 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Linear Classification from Limited Training Data
Oct 04, 2021
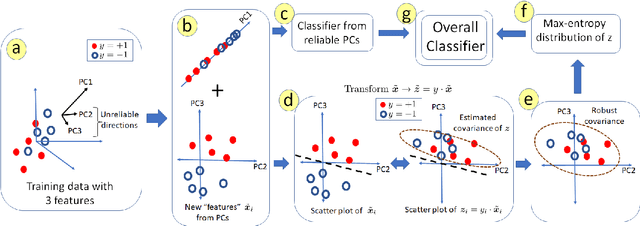
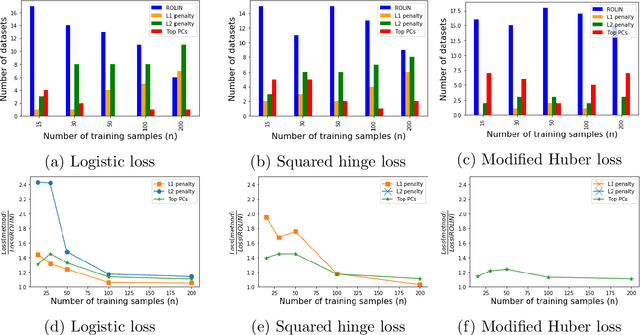
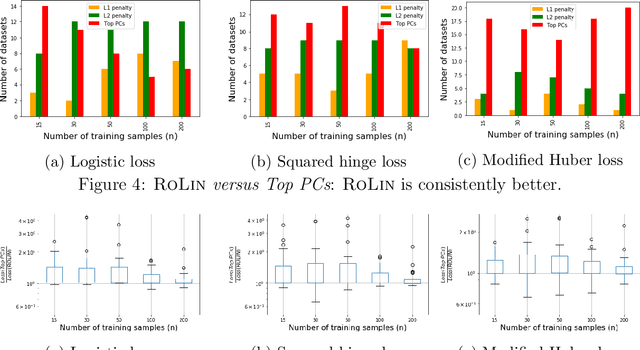
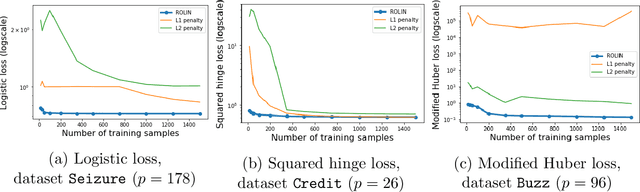
We consider the problem of linear classification under general loss functions in the limited-data setting. Overfitting is a common problem here. The standard approaches to prevent overfitting are dimensionality reduction and regularization. But dimensionality reduction loses information, while regularization requires the user to choose a norm, or a prior, or a distance metric. We propose an algorithm called RoLin that needs no user choice and applies to a large class of loss functions. RoLin combines reliable information from the top principal components with a robust optimization to extract any useful information from unreliable subspaces. It also includes a new robust cross-validation that is better than existing cross-validation methods in the limited-data setting. Experiments on $25$ real-world datasets and three standard loss functions show that RoLin broadly outperforms both dimensionality reduction and regularization. Dimensionality reduction has $14\%-40\%$ worse test loss on average as compared to RoLin. Against $L_1$ and $L_2$ regularization, RoLin can be up to 3x better for logistic loss and 12x better for squared hinge loss. The differences are greatest for small sample sizes, where RoLin achieves the best loss on 2x to 3x more datasets than any competing method. For some datasets, RoLin with $15$ training samples is better than the best norm-based regularization with $1500$ samples.
