 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TEACh: Task-driven Embodied Agents that Chat
Oct 01, 2021
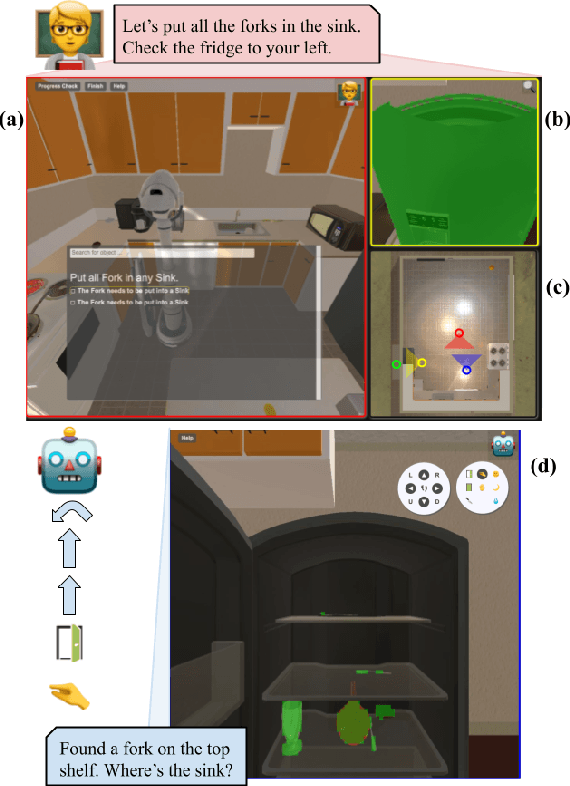
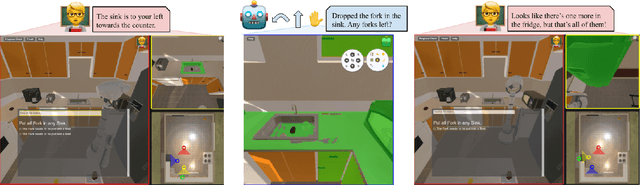
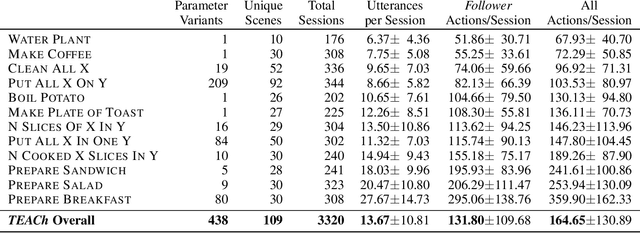
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
Dec 02, 2021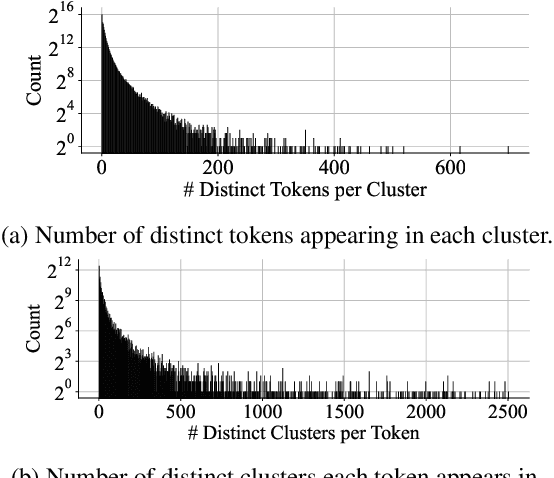
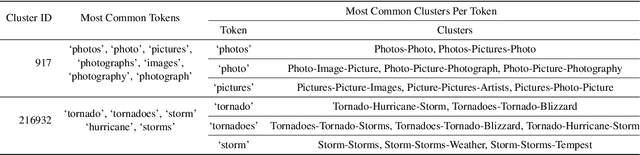
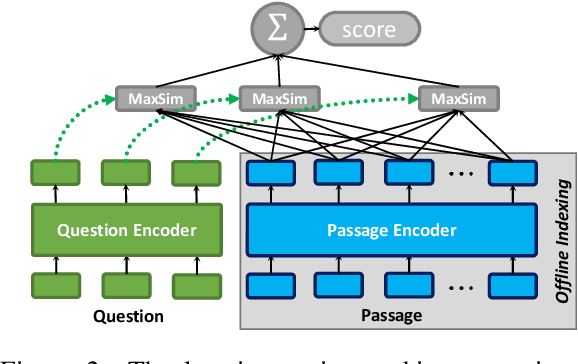
Neural information retrieval (IR) has greatly advanced search and other knowledge-intensive language tasks. While many neural IR methods encode queries and documents into single-vector representations, late interaction models produce multi-vector representations at the granularity of each token and decompose relevance modeling into scalable token-level computations. This decomposition has been shown to make late interaction more effective, but it inflates the space footprint of these models by an order of magnitude. In this work, we introduce ColBERTv2, a retriever that couples an aggressive residual compression mechanism with a denoised supervision strategy to simultaneously improve the quality and space footprint of late interaction. We evaluate ColBERTv2 across a wide range of benchmarks, establishing state-of-the-art quality within and outside the training domain while reducing the space footprint of late interaction models by 5--8$\times$.
