 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pre-Training of Deep Bidirectional Protein Sequence Representations with Structural Information
Nov 25, 2019
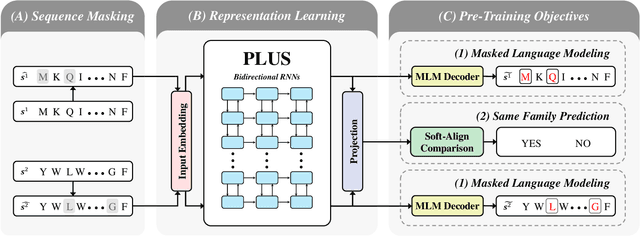
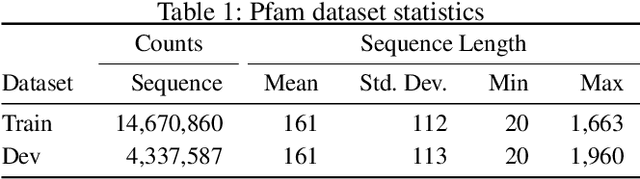
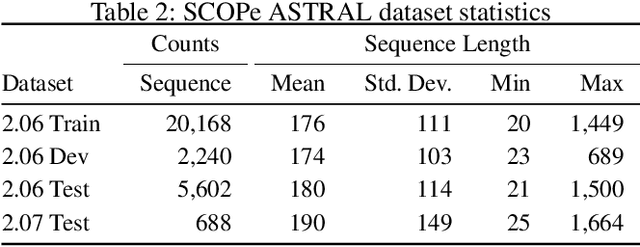
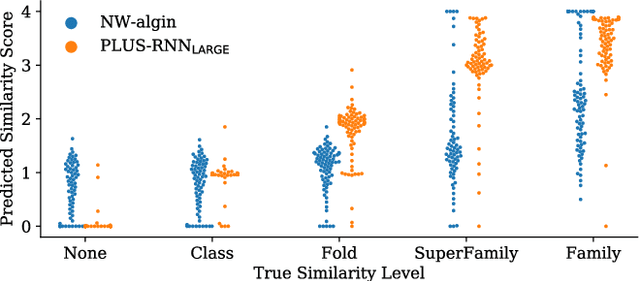
A structure of a protein has a direct impact on its properties and functions. However, identification of structural similarity directly from amino acid sequences remains as a challenging problem in computational biology. In this paper, we introduce a novel BERT-wise pre-training scheme for a protein sequence representation model called PLUS, which stands for Protein sequence representations Learned Using Structural information. As natural language representation models capture syntactic and semantic information of words from a large unlabeled text corpus, PLUS captures structural information of amino acids from a large weakly labeled protein database. Since the Transformer encoder, BERT's original model architecture, has a severe computational requirement to handle long sequences, we first propose to combine a bidirectional recurrent neural network with the BERT-wise pre-training scheme. PLUS is designed to learn protein representations with two pre-training objectives, i.e., masked language modeling and same family prediction. Then, the pre-trained model can be fine-tuned for a wide range of tasks without training randomly initialized task-specific models from scratch. It obtains new state-of-the-art results on both (1) protein-level and (2) amino-acid-level tasks, outperforming many task-specific algorithms.
