 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Next Day Wildfire Spread: A Machine Learning Data Set to Predict Wildfire Spreading from Remote-Sensing Data
Dec 04, 2021
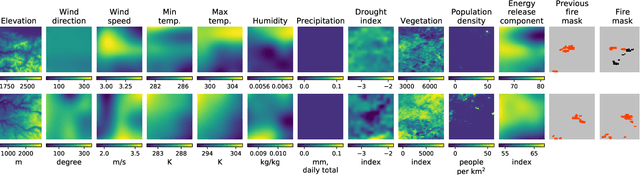
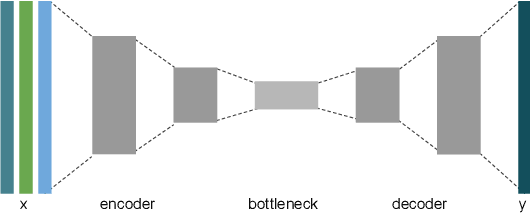
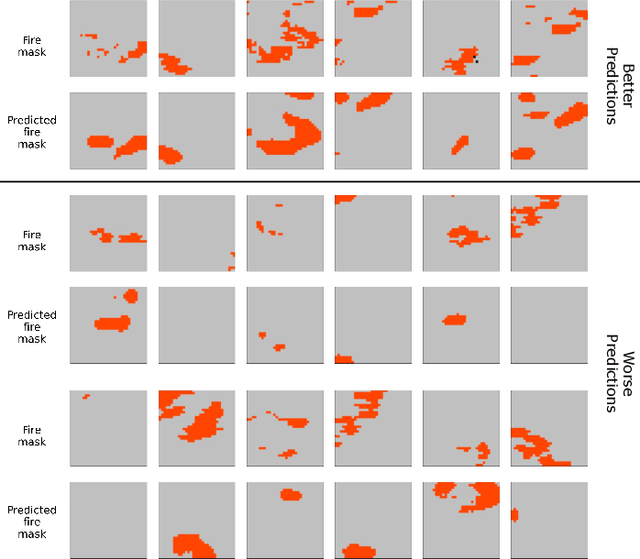
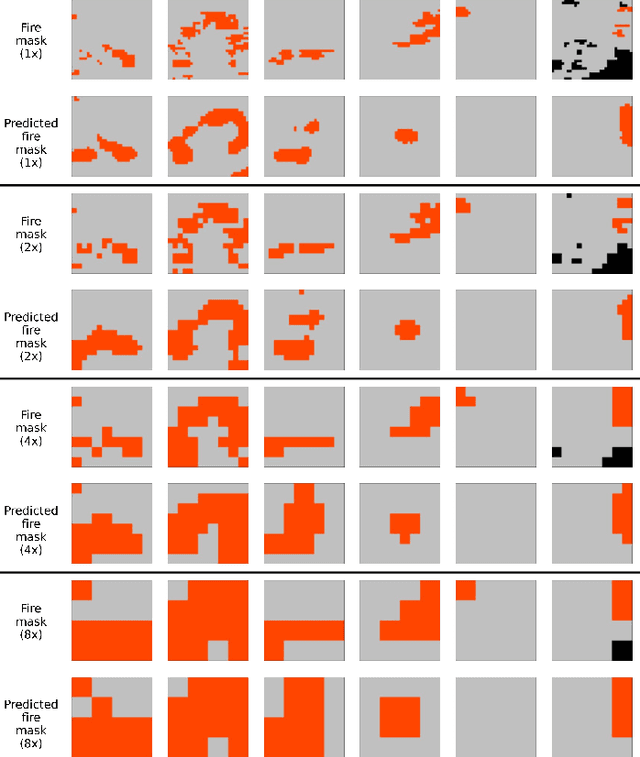
Predicting wildfire spread is critical for land management and disaster preparedness. To this end, we present `Next Day Wildfire Spread,' a curated, large-scale, multivariate data set of historical wildfires aggregating nearly a decade of remote-sensing data across the United States. In contrast to existing fire data sets based on Earth observation satellites, our data set combines 2D fire data with multiple explanatory variables (e.g., topography, vegetation, weather, drought index, population density) aligned over 2D regions, providing a feature-rich data set for machine learning. To demonstrate the usefulness of this data set, we implement a convolutional autoencoder that takes advantage of the spatial information of this data to predict wildfire spread. We compare the performance of the neural network with other machine learning models: logistic regression and random forest. This data set can be used as a benchmark for developing wildfire propagation models based on remote sensing data for a lead time of one day.
