 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Detecting Escalation Level from Speech with Transfer Learning and Acoustic-Lexical Information Fusion
Apr 13, 2021
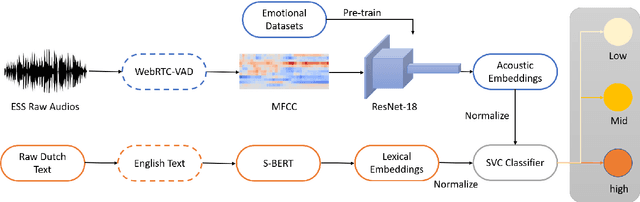
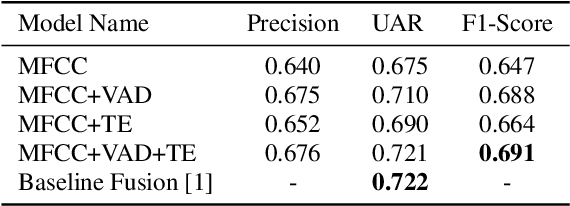
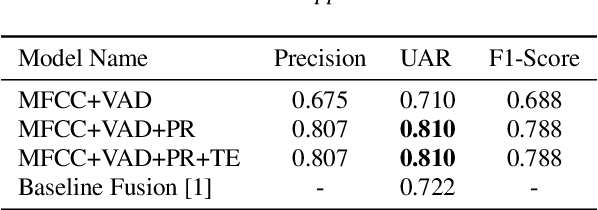
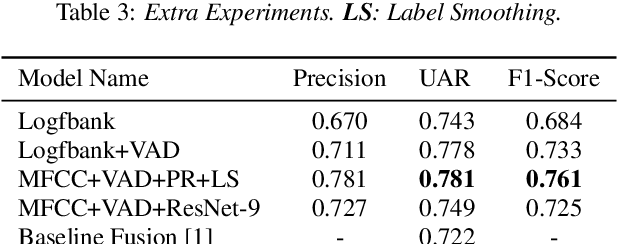
Textual escalation detection has been widely applied to e-commerce companies' customer service systems to pre-alert and prevent potential conflicts. Similarly, in public areas such as airports and train stations, where many impersonal conversations frequently take place, acoustic-based escalation detection systems are also useful to enhance passengers' safety and maintain public order. To this end, we introduce a system based on acoustic-lexical features to detect escalation from speech, Voice Activity Detection (VAD) and label smoothing are adopted to further enhance the performance in our experiments. Considering a small set of training and development data, we also employ transfer learning on several well-known emotional detection datasets, i.e. RAVDESS, CREMA-D, to learn advanced emotional representations that can be applied to the escalation detection task. On the development set, our proposed system achieves 81.5% unweighted average recall (UAR) which significantly outperforms the baseline with 72.2% UAR.
Trash or Treasure? An Interactive Dual-Stream Strategy for Single Image Reflection Separation
Oct 20, 2021
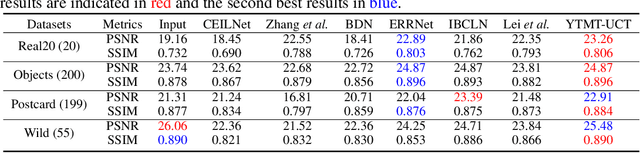
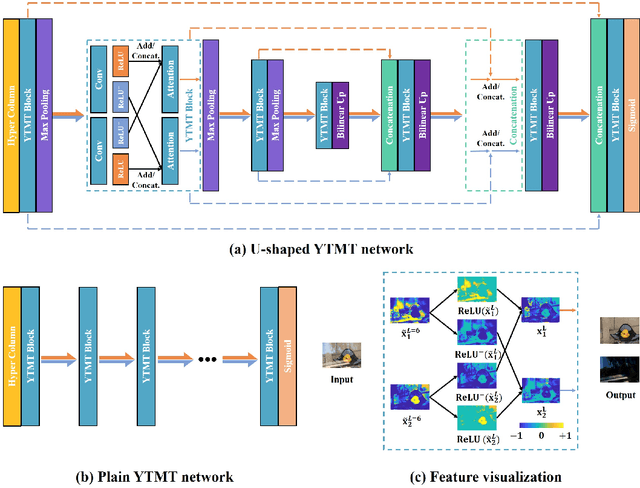
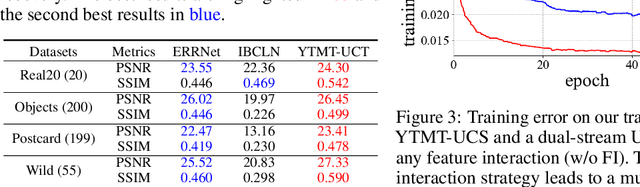
Single image reflection separation (SIRS), as a representative blind source separation task, aims to recover two layers, $\textit{i.e.