 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhanced Object Detection in Floor-plan through Super Resolution
Dec 18, 2021
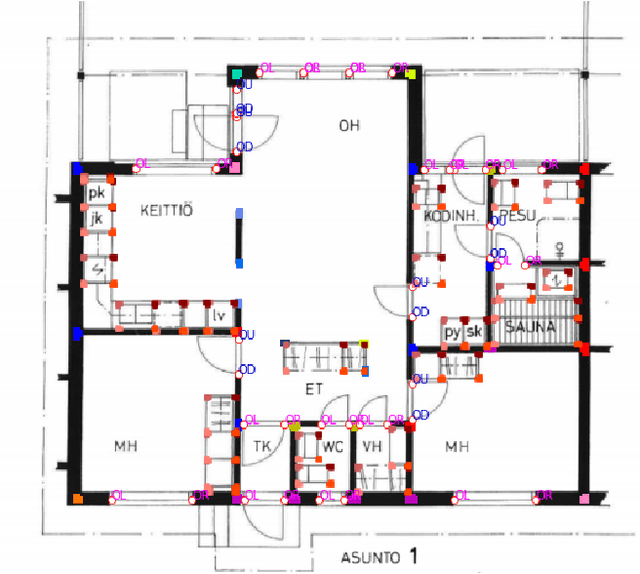
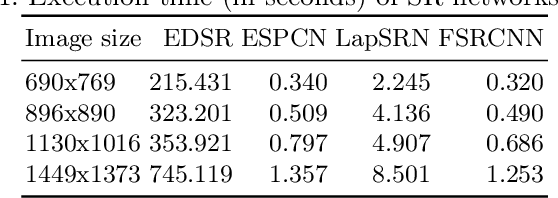
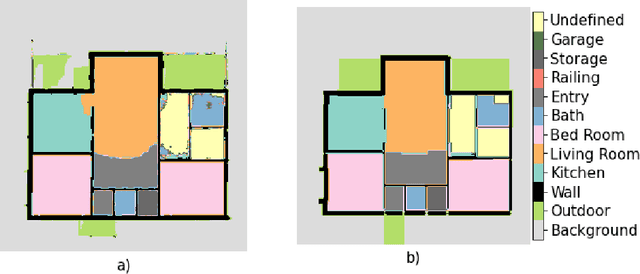
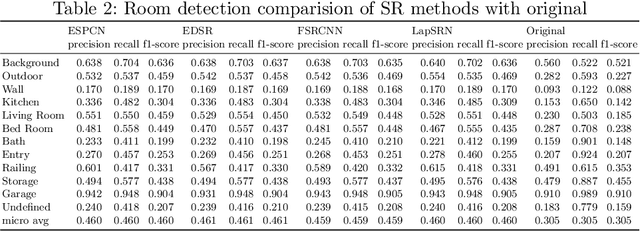
Building Information Modelling (BIM) software use scalable vector formats to enable flexible designing of floor plans in the industry. Floor plans in the architectural domain can come from many sources that may or may not be in scalable vector format. The conversion of floor plan images to fully annotated vector images is a process that can now be realized by computer vision. Novel datasets in this field have been used to train Convolutional Neural Network (CNN) architectures for object detection. Image enhancement through Super-Resolution (SR) is also an established CNN based network in computer vision that is used for converting low resolution images to high resolution ones. This work focuses on creating a multi-component module that stacks a SR model on a floor plan object detection model. The proposed stacked model shows greater performance than the corresponding vanilla object detection model. For the best case, the the inclusion of SR showed an improvement of 39.47% in object detection over the vanilla network. Data and code are made publicly available at https://github.com/rbg-research/Floor-Plan-Detection.