MuMuQA: Multimedia Multi-Hop News Question Answering via Cross-Media Knowledge Extraction and Grounding
Dec 20, 2021

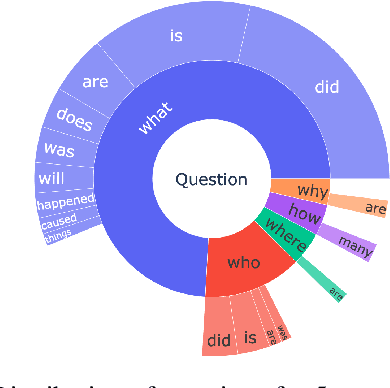
Recently, there has been an increasing interest in building question answering (QA) models that reason across multiple modalities, such as text and images. However, QA using images is often limited to just picking the answer from a pre-defined set of options. In addition, images in the real world, especially in news, have objects that are co-referential to the text, with complementary information from both modalities. In this paper, we present a new QA evaluation benchmark with 1,384 questions over news articles that require cross-media grounding of objects in images onto text. Specifically, the task involves multi-hop questions that require reasoning over image-caption pairs to identify the grounded visual object being referred to and then predicting a span from the news body text to answer the question. In addition, we introduce a novel multimedia data augmentation framework, based on cross-media knowledge extraction and synthetic question-answer generation, to automatically augment data that can provide weak supervision for this task. We evaluate both pipeline-based and end-to-end pretraining-based multimedia QA models on our benchmark, and show that they achieve promising performance, while considerably lagging behind human performance hence leaving large room for future work on this challenging new task.
The Impact of User Demographics and Task Types on Cross-App Mobile Search
Sep 14, 2021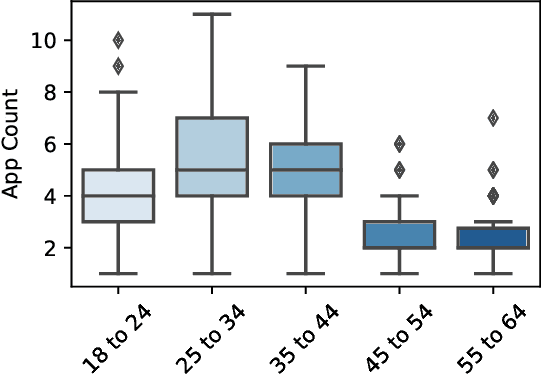
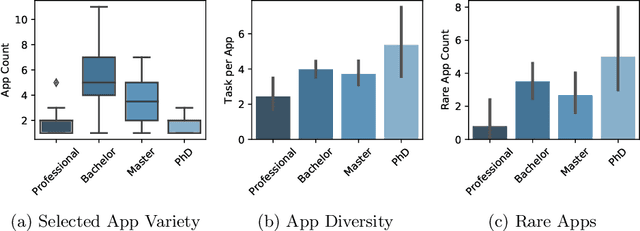
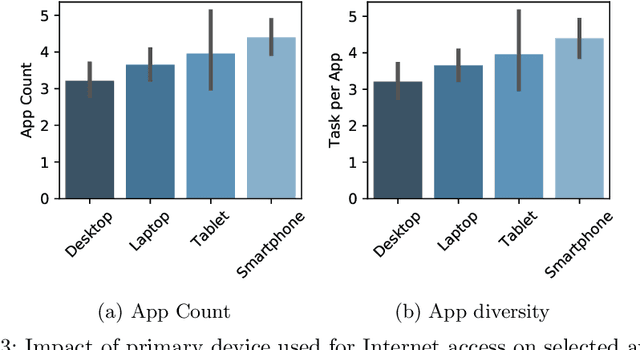
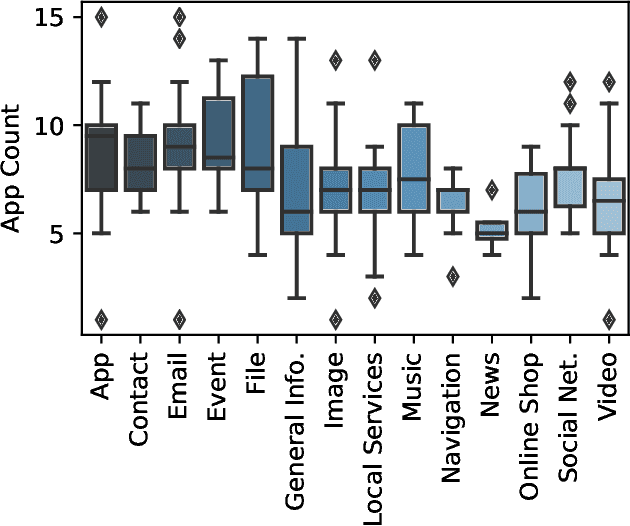
