 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Personalizing ASR with limited data using targeted subset selection
Oct 29, 2021
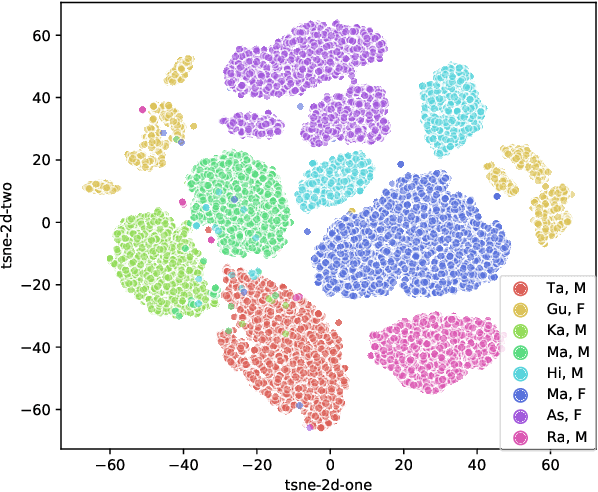
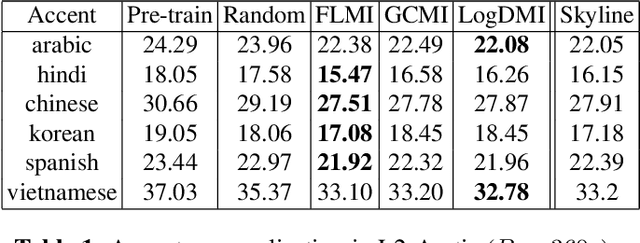
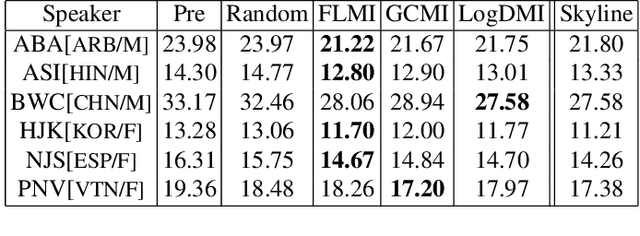
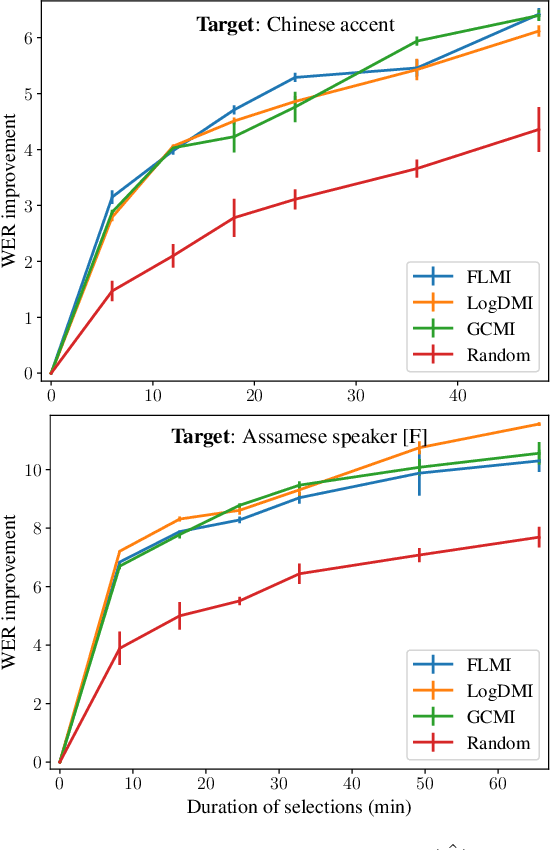
We study the task of personalizing ASR models to a target non-native speaker/accent while being constrained by a transcription budget on the duration of utterances selected from a large unlabelled corpus. We propose a subset selection approach using the recently proposed submodular mutual information functions, in which we identify a diverse set of utterances that match the target speaker/accent. This is specified through a few target utterances and achieved by modeling the relationship between the target subset and the selected subset using submodular mutual information functions. This method is applied at both the speaker and accent levels. We personalize the model by fine tuning it with utterances selected and transcribed from the unlabelled corpus. Our method is able to consistently identify utterances from the target speaker/accent using just speech features. We show that the targeted subset selection approach improves upon random sampling by as much as 2% to 5% (absolute) depending on the speaker and accent and is 2x to 4x more label-efficient compared to random sampling. We also compare with a skyline where we specifically pick from the target and our method generally outperforms the oracle in its selections.
