 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reframing Human-AI Collaboration for Generating Free-Text Explanations
Dec 16, 2021

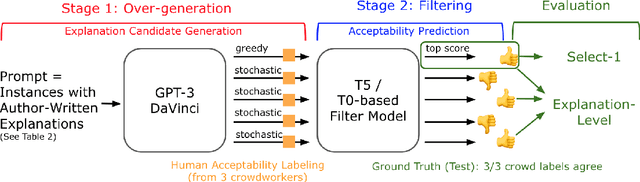

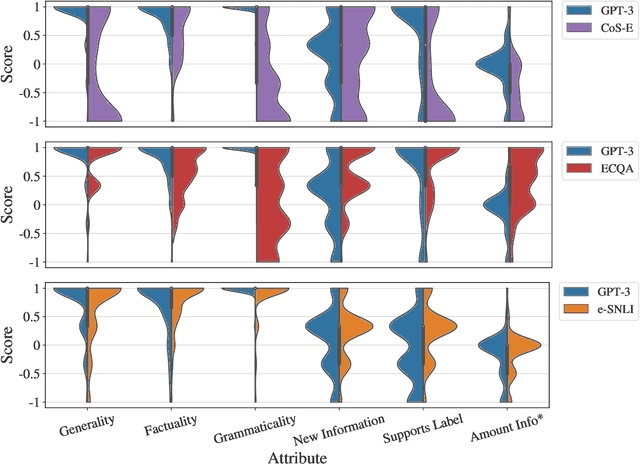
Large language models are increasingly capable of generating fluent-appearing text with relatively little task-specific supervision. But can these models accurately explain classification decisions? We consider the task of generating free-text explanations using a small number of human-written examples (i.e., in a few-shot manner). We find that (1) authoring higher-quality examples for prompting results in higher quality generations; and (2) surprisingly, in a head-to-head comparison, crowdworkers often prefer explanations generated by GPT-3 to crowdsourced human-written explanations contained within existing datasets. Crowdworker ratings also show, however, that while models produce factual, grammatical, and sufficient explanations, they have room to improve, e.g., along axes such as providing novel information and supporting the label. We create a pipeline that combines GPT-3 with a supervised filter that incorporates humans-in-the-loop via binary acceptability judgments. Despite significant subjectivity intrinsic to judging acceptability, our approach is able to consistently filter GPT-3 generated explanations deemed acceptable by humans.
A perspective on multi-agent communication for information fusion
Nov 09, 2019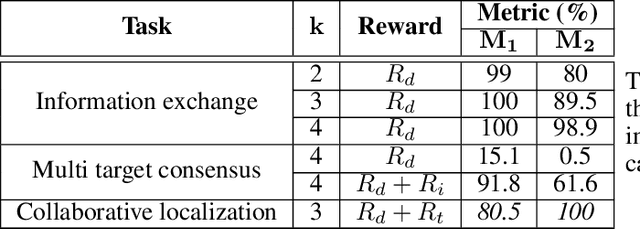
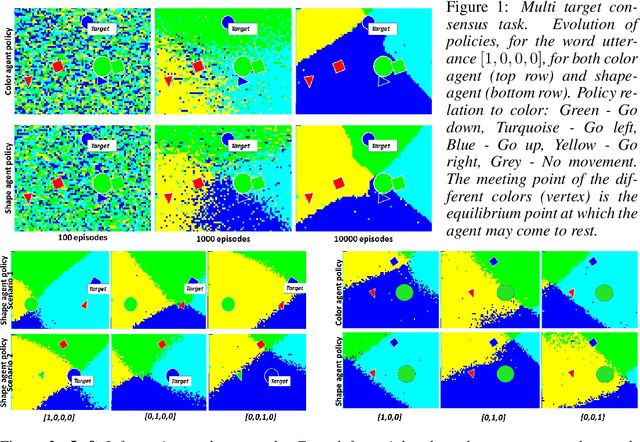
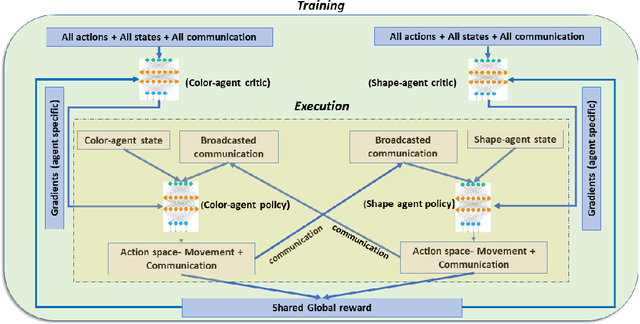

Collaborative decision making in multi-agent systems typically requires a predefined communication protocol among agents. Usually, agent-level observations are locally processed and information is exchanged using the predefined protocol, enabling the team to perform more efficiently than each agent operating in isolation. In this work, we consider the situation where agents, with complementary sensing modalities must co-operate to achieve a common goal/task by learning an efficient communication protocol. We frame the problem within an actor-critic scheme, where the agents learn optimal policies in a centralized fashion, while taking action in a distributed manner. We provide an interpretation of the emergent communication between the agents. We observe that the information exchanged is not just an encoding of the raw sensor data but is, rather, a specific set of directive actions that depend on the overall task. Simulation results demonstrate the interpretability of the learnt communication in a variety of tasks.