NICE-Beam: Neural Integrated Covariance Estimators for Time-Varying Beamformers
Dec 08, 2021
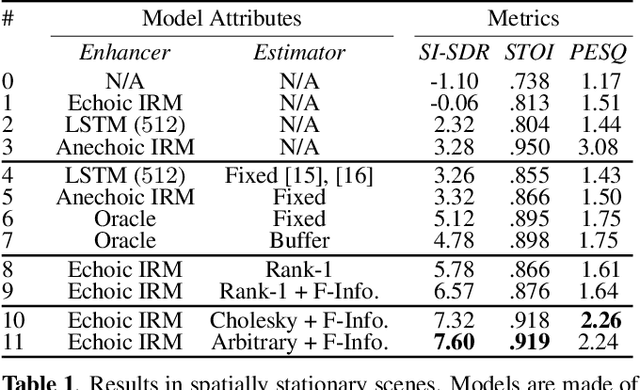
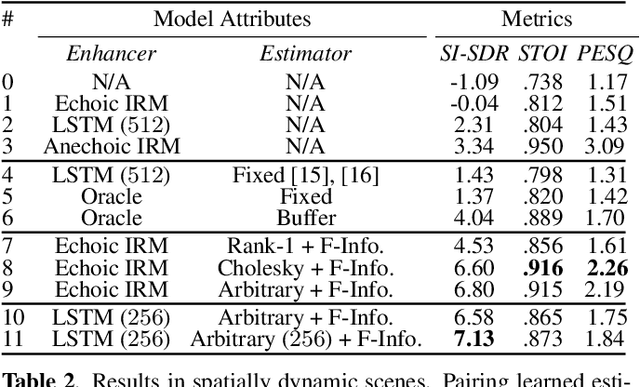

Estimating a time-varying spatial covariance matrix for a beamforming algorithm is a challenging task, especially for wearable devices, as the algorithm must compensate for time-varying signal statistics due to rapid pose-changes. In this paper, we propose Neural Integrated Covariance Estimators for Beamformers, NICE-Beam. NICE-Beam is a general technique for learning how to estimate time-varying spatial covariance matrices, which we apply to joint speech enhancement and dereverberation. It is based on training a neural network module to non-linearly track and leverage scene information across time. We integrate our solution into a beamforming pipeline, which enables simple training, faster than real-time inference, and a variety of test-time adaptation options. We evaluate the proposed model against a suite of baselines in scenes with both stationary and moving microphones. Our results show that the proposed method can outperform a hand-tuned estimator, despite the hand-tuned estimator using oracle source separation knowledge.
