 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Testing the Generalization of Neural Language Models for COVID-19 Misinformation Detection
Nov 29, 2021

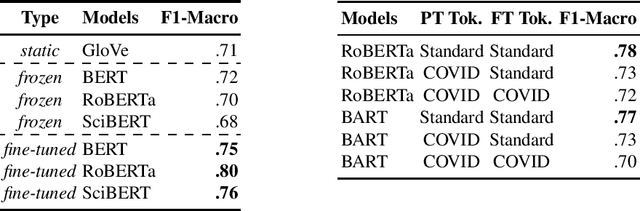
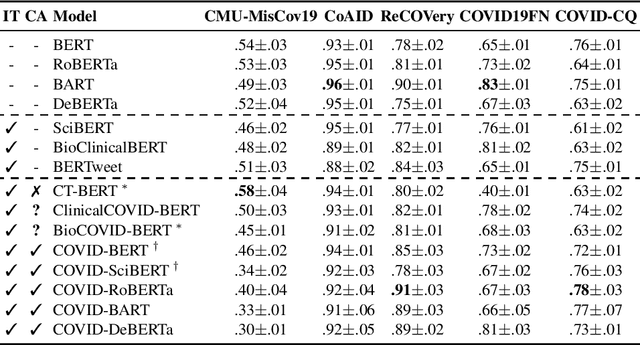
A drastic rise in potentially life-threatening misinformation has been a by-product of the COVID-19 pandemic. Computational support to identify false information within the massive body of data on the topic is crucial to prevent harm. Researchers proposed many methods for flagging online misinformation related to COVID-19. However, these methods predominantly target specific content types (e.g., news) or platforms (e.g., Twitter). The methods' capabilities to generalize were largely unclear so far. We evaluate fifteen Transformer-based models on five COVID-19 misinformation datasets that include social media posts, news articles, and scientific papers to fill this gap. We show tokenizers and models tailored to COVID-19 data do not provide a significant advantage over general-purpose ones. Our study provides a realistic assessment of models for detecting COVID-19 misinformation. We expect that evaluating a broad spectrum of datasets and models will benefit future research in developing misinformation detection systems.
Representation Edit Distance as a Measure of Novelty
Nov 04, 2021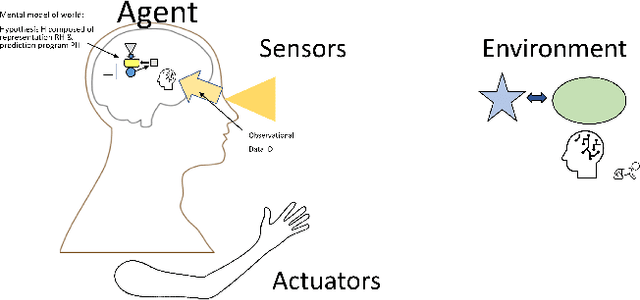
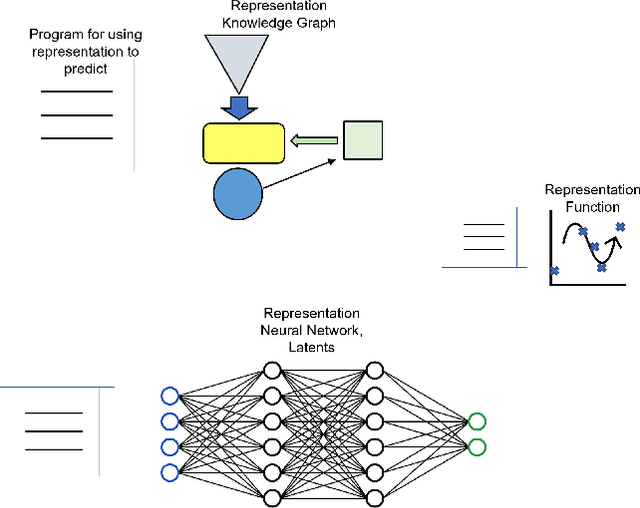
Adaptation to novelty is viewed as learning to change and augment existing skills to confront unfamiliar situations. In this paper, we propose that the amount of editing of an effective representation (the Representation Edit Distance or RED) used in a set of skill programs in an agent's mental model is a measure of difficulty for adaptation to novelty. The RED is an intuitive approximation to the change in information content in bit strings measured by comparing pre-novelty and post-novelty skill programs. We also present some notional examples of how to use RED for predicting difficulty.
