 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Implicit Data Augmentation Using Feature Interpolation for Diversified Low-Shot Image Generation
Dec 04, 2021
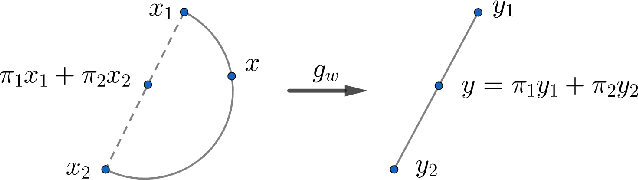
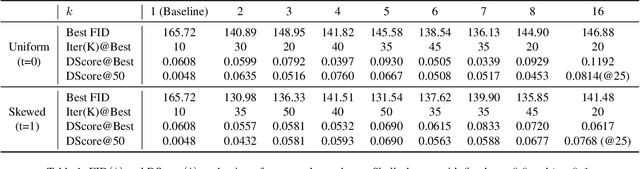
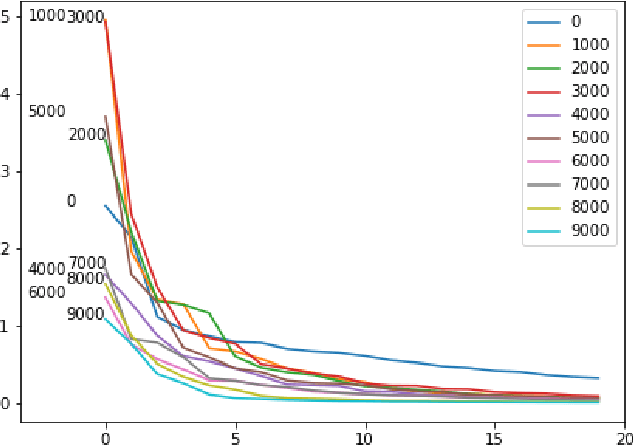
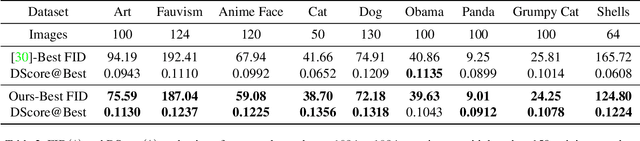
Training of generative models especially Generative Adversarial Networks can easily diverge in low-data setting. To mitigate this issue, we propose a novel implicit data augmentation approach which facilitates stable training and synthesize diverse samples. Specifically, we view the discriminator as a metric embedding of the real data manifold, which offers proper distances between real data points. We then utilize information in the feature space to develop a data-driven augmentation method. We further bring up a simple metric to evaluate the diversity of synthesized samples. Experiments on few-shot generation tasks show our method improves FID and diversity of results compared to current methods, and allows generating high-quality and diverse images with less than 100 training samples.
A Pixel-Level Meta-Learner for Weakly Supervised Few-Shot Semantic Segmentation
Nov 02, 2021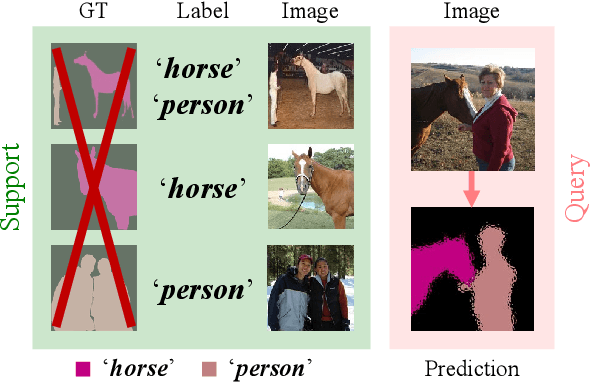
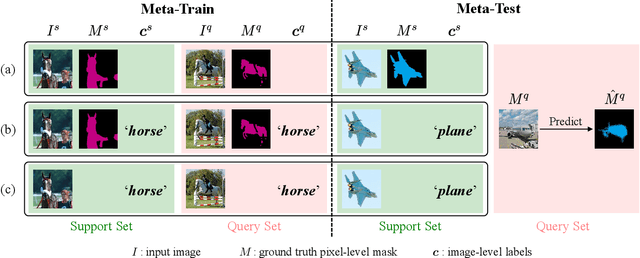
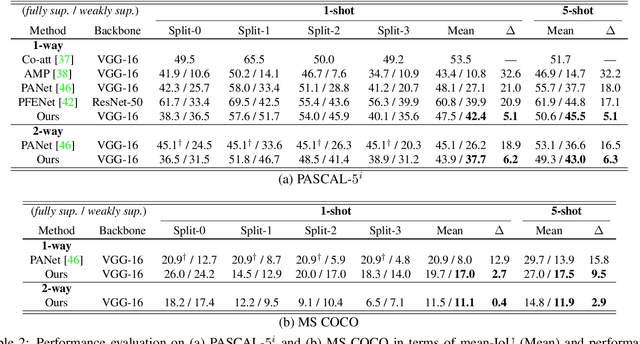
Few-shot semantic segmentation addresses the learning task in which only few images with ground truth pixel-level labels are available for the novel classes of interest. One is typically required to collect a large mount of data (i.e., base classes) with such ground truth information, followed by meta-learning strategies to address the above learning task. When only image-level semantic labels can be observed during both training and testing, it is considered as an even more challenging task of weakly supervised few-shot semantic segmentation. To address this problem, we propose a novel meta-learning framework, which predicts pseudo pixel-level segmentation masks