Prompting Visual-Language Models for Efficient Video Understanding
Dec 08, 2021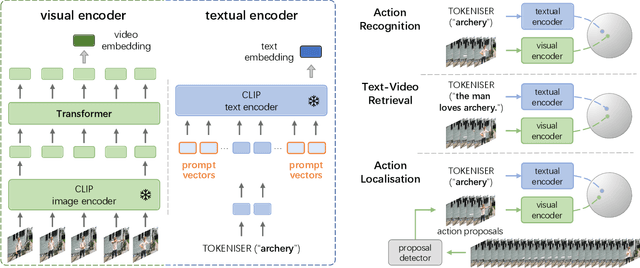
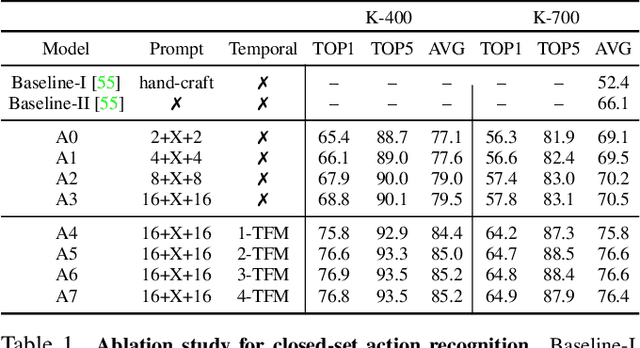
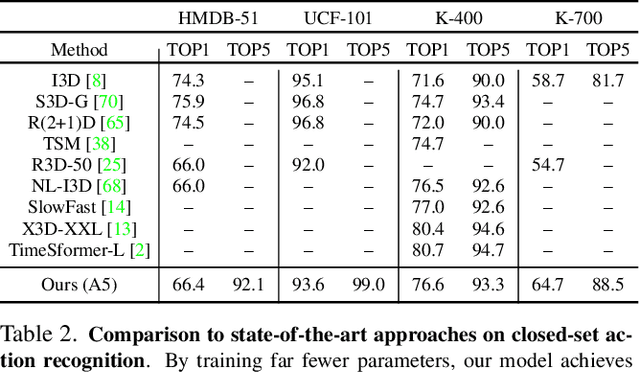
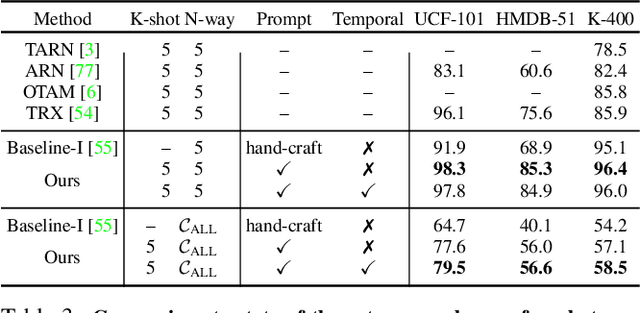
Visual-language pre-training has shown great success for learning joint visual-textual representations from large-scale web data, demonstrating remarkable ability for zero-shot generalisation. This paper presents a simple method to efficiently adapt one pre-trained visual-language model to novel tasks with minimal training, and here, we consider video understanding tasks. Specifically, we propose to optimise a few random vectors, termed as continuous prompt vectors, that convert the novel tasks into the same format as the pre-training objectives. In addition, to bridge the gap between static images and videos, temporal information is encoded with lightweight Transformers stacking on top of frame-wise visual features. Experimentally, we conduct extensive ablation studies to analyse the critical components and necessities. On 9 public benchmarks of action recognition, action localisation, and text-video retrieval, across closed-set, few-shot, open-set scenarios, we achieve competitive or state-of-the-art performance to existing methods, despite training significantly fewer parameters.
Tracking People by Predicting 3D Appearance, Location & Pose
Dec 08, 2021
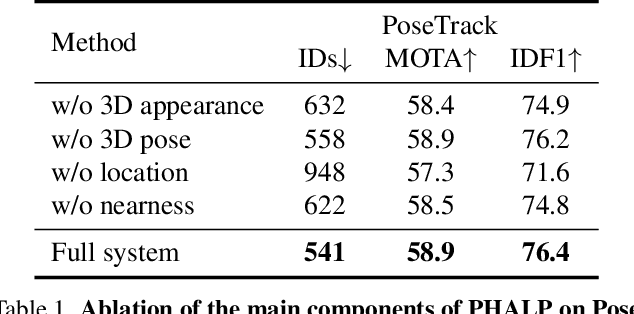
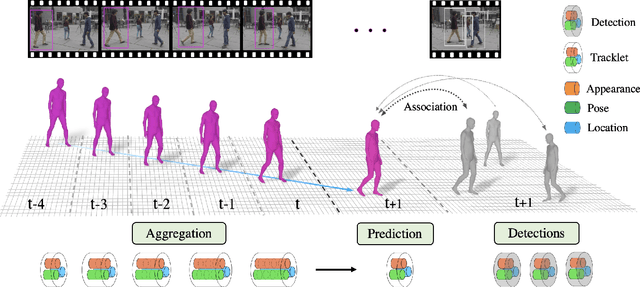

In this paper, we present an approach for tracking people in monocular videos, by predicting their future 3D representations. To achieve this, we first lift people to 3D from a single frame in a robust way. This lifting includes information about the 3D pose of the person, his or her location in the 3D space, and the 3D appearance. As we track a person, we collect 3D observations over time in a tracklet representation. Given the 3D nature of our observations, we build temporal models for each one of the previous attributes. We use these models to predict the future state of the tracklet, including 3D location, 3D appearance, and 3D pose. For a future frame, we compute the similarity between the predicted state of a tracklet and the single frame observations in a probabilistic manner. Association is solved with simple Hungarian matching, and the matches are used to update the respective tracklets. We evaluate our approach on various benchmarks and report state-of-the-art results.
