 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TEACh: Task-driven Embodied Agents that Chat
Oct 01, 2021
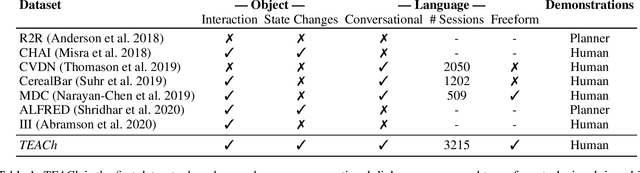
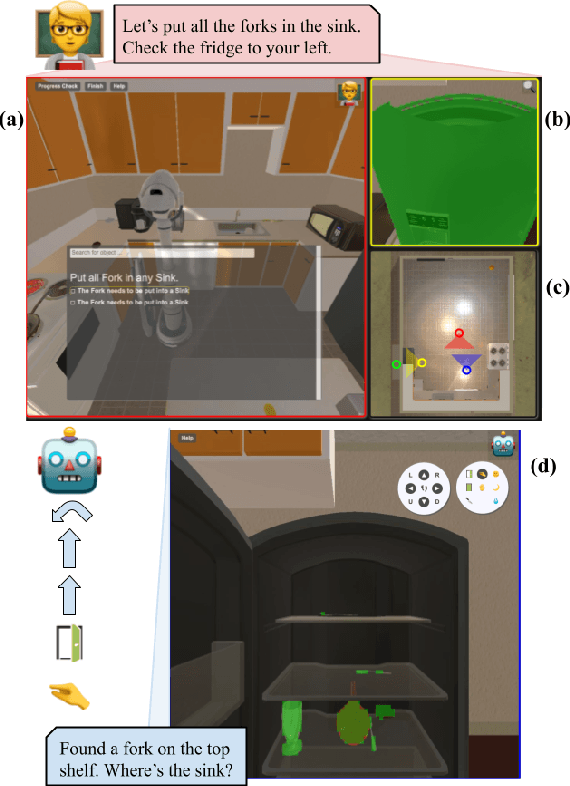
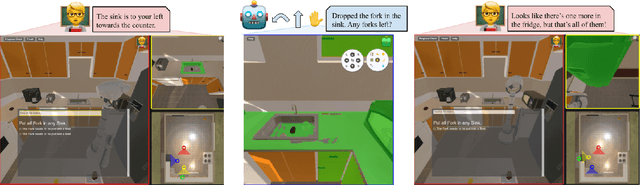
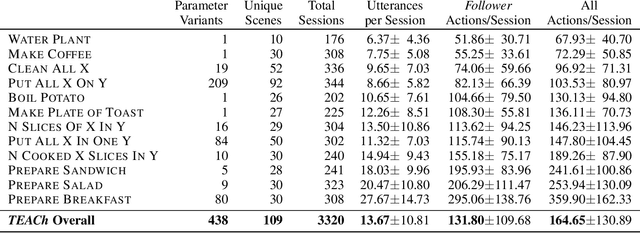
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
Task-Oriented Image Transmission for Scene Classification in Unmanned Aerial Systems
Dec 21, 2021



The vigorous developments of Internet of Things make it possible to extend its computing and storage capabilities to computing tasks in the aerial system with collaboration of cloud and edge, especially for artificial intelligence (AI) tasks based on deep learning (DL). Collecting a large amount of image/video data, Unmanned aerial vehicles (UAVs) can only handover intelligent analysis tasks to the back-end mobile edge computing (MEC) server due to their limited storage and computing capabilities. How to efficiently transmit the most correlated information for the AI model is a challenging topic. Inspired by the task-oriented communication in recent years, we propose a new aerial image transmission paradigm for the scene classification task. A lightweight model is developed on the front-end UAV for semantic blocks transmission with perception of images and channel conditions. In order to achieve the tradeoff between transmission latency and classification accuracy, deep reinforcement learning (DRL) is used to explore the semantic blocks which have the best contribution to the back-end classifier under various channel conditions. Experimental results show that the proposed method can significantly improve classification accuracy compared to the fixed transmission strategy and traditional content perception methods.
