 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Combining Latent Space and Structured Kernels for Bayesian Optimization over Combinatorial Spaces
Nov 01, 2021
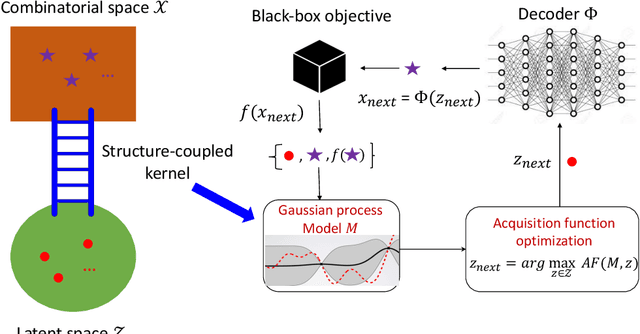
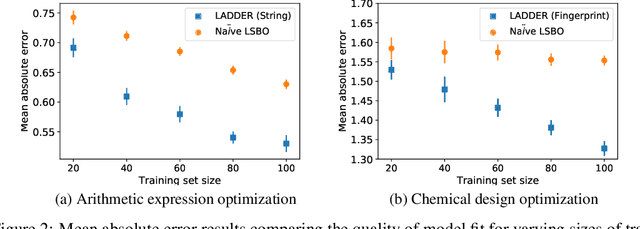
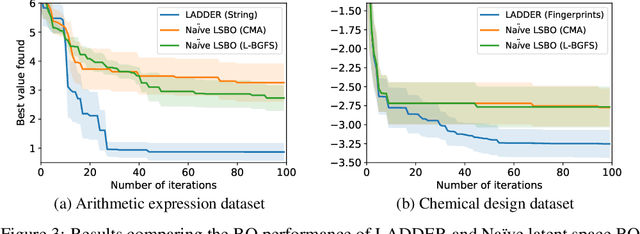
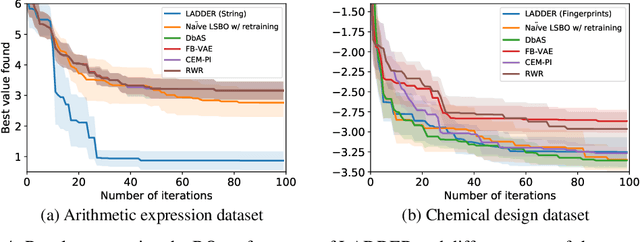
We consider the problem of optimizing combinatorial spaces (e.g., sequences, trees, and graphs) using expensive black-box function evaluations. For example, optimizing molecules for drug design using physical lab experiments. Bayesian optimization (BO) is an efficient framework for solving such problems by intelligently selecting the inputs with high utility guided by a learned surrogate model. A recent BO approach for combinatorial spaces is through a reduction to BO over continuous spaces by learning a latent representation of structures using deep generative models (DGMs). The selected input from the continuous space is decoded into a discrete structure for performing function evaluation. However, the surrogate model over the latent space only uses the information learned by the DGM, which may not have the desired inductive bias to approximate the target black-box function. To overcome this drawback, this paper proposes a principled approach referred as LADDER. The key idea is to define a novel structure-coupled kernel that explicitly integrates the structural information from decoded structures with the learned latent space representation for better surrogate modeling. Our experiments on real-world benchmarks show that LADDER significantly improves over the BO over latent space method, and performs better or similar to state-of-the-art methods.