3D Reconstruction of Curvilinear Structures with Stereo Matching DeepConvolutional Neural Networks
Oct 14, 2021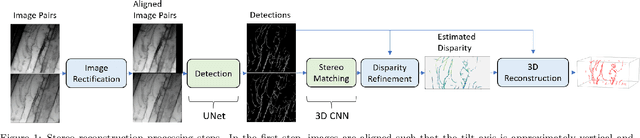

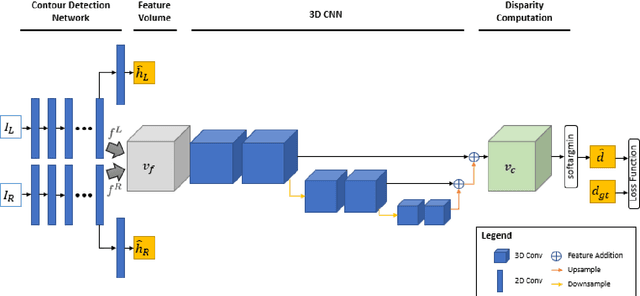
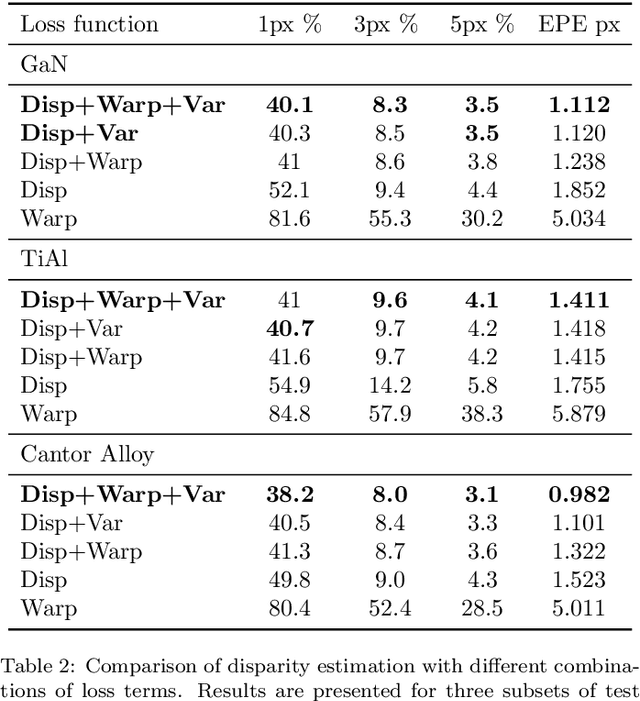
Curvilinear structures frequently appear in microscopy imaging as the object of interest. Crystallographic defects, i.e., dislocations, are one of the curvilinear structures that have been repeatedly investigated under transmission electron microscopy (TEM) and their 3D structural information is of great importance for understanding the properties of materials. 3D information of dislocations is often obtained by tomography which is a cumbersome process since it is required to acquire many images with different tilt angles and similar imaging conditions. Although, alternative stereoscopy methods lower the number of required images to two, they still require human intervention and shape priors for accurate 3D estimation. We propose a fully automated pipeline for both detection and matching of curvilinear structures in stereo pairs by utilizing deep convolutional neural networks (CNNs) without making any prior assumption on 3D shapes. In this work, we mainly focus on 3D reconstruction of dislocations from stereo pairs of TEM images.
