 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhanced Object Detection in Floor-plan through Super Resolution
Dec 18, 2021
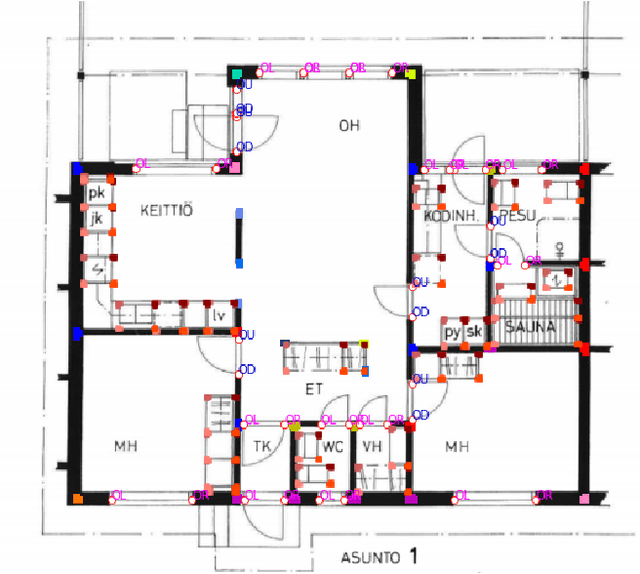
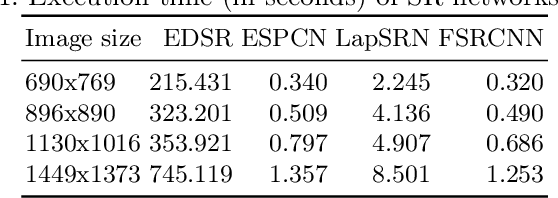
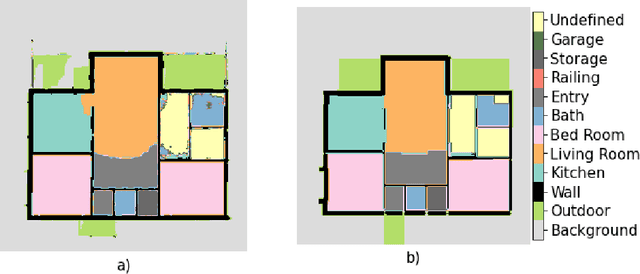
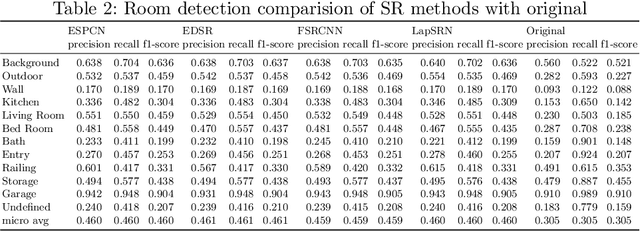
Building Information Modelling (BIM) software use scalable vector formats to enable flexible designing of floor plans in the industry. Floor plans in the architectural domain can come from many sources that may or may not be in scalable vector format. The conversion of floor plan images to fully annotated vector images is a process that can now be realized by computer vision. Novel datasets in this field have been used to train Convolutional Neural Network (CNN) architectures for object detection. Image enhancement through Super-Resolution (SR) is also an established CNN based network in computer vision that is used for converting low resolution images to high resolution ones. This work focuses on creating a multi-component module that stacks a SR model on a floor plan object detection model. The proposed stacked model shows greater performance than the corresponding vanilla object detection model. For the best case, the the inclusion of SR showed an improvement of 39.47% in object detection over the vanilla network. Data and code are made publicly available at https://github.com/rbg-research/Floor-Plan-Detection.
Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention
Dec 28, 2021



Recently, Transformers have shown promising performance in various vision tasks. To reduce the quadratic computation complexity caused by the global self-attention, various methods constrain the range of attention within a local region to improve its efficiency. Consequently, their receptive fields in a single attention layer are not large enough, resulting in insufficient context modeling. To address this issue, we propose a Pale-Shaped self-Attention (PS-Attention), which performs self-attention within a pale-shaped region. Compared to the global self-attention, PS-Attention can reduce the computation and memory costs significantly. Meanwhile, it can capture richer contextual information under the similar computation complexity with previous local self-attention mechanisms. Based on the PS-Attention, we develop a general Vision Transformer backbone with a hierarchical architecture, named Pale Transformer, which achieves 83.4%, 84.3%, and 84.9% Top-1 accuracy with the model size of 22M, 48M, and 85M respectively for 224 ImageNet-1K classification, outperforming the previous Vision Transformer backbones. For downstream tasks, our Pale Transformer backbone performs better than the recent state-of-the-art CSWin Transformer by a large margin on ADE20K semantic segmentation and COCO object detection & instance segmentation. The code will be released on https://github.com/BR-IDL/PaddleViT.
Brick-by-Brick: Combinatorial Construction with Deep Reinforcement Learning
Oct 29, 2021
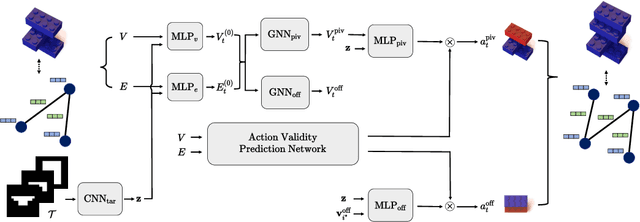
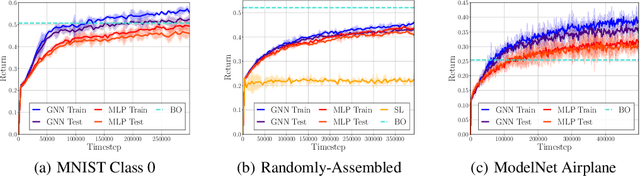
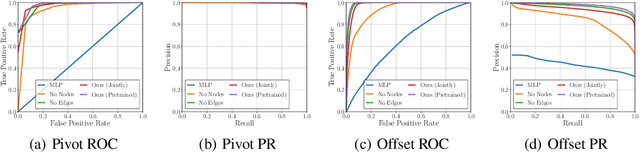
Discovering a solution in a combinatorial space is prevalent in many real-world problems but it is also challenging due to diverse complex constraints and the vast number of possible combinations. To address such a problem, we introduce a novel formulation, combinatorial construction, which requires a building agent to assemble unit primitives (i.e., LEGO bricks) sequentially -- every connection between two bricks must follow a fixed rule, while no bricks mutually overlap. To construct a target object, we provide incomplete knowledge about the desired target (i.e., 2D images) instead of exact and explicit volumetric information to the agent. This problem requires a comprehensive understanding of partial information and long-term planning to append a brick sequentially, which leads us to employ reinforcement learning. The approach has to consider a variable-sized action space where a large number of invalid actions, which would cause overlap between bricks, exist. To resolve these issues, our model, dubbed Brick-by-Brick, adopts an action validity prediction network that efficiently filters invalid actions for an actor-critic network. We demonstrate that the proposed method successfully learns to construct an unseen object conditioned on a single image or multiple views of a target object.
RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
Oct 14, 2021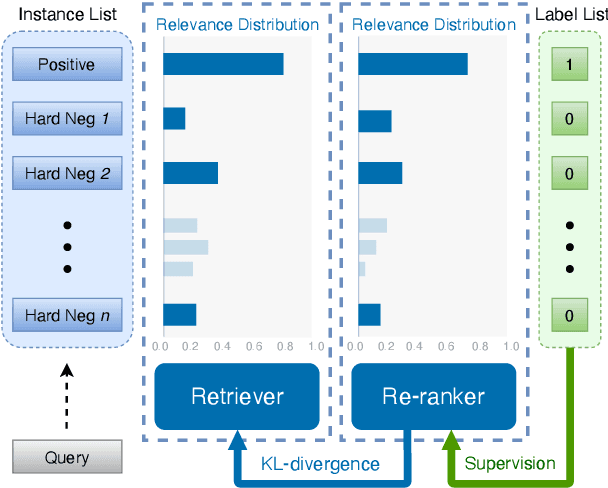

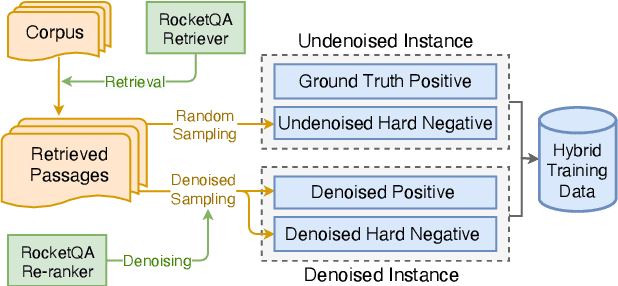
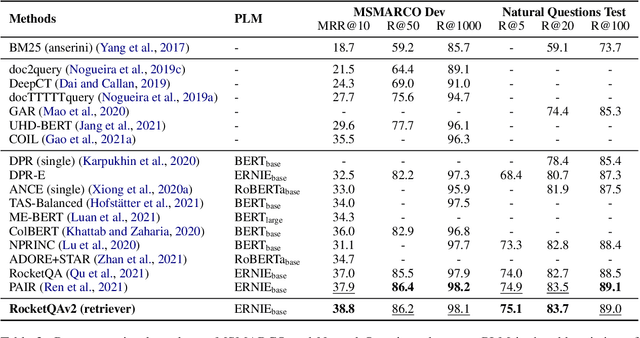
In various natural language processing tasks, passage retrieval and passage re-ranking are two key procedures in finding and ranking relevant information. Since both the two procedures contribute to the final performance, it is important to jointly optimize them in order to achieve mutual improvement. In this paper, we propose a novel joint training approach for dense passage retrieval and passage re-ranking. A major contribution is that we introduce the dynamic listwise distillation, where we design a unified listwise training approach for both the retriever and the re-ranker. During the dynamic distillation, the retriever and the re-ranker can be adaptively improved according to each other's relevance information. We also propose a hybrid data augmentation strategy to construct diverse training instances for listwise training approach. Extensive experiments show the effectiveness of our approach on both MSMARCO and Natural Questions datasets. Our code is available at https://github.com/PaddlePaddle/RocketQA.
The Tensor Brain: A Unified Theory of Perception, Memory and Semantic Decoding
Oct 06, 2021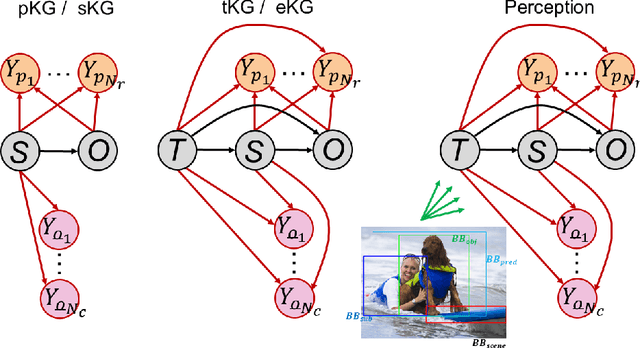

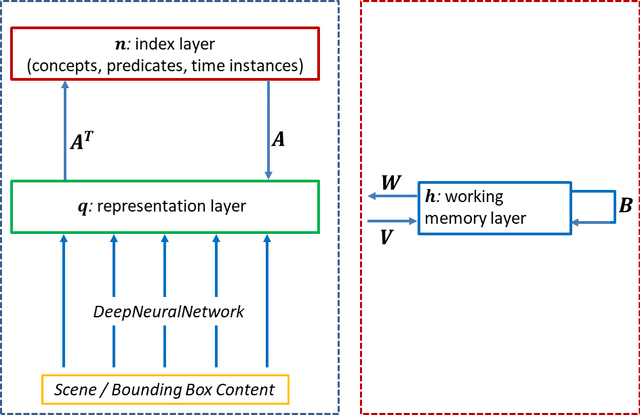
We present a unified computational theory of perception and memory. In our model, perception, episodic memory, and semantic memory are realized by different functional and operational modes of the oscillating interactions between an index layer and a representation layer in a bilayer tensor network (BTN). The memoryless semantic {representation layer} broadcasts information. In cognitive neuroscience, it would be the "mental canvas", or the "global workspace" and reflects the cognitive brain state. The symbolic {index layer} represents concepts and past episodes, whose semantic embeddings are implemented in the connection weights between both layers. In addition, we propose a {working memory layer} as a processing center and information buffer. Episodic and semantic memory realize memory-based reasoning, i.e., the recall of relevant past information to enrich perception, and are personalized to an agent's current state, as well as to an agent's unique memories. Episodic memory stores and retrieves past observations and provides provenance and context. Recent episodic memory enriches perception by the retrieval of perceptual experiences, which provide the agent with a sense about the here and now: to understand its own state, and the world's semantic state in general, the agent needs to know what happened recently, in recent scenes, and on recently perceived entities. Remote episodic memory retrieves relevant past experiences, contributes to our conscious self, and, together with semantic memory, to a large degree defines who we are as individuals.