A Temporal Knowledge Graph Completion Method Based on Balanced Timestamp Distribution
Aug 30, 2021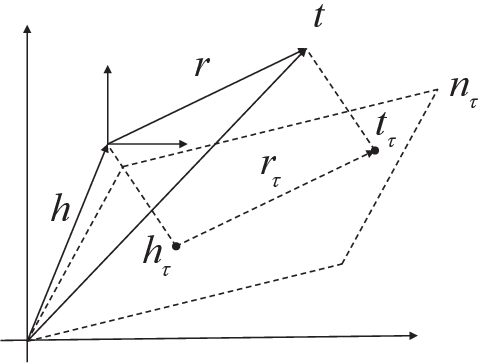


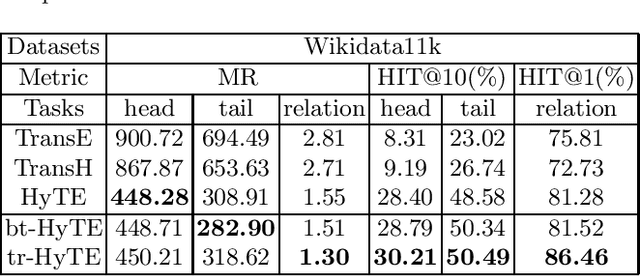
Completion through the embedding representation of the knowledge graph (KGE) has been a research hotspot in recent years. Realistic knowledge graphs are mostly related to time, while most of the existing KGE algorithms ignore the time information. A few existing methods directly or indirectly encode the time information, ignoring the balance of timestamp distribution, which greatly limits the performance of temporal knowledge graph completion (KGC). In this paper, a temporal KGC method is proposed based on the direct encoding time information framework, and a given time slice is treated as the finest granularity for balanced timestamp distribution. A large number of experiments on temporal knowledge graph datasets extracted from the real world demonstrate the effectiveness of our method.
Top-Down Deep Clustering with Multi-generator GANs
Dec 24, 2021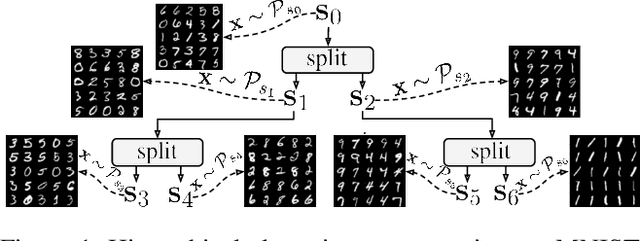
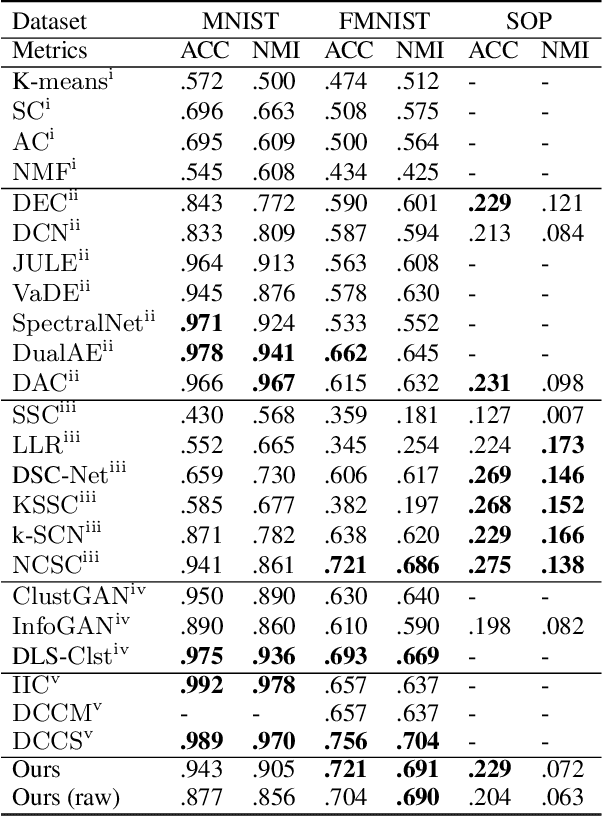
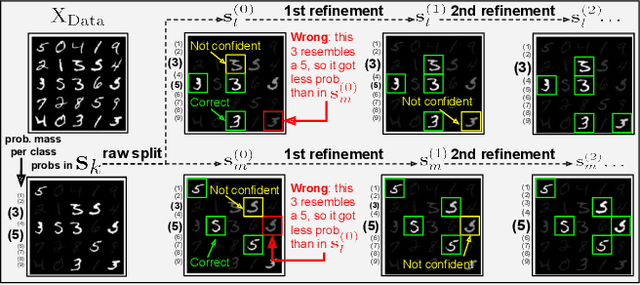

Deep clustering (DC) leverages the representation power of deep architectures to learn embedding spaces that are optimal for cluster analysis. This approach filters out low-level information irrelevant for clustering and has proven remarkably successful for high dimensional data spaces. Some DC methods employ Generative Adversarial Networks (GANs), motivated by the powerful latent representations these models are able to learn implicitly. In this work, we propose HC-MGAN, a new technique based on GANs with multiple generators (MGANs), which have not been explored for clustering. Our method is inspired by the observation that each generator of a MGAN tends to generate data that correlates with a sub-region of the real data distribution. We use this clustered generation to train a