}$, transmission and reflection, from one mixed observation, which is challenging due to the highly ill-posed nature. Existing deep learning based solutions typically restore the target layers individually, or with some concerns at the end of the output, barely taking into account the interaction across the two streams/branches. In order to utilize information more efficiently, this work presents a general yet simple interactive strategy, namely $\textit{your trash is my treasure}$ (YTMT), for constructing dual-stream decomposition networks. To be specific, we explicitly enforce the two streams to communicate with each other block-wisely. Inspired by the additive property between the two components, the interactive path can be easily built via transferring, instead of discarding, deactivated information by the ReLU rectifier from one stream to the other. Both ablation studies and experimental results on widely-used SIRS datasets are conducted to demonstrate the efficacy of YTMT, and reveal its superiority over other state-of-the-art alternatives. The implementation is quite simple and our code is publicly available at $\href{https://github.com/mingcv/YTMT-Strategy}{\textit{https://github.com/mingcv/YTMT-Strategy}}$.
Exploring Story Generation with Multi-task Objectives in Variational Autoencoders
Nov 15, 2021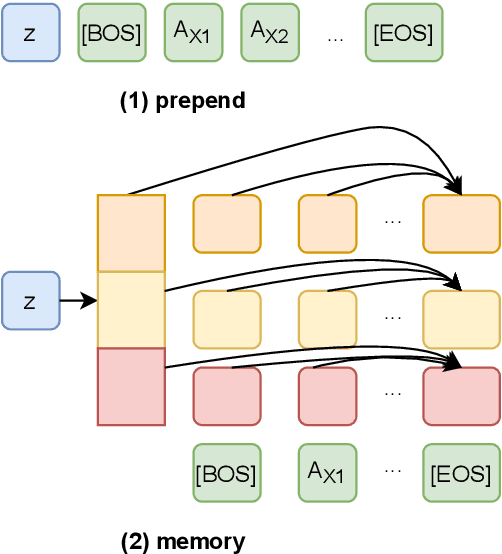

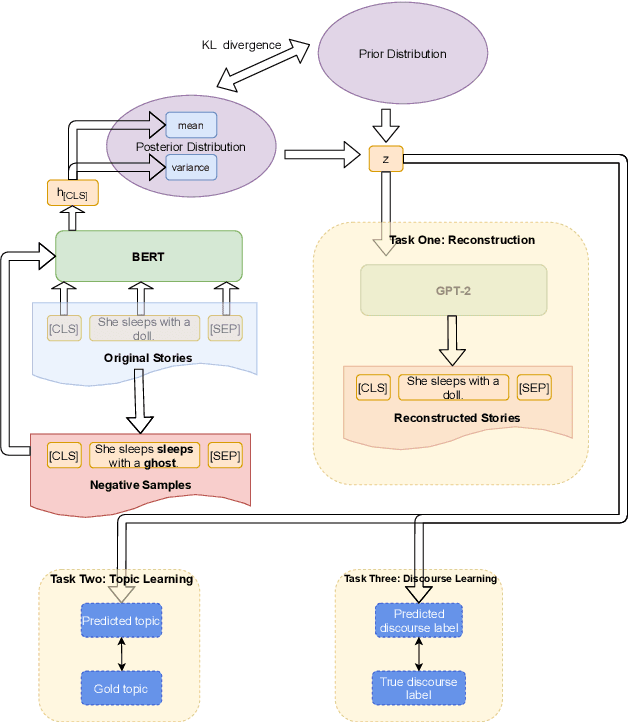
GPT-2 has been frequently adapted in story generation models as it provides powerful generative capability. However, it still fails to generate consistent stories and lacks diversity. Current story generation models leverage additional information such as plots or commonsense into GPT-2 to guide the generation process. These approaches focus on improving generation quality of stories while our work look at both quality and diversity. We explore combining BERT and GPT-2 to build a variational autoencoder (VAE), and extend it by adding additional objectives to learn global features such as story topic and discourse relations. Our evaluations show our enhanced VAE can provide better quality and diversity trade off, generate less repetitive story content and learn a more informative latent variable.
