 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HVTR: Hybrid Volumetric-Textural Rendering for Human Avatars
Dec 19, 2021

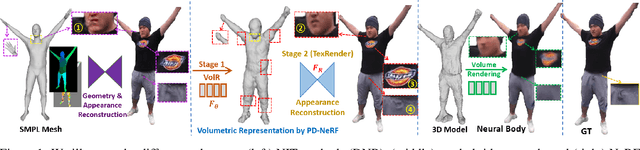
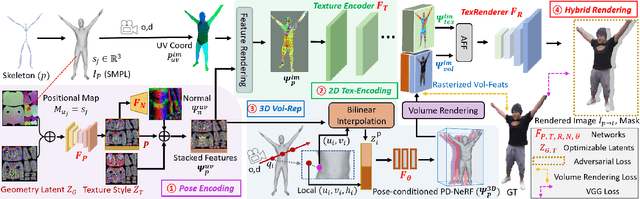
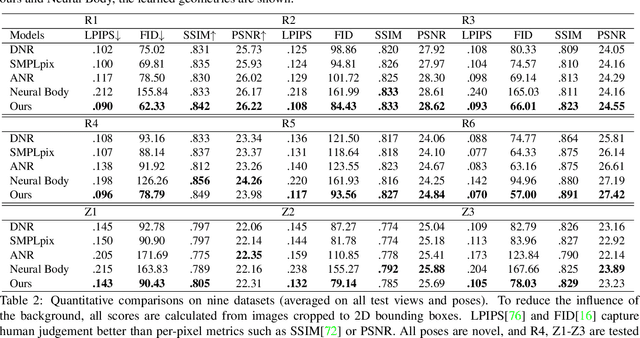
We propose a novel neural rendering pipeline, Hybrid Volumetric-Textural Rendering (HVTR), which synthesizes virtual human avatars from arbitrary poses efficiently and at high quality. First, we learn to encode articulated human motions on a dense UV manifold of the human body surface. To handle complicated motions (e.g., self-occlusions), we then leverage the encoded information on the UV manifold to construct a 3D volumetric representation based on a dynamic pose-conditioned neural radiance field. While this allows us to represent 3D geometry with changing topology, volumetric rendering is computationally heavy. Hence we employ only a rough volumetric representation using a pose-conditioned downsampled neural radiance field (PD-NeRF), which we can render efficiently at low resolutions. In addition, we learn 2D textural features that are fused with rendered volumetric features in image space. The key advantage of our approach is that we can then convert the fused features into a high resolution, high-quality avatar by a fast GAN-based textural renderer. We demonstrate that hybrid rendering enables HVTR to handle complicated motions, render high-quality avatars under user-controlled poses/shapes and even loose clothing, and most importantly, be fast at inference time. Our experimental results also demonstrate state-of-the-art quantitative results.
End-to-End Learning of Multi-category 3D Pose and Shape Estimation
Dec 19, 2021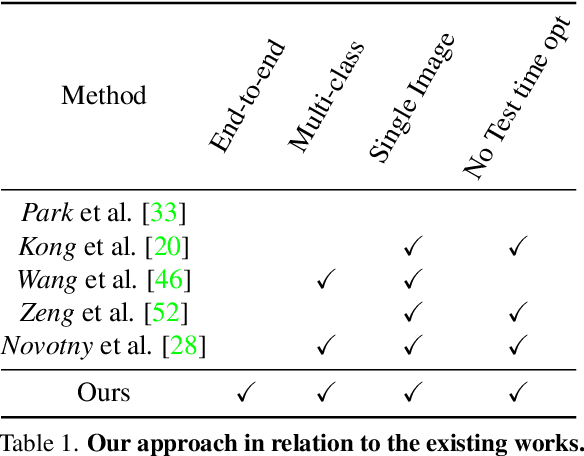

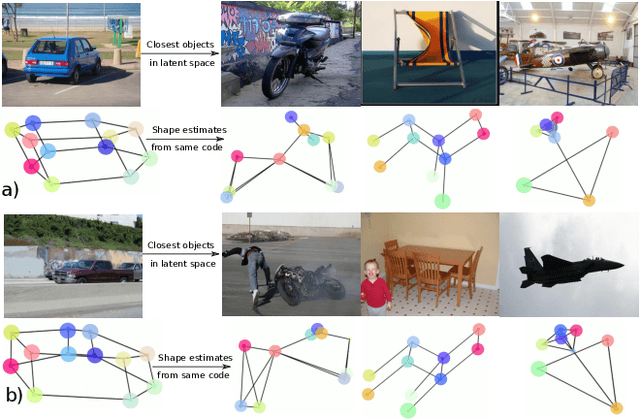
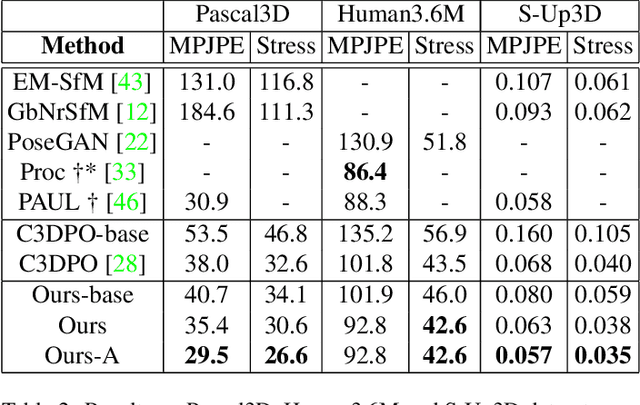
In this paper, we study the representation of the shape and pose of objects using their keypoints. Therefore, we propose an end-to-end method that simultaneously detects 2D keypoints from an image and lifts them to 3D. The proposed method learns both 2D detection and 3D lifting only from 2D keypoints annotations. In this regard, a novel method that explicitly disentangles the pose and 3D shape by means of