HIERMATCH: Leveraging Label Hierarchies for Improving Semi-Supervised Learning
Oct 30, 2021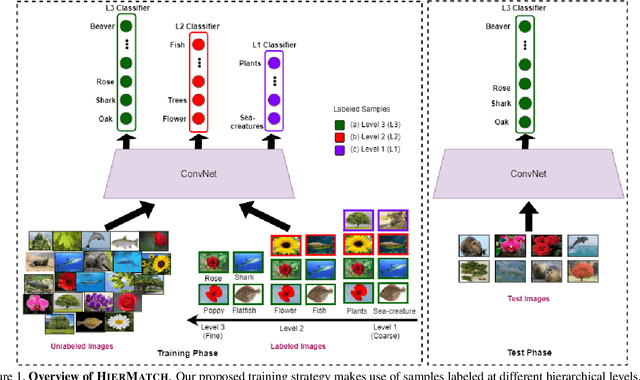
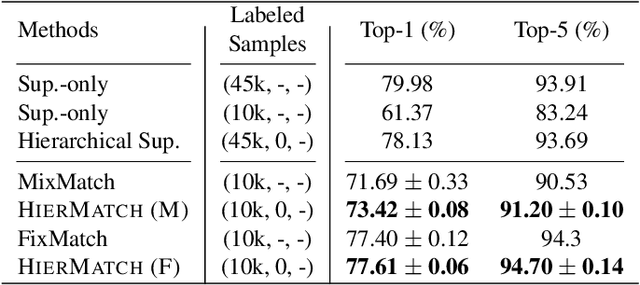
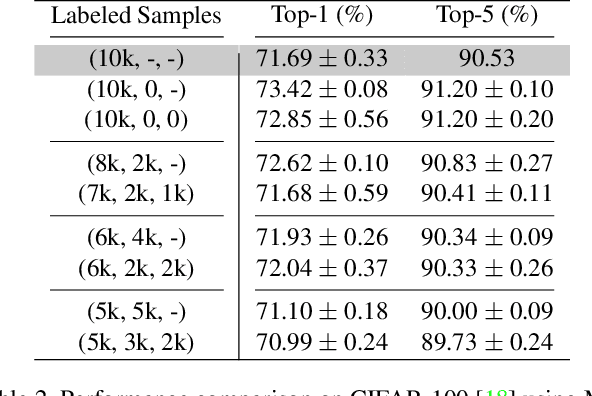
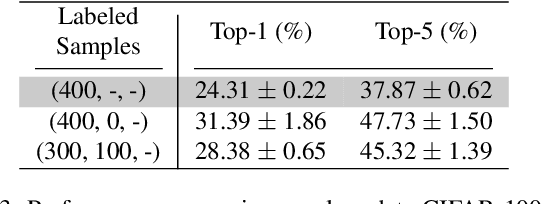
Semi-supervised learning approaches have emerged as an active area of research to combat the challenge of obtaining large amounts of annotated data. Towards the goal of improving the performance of semi-supervised learning methods, we propose a novel framework, HIERMATCH, a semi-supervised approach that leverages hierarchical information to reduce labeling costs and performs as well as a vanilla semi-supervised learning method. Hierarchical information is often available as prior knowledge in the form of coarse labels (e.g., woodpeckers) for images with fine-grained labels (e.g., downy woodpeckers or golden-fronted woodpeckers). However, the use of supervision using coarse category labels to improve semi-supervised techniques has not been explored. In the absence of fine-grained labels, HIERMATCH exploits the label hierarchy and uses coarse class labels as a weak supervisory signal. Additionally, HIERMATCH is a generic-approach to improve any semisupervised learning framework, we demonstrate this using our results on recent state-of-the-art techniques MixMatch and FixMatch. We evaluate the efficacy of HIERMATCH on two benchmark datasets, namely CIFAR-100 and NABirds. HIERMATCH can reduce the usage of fine-grained labels by 50% on CIFAR-100 with only a marginal drop of 0.59% in top-1 accuracy as compared to MixMatch.
