 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Query Suggestion with Multi-Agent Reinforcement Learning from Human Feedback
Feb 07, 2024
In the rapidly evolving landscape of information retrieval, search engines strive to provide more personalized and relevant results to users. Query suggestion systems play a crucial role in achieving this goal by assisting users in formulating effective queries. However, existing query suggestion systems mainly rely on textual inputs, potentially limiting user search experiences for querying images. In this paper, we introduce a novel Multimodal Query Suggestion (MMQS) task, which aims to generate query suggestions based on user query images to improve the intentionality and diversity of search results. We present the RL4Sugg framework, leveraging the power of Large Language Models (LLMs) with Multi-Agent Reinforcement Learning from Human Feedback to optimize the generation process. Through comprehensive experiments, we validate the effectiveness of RL4Sugg, demonstrating a 18% improvement compared to the best existing approach. Moreover, the MMQS has been transferred into real-world search engine products, which yield enhanced user engagement. Our research advances query suggestion systems and provides a new perspective on multimodal information retrieval.
Semantic segmentation for recognition of epileptiform patterns recorded via Microelectrode Arrays in vitro
Feb 12, 2024Epilepsy is a prevalent neurological disorder that affects approximately 1% of the global population. Around 30-40% of patients do not respond to pharmacological treatment, leading to a significant negative impact on their quality of life. Closed-loop deep brain stimulation (DBS) is a promising treatment for individuals who do not respond to medical therapy. To achieve effective seizure control, algorithms play an important role in identifying relevant electrographic biomarkers from local field potentials (LFPs) to determine the optimal stimulation timing. In this regard, the detection and classification of events from ongoing brain activity, while achieving low power through computationally unexpensive implementations, represents a major challenge in the field. To address this challenge, we here present two lightweight algorithms, the ZdensityRODE and the AMPDE, for identifying relevant events from LFPs by utilizing semantic segmentation, which involves extracting different levels of information from the LFP and relevant events from it. The algorithms performance was validated against epileptiform activity induced by 4-minopyridine in mouse hippocampus-cortex (CTX) slices and recorded via microelectrode array, as a case study. The ZdensityRODE algorithm showcased a precision and recall of 93% for ictal event detection and 42% precision for interictal event detection, while the AMPDE algorithm attained a precision of 96% and recall of 90% for ictal event detection and 54% precision for interictal event detection. While initially trained specifically for detection of ictal activity, these algorithms can be fine-tuned for improved interictal detection, aiming at seizure prediction. Our results suggest that these algorithms can effectively capture epileptiform activity; their light weight opens new possibilities for real-time seizure detection and seizure prediction and control.
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension
Feb 12, 2024Recently, instruction-following audio-language models have received broad attention for human-audio interaction. However, the absence of benchmarks capable of evaluating audio-centric interaction capabilities has impeded advancements in this field. Previous models primarily focus on assessing different fundamental tasks, such as Automatic Speech Recognition (ASR), and lack an assessment of the open-ended generative capabilities centered around audio. Thus, it is challenging to track the progression in the Large Audio-Language Models (LALMs) domain and to provide guidance for future improvement. In this paper, we introduce AIR-Bench (\textbf{A}udio \textbf{I}nst\textbf{R}uction \textbf{Bench}mark), the first benchmark designed to evaluate the ability of LALMs to understand various types of audio signals (including human speech, natural sounds, and music), and furthermore, to interact with humans in the textual format. AIR-Bench encompasses two dimensions: \textit{foundation} and \textit{chat} benchmarks. The former consists of 19 tasks with approximately 19k single-choice questions, intending to inspect the basic single-task ability of LALMs. The latter one contains 2k instances of open-ended question-and-answer data, directly assessing the comprehension of the model on complex audio and its capacity to follow instructions. Both benchmarks require the model to generate hypotheses directly. We design a unified framework that leverages advanced language models, such as GPT-4, to evaluate the scores of generated hypotheses given the meta-information of the audio. Experimental results demonstrate a high level of consistency between GPT-4-based evaluation and human evaluation. By revealing the limitations of existing LALMs through evaluation results, AIR-Bench can provide insights into the direction of future research.
Speech Rhythm-Based Speaker Embeddings Extraction from Phonemes and Phoneme Duration for Multi-Speaker Speech Synthesis
Feb 11, 2024This paper proposes a speech rhythm-based method for speaker embeddings to model phoneme duration using a few utterances by the target speaker. Speech rhythm is one of the essential factors among speaker characteristics, along with acoustic features such as F0, for reproducing individual utterances in speech synthesis. A novel feature of the proposed method is the rhythm-based embeddings extracted from phonemes and their durations, which are known to be related to speaking rhythm. They are extracted with a speaker identification model similar to the conventional spectral feature-based one. We conducted three experiments, speaker embeddings generation, speech synthesis with generated embeddings, and embedding space analysis, to evaluate the performance. The proposed method demonstrated a moderate speaker identification performance (15.2% EER), even with only phonemes and their duration information. The objective and subjective evaluation results demonstrated that the proposed method can synthesize speech with speech rhythm closer to the target speaker than the conventional method. We also visualized the embeddings to evaluate the relationship between the distance of the embeddings and the perceptual similarity. The visualization of the embedding space and the relation analysis between the closeness indicated that the distribution of embeddings reflects the subjective and objective similarity.
