 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Soft-Output Joint Channel Estimation and Data Detection using Deep Unfolding
Dec 01, 2021

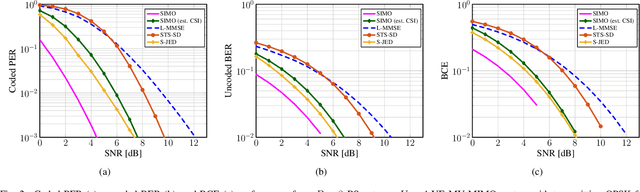
We propose a novel soft-output joint channel estimation and data detection (JED) algorithm for multiuser (MU) multiple-input multiple-output (MIMO) wireless communication systems. Our algorithm approximately solves a maximum a-posteriori JED optimization problem using deep unfolding and generates soft-output information for the transmitted bits in every iteration. The parameters of the unfolded algorithm are computed by a hyper-network that is trained with a binary cross entropy (BCE) loss. We evaluate the performance of our algorithm in a coded MU-MIMO system with 8 basestation antennas and 4 user equipments and compare it to state-of-the-art algorithms separate channel estimation from soft-output data detection. Our results demonstrate that our JED algorithm outperforms such data detectors with as few as 10 iterations.
Understanding Procedural Knowledge by Sequencing Multimodal Instructional Manuals
Oct 16, 2021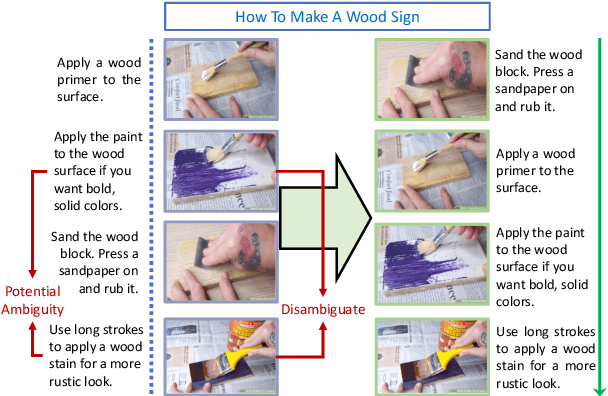
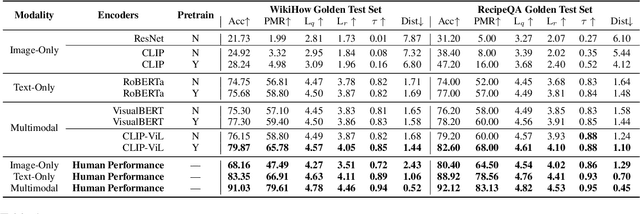
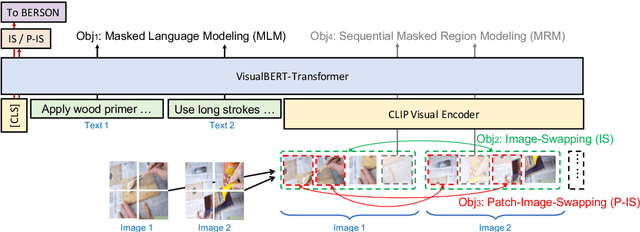

The ability to sequence unordered events is an essential skill to comprehend and reason about real world task procedures, which often requires thorough understanding of temporal common sense and multimodal information, as these procedures are often communicated through a combination of texts and images. Such capability is essential for applications such as sequential task planning and multi-source instruction summarization. While humans are capable of reasoning about and sequencing unordered multimodal procedural instructions, whether current machine learning models have such essential capability is still an open question. In this work, we benchmark models' capability of reasoning over and sequencing unordered multimodal instructions by curating datasets from popular online instructional manuals and collecting comprehensive human annotations. We find models not only perform significantly worse than humans but also seem incapable of efficiently utilizing the multimodal information. To improve machines' performance on multimodal event sequencing, we propose sequentiality-aware pretraining techniques that exploit the sequential alignment properties of both texts and images, resulting in > 5% significant improvements.