Self-supervised Recommendation with Cross-channel Matching Representation and Hierarchical Contrastive Learning
Sep 14, 2021
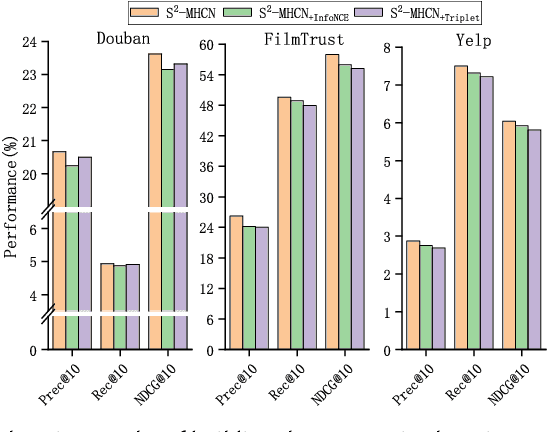
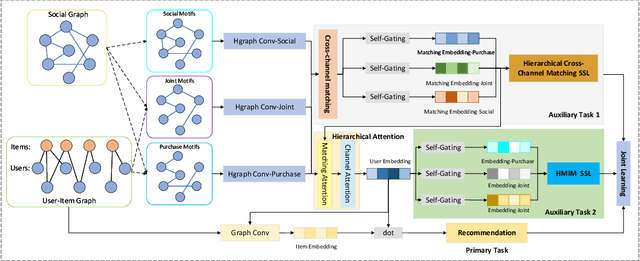
Recently, using different channels to model social semantic information, and using self-supervised learning tasks to maintain the characteristics of each channel when fusing the information, which has been proven to be a very promising work. However, how to deeply dig out the relationship between different channels and make full use of it while maintaining the uniqueness of each channel is a problem that has not been well studied and resolved in this field. Under such circumstances, this paper explores and verifies the deficiency of directly constructing contrastive learning tasks on different channels with practical experiments and proposes the scheme of interactive modeling and matching representation across different channels. This is the first attempt in the field of recommender systems, we believe the insight of this paper is inspirational to future self-supervised learning research based on multi-channel information. To solve this problem, we propose a cross-channel matching representation model based on attentive interaction, which realizes efficient modeling of the relationship between cross-channel information. Based on this, we also proposed a hierarchical self-supervised learning model, which realized two levels of self-supervised learning within and between channels and improved the ability of self-supervised tasks to autonomously mine different levels of potential information. We have conducted abundant experiments, and many experimental metrics on multiple public data sets show that the method proposed in this paper has a significant improvement compared with the state-of-the-art methods, no matter in the general or cold-start scenario. And in the experiment of model variant analysis, the benefits of the cross-channel matching representation model and the hierarchical self-supervised model proposed in this paper are also fully verified.
Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention
Dec 28, 2021



Recently, Transformers have shown promising performance in various vision tasks. To reduce the quadratic computation complexity caused by the global self-attention, various methods constrain the range of attention within a local region to improve its efficiency. Consequently, their receptive fields in a single attention layer are not large enough, resulting in insufficient context modeling. To address this issue, we propose a Pale-Shaped self-Attention (PS-Attention), which performs self-attention within a pale-shaped region. Compared to the global self-attention, PS-Attention can reduce the computation and memory costs significantly. Meanwhile, it can capture richer contextual information under the similar computation complexity with previous local self-attention mechanisms. Based on the PS-Attention, we develop a general Vision Transformer backbone with a hierarchical architecture, named Pale Transformer, which achieves 83.4%, 84.3%, and 84.9% Top-1 accuracy with the model size of 22M, 48M, and 85M respectively for 224 ImageNet-1K classification, outperforming the previous Vision Transformer backbones. For downstream tasks, our Pale Transformer backbone performs better than the recent state-of-the-art CSWin Transformer by a large margin on ADE20K semantic segmentation and COCO object detection & instance segmentation. The code will be released on https://github.com/BR-IDL/PaddleViT.