Next-Best-View Estimation based on Deep Reinforcement Learning for Active Object Classification
Oct 14, 2021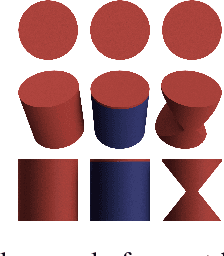
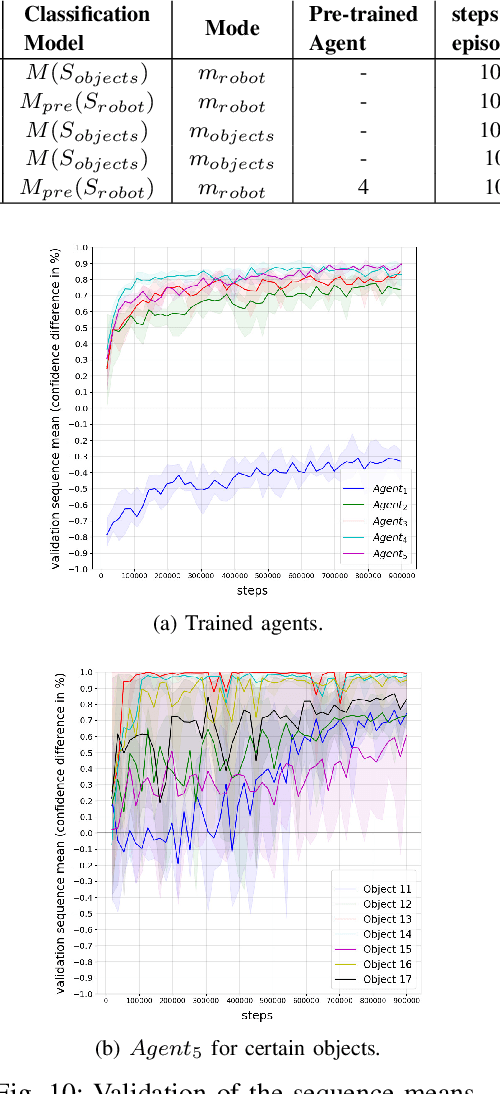
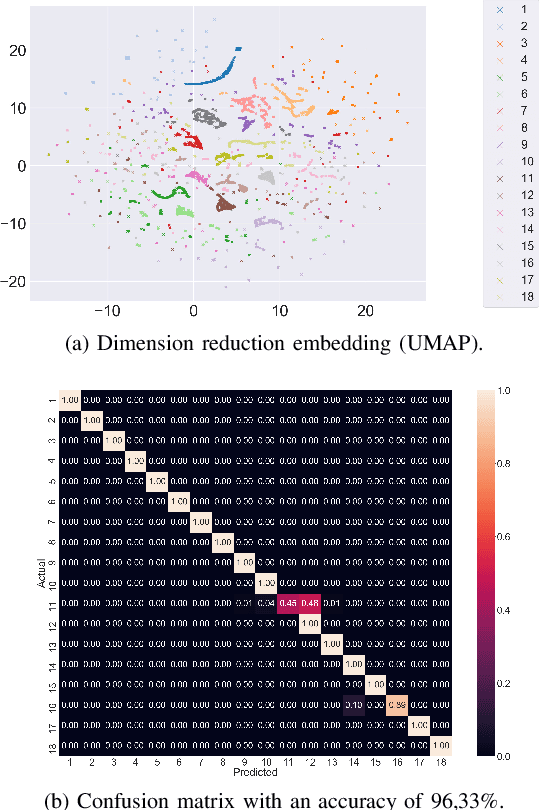
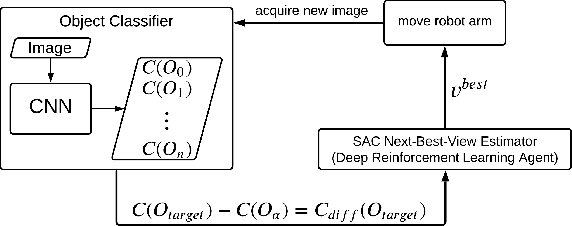
The presentation and analysis of image data from a single viewpoint are often not sufficient to solve a task. Several viewpoints are necessary to obtain more information. The next-best-view problem attempts to find the optimal viewpoint with the greatest information gain for the underlying task. In this work, a robot arm holds an object in its end-effector and searches for a sequence of next-best-view to explicitly identify the object. We use Soft Actor-Critic (SAC), a method of deep reinforcement learning, to learn these next-best-views for a specific set of objects. The evaluation shows that an agent can learn to determine an object pose to which the robot arm should move an object. This leads to a viewpoint that provides a more accurate prediction to distinguish such an object from other objects better. We make the code publicly available for the scientific community and for reproducibility.