Rebooting ACGAN: Auxiliary Classifier GANs with Stable Training
Nov 01, 2021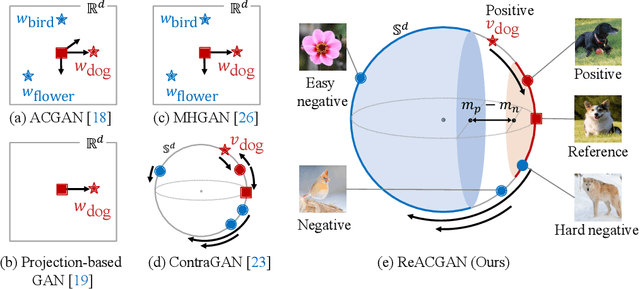
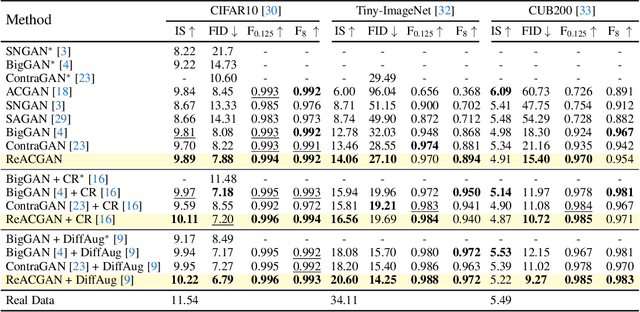
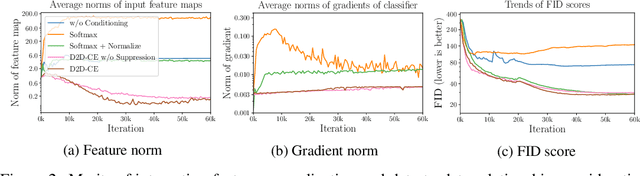
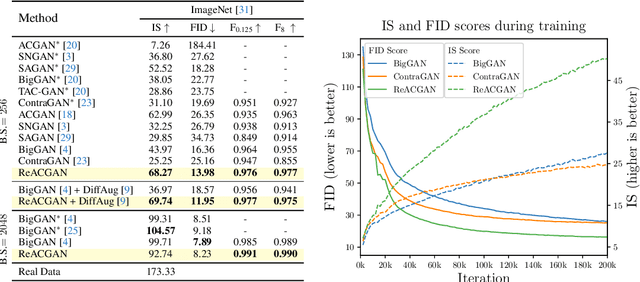
Conditional Generative Adversarial Networks (cGAN) generate realistic images by incorporating class information into GAN. While one of the most popular cGANs is an auxiliary classifier GAN with softmax cross-entropy loss (ACGAN), it is widely known that training ACGAN is challenging as the number of classes in the dataset increases. ACGAN also tends to generate easily classifiable samples with a lack of diversity. In this paper, we introduce two cures for ACGAN. First, we identify that gradient exploding in the classifier can cause an undesirable collapse in early training, and projecting input vectors onto a unit hypersphere can resolve the problem. Second, we propose the Data-to-Data Cross-Entropy loss (D2D-CE) to exploit relational information in the class-labeled dataset. On this foundation, we propose the Rebooted Auxiliary Classifier Generative Adversarial Network (ReACGAN). The experimental results show that ReACGAN achieves state-of-the-art generation results on CIFAR10, Tiny-ImageNet, CUB200, and ImageNet datasets. We also verify that ReACGAN benefits from differentiable augmentations and that D2D-CE harmonizes with StyleGAN2 architecture. Model weights and a software package that provides implementations of representative cGANs and all experiments in our paper are available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.
Direct then Diffuse: Incremental Unsupervised Skill Discovery for State Covering and Goal Reaching
Oct 27, 2021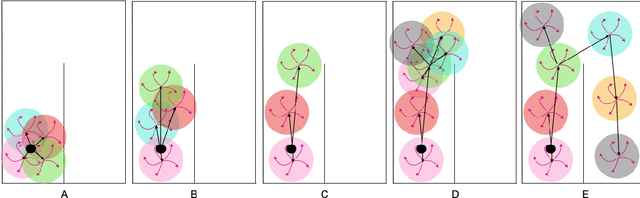
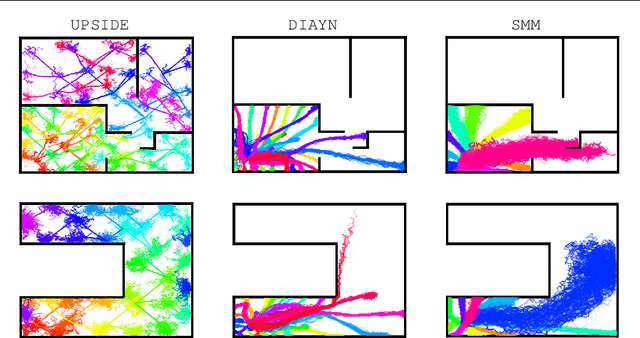
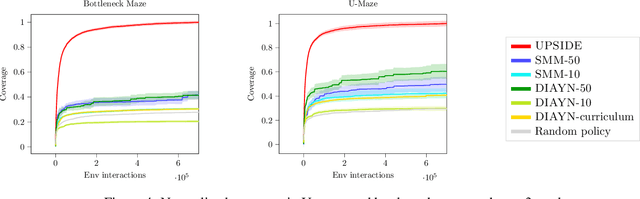
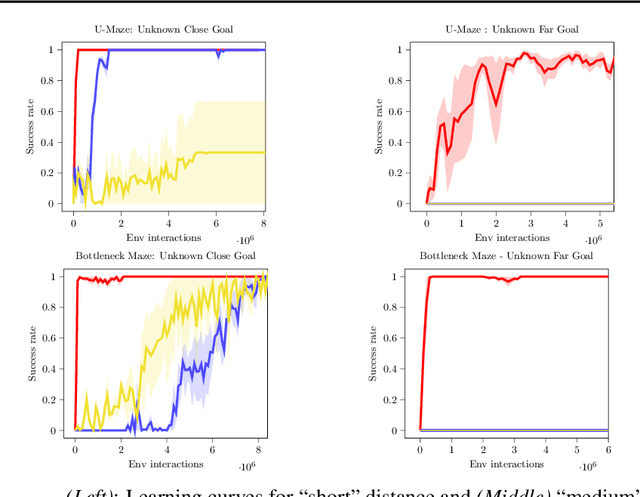