An Analysis of Attentive Walk-Aggregating Graph Neural Networks
Oct 06, 2021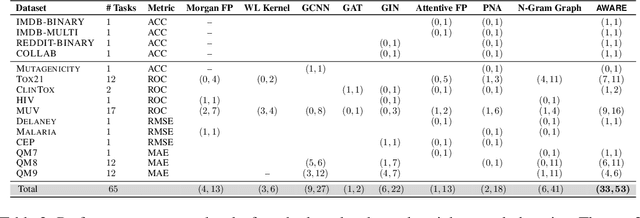

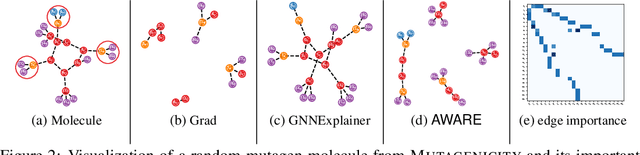
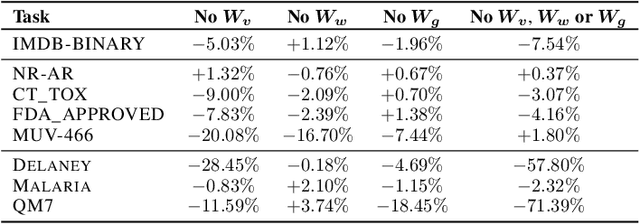
Graph neural networks (GNNs) have been shown to possess strong representation power, which can be exploited for downstream prediction tasks on graph-structured data, such as molecules and social networks. They typically learn representations by aggregating information from the K-hop neighborhood of individual vertices or from the enumerated walks in the graph. Prior studies have demonstrated the effectiveness of incorporating weighting schemes into GNNs; however, this has been primarily limited to K-hop neighborhood GNNs so far. In this paper, we aim to extensively analyze the effect of incorporating weighting schemes into walk-aggregating GNNs. Towards this objective, we propose a novel GNN model, called AWARE, that aggregates information about the walks in the graph using attention schemes in a principled way to obtain an end-to-end supervised learning method for graph-level prediction tasks. We perform theoretical, empirical, and interpretability analyses of AWARE. Our theoretical analysis provides the first provable guarantees for weighted GNNs, demonstrating how the graph information is encoded in the representation, and how the weighting schemes in AWARE affect the representation and learning performance. We empirically demonstrate the superiority of AWARE over prior baselines in the domains of molecular property prediction (61 tasks) and social networks (4 tasks). Our interpretation study illustrates that AWARE can successfully learn to capture the important substructures of the input graph.
Siamese Network with Interactive Transformer for Video Object Segmentation
Dec 28, 2021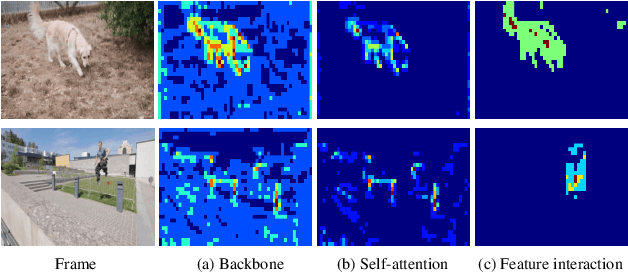
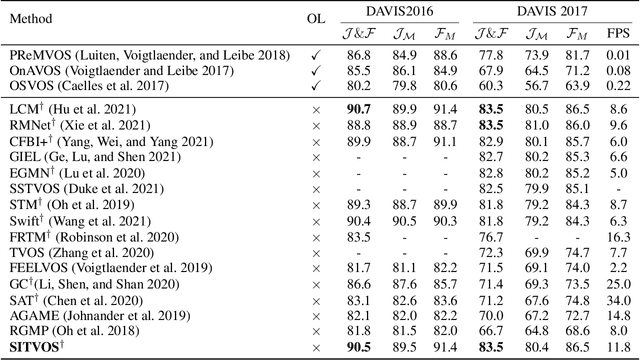
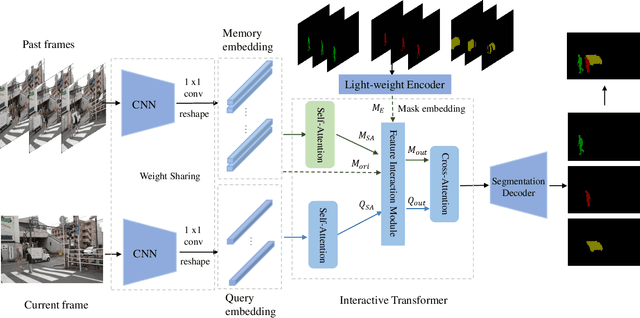
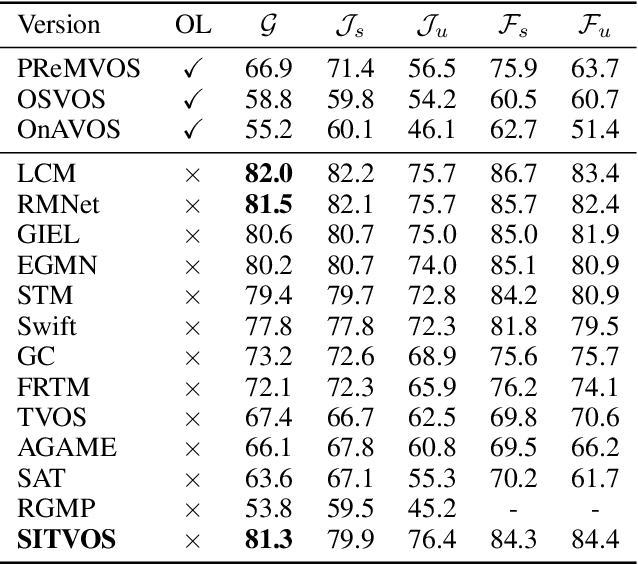
Semi-supervised video object segmentation (VOS) refers to segmenting the target object in remaining frames given its annotation in the first frame, which has been actively studied in recent years. The key challenge lies in finding effective ways to exploit the spatio-temporal context of past frames to help learn discriminative target representation of current frame. In this