Simple Text Detoxification by Identifying a Linear Toxic Subspace in Language Model Embeddings
Dec 15, 2021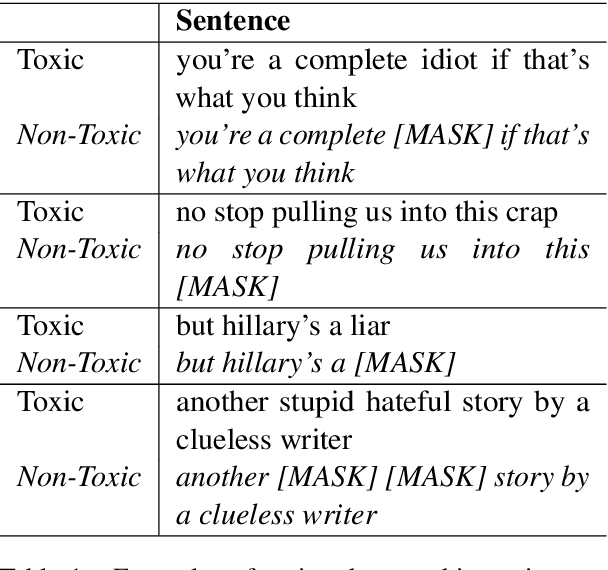
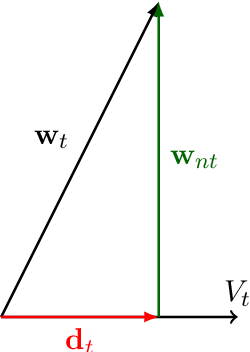
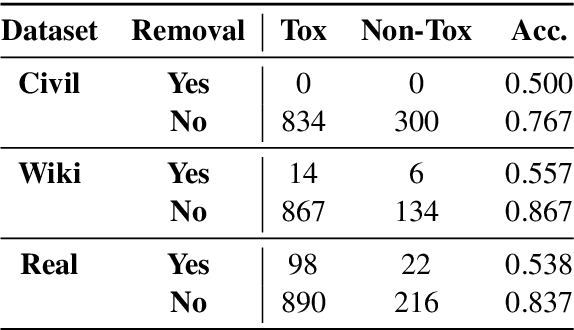
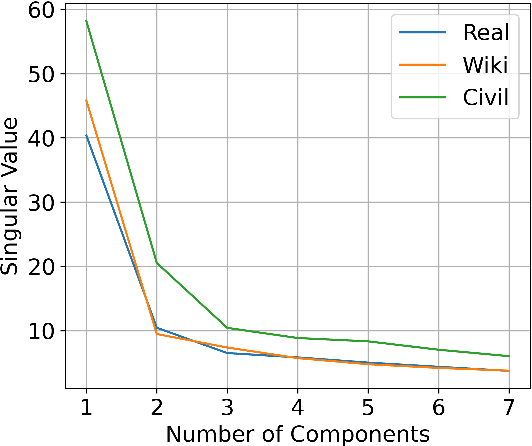
Large pre-trained language models are often trained on large volumes of internet data, some of which may contain toxic or abusive language. Consequently, language models encode toxic information, which makes the real-world usage of these language models limited. Current methods aim to prevent toxic features from appearing generated text. We hypothesize the existence of a low-dimensional toxic subspace in the latent space of pre-trained language models, the existence of which suggests that toxic features follow some underlying pattern and are thus removable. To construct this toxic subspace, we propose a method to generalize toxic directions in the latent space. We also provide a methodology for constructing parallel datasets using a context based word masking system. Through our experiments, we show that when the toxic subspace is removed from a set of sentence representations, almost no toxic representations remain in the result. We demonstrate empirically that the subspace found using our method generalizes to multiple toxicity corpora, indicating the existence of a low-dimensional toxic subspace.
