 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Latent Space Explanation by Intervention
Dec 09, 2021
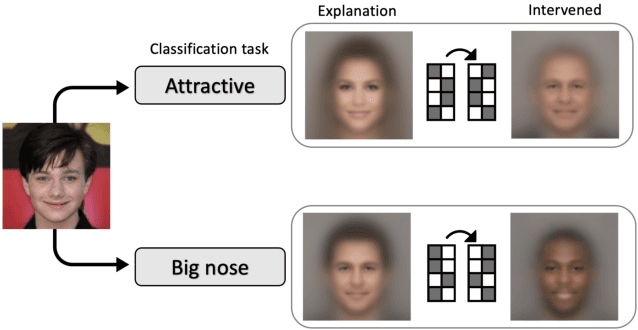
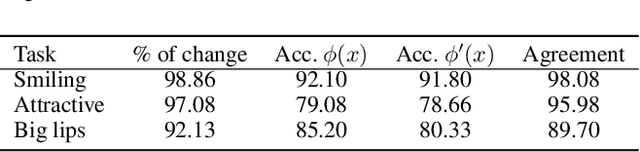
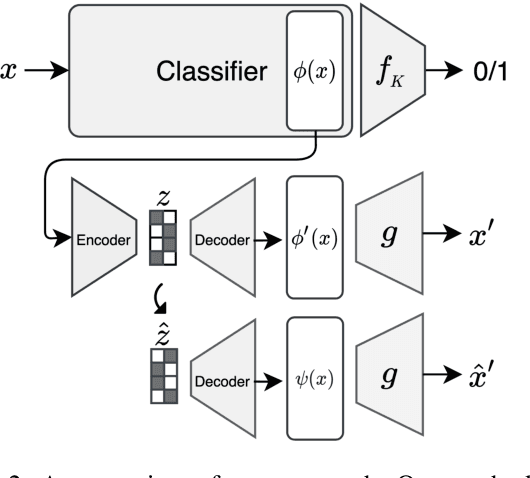

The success of deep neural nets heavily relies on their ability to encode complex relations between their input and their output. While this property serves to fit the training data well, it also obscures the mechanism that drives prediction. This study aims to reveal hidden concepts by employing an intervention mechanism that shifts the predicted class based on discrete variational autoencoders. An explanatory model then visualizes the encoded information from any hidden layer and its corresponding intervened representation. By the assessment of differences between the original representation and the intervened representation, one can determine the concepts that can alter the class, hence providing interpretability. We demonstrate the effectiveness of our approach on CelebA, where we show various visualizations for bias in the data and suggest different interventions to reveal and change bias.
Neural Content Extraction for Poster Generation of Scientific Papers
Dec 16, 2021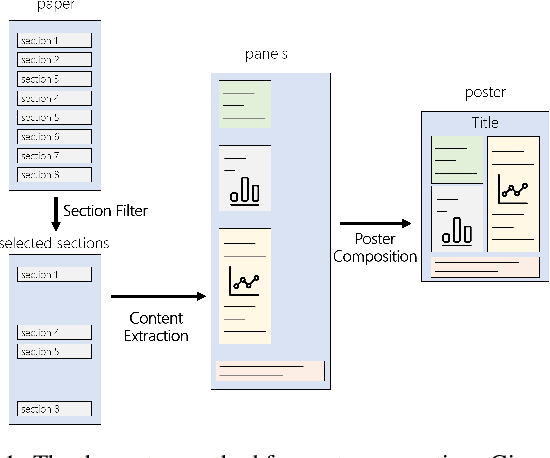


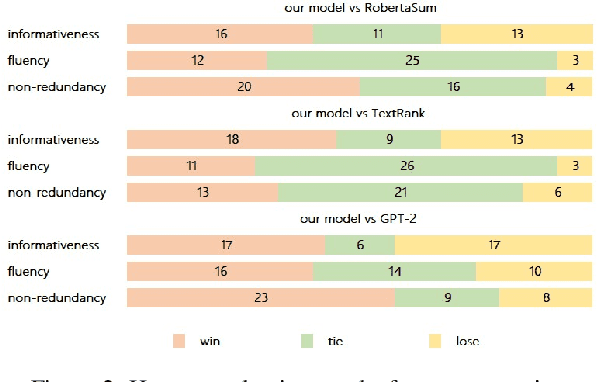
The problem of poster generation for scientific papers is under-investigated. Posters often present the most important information of papers, and the task can be considered as a special form of document summarization. Previous studies focus mainly on poster layout and panel composition, while neglecting the importance of content extraction. Besides, their datasets are not publicly available, which hinders further research. In this paper, we construct a benchmark dataset from scratch for this task. Then we propose a three-step framework to tackle this task and focus on the content extraction step in this study. To get both textual and visual elements of a poster panel, a neural extractive model is proposed to extract text, figures and tables of a paper section simultaneously. We conduct experiments on the dataset and also perform ablation study. Results demonstrate the efficacy of our proposed model. The dataset and code will be released.