CTIN: Robust Contextual Transformer Network for Inertial Navigation
Dec 03, 2021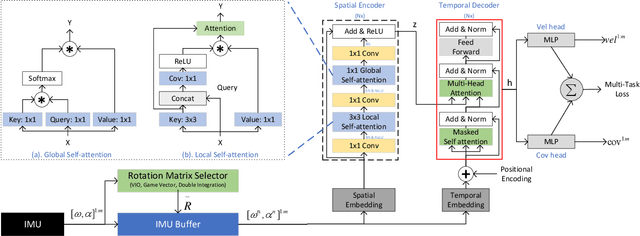

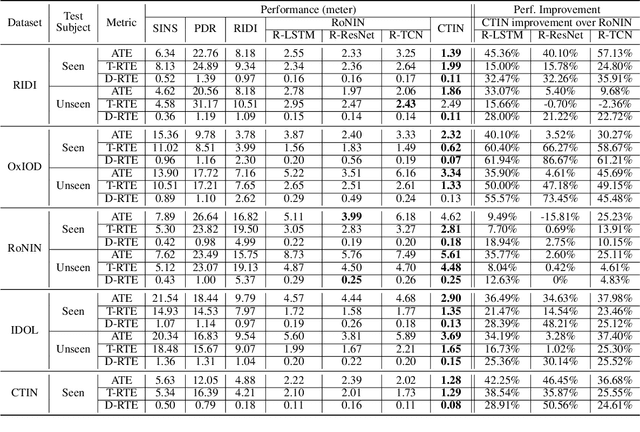
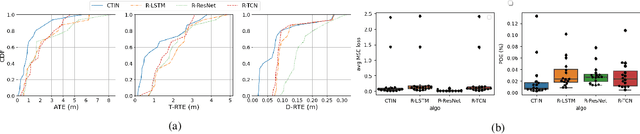
Recently, data-driven inertial navigation approaches have demonstrated their capability of using well-trained neural networks to obtain accurate position estimates from inertial measurement units (IMU) measurements. In this paper, we propose a novel robust Contextual Transformer-based network for Inertial Navigation~(CTIN) to accurately predict velocity and trajectory. To this end, we first design a ResNet-based encoder enhanced by local and global multi-head self-attention to capture spatial contextual information from IMU measurements. Then we fuse these spatial representations with temporal knowledge by leveraging multi-head attention in the Transformer decoder. Finally, multi-task learning with uncertainty reduction is leveraged to improve learning efficiency and prediction accuracy of velocity and trajectory. Through extensive experiments over a wide range of inertial datasets~(e.g. RIDI, OxIOD, RoNIN, IDOL, and our own), CTIN is very robust and outperforms state-of-the-art models.
Tri-graph Information Propagation for Polypharmacy Side Effect Prediction
Jan 28, 2020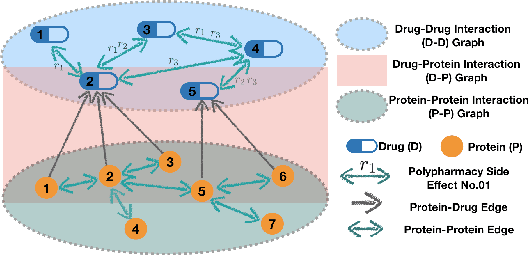

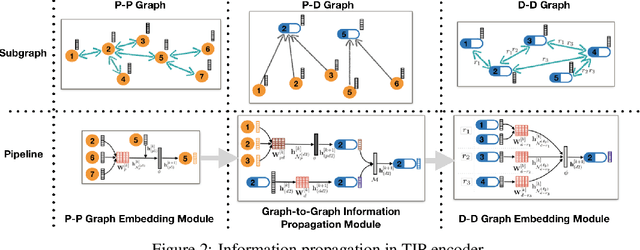
The use of drug combinations often leads to polypharmacy side effects (POSE). A recent method formulates POSE prediction as a link prediction problem on a graph of drugs and proteins, and solves it with Graph Convolutional Networks (GCNs). However, due to the complex relationships in POSE, this method has high computational cost and memory demand. This paper proposes a flexible Tri-graph Information Propagation (TIP) model that operates on three subgraphs to learn representations progressively by propagation from protein-protein graph to drug-drug graph via protein-drug graph. Experiments show that TIP improves accuracy by 7%+, time efficiency by 83$\times$, and space efficiency by 3$\times$.