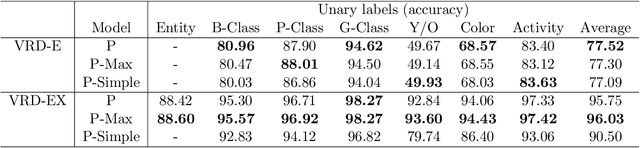
Dynamic optimization with side information
Jul 17, 2019
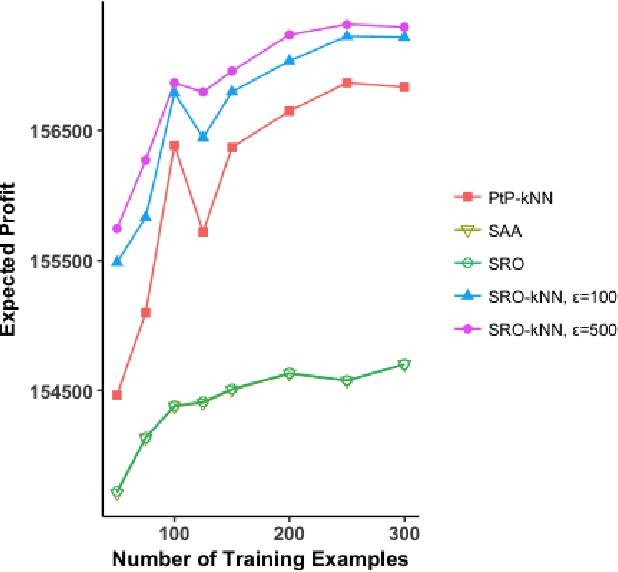
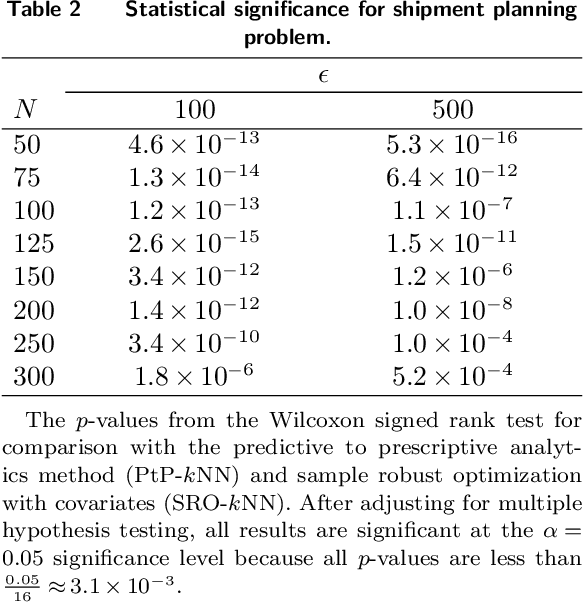
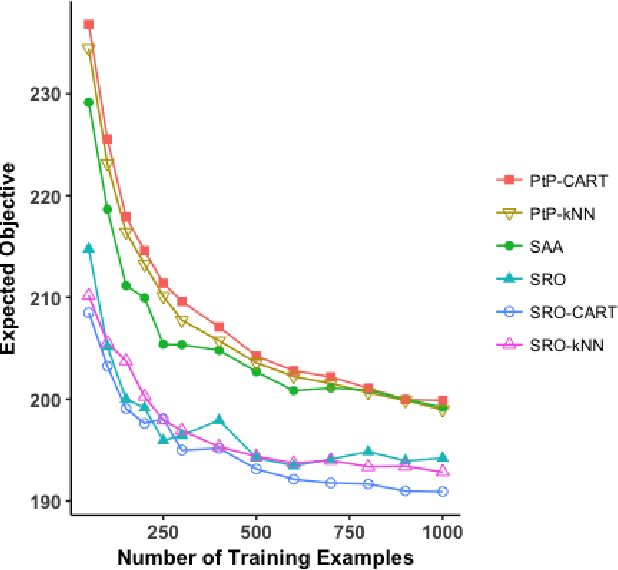
We present a data-driven framework for incorporating side information in dynamic optimization under uncertainty. Specifically, our approach uses predictive machine learning methods (such as k-nearest neighbors, kernel regression, and random forests) to weight the relative importance of various data-driven uncertainty sets in a robust optimization formulation. Through a novel measure concentration result for local machine learning methods, we prove that the proposed framework is asymptotically optimal for stochastic dynamic optimization with covariates. We also describe a general-purpose approximation for the proposed framework, based on overlapping linear decision rules, which is computationally tractable and produces high-quality solutions for dynamic problems with many stages. Across a variety of examples in shipment planning, inventory management, and finance, our method achieves improvements of up to 15% over alternatives and requires less than one minute of computation time on problems with twelve stages.