augmentation-based cyclic self-supervision is proposed, for the first time. In addition of being end-to-end in image to 3D learning, our method also handles objects from multiple categories using a single neural network. We use a Transformer-based architecture to detect the keypoints, as well as to summarize the visual context of the image. This visual context information is then used while lifting the keypoints to 3D, so as to allow the context-based reasoning for better performance. While lifting, our method learns a small set of basis shapes and their sparse non-negative coefficients to represent the 3D shape in canonical frame. Our method can handle occlusions as well as wide variety of object classes. Our experiments on three benchmarks demonstrate that our method performs better than the state-of-the-art. Our source code will be made publicly available.
Exact Information Bottleneck with Invertible Neural Networks: Getting the Best of Discriminative and Generative Modeling
Jan 17, 2020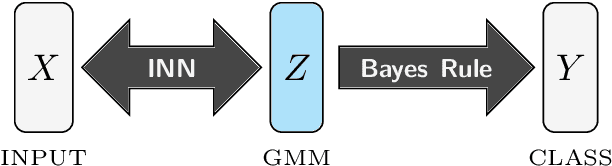

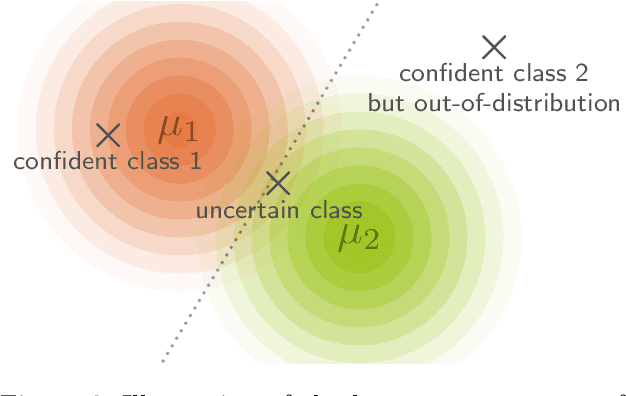
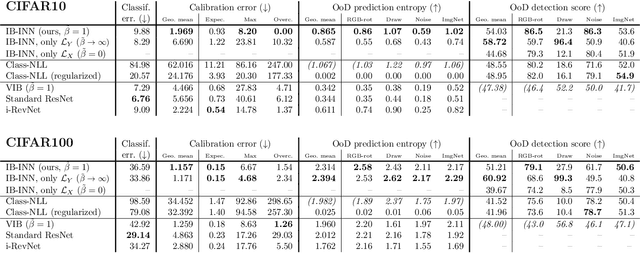
The Information Bottleneck (IB) principle offers a unified approach to many learning and prediction problems. Although optimal in an information-theoretic sense, practical applications of IB are hampered by a lack of accurate high-dimensional estimators of mutual information, its main constituent. We propose to combine IB with invertible neural networks (INNs), which for the first time allows exact calculation of the required mutual information. Applied to classification, our proposed method results in a generative classifier we call IB-INN. It accurately models the class conditional likelihoods, generalizes well to unseen data and reliably recognizes out-of-distribution examples. In contrast to existing generative classifiers, these advantages incur only minor reductions in classification accuracy in comparison to corresponding discriminative methods such as feed-forward networks. Furthermore, we provide insight into why IB-INNs are superior to other generative architectures and training procedures and show experimentally that our method outperforms alternative models of comparable complexity.