LUNAR: Unifying Local Outlier Detection Methods via Graph Neural Networks
Dec 10, 2021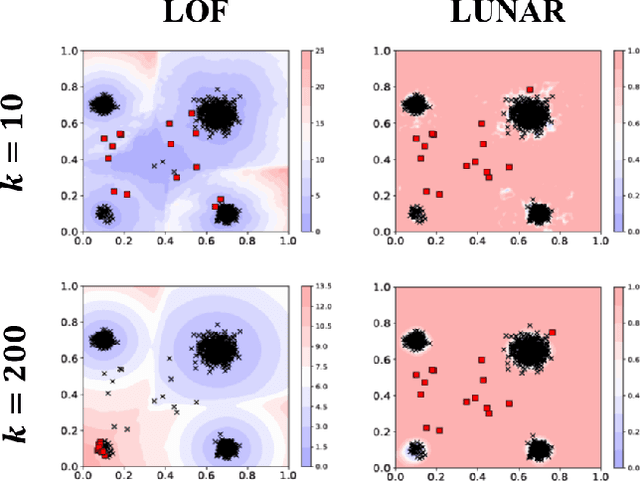
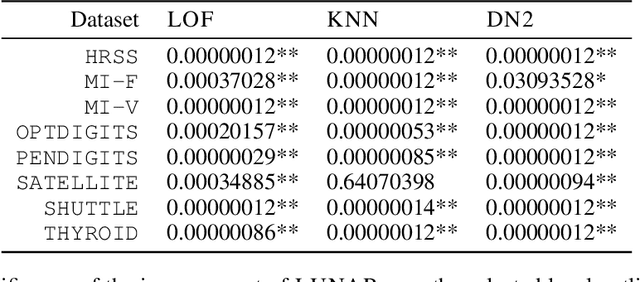
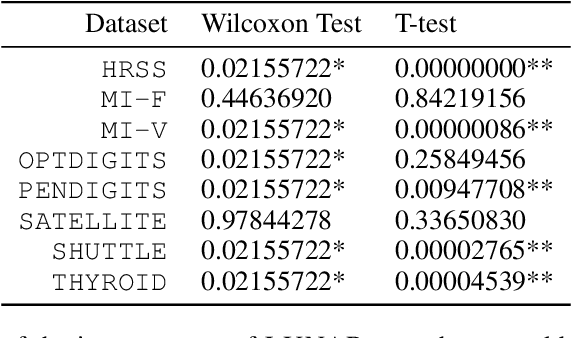
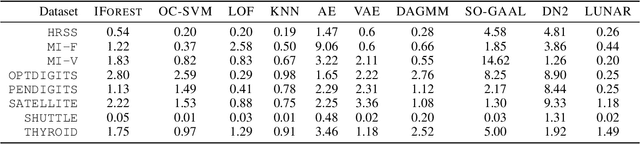
Many well-established anomaly detection methods use the distance of a sample to those in its local neighbourhood: so-called `local outlier methods', such as LOF and DBSCAN. They are popular for their simple principles and strong performance on unstructured, feature-based data that is commonplace in many practical applications. However, they cannot learn to adapt for a particular set of data due to their lack of trainable parameters. In this paper, we begin by unifying local outlier methods by showing that they are particular cases of the more general message passing framework used in graph neural networks. This allows us to introduce learnability into local outlier methods, in the form of a neural network, for greater flexibility and expressivity: specifically, we propose LUNAR, a novel, graph neural network-based anomaly detection method. LUNAR learns to use information from the nearest neighbours of each node in a trainable way to find anomalies. We show that our method performs significantly better than existing local outlier methods, as well as state-of-the-art deep baselines. We also show that the performance of our method is much more robust to different settings of the local neighbourhood size.