Direct then Diffuse: Incremental Unsupervised Skill Discovery for State Covering and Goal Reaching
Oct 27, 2021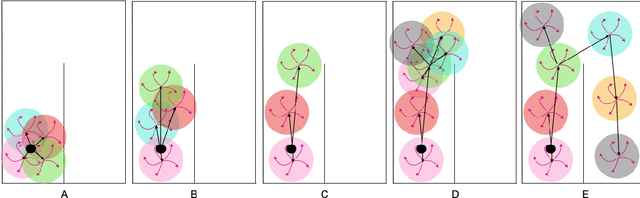
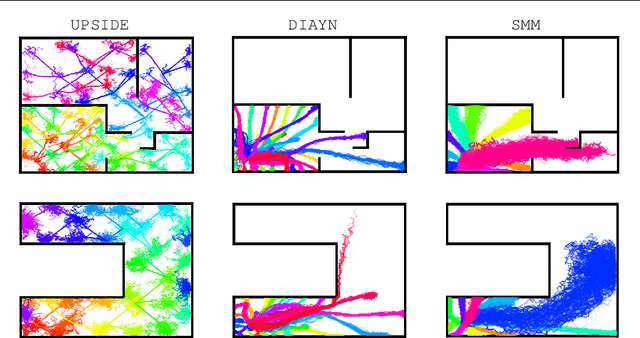
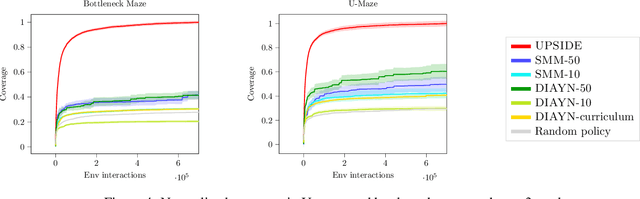
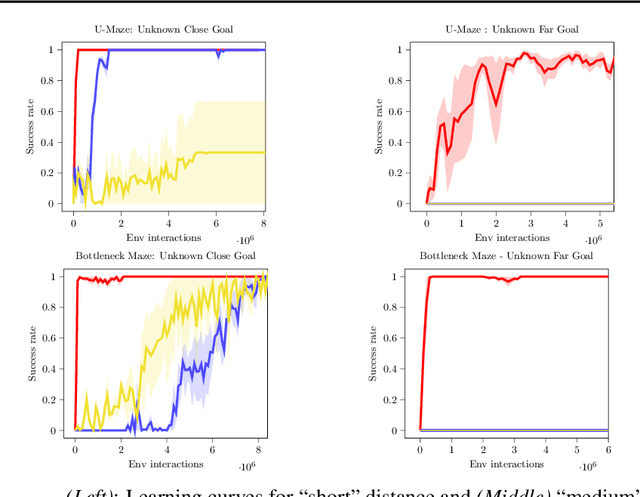
Learning meaningful behaviors in the absence of reward is a difficult problem in reinforcement learning. A desirable and challenging unsupervised objective is to learn a set of diverse skills that provide a thorough coverage of the state space while being directed, i.e., reliably reaching distinct regions of the environment. In this paper, we build on the mutual information framework for skill discovery and introduce UPSIDE, which addresses the coverage-directedness trade-off in the following ways: 1) We design policies with a decoupled structure of a directed skill, trained to reach a specific region, followed by a diffusing part that induces a local coverage. 2) We optimize policies by maximizing their number under the constraint that each of them reaches distinct regions of the environment (i.e., they are sufficiently discriminable) and prove that this serves as a lower bound to the original mutual information objective. 3) Finally, we compose the learned directed skills into a growing tree that adaptively covers the environment. We illustrate in several navigation and control environments how the skills learned by UPSIDE solve sparse-reward downstream tasks better than existing baselines.