Expert and Crowd-Guided Affect Annotation and Prediction
Dec 15, 2021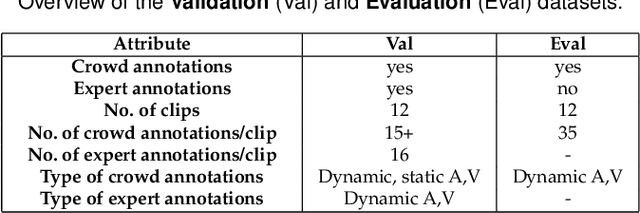
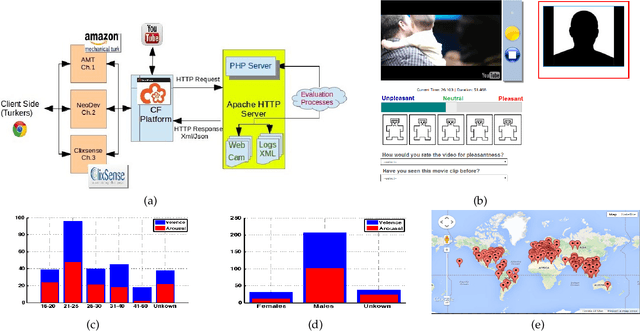

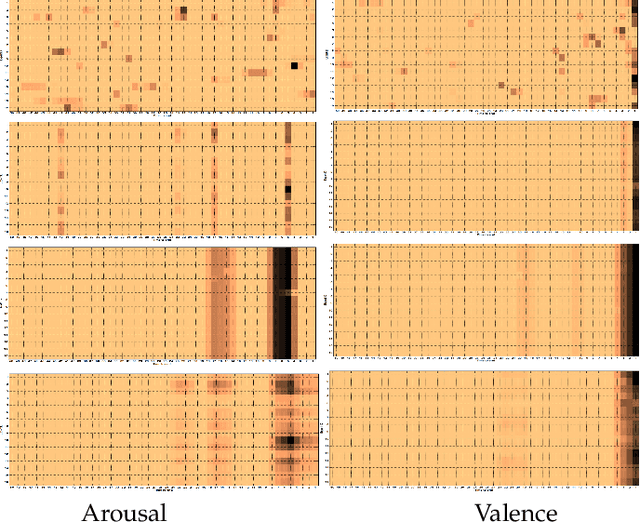
We employ crowdsourcing to acquire time-continuous affective annotations for movie clips, and refine noisy models trained from these crowd annotations incorporating expert information within a Multi-task Learning (MTL) framework. We propose a novel \textbf{e}xpert \textbf{g}uided MTL (EG-MTL) algorithm, which minimizes the loss with respect to both crowd and expert labels to learn a set of weights corresponding to each movie clip for which crowd annotations are acquired. We employ EG-MTL to solve two problems, namely, \textbf{\texttt{P1}}: where dynamic annotations acquired from both experts and crowdworkers for the \textbf{Validation} set are used to train a regression model with audio-visual clip descriptors as features, and predict dynamic arousal and valence levels on 5--15 second snippets derived from the clips; and \textbf{\texttt{P2}}: where a classification model trained on the \textbf{Validation} set using dynamic crowd and expert annotations (as features) and static affective clip labels is used for binary emotion recognition on the \textbf{Evaluation} set for which only dynamic crowd annotations are available. Observed experimental results confirm the effectiveness of the EG-MTL algorithm, which is reflected via improved arousal and valence estimation for \textbf{\texttt{P1}}, and higher recognition accuracy for \textbf{\texttt{P2}}.
