 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Label-Efficient Semantic Segmentation with Diffusion Models
Dec 06, 2021
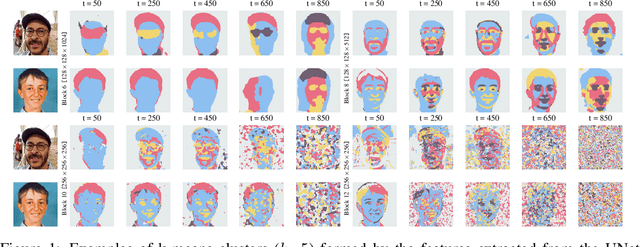
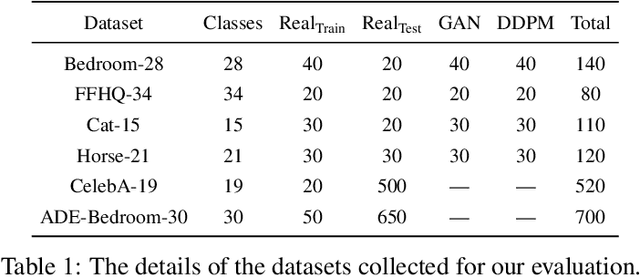
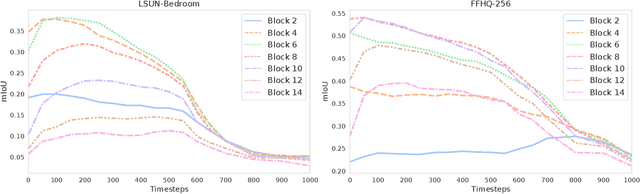
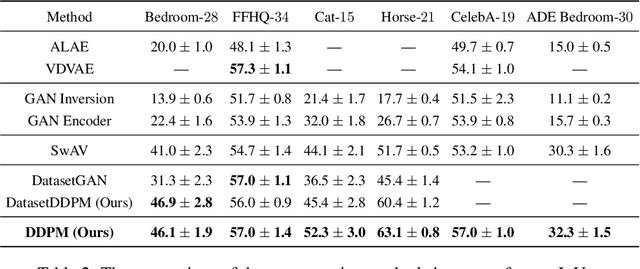
Denoising diffusion probabilistic models have recently received much research attention since they outperform alternative approaches, such as GANs, and currently provide state-of-the-art generative performance. The superior performance of diffusion models has made them an appealing tool in several applications, including inpainting, super-resolution, and semantic editing. In this paper, we demonstrate that diffusion models can also serve as an instrument for semantic segmentation, especially in the setup when labeled data is scarce. In particular, for several pretrained diffusion models, we investigate the intermediate activations from the networks that perform the Markov step of the reverse diffusion process. We show that these activations effectively capture the semantic information from an input image and appear to be excellent pixel-level representations for the segmentation problem. Based on these observations, we describe a simple segmentation method, which can work even if only a few training images are provided. Our approach significantly outperforms the existing alternatives on several datasets for the same amount of human supervision.