Track Boosting and Synthetic Data Aided Drone Detection
Nov 24, 2021
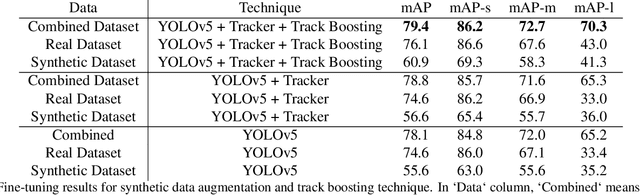

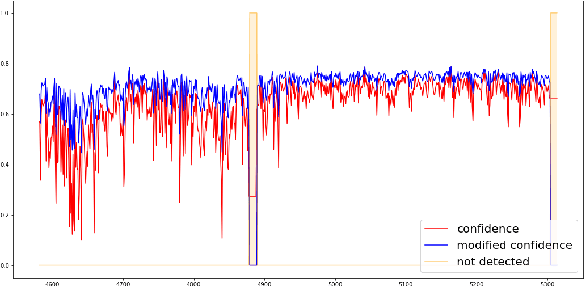
As the usage of drones increases with lowered costs and improved drone technology, drone detection emerges as a vital object detection task. However, detecting distant drones under unfavorable conditions, namely weak contrast, long-range, low visibility, requires effective algorithms. Our method approaches the drone detection problem by fine-tuning a YOLOv5 model with real and synthetically generated data using a Kalman-based object tracker to boost detection confidence. Our results indicate that augmenting the real data with an optimal subset of synthetic data can increase the performance. Moreover, temporal information gathered by object tracking methods can increase performance further.
Inferring Turbulent Parameters via Machine Learning
Jan 03, 2022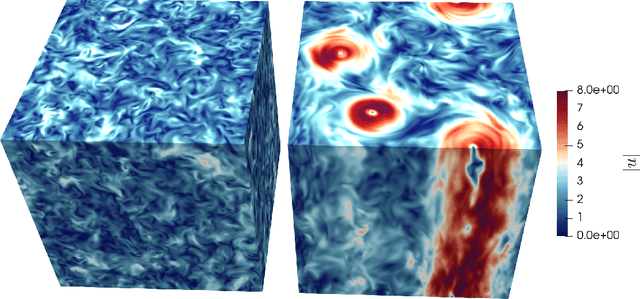
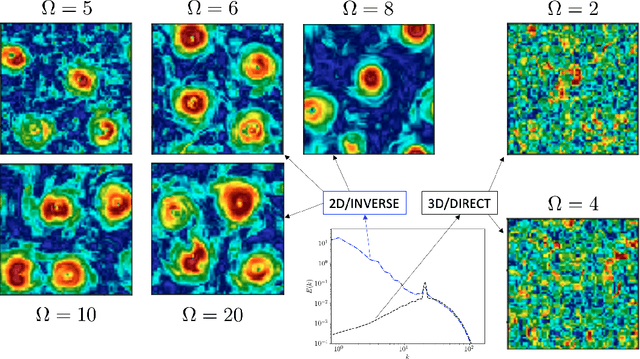
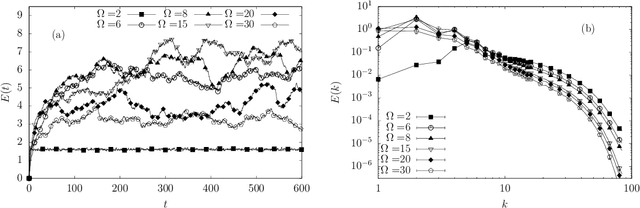
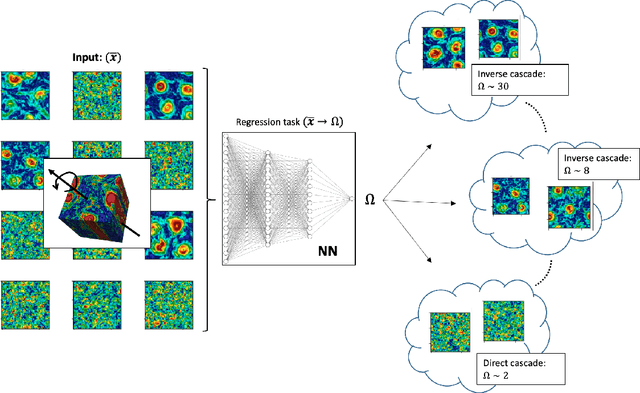
We design a machine learning technique to solve the general problem of inferring physical parameters from the observation of turbulent flows, a relevant exercise in many theoretical and applied fields, from engineering to earth observation and astrophysics. Our approach is to train the machine learning system to regress the rotation frequency of the flow's reference frame, from the observation of the flow's velocity amplitude on a 2d plane extracted from the 3d domain. The machine learning approach consists of a Deep Convolutional Neural Network (DCNN) of the same kind developed in computer vision. The training and validation datasets are produced by means of fully resolved direct numerical simulations. This study shows interesting results from two different