Elastic-Link for Binarized Neural Network
Dec 19, 2021
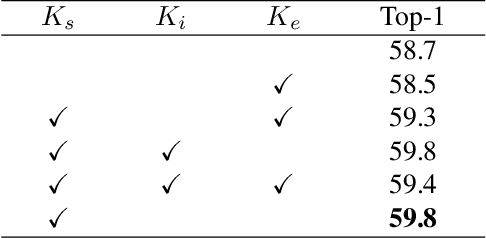
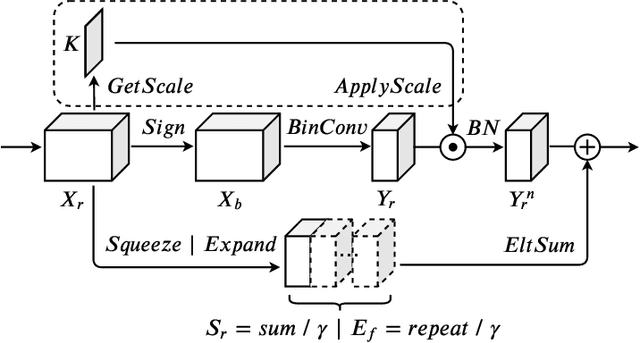
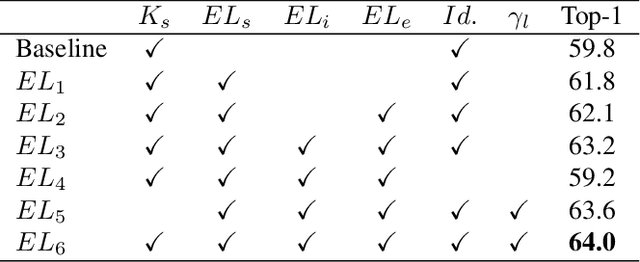
Recent work has shown that Binarized Neural Networks (BNNs) are able to greatly reduce computational costs and memory footprints, facilitating model deployment on resource-constrained devices. However, in comparison to their full-precision counterparts, BNNs suffer from severe accuracy degradation. Research aiming to reduce this accuracy gap has thus far largely focused on specific network architectures with few or no 1x1 convolutional layers, for which standard binarization methods do not work well. Because 1x1 convolutions are common in the design of modern architectures (e.g. GoogleNet, ResNet, DenseNet), it is crucial to develop a method to binarize them effectively for BNNs to be more widely adopted. In this work, we propose an "Elastic-Link" (EL) module to enrich information flow within a BNN by adaptively adding real-valued input features to the subsequent convolutional output features. The proposed EL module is easily implemented and can be used in conjunction with other methods for BNNs. We demonstrate that adding EL to BNNs produces a significant improvement on the challenging large-scale ImageNet dataset. For example, we raise the top-1 accuracy of binarized ResNet26 from 57.9% to 64.0%. EL also aids convergence in the training of binarized MobileNet, for which a top-1 accuracy of 56.4% is achieved. Finally, with the integration of ReActNet, it yields a new state-of-the-art result of 71.9% top-1 accuracy.
