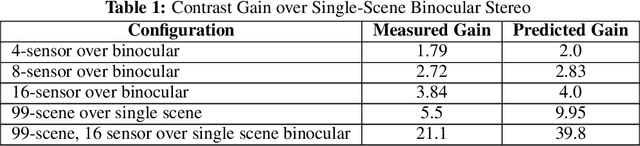


This report discusses the results of SBIR Phase I effort to prove the feasibility of dramatic improvement of the microbolometer-based Long Wave Infrared (LWIR) detectors sensitivity, especially for the 3D measurements. The resulting low SWaP-C thermal depth-sensing system will enable the situational awareness of Autonomous Air Vehicles for Advanced Air Mobility (AAM). It will provide robust 3D information of the surrounding environment, including low-contrast static and moving objects, at far distances in degraded visual conditions and GPS-denied areas. Our multi-sensor 3D perception enabled by COTS uncooled thermal sensors mitigates major weakness of LWIR sensors - low contrast by increasing the system sensitivity over an order of magnitude. There were no available thermal image sets suitable for evaluating this technology, making datasets acquisition our first goal. We discuss the design and construction of the prototype system with sixteen 640pix x 512pix LWIR detectors, camera calibration to subpixel resolution, capture, and process synchronized image. The results show the 3.84x contrast increase for intrascene-only data and an additional 5.5x - with the interscene accumulation, reaching system noise-equivalent temperature difference (NETD) of 1.9 mK with the 40 mK sensors.
Learning to Navigate from Simulation via Spatial and Semantic Information Synthesis
Oct 13, 2019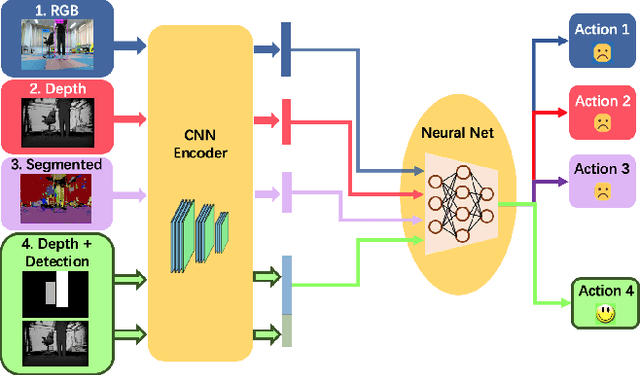
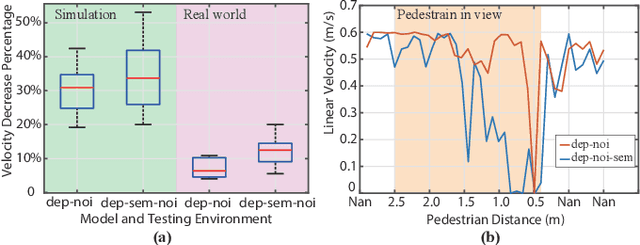

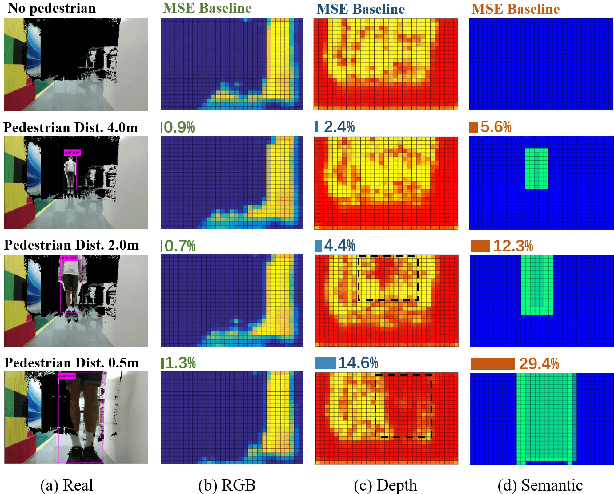
While training an end-to-end navigation network in the real world is usually of high cost, simulations provide a safe and cheap environment in this training stage. However, training neural network models in simulations brings up the problem of how to effectively transfer the model from simulations to the real world (sim-to-real). We regard the environment representation as a crucial element in this transfer process. In this work, we propose a visual information pyramid (VIP) theory to systematically investigate a practical environment representation. A representation composed of spatial and semantic information synthesis is established based on this theory. Specifically, the spatial information is presented by a noise-model-assisted depth image while the semantic information is expressed with a categorized detection image. To explore the effectiveness of this representation, we first extract different representations from a same dataset collected from expert operations, then feed them to the same or very similar neural networks to train the network parameters, and finally evaluate the trained neural networks in simulated and real world navigation tasks. Results suggest that our proposed environment representation behaves best compared with representations popularly used in the literature. With mere one-hour-long training data collected from simulation, the network model trained with our representation can successfully navigate the robot in various scenarios with obstacles. Furthermore, an analysis on the feature map is implemented to investigate the effectiveness through inner reaction, which could be irradiative for future researches on end-to-end navigation.