THE Benchmark: Transferable Representation Learning for Monocular Height Estimation
Dec 30, 2021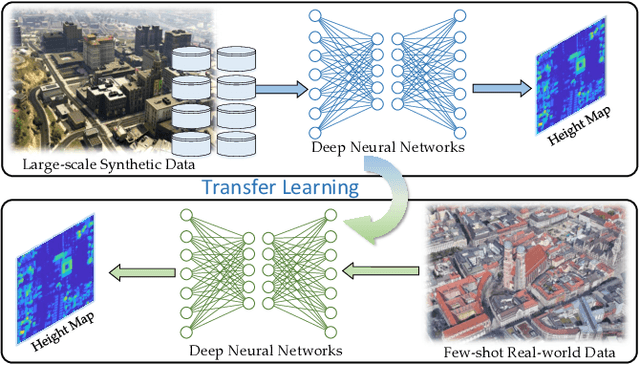
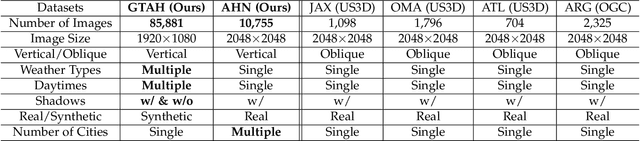

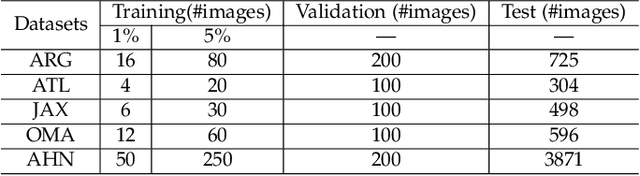
Generating 3D city models rapidly is crucial for many applications. Monocular height estimation is one of the most efficient and timely ways to obtain large-scale geometric information. However, existing works focus primarily on training and testing models using unbiased datasets, which don't align well with real-world applications. Therefore, we propose a new benchmark dataset to study the transferability of height estimation models in a cross-dataset setting. To this end, we first design and construct a large-scale benchmark dataset for cross-dataset transfer learning on the height estimation task. This benchmark dataset includes a newly proposed large-scale synthetic dataset, a newly collected real-world dataset, and four existing datasets from different cities. Next, two new experimental protocols, zero-shot and few-shot cross-dataset transfer, are designed. For few-shot cross-dataset transfer, we enhance the window-based Transformer with the proposed scale-deformable convolution module to handle the severe scale-variation problem. To improve the generalizability of deep models in the zero-shot cross-dataset setting, a max-normalization-based Transformer network is designed to decouple the relative height map from the absolute heights. Experimental results have demonstrated the effectiveness of the proposed methods in both the traditional and cross-dataset transfer settings. The datasets and codes are publicly available at https://thebenchmarkh.github.io/.