paper, we propose a novel Siamese network with a specifically designed interactive transformer, called SITVOS, to enable effective context propagation from historical to current frames. Technically, we use the transformer encoder and decoder to handle the past frames and current frame separately, i.e., the encoder encodes robust spatio-temporal context of target object from the past frames, while the decoder takes the feature embedding of current frame as the query to retrieve the target from the encoder output. To further enhance the target representation, a feature interaction module (FIM) is devised to promote the information flow between the encoder and decoder. Moreover, we employ the Siamese architecture to extract backbone features of both past and current frames, which enables feature reuse and is more efficient than existing methods. Experimental results on three challenging benchmarks validate the superiority of SITVOS over state-of-the-art methods.
Spatio-Temporal Graph Complementary Scattering Networks
Oct 23, 2021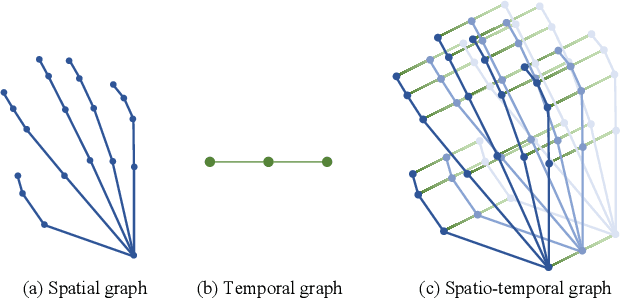

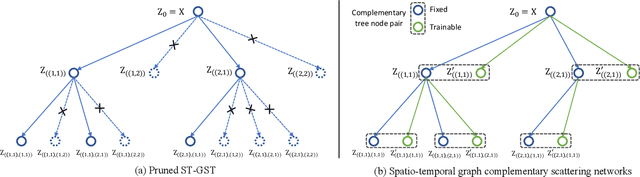

Spatio-temporal graph signal analysis has a significant impact on a wide range of applications, including hand/body pose action recognition. To achieve effective analysis, spatio-temporal graph convolutional networks (ST-GCN) leverage the powerful learning ability to achieve great empirical successes; however, those methods need a huge amount of high-quality training data and lack theoretical interpretation. To address this issue, the spatio-temporal graph scattering transform (ST-GST) was proposed to put forth a theoretically interpretable framework; however, the empirical performance of this approach is constrainted by the fully mathematical design. To benefit from both sides, this work proposes a novel complementary mechanism to organically combine the spatio-temporal graph scattering transform and neural networks, resulting in the proposed spatio-temporal graph complementary scattering networks (ST-GCSN). The essence is to leverage the mathematically designed graph wavelets with pruning techniques to cover major information and use trainable networks to capture complementary information. The empirical experiments on hand pose action recognition show that the proposed ST-GCSN outperforms both ST-GCN and ST-GST.