CRLB Approaching Pilot-aided Phase and Channel Estimation Algorithm in MIMO Systems with Phase Noise and Quasi-Static Channel Fading
Dec 05, 2021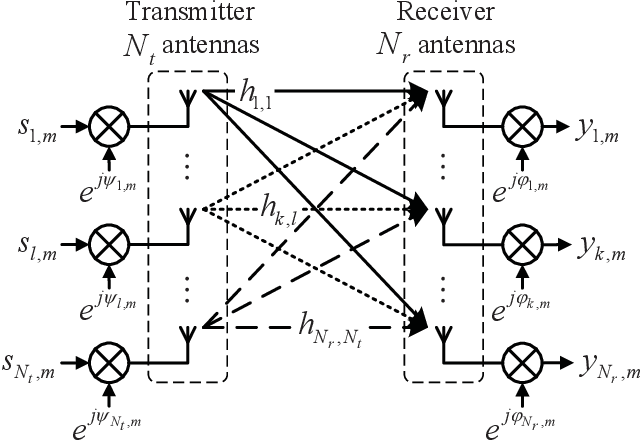
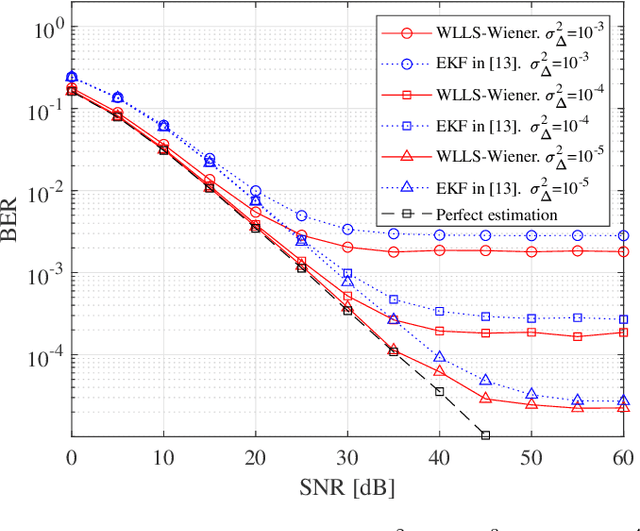
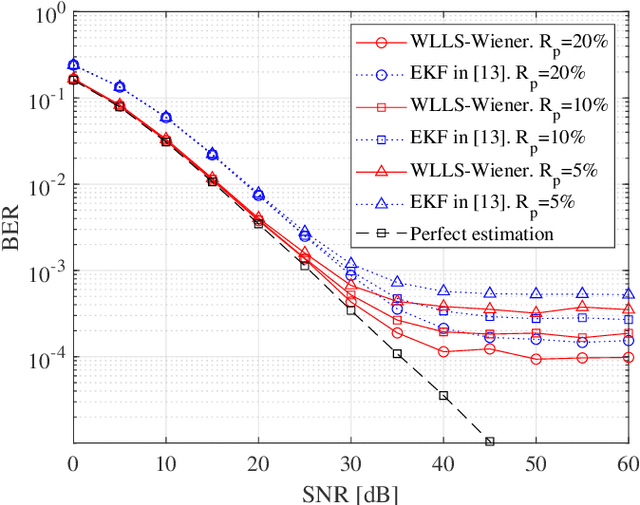
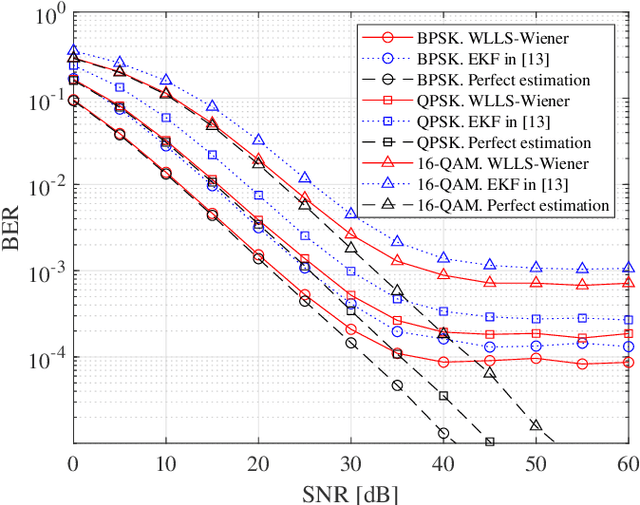
This paper derives a novel pilot-aided phase and channel estimation algorithm for multiple-input multiple-output (MIMO) systems with phase noise and quasi-static channel fading. Our novel approach allows, for the first time, carrier phase estimation and recovery to be performed before full channel estimation. This in turn enables the channel estimation to be calculated using the whole frame, significantly improving its accuracy. The proposed algorithm is a sequential combination of several linear algorithms, which greatly reduces the computational complexity. Moreover, we also derive, for the first time, the Cramer-Rao lower bound (CRLB) for a MIMO system, where phase noise is estimated using only angular information. Our numerical results show that the performance of our phase estimation algorithm is close to the proposed CRLB. Moreover, when compared with the conventional Kalman based algorithms, our proposed algorithm significantly improves the system BER performance.