GhostNets on Heterogeneous Devices via Cheap Operations
Jan 10, 2022
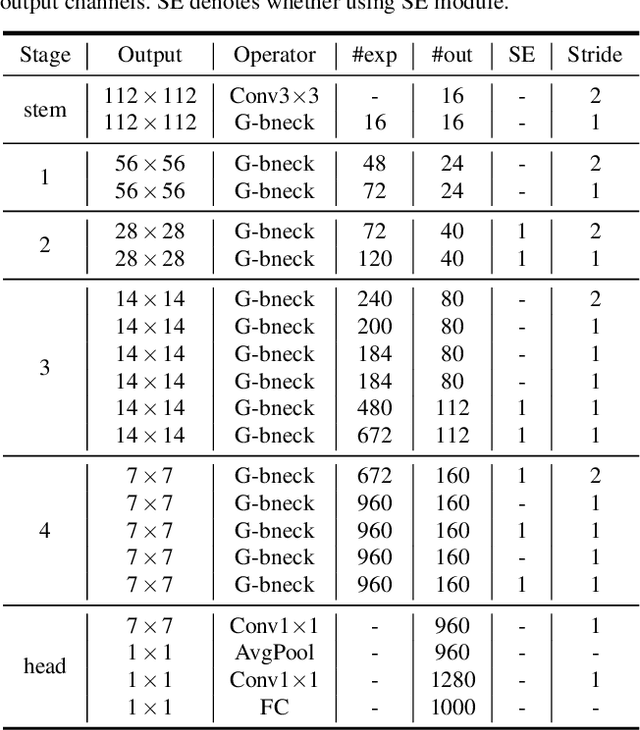
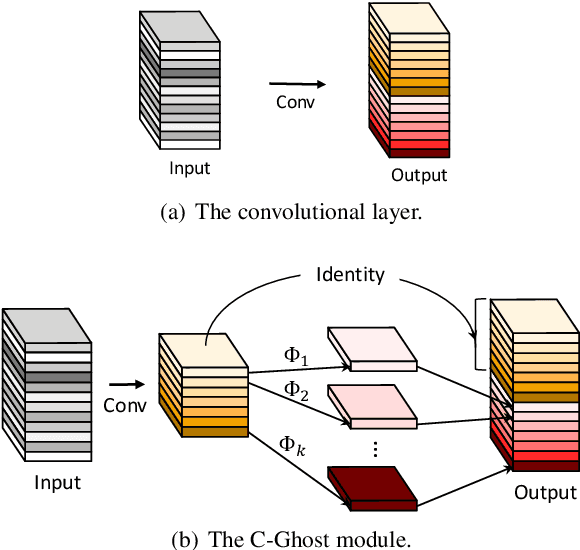
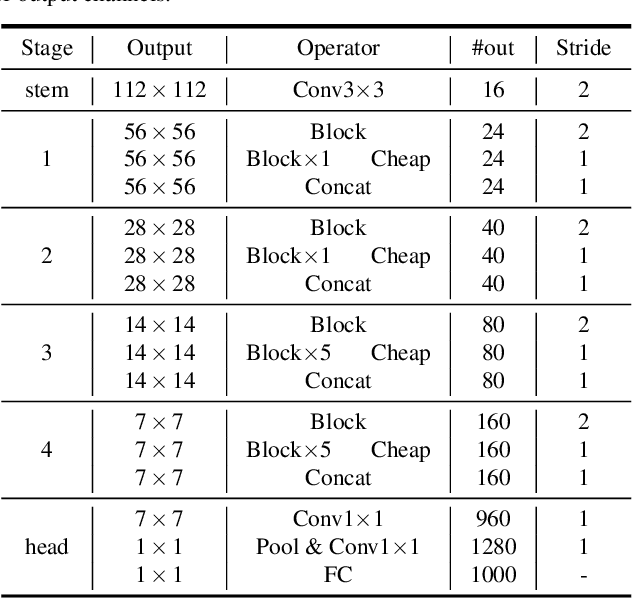
Deploying convolutional neural networks (CNNs) on mobile devices is difficult due to the limited memory and computation resources. We aim to design efficient neural networks for heterogeneous devices including CPU and GPU, by exploiting the redundancy in feature maps, which has rarely been investigated in neural architecture design. For CPU-like devices, we propose a novel CPU-efficient Ghost (C-Ghost) module to generate more feature maps from cheap operations. Based on a set of intrinsic feature maps, we apply a series of linear transformations with cheap cost to generate many ghost feature maps that could fully reveal information underlying intrinsic features. The proposed C-Ghost module can be taken as a plug-and-play component to upgrade existing convolutional neural networks. C-Ghost bottlenecks are designed to stack C-Ghost modules, and then the lightweight C-GhostNet can be easily established. We further consider the efficient networks for GPU devices. Without involving too many GPU-inefficient operations (e.g.,, depth-wise convolution) in a building stage, we propose to utilize the stage-wise feature redundancy to formulate GPU-efficient Ghost (G-Ghost) stage structure. The features in a stage are split into two parts where the first part is processed using the original block with fewer output channels for generating intrinsic features, and the other are generated using cheap operations by exploiting stage-wise redundancy. Experiments conducted on benchmarks demonstrate the effectiveness of the proposed C-Ghost module and the G-Ghost stage. C-GhostNet and G-GhostNet can achieve the optimal trade-off of accuracy and latency for CPU and GPU, respectively. Code is available at https://github.com/huawei-noah/CV-Backbones.