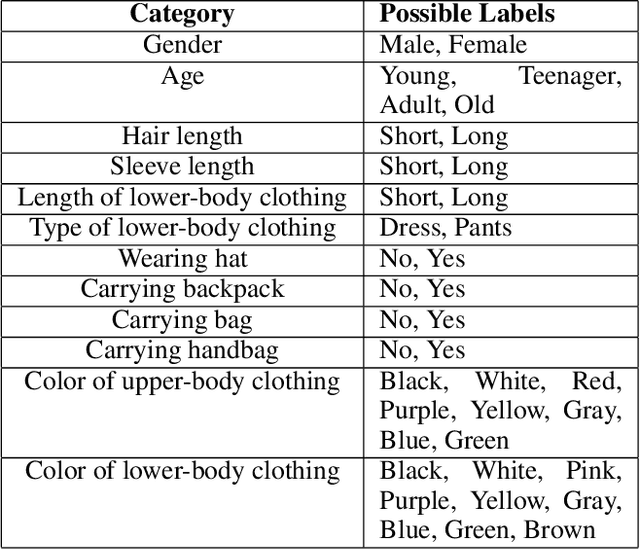
Recent developments in the mobile app industry have resulted in various types of mobile apps, each targeting a different need and a specific audience. Consequently, users access distinct apps to complete their information need tasks. This leads to the use of various apps not only separately, but also collaboratively in the same session to achieve a single goal. Recent work has argued the need for a unified mobile search system that would act as metasearch on users' mobile devices. The system would identify the target apps for the user's query, submit the query to the apps, and present the results to the user in a unified way. In this work, we aim to deepen our understanding of user behavior while accessing information on their mobile phones by conducting an extensive analysis of various aspects related to the search process. In particular, we study the effect of task type and user demographics on their behavior in interacting with mobile apps. Our findings reveal trends and patterns that can inform the design of a more effective mobile information access environment.
Bootstrapping Concept Formation in Small Neural Networks
Oct 26, 2021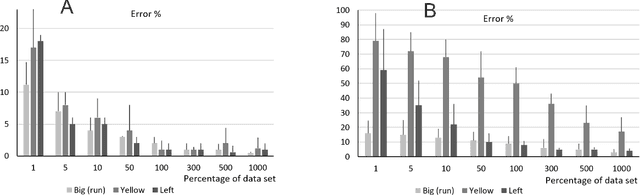
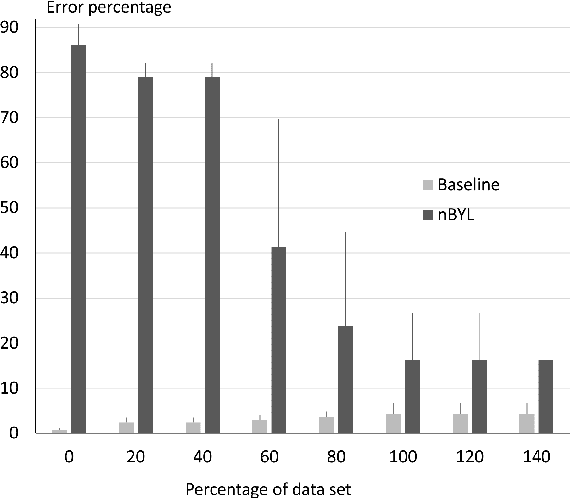
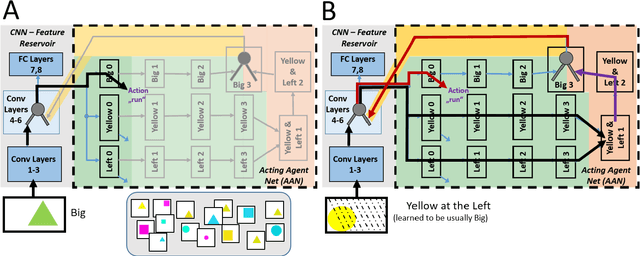
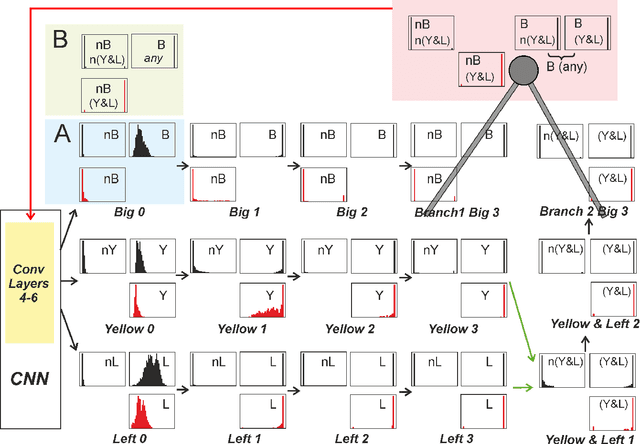
The question how neural systems (of humans) can perform reasoning is still far from being solved. We posit that the process of forming Concepts is a fundamental step required for this. We argue that, first, Concepts are formed as closed representations, which are then consolidated by relating them to each other. Here we present a model system (agent) with a small neural