UAV Path Planning for Optimal Coverage of Areas with Nonuniform Importance
Oct 19, 2021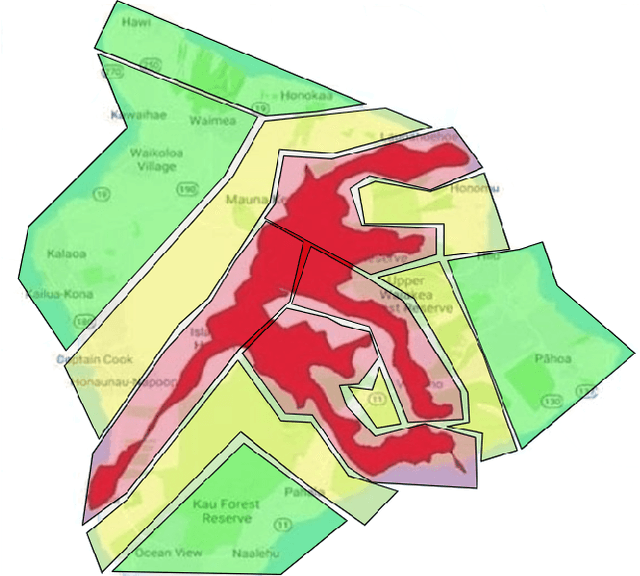
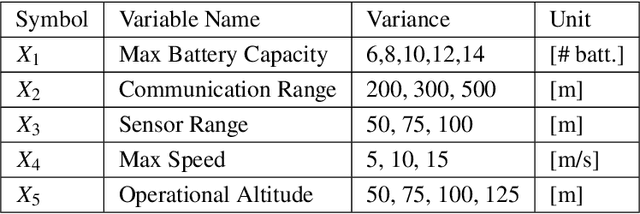
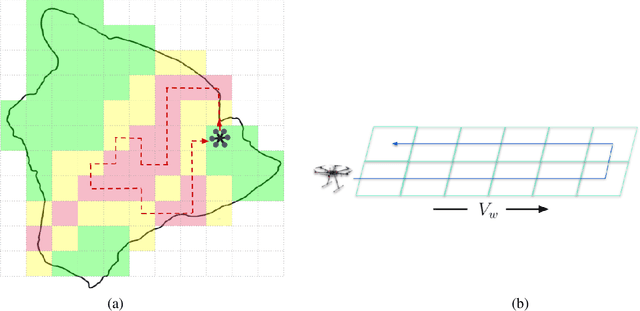
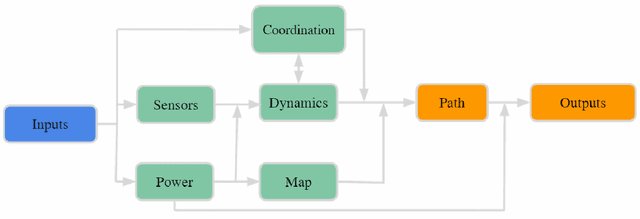
Coverage of an inaccessible or difficult terrain with potential health and safety hazards, such as in a volcanic region, is difficult yet crucial from scientific and meteorological perspectives. Areas contained within this region can provide us with different types of valuable information of varying importance. We present an algorithm to optimally cover a volcanic region in Hawai`i with an unmanned aerial vehicle (UAV). The target region is assigned with a nonuniform coverage importance score distribution. For a specified battery capacity of the UAV, the optimization problem seeks the path that maximizes the total coverage area and the accumulated importance score while penalizing the revisiting of the same area. Trajectories are generated offline for the UAV based on the available power and coverage information map. The optimal trajectory minimizes the unspent battery power while enforcing that the UAV returns to its starting location. This multi-objective optimization problem is solved by using sequential quadratic programming. The details of the competitive optimization problem are discussed along with the analysis and simulation results to demonstrate the applicability of the proposed algorithm.