Combining Latent Space and Structured Kernels for Bayesian Optimization over Combinatorial Spaces
Nov 01, 2021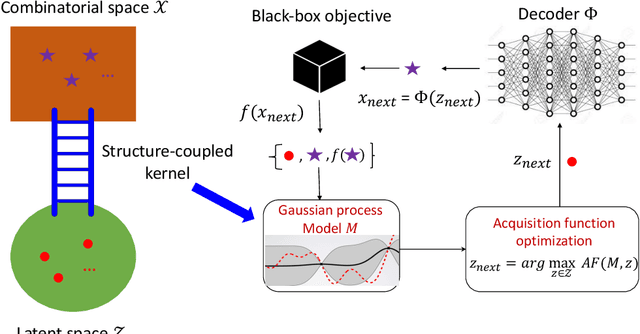
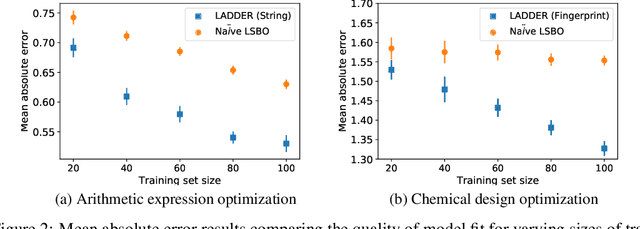
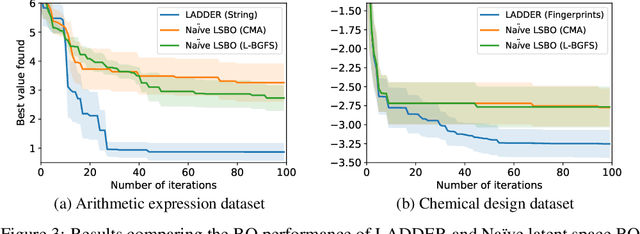
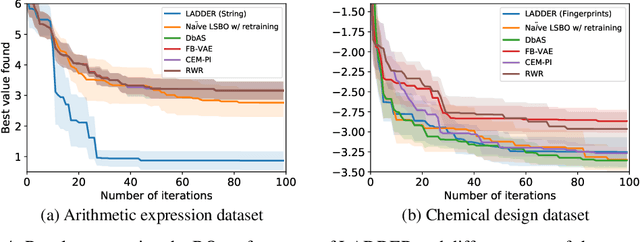
We consider the problem of optimizing combinatorial spaces (e.g., sequences, trees, and graphs) using expensive black-box function evaluations. For example, optimizing molecules for drug design using physical lab experiments. Bayesian optimization (BO) is an efficient framework for solving such problems by intelligently selecting the inputs with high utility guided by a learned surrogate model. A recent BO approach for combinatorial spaces is through a reduction to BO over continuous spaces by learning a latent representation of structures using deep generative models (DGMs). The selected input from the continuous space is decoded into a discrete structure for performing function evaluation. However, the surrogate model over the latent space only uses the information learned by the DGM, which may not have the desired inductive bias to approximate the target black-box function. To overcome this drawback, this paper proposes a principled approach referred as LADDER. The key idea is to define a novel structure-coupled kernel that explicitly integrates the structural information from decoded structures with the learned latent space representation for better surrogate modeling. Our experiments on real-world benchmarks show that LADDER significantly improves over the BO over latent space method, and performs better or similar to state-of-the-art methods.
CLUE: Contextualised Unified Explainable Learning of User Engagement in Video Lectures
Jan 14, 2022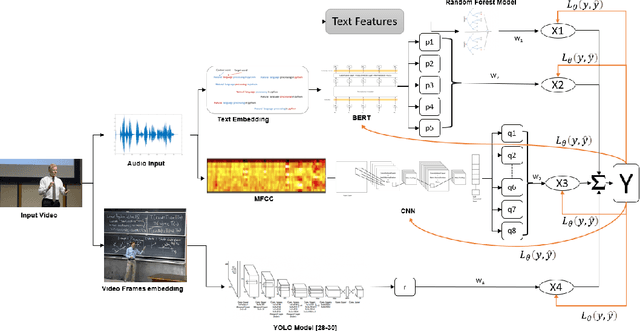
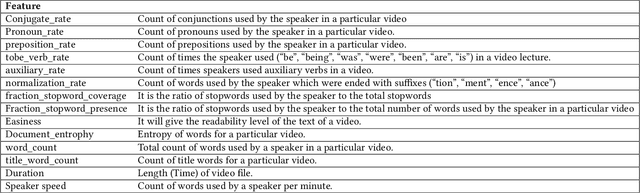
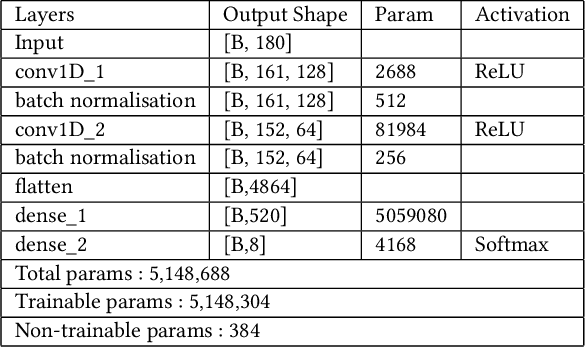
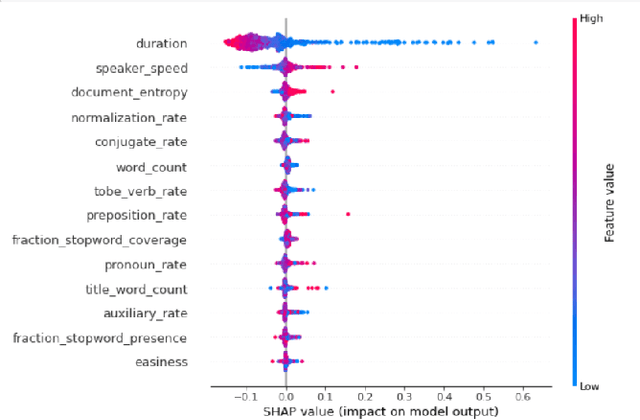
Predicting contextualised engagement in videos is a long-standing problem that has been popularly attempted by exploiting the number of views or the associated likes using different computational methods. The recent decade has seen a boom in online learning resources, and during the pandemic, there has been an exponential rise of online teaching videos without much quality control. The quality of the content could be improved if the creators could get constructive feedback on their content. Employing an army of domain expert volunteers to provide feedback on the videos might not scale. As a result, there has been a steep rise in developing computational methods to predict a user engagement score that is indicative of some form of possible