Damage Estimation and Localization from Sparse Aerial Imagery
Nov 05, 2021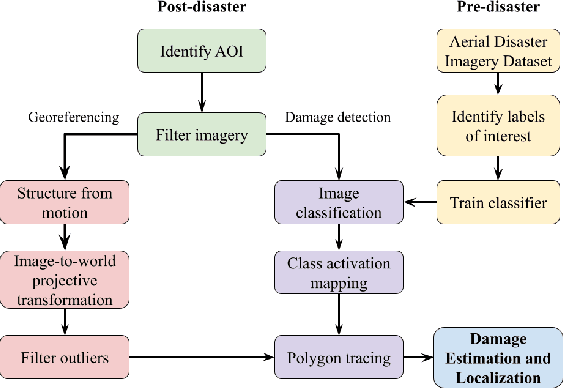

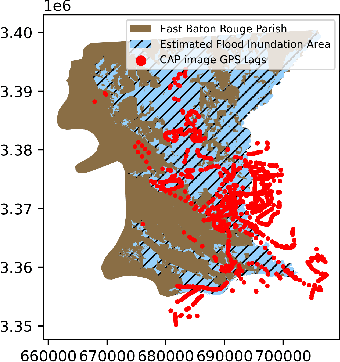
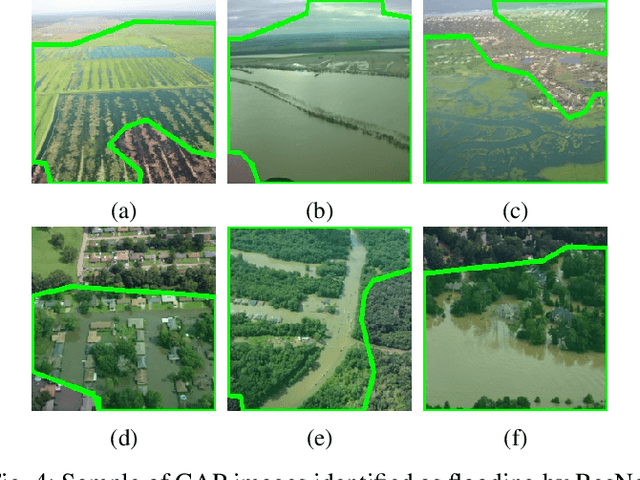
Aerial images provide important situational awareness for responding to natural disasters such as hurricanes. They are well-suited for providing information for damage estimation and localization (DEL); i.e., characterizing the type and spatial extent of damage following a disaster. Despite recent advances in sensing and unmanned aerial systems technology, much of post-disaster aerial imagery is still taken by handheld DSLR cameras from small, manned, fixed-wing aircraft. However, these handheld cameras lack IMU information, and images are taken opportunistically post-event by operators. As such, DEL from such imagery is still a highly manual and time-consuming process. We propose an approach to both detect damage in aerial images and localize it in world coordinates, with specific focus on detecting and localizing flooding. The approach is based on using structure from motion to relate image coordinates to world coordinates via a projective transformation, using class activation mapping to detect the extent of damage in an image, and applying the projective transformation to localize damage in world coordinates. We evaluate the performance of our approach on post-event data from the 2016 Louisiana floods, and find that our approach achieves a precision of 88%. Given this high precision using limited data, we argue that this approach is currently viable for fast and effective DEL from handheld aerial imagery for disaster response.