Leveraging Unsupervised Image Registration for Discovery of Landmark Shape Descriptor
Nov 13, 2021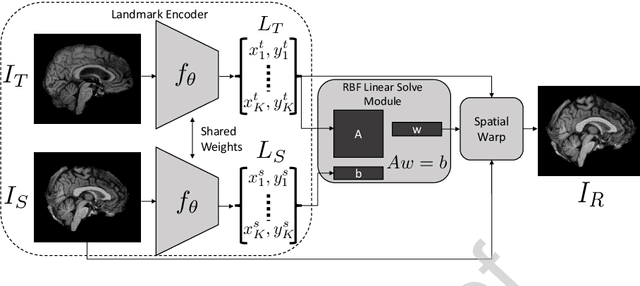
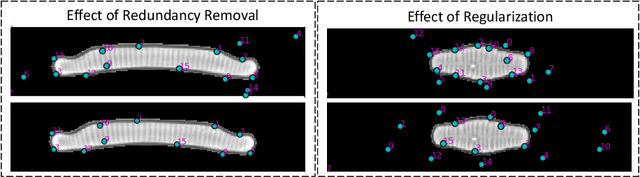
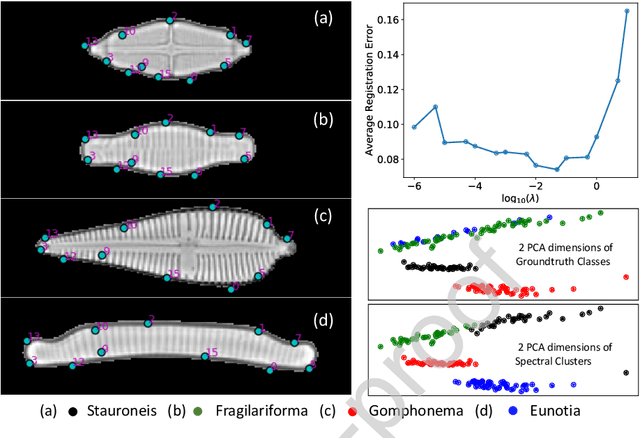
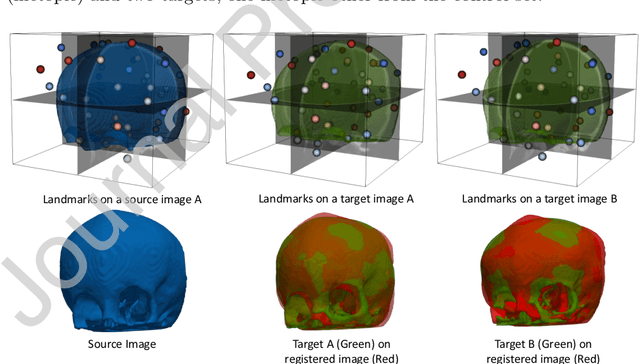
In current biological and medical research, statistical shape modeling (SSM) provides an essential framework for the characterization of anatomy/morphology. Such analysis is often driven by the identification of a relatively small number of geometrically consistent features found across the samples of a population. These features can subsequently provide information about the population shape variation. Dense correspondence models can provide ease of computation and yield an interpretable low-dimensional shape descriptor when followed by dimensionality reduction. However, automatic methods for obtaining such correspondences usually require image segmentation followed by significant preprocessing, which is taxing in terms of both computation as well as human resources. In many cases, the segmentation and subsequent processing require manual guidance and anatomy specific domain expertise. This paper proposes a self-supervised deep learning approach for discovering landmarks from images that can directly be used as a shape descriptor for subsequent analysis. We use landmark-driven image registration as the primary task to force the neural network to discover landmarks that register the images well. We also propose a regularization term that allows for robust optimization of the neural network and ensures that the landmarks uniformly span the image domain. The proposed method circumvents segmentation and preprocessing and directly produces a usable shape descriptor using just 2D or 3D images. In addition, we also propose two variants on the training loss function that allows for prior shape information to be integrated into the model. We apply this framework on several 2D and 3D datasets to obtain their shape descriptors, and analyze their utility for various applications.