* 11 pages,9 figures, Accepted to IEICE TRANSACTIONS on Information and Systems
Sparse Graph Representations for Procedural Instructional Documents
Feb 06, 2024Computation of document similarity is a critical task in various NLP domains that has applications in deduplication, matching, and recommendation. Traditional approaches for document similarity computation include learning representations of documents and employing a similarity or a distance function over the embeddings. However, pairwise similarities and differences are not efficiently captured by individual representations. Graph representations such as Joint Concept Interaction Graph (JCIG) represent a pair of documents as a joint undirected weighted graph. JCIGs facilitate an interpretable representation of document pairs as a graph. However, JCIGs are undirected, and don't consider the sequential flow of sentences in documents. We propose two approaches to model document similarity by representing document pairs as a directed and sparse JCIG that incorporates sequential information. We propose two algorithms inspired by Supergenome Sorting and Hamiltonian Path that replace the undirected edges with directed edges. Our approach also sparsifies the graph to $O(n)$ edges from JCIG's worst case of $O(n^2)$. We show that our sparse directed graph model architecture consisting of a Siamese encoder and GCN achieves comparable results to the baseline on datasets not containing sequential information and beats the baseline by ten points on an instructional documents dataset containing sequential information.
You Only Need One Color Space: An Efficient Network for Low-light Image Enhancement
Feb 08, 2024Low-Light Image Enhancement (LLIE) task tends to restore the details and visual information from corrupted low-light images. Most existing methods learn the mapping function between low/normal-light images by Deep Neural Networks (DNNs) on sRGB and HSV color space. Nevertheless, enhancement involves amplifying image signals, and applying these color spaces to low-light images with a low signal-to-noise ratio can introduce sensitivity and instability into the enhancement process. Consequently, this results in the presence of color artifacts and brightness artifacts in the enhanced images. To alleviate this problem, we propose a novel trainable color space, named Horizontal/Vertical-Intensity (HVI). It not only decouples brightness and color from RGB channels to mitigate the instability during enhancement but also adapts to low-light images in different illumination ranges due to the trainable parameters. Further, we design a novel Color and Intensity Decoupling Network (CIDNet) with two branches dedicated to processing the decoupled image brightness and color in the HVI space. Within CIDNet, we introduce the Lightweight Cross-Attention (LCA) module to facilitate interaction between image structure and content information in both branches, while also suppressing noise in low-light images. Finally, we conducted 22 quantitative and qualitative experiments to show that the proposed CIDNet outperforms the state-of-the-art methods on 11 datasets. The code will be available at https://github.com/Fediory/HVI-CIDNet.
pFedMoE: Data-Level Personalization with Mixture of Experts for Model-Heterogeneous Personalized Federated Learning
Feb 08, 2024Federated learning (FL) has been widely adopted for collaborative training on decentralized data. However, it faces the challenges of data, system, and model heterogeneity. This has inspired the emergence of model-heterogeneous personalized federated learning (MHPFL). Nevertheless, the problem of ensuring data and model privacy, while achieving good model performance and keeping communication and computation costs low remains open in MHPFL. To address this problem, we propose a model-heterogeneous personalized Federated learning with Mixture of Experts (pFedMoE) method. It assigns a shared homogeneous small feature extractor and a local gating network for each client's local heterogeneous large model. Firstly, during local training, the local heterogeneous model's feature extractor acts as a local expert for personalized feature (representation) extraction, while the shared homogeneous small feature extractor serves as a global expert for generalized feature extraction. The local gating network produces personalized weights for extracted representations from both experts on each data sample. The three models form a local heterogeneous MoE. The weighted mixed representation fuses generalized and personalized features and is processed by the local heterogeneous large model's header with personalized prediction information. The MoE and prediction header are updated simultaneously. Secondly, the trained local homogeneous small feature extractors are sent to the server for cross-client information fusion via aggregation. Overall, pFedMoE enhances local model personalization at a fine-grained data level, while supporting model heterogeneity.
