 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Capacity and Performance Analysis of RIS-Assisted Communication Over Rician Fading Channels
Nov 08, 2021
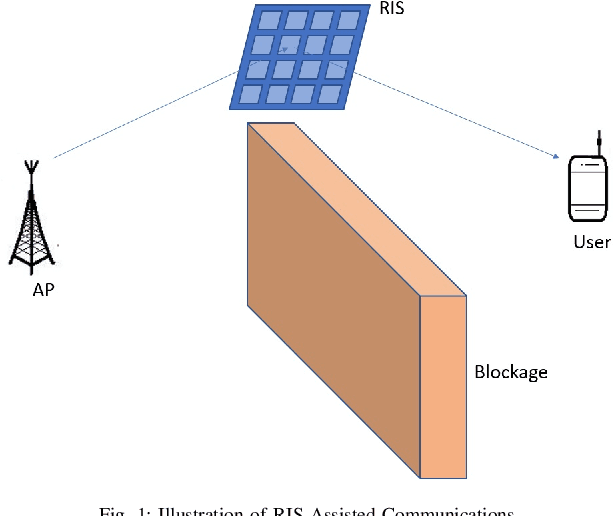
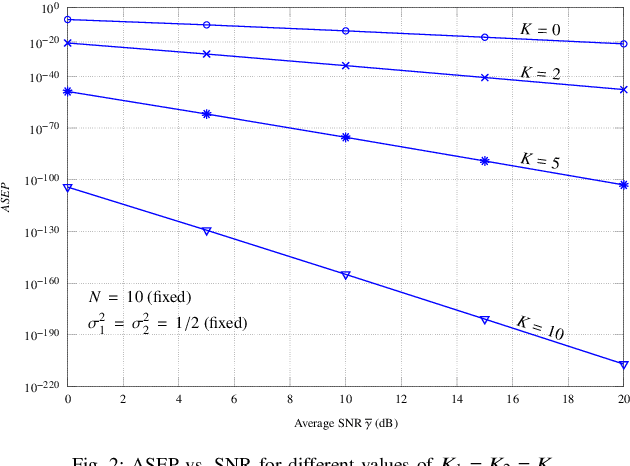
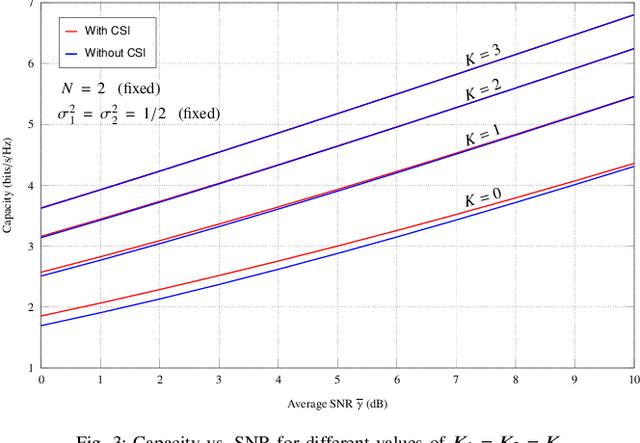
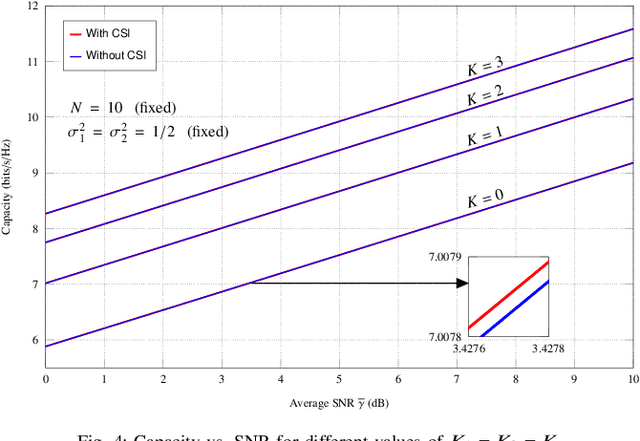
This paper investigates two performance metrics, namely ergodic capacity and symbol error rate, of mmWave communication system assisted by a reconfigurable intelligent surface (RIS). We assume independent and identically distributed (i.i.d.) Rician fadings between user-RIS-Access Point (AP), with RIS surface consisting of passive reflecting elements. First, we derive a new unified closed-form formula for the average symbol error probability of generalised M-QAM/M-PSK signalling over this mmWave link. We then obtain new closed-form expressions for the ergodic capacity with and without channel state information (CSI) at the AP.
TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation
Oct 29, 2021
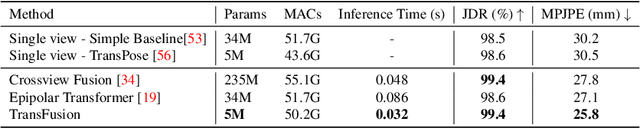
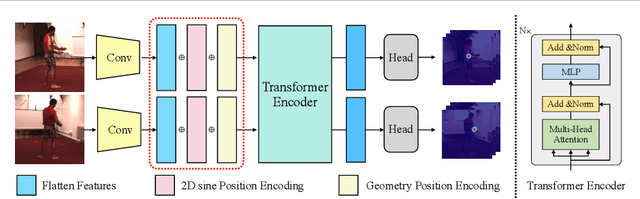

Estimating the 2D human poses in each view is typically the first step in calibrated multi-view 3D pose estimation. But the performance of 2D pose detectors suffers from challenging situations such as occlusions and oblique viewing angles. To address these challenges, previous works derive point-to-point correspondences between different views from epipolar geometry and utilize the correspondences to merge prediction heatmaps or feature representations. Instead of post-prediction merge/calibration, here we introduce a transformer framework for multi-view 3D pose estimation, aiming at directly improving individual 2D predictors by integrating information from different views. Inspired by previous multi-modal transformers, we design a unified transformer architecture, named TransFusion, to fuse cues from both current views and neighboring views. Moreover, we propose the concept of epipolar field to encode 3D positional information into the transformer model. The 3D position encoding guided by the epipolar field provides an efficient way of encoding correspondences between pixels of different views. Experiments on Human 3.6M and Ski-Pose show that our method is more efficient and has consistent improvements compared to other fusion methods. Specifically, we achieve 25.8 mm MPJPE on Human 3.6M with only 5M parameters on 256 x 256 resolution.
Offsetting Unequal Competition through RL-assisted Incentive Schemes
Jan 05, 2022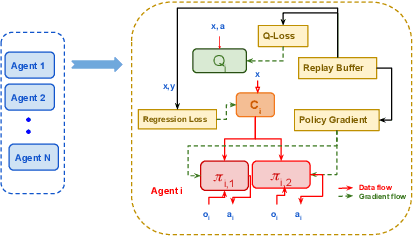
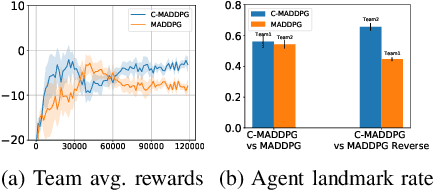
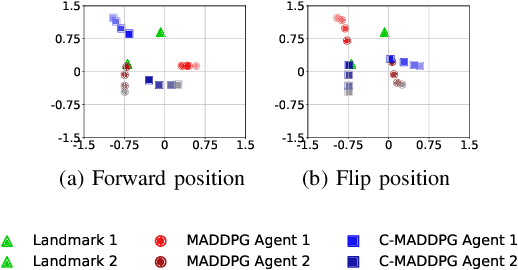
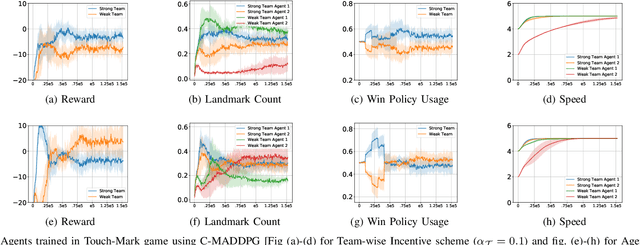
This paper investigates the dynamics of competition among organizations with unequal expertise. Multi-agent reinforcement learning has been used to simulate and understand the impact of various incentive schemes designed to offset such inequality. We design Touch-Mark, a game based on well-known multi-agent-particle-environment, where two teams (weak, strong) with unequal but changing skill levels compete against each other. For training such a game, we propose a novel controller assisted multi-agent reinforcement learning algorithm \our\, which empowers each agent with an ensemble of policies along with a supervised controller that by selectively partitioning the sample space, triggers intelligent role division among the teammates. Using C-MADDPG as an underlying framework, we propose an incentive scheme for the weak team such that the final rewards of both teams become the same. We find that in spite of the incentive, the final reward of the weak team falls short of the strong team. On inspecting, we realize that an overall incentive scheme for the weak team does not incentivize the weaker agents within that team to learn and improve. To offset this, we now specially incentivize the weaker player to learn and as a result, observe that the weak team beyond an initial phase performs at par with the stronger team. The final goal of the paper has been to formulate a dynamic incentive scheme that continuously balances the reward of the two teams. This is achieved by devising an incentive scheme enriched with an RL agent which takes minimum information from the environment.