Reliable Multi-Object Tracking in the Presence of Unreliable Detections
Dec 15, 2021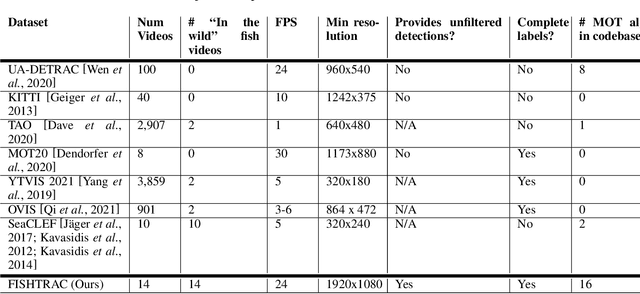
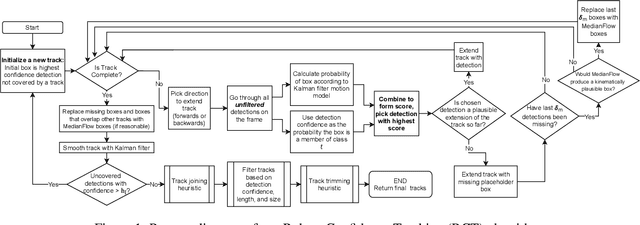
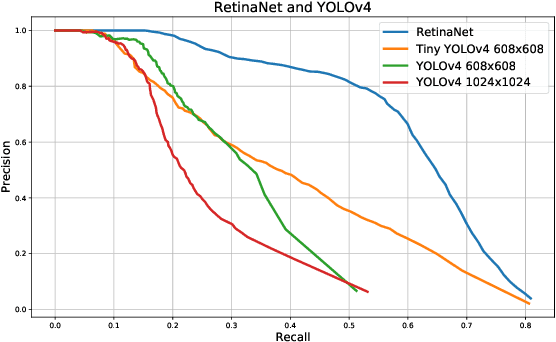
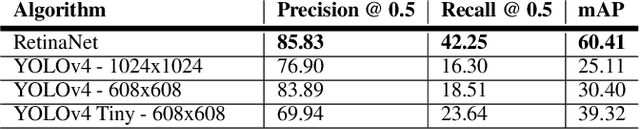
Recent multi-object tracking (MOT) systems have leveraged highly accurate object detectors; however, training such detectors requires large amounts of labeled data. Although such data is widely available for humans and vehicles, it is significantly more scarce for other animal species. We present Robust Confidence Tracking (RCT), an algorithm designed to maintain robust performance even when detection quality is poor. In contrast to prior methods which discard detection confidence information, RCT takes a fundamentally different approach, relying on the exact detection confidence values to initialize tracks, extend tracks, and filter tracks. In particular, RCT is able to minimize identity switches by efficiently using low-confidence detections (along with a single object tracker) to keep continuous track of objects. To evaluate trackers in the presence of unreliable detections, we present a challenging real-world underwater fish tracking dataset, FISHTRAC. In an evaluation on FISHTRAC as well as the UA-DETRAC dataset, we find that RCT outperforms other algorithms when provided with imperfect detections, including state-of-the-art deep single and multi-object trackers as well as more classic approaches. Specifically, RCT has the best average HOTA across methods that successfully return results for all sequences, and has significantly less identity switches than other methods.
Encoding Causal Macrovariables
Nov 29, 2021
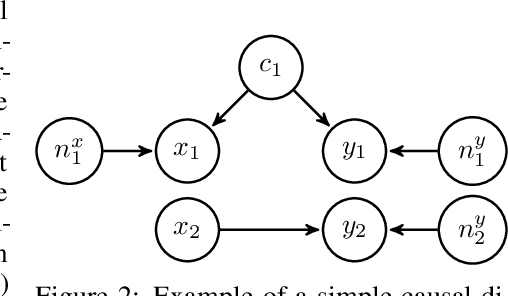

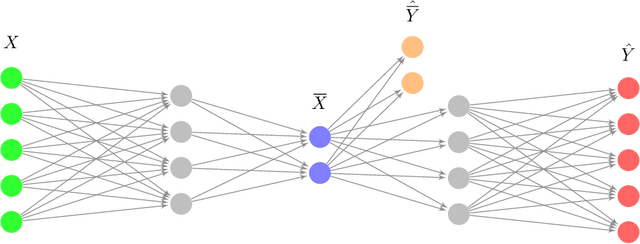
In many scientific disciplines, coarse-grained causal models are used to explain and predict the dynamics of more fine-grained systems. Naturally, such models require appropriate macrovariables. Automated procedures to detect suitable variables would be useful to leverage increasingly available high-dimensional observational datasets. This work introduces a novel algorithmic approach that is inspired by a new characterisation of causal macrovariables as information bottlenecks between microstates. Its general form can be adapted to address individual needs of different scientific goals. After a further transformation step, the causal relationships between learned variables can be investigated through additive noise models. Experiments on both simulated data and on a real climate dataset are reported. In a synthetic dataset, the algorithm robustly detects the ground-truth variables and correctly infers the causal relationships between them. In a real climate dataset, the algorithm robustly detects two variables that correspond to the two known variations of the El Nino phenomenon.