classifier for inferring from which generator a given image came from, thus providing a semantically meaningful clustering for the real distribution. Additionally, we design our method so that it is performed in a top-down hierarchical clustering tree, thus proposing the first hierarchical DC method, to the best of our knowledge. We conduct several experiments to evaluate the proposed method against recent DC methods, obtaining competitive results. Last, we perform an exploratory analysis of the hierarchical clustering tree that highlights how accurately it organizes the data in a hierarchy of semantically coherent patterns.
Symmetry-Enhanced Attention Network for Acute Ischemic Infarct Segmentation with Non-Contrast CT Images
Oct 11, 2021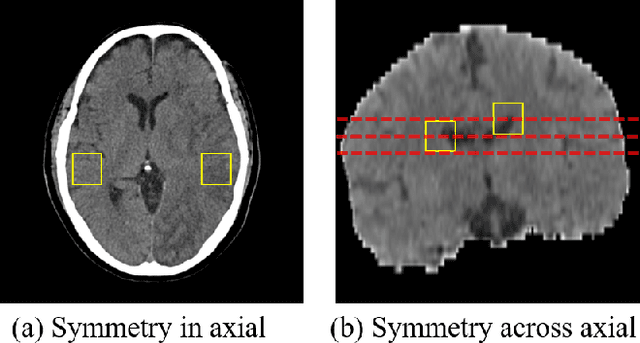
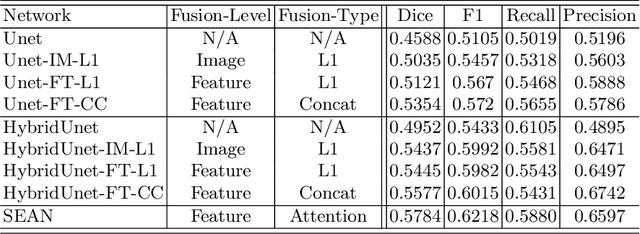
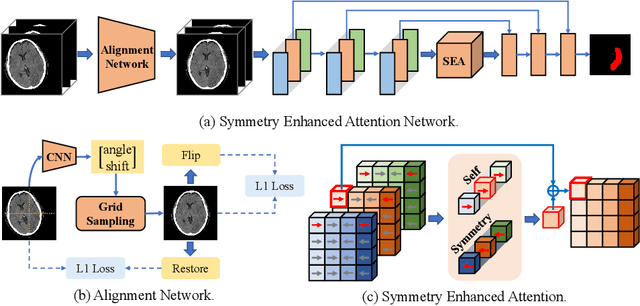
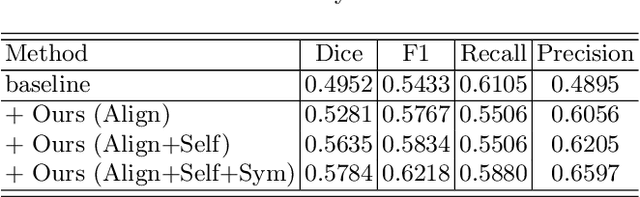
Quantitative estimation of the acute ischemic infarct is crucial to improve neurological outcomes of the patients with stroke symptoms. Since the density of lesions is subtle and can be confounded by normal physiologic changes, anatomical asymmetry provides useful information to differentiate the ischemic and healthy brain tissue. In this paper, we propose a symmetry enhanced attention network (SEAN) for acute ischemic infarct segmentation. Our proposed network automatically transforms an input CT image into the standard space where the brain tissue is bilaterally symmetric. The transformed image is further processed by a Ushape network integrated with the proposed symmetry enhanced attention for pixel-wise labelling. The symmetry enhanced attention can efficiently capture context information from the opposite side of the image by estimating long-range dependencies. Experimental results show that the proposed SEAN outperforms some symmetry-based state-of-the-art methods in terms of both dice coefficient and infarct localization.