points of view. From the machine learning point of view it shows the potential of DCNN, reaching good results on such a particularly complex problem that goes well outside the limits of human vision. Second, from the physics point of view, it provides an example on how machine learning can be exploited in data analysis to infer information that would be inaccessible otherwise. Indeed, by comparing DCNN with the other possible Bayesian approaches, we find that DCNN yields to a much higher inference accuracy in all the examined cases.
Trees in transformers: a theoretical analysis of the Transformer's ability to represent trees
Dec 16, 2021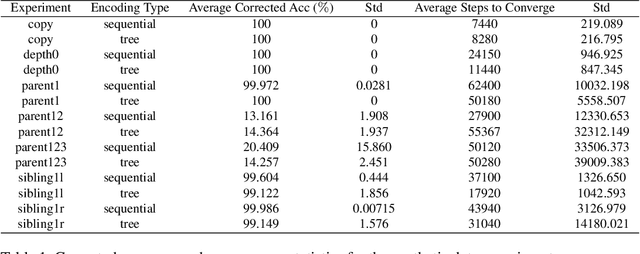
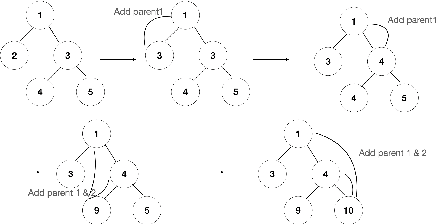
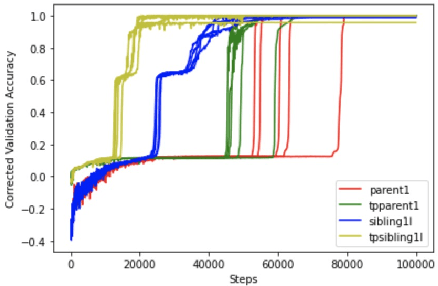
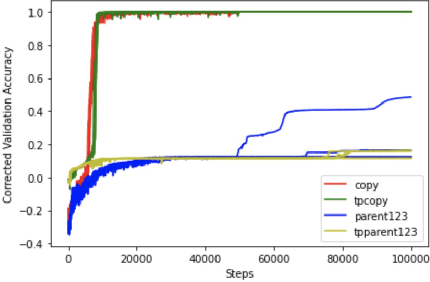
Transformer networks are the de facto standard architecture in natural language processing. To date, there are no theoretical analyses of the Transformer's ability to capture tree structures. We focus on the ability of Transformer networks to learn tree structures that are important for tree transduction problems. We first analyze the theoretical capability of the standard Transformer architecture to learn tree structures given enumeration of all possible tree backbones, which we define as trees without labels. We then prove that two linear layers with ReLU activation function can recover any tree backbone from any two nonzero, linearly independent starting backbones. This implies that a Transformer can learn tree structures well in theory. We conduct experiments with synthetic data and find that the standard Transformer achieves similar accuracy compared to a Transformer where tree position information is explicitly encoded, albeit with slower convergence. This confirms empirically that Transformers can learn tree structures.