Learning meaningful behaviors in the absence of reward is a difficult problem in reinforcement learning. A desirable and challenging unsupervised objective is to learn a set of diverse skills that provide a thorough coverage of the state space while being directed, i.e., reliably reaching distinct regions of the environment. In this paper, we build on the mutual information framework for skill discovery and introduce UPSIDE, which addresses the coverage-directedness trade-off in the following ways: 1) We design policies with a decoupled structure of a directed skill, trained to reach a specific region, followed by a diffusing part that induces a local coverage. 2) We optimize policies by maximizing their number under the constraint that each of them reaches distinct regions of the environment (i.e., they are sufficiently discriminable) and prove that this serves as a lower bound to the original mutual information objective. 3) Finally, we compose the learned directed skills into a growing tree that adaptively covers the environment. We illustrate in several navigation and control environments how the skills learned by UPSIDE solve sparse-reward downstream tasks better than existing baselines.
Learning Target-aware Representation for Visual Tracking via Informative Interactions
Jan 07, 2022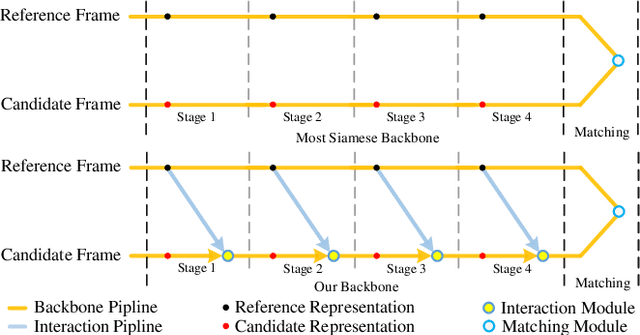
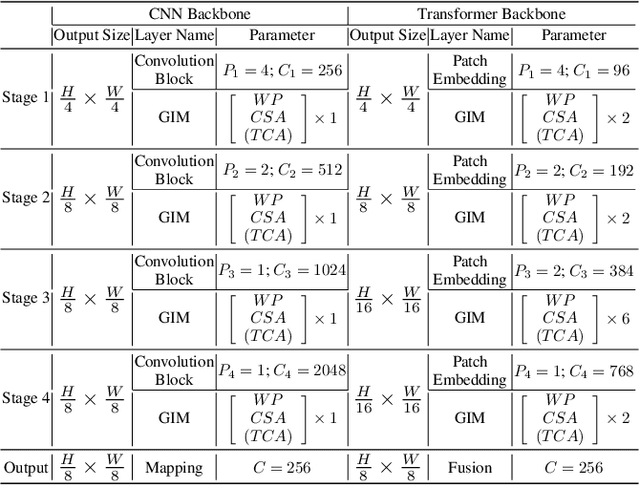
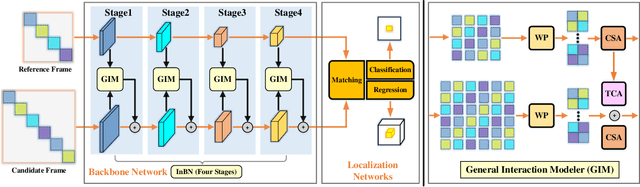
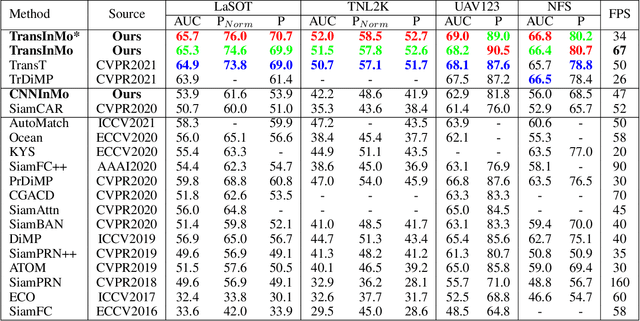
We introduce a novel backbone architecture to improve target-perception ability of feature representation for tracking. Specifically, having observed that de facto frameworks perform feature matching simply using the outputs from backbone for target localization, there is no direct feedback from the matching module to the backbone network, especially the shallow layers. More concretely, only the matching module can directly access the target information (in the reference frame), while the representation learning of candidate frame is blind to the reference target. As a consequence, the accumulation effect of target-irrelevant interference in the shallow stages may degrade the feature quality of deeper layers. In this paper, we