MAg: a simple learning-based patient-level aggregation method for detecting microsatellite instability from whole-slide images
Jan 13, 2022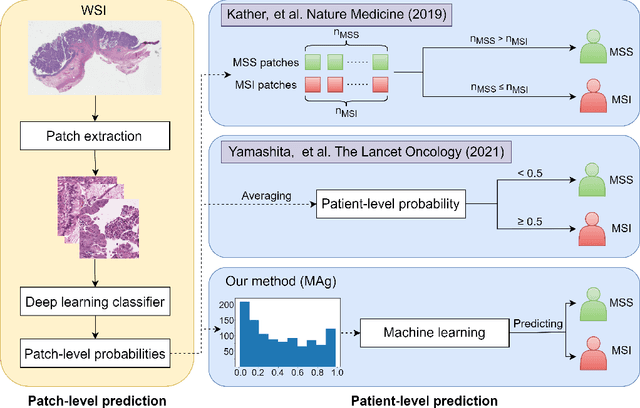
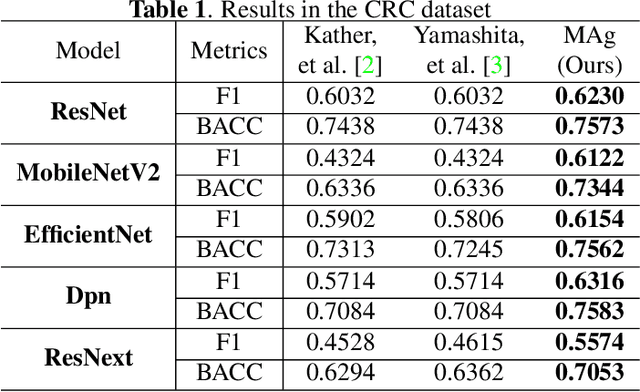
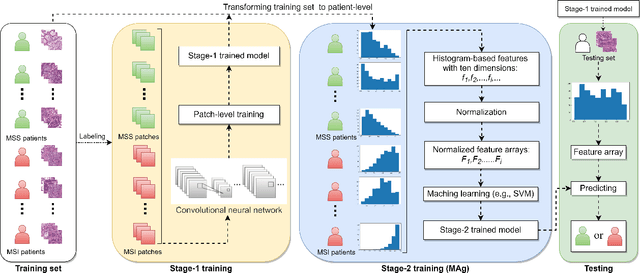
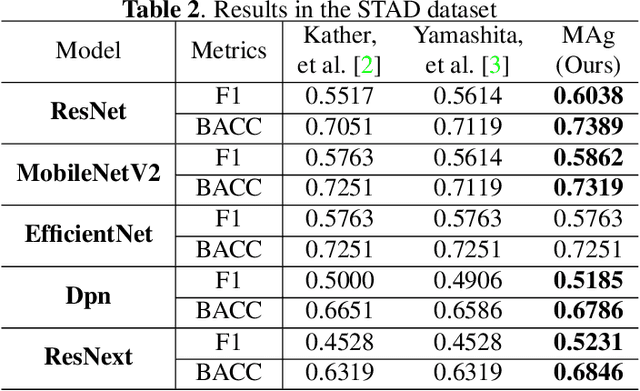
The prediction of microsatellite instability (MSI) and microsatellite stability (MSS) is essential in predicting both the treatment response and prognosis of gastrointestinal cancer. In clinical practice, a universal MSI testing is recommended, but the accessibility of such a test is limited. Thus, a more cost-efficient and broadly accessible tool is desired to cover the traditionally untested patients. In the past few years, deep-learning-based algorithms have been proposed to predict MSI directly from haematoxylin and eosin (H&E)-stained whole-slide images (WSIs). Such algorithms can be summarized as (1) patch-level MSI/MSS prediction, and (2) patient-level aggregation. Compared with the advanced deep learning approaches that have been employed for the first stage, only the na\"ive first-order statistics (e.g., averaging and counting) were employed in the second stage. In this paper, we propose a simple yet broadly generalizable patient-level MSI aggregation (MAg) method to effectively integrate the precious patch-level information. Briefly, the entire probabilistic distribution in the first stage is modeled as histogram-based features to be fused as the final outcome with machine learning (e.g., SVM). The proposed MAg method can be easily used in a plug-and-play manner, which