Multi-view Data Classification with a Label-driven Auto-weighted Strategy
Jan 03, 2022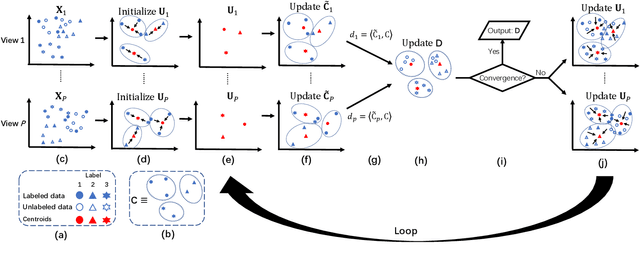
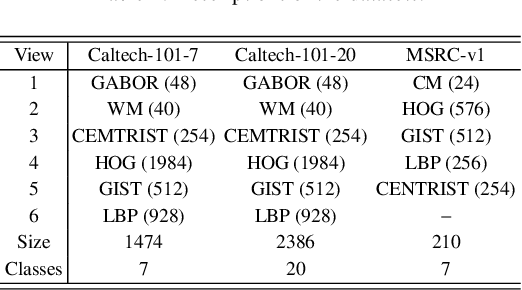
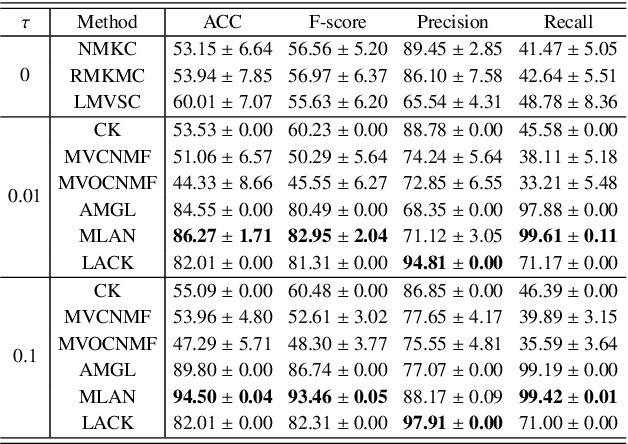
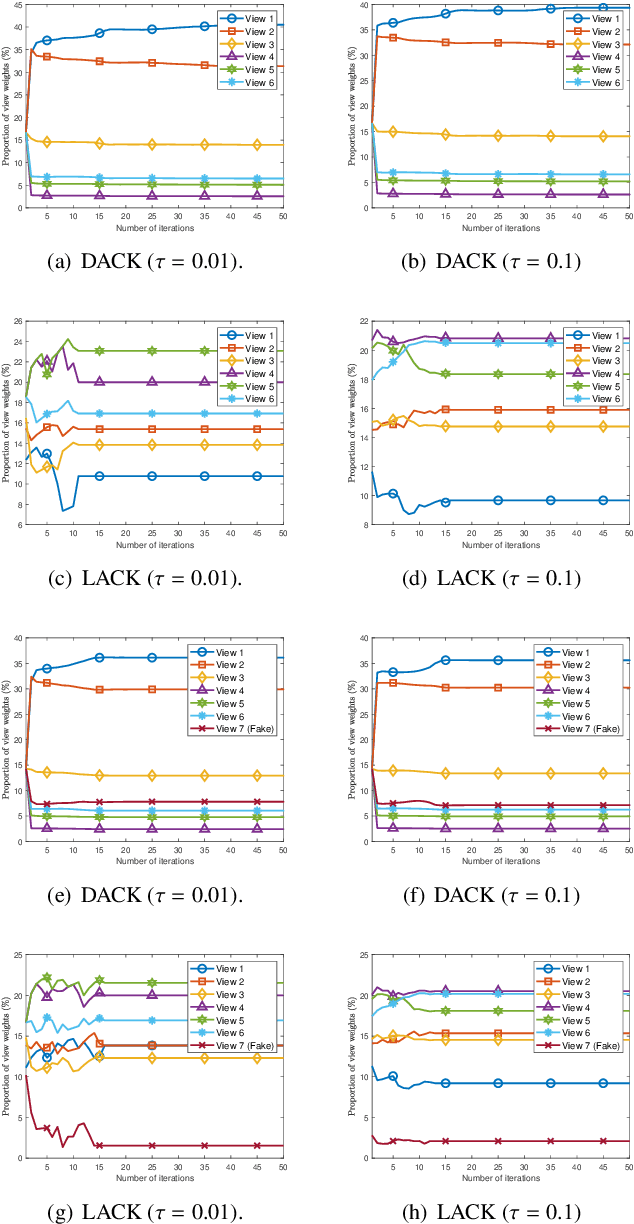
Distinguishing the importance of views has proven to be quite helpful for semi-supervised multi-view learning models. However, existing strategies cannot take advantage of semi-supervised information, only distinguishing the importance of views from a data feature perspective, which is often influenced by low-quality views then leading to poor performance. In this paper, by establishing a link between labeled data and the importance of different views, we propose an auto-weighted strategy to evaluate the importance of views from a label perspective to avoid the negative impact of unimportant or low-quality views. Based on this strategy, we propose a transductive semi-supervised auto-weighted multi-view classification model. The initialization of the proposed model can be effectively determined by labeled data, which is practical. The model is decoupled into three small-scale sub-problems that can efficiently be optimized with a local convergence guarantee. The experimental results on classification tasks show that the proposed method achieves optimal or sub-optimal classification accuracy at the lowest computational cost compared to other related methods, and the weight change experiments show that our proposed strategy can distinguish view importance more accurately than other related strategies on multi-view datasets with low-quality views.