A Dual-Attention Neural Network for Pun Location and Using Pun-Gloss Pairs for Interpretation
Oct 14, 2021

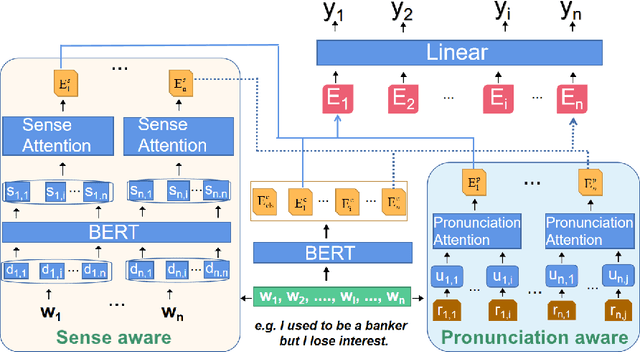
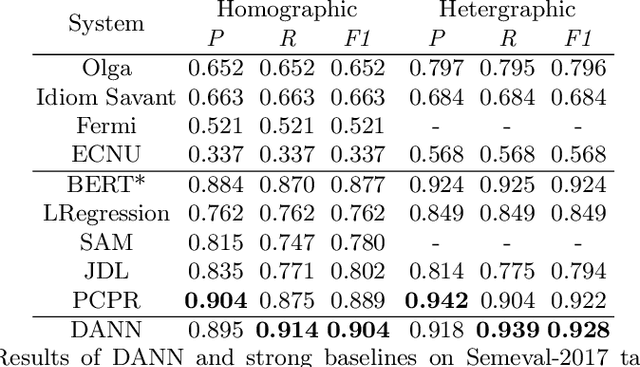
Pun location is to identify the punning word (usually a word or a phrase that makes the text ambiguous) in a given short text, and pun interpretation is to find out two different meanings of the punning word. Most previous studies adopt limited word senses obtained by WSD(Word Sense Disambiguation) technique or pronunciation information in isolation to address pun location. For the task of pun interpretation, related work pays attention to various WSD algorithms. In this paper, a model called DANN (Dual-Attentive Neural Network) is proposed for pun location, effectively integrates word senses and pronunciation with context information to address two kinds of pun at the same time. Furthermore, we treat pun interpretation as a classification task and construct pungloss pairs as processing data to solve this task. Experiments on the two benchmark datasets show that our proposed methods achieve new state-of-the-art results. Our source code is available in the public code repository.