TopNet: Learning from Neural Topic Model to Generate Long Stories
Dec 14, 2021
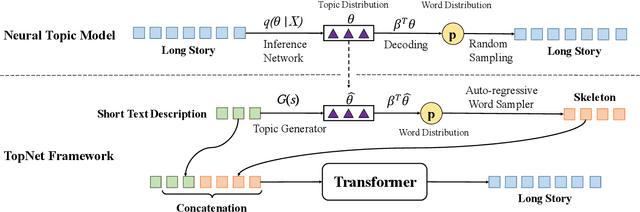

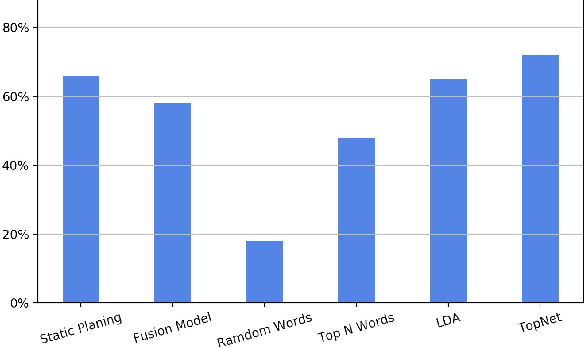
Long story generation (LSG) is one of the coveted goals in natural language processing. Different from most text generation tasks, LSG requires to output a long story of rich content based on a much shorter text input, and often suffers from information sparsity. In this paper, we propose \emph{TopNet} to alleviate this problem, by leveraging the recent advances in neural topic modeling to obtain high-quality skeleton words to complement the short input. In particular, instead of directly generating a story, we first learn to map the short text input to a low-dimensional topic distribution (which is pre-assigned by a topic model). Based on this latent topic distribution, we can use the reconstruction decoder of the topic model to sample a sequence of inter-related words as a skeleton for the story. Experiments on two benchmark datasets show that our proposed framework is highly effective in skeleton word selection and significantly outperforms the state-of-the-art models in both automatic evaluation and human evaluation.
* KDD2021, 9 pages
Top-Down Deep Clustering with Multi-generator GANs
Dec 24, 2021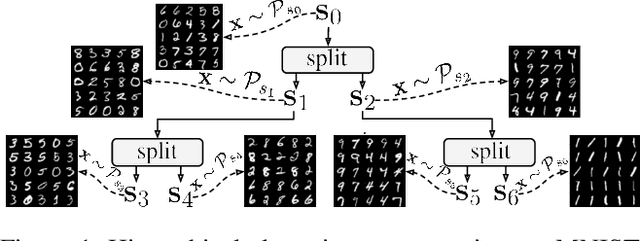
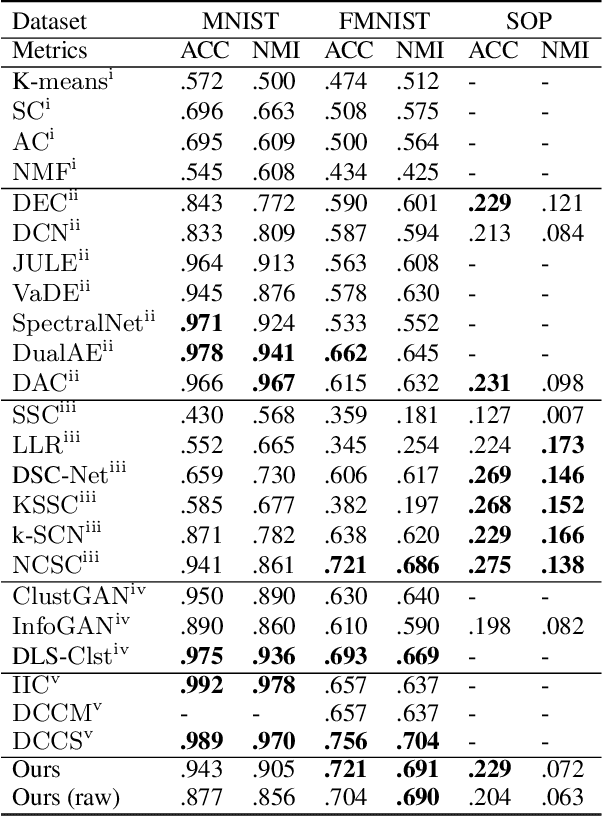
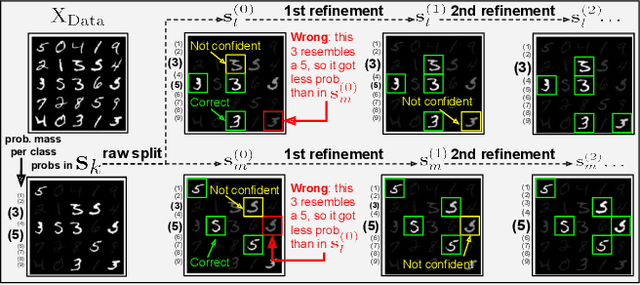

Deep clustering (DC) leverages the representation power of deep architectures to learn embedding spaces that are optimal for cluster analysis. This approach filters out low-level information irrelevant for clustering and has proven remarkably successful for high dimensional data spaces. Some DC methods employ Generative Adversarial Networks (GANs), motivated by the powerful latent representations these models are able to learn implicitly. In this work, we propose HC-MGAN, a new technique based on GANs with multiple generators (MGANs), which have not been explored for clustering. Our method is inspired by the observation that each generator of a MGAN tends to generate data that correlates with a sub-region of the real data distribution. We use this clustered generation to train a classifier for inferring from which generator a given image came from, thus providing a semantically meaningful clustering for the real distribution. Additionally, we design our method so that it is performed in a top-down hierarchical clustering tree, thus proposing the first hierarchical DC method, to the best of our knowledge. We conduct several experiments to evaluate the proposed method against recent DC methods, obtaining competitive results. Last, we perform an exploratory analysis of the hierarchical clustering tree that highlights how accurately it organizes the data in a hierarchy of semantically coherent patterns.