FaSS-MVS -- Fast Multi-View Stereo with Surface-Aware Semi-Global Matching from UAV-borne Monocular Imagery
Dec 01, 2021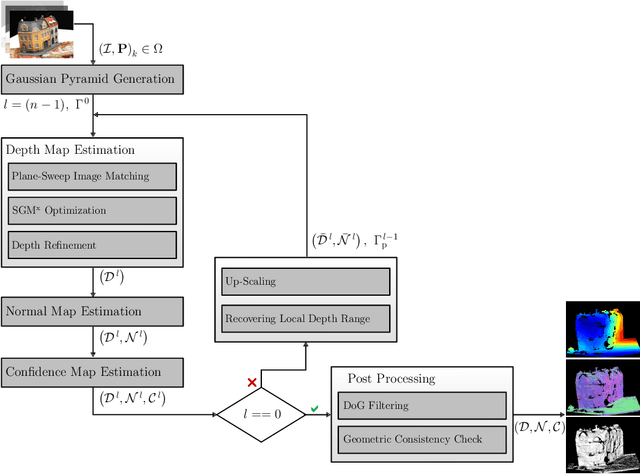
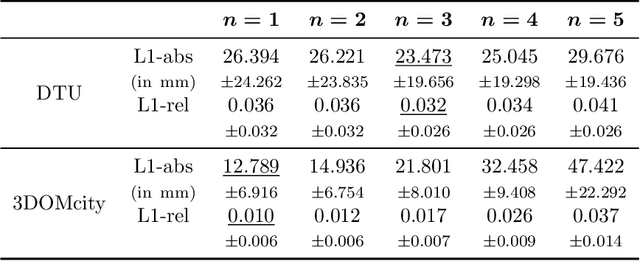
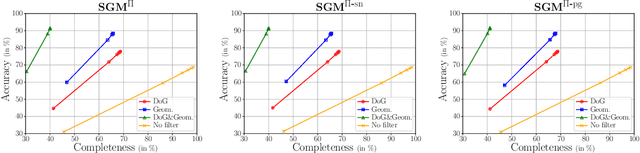
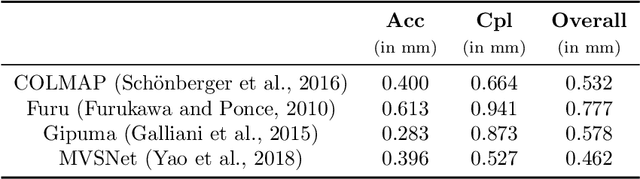
With FaSS-MVS, we present an approach for fast multi-view stereo with surface-aware Semi-Global Matching that allows for rapid depth and normal map estimation from monocular aerial video data captured by UAVs. The data estimated by FaSS-MVS, in turn, facilitates online 3D mapping, meaning that a 3D map of the scene is immediately and incrementally generated while the image data is acquired or being received. FaSS-MVS is comprised of a hierarchical processing scheme in which depth and normal data, as well as corresponding confidence scores, are estimated in a coarse-to-fine manner, allowing to efficiently process large scene depths which are inherent to oblique imagery captured by low-flying UAVs. The actual depth estimation employs a plane-sweep algorithm for dense multi-image matching to produce depth hypotheses from which the actual depth map is extracted by means of a surface-aware semi-global optimization, reducing the fronto-parallel bias of SGM. Given the estimated depth map, the pixel-wise surface normal information is then computed by reprojecting the depth map into a point cloud and calculating the normal vectors within a confined local neighborhood. In a thorough quantitative and ablative study we show that the accuracies of the 3D information calculated by FaSS-MVS is close to that