A Broad-persistent Advising Approach for Deep Interactive Reinforcement Learning in Robotic Environments
Oct 15, 2021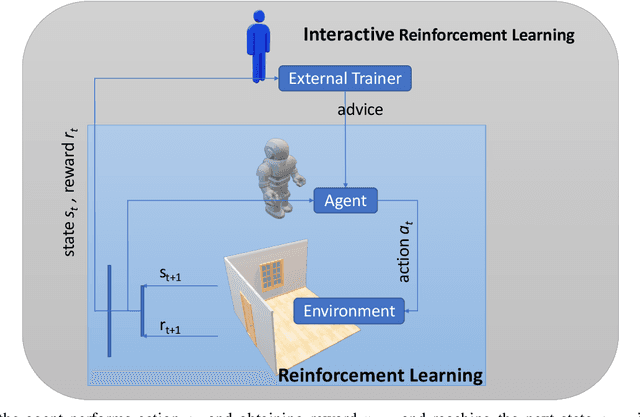
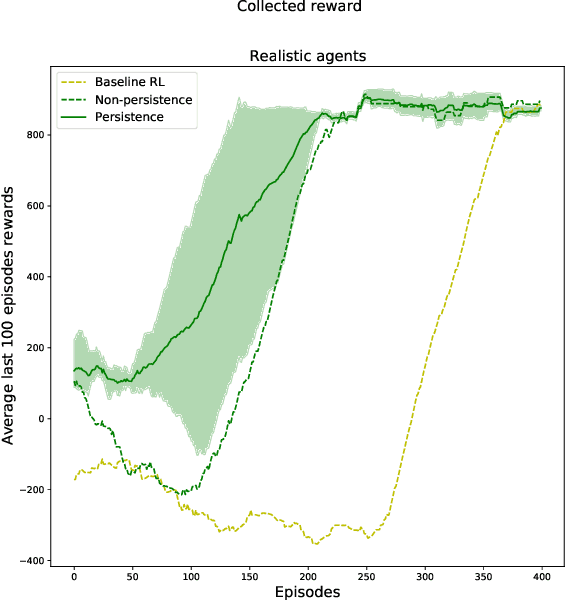
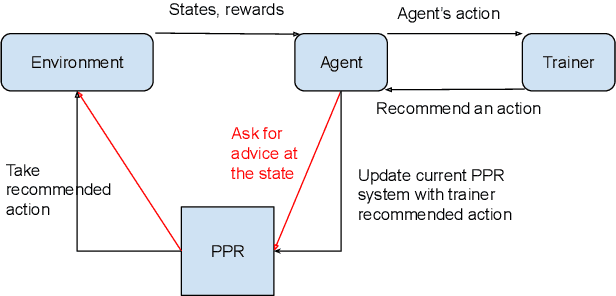
Deep Reinforcement Learning (DeepRL) methods have been widely used in robotics to learn about the environment and acquire behaviors autonomously. Deep Interactive Reinforcement Learning (DeepIRL) includes interactive feedback from an external trainer or expert giving advice to help learners choosing actions to speed up the learning process. However, current research has been limited to interactions that offer actionable advice to only the current state of the agent. Additionally, the information is discarded by the agent after a single use that causes a duplicate process at the same state for a revisit. In this paper, we present Broad-persistent Advising (BPA), a broad-persistent advising approach that retains and reuses the processed information. It not only helps trainers to give more general advice relevant to similar states instead of only the current state but also allows the agent to speed up the learning process. We test the proposed approach in two continuous robotic scenarios, namely, a cart pole balancing task and a simulated robot navigation task. The obtained results show that the performance of the agent using BPA improves while keeping the number of interactions required for the trainer in comparison to the DeepIRL approach.