Advancing 3D Medical Image Analysis with Variable Dimension Transform based Supervised 3D Pre-training
Jan 05, 2022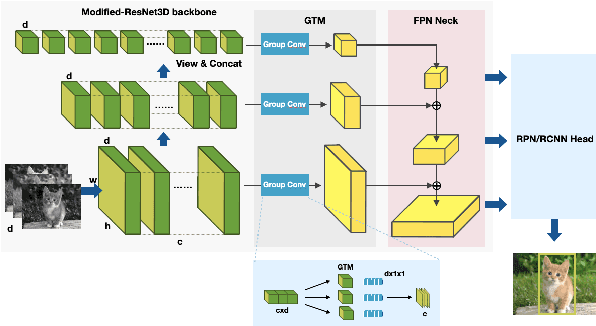
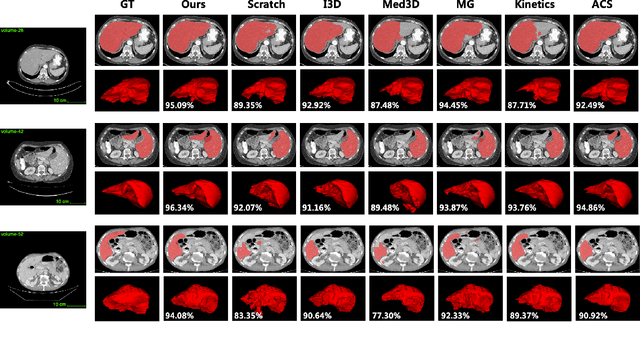
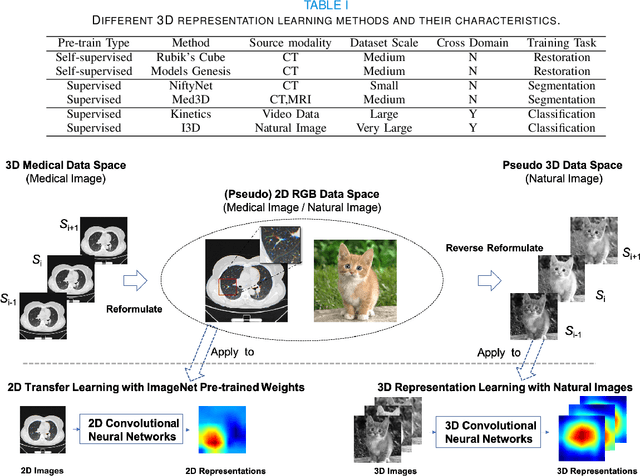
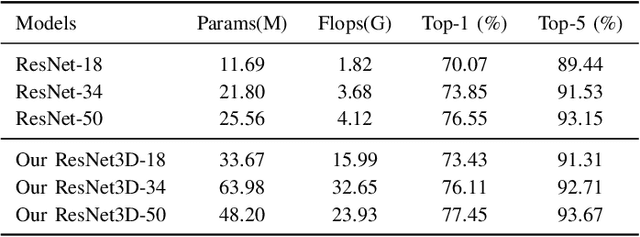
The difficulties in both data acquisition and annotation substantially restrict the sample sizes of training datasets for 3D medical imaging applications. As a result, constructing high-performance 3D convolutional neural networks from scratch remains a difficult task in the absence of a sufficient pre-training parameter. Previous efforts on 3D pre-training have frequently relied on self-supervised approaches, which use either predictive or contrastive learning on unlabeled data to build invariant 3D representations. However, because of the unavailability of large-scale supervision information, obtaining semantically invariant and discriminative representations from these learning frameworks remains problematic. In this paper, we revisit an innovative yet simple fully-supervised 3D network pre-training framework to take advantage of semantic supervisions from large-scale 2D natural image datasets. With a redesigned 3D network architecture, reformulated natural images are used to address the problem of data scarcity and develop powerful 3D representations. Comprehensive experiments on four benchmark datasets demonstrate that the proposed pre-trained models can effectively accelerate convergence while also improving accuracy for a variety of 3D medical imaging tasks such as classification, segmentation and detection. In addition, as compared to training from scratch, it can save up to 60% of annotation efforts. On the NIH DeepLesion dataset, it likewise achieves state-of-the-art detection performance, outperforming earlier self-supervised and fully-supervised pre-training approaches, as well as methods that do training from scratch. To facilitate further development of 3D medical models, our code and pre-trained model weights are publicly available at https://github.com/urmagicsmine/CSPR.