of state-of-the-art approaches for offline multi-view stereo, with the error not even being one magnitude higher than that of COLMAP. At the same time, however, the average run-time of FaSS-MVS to estimate a single depth and normal map is less than 14 % of that of COLMAP, allowing to perform an online and incremental processing of Full-HD imagery at 1-2 Hz.
SimViT: Exploring a Simple Vision Transformer with sliding windows
Dec 24, 2021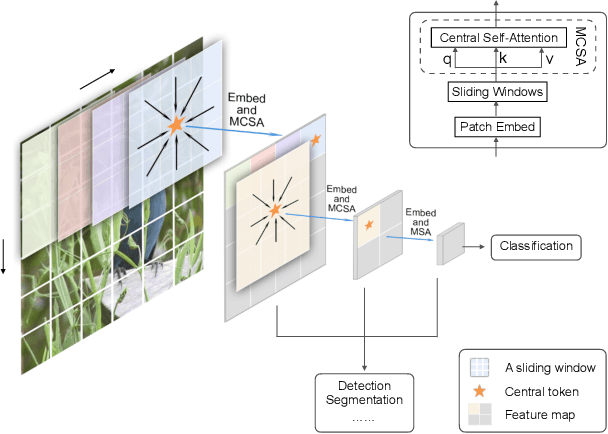
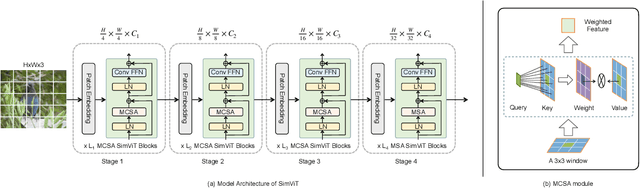
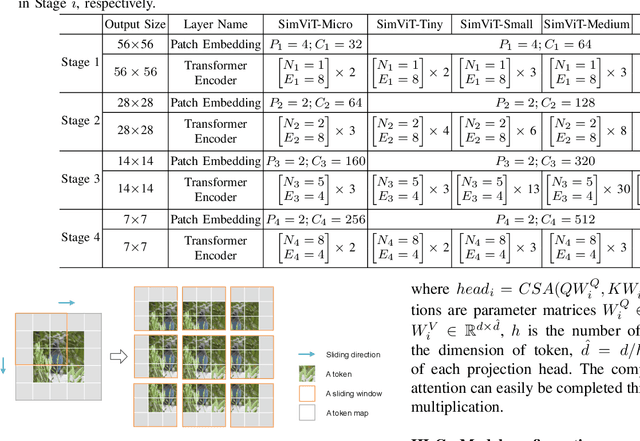
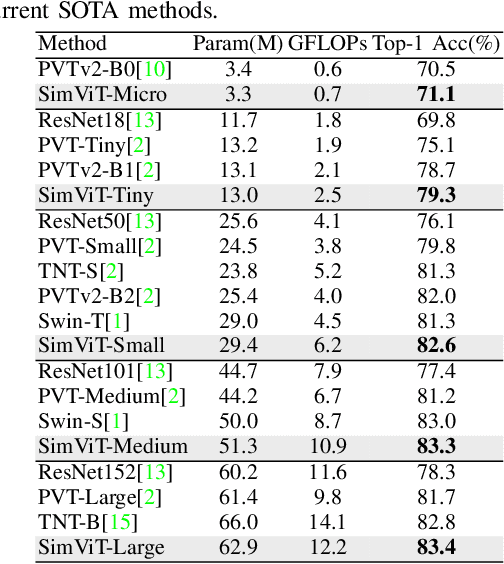
Although vision Transformers have achieved excellent performance as backbone models in many vision tasks, most of them intend to capture global relations of all tokens in an image or a window, which disrupts the inherent spatial and local correlations between patches in 2D structure. In this paper, we introduce a simple vision Transformer named SimViT, to incorporate spatial structure and local information into the vision Transformers. Specifically, we introduce Multi-head Central Self-Attention(MCSA) instead of conventional Multi-head Self-Attention to capture highly local relations. The introduction of sliding windows facilitates the capture of spatial structure. Meanwhile, SimViT extracts multi-scale hierarchical features from different layers for dense prediction tasks. Extensive experiments show the SimViT is effective and efficient as a general-purpose backbone model for various image processing tasks. Especially, our SimViT-Micro only needs 3.3M parameters to achieve 71.1% top-1 accuracy on ImageNet-1k dataset, which is the smallest size vision Transformer model by now. Our code will be available in https://github.com/ucasligang/SimViT.