Guiding drones by information gain
Jan 08, 2024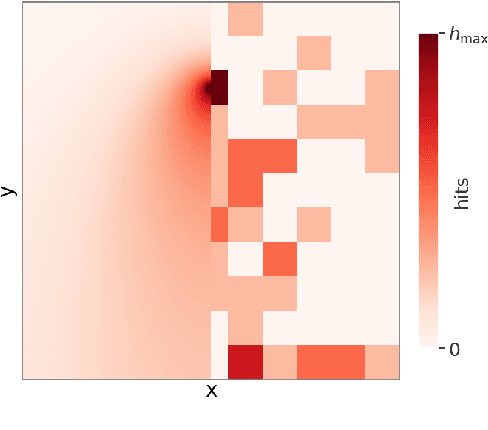
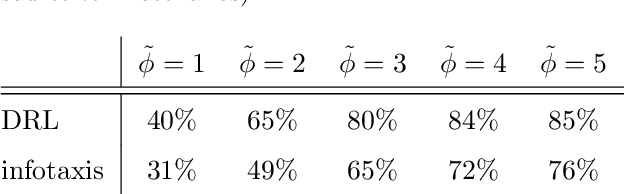
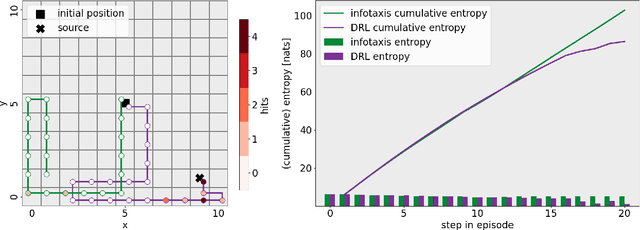
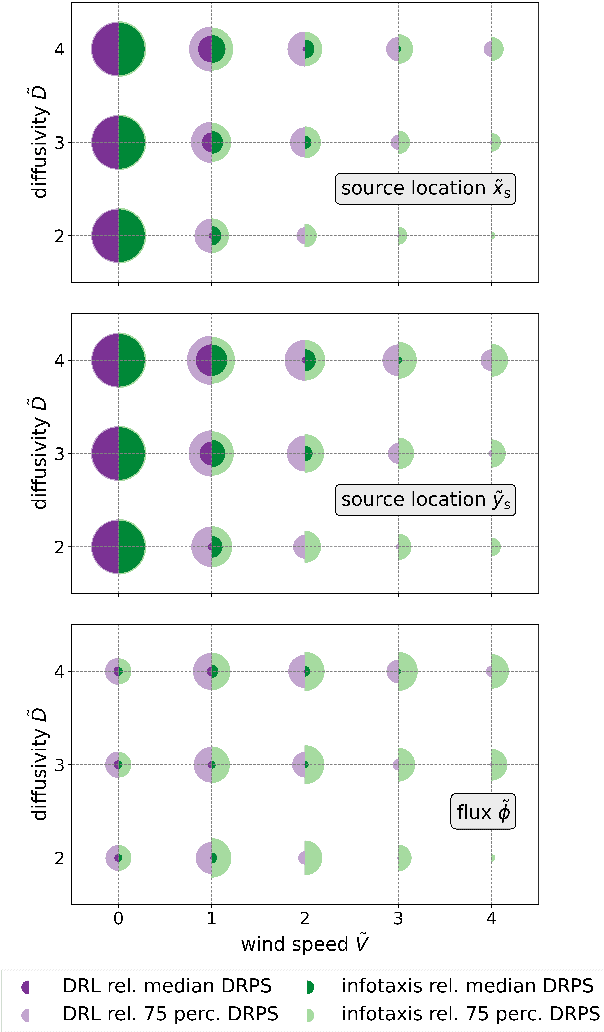
The accurate estimation of locations and emission rates of gas sources is crucial across various domains, including environmental monitoring and greenhouse gas emission analysis. This study investigates two drone sampling strategies for inferring source term parameters of gas plumes from atmospheric measurements. Both strategies are guided by the goal of maximizing information gain attained from observations at sequential locations. Our research compares the myopic approach of infotaxis to a far-sighted navigation strategy trained through deep reinforcement learning. We demonstrate the superior performance of deep reinforcement learning over infotaxis in environments with non-isotropic gas plumes.
Effective Acquisition Functions for Active Correlation Clustering
Feb 05, 2024Correlation clustering is a powerful unsupervised learning paradigm that supports positive and negative similarities. In this paper, we assume the similarities are not known in advance. Instead, we employ active learning to iteratively query similarities in a cost-efficient way. In particular, we develop three effective acquisition functions to be used in this setting. One is based on the notion of inconsistency (i.e., when similarities violate the transitive property). The remaining two are based on information-theoretic quantities, i.e., entropy and information gain.
Learning from Emotions, Demographic Information and Implicit User Feedback in Task-Oriented Document-Grounded Dialogues
Jan 17, 2024The success of task-oriented and document-grounded dialogue systems depends on users accepting and enjoying using them. To achieve this, recently published work in the field of Human-Computer Interaction suggests that the combination of considering demographic information, user emotions and learning from the implicit feedback in their utterances, is particularly important. However, these findings have not yet been transferred to the field of Natural Language Processing, where these data are primarily studied separately. Accordingly, no sufficiently annotated dataset is available. To address this gap, we introduce FEDI, the first English dialogue dataset for task-oriented document-grounded dialogues annotated with demographic information, user emotions and implicit feedback. Our experiments with FLAN-T5, GPT-2 and LLaMA-2 show that these data have the potential to improve task completion and the factual consistency of the generated responses and user acceptance.