approach the problem from a different angle by conducting multiple branch-wise interactions inside the Siamese-like backbone networks (InBN). At the core of InBN is a general interaction modeler (GIM) that injects the prior knowledge of reference image to different stages of the backbone network, leading to better target-perception and robust distractor-resistance of candidate feature representation with negligible computation cost. The proposed GIM module and InBN mechanism are general and applicable to different backbone types including CNN and Transformer for improvements, as evidenced by our extensive experiments on multiple benchmarks. In particular, the CNN version (based on SiamCAR) improves the baseline with 3.2/6.9 absolute gains of SUC on LaSOT/TNL2K, respectively. The Transformer version obtains SUC scores of 65.7/52.0 on LaSOT/TNL2K, which are on par with recent state of the arts. Code and models will be released.
Patent Sentiment Analysis to Highlight Patent Paragraphs
Nov 06, 2021
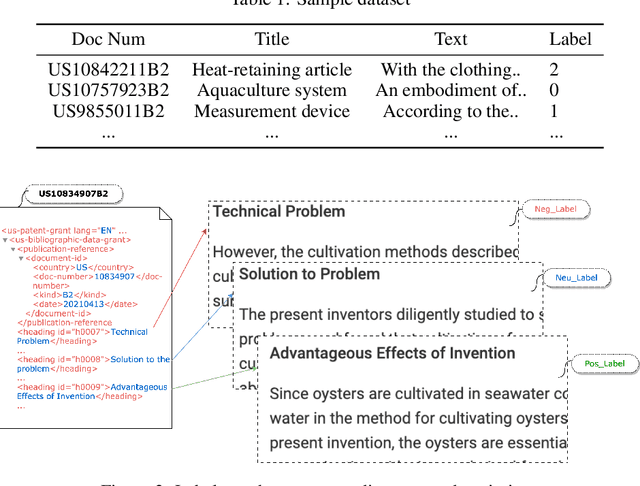
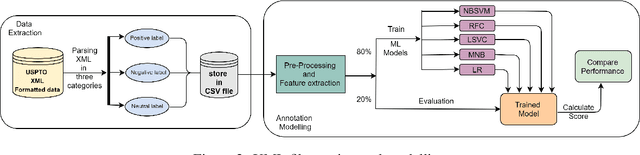
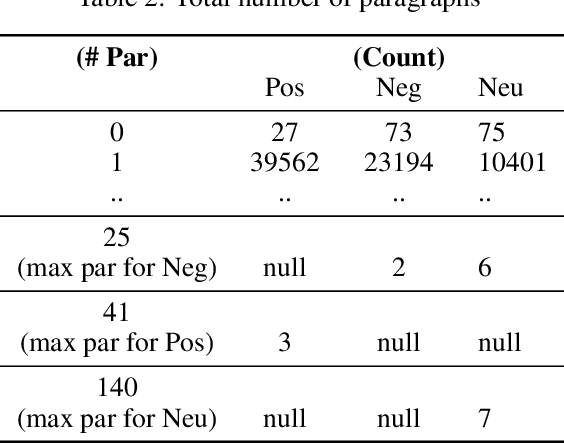
Given a patent document, identifying distinct semantic annotations is an interesting research aspect. Text annotation helps the patent practitioners such as examiners and patent attorneys to quickly identify the key arguments of any invention, successively providing a timely marking of a patent text. In the process of manual patent analysis, to attain better readability, recognising the semantic information by marking paragraphs is in practice. This semantic annotation process is laborious and time-consuming. To alleviate such a problem, we proposed a novel dataset to train Machine Learning algorithms to automate the highlighting process. The contributions of this work are: i) we developed a multi-class, novel dataset of size 150k samples by traversing USPTO patents over a decade, ii) articulated statistics and distributions of data using imperative exploratory data analysis, iii) baseline Machine