Value of Information Analysis via Active Learning and Knowledge Sharing in Error-Controlled Adaptive Kriging
Mar 13, 2020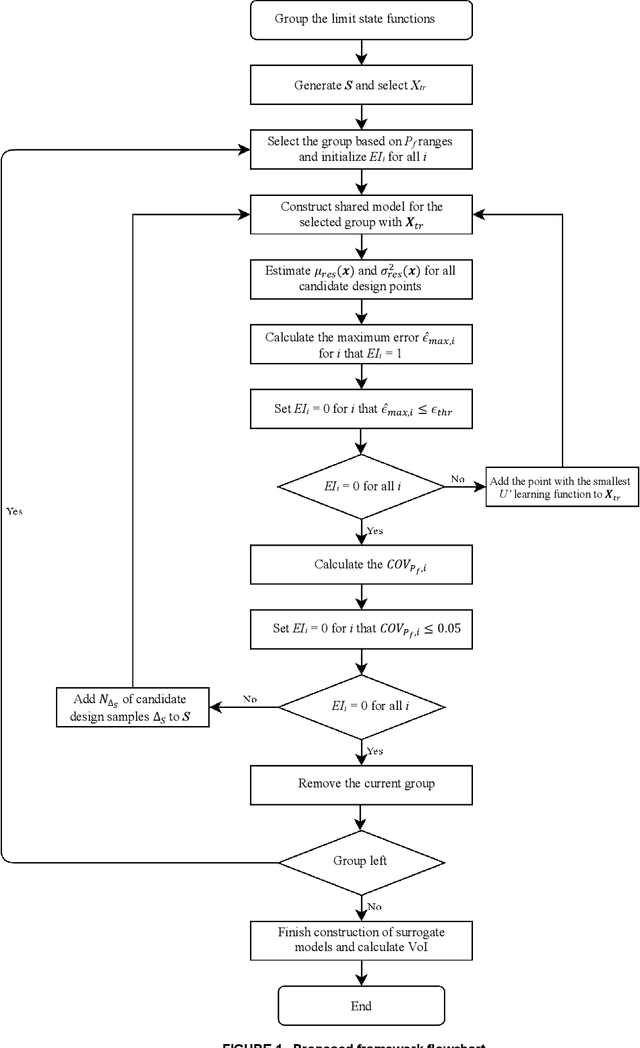
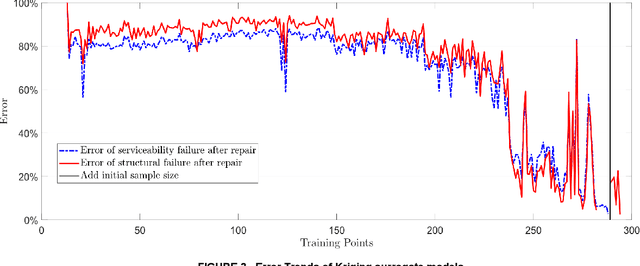
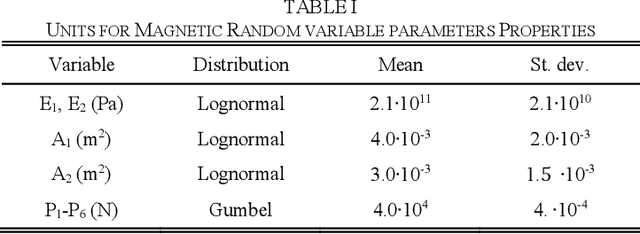
Large uncertainties in many phenomena have challenged decision making. Collecting additional information to better characterize reducible uncertainties is among decision alternatives. Value of information (VoI) analysis is a mathematical decision framework that quantifies expected potential benefits of new data and assists with optimal allocation of resources for information collection. However, analysis of VoI is computational very costly because of the underlying Bayesian inference especially for equality-type information. This paper proposes the first surrogate-based framework for VoI analysis. Instead of modeling the limit state functions describing events of interest for decision making, which is commonly pursued in surrogate model-based reliability methods, the proposed framework models system responses. This approach affords sharing equality-type information from observations among surrogate models to update likelihoods of multiple events of interest. Moreover, two knowledge sharing schemes called model and training points sharing are proposed to most effectively take advantage of the knowledge offered by costly model evaluations. Both schemes are integrated with an error rate-based adaptive training approach to efficiently generate accurate Kriging surrogate models. The proposed VoI analysis framework is applied for an optimal decision-making problem involving load testing of a truss bridge. While state-of-the-art methods based on importance sampling and adaptive Kriging Monte Carlo simulation are unable to solve this problem, the proposed method is shown to offer accurate and robust estimates of VoI with a limited number of model evaluations. Therefore, the proposed method facilitates the application of VoI for complex decision problems.