Flexible Option Learning
Dec 06, 2021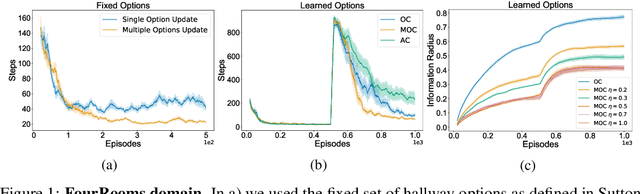
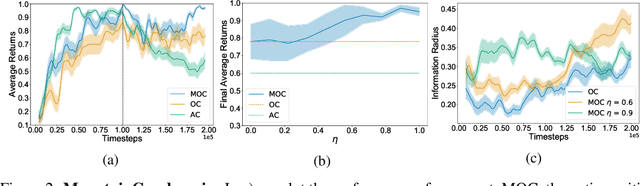

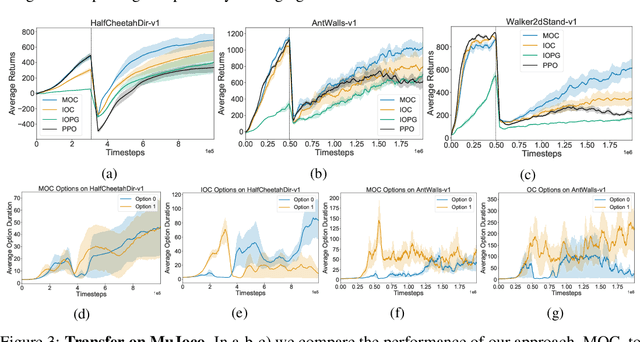
Temporal abstraction in reinforcement learning (RL), offers the promise of improving generalization and knowledge transfer in complex environments, by propagating information more efficiently over time. Although option learning was initially formulated in a way that allows updating many options simultaneously, using off-policy, intra-option learning (Sutton, Precup & Singh, 1999), many of the recent hierarchical reinforcement learning approaches only update a single option at a time: the option currently executing. We revisit and extend intra-option learning in the context of deep reinforcement learning, in order to enable updating all options consistent with current primitive action choices, without introducing any additional estimates. Our method can therefore be naturally adopted in most hierarchical RL frameworks. When we combine our approach with the option-critic algorithm for option discovery, we obtain significant improvements in performance and data-efficiency across a wide variety of domains.
Deep Depth from Focus with Differential Focus Volume
Dec 03, 2021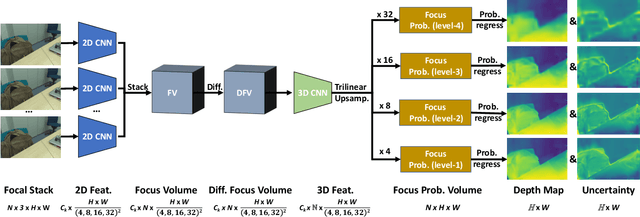

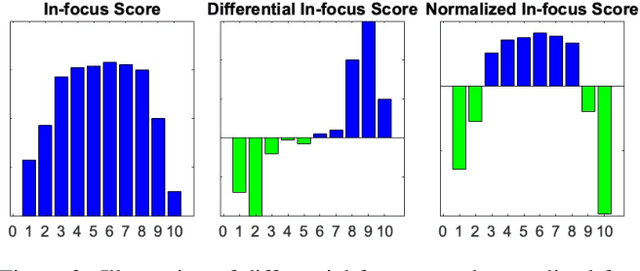

Depth-from-focus (DFF) is a technique that infers depth using the focus change of a camera. In this work, we propose a convolutional neural network (CNN) to find the best-focused pixels in a focal stack and infer depth from the focus estimation. The key innovation of the network is the novel deep differential focus volume (DFV). By computing the first-order derivative with the stacked features over different focal distances, DFV is able to capture both the focus and context information for focus analysis. Besides, we also introduce a probability regression mechanism for focus estimation to handle sparsely sampled focal stacks and provide uncertainty estimation to the final prediction. Comprehensive experiments demonstrate that the proposed model achieves state-of-the-art performance on multiple datasets with good generalizability and fast speed.