Applying graph matching techniques to enhance reuse of plant design information
Mar 23, 2021
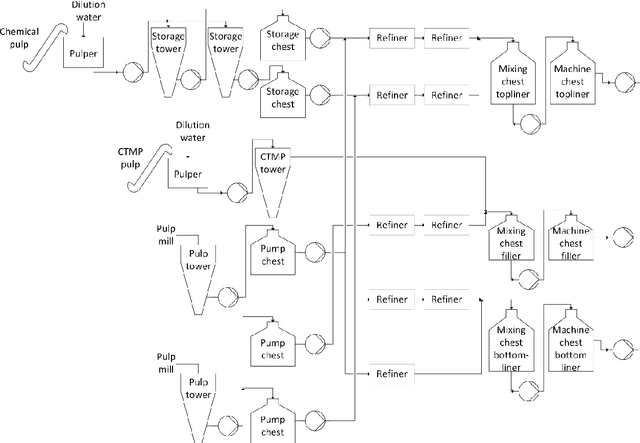
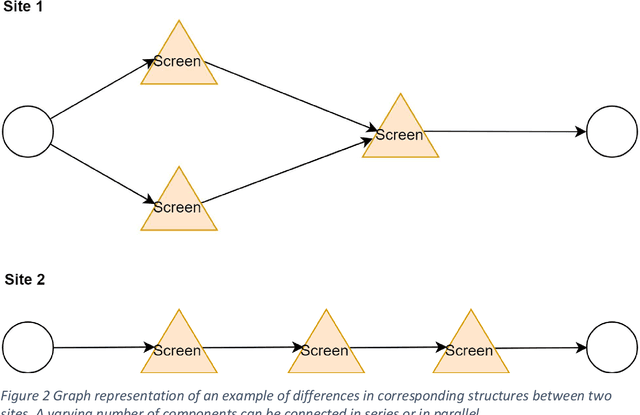
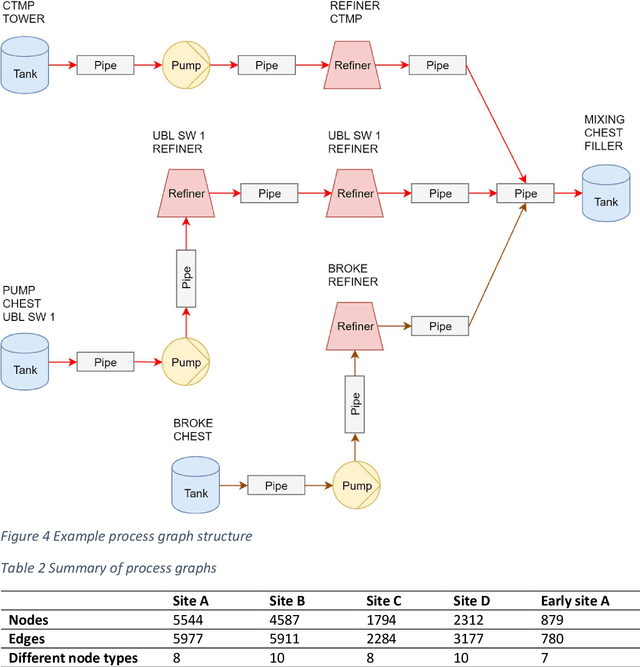
This article investigates how graph matching can be applied to process plant design data in order to support the reuse of previous designs. A literature review of existing graph matching algorithms is performed, and a group of algorithms is chosen for further testing. A use case from early phase plant design is presented. A methodology for addressing the use case is proposed, including graph simplification algorithms and node similarity measures, so that existing graph matching algorithms can be applied in the process plant domain. The proposed methodology is evaluated empirically on an industrial case consisting of design data from several pulp and paper plants.
MAg: a simple learning-based patient-level aggregation method for detecting microsatellite instability from whole-slide images
Jan 13, 2022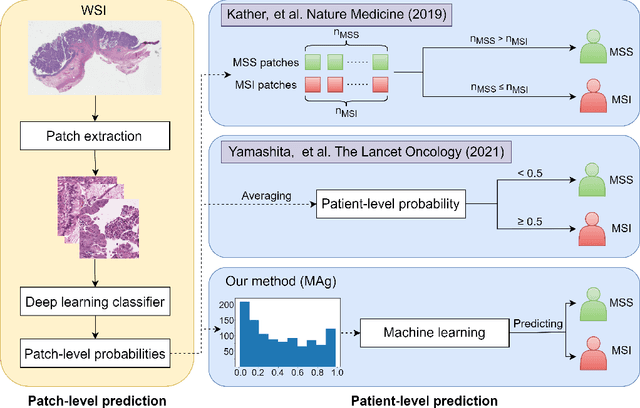
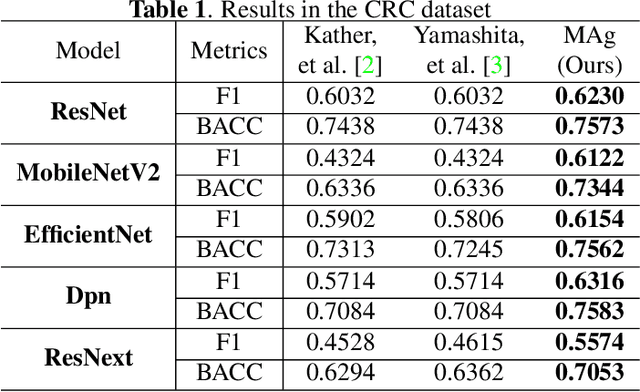
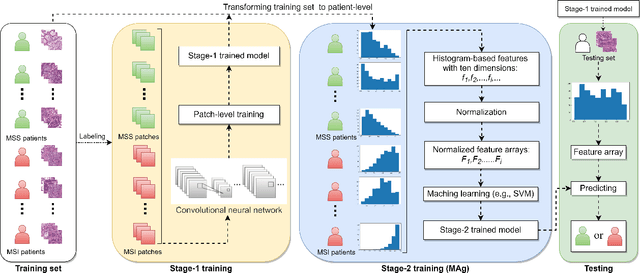
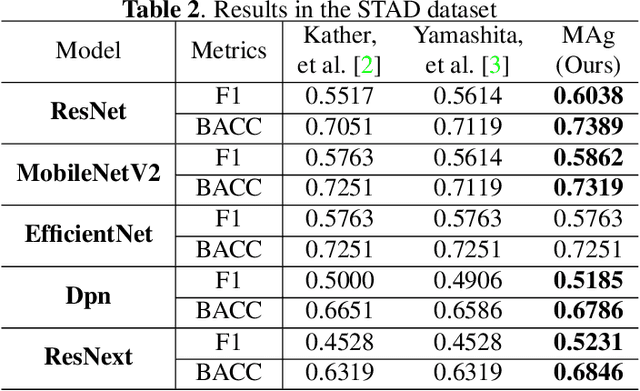
The prediction of microsatellite instability (MSI) and microsatellite stability (MSS) is essential in predicting both the treatment response and prognosis of gastrointestinal cancer. In clinical practice, a universal MSI testing is recommended, but the accessibility of such a test is limited. Thus, a more cost-efficient and broadly accessible tool is desired to cover the traditionally untested patients. In the past few years, deep-learning-based algorithms have been proposed to predict MSI directly from haematoxylin and eosin (H&E)-stained whole-slide images (WSIs). Such algorithms can be summarized as (1) patch-level MSI/MSS prediction, and (2) patient-level aggregation. Compared with the advanced deep learning approaches that have been employed for the first stage, only the na\"ive first-order statistics (e.g., averaging and counting) were employed in the second stage. In this paper, we propose a simple yet broadly generalizable patient-level MSI aggregation (MAg) method to effectively integrate the precious patch-level information. Briefly, the entire probabilistic distribution in the first stage is modeled as histogram-based features to be fused as the final outcome with machine learning (e.g., SVM). The proposed MAg method can be easily used in a plug-and-play manner, which has been evaluated upon five broadly used deep neural networks: ResNet, MobileNetV2, EfficientNet, Dpn and ResNext. From the results, the proposed MAg method consistently improves the accuracy of patient-level aggregation for two publicly available datasets. It is our hope that the proposed method could potentially leverage the low-cost H&E based MSI detection method. The code of our work has been made publicly available at https://github.com/Calvin-Pang/MAg.