Learning models are developed to utilize the dataset to address patent paragraph highlighting task, iv) dataset and codes relating to this task are open-sourced through a dedicated GIT web page: https://github.com/Renuk9390/Patent_Sentiment_Analysis and v) future path to extend this work using Deep Learning and domain specific pre-trained language models to develop a tool to highlight is provided. This work assist patent practitioners in highlighting semantic information automatically and aid to create a sustainable and efficient patent analysis using the aptitude of Machine Learning.
Understanding Procedural Knowledge by Sequencing Multimodal Instructional Manuals
Oct 16, 2021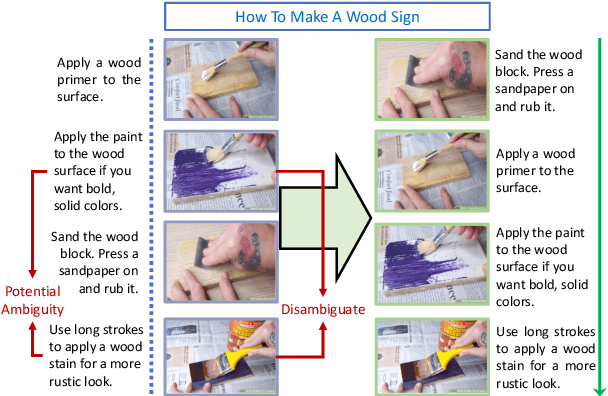
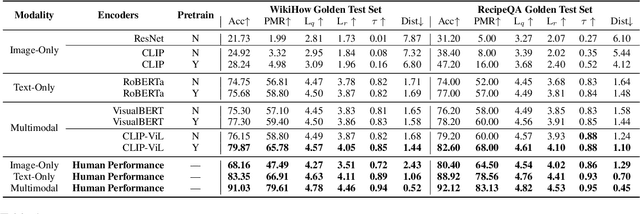
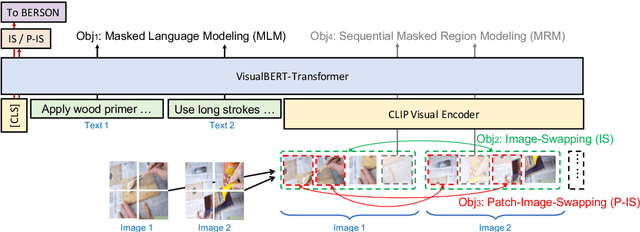

The ability to sequence unordered events is an essential skill to comprehend and reason about real world task procedures, which often requires thorough understanding of temporal common sense and multimodal information, as these procedures are often communicated through a combination of texts and images. Such capability is essential for applications such as sequential task planning and multi-source instruction summarization. While humans are capable of reasoning about and sequencing unordered multimodal procedural instructions, whether current machine learning models have such essential capability is still an open question. In this work, we benchmark models' capability of reasoning over and sequencing unordered multimodal instructions by curating datasets from popular online instructional manuals and collecting comprehensive human annotations. We find models not only perform significantly worse than humans but also seem incapable of efficiently utilizing the multimodal information. To improve machines' performance on multimodal event sequencing, we propose sequentiality-aware pretraining techniques that exploit the sequential alignment properties of both texts and images, resulting in > 5% significant improvements.