Learning Reward Functions from Scale Feedback
Oct 01, 2021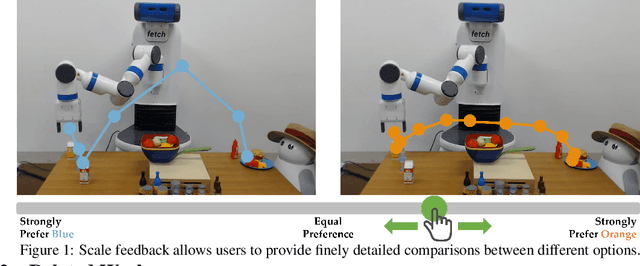

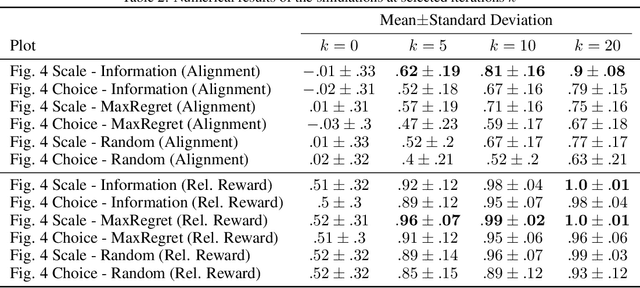

Today's robots are increasingly interacting with people and need to efficiently learn inexperienced user's preferences. A common framework is to iteratively query the user about which of two presented robot trajectories they prefer. While this minimizes the users effort, a strict choice does not yield any information on how much one trajectory is preferred. We propose scale feedback, where the user utilizes a slider to give more nuanced information. We introduce a probabilistic model on how users would provide feedback and derive a learning framework for the robot. We demonstrate the performance benefit of slider feedback in simulations, and validate our approach in two user studies suggesting that scale feedback enables more effective learning in practice.
Biased or Not?: The Story of Two Search Engines
Dec 23, 2021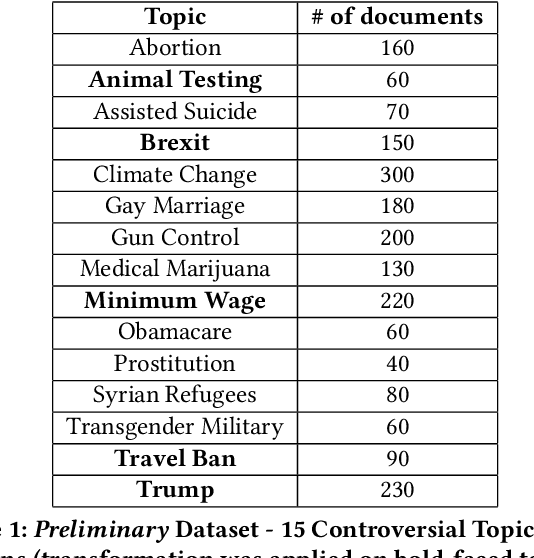
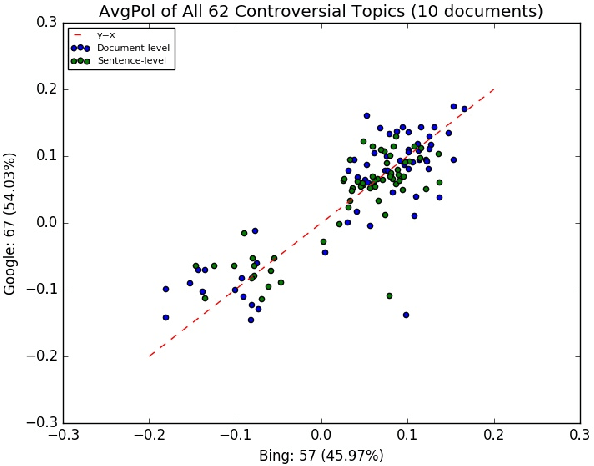
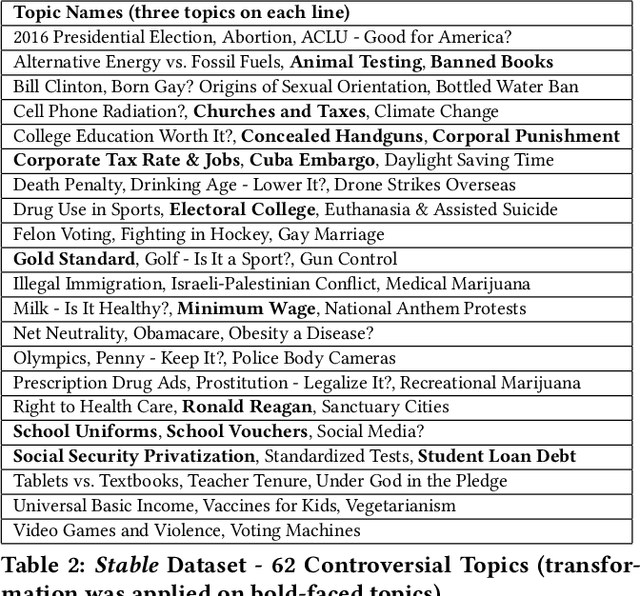
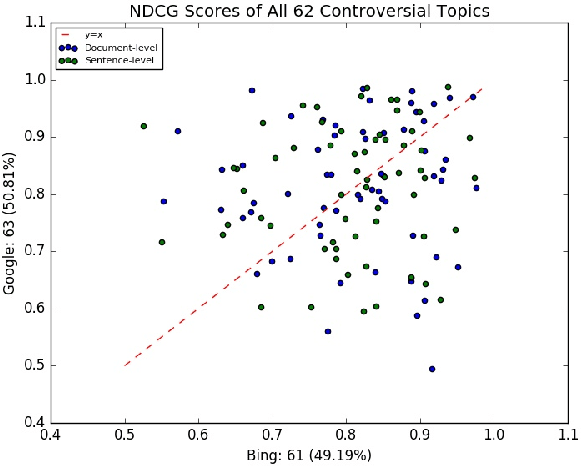
Search engines can be considered as a gate to the world of WEB, and they also decide what we see for a given search query. Since many people are exposed to information through search engines, it is fair to expect that search engines should be neutral; i.e. the returned results must cover all the elements or aspects of the search topic, and they should be impartial where the results are returned based on relevance. However, the search engine results are based on many features and sophisticated algorithms where search neutrality is not necessarily the focal point. In this work we performed an empirical study on two popular search engines and analysed the search engine result pages for controversial topics such as abortion, medical marijuana, and