Triple Classification for Scholarly Knowledge Graph Completion
Nov 23, 2021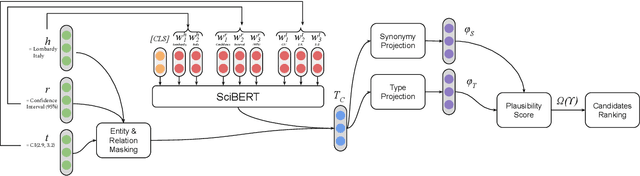

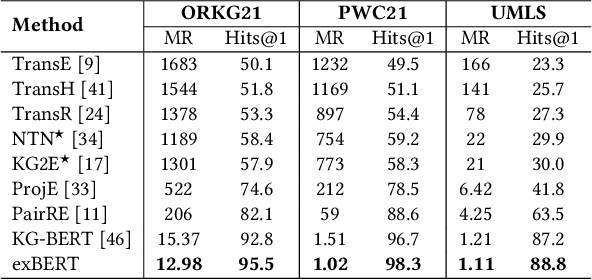
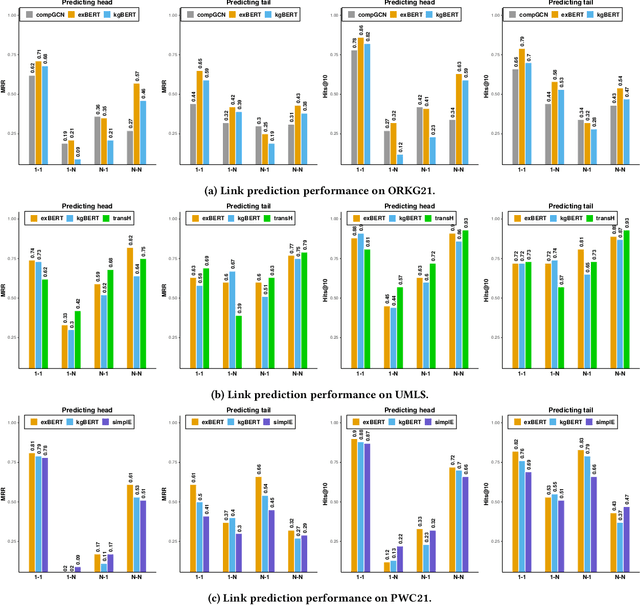
Scholarly Knowledge Graphs (KGs) provide a rich source of structured information representing knowledge encoded in scientific publications. With the sheer volume of published scientific literature comprising a plethora of inhomogeneous entities and relations to describe scientific concepts, these KGs are inherently incomplete. We present exBERT, a method for leveraging pre-trained transformer language models to perform scholarly knowledge graph completion. We model triples of a knowledge graph as text and perform triple classification (i.e., belongs to KG or not). The evaluation shows that exBERT outperforms other baselines on three scholarly KG completion datasets in the tasks of triple classification, link prediction, and relation prediction. Furthermore, we present two scholarly datasets as resources for the research community, collected from public KGs and online resources.
General Facial Representation Learning in a Visual-Linguistic Manner
Dec 06, 2021
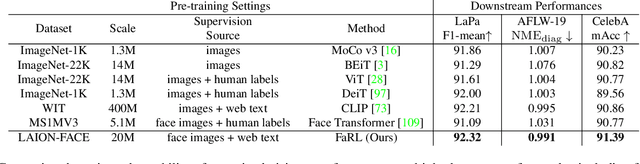

How to learn a universal facial representation that boosts all face analysis tasks? This paper takes one step toward this goal. In this paper, we study the transfer performance of pre-trained models on face analysis tasks and introduce a framework, called FaRL, for general Facial Representation Learning in a visual-linguistic manner. On one hand, the framework involves a contrastive loss to learn high-level semantic meaning from image-text pairs. On the other hand, we propose exploring low-level information simultaneously to further enhance the face representation, by adding a masked image modeling. We perform pre-training on LAION-FACE, a dataset containing large amount of face image-text pairs, and evaluate the representation capability on multiple downstream tasks. We show that FaRL achieves better transfer performance compared with previous pre-trained models. We also verify its superiority in the low-data regime. More importantly, our model surpasses the state-of-the-art methods on face analysis tasks including face parsing and face alignment.