Attention-based Bidirectional LSTM for Deceptive Opinion Spam Classification
Dec 29, 2021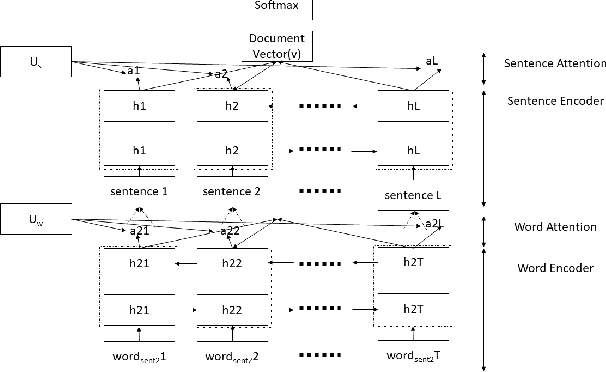
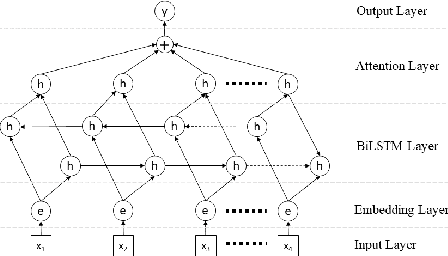
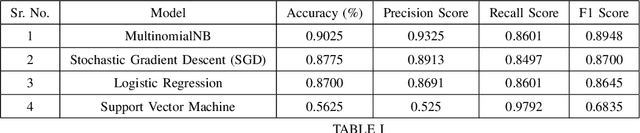
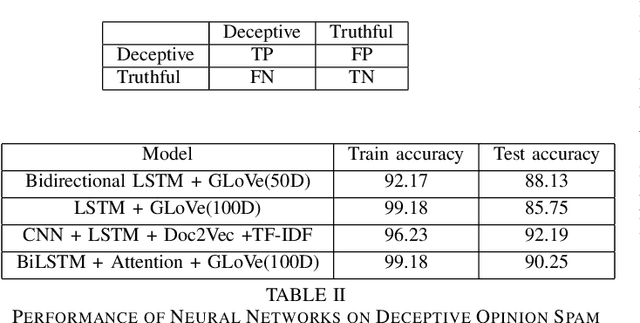
Online Reviews play a vital role in e commerce for decision making. Much of the population makes the decision of which places, restaurant to visit, what to buy and from where to buy based on the reviews posted on the respective platforms. A fraudulent review or opinion spam is categorized as an untruthful or deceptive review. Positive reviews of a product or a restaurant helps attract customers and thereby lead to an increase in sales whereas negative reviews may hamper the progress of a restaurant or sales of a product and thereby lead to defamed reputation and loss. Fraudulent reviews are deliberately posted on various online review platforms to trick customers to buy, visit or distract against a product or a restaurant. They are also written to commend or discredit the product's repute. The work aims at detecting and classifying the reviews as deceptive or truthful. It involves use of various deep learning techniques for classifying the reviews and an overview of proposed approach involving Attention based Bidirectional LSTM to tackle issues related to semantic information in reviews and a comparative study over baseline machine learning techniques for review classification.