network that uses realistic learning rules and receives only feedback from the environment in which the agent performs virtual actions. First, the actions of the agent are reflexive. In the process of learning, statistical regularities in the input lead to the formation of neuronal pools representing relations between the entities observed by the agent from its artificial world. This information then influences the behavior of the agent via feedback connections replacing the initial reflex by an action driven by these relational representations. We hypothesize that the neuronal pools representing relational information can be considered as primordial Concepts, which may in a similar way be present in some pre-linguistic animals, too. We argue that systems such as this can help formalizing the discussion about what constitutes Concepts and serve as a starting point for constructing artificial cogitating systems.
Blind inverse problems with isolated spikes
Nov 03, 2021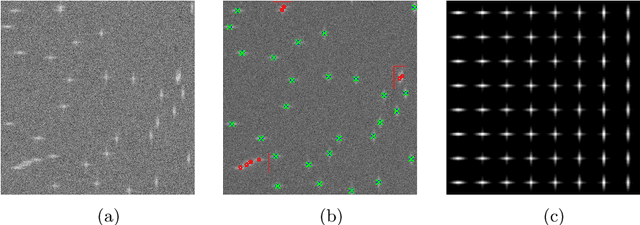
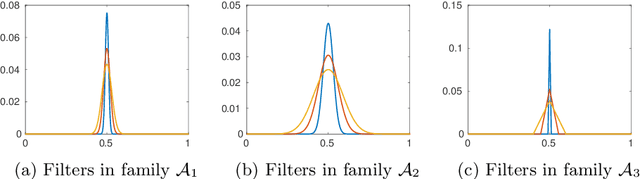
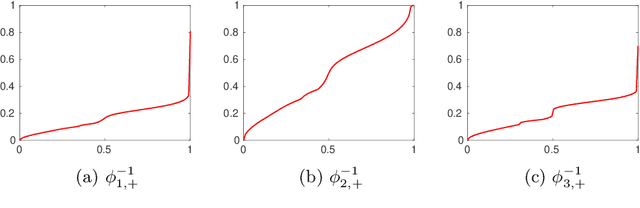
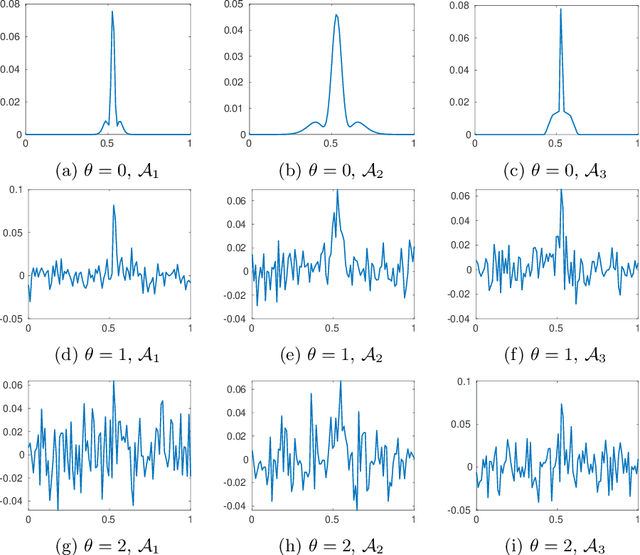
Assume that an unknown integral operator living in some known subspace is observed indirectly, by evaluating its action on a few Dirac masses at unknown locations. Is this information enough to recover the operator and the impulse responses locations stably? We study this question and answer positively under realistic technical assumptions. We illustrate the well-foundedness of this theory on two challenging optical imaging problems: blind super-resolution and deconvolution. This provides a simple, practical and theoretically grounded approach to solve these long resisting problems.
