 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Universal Transformer Hawkes Process with Adaptive Recursive Iteration
Dec 29, 2021

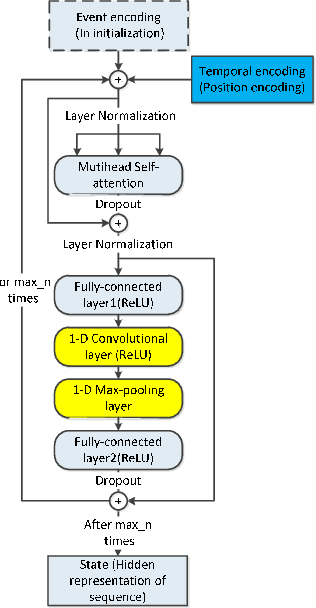
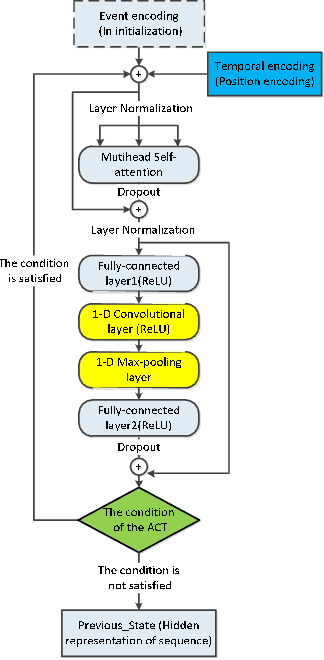
Asynchronous events sequences are widely distributed in the natural world and human activities, such as earthquakes records, users activities in social media and so on. How to distill the information from these seemingly disorganized data is a persistent topic that researchers focus on. The one of the most useful model is the point process model, and on the basis, the researchers obtain many noticeable results. Moreover, in recent years, point process models on the foundation of neural networks, especially recurrent neural networks (RNN) are proposed and compare with the traditional models, their performance are greatly improved. Enlighten by transformer model, which can learning sequence data efficiently without recurrent and convolutional structure, transformer Hawkes process is come out, and achieves state-of-the-art performance. However, there is some research proving that the re-introduction of recursive calculations in transformer can further improve transformers performance. Thus, we come out with a new kind of transformer Hawkes process model, universal transformer Hawkes process (UTHP), which contains both recursive mechanism and self-attention mechanism, and to improve the local perception ability of the model, we also introduce convolutional neural network (CNN) in the position-wise-feed-forward part. We conduct experiments on several datasets to validate the effectiveness of UTHP and explore the changes after the introduction of the recursive mechanism. These experiments on multiple datasets demonstrate that the performance of our proposed new model has a certain improvement compared with the previous state-of-the-art models.
A Survey of Knowledge Graph Embedding and Their Applications
Jul 16, 2021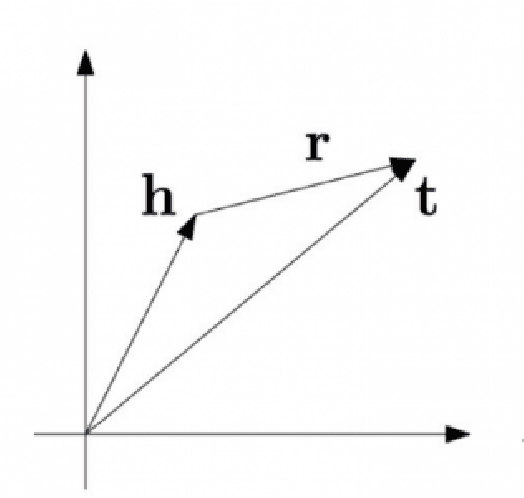
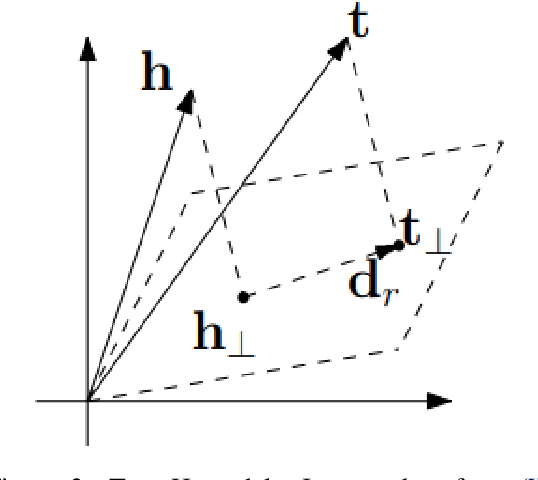
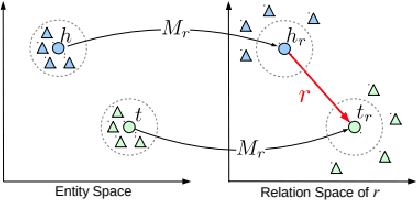
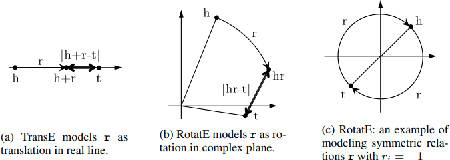