Revisiting spatio-temporal layouts for compositional action recognition
Nov 02, 2021
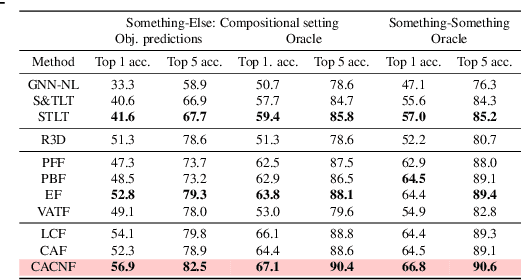
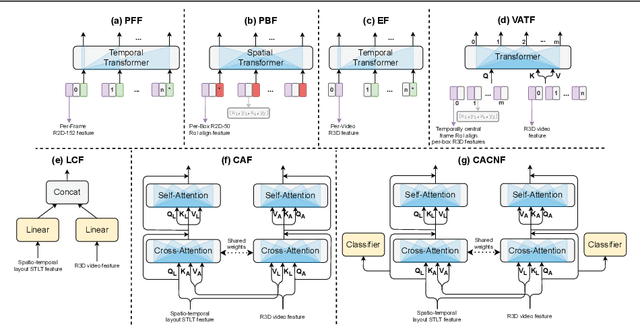
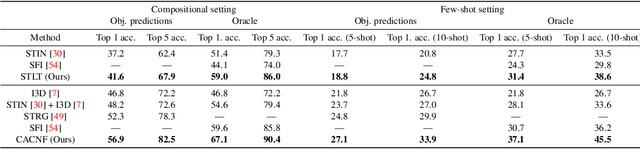
Recognizing human actions is fundamentally a spatio-temporal reasoning problem, and should be, at least to some extent, invariant to the appearance of the human and the objects involved. Motivated by this hypothesis, in this work, we take an object-centric approach to action recognition. Multiple works have studied this setting before, yet it remains unclear (i) how well a carefully crafted, spatio-temporal layout-based method can recognize human actions, and (ii) how, and when, to fuse the information from layout and appearance-based models. The main focus of this paper is compositional/few-shot action recognition, where we advocate the usage of multi-head attention (proven to be effective for spatial reasoning) over spatio-temporal layouts, i.e., configurations of object bounding boxes. We evaluate different schemes to inject video appearance information to the system, and benchmark our approach on background cluttered action recognition. On the Something-Else and Action Genome datasets, we demonstrate (i) how to extend multi-head attention for spatio-temporal layout-based action recognition, (ii) how to improve the performance of appearance-based models by fusion with layout-based models, (iii) that even on non-compositional background-cluttered video datasets, a fusion between layout- and appearance-based models improves the performance.
Advancing Residual Learning towards Powerful Deep Spiking Neural Networks
Dec 23, 2021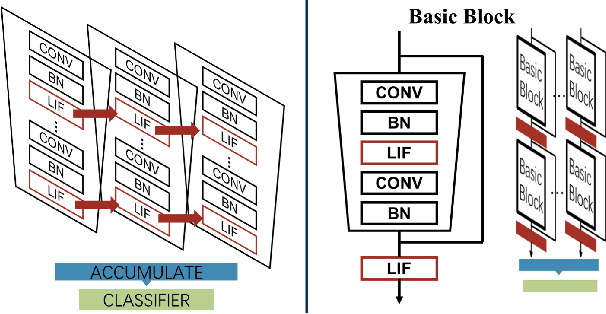

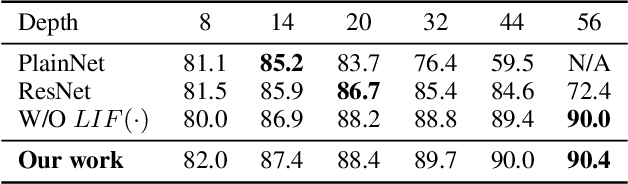
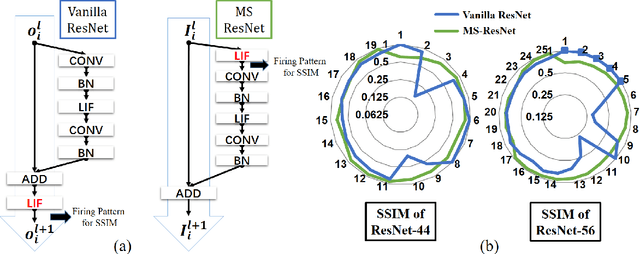
Despite the rapid progress of neuromorphic computing, inadequate capacity and insufficient representation power of spiking neural networks (SNNs) severely restrict their application scope in practice. Residual learning and shortcuts have been evidenced as an important approach for training deep neural networks, but rarely did previous work assess their applicability to the characteristics of spike-based communication and spatiotemporal dynamics. In this paper, we first identify that this negligence leads to impeded information flow and accompanying degradation problem in previous residual SNNs. Then we propose a novel SNN-oriented residual block, MS-ResNet, which is able to significantly extend the depth of directly trained SNNs, e.g. up to 482 layers on CIFAR-10 and 104 layers on ImageNet, without observing any slight degradation problem. We validate the effectiveness of MS-ResNet on both frame-based and neuromorphic datasets, and MS-ResNet104 achieves a superior result of 76.02% accuracy on ImageNet, the first time in the domain of directly trained SNNs. Great energy efficiency is also observed that on average only one spike per neuron is needed to classify an input sample. We believe our powerful and scalable models will provide a strong support for further exploration of SNNs.