Active Sensing for Search and Tracking: A Review
Dec 04, 2021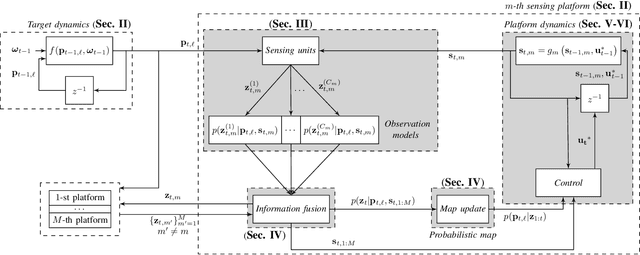
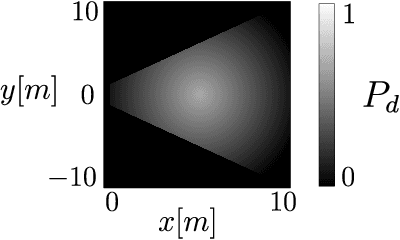
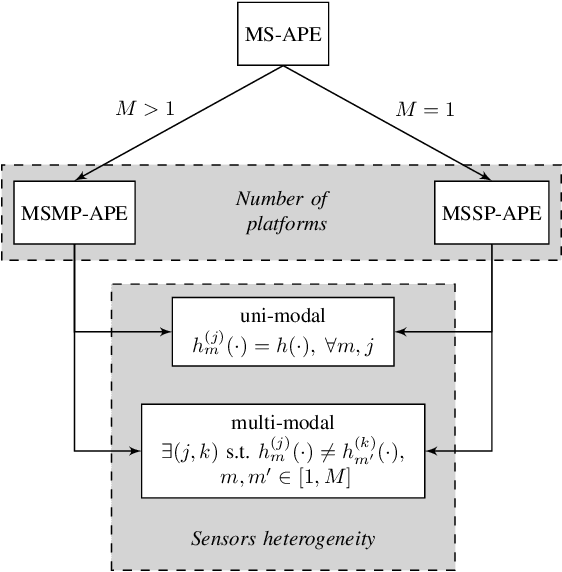
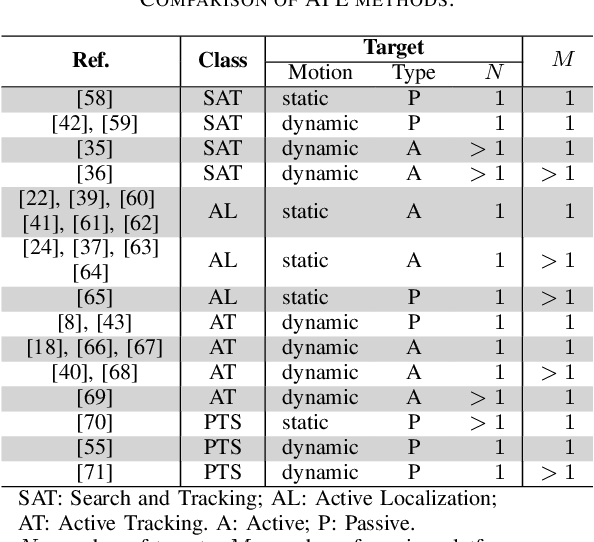
Active Position Estimation (APE) is the task of localizing one or more targets using one or more sensing platforms. APE is a key task for search and rescue missions, wildlife monitoring, source term estimation, and collaborative mobile robotics. Success in APE depends on the level of cooperation of the sensing platforms, their number, their degrees of freedom and the quality of the information gathered. APE control laws enable active sensing by satisfying either pure-exploitative or pure-explorative criteria. The former minimizes the uncertainty on position estimation; whereas the latter drives the platform closer to its task completion. In this paper, we define the main elements of APE to systematically classify and critically discuss the state of the art in this domain. We also propose a reference framework as a formalism to classify APE-related solutions. Overall, this survey explores the principal challenges and envisages the main research directions in the field of autonomous perception systems for localization tasks. It is also beneficial to promote the development of robust active sensing methods for search and tracking applications.