Knowledge Graph embedding provides a versatile technique for representing knowledge. These techniques can be used in a variety of applications such as completion of knowledge graph to predict missing information, recommender systems, question answering, query expansion, etc. The information embedded in Knowledge graph though being structured is challenging to consume in a real-world application. Knowledge graph embedding enables the real-world application to consume information to improve performance. Knowledge graph embedding is an active research area. Most of the embedding methods focus on structure-based information. Recent research has extended the boundary to include text-based information and image-based information in entity embedding. Efforts have been made to enhance the representation with context information. This paper introduces growth in the field of KG embedding from simple translation-based models to enrichment-based models. This paper includes the utility of the Knowledge graph in real-world applications.
The Tensor Brain: A Unified Theory of Perception, Memory and Semantic Decoding
Sep 27, 2021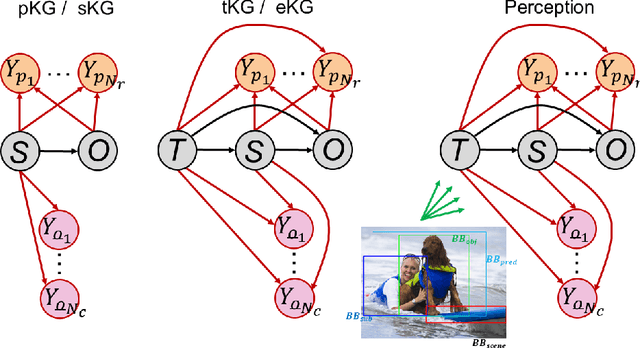

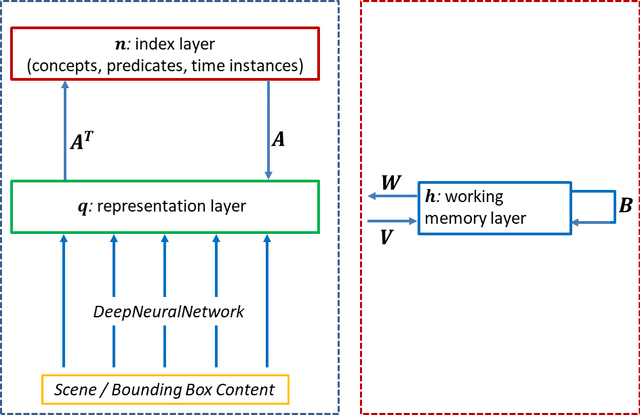
We present a unified computational theory of perception and memory. In our model, perception, episodic memory, and semantic memory are realized by different functional and operational modes of the oscillating interactions between an index layer and a representation layer in a bilayer tensor network (BTN). The memoryless semantic {representation layer} broadcasts information. In cognitive neuroscience, it would be the "mental canvas", or the "global workspace" and reflects the cognitive brain state. The symbolic {index layer} represents concepts and past episodes, whose semantic embeddings are implemented in the connection weights between both layers. In addition, we propose a {working memory layer} as a processing center and information buffer. Episodic and semantic memory realize memory-based reasoning, i.e., the recall of relevant past information to enrich perception, and are personalized to an agent's current state, as well as to an agent's unique memories. Episodic memory stores and retrieves past observations and provides provenance and context. Recent episodic memory enriches perception by the retrieval of perceptual experiences, which provide the agent with a sense about the here and now: to understand its own state, and the world's semantic state in general, the agent needs to know what happened recently, in recent scenes, and on recently perceived entities. Remote episodic memory retrieves relevant past experiences, contributes to our conscious self, and, together with semantic memory, to a large degree defines who we are as individuals.