Heuristic Search Planning with Deep Neural Networks using Imitation, Attention and Curriculum Learning
Dec 03, 2021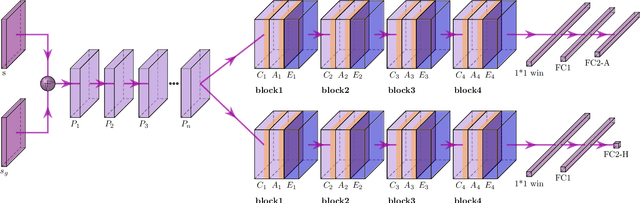
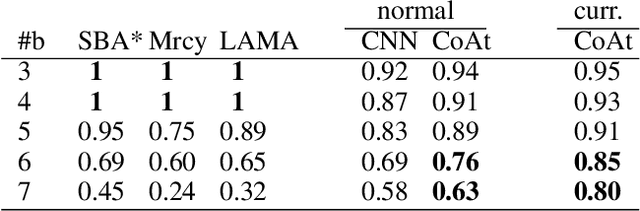
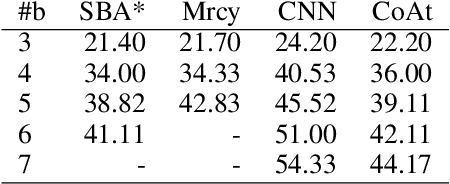
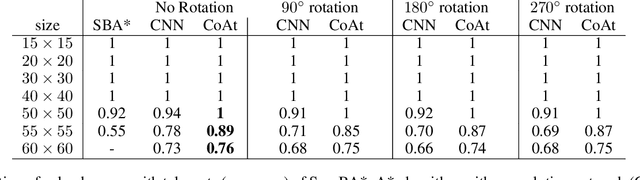
Learning a well-informed heuristic function for hard task planning domains is an elusive problem. Although there are known neural network architectures to represent such heuristic knowledge, it is not obvious what concrete information is learned and whether techniques aimed at understanding the structure help in improving the quality of the heuristics. This paper presents a network model to learn a heuristic capable of relating distant parts of the state space via optimal plan imitation using the attention mechanism, which drastically improves the learning of a good heuristic function. To counter the limitation of the method in the creation of problems of increasing difficulty, we demonstrate the use of curriculum learning, where newly solved problem instances are added to the training set, which, in turn, helps to solve problems of higher complexities and far exceeds the performances of all existing baselines including classical planning heuristics. We demonstrate its effectiveness for grid-type PDDL domains.