gay marriage. Our analysis is based on the sentiment in search results to identify their viewpoint as conservative or liberal. We also propose three sentiment-based metrics to show the existence of bias as well as to compare viewpoints of the two search engines. Extensive experiments performed on controversial topics show that both search engines are biased, moreover they have the same kind of bias towards a given controversial topic.
Deep Keyphrase Completion
Oct 29, 2021
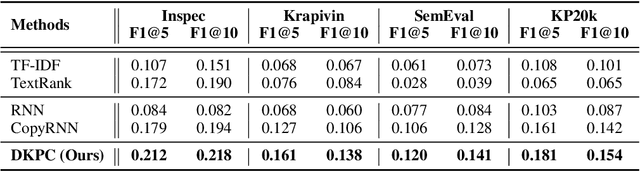
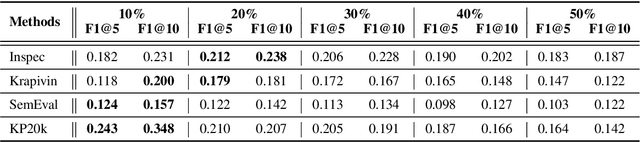

Keyphrase provides accurate information of document content that is highly compact, concise, full of meanings, and widely used for discourse comprehension, organization, and text retrieval. Though previous studies have made substantial efforts for automated keyphrase extraction and generation, surprisingly, few studies have been made for \textit{keyphrase completion} (KPC). KPC aims to generate more keyphrases for document (e.g. scientific publication) taking advantage of document content along with a very limited number of known keyphrases, which can be applied to improve text indexing system, etc. In this paper, we propose a novel KPC method with an encoder-decoder framework. We name it \textit{deep keyphrase completion} (DKPC) since it attempts to capture the deep semantic meaning of the document content together with known keyphrases via a deep learning framework. Specifically, the encoder and the decoder in DKPC play different roles to make full use of the known keyphrases. The former considers the keyphrase-guiding factors, which aggregates information of known keyphrases into context. On the contrary, the latter considers the keyphrase-inhibited factor to inhibit semantically repeated keyphrase generation. Extensive experiments on benchmark datasets demonstrate the efficacy of our proposed model.