PL-EESR: Perceptual Loss Based END-TO-END Robust Speaker Representation Extraction
Oct 03, 2021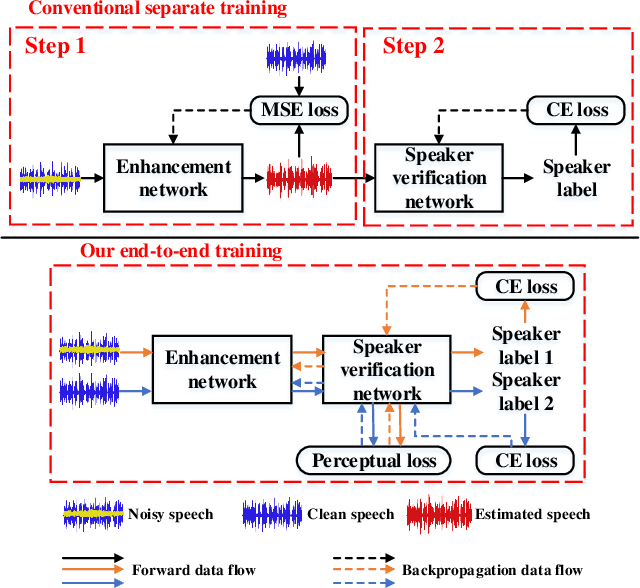

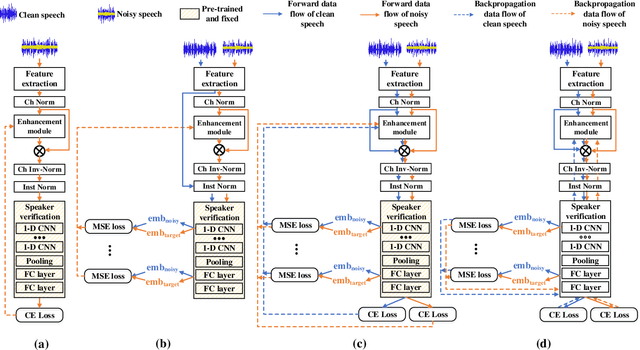
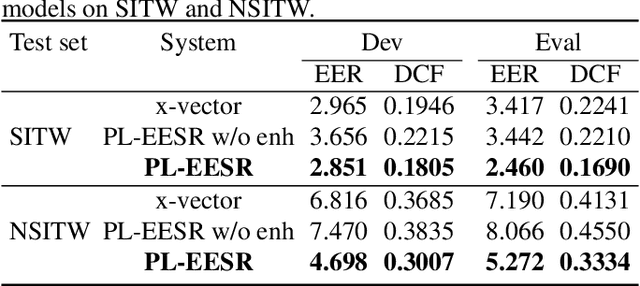
Speech enhancement aims to improve the perceptual quality of the speech signal by suppression of the background noise. However, excessive suppression may lead to speech distortion and speaker information loss, which degrades the performance of speaker embedding extraction. To alleviate this problem, we propose an end-to-end deep learning framework, dubbed PL-EESR, for robust speaker representation extraction. This framework is optimized based on the feedback of the speaker identification task and the high-level perceptual deviation between the raw speech signal and its noisy version. We conducted speaker verification tasks in both noisy and clean environment respectively to evaluate our system. Compared to the baseline, our method shows better performance in both clean and noisy environments, which means our method can not only enhance the speaker relative information but also avoid adding distortions.