DB-BERT: a Database Tuning Tool that "Reads the Manual"
Dec 21, 2021
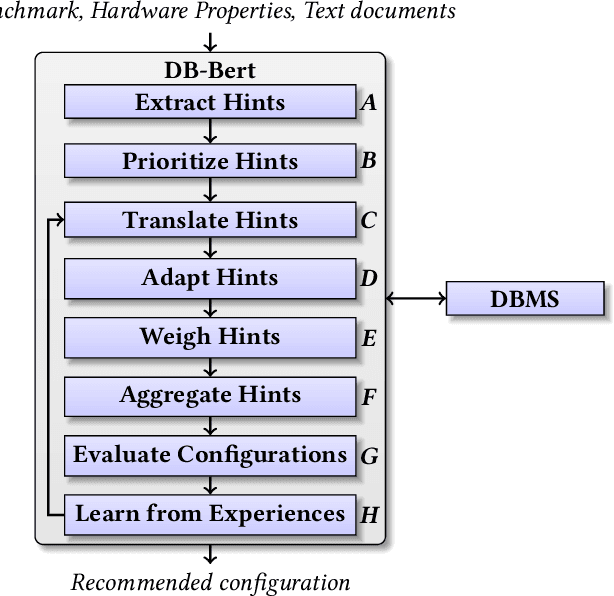
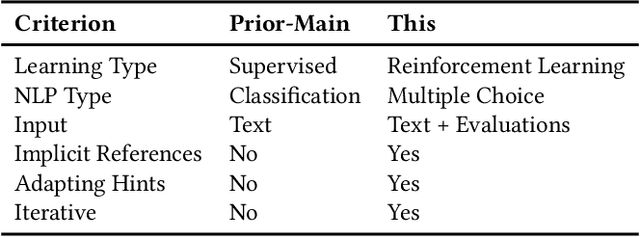
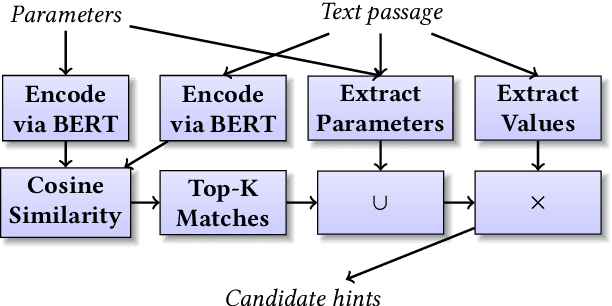
DB-BERT is a database tuning tool that exploits information gained via natural language analysis of manuals and other relevant text documents. It uses text to identify database system parameters to tune as well as recommended parameter values. DB-BERT applies large, pre-trained language models (specifically, the BERT model) for text analysis. During an initial training phase, it fine-tunes model weights in order to translate natural language hints into recommended settings. At run time, DB-BERT learns to aggregate, adapt, and prioritize hints to achieve optimal performance for a specific database system and benchmark. Both phases are iterative and use reinforcement learning to guide the selection of tuning settings to evaluate (penalizing settings that the database system rejects while rewarding settings that improve performance). In our experiments, we leverage hundreds of text documents about database tuning as input for DB-BERT. We compare DB-BERT against various baselines, considering different benchmarks (TPC-C and TPC-H), metrics (throughput and run time), as well as database systems (Postgres and MySQL). In all cases, DB-BERT finds the best parameter settings among all compared methods. The code of DB-BERT is available online at https://itrummer.github.io/dbbert/.