Hierarchical Multimodal Transformer to Summarize Videos
Sep 22, 2021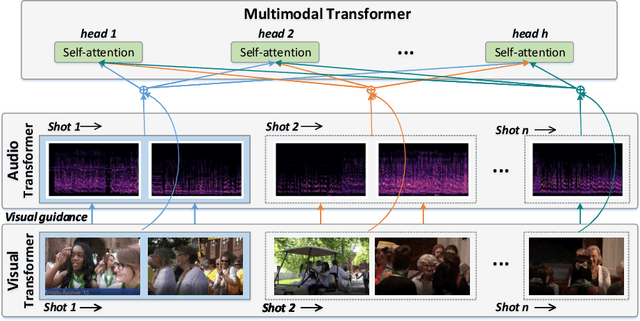
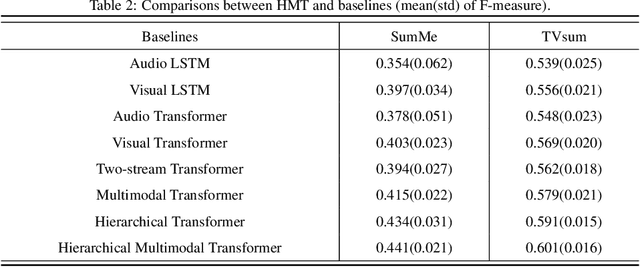
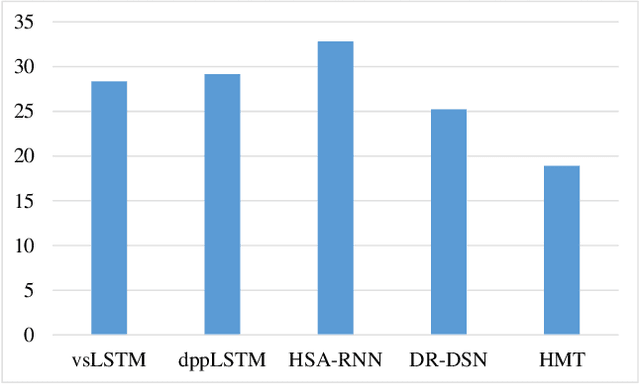
Although video summarization has achieved tremendous success benefiting from Recurrent Neural Networks (RNN), RNN-based methods neglect the global dependencies and multi-hop relationships among video frames, which limits the performance. Transformer is an effective model to deal with this problem, and surpasses RNN-based methods in several sequence modeling tasks, such as machine translation, video captioning, \emph{etc}. Motivated by the great success of transformer and the natural structure of video (frame-shot-video), a hierarchical transformer is developed for video summarization, which can capture the dependencies among frame and shots, and summarize the video by exploiting the scene information formed by shots. Furthermore, we argue that both the audio and visual information are essential for the video summarization task. To integrate the two kinds of information, they are encoded in a two-stream scheme, and a multimodal fusion mechanism is developed based on the hierarchical transformer. In this paper, the proposed method is denoted as Hierarchical Multimodal Transformer (HMT). Practically, extensive experiments show that HMT surpasses most of the traditional, RNN-based and attention-based video summarization methods.