Pre-Training of Deep Bidirectional Protein Sequence Representations with Structural Information
Nov 25, 2019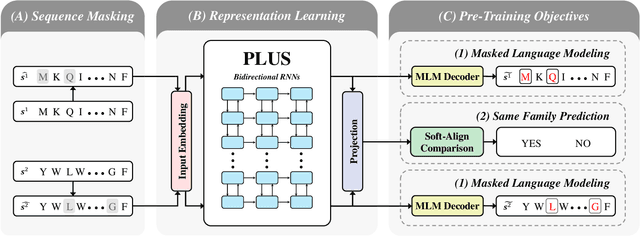
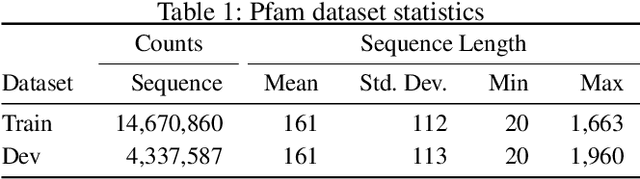
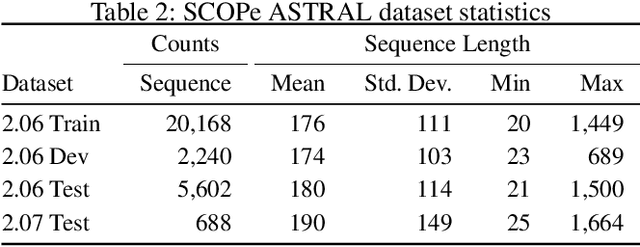
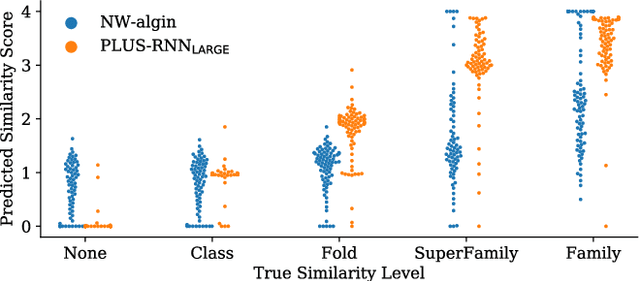
A structure of a protein has a direct impact on its properties and functions. However, identification of structural similarity directly from amino acid sequences remains as a challenging problem in computational biology. In this paper, we introduce a novel BERT-wise pre-training scheme for a protein sequence representation model called PLUS, which stands for Protein sequence representations Learned Using Structural information. As natural language representation models capture syntactic and semantic information of words from a large unlabeled text corpus, PLUS captures structural information of amino acids from a large weakly labeled protein database. Since the Transformer encoder, BERT's original model architecture, has a severe computational requirement to handle long sequences, we first propose to combine a bidirectional recurrent neural network with the BERT-wise pre-training scheme. PLUS is designed to learn protein representations with two pre-training objectives, i.e., masked language modeling and same family prediction. Then, the pre-trained model can be fine-tuned for a wide range of tasks without training randomly initialized task-specific models from scratch. It obtains new state-of-the-art results on both (1) protein-level and (2) amino-acid-level tasks, outperforming many task-specific algorithms.
Understand me, if you refer to Aspect Knowledge: Knowledge-aware Gated Recurrent Memory Network
Aug 05, 2021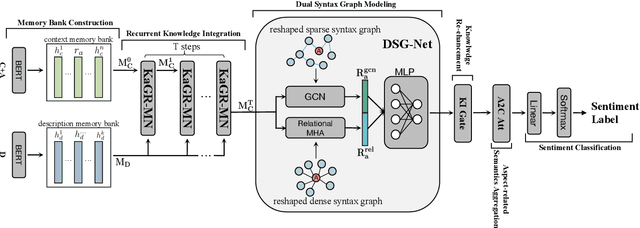
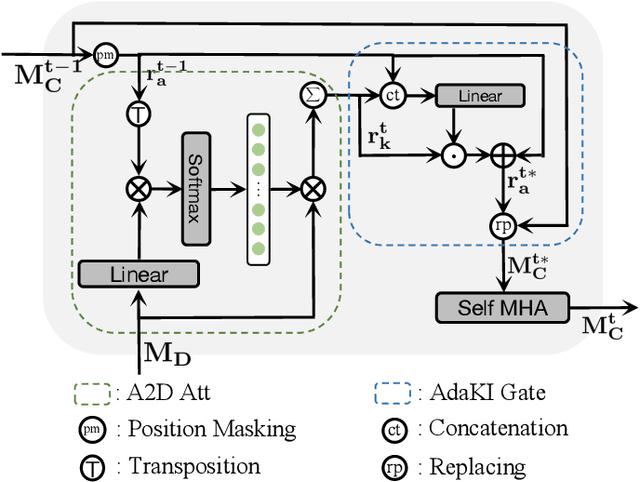
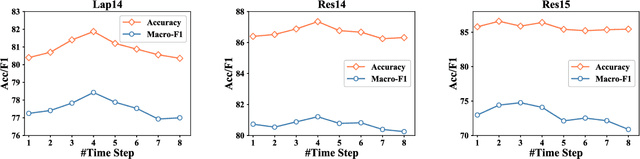
Aspect-level sentiment classification (ASC) aims to predict the fine-grained sentiment polarity towards a given aspect mentioned in a review. Despite recent advances in ASC, enabling machines to preciously infer aspect sentiments is still challenging. This paper tackles two challenges in ASC: (1) due to lack of aspect knowledge, aspect representation derived in prior works is inadequate to represent aspect's exact meaning and property information; (2) prior works only capture either local syntactic information or global relational information, thus missing either one of them leads to insufficient syntactic information. To tackle these challenges, we propose a novel ASC model which not only end-to-end embeds and leverages aspect knowledge but also marries the two kinds of syntactic information and lets them compensate for each other. Our model includes three key components: (1) a knowledge-aware gated recurrent memory network recurrently integrates dynamically summarized aspect knowledge; (2) a dual syntax graph network combines both kinds of syntactic information to comprehensively capture sufficient syntactic information; (3) a knowledge integrating gate re-enhances the final representation with further needed aspect knowledge; (4) an aspect-to-context attention mechanism aggregates the aspect-related semantics from all hidden states into the final representation. Experimental results on several benchmark datasets demonstrate the effectiveness of our model, which overpass previous state-of-the-art models by large margins in terms of both Accuracy and Macro-F1.