from a limited amount of data and their semantic labels. More importantly, our learning scheme further exploits the produced pixel-level information for query image inputs with segmentation guarantees. Thus, our proposed learning model can be viewed as a pixel-level meta-learner. Through extensive experiments on benchmark datasets, we show that our model achieves satisfactory performances under fully supervised settings, yet performs favorably against state-of-the-art methods under weakly supervised settings.
Discovering Differential Features: Adversarial Learning for Information Credibility Evaluation
Sep 16, 2019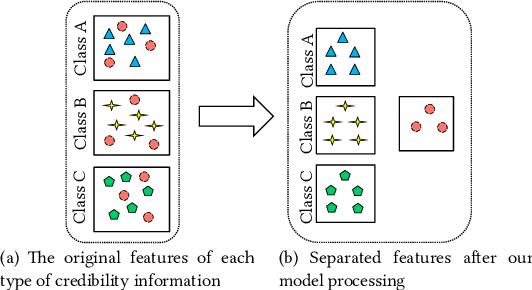
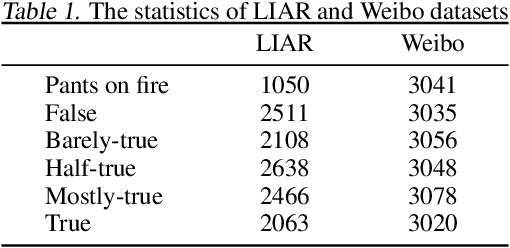
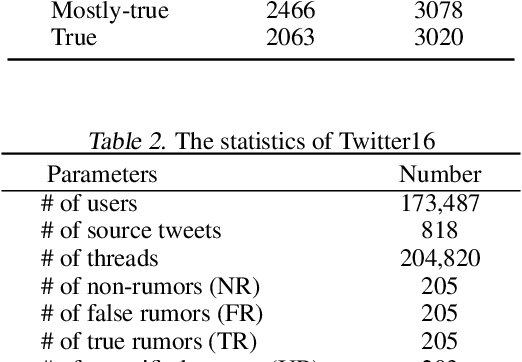
A series of deep learning approaches extract a large number of credibility features to detect fake news on the Internet. However, these extracted features still suffer from many irrelevant and noisy features that restrict severely the performance of the approaches. In this paper, we propose a novel model based on Adversarial Networks and inspirited by the Shared-Private model (ANSP), which aims at reducing common, irrelevant features from the extracted features for information credibility evaluation. Specifically, ANSP involves two tasks: one is to prevent the binary classification of true and false information for capturing common features relying on adversarial networks guided by reinforcement learning. Another extracts credibility features (henceforth, private features) from multiple types of credibility information and compares with the common features through two strategies, i.e., orthogonality constraints and KL-divergence for making the private features more differential. Experiments first on two six-label LIAR and Weibo datasets demonstrate that ANSP achieves the state-of-the-art performance, boosting the accuracy by 2.1%, 3.1%, respectively and then on four-label Twitter16 validate the robustness of the model with 1.8% performance improvements.