Scheduling in Parallel Finite Buffer Systems: Optimal Decisions under Delayed Feedback
Sep 17, 2021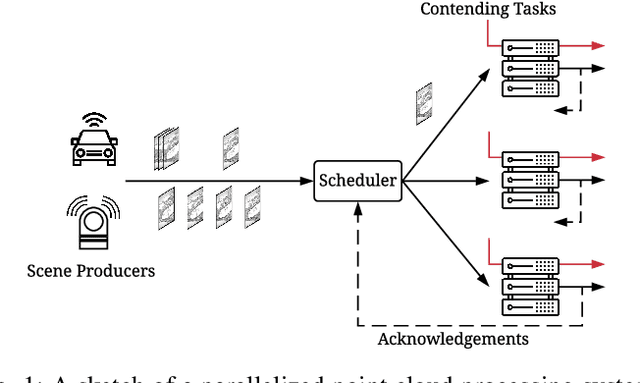
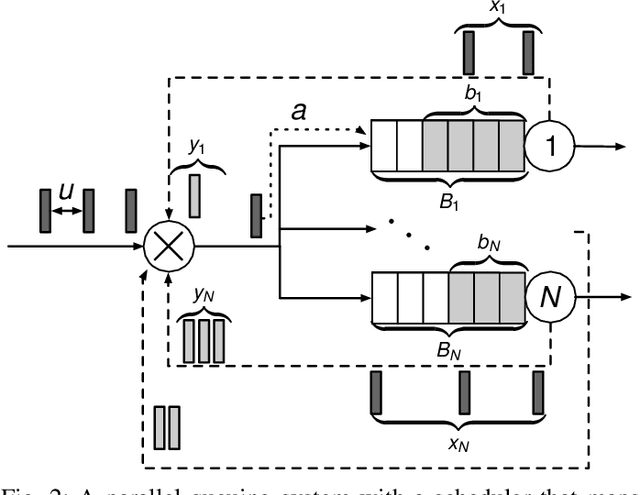
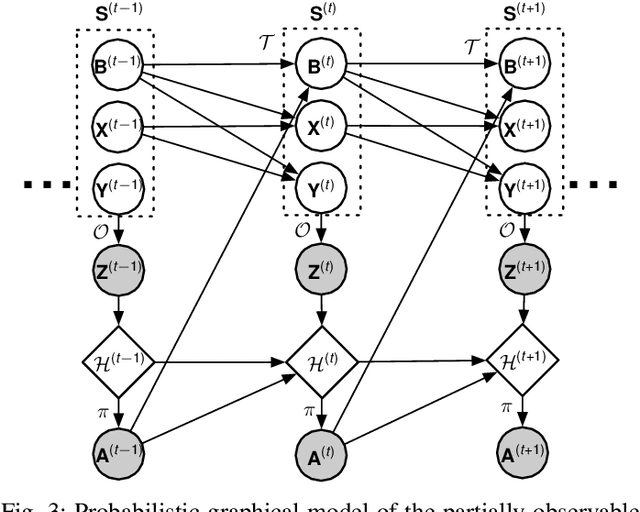

Scheduling decisions in parallel queuing systems arise as a fundamental problem, underlying the dimensioning and operation of many computing and communication systems, such as job routing in data center clusters, multipath communication, and Big Data systems. In essence, the scheduler maps each arriving job to one of the possibly heterogeneous servers while aiming at an optimization goal such as load balancing, low average delay or low loss rate. One main difficulty in finding optimal scheduling decisions here is that the scheduler only partially observes the impact of its decisions, e.g., through the delayed acknowledgements of the served jobs. In this paper, we provide a partially observable (PO) model that captures the scheduling decisions in parallel queuing systems under limited information of delayed acknowledgements. We present a simulation model for this PO system to find a near-optimal scheduling policy in real-time using a scalable Monte Carlo tree search algorithm. We numerically show that the resulting policy outperforms other limited information scheduling strategies such as variants of Join-the-Most-Observations and has comparable performance to full information strategies like: Join-the-Shortest-Queue, Join-the- Shortest-Queue(d) and Shortest-Expected-Delay. Finally, we show how our approach can optimise the real-time parallel processing by using network data provided by Kaggle.