Cross-Modality Attentive Feature Fusion for Object Detection in Multispectral Remote Sensing Imagery
Dec 06, 2021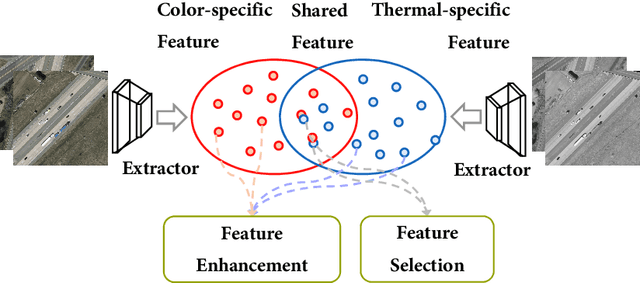
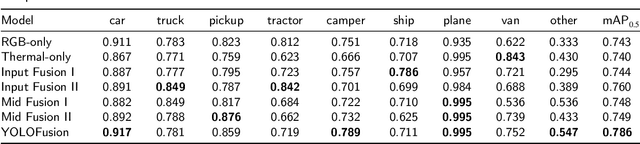
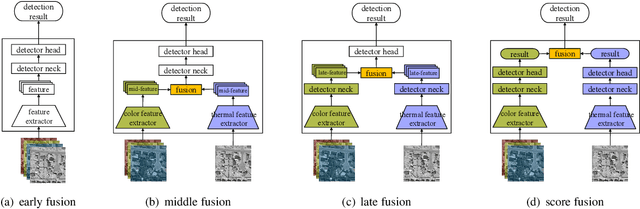
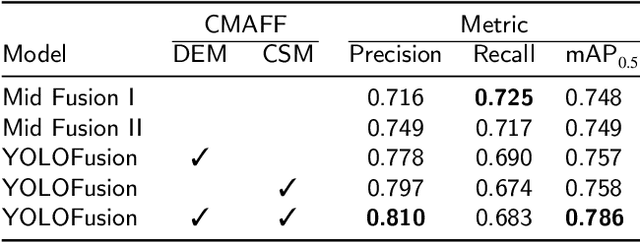
Cross-modality fusing complementary information of multispectral remote sensing image pairs can improve the perception ability of detection algorithms, making them more robust and reliable for a wider range of applications, such as nighttime detection. Compared with prior methods, we think different features should be processed specifically, the modality-specific features should be retained and enhanced, while the modality-shared features should be cherry-picked from the RGB and thermal IR modalities. Following this idea, a novel and lightweight multispectral feature fusion approach with joint common-modality and differential-modality attentions are proposed, named Cross-Modality Attentive Feature Fusion (CMAFF). Given the intermediate feature maps of RGB and IR images, our module parallel infers attention maps from two separate modalities, common- and differential-modality, then the attention maps are multiplied to the input feature map respectively for adaptive feature enhancement or selection. Extensive experiments demonstrate that our proposed approach can achieve the state-of-the-art performance at a low computation cost.