End-to-end translation of human neural activity to speech with a dual-dual generative adversarial network
Oct 13, 2021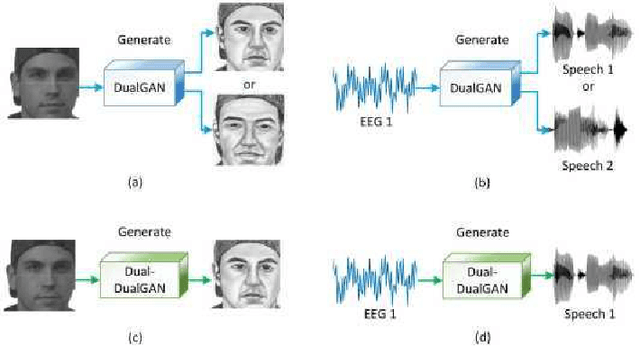
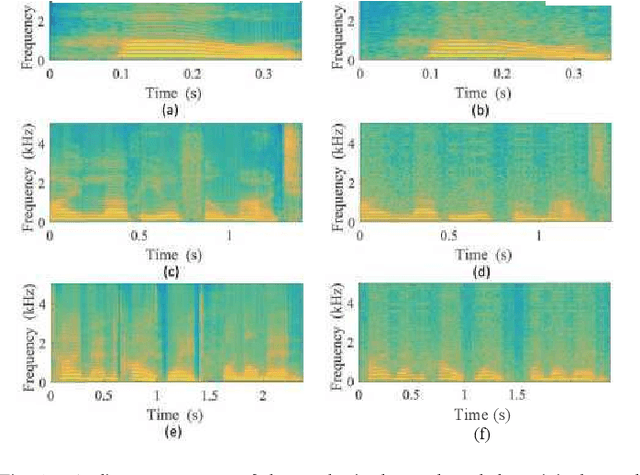
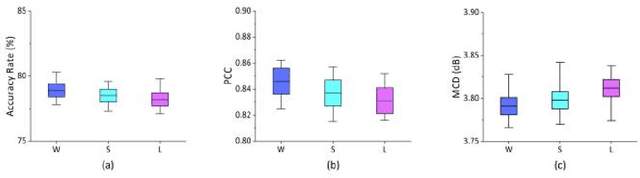
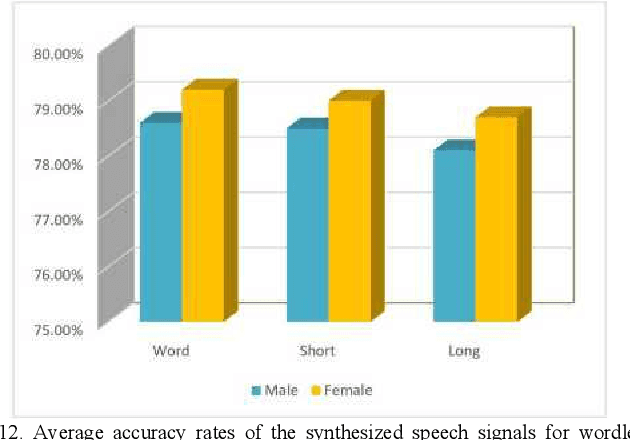
In a recent study of auditory evoked potential (AEP) based brain-computer interface (BCI), it was shown that, with an encoder-decoder framework, it is possible to translate human neural activity to speech (T-CAS). However, current encoder-decoder-based methods achieve T-CAS often with a two-step method where the information is passed between the encoder and decoder with a shared dimension reduction vector, which may result in a loss of information. A potential approach to this problem is to design an end-to-end method by using a dual generative adversarial network (DualGAN) without dimension reduction of passing information, but it cannot realize one-to-one signal-to-signal translation (see Fig.1 (a) and (b)). In this paper, we propose an end-to-end model to translate human neural activity to speech directly, create a new electroencephalogram (EEG) datasets for participants with good attention by design a device to detect participants' attention, and introduce a dual-dual generative adversarial network (Dual-DualGAN) (see Fig. 1 (c) and (d)) to address an end-to-end translation of human neural activity to speech (ET-CAS) problem by group labelling EEG signals and speech signals, inserting a transition domain to realize cross-domain mapping. In the transition domain, the transition signals are cascaded by the corresponding EEG and speech signals in a certain proportion, which can build bridges for EEG and speech signals without corresponding features, and realize one-to-one cross-domain EEG-to-speech translation. The proposed method can translate word-length and sentence-length sequences of neural activity to speech. Experimental evaluation has been conducted to show that the proposed method significantly outperforms state-of-the-art methods on both words and sentences of auditory stimulus.