PointMixer: MLP-Mixer for Point Cloud Understanding
Nov 22, 2021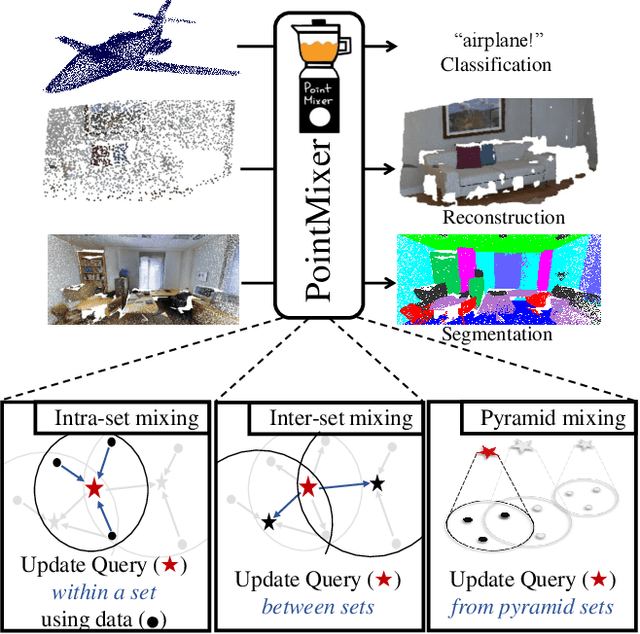

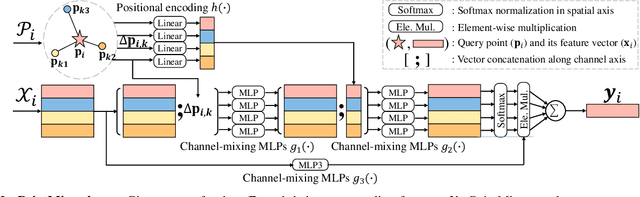

MLP-Mixer has newly appeared as a new challenger against the realm of CNNs and transformer. Despite its simplicity compared to transformer, the concept of channel-mixing MLPs and token-mixing MLPs achieves noticeable performance in visual recognition tasks. Unlike images, point clouds are inherently sparse, unordered and irregular, which limits the direct use of MLP-Mixer for point cloud understanding. In this paper, we propose PointMixer, a universal point set operator that facilitates information sharing among unstructured 3D points. By simply replacing token-mixing MLPs with a softmax function, PointMixer can "mix" features within/between point sets. By doing so, PointMixer can be broadly used in the network as inter-set mixing, intra-set mixing, and pyramid mixing. Extensive experiments show the competitive or superior performance of PointMixer in semantic segmentation, classification, and point reconstruction against transformer-based methods.