Privacy preserving n-party scalar product protocol
Dec 17, 2021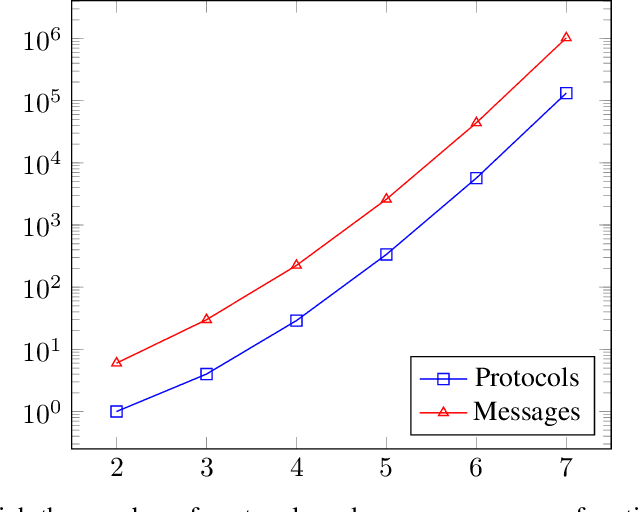
Privacy-preserving machine learning enables the training of models on decentralized datasets without the need to reveal the data, both on horizontal and vertically partitioned data. However, it relies on specialized techniques and algorithms to perform the necessary computations. The privacy preserving scalar product protocol, which enables the dot product of vectors without revealing them, is one popular example for its versatility. Unfortunately, the solutions currently proposed in the literature focus mainly on two-party scenarios, even though scenarios with a higher number of data parties are becoming more relevant. For example when performing analyses that require counting the number of samples which fulfill certain criteria defined across various sites, such as calculating the information gain at a node in a decision tree. In this paper we propose a generalization of the protocol for an arbitrary number of parties, based on an existing two-party method. Our proposed solution relies on a recursive resolution of smaller scalar products. After describing our proposed method, we discuss potential scalability issues. Finally, we describe the privacy guarantees and identify any concerns, as well as comparing the proposed method to the original solution in this aspect.
Construction de variables à l'aide de classifieurs comme aide à la régression
Dec 03, 2021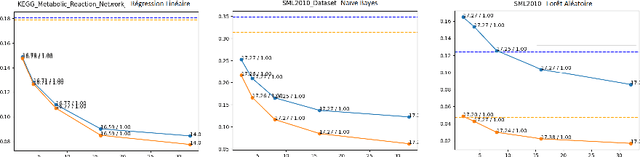

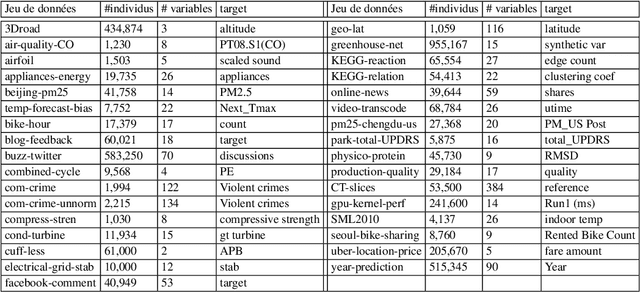
This paper proposes a method for the automatic creation of variables (in the case of regression) that complement the information contained in the initial input vector. The method works as a pre-processing step in which the continuous values of the variable to be regressed are discretized into a set of intervals which are then used to define value thresholds. Then classifiers are trained to predict whether the value to be regressed is less than or equal to each of these thresholds. The different outputs of the classifiers are then concatenated in the form of an additional vector of variables that enriches the initial vector of the regression problem. The implemented system can thus be considered as a generic pre-processing tool. We tested the proposed enrichment method with 5 types of regressors and evaluated it in 33 regression datasets. Our experimental results confirm the interest of the approach.