On Efficient Transformer and Image Pre-training for Low-level Vision
Dec 19, 2021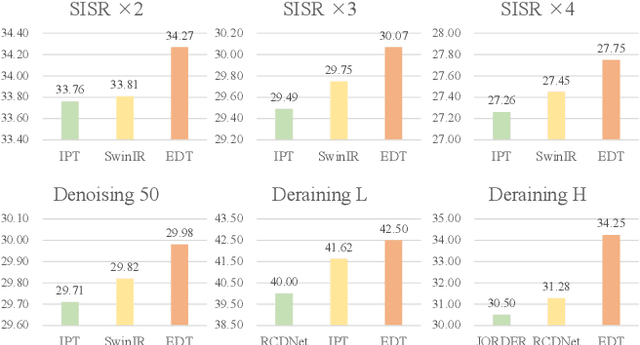
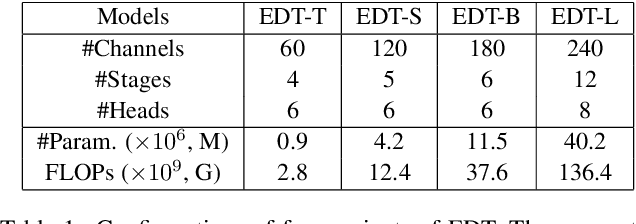
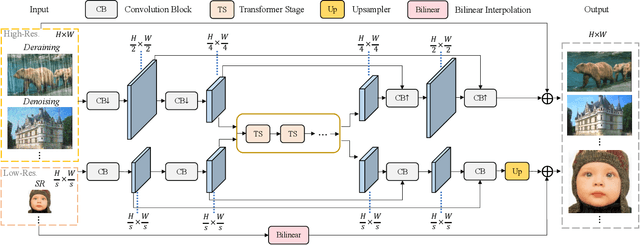
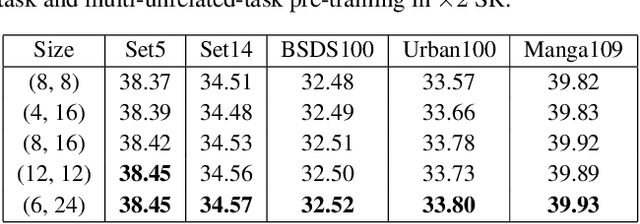
Pre-training has marked numerous state of the arts in high-level computer vision, but few attempts have ever been made to investigate how pre-training acts in image processing systems. In this paper, we present an in-depth study of image pre-training. To conduct this study on solid ground with practical value in mind, we first propose a generic, cost-effective Transformer-based framework for image processing. It yields highly competitive performance across a range of low-level tasks, though under constrained parameters and computational complexity. Then, based on this framework, we design a whole set of principled evaluation tools to seriously and comprehensively diagnose image pre-training in different tasks, and uncover its effects on internal network representations. We find pre-training plays strikingly different roles in low-level tasks. For example, pre-training introduces more local information to higher layers in super-resolution (SR), yielding significant performance gains, while pre-training hardly affects internal feature representations in denoising, resulting in a little gain. Further, we explore different methods of pre-training, revealing that multi-task pre-training is more effective and data-efficient. All codes and models will be released at https://github.com/fenglinglwb/EDT.