CALDA: Improving Multi-Source Time Series Domain Adaptation with Contrastive Adversarial Learning
Sep 30, 2021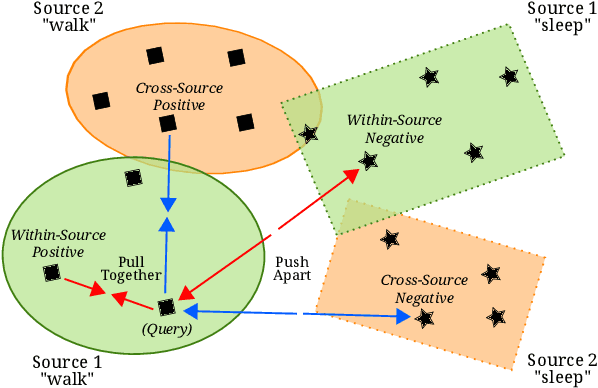
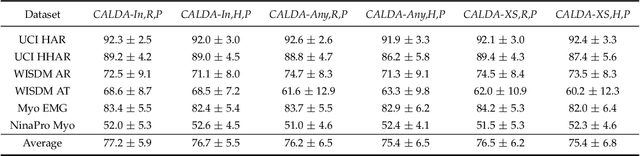
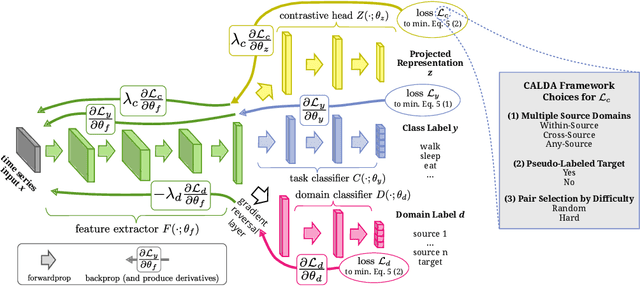
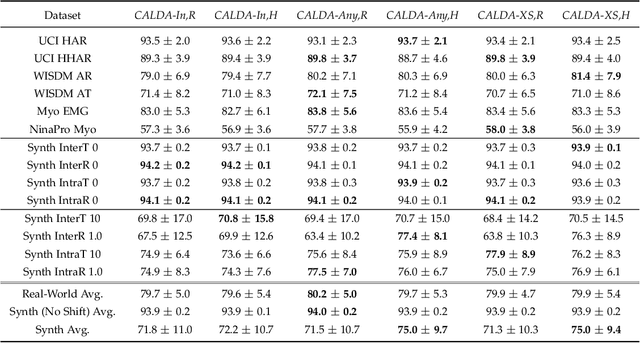
Unsupervised domain adaptation (UDA) provides a strategy for improving machine learning performance in data-rich (target) domains where ground truth labels are inaccessible but can be found in related (source) domains. In cases where meta-domain information such as label distributions is available, weak supervision can further boost performance. We propose a novel framework, CALDA, to tackle these two problems. CALDA synergistically combines the principles of contrastive learning and adversarial learning to robustly support multi-source UDA (MS-UDA) for time series data. Similar to prior methods, CALDA utilizes adversarial learning to align source and target feature representations. Unlike prior approaches, CALDA additionally leverages cross-source label information across domains. CALDA pulls examples with the same label close to each other, while pushing apart examples with different labels, reshaping the space through contrastive learning. Unlike prior contrastive adaptation methods, CALDA requires neither data augmentation nor pseudo labeling, which may be more challenging for time series. We