Kernelized information bottleneck leads to biologically plausible 3-factor Hebbian learning in deep networks
Jun 12, 2020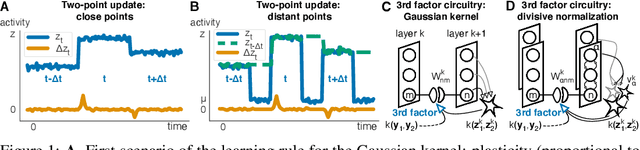
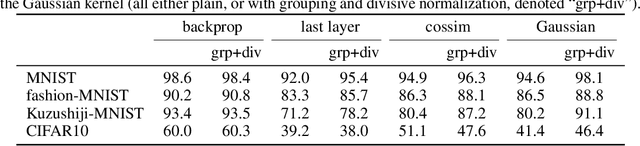
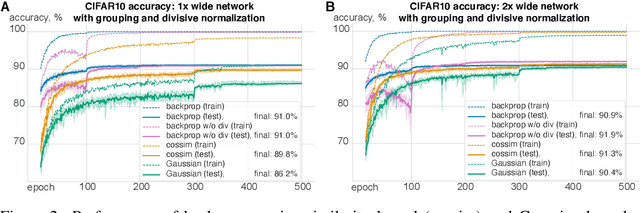

The state-of-the art machine learning approach to training deep neural networks, backpropagation, is implausible for real neural networks: neurons need to know their outgoing weights; training alternates between a forward pass (computation) and a backward pass (learning); and the algorithm needs a large amount of labeled data. Biologically plausible approximations to backpropagation, such as feedback alignment, solve the weight transport problem, but not the other two. Thus, fully biologically plausible learning rules have so far remained elusive. Here we present a family of learning rules that does not suffer from any of these problems. It is motivated by the information bottleneck principle (extended with kernel methods), in which networks learn to squeeze as much information as possible out of the input without sacrificing prediction of the output. The resulting rules have a 3-factor Hebbian structure: they require pre- and post-synaptic firing rates and a global error signal - the third factor - that can be supplied by a neuromodulator. Moreover, they do not require precise labels; instead, they rely on the similarity between the desired outputs. They thus solve all three implausibility issues of backpropagation. Moreover, to obtain good performance on hard problems and retain biologically plausible learning rules, our rules need divisive normalization - a known feature of biological networks. Finally, simulations show that our rule performs nearly as well as backpropagation on image classification tasks.
TransVOD: End-to-end Video Object Detection with Spatial-Temporal Transformers
Jan 14, 2022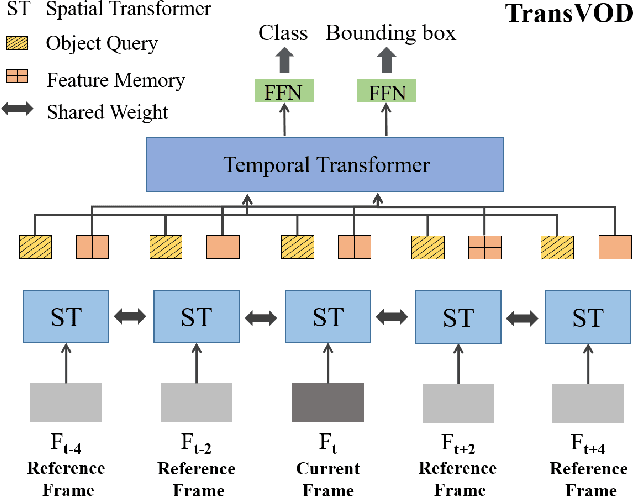
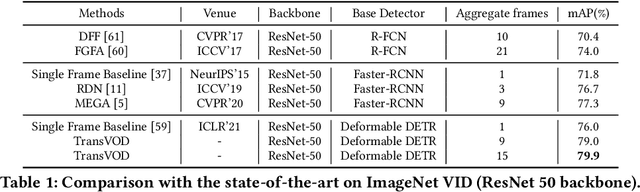
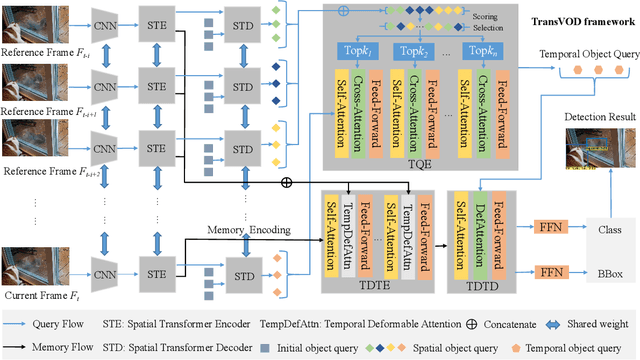
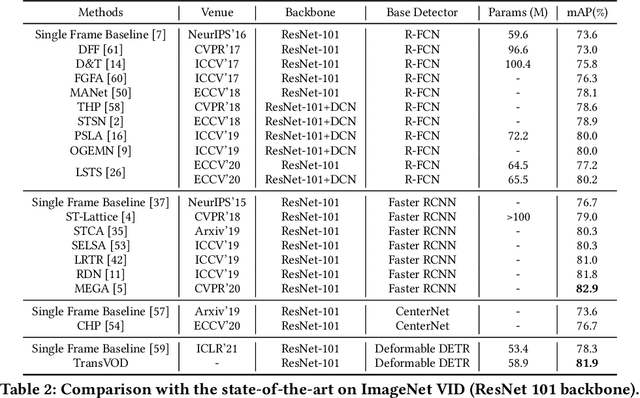
Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.