The identity of information: how deterministic dependencies constrain information synergy and redundancy
Nov 13, 2017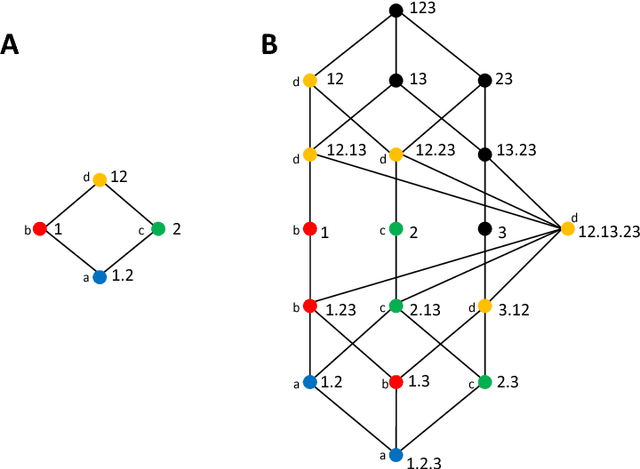
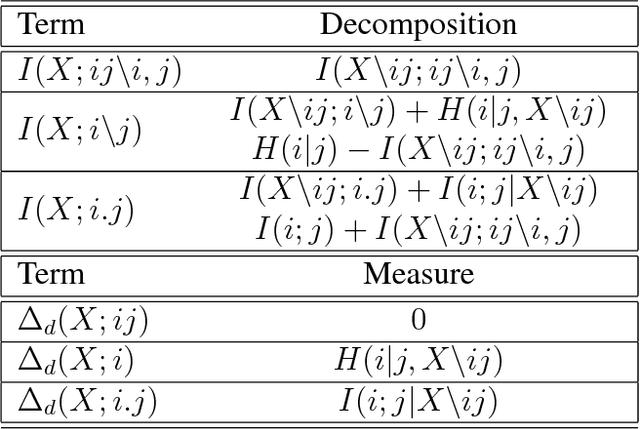

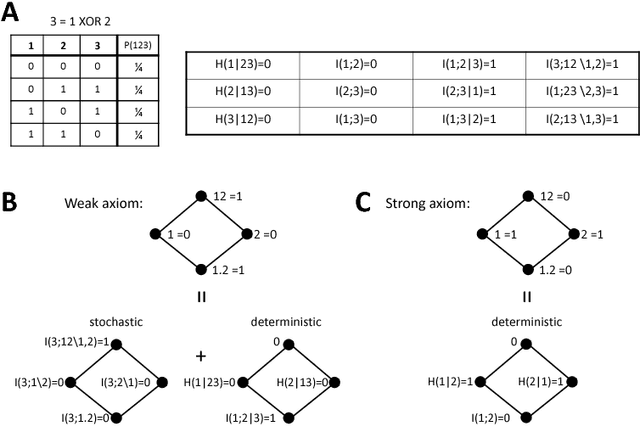
Understanding how different information sources together transmit information is crucial in many domains. For example, understanding the neural code requires characterizing how different neurons contribute unique, redundant, or synergistic pieces of information about sensory or behavioral variables. Williams and Beer (2010) proposed a partial information decomposition (PID) which separates the mutual information that a set of sources contains about a set of targets into nonnegative terms interpretable as these pieces. Quantifying redundancy requires assigning an identity to different information pieces, to assess when information is common across sources. Harder et al. (2013) proposed an identity axiom stating that there cannot be redundancy between two independent sources about a copy of themselves. However, Bertschinger et al. (2012) showed that with a deterministically related sources-target copy this axiom is incompatible with ensuring PID nonnegativity. Here we study systematically the effect of deterministic target-sources dependencies. We introduce two synergy stochasticity axioms that generalize the identity axiom, and we derive general expressions separating stochastic and deterministic PID components. Our analysis identifies how negative terms can originate from deterministic dependencies and shows how different assumptions on information identity, implicit in the stochasticity and identity axioms, determine the PID structure. The implications for studying neural coding are discussed.