empirically validate our proposed approach. Based on results from human activity recognition, electromyography, and synthetic datasets, we find utilizing cross-source information improves performance over prior time series and contrastive methods. Weak supervision further improves performance, even in the presence of noise, allowing CALDA to offer generalizable strategies for MS-UDA. Code is available at: https://github.com/floft/calda
Isolation forests: looking beyond tree depth
Nov 23, 2021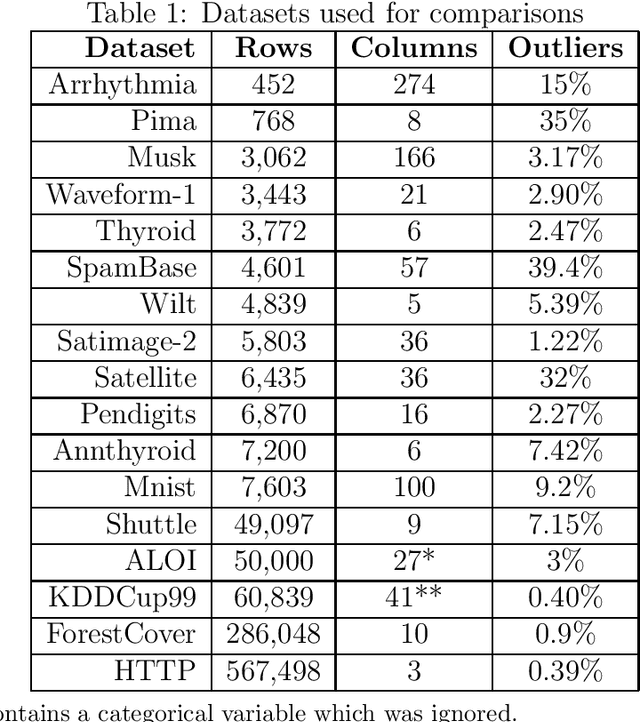
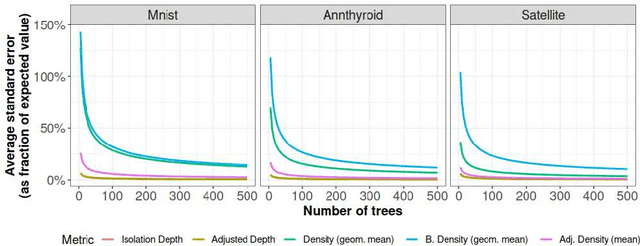
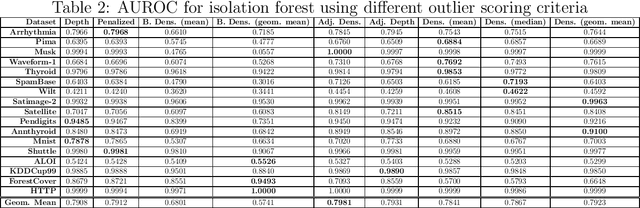
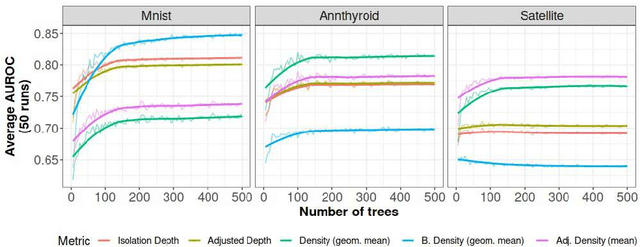
The isolation forest algorithm for outlier detection exploits a simple yet effective observation: if taking some multivariate data and making uniformly random cuts across the feature space recursively, it will take fewer such random cuts for an outlier to be left alone in a given subspace as compared to regular observations. The original idea proposed an outlier score based on the tree depth (number of random cuts) required for isolation, but experiments here show that using information about the size of the feature space taken and the number of points assigned to it can result in improved results in many situations without any modification to the tree structure, especially in the presence of categorical features.