Data-Free Knowledge Transfer: A Survey
Dec 31, 2021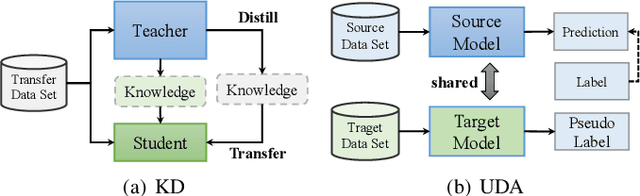

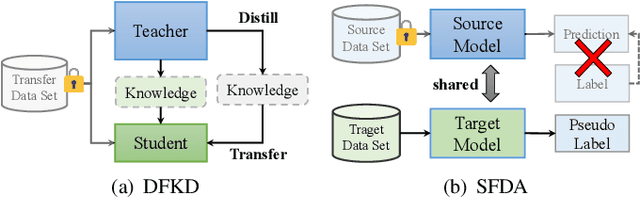
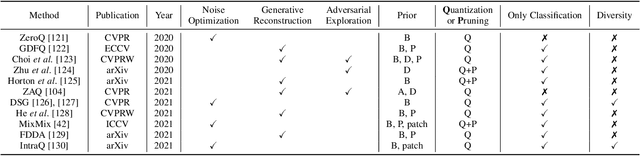
In the last decade, many deep learning models have been well trained and made a great success in various fields of machine intelligence, especially for computer vision and natural language processing. To better leverage the potential of these well-trained models in intra-domain or cross-domain transfer learning situations, knowledge distillation (KD) and domain adaptation (DA) are proposed and become research highlights. They both aim to transfer useful information from a well-trained model with original training data. However, the original data is not always available in many cases due to privacy, copyright or confidentiality. Recently, the data-free knowledge transfer paradigm has attracted appealing attention as it deals with distilling valuable knowledge from well-trained models without requiring to access to the training data. In particular, it mainly consists of the data-free knowledge distillation (DFKD) and source data-free domain adaptation (SFDA). On the one hand, DFKD aims to transfer the intra-domain knowledge of original data from a cumbersome teacher network to a compact student network for model compression and efficient inference. On the other hand, the goal of SFDA is to reuse the cross-domain knowledge stored in a well-trained source model and adapt it to a target domain. In this paper, we provide a comprehensive survey on data-free knowledge transfer from the perspectives of knowledge distillation and unsupervised domain adaptation, to help readers have a better understanding of the current research status and ideas. Applications and challenges of the two areas are briefly reviewed, respectively. Furthermore, we provide some insights to the subject of future research.