Information Bottleneck Methods on Convolutional Neural Networks
Nov 09, 2019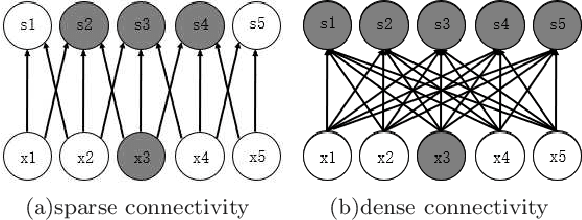
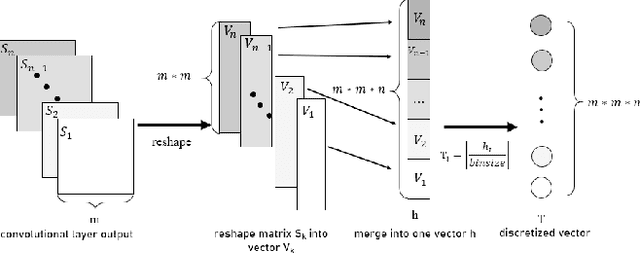
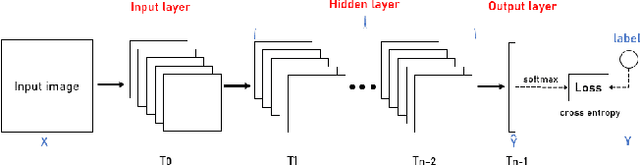
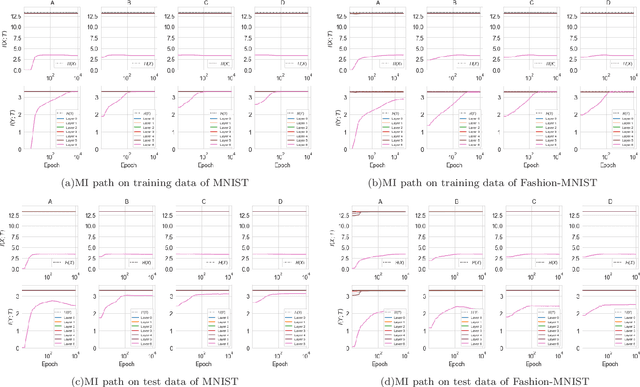
Recent year, many researches attempt to open the black box of deep neural networks and propose a various of theories to understand it. Among them, information bottleneck theory (IB) claims that there are two distinct phases consisting of fitting phase and compression phase in the course of training. This statement attracts many attentions since its success in explaining the inner behavior of feedforward neural networks. In this paper, we employ IB theory to understand the dynamic behavior of convolutional neural networks (CNNs) and investigate how the fundamental features have impact on the performance of CNNs. In particular, through a series of experimental analysis on benchmark of MNIST and Fashion-MNIST, we demonstrate that the compression phase is not observed in all these cases. This show us the CNNs have a rather complicated behavior than feedforward neural networks.