Adverse Media Mining for KYC and ESG Compliance
Oct 22, 2021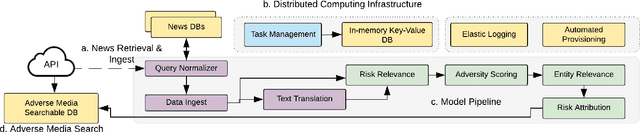
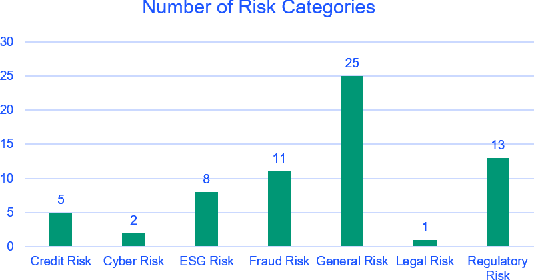
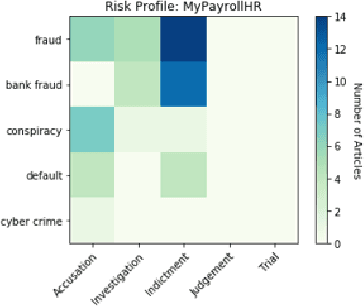
In recent years, institutions operating in the global market economy face growing risks stemming from non-financial risk factors such as cyber, third-party, and reputational outweighing traditional risks of credit and liquidity. Adverse media or negative news screening is crucial for the identification of such non-financial risks. Typical tools for screening are not real-time, involve manual searches, require labor-intensive monitoring of information sources. Moreover, they are costly processes to maintain up-to-date with complex regulatory requirements and the institution's evolving risk appetite. In this extended abstract, we present an automated system to conduct both real-time and batch search of adverse media for users' queries (person or organization entities) using news and other open-source, unstructured sources of information. Our scalable, machine-learning driven approach to high-precision, adverse news filtering is based on four perspectives - relevance to risk domains, search query (entity) relevance, adverse sentiment analysis, and risk encoding. With the help of model evaluations and case studies, we summarize the performance of our deployed application.
Spectral Transform Forms Scalable Transformer
Nov 15, 2021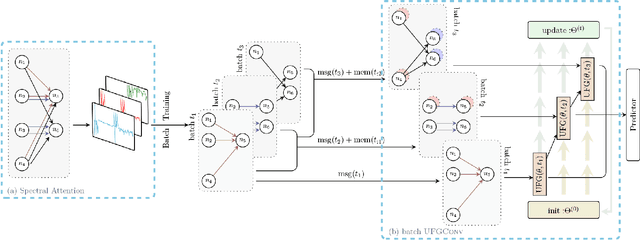
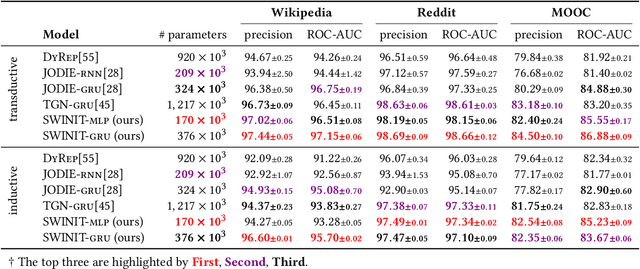
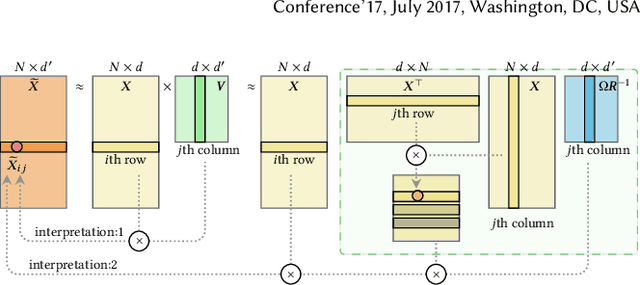
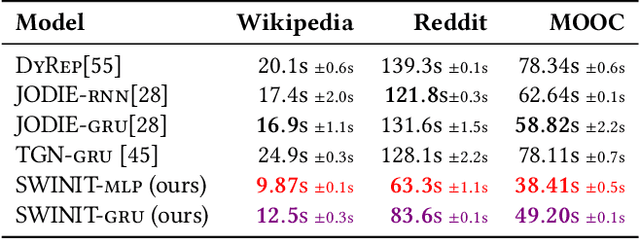
Many real-world relational systems, such as social networks and biological systems, contain dynamic interactions. When learning dynamic graph representation, it is essential to employ sequential temporal information and geometric structure. Mainstream work achieves topological embedding via message passing networks (e.g., GCN, GAT). The temporal evolution, on the other hand, is conventionally expressed via memory units (e.g., LSTM or GRU) that possess convenient information filtration in a gate mechanism. Though, such a design prevents large-scale input sequence due to the over-complicated encoding. This work learns from the philosophy of self-attention and proposes an efficient spectral-based neural unit that employs informative long-range temporal interaction. The developed spectral window unit (SWINIT) model predicts scalable dynamic graphs with assured efficiency. The architecture is assembled with a few simple effective computational blocks that constitute randomized SVD, MLP, and graph