Forming a sparse representation for visual place recognition using a neurorobotic approach
Sep 30, 2021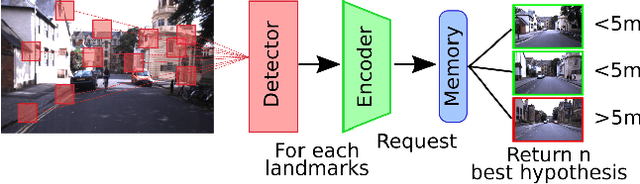
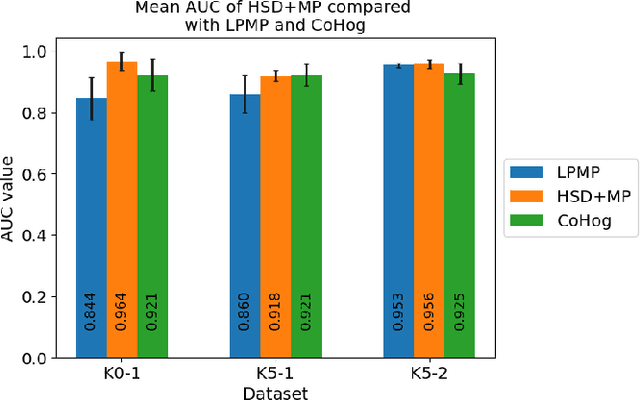
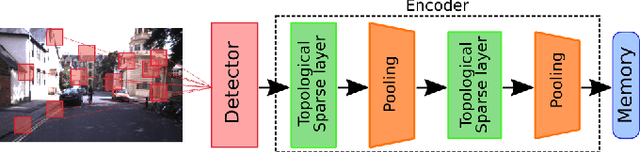
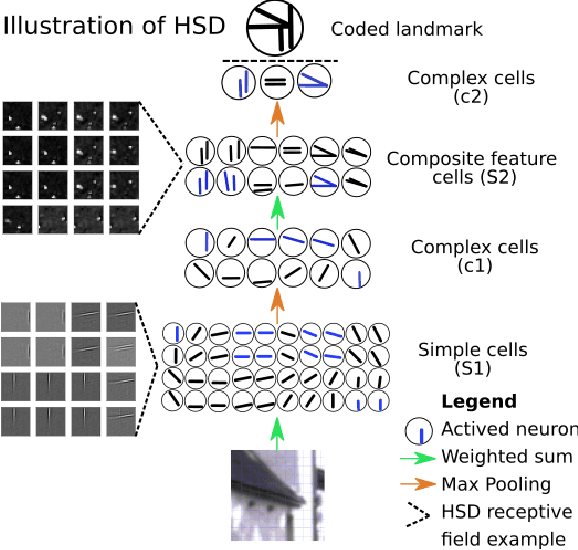
This paper introduces a novel unsupervised neural network model for visual information encoding which aims to address the problem of large-scale visual localization. Inspired by the structure of the visual cortex, the model (namely HSD) alternates layers of topologic sparse coding and pooling to build a more compact code of visual information. Intended for visual place recognition (VPR) systems that use local descriptors, the impact of its integration in a bio-inpired model for self-localization (LPMP) is evaluated. Our experimental results on the KITTI dataset show that HSD improves the runtime speed of LPMP by a factor of at least 2 and its localization accuracy by 10%. A comparison with CoHog, a state-of-the-art VPR approach, showed that our method achieves slightly better results.