Fair Data Representation for Machine Learning at the Pareto Frontier
Jan 02, 2022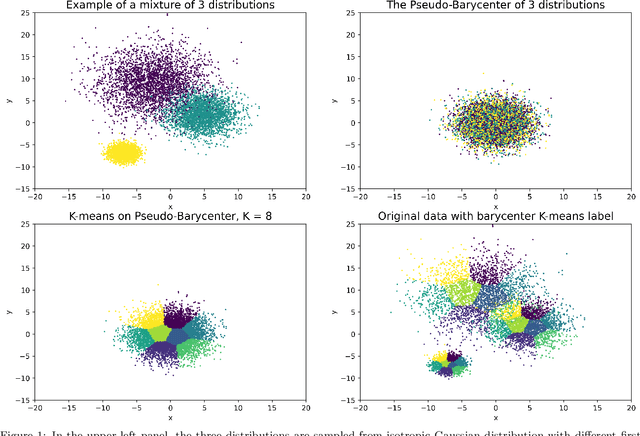
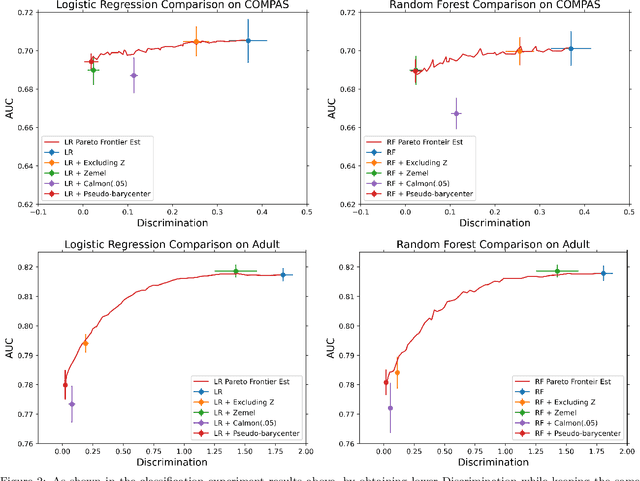
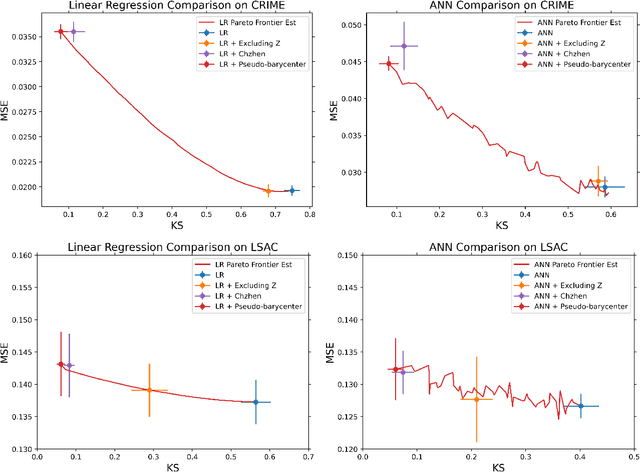
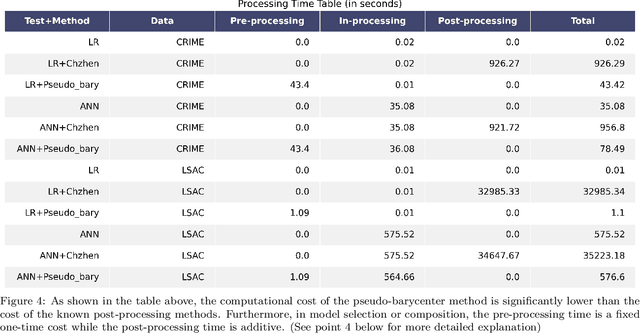
As machine learning powered decision making is playing an increasingly important role in our daily lives, it is imperative to strive for fairness of the underlying data processing and algorithms. We propose a pre-processing algorithm for fair data representation via which L2- objective supervised learning algorithms result in an estimation of the Pareto frontier between prediction error and statistical disparity. In particular, the present work applies the optimal positive definite affine transport maps to approach the post-processing Wasserstein barycenter characterization of the optimal fair L2-objective supervised learning via a pre-processing data deformation. We call the resulting data Wasserstein pseudo-barycenter. Furthermore, we show that the Wasserstein geodesics from the learning outcome marginals to the barycenter characterizes the Pareto frontier between L2-loss and total Wasserstein distance among learning outcome marginals. Thereby, an application of McCann interpolation generalizes the pseudo-barycenter to a family of data representations via which L2-objective supervised learning algorithms result in the Pareto frontier. Numerical simulations underscore the advantages of the proposed data representation: (1) the pre-processing step is compositive with arbitrary L2-objective supervised learning methods and unseen data; (2) the fair representation protects data privacy by preventing the training machine from direct or indirect access to the sensitive information of the data; (3) the optimal affine map results in efficient computation of fair supervised learning on high-dimensional data; (4) experimental results shed light on the fairness of L2-objective unsupervised learning via the proposed fair data representation.