LCTR: On Awakening the Local Continuity of Transformer for Weakly Supervised Object Localization
Dec 10, 2021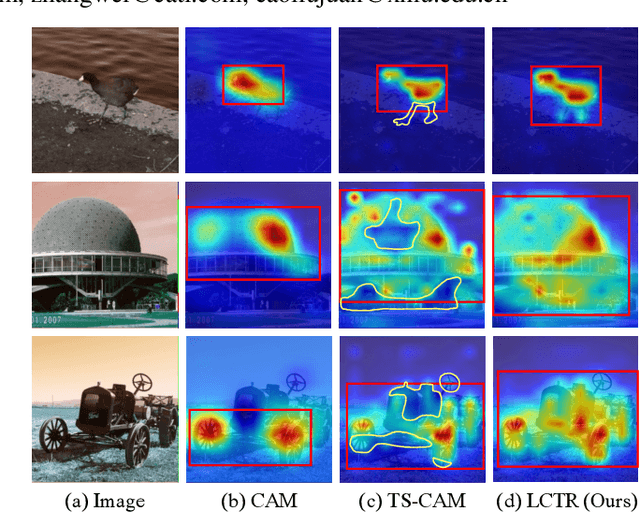
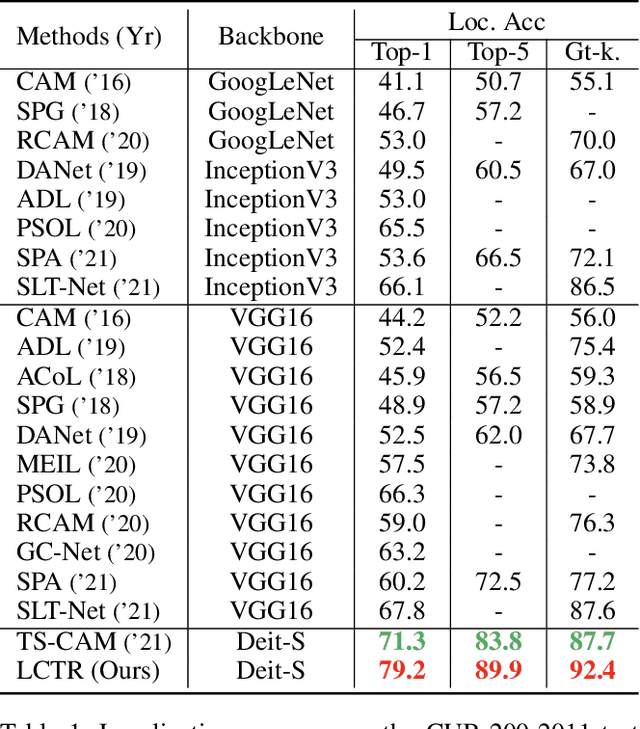
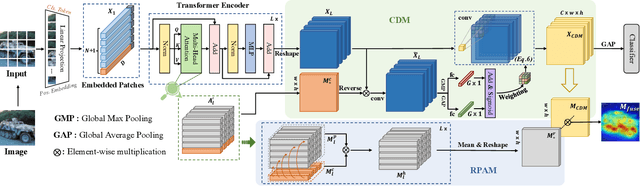
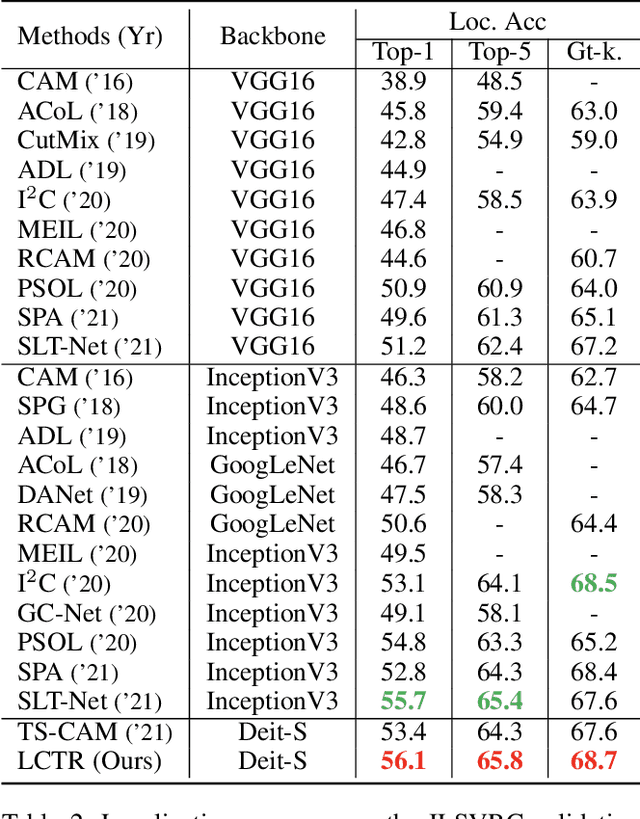
Weakly supervised object localization (WSOL) aims to learn object localizer solely by using image-level labels. The convolution neural network (CNN) based techniques often result in highlighting the most discriminative part of objects while ignoring the entire object extent. Recently, the transformer architecture has been deployed to WSOL to capture the long-range feature dependencies with self-attention mechanism and multilayer perceptron structure. Nevertheless, transformers lack the locality inductive bias inherent to CNNs and therefore may deteriorate local feature details in WSOL. In this paper, we propose a novel framework built upon the transformer, termed LCTR (Local Continuity TRansformer), which targets at enhancing the local perception capability of global features among long-range feature dependencies. To this end, we propose a relational patch-attention module (RPAM), which considers cross-patch information on a global basis. We further design a cue digging module (CDM), which utilizes local features to guide the learning trend of the model for highlighting the weak local responses. Finally, comprehensive experiments are carried out on two widely used datasets, ie, CUB-200-2011 and ILSVRC, to verify the effectiveness of our method.