has been evaluated upon five broadly used deep neural networks: ResNet, MobileNetV2, EfficientNet, Dpn and ResNext. From the results, the proposed MAg method consistently improves the accuracy of patient-level aggregation for two publicly available datasets. It is our hope that the proposed method could potentially leverage the low-cost H&E based MSI detection method. The code of our work has been made publicly available at https://github.com/Calvin-Pang/MAg.
Siamese Network with Interactive Transformer for Video Object Segmentation
Dec 28, 2021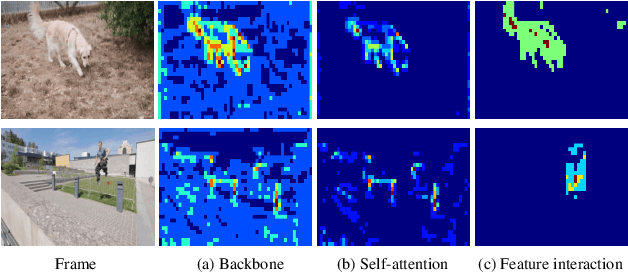
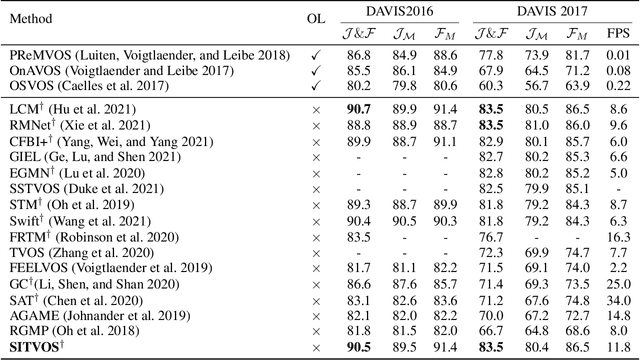
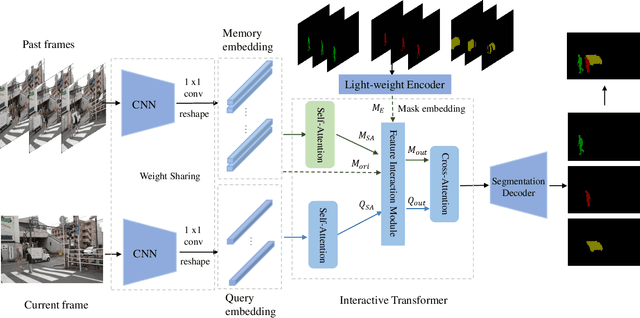
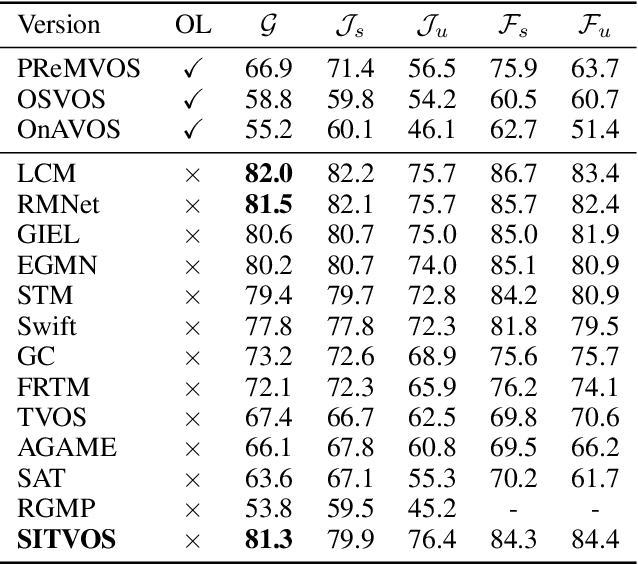
Semi-supervised video object segmentation (VOS) refers to segmenting the target object in remaining frames given its annotation in the first frame, which has been actively studied in recent years. The key challenge lies in finding effective ways to exploit the spatio-temporal context of past frames to help learn discriminative target representation of current frame. In this paper, we propose a novel Siamese network with a specifically designed interactive transformer, called SITVOS, to enable effective context propagation from historical to current frames. Technically, we use the transformer encoder and decoder to handle the past frames and current frame separately, i.e., the encoder encodes robust spatio-temporal context of target object from the past frames, while the decoder takes the feature embedding of current frame as the query to retrieve the target from the