JoinABLe: Learning Bottom-up Assembly of Parametric CAD Joints
Nov 24, 2021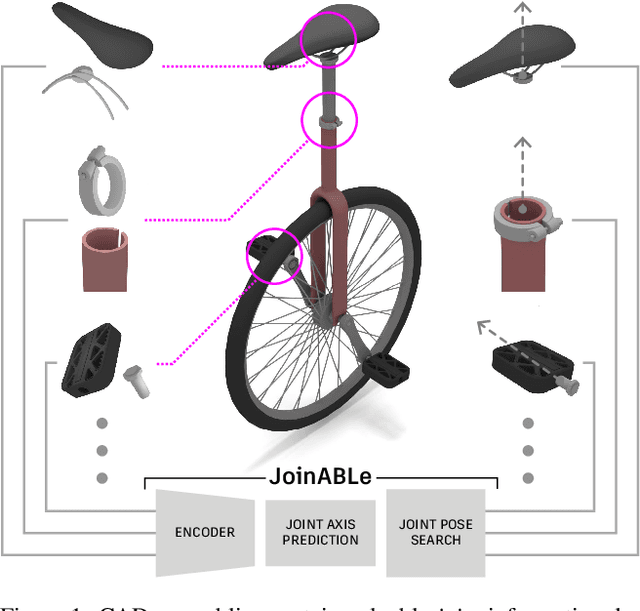
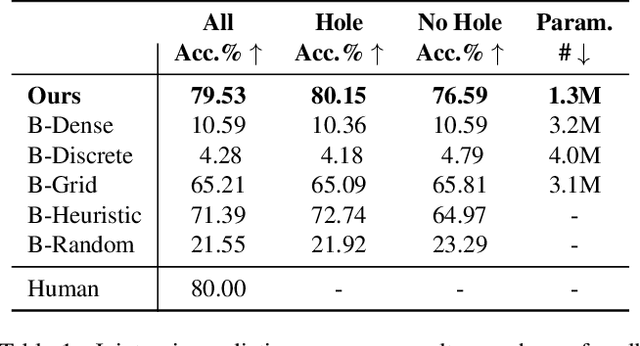
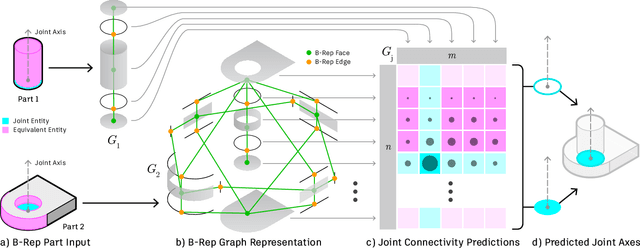
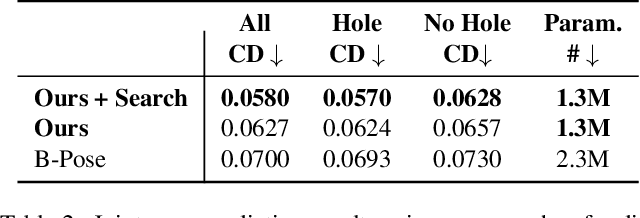
Physical products are often complex assemblies combining a multitude of 3D parts modeled in computer-aided design (CAD) software. CAD designers build up these assemblies by aligning individual parts to one another using constraints called joints. In this paper we introduce JoinABLe, a learning-based method that assembles parts together to form joints. JoinABLe uses the weak supervision available in standard parametric CAD files without the help of object class labels or human guidance. Our results show that by making network predictions over a graph representation of solid models we can outperform multiple baseline methods with an accuracy (79.53%) that approaches human performance (80%). Finally, to support future research we release the Fusion 360 Gallery assembly dataset, containing assemblies with rich information on joints, contact surfaces, holes, and the underlying assembly graph structure.