Long-Range Thermal 3D Perception in Low Contrast Environments
Dec 10, 2021
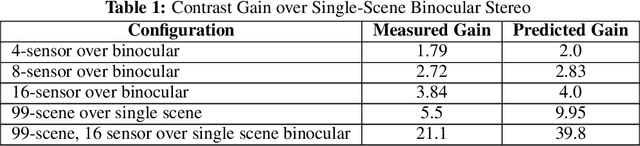


This report discusses the results of SBIR Phase I effort to prove the feasibility of dramatic improvement of the microbolometer-based Long Wave Infrared (LWIR) detectors sensitivity, especially for the 3D measurements. The resulting low SWaP-C thermal depth-sensing system will enable the situational awareness of Autonomous Air Vehicles for Advanced Air Mobility (AAM). It will provide robust 3D information of the surrounding environment, including low-contrast static and moving objects, at far distances in degraded visual conditions and GPS-denied areas. Our multi-sensor 3D perception enabled by COTS uncooled thermal sensors mitigates major weakness of LWIR sensors - low contrast by increasing the system sensitivity over an order of magnitude. There were no available thermal image sets suitable for evaluating this technology, making datasets acquisition our first goal. We discuss the design and construction of the prototype system with sixteen 640pix x 512pix LWIR detectors, camera calibration to subpixel resolution, capture, and process synchronized image. The results show the 3.84x contrast increase for intrascene-only data and an additional 5.5x - with the interscene accumulation, reaching system noise-equivalent temperature difference (NETD) of 1.9 mK with the 40 mK sensors.
Node Feature Extraction by Self-Supervised Multi-scale Neighborhood Prediction
Oct 29, 2021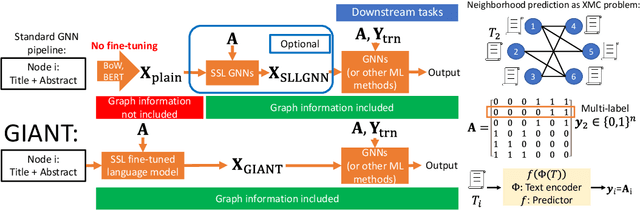

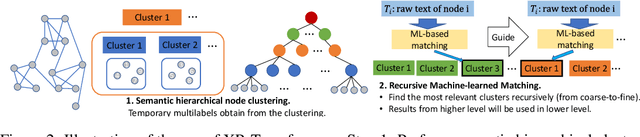
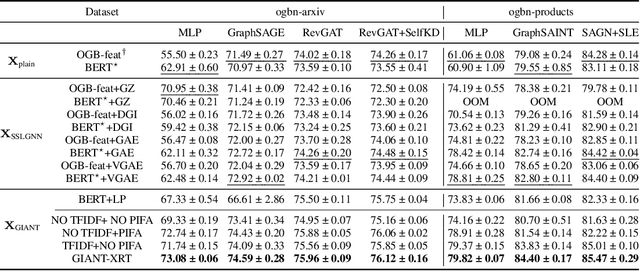
Learning on graphs has attracted significant attention in the learning community due to numerous real-world applications. In particular, graph neural networks (GNNs), which take numerical node features and graph structure as inputs, have been shown to achieve state-of-the-art performance on various graph-related learning tasks. Recent works exploring the correlation between numerical node features and graph structure via self-supervised learning have paved the way for further performance improvements of GNNs. However, methods used for extracting numerical node features from raw data are still graph-agnostic within standard GNN pipelines. This practice is sub-optimal as it prevents one from fully utilizing potential correlations between graph topology and node attributes. To mitigate this issue, we propose a new self-supervised learning framework, Graph Information Aided Node feature exTraction (GIANT). GIANT makes use of the eXtreme Multi-label Classification (XMC) formalism, which is crucial for fine-tuning the language model based on graph information, and scales to large datasets. We also provide a theoretical analysis that justifies the use of XMC over link prediction and motivates integrating XR-Transformers, a powerful method for solving XMC problems, into the GIANT framework. We demonstrate the superior performance of GIANT over the standard GNN pipeline on Open Graph Benchmark datasets: For example, we improve the accuracy of the top-ranked method GAMLP from $68.25\%$ to $69.67\%$, SGC from $63.29\%$ to $66.10\%$ and MLP from $47.24\%$ to $61.10\%$ on the ogbn-papers100M dataset by leveraging GIANT.