Framelet convolution. The SVD plus MLP module encodes the long-short-term feature evolution of the dynamic graph events. A fast framelet graph transform in the framelet convolution embeds the structural dynamics. Both strategies enhance the model's ability on scalable analysis. In particular, the iterative SVD approximation shrinks the computational complexity of attention to O(Nd\log(d)) for the dynamic graph with N edges and d edge features, and the multiscale transform of framelet convolution allows sufficient scalability in the network training. Our SWINIT achieves state-of-the-art performance on a variety of online continuous-time dynamic graph learning tasks, while compared to baseline methods, the number of its learnable parameters reduces by up to seven times.
M-FasterSeg: An Efficient Semantic Segmentation Network Based on Neural Architecture Search
Dec 30, 2021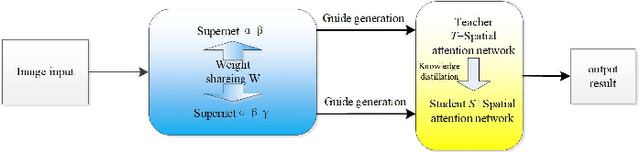
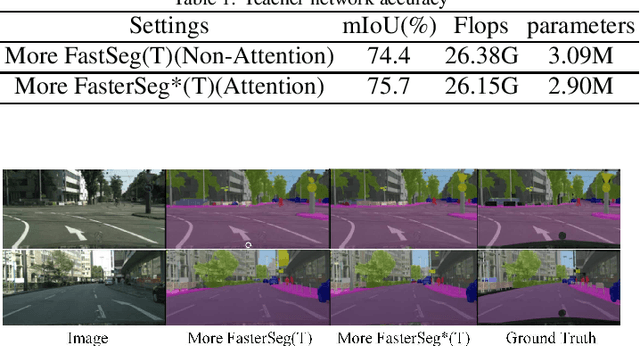
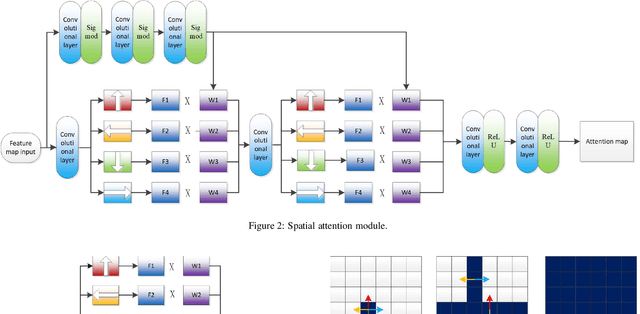
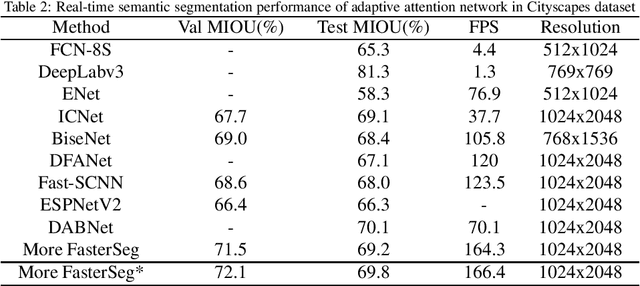
Image semantic segmentation technology is one of the key technologies for intelligent systems to understand natural scenes. As one of the important research directions in the field of visual intelligence, this technology has broad application scenarios in the fields of mobile robots, drones, smart driving, and smart security. However, in the actual application of mobile robots, problems such as inaccurate segmentation semantic label prediction and loss of edge information of segmented objects and background may occur. This paper proposes an improved structure of a semantic segmentation network based on a deep learning network that combines self-attention neural network and neural network architecture search methods. First, a neural network search method NAS (Neural Architecture Search) is used to find a semantic segmentation network with multiple resolution branches. In the search process, combine the self-attention network structure module to adjust the searched neural network structure, and then combine the semantic segmentation network searched by different branches to form a fast semantic segmentation network structure, and input the picture into the network structure to get the final forecast result. The experimental results on the Cityscapes dataset show that the accuracy of the algorithm is 69.8%, and the segmentation speed is 48/s. It achieves a good balance between real-time and accuracy, can optimize edge segmentation, and has a better performance in complex scenes. Good robustness is suitable for practical application.