Why Do We Click: Visual Impression-aware News Recommendation
Sep 26, 2021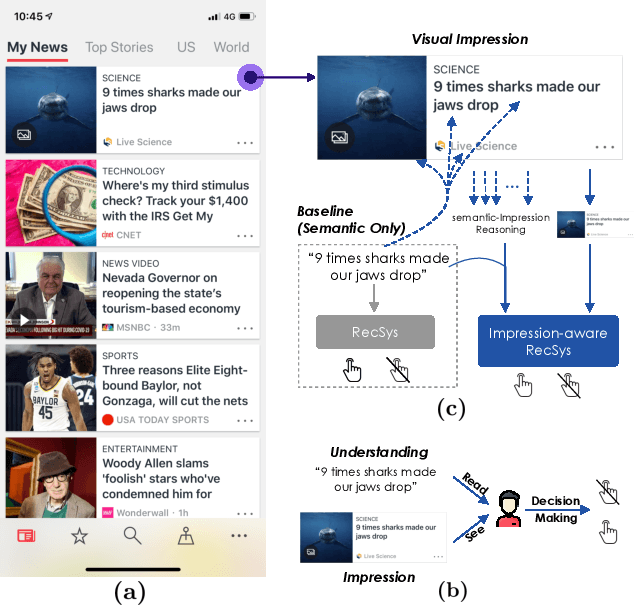
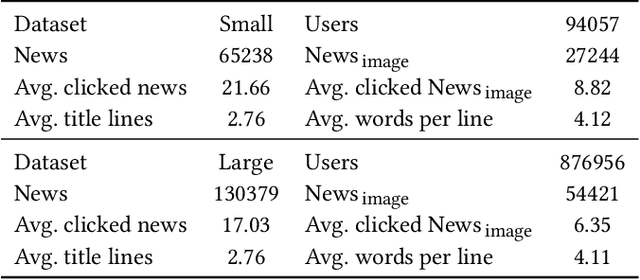
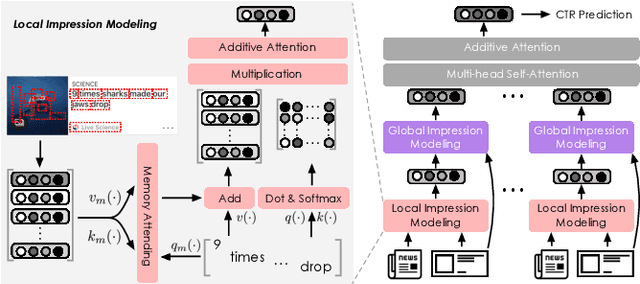
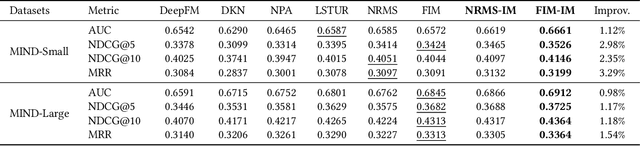
There is a soaring interest in the news recommendation research scenario due to the information overload. To accurately capture users' interests, we propose to model multi-modal features, in addition to the news titles that are widely used in existing works, for news recommendation. Besides, existing research pays little attention to the click decision-making process in designing multi-modal modeling modules. In this work, inspired by the fact that users make their click decisions mostly based on the visual impression they perceive when browsing news, we propose to capture such visual impression information with visual-semantic modeling for news recommendation. Specifically, we devise the local impression modeling module to simultaneously attend to decomposed details in the impression when understanding the semantic meaning of news title, which could explicitly get close to the process of users reading news. In addition, we inspect the impression from a global view and take structural information, such as the arrangement of different fields and spatial position of different words on the impression, into the modeling of multiple modalities. To accommodate the research of visual impression-aware news recommendation, we extend the text-dominated news recommendation dataset MIND by adding snapshot impression images and will release it to nourish the research field. Extensive comparisons with the state-of-the-art news recommenders along with the in-depth analyses demonstrate the effectiveness of the proposed method and the promising capability of modeling visual impressions for the content-based recommenders.