Lane level context and hidden space characterization for autonomous driving
Aug 31, 2021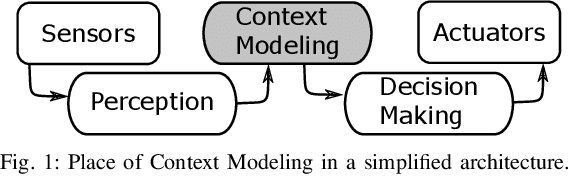
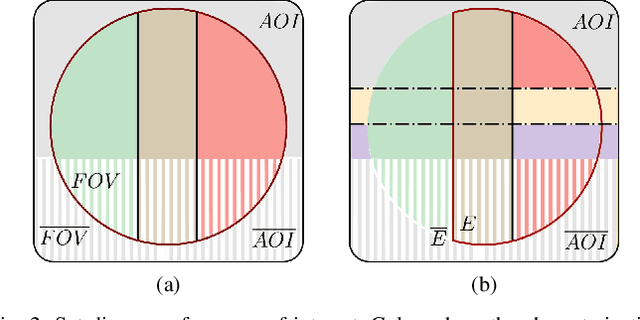
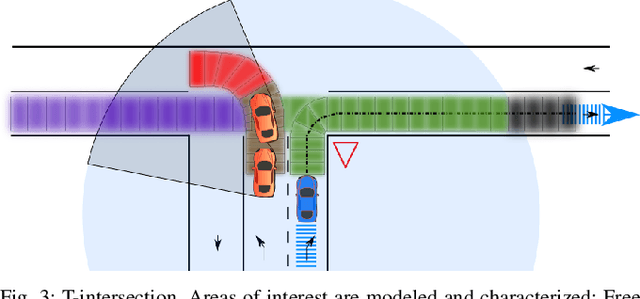
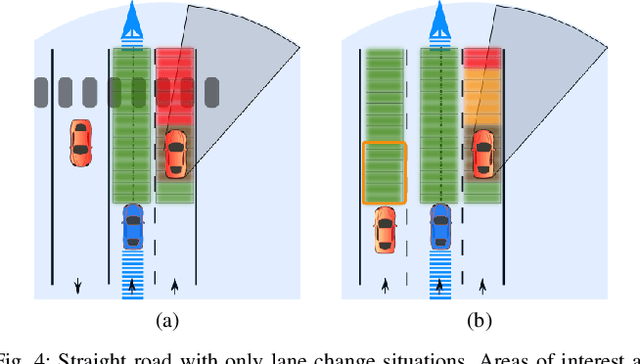
For an autonomous vehicle, situation understand-ing is a key capability towards safe and comfortable decision-making and navigation. Information is in general provided bymultiple sources. Prior information about the road topology andtraffic laws can be given by a High Definition (HD) map whilethe perception system provides the description of the spaceand of road entities evolving in the vehicle surroundings. Incomplex situations such as those encountered in urban areas,the road user behaviors are governed by strong interactionswith the others, and with the road network. In such situations,reliable situation understanding is therefore mandatory to avoidinappropriate decisions. Nevertheless, situation understandingis a complex task that requires access to a consistent andnon-misleading representation of the vehicle surroundings. Thispaper proposes a formalism (an interaction lane grid) whichallows to represent, with different levels of abstraction, thenavigable and interacting spaces which must be considered forsafe navigation. A top-down approach is chosen to assess andcharacterize the relevant information of the situation. On a highlevel of abstraction, the identification of the areas of interestwhere the vehicle should pay attention is depicted. On a lowerlevel, it enables to characterize the spatial information in aunified representation and to infer additional information inoccluded areas by reasoning with dynamic objects.