In-painting Radiography Images for Unsupervised Anomaly Detection
Nov 26, 2021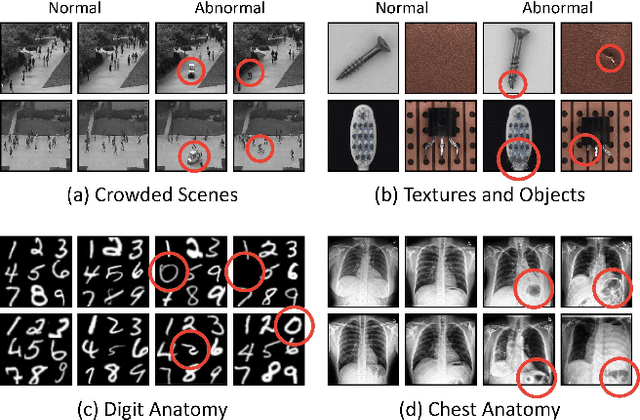
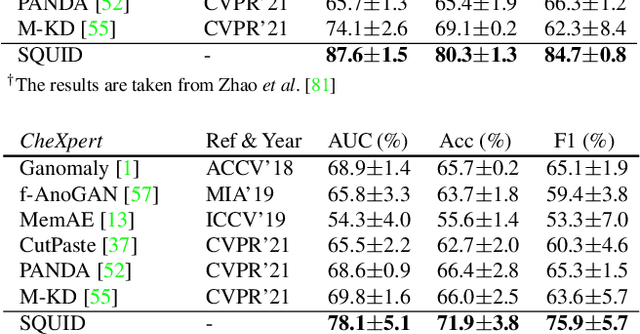
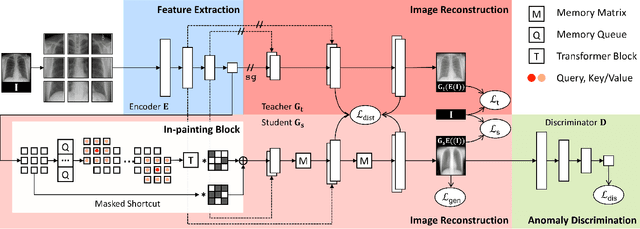
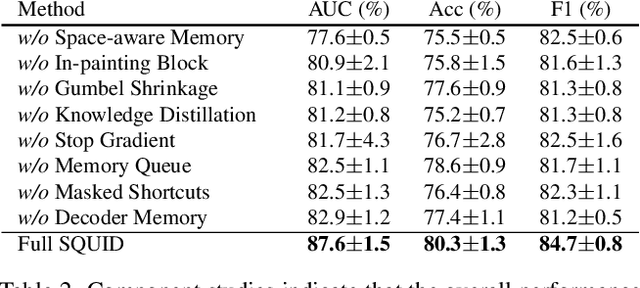
We propose space-aware memory queues for in-painting and detecting anomalies from radiography images (abbreviated as SQUID). Radiography imaging protocols focus on particular body regions, therefore producing images of great similarity and yielding recurrent anatomical structures across patients. To exploit this structured information, our SQUID consists of a new Memory Queue and a novel in-painting block in the feature space. We show that SQUID can taxonomize the ingrained anatomical structures into recurrent patterns; and in the inference, SQUID can identify anomalies (unseen/modified patterns) in the image. SQUID surpasses the state of the art in unsupervised anomaly detection by over 5 points on two chest X-ray benchmark datasets. Additionally, we have created a new dataset (DigitAnatomy), which synthesizes the spatial correlation and consistent shape in chest anatomy. We hope DigitAnatomy can prompt the development, evaluation, and interpretability of anomaly detection methods, particularly for radiography imaging.