The Power of Communication in a Distributed Multi-Agent System
Dec 01, 2021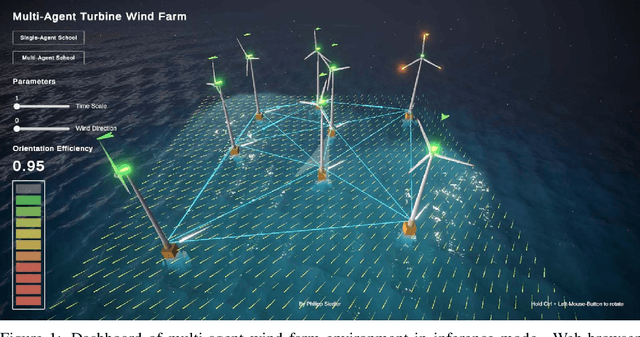
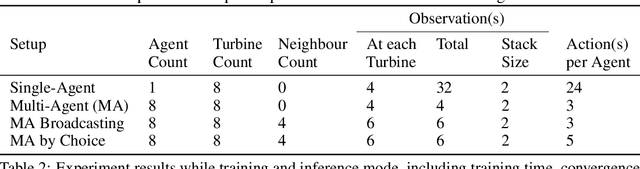


Single-Agent (SA) Reinforcement Learning systems have shown outstanding re-sults on non-stationary problems. However, Multi-Agent Reinforcement Learning(MARL) can surpass SA systems generally and when scaling. Furthermore, MAsystems can be super-powered by collaboration, which can happen through ob-serving others, or a communication system used to share information betweencollaborators. Here, we developed a distributed MA learning mechanism withthe ability to communicate based on decentralised partially observable Markovdecision processes (Dec-POMDPs) and Graph Neural Networks (GNNs). Minimis-ing the time and energy consumed by training Machine Learning models whileimproving performance can be achieved by collaborative MA mechanisms. Wedemonstrate this in a real-world scenario, an offshore wind farm, including a set ofdistributed wind turbines, where the objective is to maximise collective efficiency.Compared to a SA system, MA collaboration has shown significantly reducedtraining time and higher cumulative rewards in unseen and scaled scenarios.
ScanQA: 3D Question Answering for Spatial Scene Understanding
Dec 20, 2021

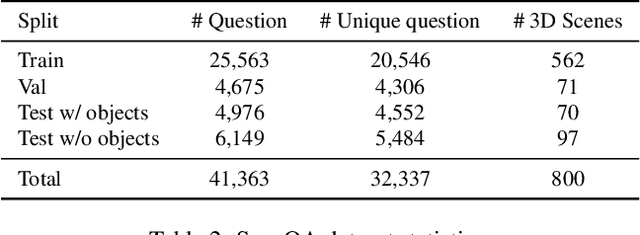

We propose a new 3D spatial understanding task of 3D Question Answering (3D-QA). In the 3D-QA task, models receive visual information from the entire 3D scene of the rich RGB-D indoor scan and answer the given textual questions about the 3D scene. Unlike the 2D-question answering of VQA, the conventional 2D-QA models suffer from problems with spatial understanding of object alignment and directions and fail the object localization from the textual questions in 3D-QA. We propose a baseline model for 3D-QA, named ScanQA model, where the model learns a fused descriptor from 3D object proposals and encoded sentence embeddings. This learned descriptor correlates the language expressions with the underlying geometric features of the 3D scan and facilitates the regression of 3D bounding boxes to determine described objects in textual questions. We collected human-edited question-answer pairs with free-form answers that are grounded to 3D objects in each 3D scene. Our new ScanQA dataset contains over 41K question-answer pairs from the 800 indoor scenes drawn from the ScanNet dataset. To the best of our knowledge, ScanQA is the first large-scale effort to perform object-grounded question-answering in 3D environments.