KAT: A Knowledge Augmented Transformer for Vision-and-Language
Dec 16, 2021
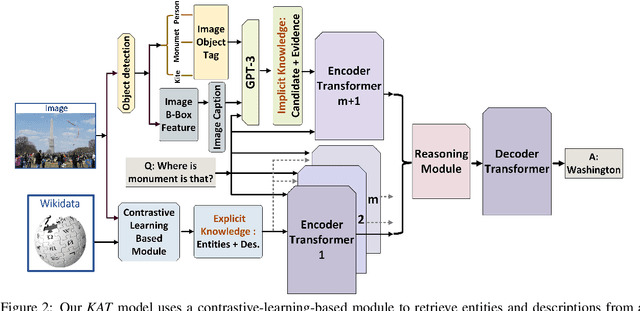
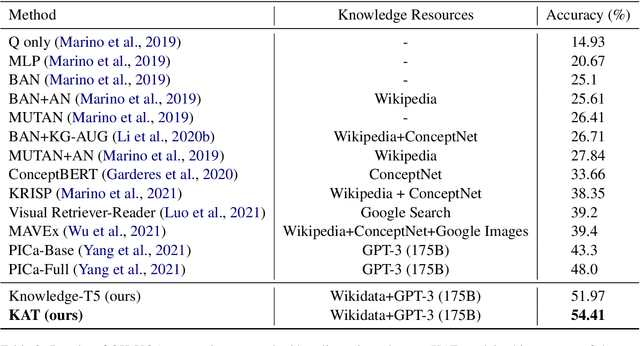
The primary focus of recent work with largescale transformers has been on optimizing the amount of information packed into the model's parameters. In this work, we ask a different question: Can multimodal transformers leverage explicit knowledge in their reasoning? Existing, primarily unimodal, methods have explored approaches under the paradigm of knowledge retrieval followed by answer prediction, but leave open questions about the quality and relevance of the retrieved knowledge used, and how the reasoning processes over implicit and explicit knowledge should be integrated. To address these challenges, we propose a novel model - Knowledge Augmented Transformer (KAT) - which achieves a strong state-of-the-art result (+6 points absolute) on the open-domain multimodal task of OK-VQA. Our approach integrates implicit and explicit knowledge in an end to end encoder-decoder architecture, while still jointly reasoning over both knowledge sources during answer generation. An additional benefit of explicit knowledge integration is seen in improved interpretability of model predictions in our analysis.
Sign Language Recognition System using TensorFlow Object Detection API
Jan 05, 2022
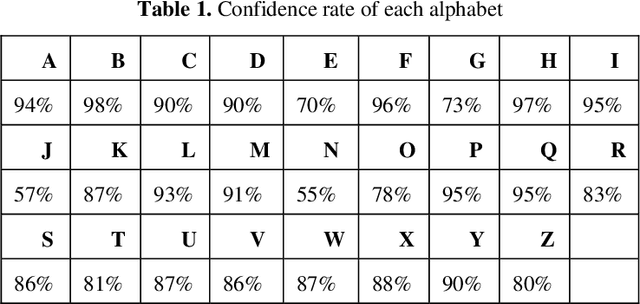


Communication is defined as the act of sharing or exchanging information, ideas or feelings. To establish communication between two people, both of them are required to have knowledge and understanding of a common language. But in the case of deaf and dumb people, the means of communication are different. Deaf is the inability to hear and dumb is the inability to speak. They communicate using sign language among themselves and with normal people but normal people do not take seriously the importance of sign language. Not everyone possesses the knowledge and understanding of sign language which makes communication difficult between a normal person and a deaf and dumb person. To overcome this barrier, one can build a model based on machine learning. A model can be trained to recognize different gestures of sign language and translate them into English. This will help a lot of people in communicating and conversing with deaf and dumb people. The existing Indian Sing Language Recognition systems are designed using machine learning algorithms with single and double-handed gestures but they are not real-time. In this paper, we propose a method to create an Indian Sign Language dataset using a webcam and then using transfer learning, train a TensorFlow model to create a real-time Sign Language Recognition system. The system achieves a good level of accuracy even with a limited size dataset.