Prompt-based Zero-shot Relation Classification with Semantic Knowledge Augmentation
Dec 08, 2021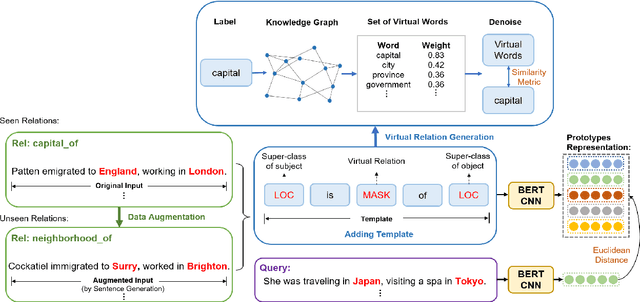
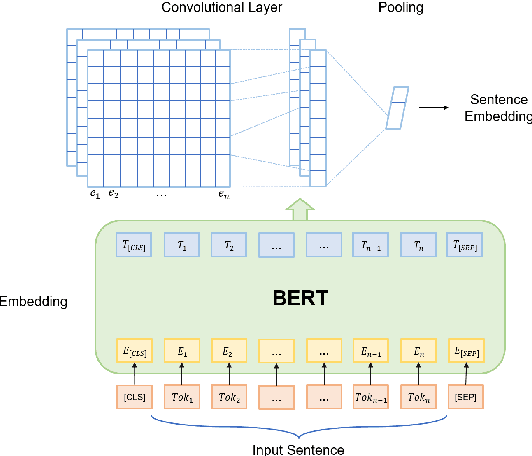
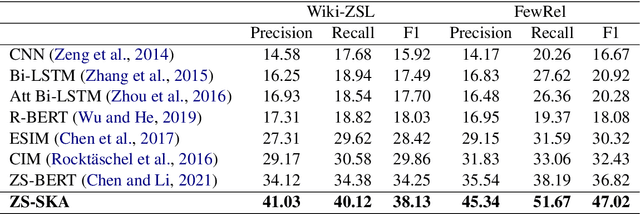
Recognizing unseen relations with no training instances is a challenging task in the real world. In this paper, we propose a prompt-based model with semantic knowledge augmentation (ZS-SKA) to recognize unseen relations under the zero-shot setting. We generate augmented instances with unseen relations from instances with seen relations following a new word-level sentence translation rule. We design prompts based on an external knowledge graph to integrate semantic knowledge information learned from seen relations. Instead of using the actual label sets in the prompt template, we construct weighted virtual label words. By generating the representations of both seen and unseen relations with augmented instances and prompts through prototypical networks, distance is calculated to predict unseen relations. Extensive experiments conducted on three public datasets show that ZS-SKA outperforms state-of-the-art methods under the zero-shot scenarios. Our experimental results also demonstrate the effectiveness and robustness of ZS-SKA.
Prompting Visual-Language Models for Efficient Video Understanding
Dec 08, 2021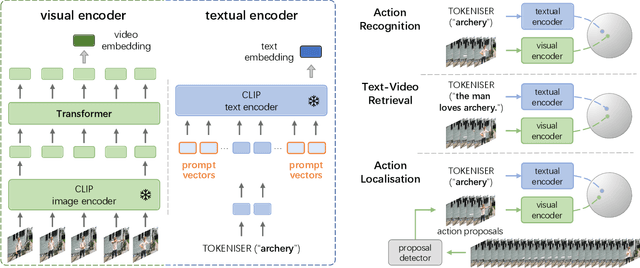
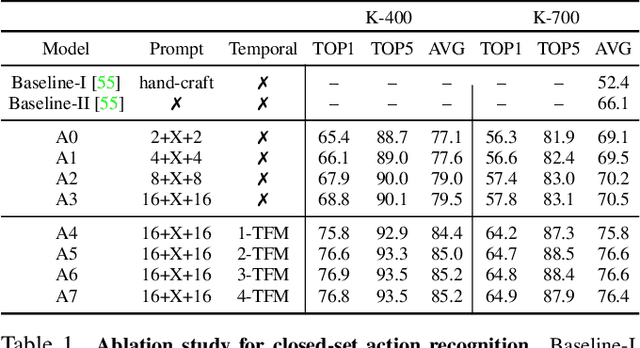
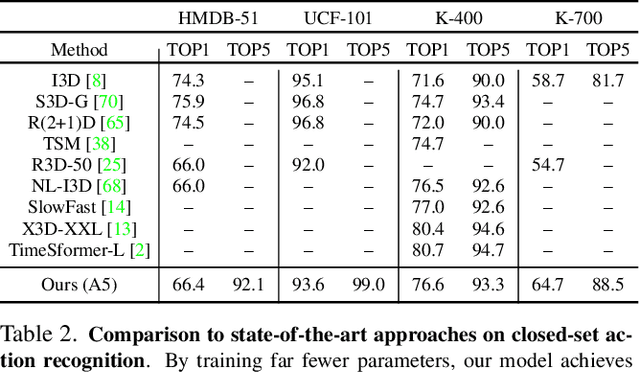
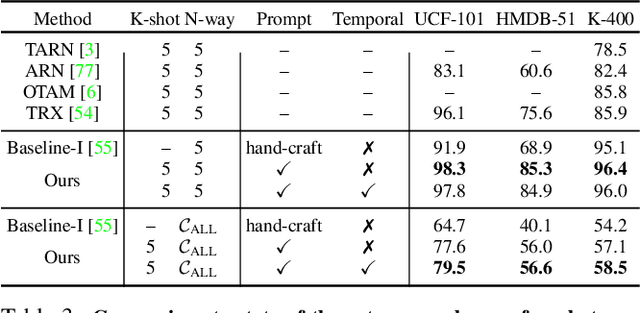
Visual-language pre-training has shown great success for learning joint visual-textual representations from large-scale web data, demonstrating remarkable ability for zero-shot generalisation. This paper presents a simple method to efficiently adapt one pre-trained visual-language model to novel tasks with minimal training, and here, we consider video understanding