Tracking and Improving Information in the Service of Fairness
Apr 22, 2019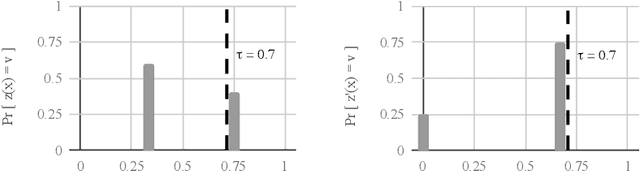
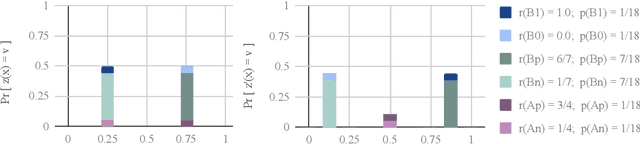
As algorithmic prediction systems have become widespread, fears that these systems may inadvertently discriminate against members of underrepresented populations have grown. With the goal of understanding fundamental principles that underpin the growing number of approaches to mitigating algorithmic discrimination, we investigate the role of information in fair prediction. A common strategy for decision-making uses a predictor to assign individuals a risk score; then, individuals are selected or rejected on the basis of this score. In this work, we formalize a framework for measuring the information content of predictors. Central to this framework is the notion of a refinement; intuitively, a refinement of a predictor $z$ increases the overall informativeness of the predictions without losing the information already contained in $z$. We show that increasing information content through refinements improves the downstream selection rules across a wide range of fairness measures (e.g. true positive rates, false positive rates, selection rates). In turn, refinements provide a simple but effective tool for reducing disparity in treatment and impact without sacrificing the utility of the predictions. Our results suggest that in many applications, the perceived "cost of fairness" results from an information disparity across populations, and thus, may be avoided with improved information.
MVLayoutNet:3D layout reconstruction with multi-view panoramas
Dec 12, 2021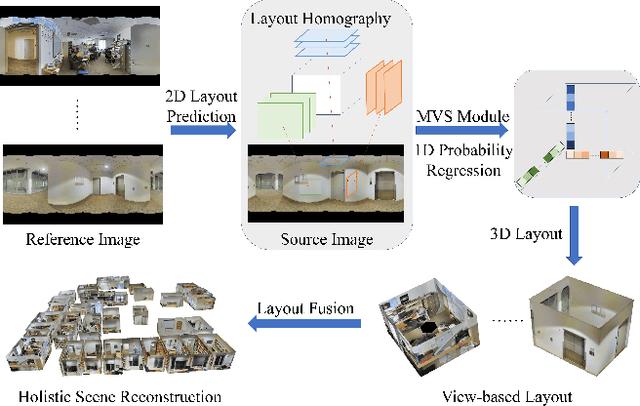
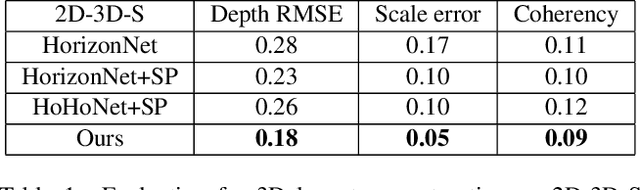
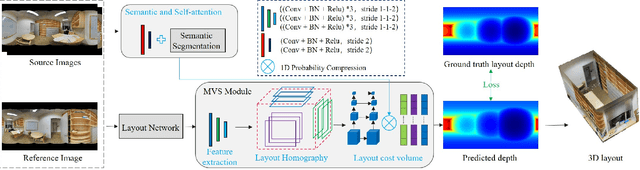
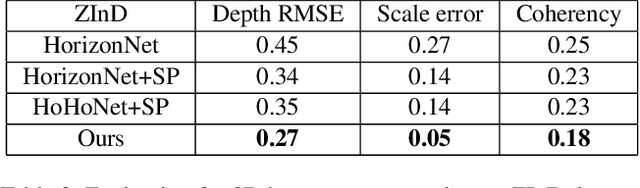
We present MVLayoutNet, an end-to-end network for holistic 3D reconstruction from multi-view panoramas. Our core contribution is to seamlessly combine learned monocular layout estimation and multi-view stereo (MVS) for accurate layout reconstruction in both 3D and image space. We jointly train a layout module to produce an initial layout and a novel MVS module to obtain accurate layout geometry. Unlike standard MVSNet [33], our MVS module takes a newly-proposed layout cost volume, which aggregates multi-view costs at the same depth layer into corresponding layout elements. We additionally provide an attention-based scheme that guides the MVS module to focus on structural regions. Such a design considers both local pixel-level costs and global holistic information for better reconstruction. Experiments show that our method outperforms state-of-the-arts in terms of depth rmse by 21.7% and 20.6% on the 2D-3D-S [1] and ZInD [5] datasets. Finally, our method leads to coherent layout geometry that enables the reconstruction of an entire scene.