Reprogrammable Surfaces Through Star Graph Metamaterials
Dec 16, 2021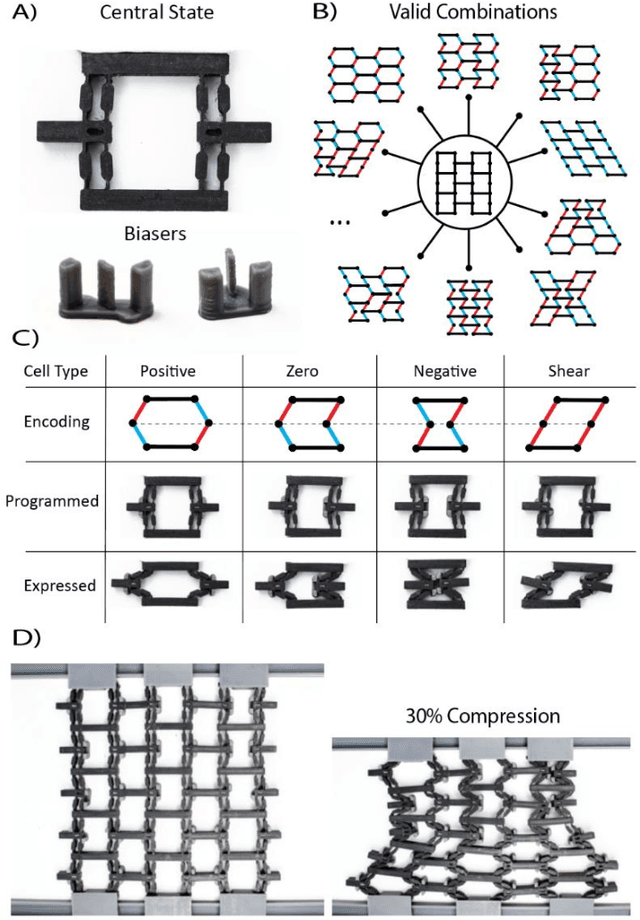
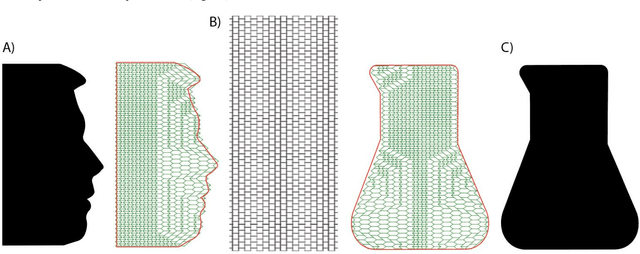

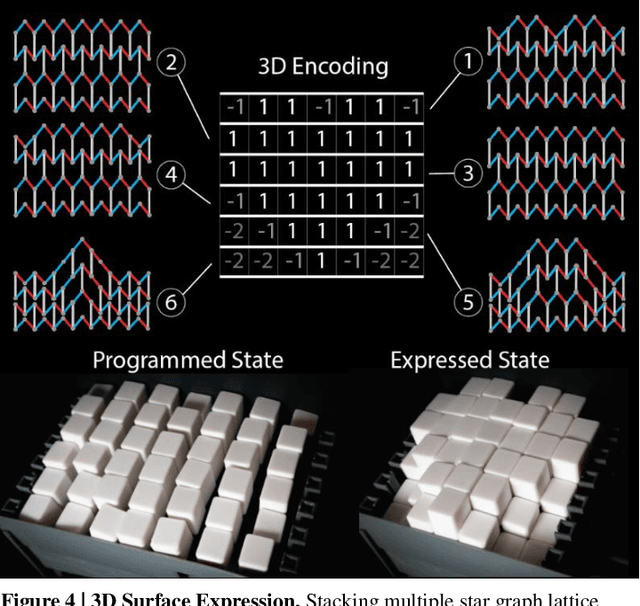
The ability to change a surface's profile allows biological systems to effectively manipulate and blend into their surroundings. Current surface morphing techniques rely either on having a small number of fixed states or on directly driving the entire system. We discovered a subset of scale-independent auxetic metamaterials have a state trajectory with a star-graph structure. At the central node, small nudges can move the material between trajectories, allowing us to locally shift Poisson's ratio, causing the material to take on different shapes under loading. While the number of possible shapes grows exponentially with the size of the material, the probability of finding one at random is vanishingly small. By actively guiding the material through the node points, we produce a reprogrammable surface that does not require inputs to maintain shape and can display arbitrary 2D information and take on complex 3D shapes. Our work opens new opportunities in micro devices, tactile displays, manufacturing, and robotic systems.