CamLessMonoDepth: Monocular Depth Estimation with Unknown Camera Parameters
Oct 27, 2021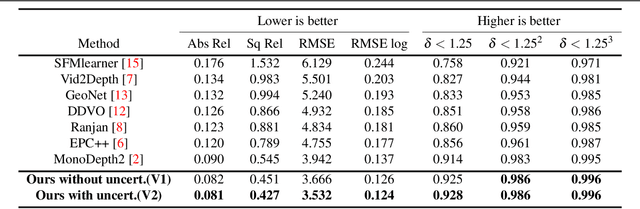
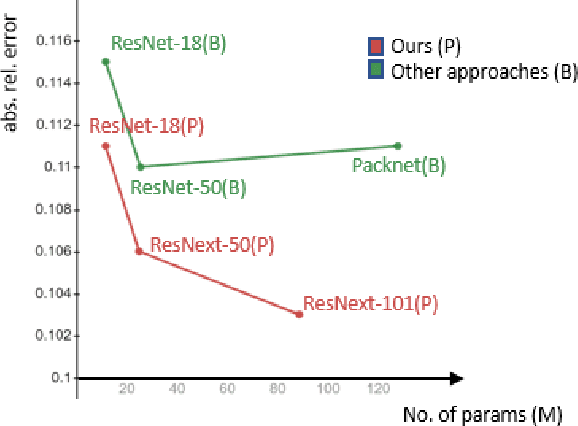
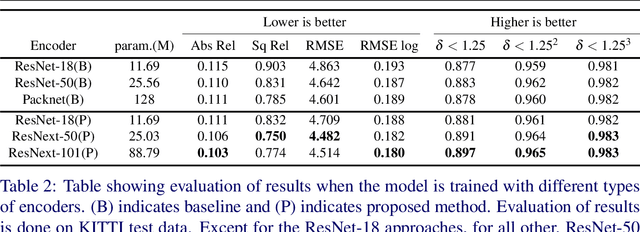
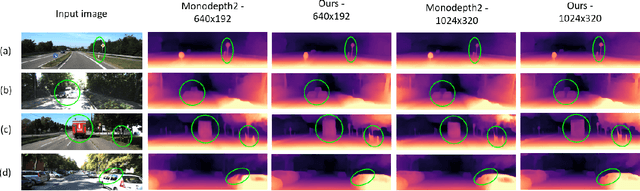
Perceiving 3D information is of paramount importance in many applications of computer vision. Recent advances in monocular depth estimation have shown that gaining such knowledge from a single camera input is possible by training deep neural networks to predict inverse depth and pose, without the necessity of ground truth data. The majority of such approaches, however, require camera parameters to be fed explicitly during training. As a result, image sequences from wild cannot be used during training. While there exist methods which also predict camera intrinsics, their performance is not on par with novel methods taking camera parameters as input. In this work, we propose a method for implicit estimation of pinhole camera intrinsics along with depth and pose, by learning from monocular image sequences alone. In addition, by utilizing efficient sub-pixel convolutions, we show that high fidelity depth estimates can be obtained. We also embed pixel-wise uncertainty estimation into the framework, to emphasize the possible applicability of this work in practical domain. Finally, we demonstrate the possibility of accurate prediction of depth information without prior knowledge of camera intrinsics, while outperforming the existing state-of-the-art approaches on KITTI benchmark.