Contrast and Generation Make BART a Good Dialogue Emotion Recognizer
Dec 21, 2021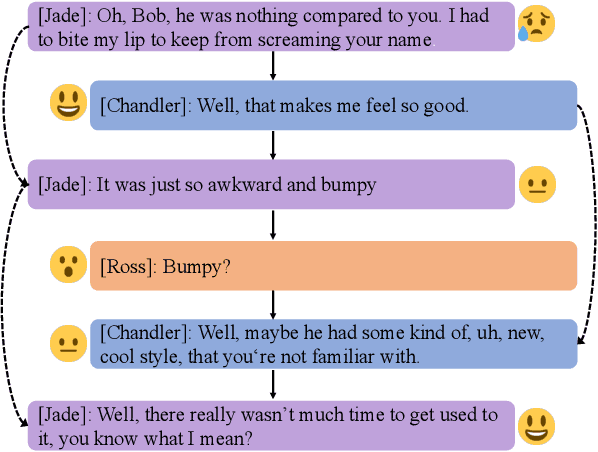
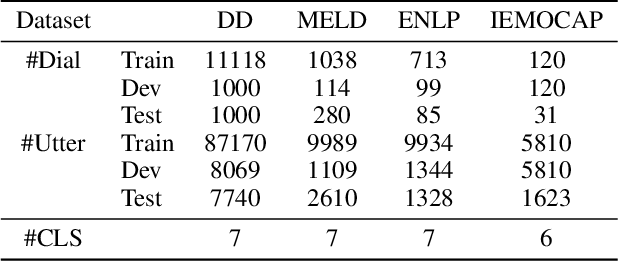
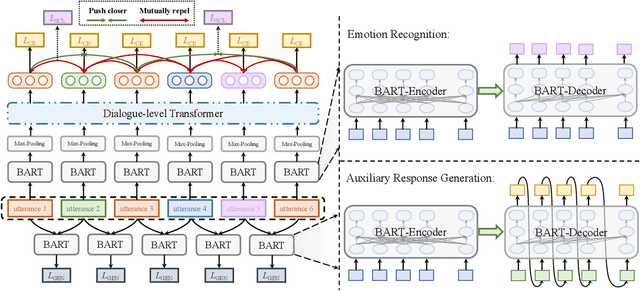
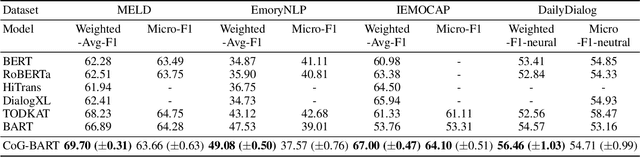
In dialogue systems, utterances with similar semantics may have distinctive emotions under different contexts. Therefore, modeling long-range contextual emotional relationships with speaker dependency plays a crucial part in dialogue emotion recognition. Meanwhile, distinguishing the different emotion categories is non-trivial since they usually have semantically similar sentiments. To this end, we adopt supervised contrastive learning to make different emotions mutually exclusive to identify similar emotions better. Meanwhile, we utilize an auxiliary response generation task to enhance the model's ability of handling context information, thereby forcing the model to recognize emotions with similar semantics in diverse contexts. To achieve these objectives, we use the pre-trained encoder-decoder model BART as our backbone model since it is very suitable for both understanding and generation tasks. The experiments on four datasets demonstrate that our proposed model obtains significantly more favorable results than the state-of-the-art model in dialogue emotion recognition. The ablation study further demonstrates the effectiveness of supervised contrastive loss and generative loss.