Evaluating Deep Music Generation Methods Using Data Augmentation
Dec 31, 2021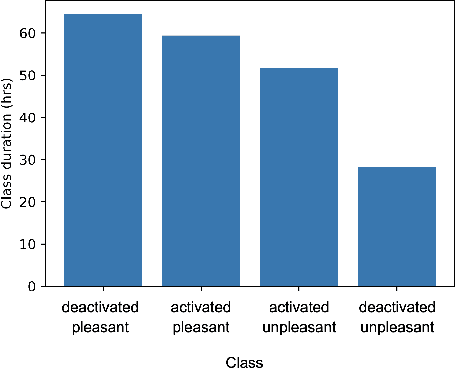
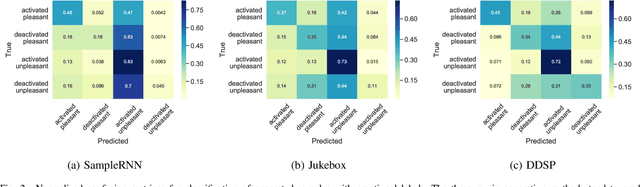
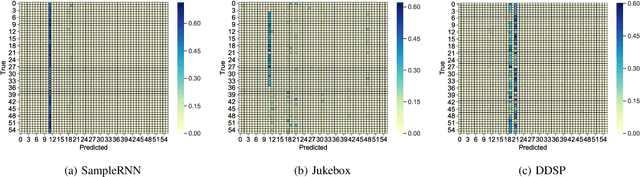
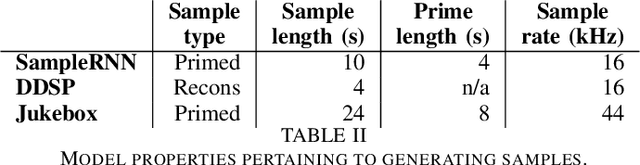
Despite advances in deep algorithmic music generation, evaluation of generated samples often relies on human evaluation, which is subjective and costly. We focus on designing a homogeneous, objective framework for evaluating samples of algorithmically generated music. Any engineered measures to evaluate generated music typically attempt to define the samples' musicality, but do not capture qualities of music such as theme or mood. We do not seek to assess the musical merit of generated music, but instead explore whether generated samples contain meaningful information pertaining to emotion or mood/theme. We achieve this by measuring the change in predictive performance of a music mood/theme classifier after augmenting its training data with generated samples. We analyse music samples generated by three models -- SampleRNN, Jukebox, and DDSP -- and employ a homogeneous framework across all methods to allow for objective comparison. This is the first attempt at augmenting a music genre classification dataset with conditionally generated music. We investigate the classification performance improvement using deep music generation and the ability of the generators to make emotional music by using an additional, emotion annotation of the dataset. Finally, we use a classifier trained on real data to evaluate the label validity of class-conditionally generated samples.