Deep covariate-learning: optimising information extraction from terrain texture for geostatistical modelling applications
Jun 15, 2020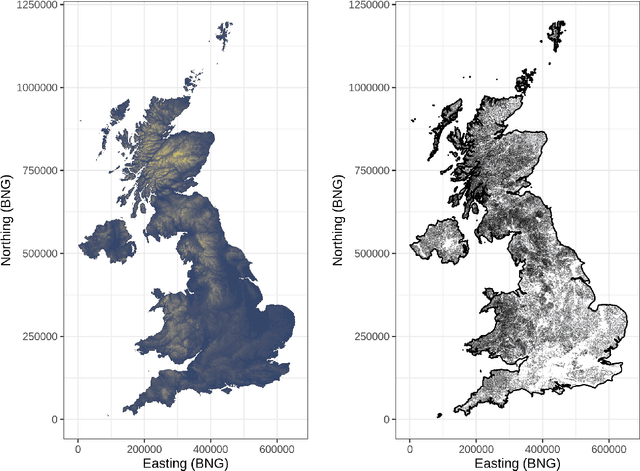
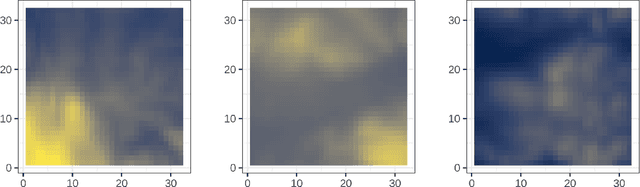
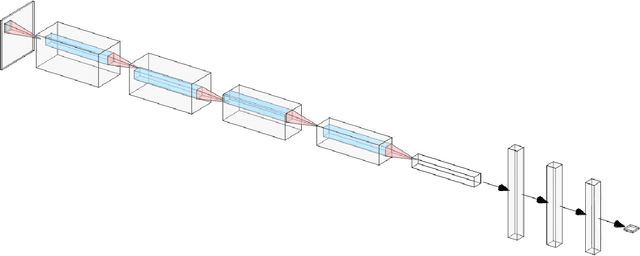
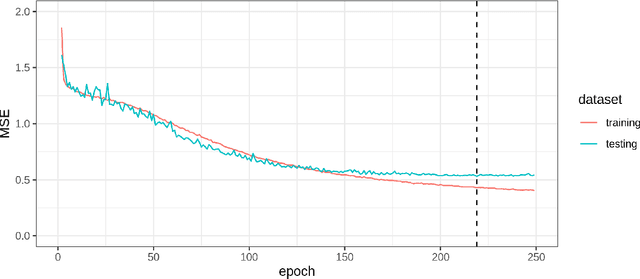
Where data is available, it is desirable in geostatistical modelling to make use of additional covariates, for example terrain data, in order to improve prediction accuracy in the modelling task. While elevation itself may be important, additional explanatory power for any given problem can be sought (but not necessarily found) by filtering digital elevation models to extract higher-order derivatives such as slope angles, curvatures, and roughness. In essence, it would be beneficial to extract as much task-relevant information as possible from the elevation grid. However, given the complexities of the natural world, chance dictates that the use of 'off-the-shelf' filters is unlikely to derive covariates that provide strong explanatory power to the target variable at hand, and any attempt to manually design informative covariates is likely to be a trial-and-error process -- not optimal. In this paper we present a solution to this problem in the form of a deep learning approach to automatically deriving optimal task-specific terrain texture covariates from a standard SRTM 90m gridded digital elevation model (DEM). For our target variables we use point-sampled geochemical data from the British Geological Survey: concentrations of potassium, calcium and arsenic in stream sediments. We find that our deep learning approach produces covariates for geostatistical modelling that have surprisingly strong explanatory power on their own, with R-squared values around 0.6 for all three elements (with arsenic on the log scale). These results are achieved without the neural network being provided with easting, northing, or absolute elevation as inputs, and purely reflect the capacity of our deep neural network to extract task-specific information from terrain texture. We hope that these results will inspire further investigation into the capabilities of deep learning within geostatistical applications.