Mapping (Dis-)Information Flow about the MH17 Plane Crash
Oct 03, 2019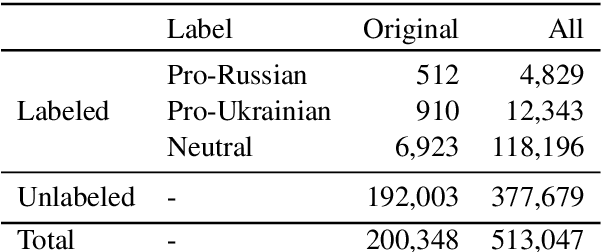
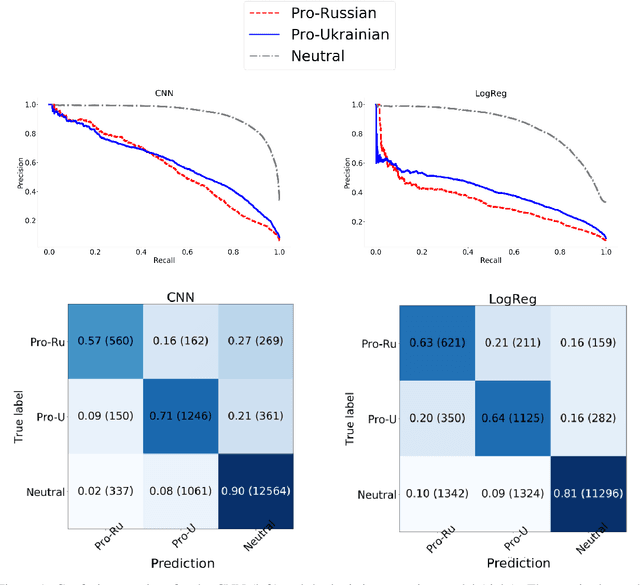


Digital media enables not only fast sharing of information, but also disinformation. One prominent case of an event leading to circulation of disinformation on social media is the MH17 plane crash. Studies analysing the spread of information about this event on Twitter have focused on small, manually annotated datasets, or used proxys for data annotation. In this work, we examine to what extent text classifiers can be used to label data for subsequent content analysis, in particular we focus on predicting pro-Russian and pro-Ukrainian Twitter content related to the MH17 plane crash. Even though we find that a neural classifier improves over a hashtag based baseline, labeling pro-Russian and pro-Ukrainian content with high precision remains a challenging problem. We provide an error analysis underlining the difficulty of the task and identify factors that might help improve classification in future work. Finally, we show how the classifier can facilitate the annotation task for human annotators.
The Spectrum of Fisher Information of Deep Networks Achieving Dynamical Isometry
Jun 14, 2020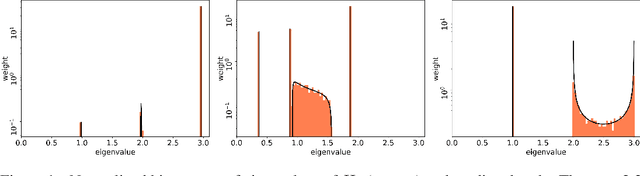

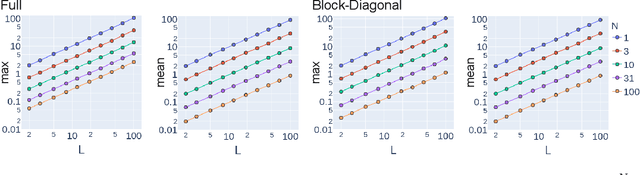
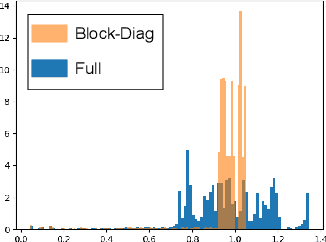
The Fisher information matrix (FIM) is fundamental for understanding the trainability of deep neural networks (DNN) since it describes the local metric of the parameter space. We investigate the spectral distribution of the FIM given a single input by focusing on fully-connected networks achieving dynamical isometry. Then, while dynamical isometry is known to keep specific backpropagated signals independent of the depth, we find that the parameter space's local metric depends on the depth. In particular, we obtain an exact expression of the spectrum of the FIM given a single input and reveal that it concentrates around the depth point. Here, considering random initialization and the wide limit, we construct an algebraic methodology to examine the spectrum based on free probability theory, which is the algebraic wrapper of random matrix theory. As a byproduct, we provide the solvable spectral distribution in the two-hidden-layer case. Lastly, we empirically confirm that the spectrum of FIM with small batch-size has the same property as the single-input version. An experimental result shows that FIM's dependence on the depth determines the appropriate size of the learning rate for convergence at the initial phase of the online training of DNNs.