encoder output. To further enhance the target representation, a feature interaction module (FIM) is devised to promote the information flow between the encoder and decoder. Moreover, we employ the Siamese architecture to extract backbone features of both past and current frames, which enables feature reuse and is more efficient than existing methods. Experimental results on three challenging benchmarks validate the superiority of SITVOS over state-of-the-art methods.
Rethinking Point Cloud Filtering: A Non-Local Position Based Approach
Oct 14, 2021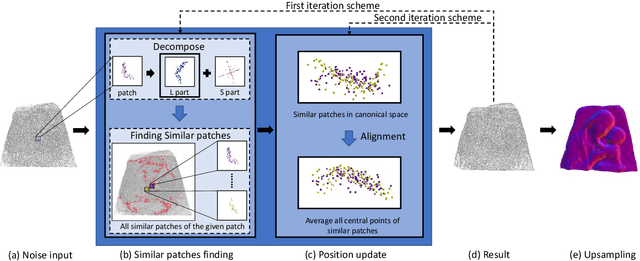
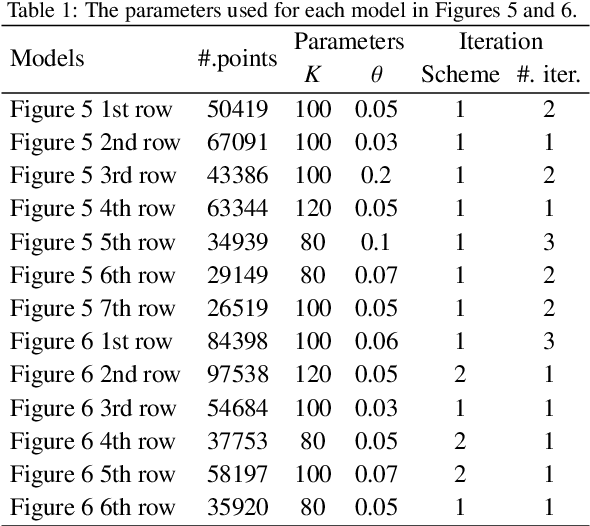
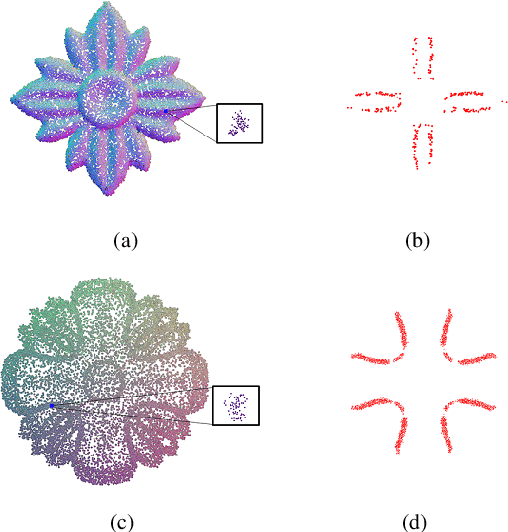
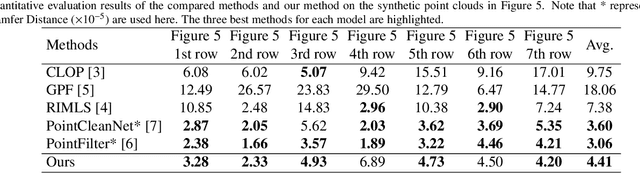
Existing position based point cloud filtering methods can hardly preserve sharp geometric features. In this paper, we rethink point cloud filtering from a non-learning non-local non-normal perspective, and propose a novel position based approach for feature-preserving point cloud filtering. Unlike normal based techniques, our method does not require the normal information. The core idea is to first design a similarity metric to search the non-local similar patches of a queried local patch. We then map the non-local similar patches into a canonical space and aggregate the non-local information. The aggregated outcome (i.e. coordinate) will be inversely mapped into the original space. Our method is simple yet effective. Extensive experiments validate our method, and show that it generally outperforms position based methods (deep learning and non-learning), and generates better or comparable outcomes to normal based techniques (deep learning and non-learning).