Capacity Bounds under Imperfect Polarization Tracking
Dec 23, 2021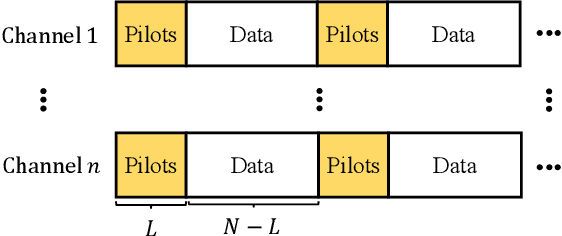
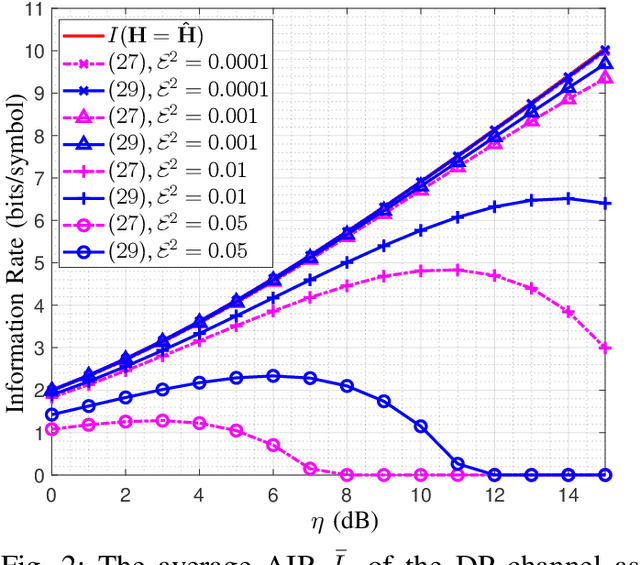
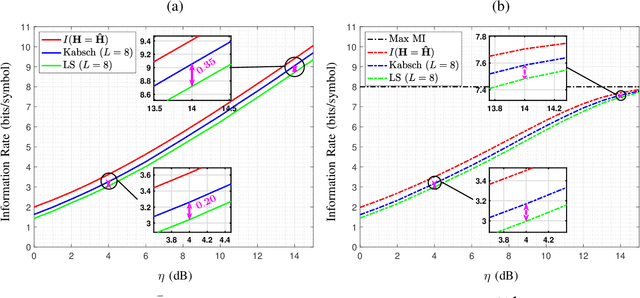
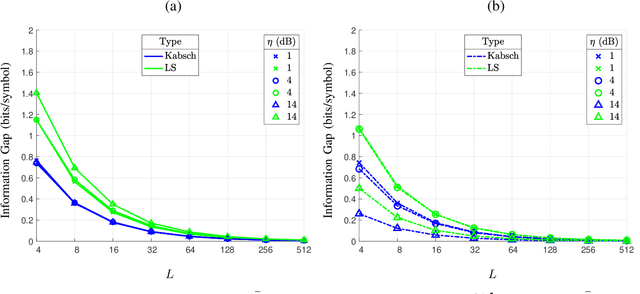
In optical fiber communication, due to the random variation of the environment, the state of polarization (SOP) fluctuates randomly with time leading to distortion and performance degradation. The memory-less SOP fluctuations can be regarded as a two-by-two random unitary matrix. In this paper, for what we believe to be the first time, the capacity of the polarization drift channel under an average power constraint with imperfect channel knowledge is characterized. An achievable information rate (AIR) is derived when imperfect channel knowledge is available and is shown to be highly dependent on the channel estimation technique. It is also shown that a tighter lower bound can be achieved when a unitary estimation of the channel is available. However, the conventional estimation algorithms do not guarantee a unitary channel estimation. Therefore, by considering the unitary constraint of the channel, a data-aided channel estimator based on the Kabsch algorithm is proposed, and its performance is numerically evaluated in terms of AIR. Monte Carlo simulations show that Kabsch outperforms the least-square error algorithm. In particular, with complex, Gaussian inputs and eight pilot symbols per block, Kabsch improves the AIR by 0:2 to 0:35 bits/symbol throughout the range of studied signal-to-noise ratios.