user engagement, i.e., to what level a user would tend to engage with the content. A drawback in current methods is that they model various features separately, in a cascaded approach, that is prone to error propagation. Besides, most of them do not provide crucial explanations on how the creator could improve their content. In this paper, we have proposed a new unified model, CLUE for the educational domain, which learns from the features extracted from freely available public online teaching videos and provides explainable feedback on the video along with a user engagement score. Given the complexity of the task, our unified framework employs different pre-trained models working together as an ensemble of classifiers. Our model exploits various multi-modal features to model the complexity of language, context agnostic information, textual emotion of the delivered content, animation, speaker's pitch and speech emotions. Under a transfer learning setup, the overall model, in the unified space, is fine-tuned for downstream applications.
Rebooting ACGAN: Auxiliary Classifier GANs with Stable Training
Nov 01, 2021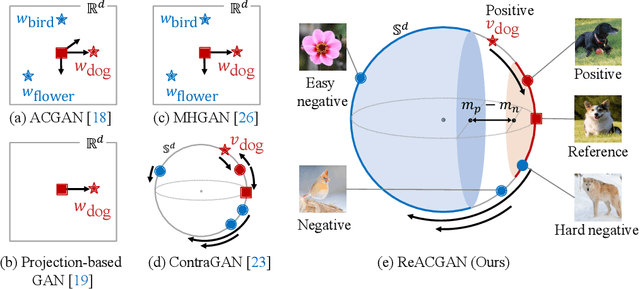
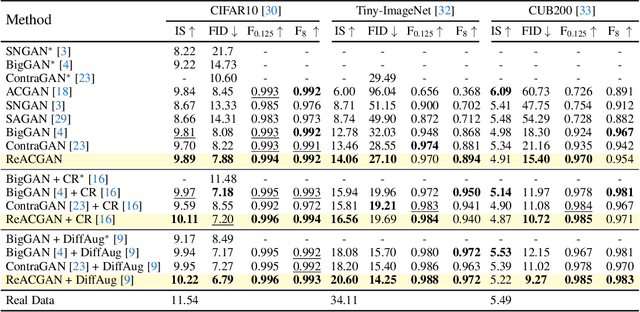
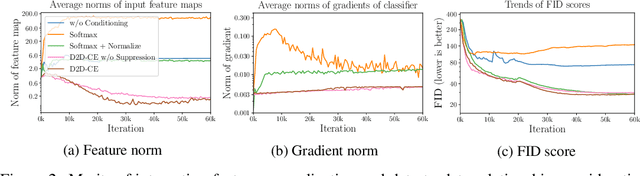
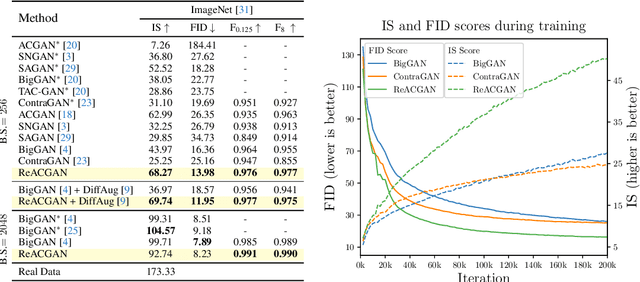
Conditional Generative Adversarial Networks (cGAN) generate realistic images by incorporating class information into GAN. While one of the most popular cGANs is an auxiliary classifier GAN with softmax cross-entropy loss (ACGAN), it is widely known that training ACGAN is challenging as the number of classes in the dataset increases. ACGAN also tends to generate easily classifiable samples with a lack of diversity. In this paper, we introduce two cures for ACGAN. First, we identify that gradient exploding in the classifier can cause an undesirable collapse in early training, and projecting input vectors onto a unit hypersphere can resolve the problem. Second, we propose the Data-to-Data Cross-Entropy loss (D2D-CE) to exploit relational information in the class-labeled dataset. On this foundation, we propose the Rebooted Auxiliary Classifier Generative Adversarial Network (ReACGAN). The experimental results show that ReACGAN achieves state-of-the-art generation results on CIFAR10, Tiny-ImageNet, CUB200, and ImageNet datasets. We also verify that ReACGAN benefits from differentiable augmentations and that D2D-CE harmonizes with StyleGAN2 architecture. Model weights and a software package that provides implementations of representative cGANs and all experiments in our paper are available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.