DialFact: A Benchmark for Fact-Checking in Dialogue
Oct 15, 2021
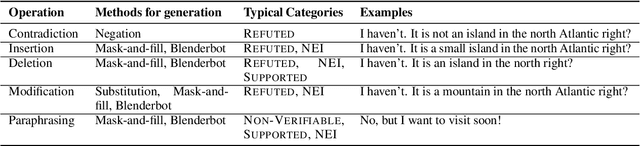
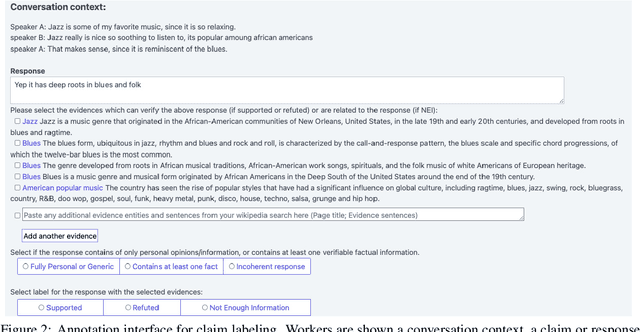
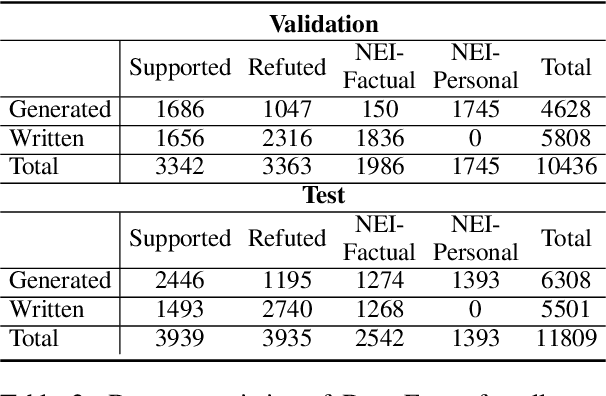
Fact-checking is an essential tool to mitigate the spread of misinformation and disinformation, however, it has been often explored to verify formal single-sentence claims instead of casual conversational claims. To study the problem, we introduce the task of fact-checking in dialogue. We construct DialFact, a testing benchmark dataset of 22,245 annotated conversational claims, paired with pieces of evidence from Wikipedia. There are three sub-tasks in DialFact: 1) Verifiable claim detection task distinguishes whether a response carries verifiable factual information; 2) Evidence retrieval task retrieves the most relevant Wikipedia snippets as evidence; 3) Claim verification task predicts a dialogue response to be supported, refuted, or not enough information. We found that existing fact-checking models trained on non-dialogue data like FEVER fail to perform well on our task, and thus, we propose a simple yet data-efficient solution to effectively improve fact-checking performance in dialogue. We point out unique challenges in DialFact such as handling the colloquialisms, coreferences, and retrieval ambiguities in the error analysis to shed light on future research in this direction.
ScanQA: 3D Question Answering for Spatial Scene Understanding
Dec 20, 2021

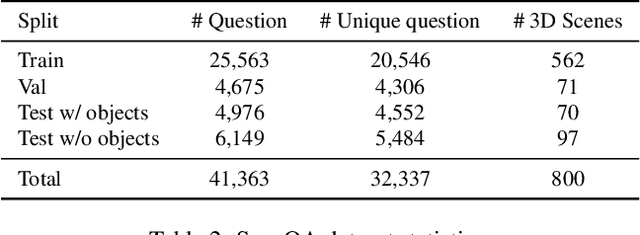

We propose a new 3D spatial understanding task of 3D Question Answering (3D-QA). In the 3D-QA task, models receive visual information from the entire 3D scene of the rich RGB-D indoor scan and answer the given textual questions about the 3D scene. Unlike the 2D-question answering of VQA, the conventional 2D-QA models suffer from problems with spatial understanding of object alignment and directions and fail the object localization from the textual questions in 3D-QA. We propose a baseline model for 3D-QA, named ScanQA model, where the model learns a fused descriptor from 3D object proposals and encoded sentence embeddings. This learned descriptor correlates the language expressions with the underlying geometric features of the 3D scan and facilitates the regression of 3D bounding boxes to determine described objects in textual questions. We collected human-edited question-answer pairs with free-form answers that are grounded to 3D objects in each 3D scene. Our new ScanQA dataset contains over 41K question-answer pairs from the 800 indoor scenes drawn from the ScanNet dataset. To the best of our knowledge, ScanQA is the first large-scale effort to perform object-grounded question-answering in 3D environments.
Online Learning in Adversarial MDPs: Is the Communicating Case Harder than Ergodic?
Nov 03, 2021
We study online learning in adversarial communicating Markov Decision Processes with full information. We give an algorithm that achieves a regret of $O(\sqrt{T})$ with respect to the best fixed deterministic policy in hindsight when the transitions are deterministic. We also prove a regret lower bound in this setting which is tight up to polynomial factors in the MDP parameters. We also give an inefficient algorithm that achieves $O(\sqrt{T})$ regret in communicating MDPs (with an additional mild restriction on the transition dynamics).