Vulcan: Solving the Steiner Tree Problem with Graph Neural Networks and Deep Reinforcement Learning
Nov 21, 2021

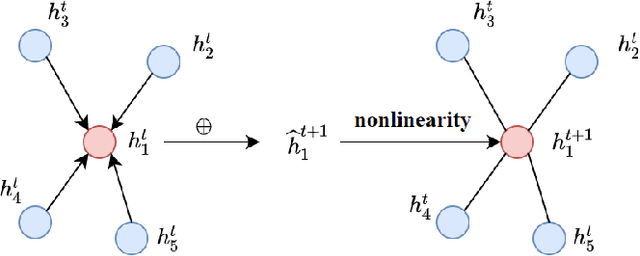

Steiner Tree Problem (STP) in graphs aims to find a tree of minimum weight in the graph that connects a given set of vertices. It is a classic NP-hard combinatorial optimization problem and has many real-world applications (e.g., VLSI chip design, transportation network planning and wireless sensor networks). Many exact and approximate algorithms have been developed for STP, but they suffer from high computational complexity and weak worst-case solution guarantees, respectively. Heuristic algorithms are also developed. However, each of them requires application domain knowledge to design and is only suitable for specific scenarios. Motivated by the recently reported observation that instances of the same NP-hard combinatorial problem may maintain the same or similar combinatorial structure but mainly differ in their data, we investigate the feasibility and benefits of applying machine learning techniques to solving STP. To this end, we design a novel model Vulcan based on novel graph neural networks and deep reinforcement learning. The core of Vulcan is a novel, compact graph embedding that transforms highdimensional graph structure data (i.e., path-changed information) into a low-dimensional vector representation. Given an STP instance, Vulcan uses this embedding to encode its pathrelated information and sends the encoded graph to a deep reinforcement learning component based on a double deep Q network (DDQN) to find solutions. In addition to STP, Vulcan can also find solutions to a wide range of NP-hard problems (e.g., SAT, MVC and X3C) by reducing them to STP. We implement a prototype of Vulcan and demonstrate its efficacy and efficiency with extensive experiments using real-world and synthetic datasets.
Reinforcement Learning on Encrypted Data
Sep 16, 2021
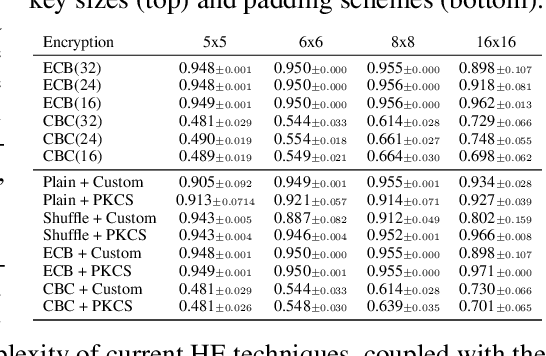
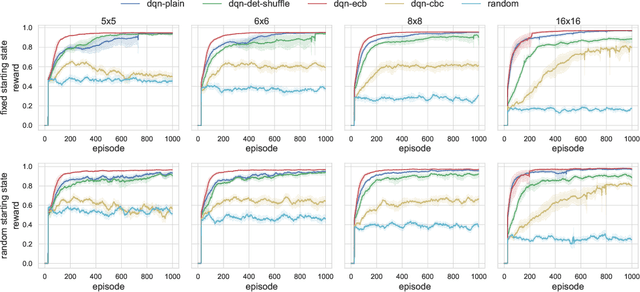
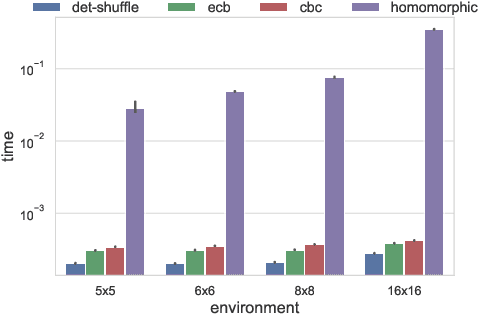
The growing number of applications of Reinforcement Learning (RL) in real-world domains has led to the development of privacy-preserving techniques due to the inherently sensitive nature of data. Most existing works focus on differential privacy, in which information is revealed in the clear to an agent whose learned model should be robust against information leakage to malicious third parties. Motivated by use cases in which only encrypted data might be shared, such as information from sensitive sites, in this work we consider scenarios in which the inputs themselves are sensitive and cannot be revealed. We develop a simple extension to the MDP framework which provides for the encryption of states. We present a preliminary, experimental study of how a DQN agent trained on encrypted states performs in environments with discrete and continuous state spaces. Our results highlight that the agent is still capable of learning in small state spaces even in presence of non-deterministic encryption, but performance collapses in more complex environments.