Lifelong Generative Modelling Using Dynamic Expansion Graph Model
Dec 15, 2021
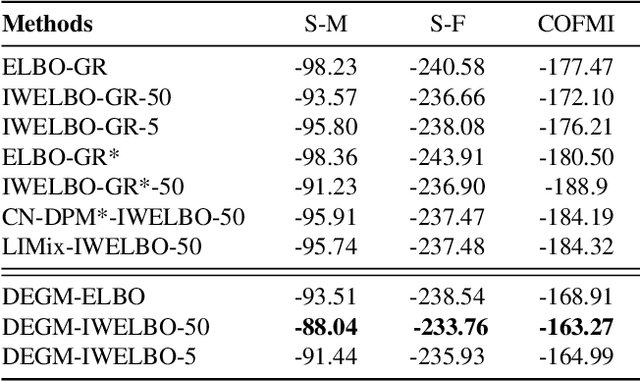
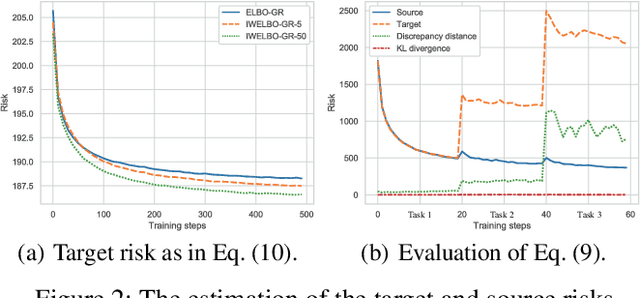
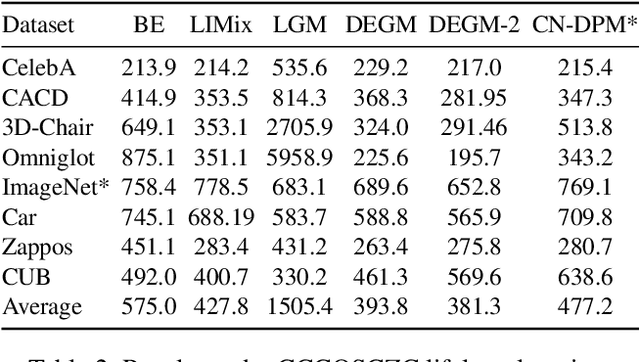
Variational Autoencoders (VAEs) suffer from degenerated performance, when learning several successive tasks. This is caused by catastrophic forgetting. In order to address the knowledge loss, VAEs are using either Generative Replay (GR) mechanisms or Expanding Network Architectures (ENA). In this paper we study the forgetting behaviour of VAEs using a joint GR and ENA methodology, by deriving an upper bound on the negative marginal log-likelihood. This theoretical analysis provides new insights into how VAEs forget the previously learnt knowledge during lifelong learning. The analysis indicates the best performance achieved when considering model mixtures, under the ENA framework, where there are no restrictions on the number of components. However, an ENA-based approach may require an excessive number of parameters. This motivates us to propose a novel Dynamic Expansion Graph Model (DEGM). DEGM expands its architecture, according to the novelty associated with each new databases, when compared to the information already learnt by the network from previous tasks. DEGM training optimizes knowledge structuring, characterizing the joint probabilistic representations corresponding to the past and more recently learned tasks. We