Forgetting Outside the Box: Scrubbing Deep Networks of Information Accessible from Input-Output Observations
Mar 05, 2020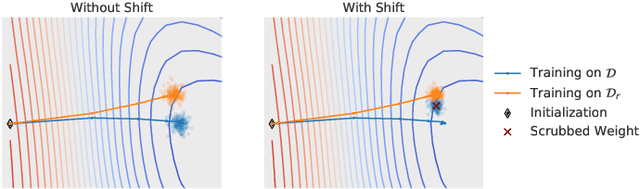
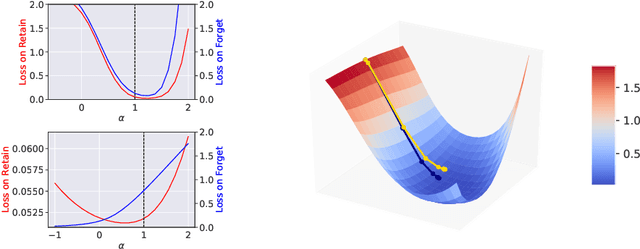
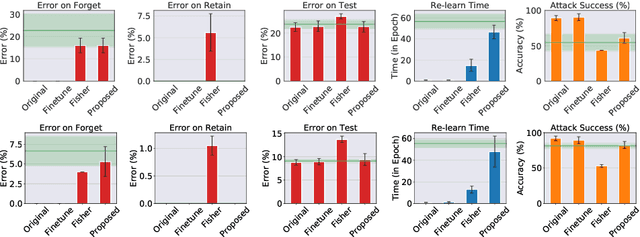
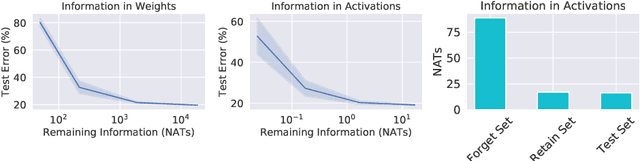
We describe a procedure for removing dependency on a cohort of training data from a trained deep network that improves upon and generalizes previous methods to different readout functions and can be extended to ensure forgetting in the activations of the network. We introduce a new bound on how much information can be extracted per query about the forgotten cohort from a black-box network for which only the input-output behavior is observed. The proposed forgetting procedure has a deterministic part derived from the differential equations of a linearized version of the model, and a stochastic part that ensures information destruction by adding noise tailored to the geometry of the loss landscape. We exploit the connections between the activation and weight dynamics of a DNN inspired by Neural Tangent Kernels to compute the information in the activations.
Integrating Visuospatial, Linguistic and Commonsense Structure into Story Visualization
Oct 21, 2021

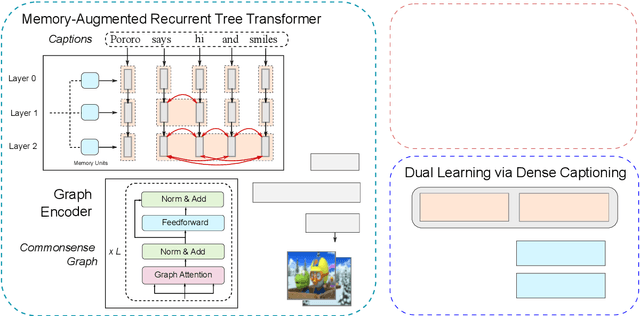
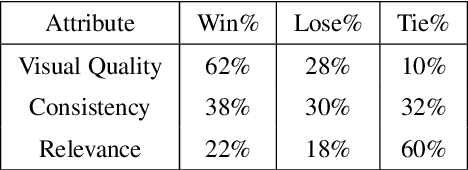
While much research has been done in text-to-image synthesis, little work has been done to explore the usage of linguistic structure of the input text. Such information is even more important for story visualization since its inputs have an explicit narrative structure that needs to be translated into an image sequence (or visual story). Prior work in this domain has shown that there is ample room for improvement in the generated image sequence in terms of visual quality, consistency and relevance. In this paper, we first explore the use of constituency parse trees using a Transformer-based recurrent architecture for encoding structured input. Second, we augment the structured input with commonsense information and study the impact of this external knowledge on the generation of visual story. Third, we also incorporate visual structure via bounding boxes and dense captioning to provide feedback about the characters/objects in generated images within a dual learning setup. We show that off-the-shelf dense-captioning models trained on Visual Genome can improve the spatial structure of images from a different target domain without needing fine-tuning. We train the model end-to-end using intra-story contrastive loss (between words and image sub-regions) and show significant improvements in several metrics (and human evaluation) for multiple datasets. Finally, we provide an analysis of the linguistic and visuo-spatial information. Code and data: https://github.com/adymaharana/VLCStoryGan.