SmartDet: Context-Aware Dynamic Control of Edge Task Offloading for Mobile Object Detection
Jan 11, 2022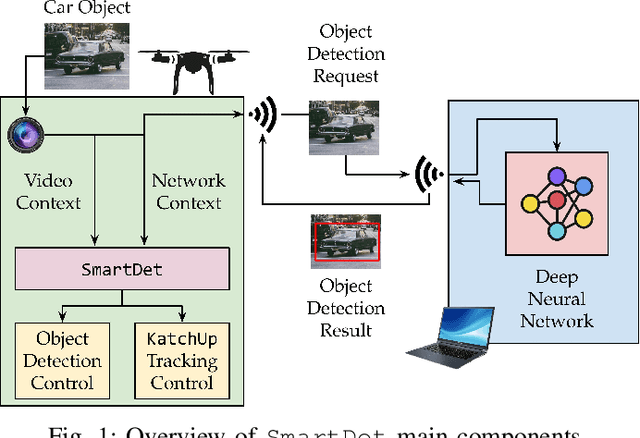
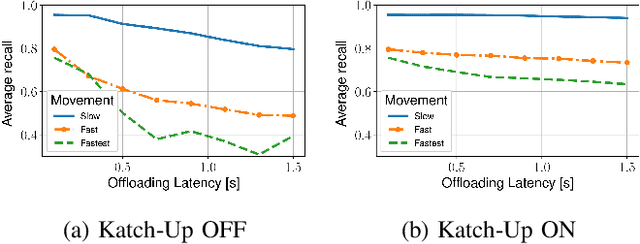

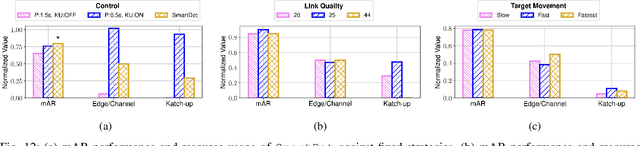
Mobile devices increasingly rely on object detection (OD) through deep neural networks (DNNs) to perform critical tasks. Due to their high complexity, the execution of these DNNs requires excessive time and energy. Low-complexity object tracking (OT) can be used with OD, where the latter is periodically applied to generate "fresh" references for tracking. However, the frames processed with OD incur large delays, which may make the reference outdated and degrade tracking quality. Herein, we propose to use edge computing in this context, and establish parallel OT (at the mobile device) and OD (at the edge server) processes that are resilient to large OD latency. We propose Katch-Up, a novel tracking mechanism that improves the system resilience to excessive OD delay. However, while Katch-Up significantly improves performance, it also increases the computing load of the mobile device. Hence, we design SmartDet, a low-complexity controller based on deep reinforcement learning (DRL) that learns controlling the trade-off between resource utilization and OD performance. SmartDet takes as input context-related information related to the current video content and the current network conditions to optimize frequency and type of OD offloading, as well as Katch-Up utilization. We extensively evaluate SmartDet on a real-world testbed composed of a JetSon Nano as mobile device and a GTX 980 Ti as edge server, connected through a Wi-Fi link. Experimental results show that SmartDet achieves an optimal balance between tracking performance - mean Average Recall (mAR) and resource usage. With respect to a baseline with full Katch-Upusage and maximum channel usage, we still increase mAR by 4% while using 50% less of the channel and 30% power resources associated with Katch-Up. With respect to a fixed strategy using minimal resources, we increase mAR by 20% while using Katch-Up on 1/3 of the frames.
MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection
Dec 07, 2021
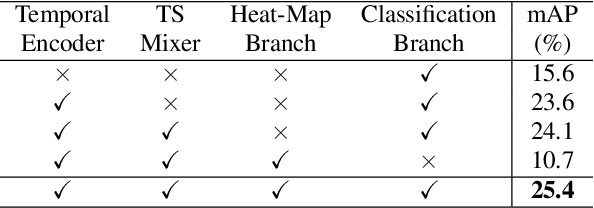
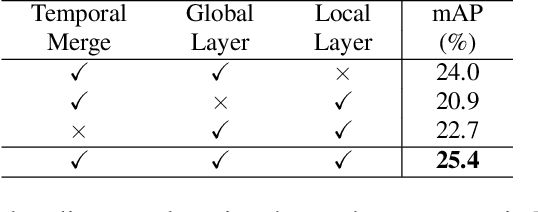
Action detection is an essential and challenging task, especially for densely labelled datasets of untrimmed videos. The temporal relation is complex in those datasets, including challenges like composite action, and co-occurring action. For detecting actions in those complex videos, efficiently capturing both short-term and long-term temporal information in the video is critical. To this end, we propose a novel ConvTransformer network for action detection. This network comprises three main components: (1) Temporal Encoder module extensively explores global and local temporal relations at multiple temporal resolutions. (2) Temporal Scale Mixer module effectively fuses the multi-scale features to have a unified feature representation. (3) Classification module is used to learn the instance center-relative position and predict the frame-level classification scores. The extensive experiments on multiple datasets, including Charades, TSU and MultiTHUMOS, confirm the effectiveness of our proposed method. Our network outperforms the state-of-the-art methods on all three datasets.