LIFE: Learning Individual Features for Multivariate Time Series Prediction with Missing Values
Sep 30, 2021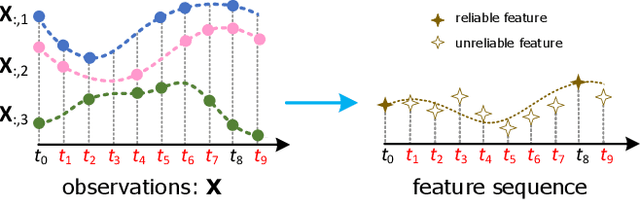
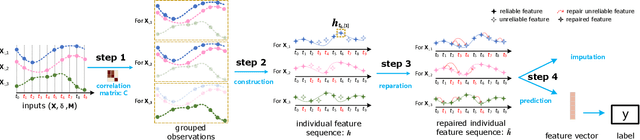
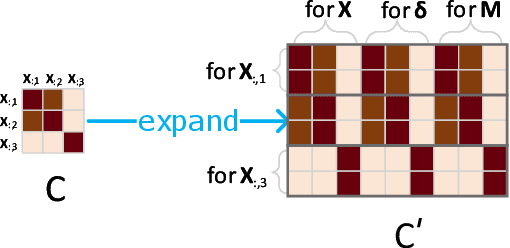
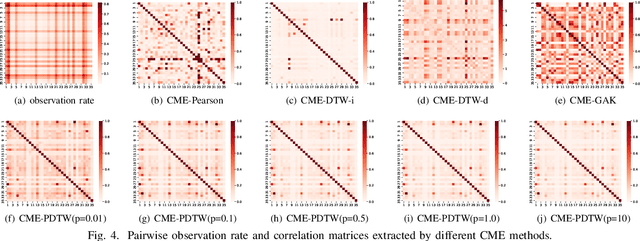
Multivariate time series (MTS) prediction is ubiquitous in real-world fields, but MTS data often contains missing values. In recent years, there has been an increasing interest in using end-to-end models to handle MTS with missing values. To generate features for prediction, existing methods either merge all input dimensions of MTS or tackle each input dimension independently. However, both approaches are hard to perform well because the former usually produce many unreliable features and the latter lacks correlated information. In this paper, we propose a Learning Individual Features (LIFE) framework, which provides a new paradigm for MTS prediction with missing values. LIFE generates reliable features for prediction by using the correlated dimensions as auxiliary information and suppressing the interference from uncorrelated dimensions with missing values. Experiments on three real-world data sets verify the superiority of LIFE to existing state-of-the-art models.
Cross-lingual COVID-19 Fake News Detection
Oct 14, 2021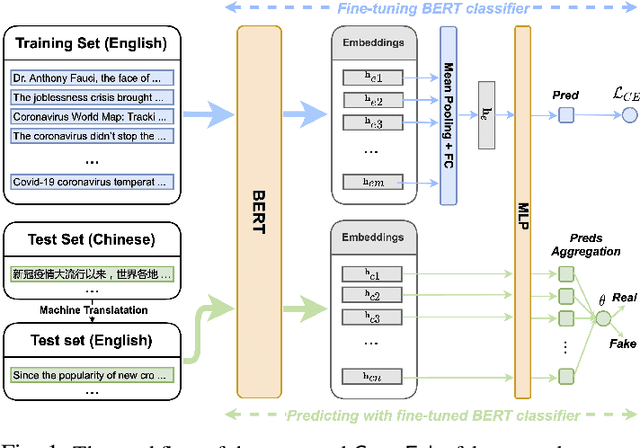

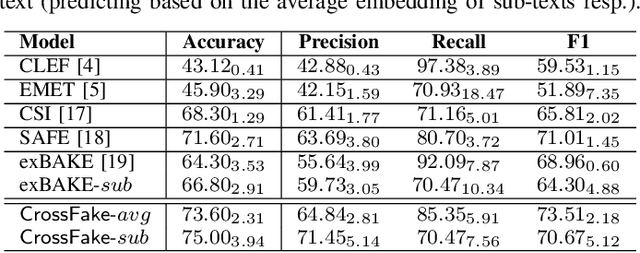
The COVID-19 pandemic poses a great threat to global public health. Meanwhile, there is massive misinformation associated with the pandemic which advocates unfounded or unscientific claims. Even major social media and news outlets have made an extra effort in debunking COVID-19 misinformation, most of the fact-checking information is in English, whereas some unmoderated COVID-19 misinformation is still circulating in other languages, threatening the health of less-informed people in immigrant communities and developing countries. In this paper, we make the first attempt to detect COVID-19 misinformation in a low-resource language (Chinese) only using the fact-checked news in a high-resource language (English). We start by curating a Chinese real&fake news dataset according to existing fact-checking information. Then, we propose a deep learning framework named CrossFake to jointly encode the cross-lingual news body texts and capture the news content as much as possible. Empirical results on our dataset demonstrate the effectiveness of CrossFake under the cross-lingual setting and it also outperforms several monolingual and cross-lingual fake news detectors. The dataset is available at https://github.com/YingtongDou/CrossFake.