Node-wise Localization of Graph Neural Networks
Oct 27, 2021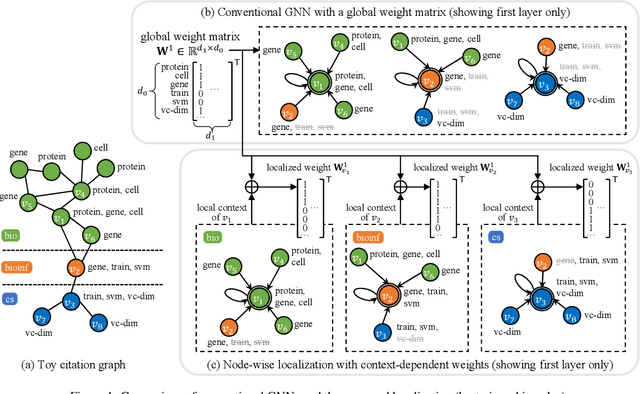
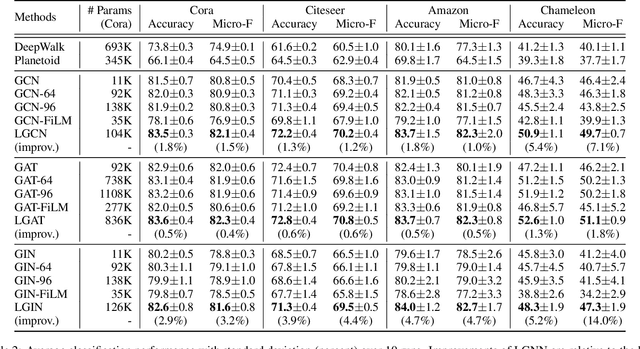
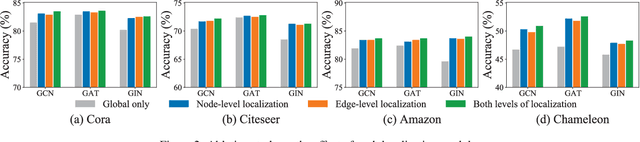
Graph neural networks (GNNs) emerge as a powerful family of representation learning models on graphs. To derive node representations, they utilize a global model that recursively aggregates information from the neighboring nodes. However, different nodes reside at different parts of the graph in different local contexts, making their distributions vary across the graph. Ideally, how a node receives its neighborhood information should be a function of its local context, to diverge from the global GNN model shared by all nodes. To utilize node locality without overfitting, we propose a node-wise localization of GNNs by accounting for both global and local aspects of the graph. Globally, all nodes on the graph depend on an underlying global GNN to encode the general patterns across the graph; locally, each node is localized into a unique model as a function of the global model and its local context. Finally, we conduct extensive experiments on four benchmark graphs, and consistently obtain promising performance surpassing the state-of-the-art GNNs.
Multi-agent Bayesian Deep Reinforcement Learning for Microgrid Energy Management under Communication Failures
Nov 22, 2021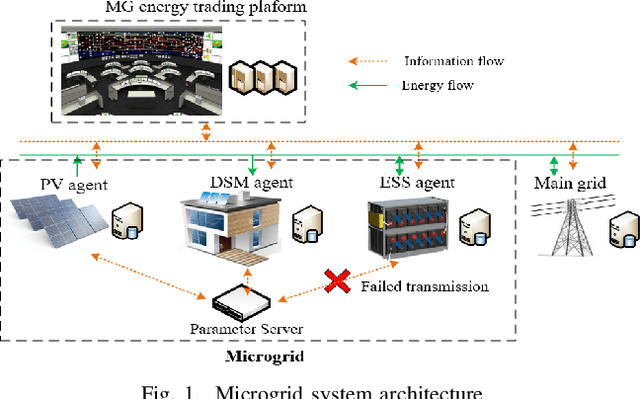
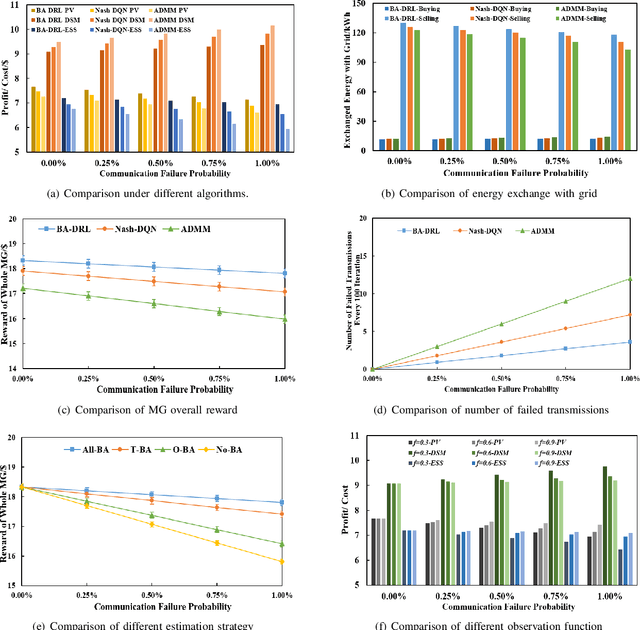
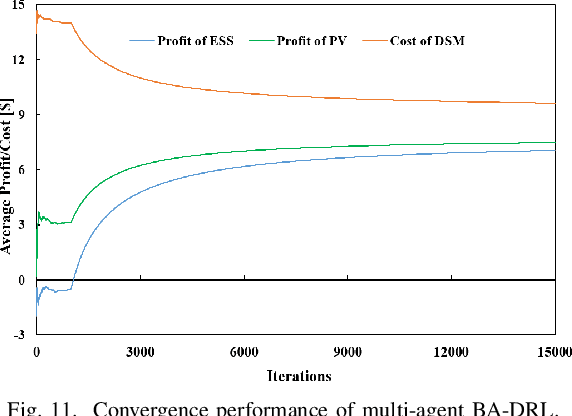
Microgrids (MGs) are important players for the future transactive energy systems where a number of intelligent Internet of Things (IoT) devices interact for energy management in the smart grid. Although there have been many works on MG energy management, most studies assume a perfect communication environment, where communication failures are not considered. In this paper, we consider the MG as a multi-agent environment with IoT devices in which AI agents exchange