Where were my keys? -- Aggregating Spatial-Temporal Instances of Objects for Efficient Retrieval over Long Periods of Time
Oct 25, 2021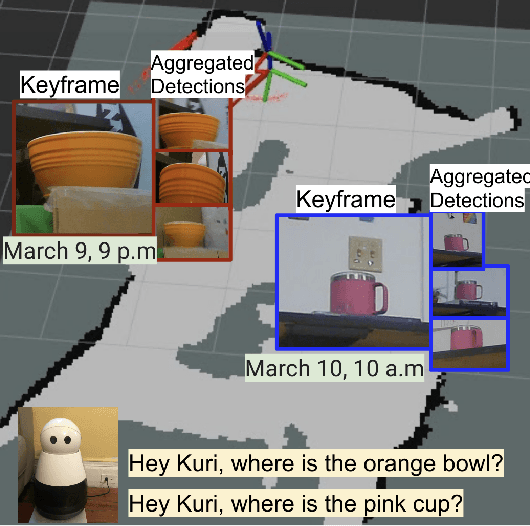

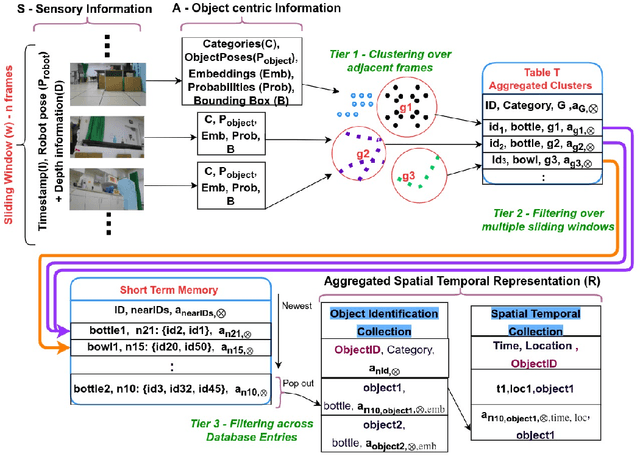
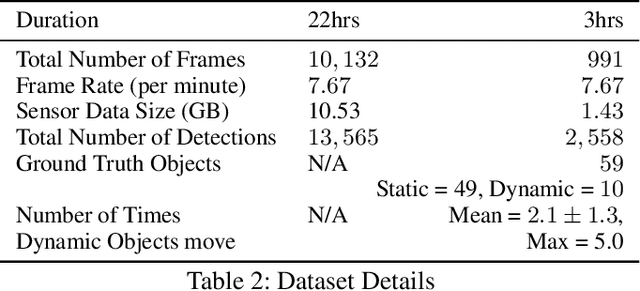
Robots equipped with situational awareness can help humans efficiently find their lost objects by leveraging spatial and temporal structure. Existing approaches to video and image retrieval do not take into account the unique constraints imposed by a moving camera with a partial view of the environment. We present a Detection-based 3-level hierarchical Association approach, D3A, to create an efficient query-able spatial-temporal representation of unique object instances in an environment. D3A performs online incremental and hierarchical learning to identify keyframes that best represent the unique objects in the environment. These keyframes are learned based on both spatial and temporal features and once identified their corresponding spatial-temporal information is organized in a key-value database. D3A allows for a variety of query patterns such as querying for objects with/without the following: 1) specific attributes, 2) spatial relationships with other objects, and 3) time slices. For a given set of 150 queries, D3A returns a small set of candidate keyframes (which occupy only 0.17% of the total sensory data) with 81.98\% mean accuracy in 11.7 ms. This is 47x faster and 33% more accurate than a baseline that naively stores the object matches (detections) in the database without associating spatial-temporal information.