demonstrate that DEGM guarantees optimal performance for each task while also minimizing the required number of parameters. Supplementary materials (SM) and source code are available in https://github.com/dtuzi123/Expansion-Graph-Model.
Applying Surface Normal Information in Drivable Area and Road Anomaly Detection for Ground Mobile Robots
Aug 26, 2020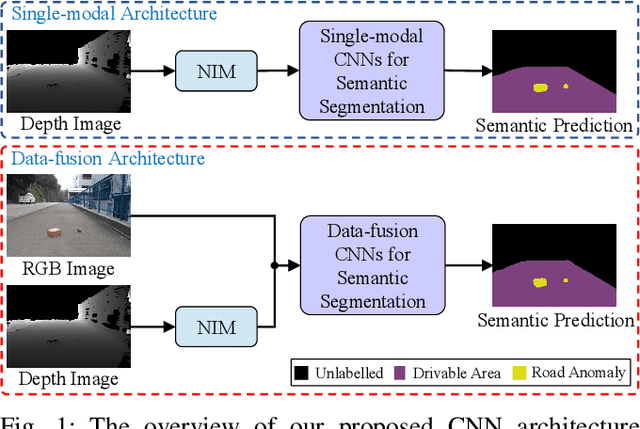
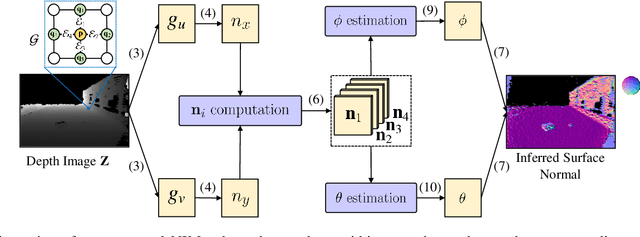
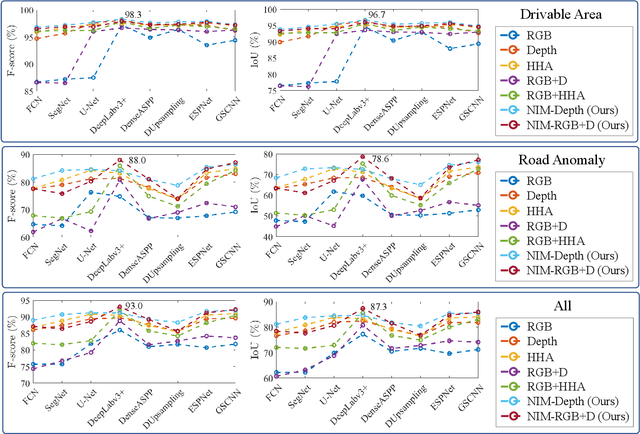
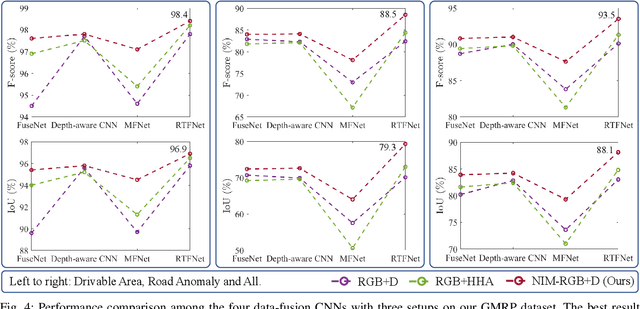
The joint detection of drivable areas and road anomalies is a crucial task for ground mobile robots. In recent years, many impressive semantic segmentation networks, which can be used for pixel-level drivable area and road anomaly detection, have been developed. However, the detection accuracy still needs improvement. Therefore, we develop a novel module named the Normal Inference Module (NIM), which can generate surface normal information from dense depth images with high accuracy and efficiency. Our NIM can be deployed in existing convolutional neural networks (CNNs) to refine the segmentation performance. To evaluate the effectiveness and robustness of our NIM, we embed it in twelve state-of-the-art CNNs. The experimental results illustrate that our NIM can greatly improve the performance of the CNNs for drivable area and road anomaly detection. Furthermore, our proposed NIM-RTFNet ranks 8th on the KITTI road benchmark and exhibits a real-time inference speed.