Exploring Temporal Information for Improved Video Understanding
May 25, 2019

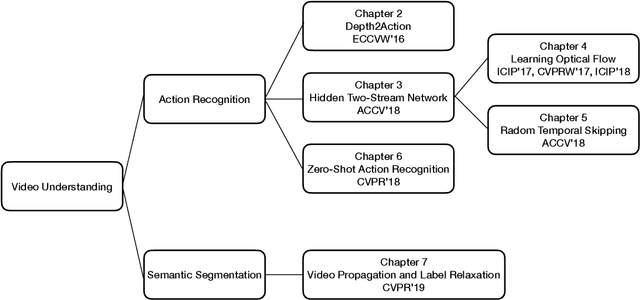

In this dissertation, I present my work towards exploring temporal information for better video understanding. Specifically, I have worked on two problems: action recognition and semantic segmentation. For action recognition, I have proposed a framework, termed hidden two-stream networks, to learn an optimal motion representation that does not require the computation of optical flow. My framework alleviates several challenges faced in video classification, such as learning motion representations, real-time inference, multi-framerate handling, generalizability to unseen actions, etc. For semantic segmentation, I have introduced a general framework that uses video prediction models to synthesize new training samples. By scaling up the training dataset, my trained models are more accurate and robust than previous models even without modifications to the network architectures or objective functions. I believe videos have much more potential to be mined, and temporal information is one of the most important cues for machines to perceive the visual world better.
Depth-aware Object Segmentation and Grasp Detection for Robotic Picking Tasks
Nov 22, 2021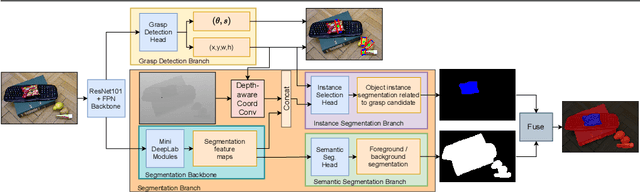

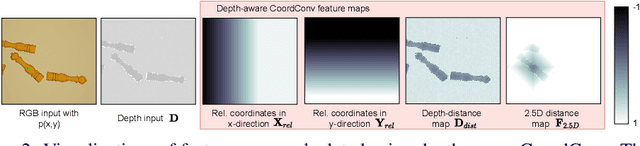
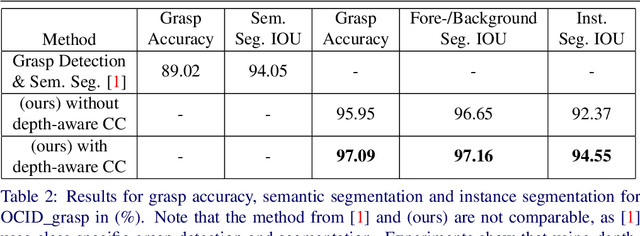
In this paper, we present a novel deep neural network architecture for joint class-agnostic object segmentation and grasp detection for robotic picking tasks using a parallel-plate gripper. We introduce depth-aware Coordinate Convolution (CoordConv), a method to increase accuracy for point proposal based object instance segmentation in complex scenes without adding any additional network parameters or computation complexity. Depth-aware CoordConv uses depth data to extract prior information about the location of an object to achieve highly accurate object instance segmentation. These resulting segmentation masks, combined with predicted grasp candidates, lead to a complete scene description for grasping using a parallel-plate gripper. We evaluate the accuracy of grasp detection and instance segmentation on challenging robotic picking datasets, namely Sil\'eane and OCID_grasp, and show the benefit of joint grasp detection and segmentation on a real-world robotic picking task.