Gradient-based Bit Encoding Optimization for Noise-Robust Binary Memristive Crossbar
Jan 05, 2022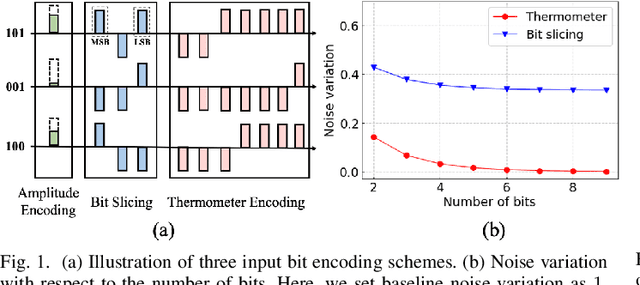
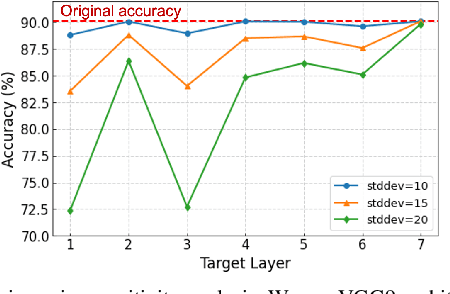
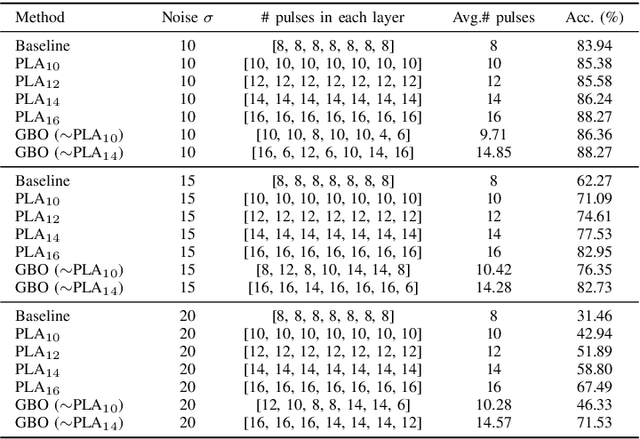
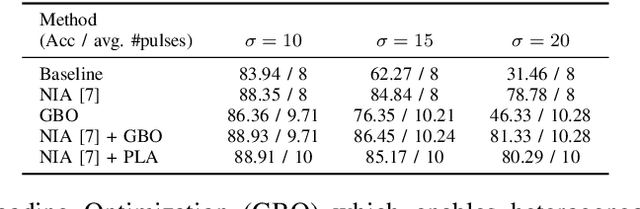
Binary memristive crossbars have gained huge attention as an energy-efficient deep learning hardware accelerator. Nonetheless, they suffer from various noises due to the analog nature of the crossbars. To overcome such limitations, most previous works train weight parameters with noise data obtained from a crossbar. These methods are, however, ineffective because it is difficult to collect noise data in large-volume manufacturing environment where each crossbar has a large device/circuit level variation. Moreover, we argue that there is still room for improvement even though these methods somewhat improve accuracy. This paper explores a new perspective on mitigating crossbar noise in a more generalized way by manipulating input binary bit encoding rather than training the weight of networks with respect to noise data. We first mathematically show that the noise decreases as the number of binary bit encoding pulses increases when representing the same amount of information. In addition, we propose Gradient-based Bit Encoding Optimization (GBO) which optimizes a different number of pulses at each layer, based on our in-depth analysis that each layer has a different level of noise sensitivity. The proposed heterogeneous layer-wise bit encoding scheme achieves high noise robustness with low computational cost. Our experimental results on public benchmark datasets show that GBO improves the classification accuracy by ~5-40% in severe noise scenarios.
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Dec 21, 2021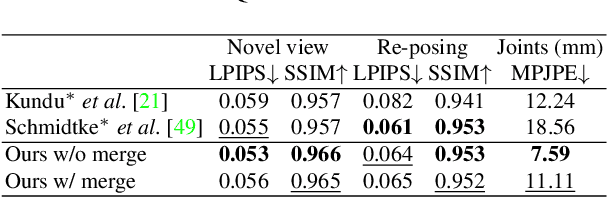
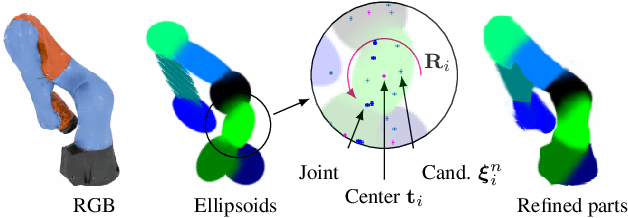
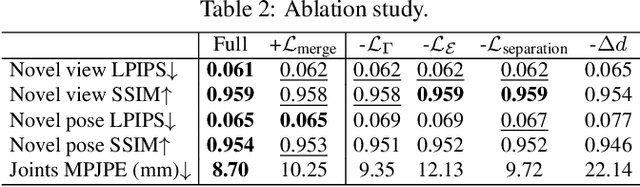
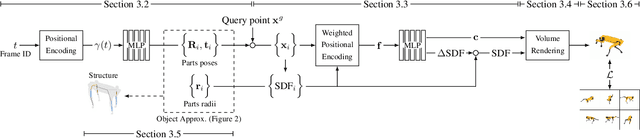
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies. Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other. Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories. We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure. Our insight is that adjacent parts that move relative to each other must be connected by a joint. To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced. We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.