Adverse Media Mining for KYC and ESG Compliance
Oct 22, 2021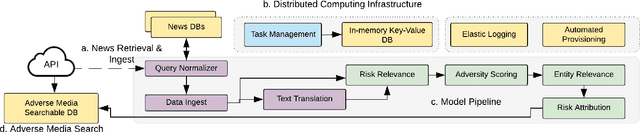
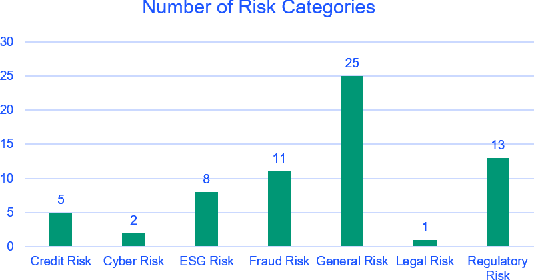
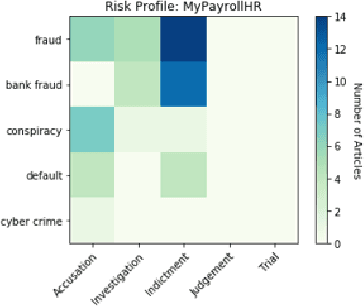
In recent years, institutions operating in the global market economy face growing risks stemming from non-financial risk factors such as cyber, third-party, and reputational outweighing traditional risks of credit and liquidity. Adverse media or negative news screening is crucial for the identification of such non-financial risks. Typical tools for screening are not real-time, involve manual searches, require labor-intensive monitoring of information sources. Moreover, they are costly processes to maintain up-to-date with complex regulatory requirements and the institution's evolving risk appetite. In this extended abstract, we present an automated system to conduct both real-time and batch search of adverse media for users' queries (person or organization entities) using news and other open-source, unstructured sources of information. Our scalable, machine-learning driven approach to high-precision, adverse news filtering is based on four perspectives - relevance to risk domains, search query (entity) relevance, adverse sentiment analysis, and risk encoding. With the help of model evaluations and case studies, we summarize the performance of our deployed application.