Semi-supervised t-SNE for Millimeter-wave Wireless Localization
Nov 26, 2021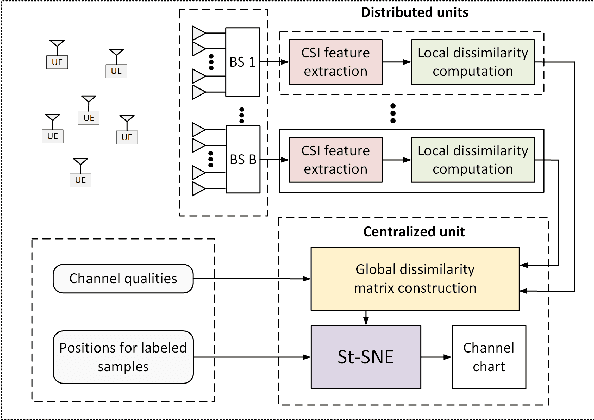
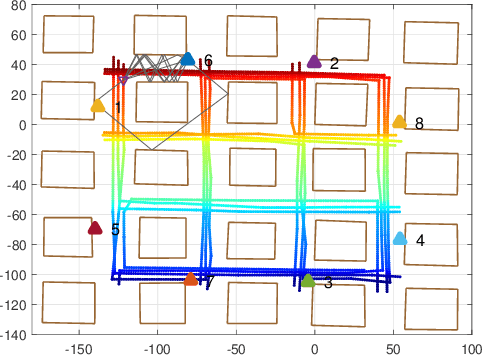
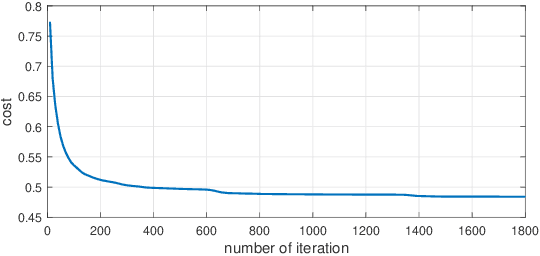
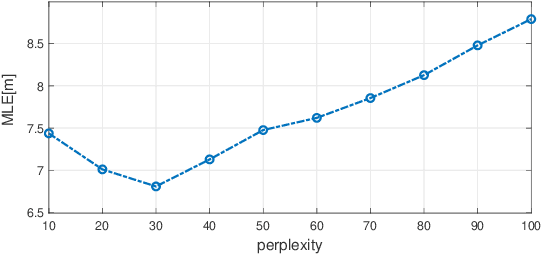
We consider the mobile localization problem in future millimeter-wave wireless networks with distributed Base Stations (BSs) based on multi-antenna channel state information (CSI). For this problem, we propose a Semi-supervised tdistributed Stochastic Neighbor Embedding (St-SNE) algorithm to directly embed the high-dimensional CSI samples into the 2D geographical map. We evaluate the performance of St-SNE in a simulated urban outdoor millimeter-wave radio access network. Our results show that St-SNE achieves a mean localization error of 6.8 m with only 5% of labeled CSI samples in a 200*200 m^2 area with a ray-tracing channel model. St-SNE does not require accurate synchronization among multiple BSs, and is promising for future large-scale millimeter-wave localization.