ExClus: Explainable Clustering on Low-dimensional Data Representations
Nov 04, 2021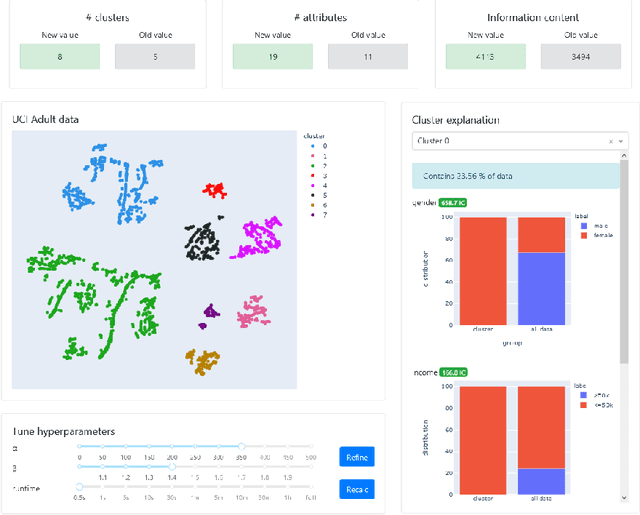
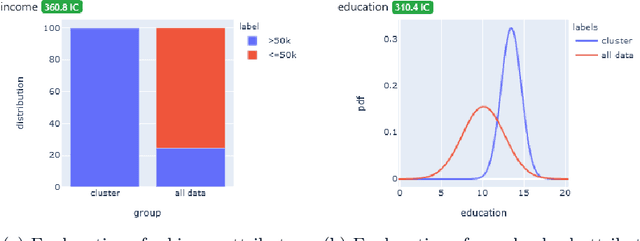
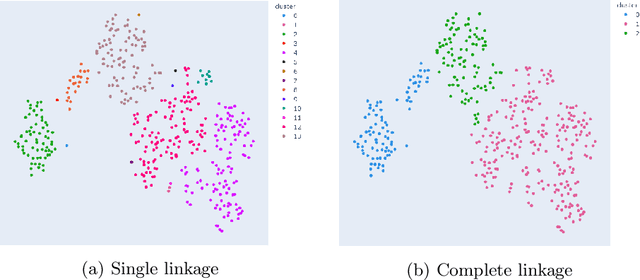
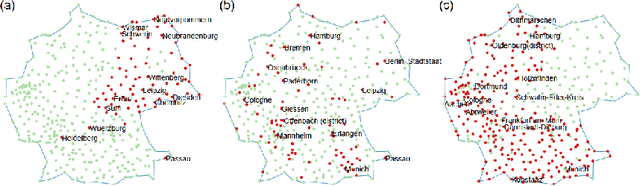
Dimensionality reduction and clustering techniques are frequently used to analyze complex data sets, but their results are often not easy to interpret. We consider how to support users in interpreting apparent cluster structure on scatter plots where the axes are not directly interpretable, such as when the data is projected onto a two-dimensional space using a dimensionality-reduction method. Specifically, we propose a new method to compute an interpretable clustering automatically, where the explanation is in the original high-dimensional space and the clustering is coherent in the low-dimensional projection. It provides a tunable balance between the complexity and the amount of information provided, through the use of information theory. We study the computational complexity of this problem and introduce restrictions on the search space of solutions to arrive at an efficient, tunable, greedy optimization algorithm. This algorithm is furthermore implemented in an interactive tool called ExClus. Experiments on several data sets highlight that ExClus can provide informative and easy-to-understand patterns, and they expose where the algorithm is efficient and where there is room for improvement considering tunability and scalability.