The Powerful Use of AI in the Energy Sector: Intelligent Forecasting
Nov 03, 2021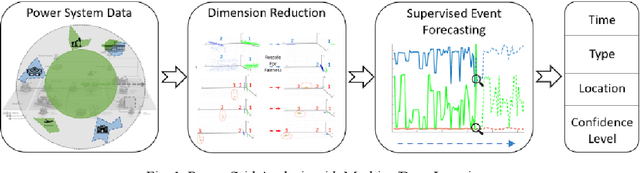
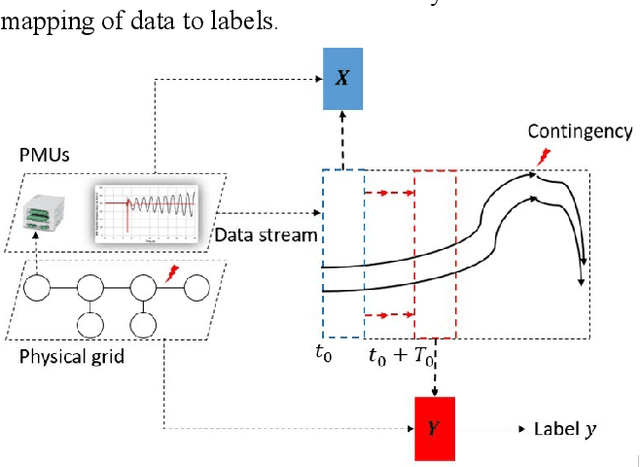
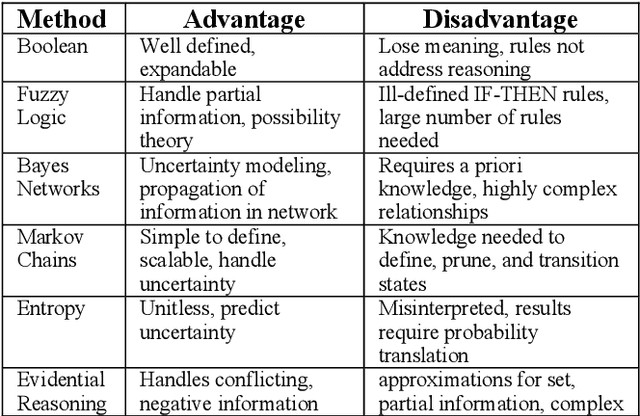
Artificial Intelligence (AI) techniques continue to broaden across governmental and public sectors, such as power and energy - which serve as critical infrastructures for most societal operations. However, due to the requirements of reliability, accountability, and explainability, it is risky to directly apply AI-based methods to power systems because society cannot afford cascading failures and large-scale blackouts, which easily cost billions of dollars. To meet society requirements, this paper proposes a methodology to develop, deploy, and evaluate AI systems in the energy sector by: (1) understanding the power system measurements with physics, (2) designing AI algorithms to forecast the need, (3) developing robust and accountable AI methods, and (4) creating reliable measures to evaluate the performance of the AI model. The goal is to provide a high level of confidence to energy utility users. For illustration purposes, the paper uses power system event forecasting (PEF) as an example, which carefully analyzes synchrophasor patterns measured by the Phasor Measurement Units (PMUs). Such a physical understanding leads to a data-driven framework that reduces the dimensionality with physics and forecasts the event with high credibility. Specifically, for dimensionality reduction, machine learning arranges physical information from different dimensions, resulting inefficient information extraction. For event forecasting, the supervised learning model fuses the results of different models to increase the confidence. Finally, comprehensive experiments demonstrate the high accuracy, efficiency, and reliability as compared to other state-of-the-art machine learning methods.