Scale up to infinity: the UWB Indoor Global Positioning System
Dec 03, 2021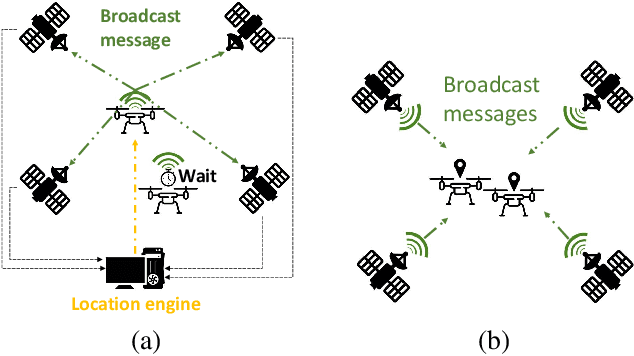
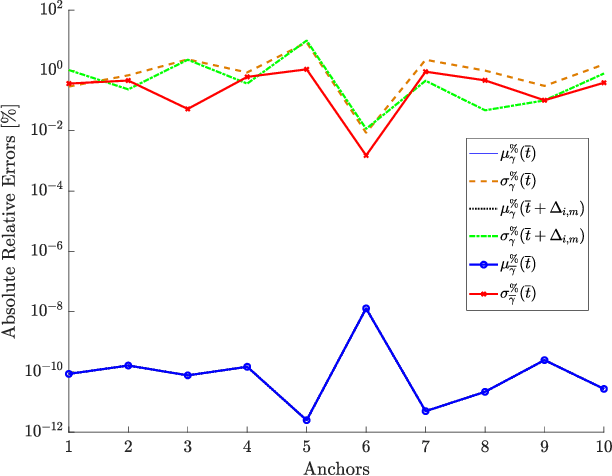
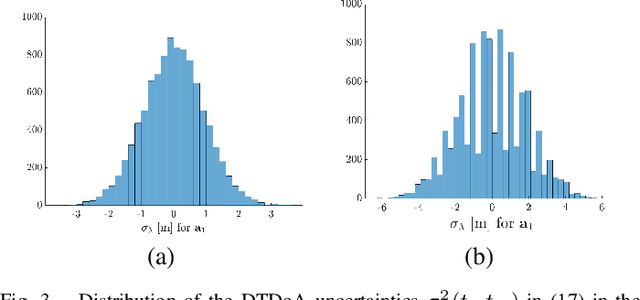
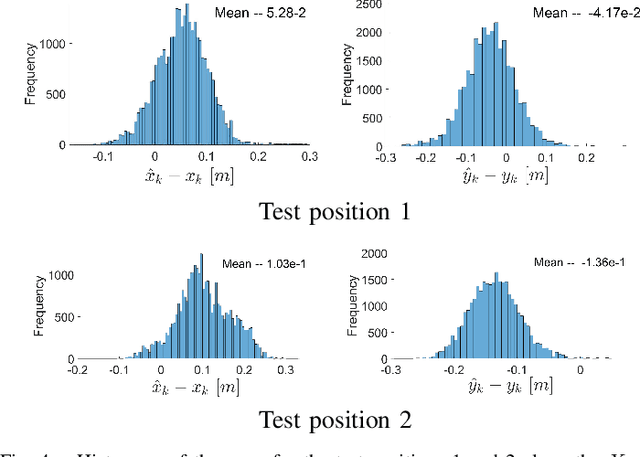
Determining assets position with high accuracy and scalability is one of the most investigated technology on the market. The accuracy provided by satellites-based positioning systems (i.e., GLONASS or Galileo) is not always sufficient when a decimeter-level accuracy is required or when there is the need of localising entities that operate inside indoor environments. Scalability is also a recurrent problem when dealing with indoor positioning systems. This paper presents an innovative UWB Indoor GPS-Like local positioning system able to tracks any number of assets without decreasing measurements update rate. To increase the system's accuracy the mathematical model and the sources of uncertainties are investigated. Results highlight how the proposed implementation provides positioning information with an absolute maximum error below 20 cm. Scalability is also resolved thanks to DTDoA transmission mechanisms not requiring an active role from the asset to be tracked.