Disentangled Sequence to Sequence Learning for Compositional Generalization
Oct 09, 2021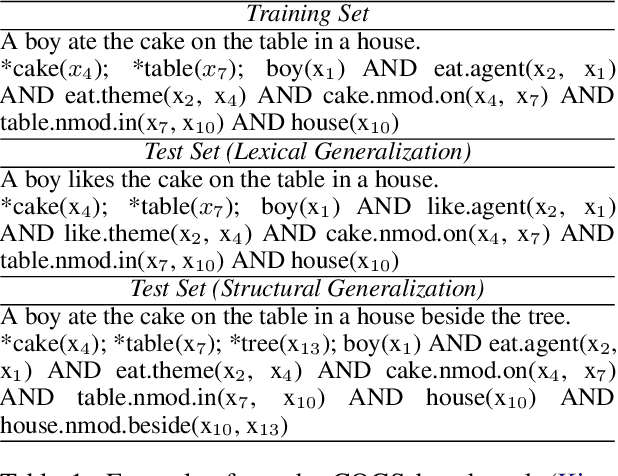
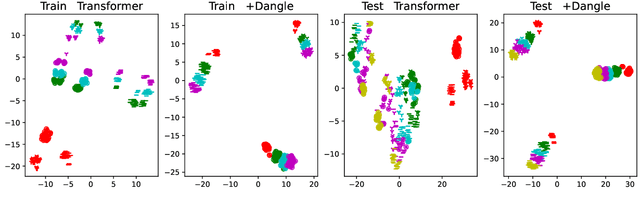
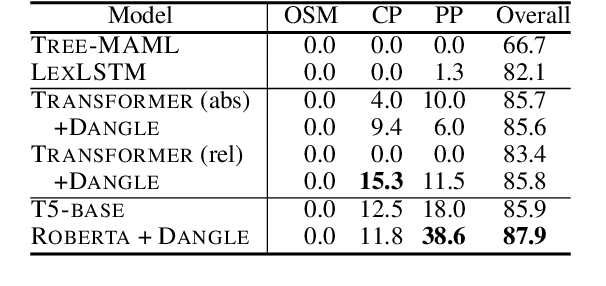
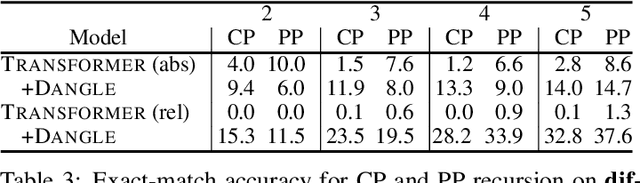
There is mounting evidence that existing neural network models, in particular the very popular sequence-to-sequence architecture, struggle with compositional generalization, i.e., the ability to systematically generalize to unseen compositions of seen components. In this paper we demonstrate that one of the reasons hindering compositional generalization relates to the representations being entangled. We propose an extension to sequence-to-sequence models which allows us to learn disentangled representations by adaptively re-encoding (at each time step) the source input. Specifically, we condition the source representations on the newly decoded target context which makes it easier for the encoder to exploit specialized information for each prediction rather than capturing all source information in a single forward pass. Experimental results on semantic parsing and machine translation empirically show that our proposal yields more disentangled representations and better generalization.
Patent Sentiment Analysis to Highlight Patent Paragraphs
Nov 06, 2021
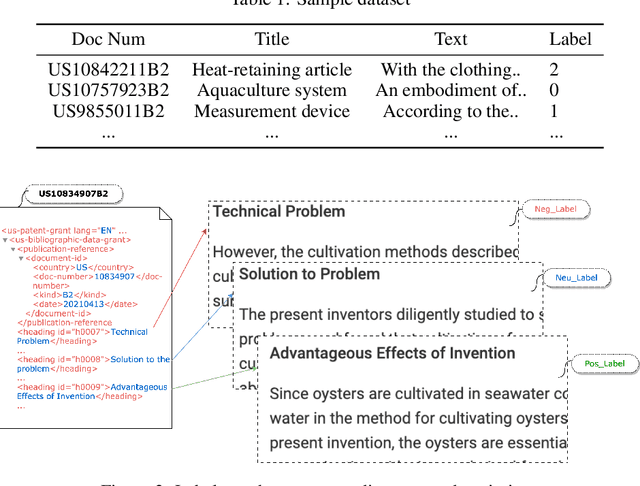
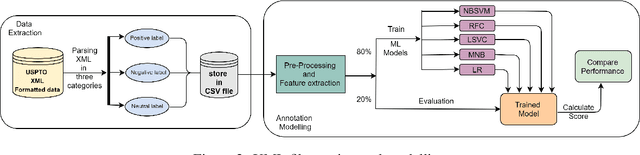
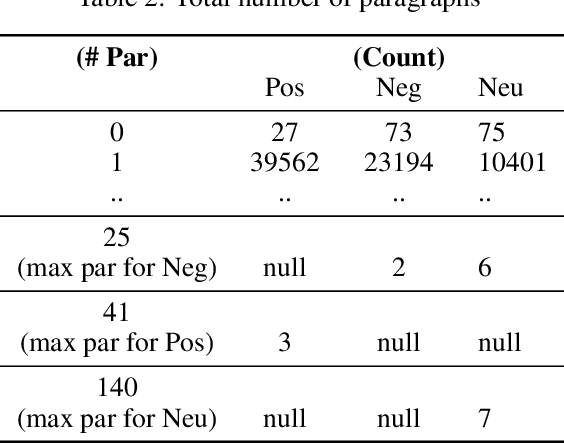
Given a patent document, identifying distinct semantic annotations is an interesting research aspect. Text annotation helps the patent practitioners such as examiners and patent attorneys to quickly identify the key arguments of any invention, successively providing a timely marking of a patent text. In the process of manual patent analysis, to attain better readability, recognising the semantic information by marking paragraphs is in practice. This semantic annotation process is laborious and time-consuming. To alleviate such a problem, we proposed a novel dataset to train Machine Learning algorithms to automate the highlighting process. The contributions of this work are: i) we developed a multi-class, novel dataset of size 150k samples by traversing USPTO patents over a decade, ii) articulated statistics and distributions of data using imperative exploratory data analysis, iii) baseline Machine Learning models are developed to utilize the dataset to address patent paragraph highlighting task, iv) dataset and codes relating to this task are open-sourced through a dedicated GIT web page: https://github.com/Renuk9390/Patent_Sentiment_Analysis and v) future path to extend this work using Deep Learning and domain specific pre-trained language models to develop a tool to highlight is provided. This work assist patent practitioners in highlighting semantic information automatically and aid to create a sustainable and efficient patent analysis using the aptitude of Machine Learning.