information with their peers for collaboration. However, the collaboration information may be lost due to communication failures or packet loss. Such events may affect the operation of the whole MG. To this end, we propose a multi-agent Bayesian deep reinforcement learning (BA-DRL) method for MG energy management under communication failures. We first define a multi-agent partially observable Markov decision process (MA-POMDP) to describe agents under communication failures, in which each agent can update its beliefs on the actions of its peers. Then, we apply a double deep Q-learning (DDQN) architecture for Q-value estimation in BA-DRL, and propose a belief-based correlated equilibrium for the joint-action selection of multi-agent BA-DRL. Finally, the simulation results show that BA-DRL is robust to both power supply uncertainty and communication failure uncertainty. BA-DRL has 4.1% and 10.3% higher reward than Nash Deep Q-learning (Nash-DQN) and alternating direction method of multipliers (ADMM) respectively under 1% communication failure probability.
Video Joint Modelling Based on Hierarchical Transformer for Co-summarization
Dec 27, 2021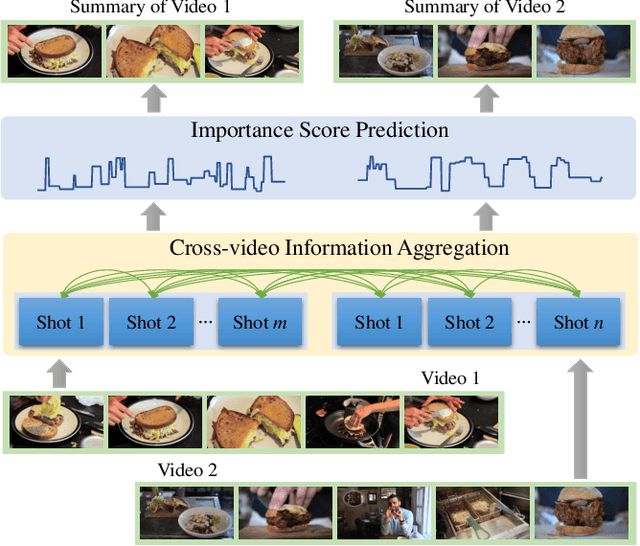

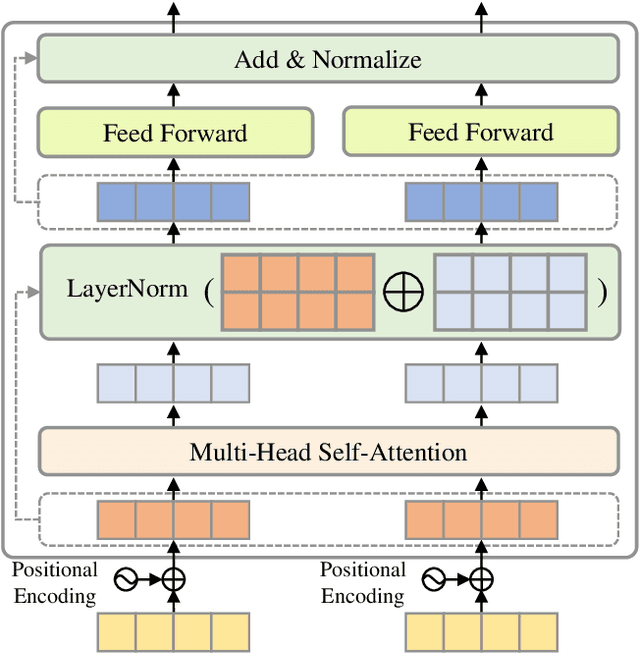
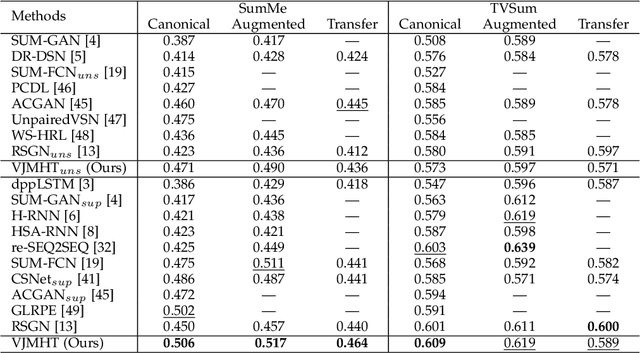
Video summarization aims to automatically generate a summary (storyboard or video skim) of a video, which can facilitate large-scale video retrieving and browsing. Most of the existing methods perform video summarization on individual videos, which neglects the correlations among similar videos. Such correlations, however, are also informative for video understanding and video summarization. To address this limitation, we propose Video Joint Modelling based on Hierarchical Transformer (VJMHT) for co-summarization, which takes into consideration the semantic dependencies across videos. Specifically, VJMHT consists of two layers of Transformer: the first layer extracts