Urban Space Insights Extraction using Acoustic Histogram Information
Dec 14, 2020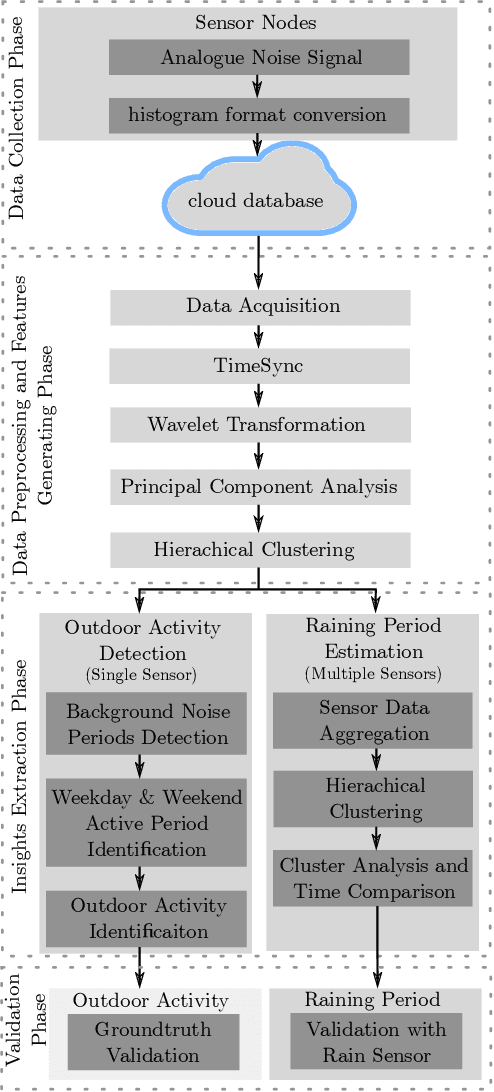

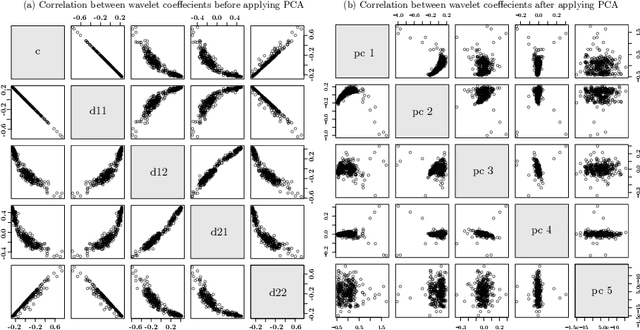
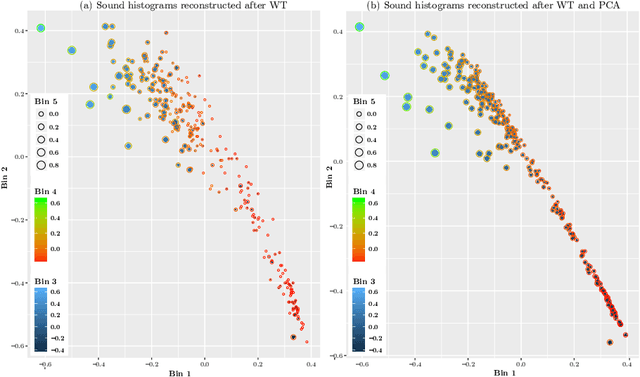
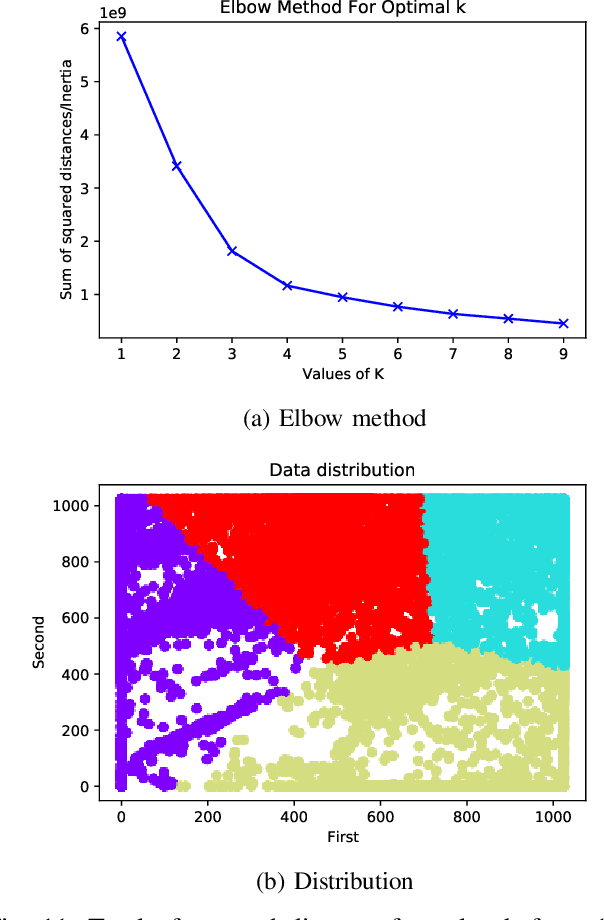
Urban data mining can be identified as a highly potential area that can enhance the smart city services towards better sustainable development especially in the urban residential activity tracking. While existing human activity tracking systems have demonstrated the capability to unveil the hidden aspects of citizens' behavior, they often come with a high implementation cost and require a large communication bandwidth. In this paper, we study the implementation of low-cost analogue sound sensors to detect outdoor activities and estimate the raining period in an urban residential area. The analogue sound sensors are transmitted to the cloud every 5 minutes in histogram format, which consists of sound data sampled every 100ms (10Hz). We then use wavelet transformation (WT) and principal component analysis (PCA) to generate a more robust and consistent feature set from the histogram. After that, we performed unsupervised clustering and attempt to understand the individual characteristics of each cluster to identify outdoor residential activities. In addition, on-site validation has been conducted to show the effectiveness of our approach.