Meta-CPR: Generalize to Unseen Large Number of Agents with Communication Pattern Recognition Module
Dec 15, 2021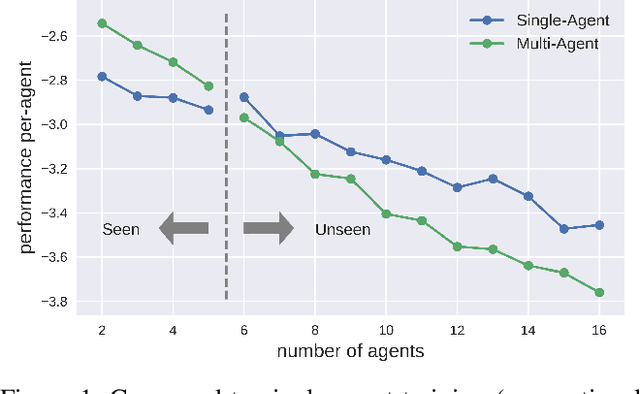
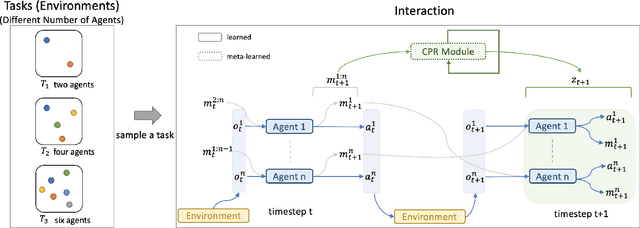
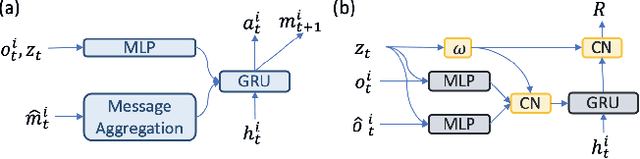
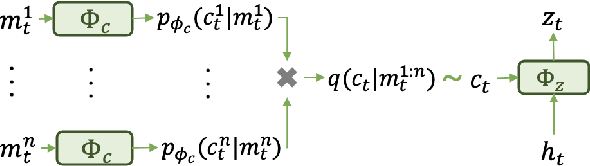
Designing an effective communication mechanism among agents in reinforcement learning has been a challenging task, especially for real-world applications. The number of agents can grow or an environment sometimes needs to interact with a changing number of agents in real-world scenarios. To this end, a multi-agent framework needs to handle various scenarios of agents, in terms of both scales and dynamics, for being practical to real-world applications. We formulate the multi-agent environment with a different number of agents as a multi-tasking problem and propose a meta reinforcement learning (meta-RL) framework to tackle this problem. The proposed framework employs a meta-learned Communication Pattern Recognition (CPR) module to identify communication behavior and extract information that facilitates the training process. Experimental results are poised to demonstrate that the proposed framework (a) generalizes to an unseen larger number of agents and (b) allows the number of agents to change between episodes. The ablation study is also provided to reason the proposed CPR design and show such design is effective.
TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning
Dec 15, 2021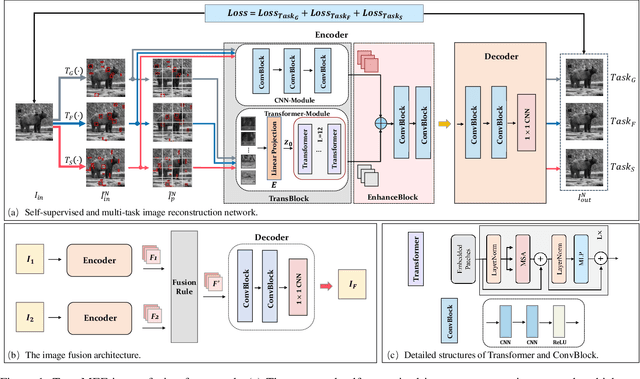
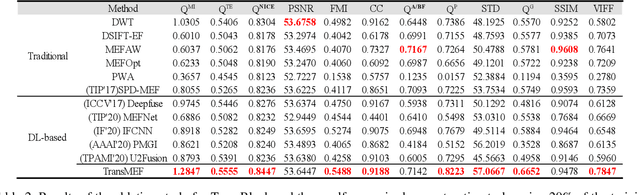


In this paper, we propose TransMEF, a transformer-based multi-exposure image fusion framework that uses self-supervised multi-task learning. The framework is based on an encoder-decoder network, which can be trained on large natural image datasets and does not require ground truth fusion images. We design three self-supervised reconstruction tasks according to the characteristics of multi-exposure images and conduct these tasks simultaneously using multi-task learning; through this process, the network can learn the characteristics of multi-exposure images and extract more generalized features. In addition, to compensate for the defect in establishing long-range dependencies in CNN-based architectures, we design an encoder that combines a CNN module with a transformer module. This combination enables the network to focus on both local and global information. We evaluated our method and compared it to 11 competitive traditional and deep learning-based methods on the latest released multi-exposure image fusion benchmark dataset, and our method achieved the best performance in both subjective and objective evaluations.
Explicit CSI Feedback Compression via Learned Approximate Message Passing
Oct 12, 2021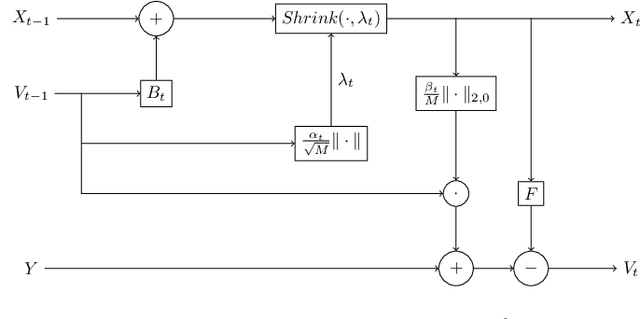
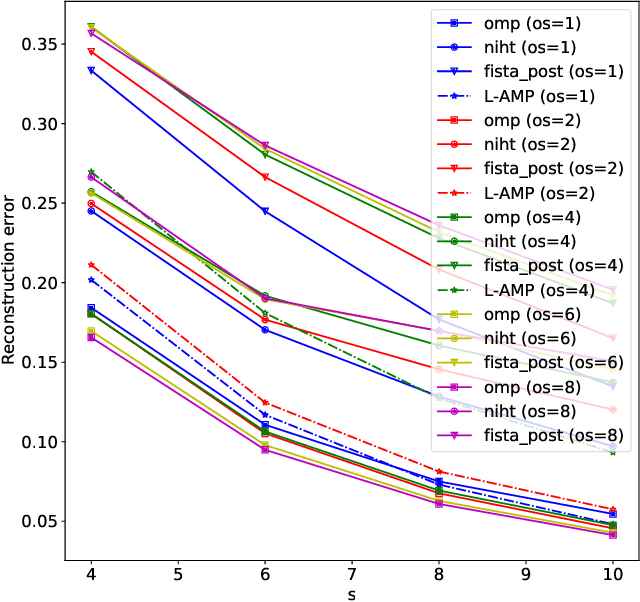
Explicit channel state information at the transmitter side is helpful to improve downlink precoding performance for multi-user MIMO systems. In order to reduce feedback signalling overhead, compression of Channel State Information (CSI) is essential. In this work different low complexity compressed sensing algorithms are compared in the context of an explicit CSI feedback scheme for 5G new radio. A neural network approach, based on learned approximate message passing for the computation of row-sparse solutions to matrix-valued compressed sensing problems is introduced. Due to extensive weight sharing, it shares the low memory footprint and fast evaluation of the forward pass with few iterations of a first order iterative algorithm. Furthermore it can be trained on purely synthetic data prior to deployment. Its performance in the explicit CSI feedback application is evaluated, and its key benefits in terms of computational complexity savings are discussed.