semantic representation from individual shots of similar videos, while the second layer performs shot-level video joint modelling to aggregate cross-video semantic information. By this means, complete cross-video high-level patterns are explicitly modelled and learned for the summarization of individual videos. Moreover, Transformer-based video representation reconstruction is introduced to maximize the high-level similarity between the summary and the original video. Extensive experiments are conducted to verify the effectiveness of the proposed modules and the superiority of VJMHT in terms of F-measure and rank-based evaluation.
Deep Learning For Prominence Detection In Children's Read Speech
Oct 27, 2021
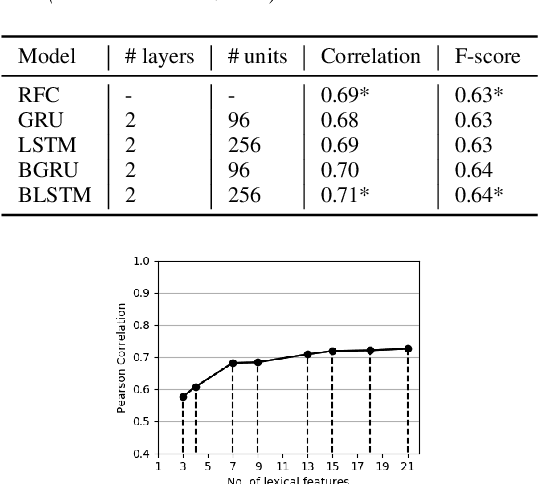
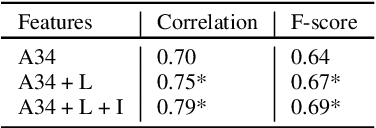
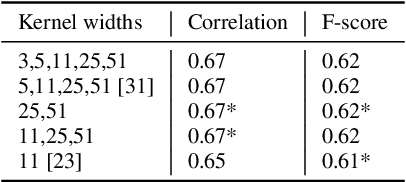
The detection of perceived prominence in speech has attracted approaches ranging from the design of linguistic knowledge-based acoustic features to the automatic feature learning from suprasegmental attributes such as pitch and intensity contours. We present here, in contrast, a system that operates directly on segmented speech waveforms to learn features relevant to prominent word detection for children's oral fluency assessment. The chosen CRNN (convolutional recurrent neural network) framework, incorporating both word-level features and sequence information, is found to benefit from the perceptually motivated SincNet filters as the first convolutional layer. We further explore the benefits of the linguistic association between the prosodic events of phrase boundary and prominence with different multi-task architectures. Matching the previously reported performance on the same dataset of a random forest ensemble predictor trained on carefully chosen hand-crafted acoustic features, we evaluate further the possibly complementary information from hand-crafted acoustic and pre-trained lexical features.