tasks. Specifically, we propose to optimise a few random vectors, termed as continuous prompt vectors, that convert the novel tasks into the same format as the pre-training objectives. In addition, to bridge the gap between static images and videos, temporal information is encoded with lightweight Transformers stacking on top of frame-wise visual features. Experimentally, we conduct extensive ablation studies to analyse the critical components and necessities. On 9 public benchmarks of action recognition, action localisation, and text-video retrieval, across closed-set, few-shot, open-set scenarios, we achieve competitive or state-of-the-art performance to existing methods, despite training significantly fewer parameters.
Tracking People by Predicting 3D Appearance, Location & Pose
Dec 08, 2021
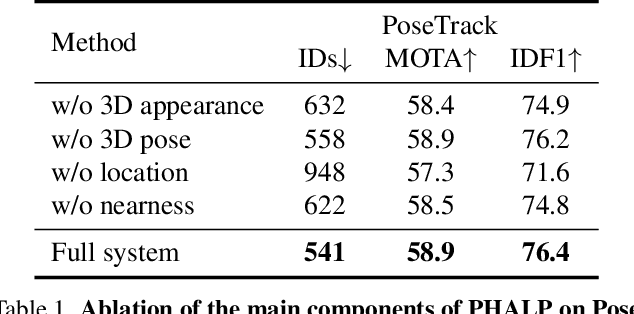
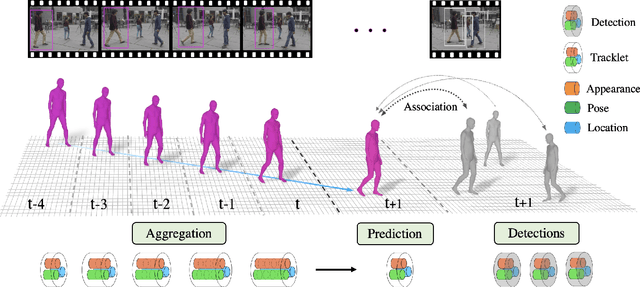

In this paper, we present an approach for tracking people in monocular videos, by predicting their future 3D representations. To achieve this, we first lift people to 3D from a single frame in a robust way. This lifting includes information about the 3D pose of the person, his or her location in the 3D space, and the 3D appearance. As we track a person, we collect 3D observations over time in a tracklet representation. Given the 3D nature of our observations, we build temporal models for each one of the previous attributes. We use these models to predict the future state of the tracklet, including 3D location, 3D appearance, and 3D pose. For a future frame, we compute the similarity between the predicted state of a tracklet and the single frame observations in a probabilistic manner. Association is solved with simple Hungarian matching, and the matches are used to update the respective tracklets. We evaluate our approach on various benchmarks and report state-of-the-art results.