Learning Agent State Online with Recurrent Generate-and-Test
Dec 30, 2021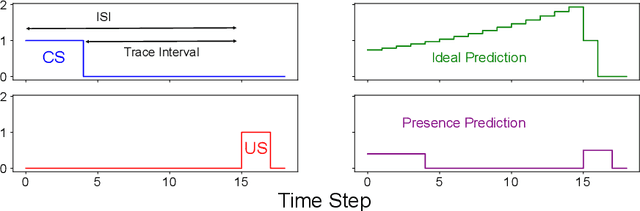
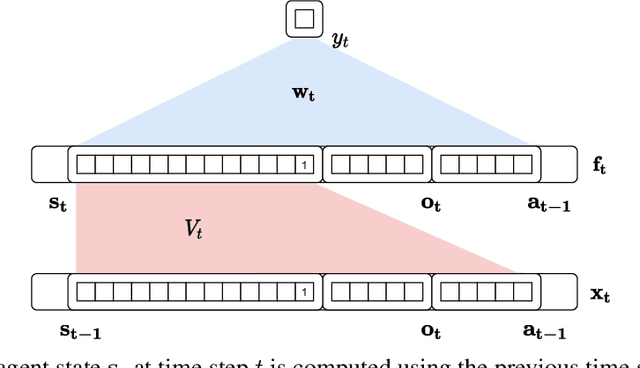
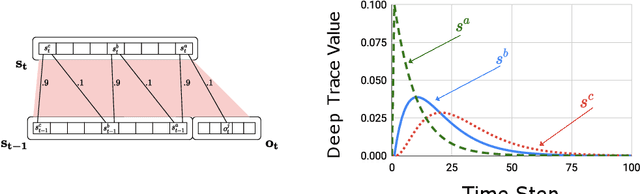
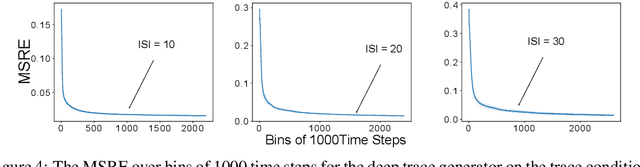
Learning continually and online from a continuous stream of data is challenging, especially for a reinforcement learning agent with sequential data. When the environment only provides observations giving partial information about the state of the environment, the agent must learn the agent state based on the data stream of experience. We refer to the state learned directly from the data stream of experience as the agent state. Recurrent neural networks can learn the agent state, but the training methods are computationally expensive and sensitive to the hyper-parameters, making them unideal for online learning. This work introduces methods based on the generate-and-test approach to learn the agent state. A generate-and-test algorithm searches for state features by generating features and testing their usefulness. In this process, features useful for the agent's performance on the task are preserved, and the least useful features get replaced with newly generated features. We study the effectiveness of our methods on two online multi-step prediction problems. The first problem, trace conditioning, focuses on the agent's ability to remember a cue for a prediction multiple steps into the future. In the second problem, trace patterning, the agent needs to learn patterns in the observation signals and remember them for future predictions. We show that our proposed methods can effectively learn the agent state online and produce accurate predictions.