Importance Estimation from Multiple Perspectives for Keyphrase Extraction
Oct 19, 2021
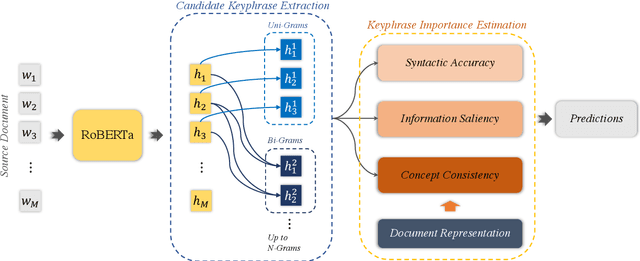

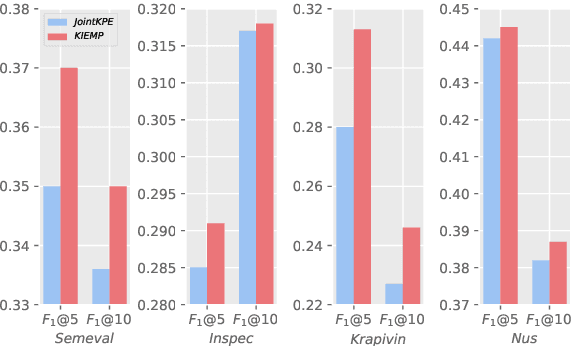
Keyphrase extraction is a fundamental task in Natural Language Processing, which usually contains two main parts: candidate keyphrase extraction and keyphrase importance estimation. From the view of human understanding documents, we typically measure the importance of phrase according to its syntactic accuracy, information saliency, and concept consistency simultaneously. However, most existing keyphrase extraction approaches only focus on the part of them, which leads to biased results. In this paper, we propose a new approach to estimate the importance of keyphrase from multiple perspectives (called as \textit{KIEMP}) and further improve the performance of keyphrase extraction. Specifically, \textit{KIEMP} estimates the importance of phrase with three modules: a chunking module to measure its syntactic accuracy, a ranking module to check its information saliency, and a matching module to judge the concept (i.e., topic) consistency between phrase and the whole document. These three modules are seamlessly jointed together via an end-to-end multi-task learning model, which is helpful for three parts to enhance each other and balance the effects of three perspectives. Experimental results on six benchmark datasets show that \textit{KIEMP} outperforms the existing state-of-the-art keyphrase extraction approaches in most cases.
On the Importance of Gradients for Detecting Distributional Shifts in the Wild
Oct 01, 2021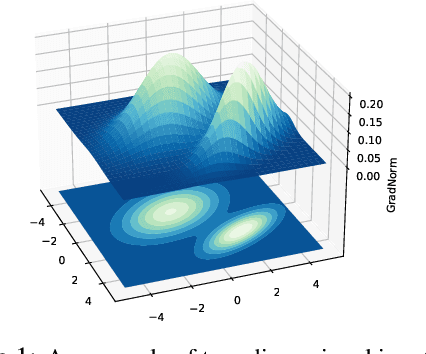
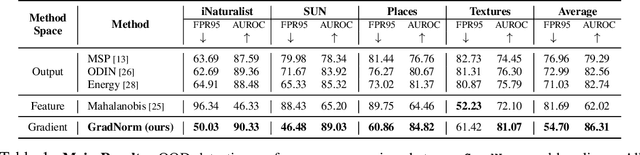
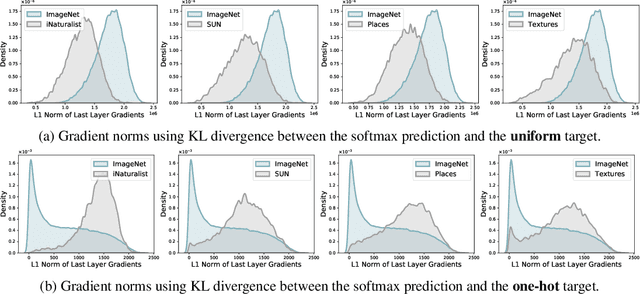
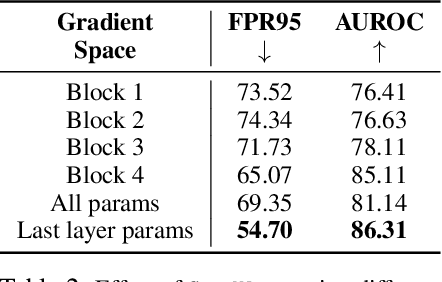
Detecting out-of-distribution (OOD) data has become a critical component in ensuring the safe deployment of machine learning models in the real world. Existing OOD detection approaches primarily rely on the output or feature space for deriving OOD scores, while largely overlooking information from the gradient space. In this paper, we present GradNorm, a simple and effective approach for detecting OOD inputs by utilizing information extracted from the gradient space. GradNorm directly employs the vector norm of gradients, backpropagated from the KL divergence between the softmax output and a uniform probability distribution. Our key idea is that the magnitude of gradients is higher for in-distribution (ID) data than that for OOD data, making it informative for OOD detection. GradNorm demonstrates superior performance, reducing the average FPR95 by up to 10.89% compared to the previous best method.