Active Sensing for Search and Tracking: A Review
Dec 04, 2021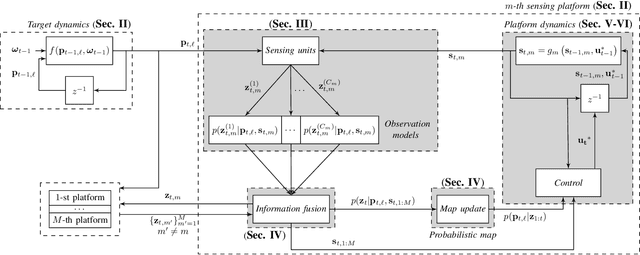
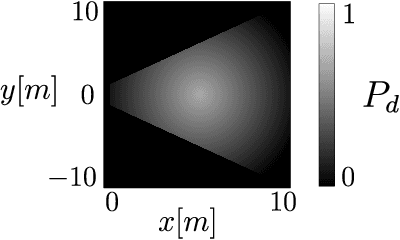
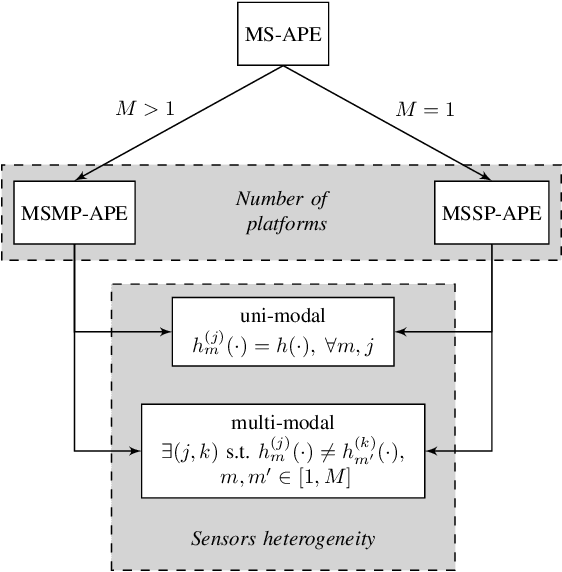
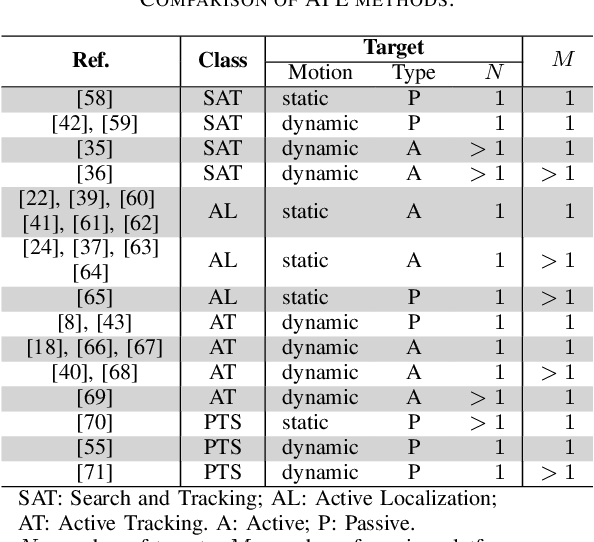
Active Position Estimation (APE) is the task of localizing one or more targets using one or more sensing platforms. APE is a key task for search and rescue missions, wildlife monitoring, source term estimation, and collaborative mobile robotics. Success in APE depends on the level of cooperation of the sensing platforms, their number, their degrees of freedom and the quality of the information gathered. APE control laws enable active sensing by satisfying either pure-exploitative or pure-explorative criteria. The former minimizes the uncertainty on position estimation; whereas the latter drives the platform closer to its task completion. In this paper, we define the main elements of APE to systematically classify and critically discuss the state of the art in this domain. We also propose a reference framework as a formalism to classify APE-related solutions. Overall, this survey explores the principal challenges and envisages the main research directions in the field of autonomous perception systems for localization tasks. It is also beneficial to promote the development of robust active sensing methods for search and tracking applications.