Advancing Residual Learning towards Powerful Deep Spiking Neural Networks
Dec 23, 2021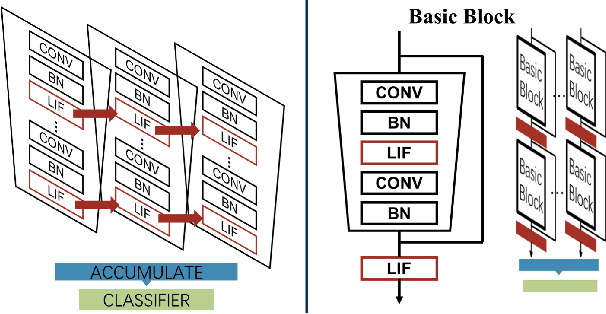

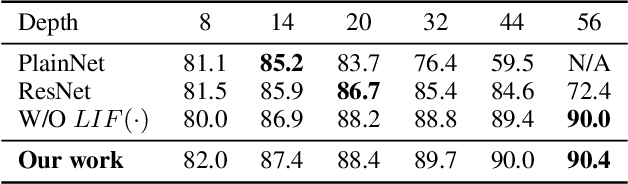
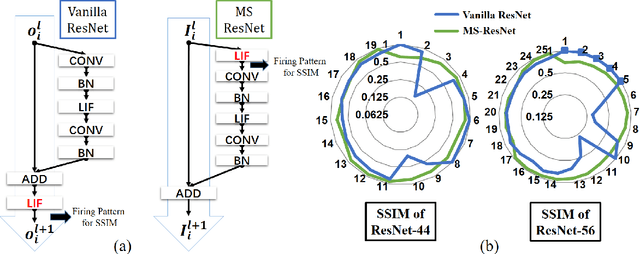
Despite the rapid progress of neuromorphic computing, inadequate capacity and insufficient representation power of spiking neural networks (SNNs) severely restrict their application scope in practice. Residual learning and shortcuts have been evidenced as an important approach for training deep neural networks, but rarely did previous work assess their applicability to the characteristics of spike-based communication and spatiotemporal dynamics. In this paper, we first identify that this negligence leads to impeded information flow and accompanying degradation problem in previous residual SNNs. Then we propose a novel SNN-oriented residual block, MS-ResNet, which is able to significantly extend the depth of directly trained SNNs, e.g. up to 482 layers on CIFAR-10 and 104 layers on ImageNet, without observing any slight degradation problem. We validate the effectiveness of MS-ResNet on both frame-based and neuromorphic datasets, and MS-ResNet104 achieves a superior result of 76.02% accuracy on ImageNet, the first time in the domain of directly trained SNNs. Great energy efficiency is also observed that on average only one spike per neuron is needed to classify an input sample. We believe our powerful and scalable models will provide a strong support for further exploration of SNNs.