Natural Computational Architectures for Cognitive Info-Communication
Oct 01, 2021Recent comprehensive overview of 40 years of research in cognitive architectures, (Kotseruba and Tsotsos 2020), evaluates modelling of the core cognitive abilities in humans, but only marginally addresses biologically plausible approaches based on natural computation. This mini review presents a set of perspectives and approaches which have shaped the development of biologically inspired computational models in the recent past that can lead to the development of biologically more realistic cognitive architectures. For describing continuum of natural cognitive architectures, from basal cellular to human-level cognition, we use evolutionary info-computational framework, where natural/ physical/ morphological computation leads to evolution of increasingly complex cognitive systems. Forty years ago, when the first cognitive architectures have been proposed, understanding of cognition, embodiment and evolution was different. So was the state of the art of information physics, bioinformatics, information chemistry, computational neuroscience, complexity theory, self-organization, theory of evolution, information and computation. Novel developments support a constructive interdisciplinary framework for cognitive architectures in the context of computing nature, where interactions between constituents at different levels of organization lead to complexification of agency and increased cognitive capacities. We identify several important research questions for further investigation that can increase understanding of cognition in nature and inspire new developments of cognitive technologies. Recently, basal cell cognition attracted a lot of interest for its possible applications in medicine, new computing technologies, as well as micro- and nanorobotics.
LIFE: Learning Individual Features for Multivariate Time Series Prediction with Missing Values
Oct 09, 2021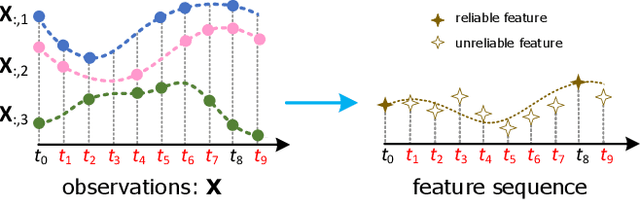
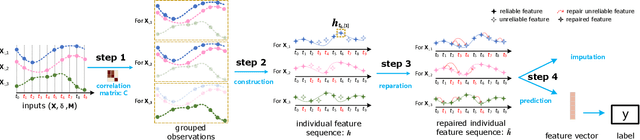
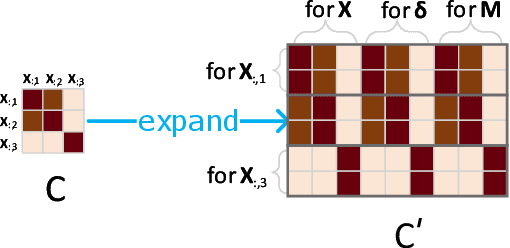
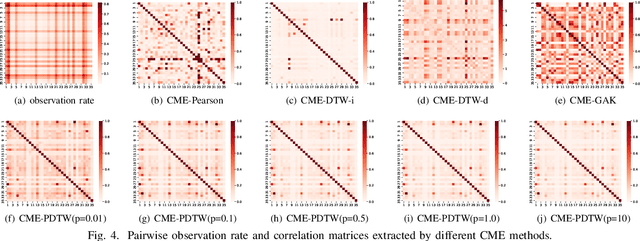
Multivariate time series (MTS) prediction is ubiquitous in real-world fields, but MTS data often contains missing values. In recent years, there has been an increasing interest in using end-to-end models to handle MTS with missing values. To generate features for prediction, existing methods either merge all input dimensions of MTS or tackle each input dimension independently. However, both approaches are hard to perform well because the former usually produce many unreliable features and the latter lacks correlated information. In this paper, we propose a Learning Individual Features (LIFE) framework, which provides a new paradigm for MTS prediction with missing values. LIFE generates reliable features for prediction by using the correlated dimensions as auxiliary information and suppressing the interference from uncorrelated dimensions with missing values. Experiments on three real-world data sets verify the superiority of LIFE to existing state-of-the-art models.